Sin electricidad, no habrá servicios de Internet altamente cargados que nos encanten tanto. Por extraño que parezca, los sistemas de control para las instalaciones de generación de electricidad, como las plantas de energía nuclear, también se distribuyen, también están sujetos a altas cargas y también requieren muchas tecnologías. Además, la participación de la energía nuclear en el mundo crecerá, la gestión de estas instalaciones y su seguridad es un tema muy importante.
Por lo tanto, comprendamos qué hay allí, cómo está organizado, dónde están las principales dificultades arquitectónicas y en qué parte de la planta de energía nuclear puede aplicar las modernas tecnologías ML y VR.
 Una planta de energía nuclear es:
Una planta de energía nuclear es:- Un promedio de 3-4 unidades de potencia con una capacidad promedio de 1000 MW por central nuclear, ya que los sistemas físicos deben ser respaldados, así como los servicios en Internet.
- Cerca de 150 subsistemas especiales que aseguran el funcionamiento de esta instalación. Por ejemplo, este es un sistema de control interno del reactor, un sistema de control de turbina, un sistema de control químico de tratamiento de agua, etc. Cada uno de estos subsistemas está integrado en un sistema enorme del nivel de bloque superior (SVBU) de un sistema de control de proceso automatizado (ACS TP).
- 200-300 mil etiquetas, es decir, fuentes de señal que cambian en tiempo real. Debe comprender qué es un cambio, qué no lo es, si no nos hemos perdido algo, y si nos hemos perdido, qué hacer al respecto. Estos parámetros son monitoreados por dos operadores, un ingeniero líder en control de reactores (VIUR) y un ingeniero líder en control de turbinas (VIUT).
- Dos edificios en los que se concentran la mayoría de los subsistemas: un reactor y un compartimento de turbina. Dos personas deben tomar una decisión en tiempo real en caso de que ocurran eventos no estándar o estándar. Se impone una responsabilidad tan alta a solo dos personas, porque si hay más de ellas, tendrán que ponerse de acuerdo entre ellas.
Sobre el orador: Vadim Podolny (
electrovenico ) representa a la fábrica de Moscú Fizpribor. Esto no es solo una fábrica, es principalmente una oficina de ingeniería en la que se desarrollan tanto hardware como software. El nombre es un homenaje a la historia de la empresa, que existe desde 1942. Esto no está muy de moda, pero es muy confiable, eso es lo que querían decirles.
IIoT en centrales nucleares
La empresa Fizpribor produce todo el complejo de equipos que se necesita para interactuar con la gran cantidad de subsistemas: estos son sensores, controladores de automatización posteriores, plataformas para construir controladores de automatización posteriores, etc.
En el diseño moderno, el controlador es solo un servidor industrial con un número ampliado de puertos de entrada / salida para conectar equipos con subsistemas especiales. Estos son gabinetes enormes, al igual que los gabinetes de servidores, solo que tienen controladores especiales que brindan computación, recopilación, procesamiento y administración.
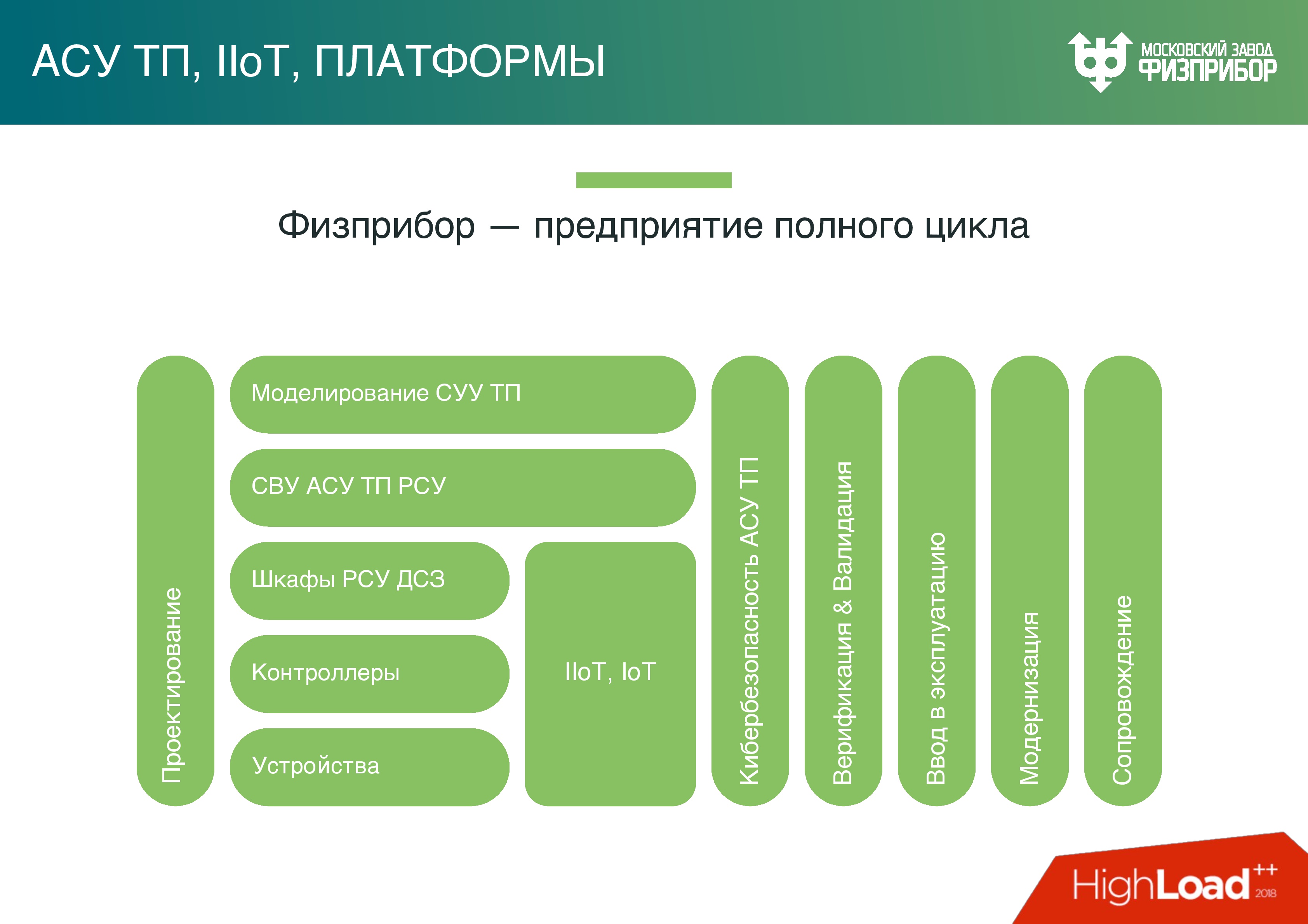
Desarrollamos software que está instalado en estos controladores, en equipos de puerta de enlace. Además, como en otros lugares, tenemos centros de datos, una nube local en la que tiene lugar la computación, el procesamiento, la toma de decisiones, el pronóstico y todo lo necesario para que funcione el objeto de control.
Cabe señalar que en nuestro siglo, el equipo está disminuyendo, volviéndose más inteligente. Muchos equipos ya tienen microprocesadores, pequeñas computadoras que proporcionan preprocesamiento, como ahora está de moda llamarlo, cálculos de límites que se realizan para no sobrecargar el sistema en general. Por lo tanto, podemos decir que el moderno sistema automatizado de control de procesos de las centrales nucleares ya es algo así como un Internet industrial de las cosas.
La plataforma que controla esto es la plataforma IoT de la que muchos han oído hablar. Hay un número considerable de ellos ahora, el nuestro está muy rígidamente vinculado al tiempo real.
Además de todo esto, los mecanismos de
verificación y validación de extremo a extremo están diseñados para proporcionar verificaciones de compatibilidad y confiabilidad. También incluye pruebas de estrés, pruebas de regresión, pruebas unitarias, todo lo que sabes. Solo esto se hace con el hardware que diseñamos y desarrollamos, y el software que funciona con este hardware. Se están abordando problemas de ciberseguridad (seguro por diseño, etc.).

