
Entro al equipo central de Tarantool y participo en el desarrollo de un motor de base de datos, comunicaciones internas de componentes del servidor y replicación. Y hoy te diré cómo funciona la replicación.
Sobre la replicación
La replicación es el proceso de hacer copias de datos de una tienda a otra. Cada copia se llama réplica. La replicación se puede usar si necesita obtener una copia de seguridad, implementar un modo de espera activo o escalar el sistema horizontalmente. Y para esto es necesario poder utilizar los mismos datos en diferentes nodos de la red informática del clúster.
Clasificamos la replicación de dos maneras principales:
- Dirección: maestro-maestro o maestro-esclavo . La replicación maestro-esclavo es la opción más fácil. Tiene un nodo en el que está cambiando los datos. Traduce estos cambios a los otros nodos donde se aplican. Con la replicación maestro-maestro, los cambios se realizan en múltiples nodos a la vez. En este caso, cada nodo cambia sus datos y aplica los cambios realizados a otros nodos.
- Modo de funcionamiento: asíncrono o síncrono . La replicación sincrónica implica que los datos no se comprometerán y la replicación no se confirmará al usuario hasta que los cambios se propaguen al menos a través del mínimo número de nodos del clúster. En la replicación asincrónica, la confirmación de una transacción (confirmación) y la interacción con un usuario son dos procesos independientes. Para confirmar los datos, solo es necesario que caigan en el registro local, y solo entonces estos cambios se transmiten de alguna manera a otros nodos. Obviamente, la replicación asincrónica tiene varios efectos secundarios debido a esto.
¿Cómo funciona la replicación en Tarantool?
La replicación en Tarantool tiene varias características:
- Está construido a partir de ladrillos básicos, con los que puede crear un clúster de cualquier topología. Cada elemento de configuración básica es unidireccional, es decir, siempre tiene maestro y esclavo. Master realiza algunas acciones y genera un registro de operaciones, que se utiliza en la réplica.
- La replicación de Tarantool es asíncrona. Es decir, el sistema confirma el compromiso con usted, independientemente de cuántas réplicas haya visto esta transacción, cuánto se aplicó a sí mismo y si resultó que se hizo.
- Otra propiedad de replicación en Tarantool es que se basa en filas. Tarantool mantiene un registro de operaciones (WAL). La operación llega línea por línea, es decir, cuando cambia una tabla del espacio, esta operación se escribe en el registro como una línea. Después de eso, el proceso en segundo plano lee esta línea del registro y la envía a la réplica. Cuántas réplicas tiene el maestro, tantos procesos en segundo plano. Es decir, cada proceso de replicación a diferentes nodos del clúster se realiza de forma asíncrona desde otros.
- Cada nodo del clúster tiene su propio identificador único, que se genera cuando se crea el nodo. Además, el nodo también tiene un identificador en el clúster (número de miembro). Esta es una constante numérica que se asigna a una réplica cuando se conecta a un clúster, y permanece con la réplica durante su vida útil en el clúster.
Debido a la asincronía, los datos se entregan a réplicas retrasadas. Es decir, realizó algún cambio, el sistema confirmó la confirmación, la operación ya se aplicó en el maestro, pero en las réplicas se aplicará con cierto retraso, que está determinado por la velocidad con la que el proceso de replicación en segundo plano lee la operación, la envía a la réplica y se aplica .
Debido a esto, existe la posibilidad de que los datos no estén sincronizados. Supongamos que tenemos varios maestros que cambian los datos interconectados. Puede resultar que las operaciones que utiliza no sean conmutativas y se refieran a los mismos datos, luego dos miembros diferentes del clúster tendrán diferentes versiones de los datos.
Si la replicación en Tarantool es unidireccional maestro-esclavo, entonces, ¿cómo hacer maestro-maestro? Muy simple: cree otro canal de replicación pero en la otra dirección. Debe comprender que en Tarantool, la replicación maestro-maestro es solo una combinación de dos flujos de datos que son independientes entre sí.
Usando el mismo principio, podemos conectar el tercer maestro y, como resultado, construir una red de malla completa en la que cada réplica sea maestra y esclava para todas las demás réplicas.