La figura muestra los módulos de procesador que controlan los controladores. Esta es una plataforma de 6 unidades con un chasis para colocar placas base, en las cuales montamos en la superficie el equipo que necesitamos, incluidos los procesadores. Ahora tenemos una ola de sustitución de importaciones, estamos
tratando de apoyar a los procesadores nacionales . Alguien dice que como resultado, la seguridad de los sistemas industriales aumentará. Esto es cierto, un poco más adelante explicaré por qué.
Sistema de seguridad
Cualquier sistema de control de procesos en una planta de energía nuclear está reservado como un sistema de seguridad. La unidad de energía nuclear está diseñada para que el avión caiga sobre ella. El sistema de seguridad debe proporcionar enfriamiento de emergencia del reactor para que, debido al calor residual generado debido a la desintegración beta, no se derrita, como sucedió en la central nuclear de Fukushima. No había un sistema de seguridad, los generadores diesel de respaldo fueron arrastrados por una ola y sucedió lo que sucedió. Esto no es posible en nuestras centrales nucleares, porque nuestros sistemas de seguridad están ubicados allí.
La base de los sistemas de seguridad es la lógica difícil.
De hecho, estamos depurando uno o varios algoritmos de control que pueden combinarse en un algoritmo de grupo funcional, y soldamos toda esta historia directamente a la placa sin un microprocesador, es decir, obtenemos una lógica difícil. Si en algún momento se necesita reemplazar un equipo, su configuración o parámetros cambiarán, y será necesario realizar cambios en su algoritmo de operación; sí, tendrá que quitar la placa en la que se suelda el algoritmo y colocar una nueva. Pero es seguro,
caro, pero seguro .

A continuación se muestra un ejemplo de un sistema triple de
protección contra sabotaje , en el que un algoritmo para resolver un problema del sistema de seguridad en la realización es dos de tres. Hay tres de cada cuatro, es como RAID.

Diversidad tecnológica
En primer lugar, es importante utilizar diferentes procesadores. Si hacemos un sistema multiplataforma y seleccionamos un sistema común de módulos que se ejecutan en diferentes procesadores, entonces si el software malicioso ingresa al sistema en alguna etapa del ciclo de vida (diseño, desarrollo, mantenimiento preventivo), entonces no lo hará golpear inmediatamente toda la variedad de tecnología de sabotaje.