Tenga en cuenta que no solo se replican aquellas operaciones que se inician localmente en este maestro, sino también aquellas que recibió externamente a través de protocolos de replicación. En este caso, los cambios creados en la réplica No. 1 vendrán a la réplica No. 3 dos veces: directamente ya través de la réplica No. 2. Esta propiedad nos permite construir topologías más complejas sin usar una malla completa. Digamos este.
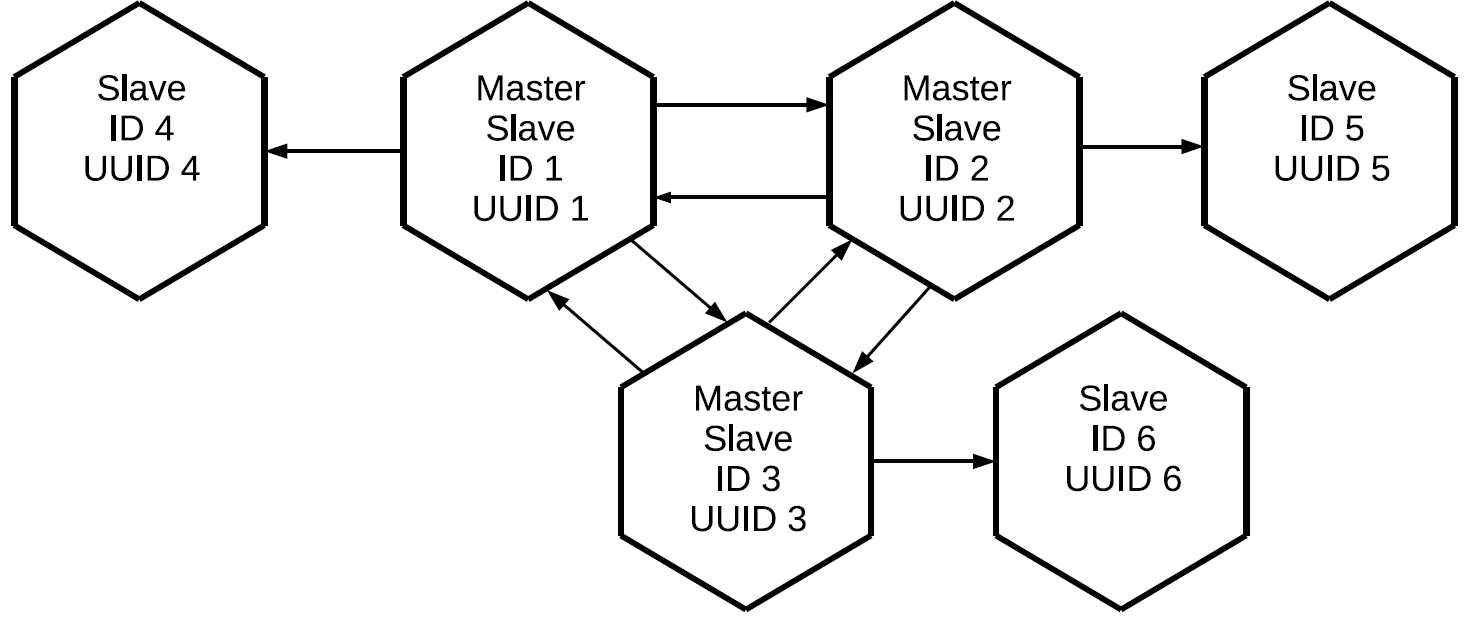
Los tres maestros, que juntos forman el núcleo de malla completa del clúster, tienen una réplica individual adjunta. Dado que la representación de registros se realiza en cada uno de los maestros, los tres esclavos "limpios" contendrán todas las operaciones que se realizaron en cualquiera de los nodos del clúster.
Esta configuración se puede usar para una variedad de tareas. No puede crear enlaces redundantes entre todos los nodos del clúster, y si las réplicas se colocan cerca, tendrán una copia exacta del maestro con un retraso mínimo. Y todo esto se hace utilizando el elemento básico de replicación maestro-esclavo.
Etiquetado de operaciones de clúster
Surge la pregunta:
si las operaciones se representan entre todos los miembros del clúster y llegan a cada réplica varias veces, ¿cómo entendemos qué operación debe realizarse y cuál no? Esto requiere un mecanismo de filtrado. A cada operación leída del registro se le asignan dos atributos:
- El identificador del servidor en el que se inició esta operación.