También hay una
variedad cuantitativa . La vista de los campos desde el satélite refleja bien el modelo, cuando cultivamos una variedad de cultivos tanto como sea posible en términos de presupuesto, espacio, comprensión y operación, es decir, nos damos cuenta de la redundancia, copiando los sistemas tanto como sea posible.
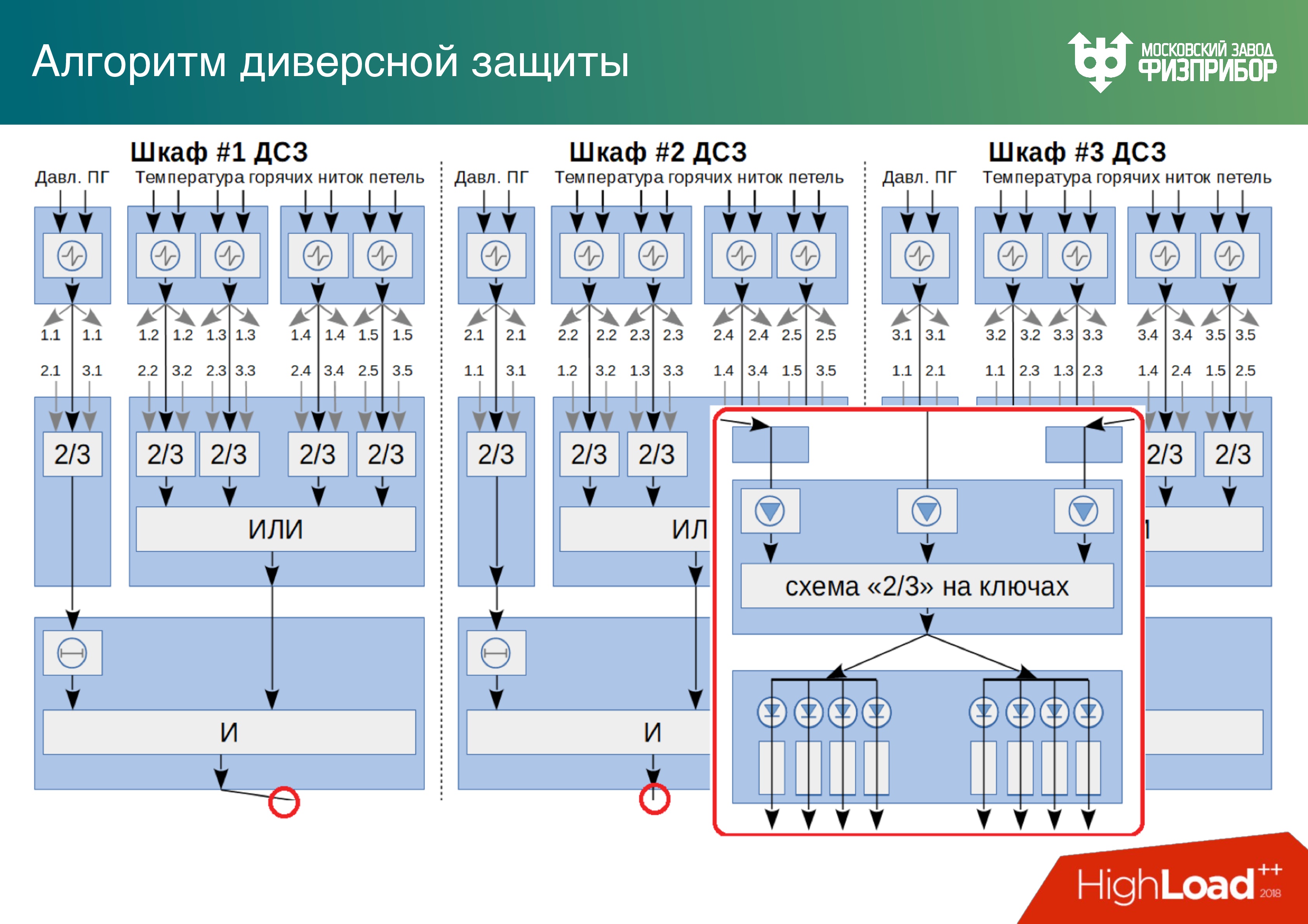
A continuación se muestra un algoritmo de ejemplo para elegir una solución basada en un sistema de protección de triple sabotaje. El algoritmo se considera correcto en función de dos de las tres respuestas. Creemos que si uno de los gabinetes falla, nosotros, en primer lugar, aprendemos al respecto, y en segundo lugar, los otros dos funcionarán bien. Hay campos enteros de tales gabinetes en las centrales nucleares.

Hablamos sobre hardware, pasemos a lo que es más interesante para todos: el software.
Software Top y columna vertebral
Así es como se ve el sistema de monitoreo de estos gabinetes.