- El número de secuencia de la operación en el servidor, lsn, que es su iniciador. Cada servidor, al realizar una operación, asigna un número creciente a cada línea de registro recibida: 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 ... Por lo tanto, si sabemos que para un servidor con un determinado identificador, aplicamos la operación con lsn 10, luego no son necesarias las operaciones con lsn 9, 8, 7, 10 que llegaron a través de otros canales de replicación. En su lugar, aplicamos lo siguiente: 11, 12, etc.
Estado de réplica
¿Y cómo almacena Tarantool información sobre las operaciones que ya ha aplicado? Para hacer esto, hay un reloj Vclock: este es el vector del último lsn aplicado a cada nodo en el clúster.
[lsn 1 , lsn 2 , lsn n ]donde
lsn i es el número de la última operación conocida del servidor con el identificador i.
Vclock también se puede llamar una instantánea del estado completo del clúster conocido por esta réplica. Al conocer la ID del servidor de la operación que ha llegado, aislamos el componente del Vclock local que necesitamos, comparamos el lsn recibido con la operación lsn y decidimos si usar esta operación. Como resultado, las operaciones iniciadas por un maestro específico se enviarán y aplicarán secuencialmente. Al mismo tiempo, los flujos de trabajo creados en diferentes maestros pueden mezclarse entre sí debido a la replicación asincrónica.
Creación de clúster
Supongamos que tenemos un clúster que consta de dos elementos maestro y esclavo, y queremos conectarle una tercera instancia. Tiene un UUID único, pero todavía no hay un identificador de clúster. Si Tarantool aún no se ha inicializado, desea unirse al clúster, debe enviar una operación JOIN a uno de los maestros que puedan realizarlo, es decir, está en modo de lectura-escritura. En respuesta a JOIN, el maestro envía su instantánea local a la réplica de conexión. La réplica lo rueda en casa, mientras que todavía no tiene un identificador. Ahora la réplica con un ligero retraso se sincroniza con el clúster. Después de eso, el maestro en el que se ejecutó JOIN asigna un identificador a esta réplica, que se registra y se envía a la réplica. Cuando se asigna un identificador a una réplica, se convierte en un nodo completo y luego puede iniciar la replicación de registros a su lado.
Las líneas del diario se envían a partir del estado de esta réplica al momento de solicitar el registro de replicación al maestro, es decir, desde el vclock que recibió durante el proceso de UNIÓN, o desde el lugar donde la réplica se detuvo antes. Si la réplica se ha caído por algún motivo, la próxima vez que se conecte al clúster, ya no se unirá, porque ya tiene una instantánea local. Ella solo pregunta por todas las operaciones que ocurrieron durante su ausencia en el grupo.
Registrar una réplica en un clúster
Se utiliza un espacio especial para almacenar el estado de la estructura del clúster: clúster. Contiene los identificadores del servidor en el clúster, sus números de serie e identificadores únicos.
[1, 'c35b285c-c5b1-4bbe-83b1-b825eb594aa4']
[2, '37b12cb7-d324-4d75-b428-cde92c18e708']
[3, 'b72b1aa6-42a0-4d73-a611-900e44cdd465']No es necesario que los identificadores vayan en orden, porque los nodos se pueden eliminar y agregar.
Aquí está el primer escollo. Como regla, los clústeres no son recopilados por un nodo: ejecuta una determinada aplicación y despliega todo el clúster a la vez. Pero la replicación en Tarantool es asincrónica. ¿Qué sucede si dos maestros conectan simultáneamente nuevos nodos y les asignan identificadores idénticos? Habrá un conflicto.
Aquí hay un ejemplo de una UNIÓN incorrecta y correcta:

Tenemos dos maestros y dos réplicas que desean conectarse. Hacen uniones en diferentes maestros. Supongamos que las réplicas obtienen los mismos identificadores. Luego, la replicación entre los maestros y aquellos que logran replicar sus registros se desmoronará, el clúster se desmoronará.