El sistema de nivel superior (después de la automatización de bajo nivel) proporciona una recopilación, procesamiento y entrega confiables de información al operador y otros servicios de interés. En primer lugar, debe resolver la tarea principal: poder resolver todo
en el momento de las cargas máximas , por lo tanto, en funcionamiento normal, el sistema se puede cargar en un 5-10%. Las capacidades restantes realmente funcionan inactivas y están diseñadas para que en caso de emergencia podamos equilibrar, distribuir y procesar todas las sobrecargas.
El ejemplo más típico es una turbina. Proporciona la mayor cantidad de información, y si comienza a funcionar de manera inestable, DDoS realmente sucede, porque todo el sistema de información está obstruido con información de diagnóstico de esta turbina. Si
QoS no funciona bien, pueden surgir problemas graves: el operador simplemente no verá parte de la información importante.
De hecho, no todo es tan aterrador. Un operador puede trabajar en un reactímetro físico durante 2 horas, pero pierde algunos equipos. Para evitar que esto suceda, estamos desarrollando nuestra nueva plataforma de software. La versión anterior ahora sirve a 15 unidades de potencia, que se construyen en Rusia y en el extranjero.
 Una plataforma de software es una arquitectura de microservicio multiplataforma
Una plataforma de software es una arquitectura de microservicio multiplataforma que consta de varias capas:
- Una capa de datos es una base de datos en tiempo real. Es muy simple, algo así como el valor clave, pero el valor solo puede ser el doble. No se almacenan más objetos allí para eliminar por completo la posibilidad de desbordamiento del búfer, apilamiento u otra cosa.
- Una base de datos separada para almacenar metadatos. Utilizamos PostgreSQL y otras tecnologías, en principio, cualquier tecnología está configurada, porque no hay tiempo real difícil.
- Capa de archivo Este es un archivo en línea (aproximadamente un día) para procesar información actual y, por ejemplo, informes.
- Archivo a largo plazo.
- Archivo de emergencia : una caja negra que se usará si ocurre un accidente y el archivo a largo plazo está dañado. Los indicadores clave, las alarmas, el hecho de reconocer las alarmas se registran en él (el reconocimiento significa que el operador ha visto la alarma y está comenzando a hacer algo ).
- La capa lógica en la que se encuentra el lenguaje de secuencias de comandos. El núcleo informático se basa en él, y después del núcleo informático, al igual que un módulo, hay un generador de informes. Nada inusual: puede imprimir un gráfico, hacer una solicitud, ver cómo cambiaron los parámetros.
- Capa de cliente : un nodo que le permite desarrollar servicios de cliente basados en código, contiene una API.
Hay varias opciones para los nodos del cliente:
- Optimizado para grabación . Desarrolla controladores de dispositivo, pero no es un controlador clásico. Este es un programa que recopila información de controladores de automatización posteriores, realiza un procesamiento preliminar, analiza toda la información y los protocolos utilizados por los equipos de automatización posteriores: OPC, HART, UART, Profibus.
- Optimizado para la lectura : para crear interfaces de usuario, controladores y todo lo que va más allá.
En base a estos nodos, estamos construyendo una
nube . Consiste en servidores confiables clásicos que se administran utilizando sistemas operativos comunes. Utilizamos principalmente Linux, a veces QNX.
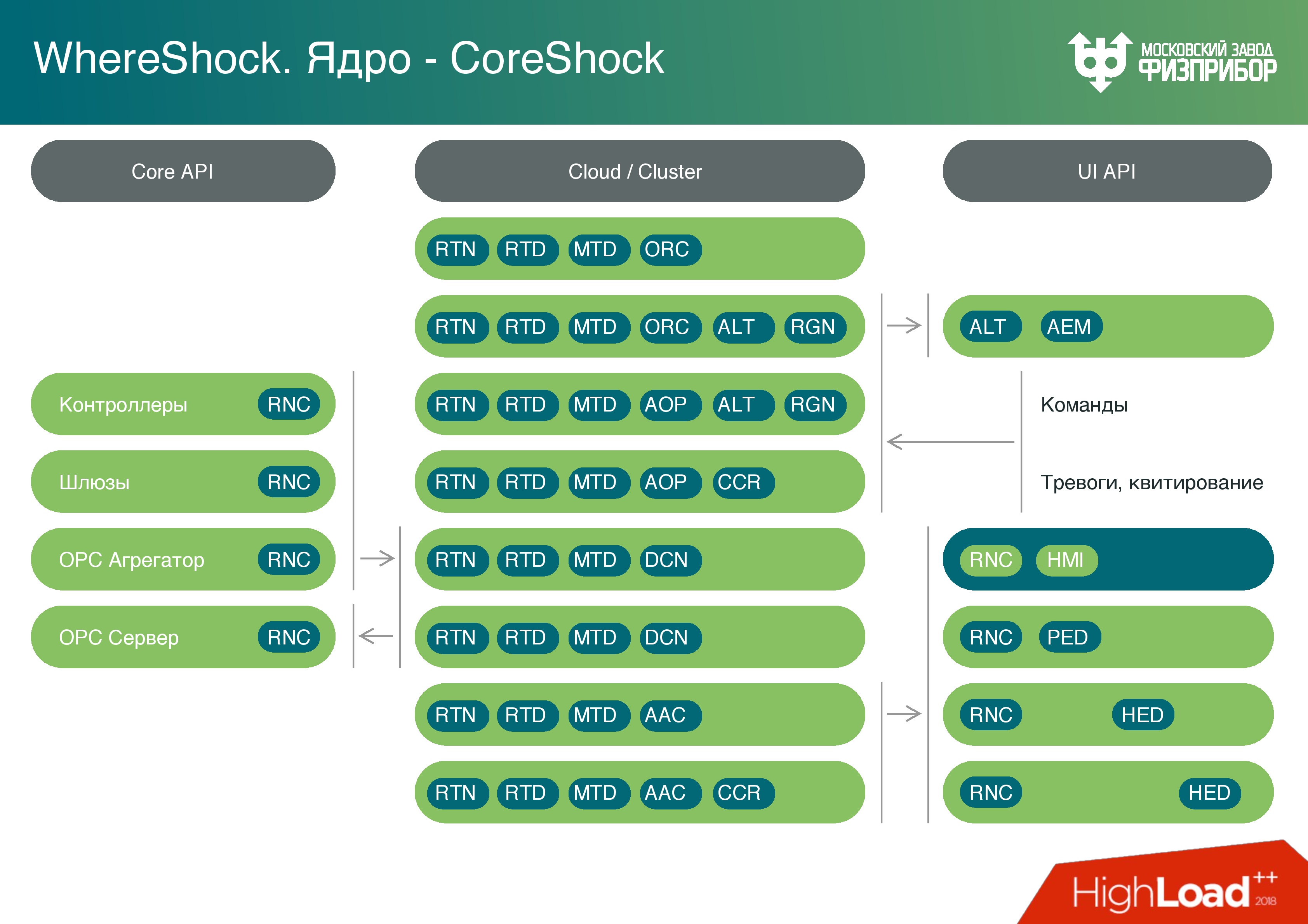
La nube se corta en máquinas virtuales, los contenedores se lanzan en algún lugar. Como parte de la virtualización de contenedores, se lanzan varios tipos de nodos que, si es necesario, realizan diferentes tareas. Por ejemplo, puede ejecutar el generador de informes una vez al día, cuando todos los materiales de informes necesarios para el día estén listos, las máquinas virtuales se descarguen y el sistema esté listo para otras tareas.
Llamamos a nuestro sistema
Vershok , y al núcleo del sistema de la
columna vertebral. Está claro por qué.

Teniendo recursos informáticos suficientemente potentes en los controladores de puerta de enlace, pensamos: ¿por qué no utilizar su potencia no solo para el preprocesamiento? Podemos convertir esta nube y todos los nodos fronterizos en niebla, y cargar estas capacidades con tareas, como, por ejemplo, identificar errores.

A veces sucede que los sensores tienen que calibrarse. Con el tiempo, las lecturas están flotando, sabemos de acuerdo a qué horario cambiarán sus lecturas, y en lugar de cambiar estos sensores, actualizamos los datos y hacemos correcciones, esto se llama calibración del sensor.
Tenemos una plataforma completa de Fog. Sí, realiza un número limitado de tareas en la niebla, pero aumentaremos gradualmente su número y descargaremos la nube total.
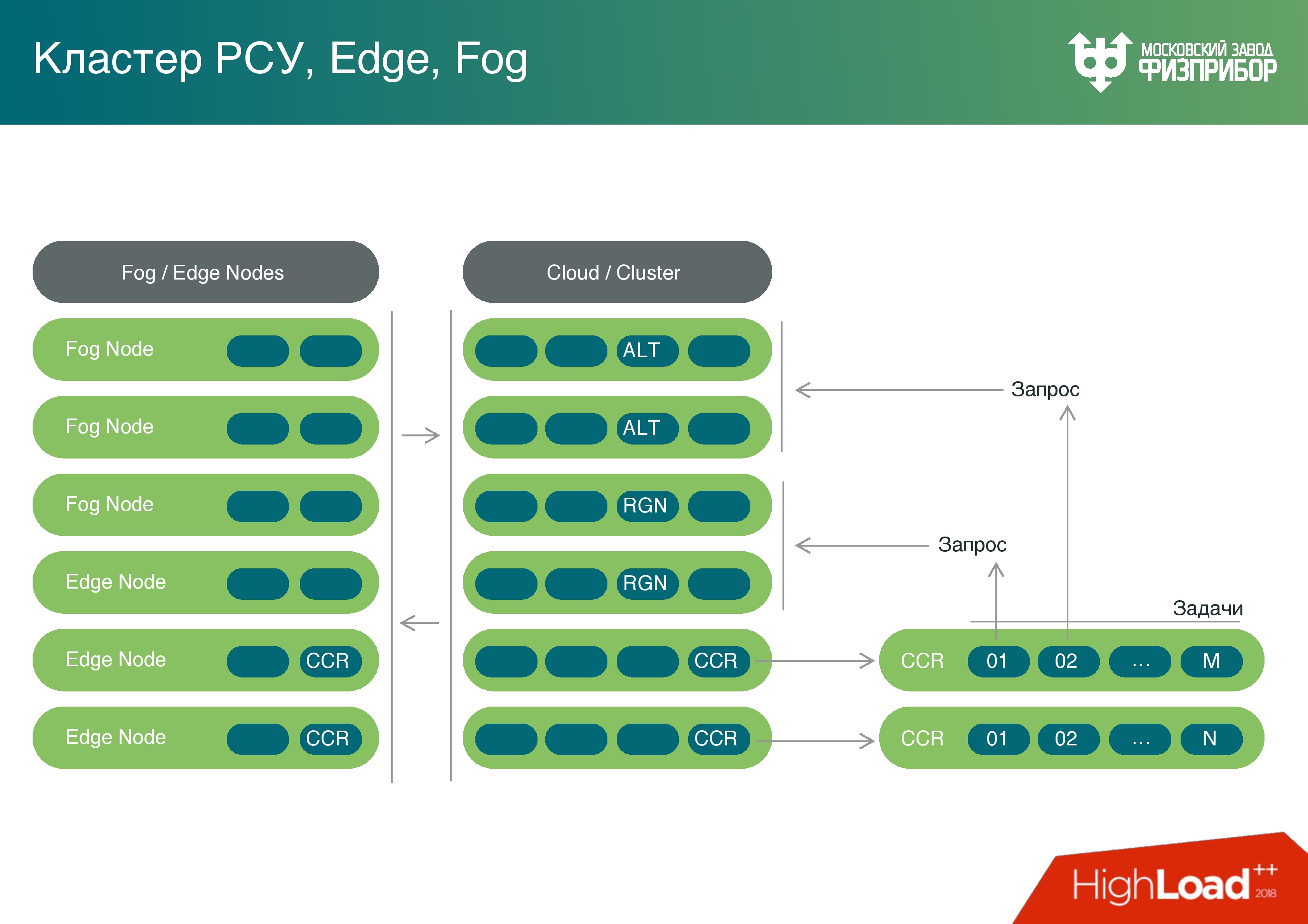
Además, tenemos un núcleo informático. Incluimos un lenguaje de script, podemos trabajar con Lua, con Python (por ejemplo, la biblioteca PyPy), con JavaScript y TypeScript para resolver problemas con las interfaces de usuario. Podemos realizar estas tareas igualmente bien tanto en la nube como en los nodos límite. Cada microservicio se puede iniciar en el procesador de absolutamente cualquier cantidad de memoria y potencia. Simplemente procesará la cantidad de información que es posible en las capacidades actuales. Pero el sistema funciona igual en absolutamente cualquier nodo. También es adecuado para su colocación en dispositivos IoT simples.
Ahora la información de varios subsistemas llega a esta plataforma: el nivel de protección física, los sistemas de control de control de acceso, la información de las cámaras, los datos de seguridad contra incendios, los sistemas de control de procesos, la infraestructura de TI, los eventos de seguridad de la información.
Sobre la base de estos datos, Behavior Analytics está construido: análisis de comportamiento. Por ejemplo, un operador no puede iniciar sesión si la cámara no registró que fue a la sala de operadores. U otro caso: vemos que algún canal de comunicación no funciona, mientras arreglamos que en este momento la temperatura del rack ha cambiado, la puerta se ha abierto. Alguien entró, abrió la puerta, sacó o golpeó el cable. Esto, por supuesto, no debería serlo, pero el monitoreo aún es necesario. Es necesario describir el mayor número posible de casos para que cuando ocurra algo de repente, lo sepamos con certeza.

Arriba hay ejemplos del equipo en el que funciona todo esto y sus parámetros:
- A la izquierda hay un servidor Supermicro normal. La elección recayó en Supermicro, ya que con todas las posibilidades de hierro están disponibles de inmediato, es posible utilizar equipos domésticos.
- A la derecha está el controlador, que se produce en nuestra fábrica. Confiamos plenamente en él y entendemos lo que está sucediendo allí. En la diapositiva, está completamente cargado con módulos informáticos.
Nuestro
controlador funciona con enfriamiento pasivo y, desde nuestro punto de vista, es mucho más confiable, por lo que intentamos transferir la cantidad máxima de tareas a los sistemas con enfriamiento pasivo. Cualquier ventilador fallará en algún momento, y la vida útil de la planta de energía nuclear es de 60 años, con la posibilidad de extensión a 80. Está claro que durante este tiempo se realizarán reparaciones preventivas programadas, se reemplazará el equipo. Pero si ahora toma un objeto que comenzó en los años 90 u 80, es incluso imposible encontrar una computadora para ejecutar el software que funciona allí. Por lo tanto, todo tiene que reescribirse y modificarse, incluidos los algoritmos.
Nuestros servicios operan en modo Multi-Master, no hay un solo punto de falla, todo esto es multiplataforma. Los nodos son autodeterminados, puede hacer Hot Swap, por lo que puede agregar y cambiar equipos, y no hay dependencia en la falla de uno o más elementos.

Existe la
degradación del sistema . Hasta cierto punto, el operador no debe notar que algo está mal en el sistema: el módulo del procesador se quemó o la alimentación del servidor desapareció y se apagó; El canal de comunicación se sobrecargó porque el sistema no está haciendo frente. Estos y otros problemas similares se pueden resolver haciendo una copia de seguridad de todos los componentes y la red. Ahora tenemos una topología de doble estrella y malla. Si algún nodo falla, la topología del sistema le permite continuar la operación normal.

Estas son comparaciones de los parámetros de Supermicro (arriba) y nuestro controlador (abajo), que obtenemos de actualizaciones basadas en una base de datos en tiempo real. Las Figuras 4 y 8 son el número de réplicas, es decir, la base de datos mantiene el estado actual de todos los nodos en tiempo real; estos son multidifusión y en tiempo real. En la configuración de prueba, hay aproximadamente 10 millones de etiquetas, es decir, fuentes de cambios de señal.
Supermicro muestra un promedio de 7 M / so 5 M / s, con un aumento en el número de réplicas. Estamos luchando para no perder el poder del sistema, con un aumento en el número de nodos. Desafortunadamente, cuando se hace necesario procesar la configuración y otros parámetros, perdemos velocidad con un aumento en el número de nodos, pero cuantos más nodos, menos pérdidas.
En
nuestro controlador (en Atom) los parámetros son un orden de magnitud menor.
Para crear una tendencia, se muestra al usuario un conjunto de etiquetas. A continuación se muestra una interfaz táctil para el operador, en la que puede seleccionar opciones. Cada nodo de cliente tiene una copia de la base de datos. El desarrollador de la aplicación cliente trabaja con memoria local y no piensa en sincronizar datos a través de la red, solo lo hace Get, Set a través de la API.
Desarrollar una interfaz de cliente para sistemas de control de procesos no es más complicado que desarrollar un sitio. Anteriormente, luchamos por el cliente en tiempo real, usamos C ++, Qt. Ahora lo hemos rechazado y hemos hecho todo en Angular. Los procesadores modernos le permiten mantener la confiabilidad de tales aplicaciones. La web ya es lo suficientemente confiable, aunque la memoria, por supuesto, es flotante.
La tarea de garantizar el funcionamiento de la aplicación durante un año sin reiniciar ya no es relevante. Todo esto está empaquetado en
Electron y, de hecho, le da independencia a la plataforma, es decir, la capacidad de ejecutar la interfaz en tabletas y paneles.
Ansiedad
Una alarma es el único objeto dinámico que aparece en el sistema. Después de que se inicia el sistema, se arregla todo el árbol de objetos; desde allí no se puede eliminar nada. Es decir, el modelo CRUD no funciona, solo puede marcar "marcar como eliminado". Si necesita eliminar una etiqueta, simplemente está marcada y oculta para todos, pero no se elimina, porque la operación de eliminación es compleja y puede dañar el estado del sistema, su integridad.
Una alarma es un objeto que aparece cuando un parámetro de señal de un equipo en particular va más allá de la configuración. Los ajustes son los límites de advertencia inferior y superior de los valores: emergencia, crítico, supercrítico, etc. Cuando un parámetro cae en un valor de escala particular, aparece una alarma correspondiente.
La primera pregunta que surge cuando se produce una alarma es a quién mostrar un mensaje al respecto. ¿Mostrar alarma a dos operadores? Pero nuestro sistema es universal, puede haber más operadores. En una planta de energía nuclear, las bases de datos del turbinista y el especialista en reactores difieren "un poco", porque el equipo es diferente. Está claro, por supuesto, si el nivel de señal ha superado los límites en el compartimento del reactor, esto lo verá el ingeniero de control del reactor líder, en la turbina, por la turbina.
Pero supongamos que hay muchos operadores. . - , . real-time , , . . , “” .
, . - “” – . , , , , “” . , . : , . , .
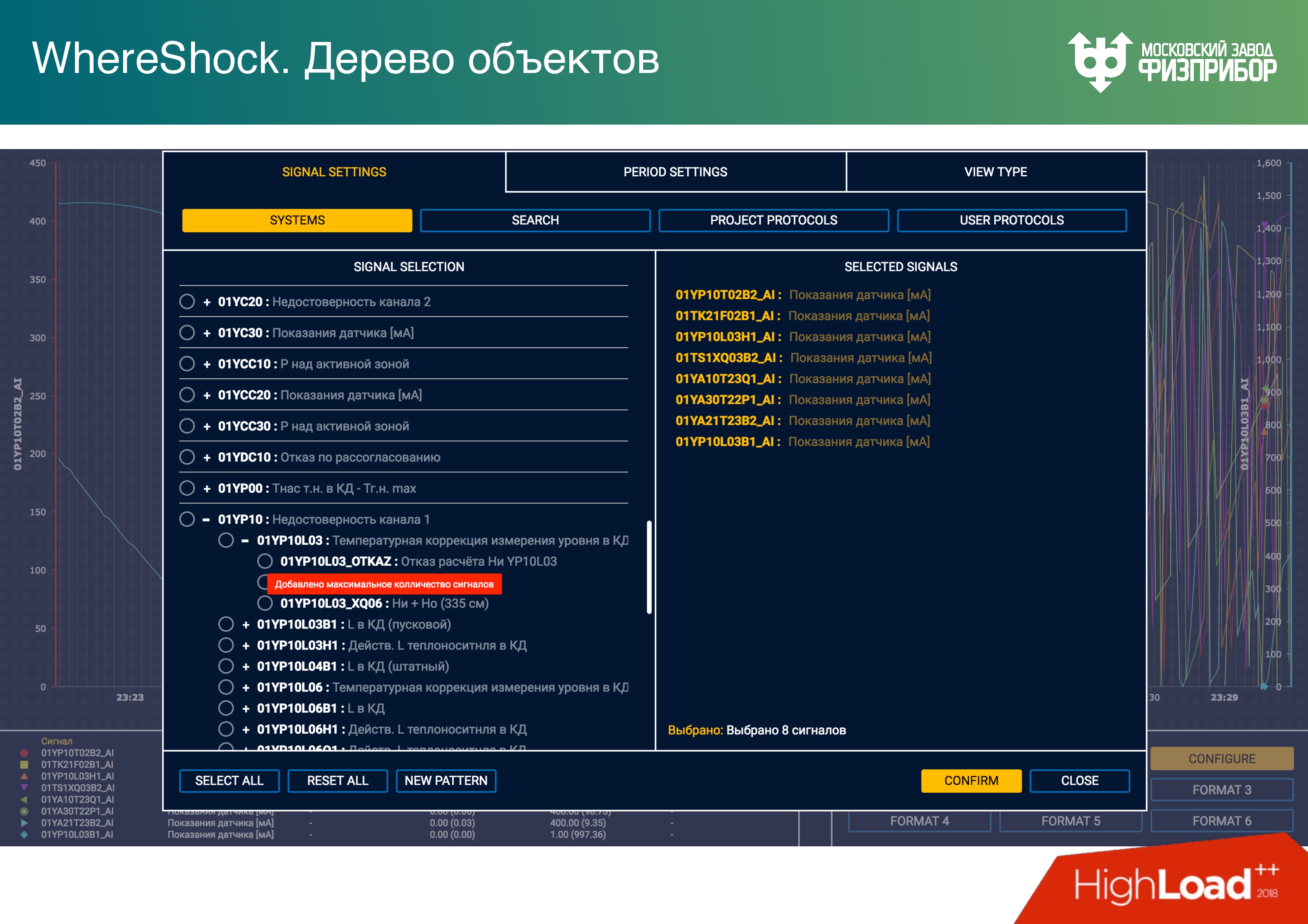
, , .

– .
. , .

.

, , , , .
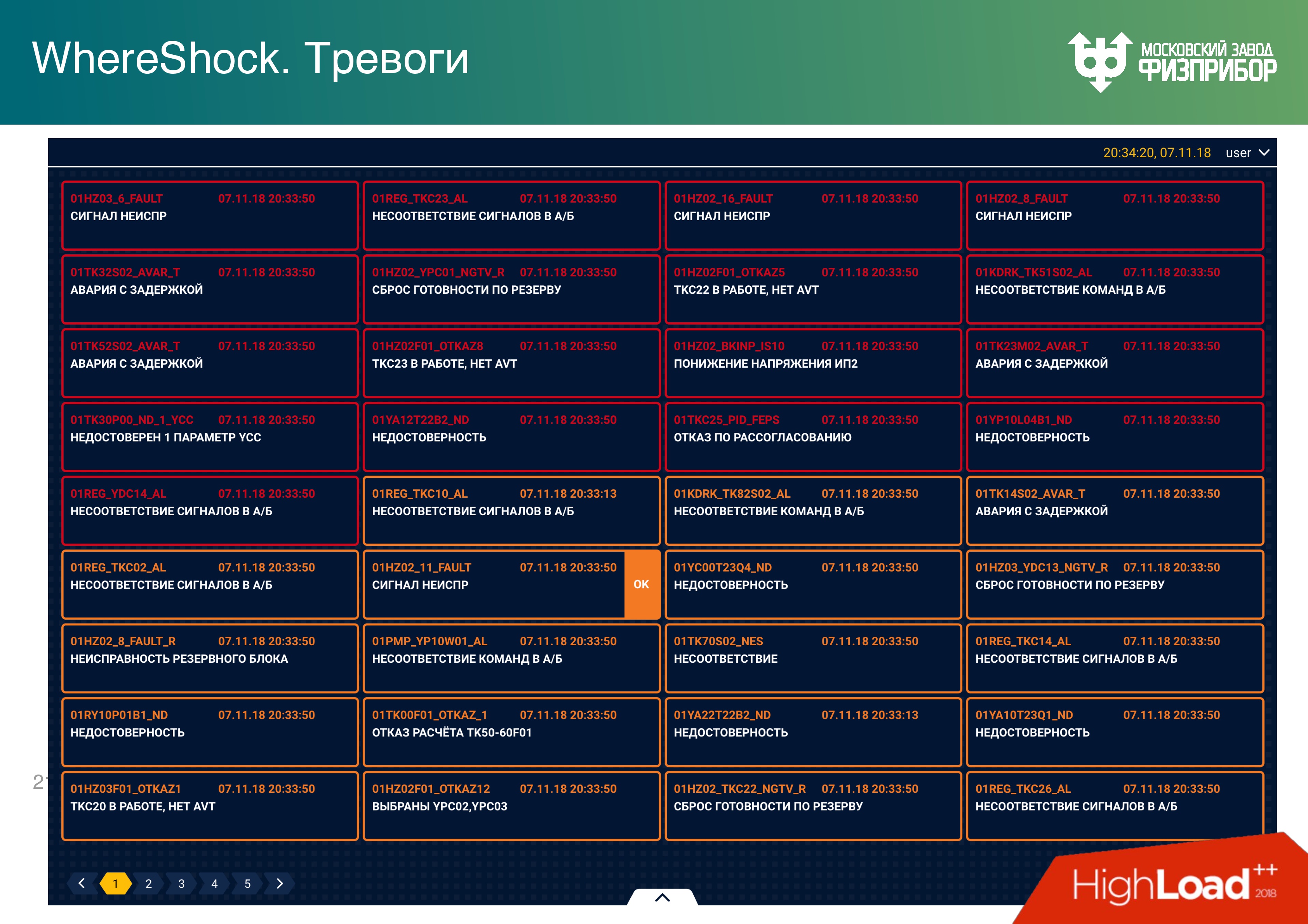
– , . SCADA/HMI , , , – , , . , : «, ! Illustrator, Sketch – , SVG». SVG . , .
, . API, . , , , . , , . , , , , – . , , , , .
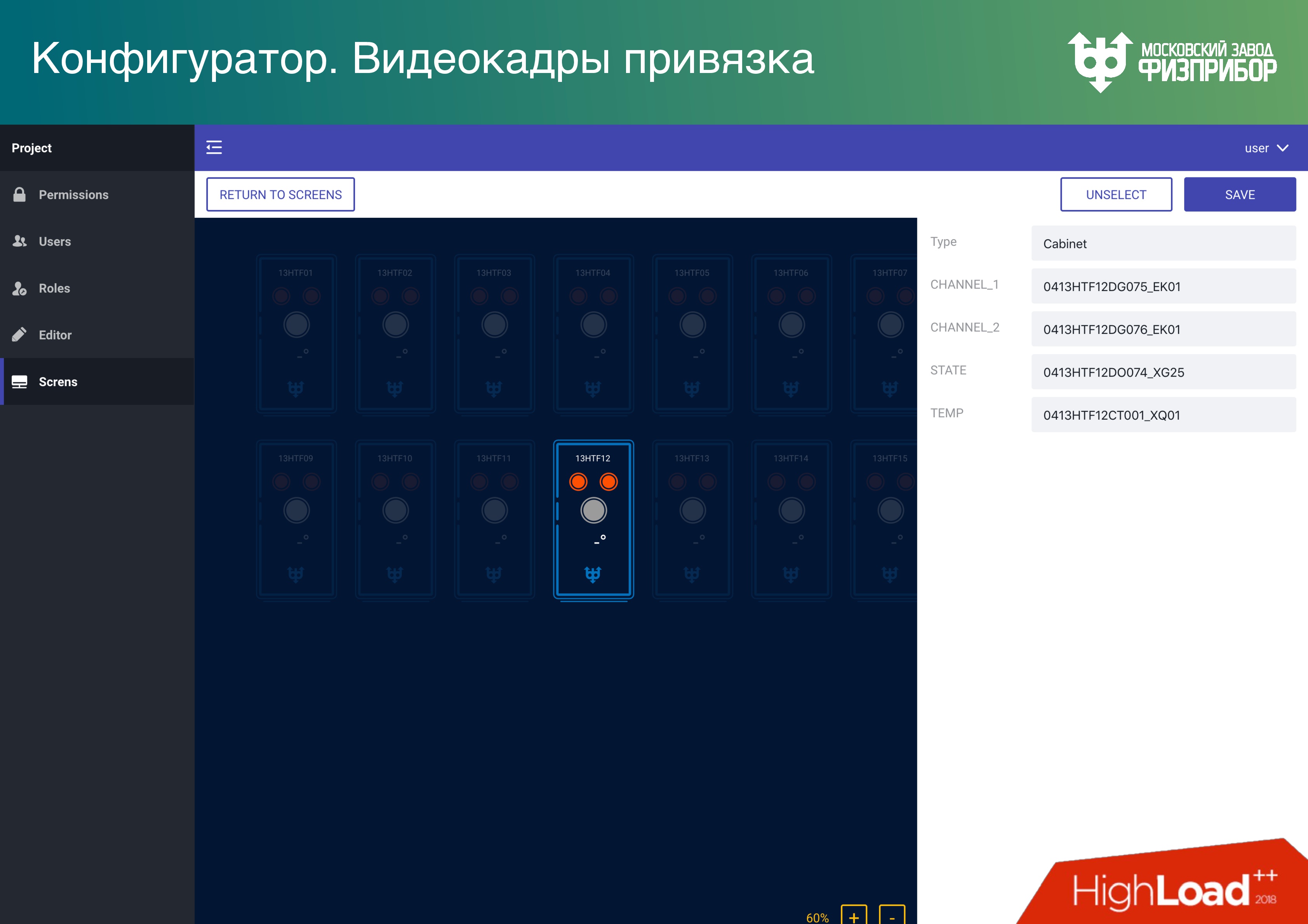
,
. , . Data Lake. ,
multitenancy (, ). .
, . , , ,
.
, : . , 10 100 , – .
, . , .
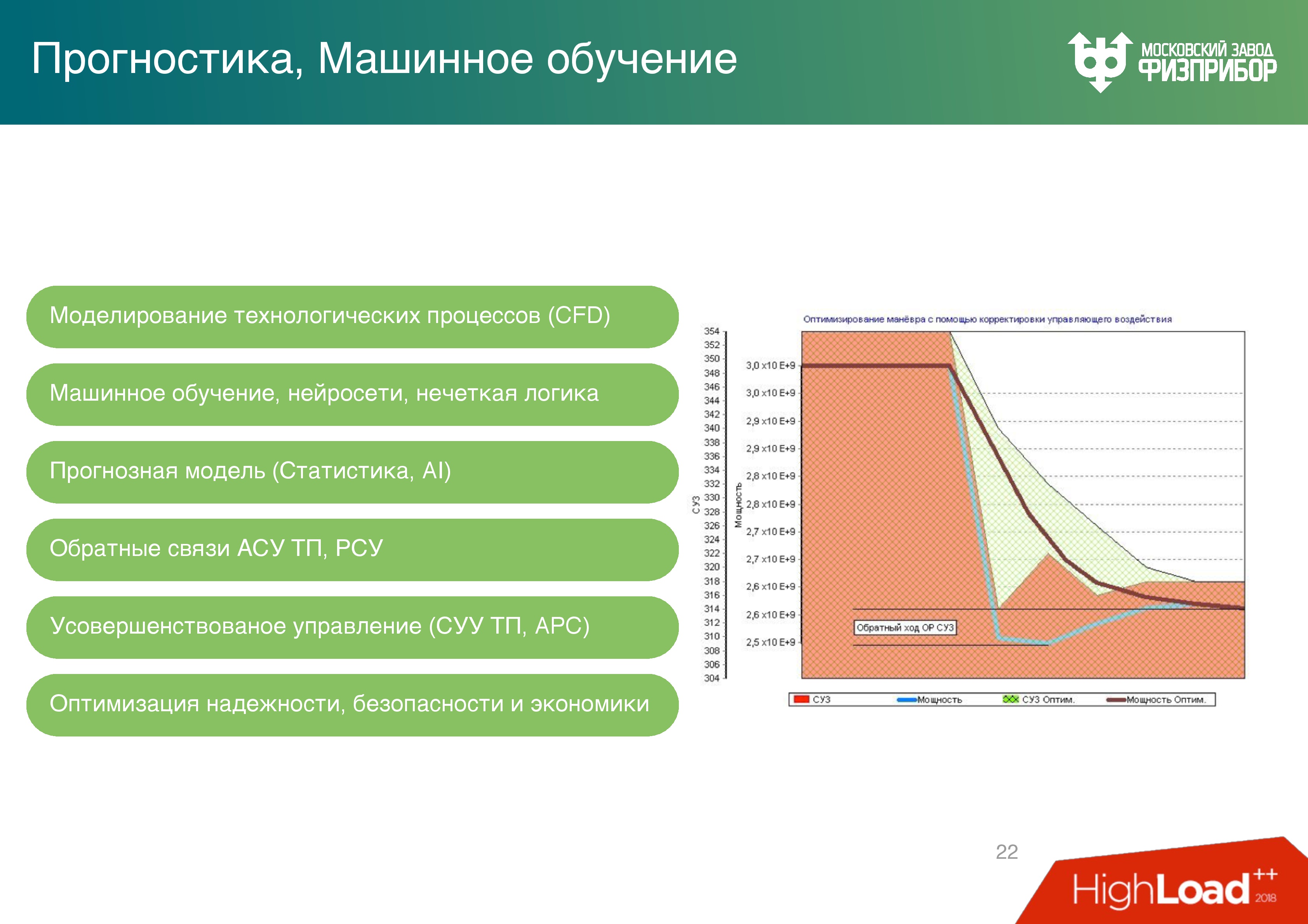
— . , , . – , : -1200 10 .
, , , , , - , , .… .
. . 5 : , , , . .
:
- - ( CPU);
- Computational Fluid Dynamics (CFD) ( GPU).
, . - , , ( ). .
60 , ( , ). KPI , .
.
 – , – .
– , – .. – . , , , – .
VR- , .

, , , . ( ) — , - . , , . — ( ), – ( ), .
, , — . . . .
ITER . , – . , , . , !
InoThings Conf 4 . IIoT , . . , .