Para evitar que esto suceda, debe iniciar réplicas estrictamente en un maestro en cualquier momento. Con este fin, Tarantool introdujo un concepto como líder de inicialización e implementó un algoritmo para elegir este líder. Una réplica que quiere conectarse al clúster primero establece una conexión con todos los maestros conocidos desde la configuración transferida. Luego, la réplica selecciona aquellos que ya se han iniciado (al implementar el clúster, no todos los nodos logran ganar dinero completo). Y de ellos se seleccionan los maestros que están disponibles para la grabación. En Tarantool, hay lectura-escritura y solo lectura, no podemos registrarnos en el nodo de solo lectura. Después de eso, de la lista de nodos filtrados, seleccionamos el que tiene el UUID más bajo.
Si usamos la misma configuración y la misma lista de servidores en instancias no inicializadas que se conectan al clúster, entonces seleccionarán el mismo maestro, lo que significa que JOIN probablemente tendrá éxito.
De aquí derivamos una regla: cuando se conectan réplicas a un clúster en paralelo, todas estas réplicas deben tener la misma configuración de replicación. Si omitimos algo en alguna parte, existe la posibilidad de que las instancias con una configuración diferente se inicien en diferentes maestros y el clúster no pueda ensamblarse.
Supongamos que nos equivocamos, o el administrador olvidó arreglar la configuración, o Ansible se rompió, y el clúster aún se desmoronó. ¿Qué puede dar testimonio de esto? Primero, las réplicas conectables no podrán crear sus instantáneas locales: las réplicas no se inician ni informan errores. En segundo lugar, en los maestros en los registros, veremos errores relacionados con conflictos en el clúster espacial.
¿Cómo resolvemos esta situación? Es simple:
- En primer lugar, debemos validar la configuración que establecemos para las réplicas de conexión, porque si no la arreglamos, todo lo demás será inútil.
- Después de eso, limpiamos los conflictos en el clúster y tomamos una foto.
Ahora puede intentar inicializar las réplicas nuevamente.
Resolución de conflictos
Entonces, creamos un clúster y nos conectamos. Todos los nodos funcionan en el modo de suscripción, es decir, reciben los cambios generados por diferentes maestros. Debido a que la replicación es asíncrona, los conflictos son posibles. Cuando cambia simultáneamente datos en diferentes maestros, diferentes réplicas obtienen diferentes copias de los datos, porque las operaciones se pueden aplicar en un orden diferente.
Aquí hay un clúster de ejemplo después de ejecutar JOIN:
Tenemos tres esclavos maestros, los registros se transmiten entre ellos, que se representan en diferentes direcciones y se aplican a los esclavos. Los datos no sincronizados significan que cada réplica tendrá su propio historial de cambios vclock, ya que las secuencias de diferentes maestros se pueden mezclar. Pero entonces el orden de las operaciones en las instancias puede variar. Si nuestras operaciones no son conmutativas, como la operación REEMPLAZAR, entonces los datos que recibamos en estas réplicas serán diferentes.
Un pequeño ejemplo. Supongamos que tenemos dos maestros con vclock = {0,0}. Y ambos realizarán dos operaciones, designadas como op1,1, op1,2, op2,1, op2,2. Este es el segundo segmento de tiempo cuando cada uno de los maestros realizó una operación local:

El verde indica un cambio en el componente vclock correspondiente. Primero, ambos maestros cambian su vclock, y luego el segundo maestro realiza otra operación local y nuevamente aumenta vclock. El primer maestro recibe la operación de replicación del segundo maestro, esto se indica con el número rojo 1 en vclock del primer nodo del clúster.

Luego, el segundo maestro recibe la operación del primero, y el primero, la segunda operación del segundo. Y al final, el primer maestro realiza su última operación, y el segundo maestro lo recibe.

Vclock en el cuanto de tiempo cero tenemos lo mismo - {0,0}. En el último cuanto de tiempo, también tenemos el mismo vclock {2,2}, parece que los datos deberían ser los mismos. Pero el orden de las operaciones realizadas en cada maestro es diferente. ¿Y si esta es una operación REPLACE con diferentes valores para las mismas claves? Luego, a pesar del mismo vclock al final, obtendremos diferentes versiones de los datos en ambas réplicas.
También podemos resolver esta situación.
- Sharding records . Primero, podemos realizar operaciones de escritura no en réplicas seleccionadas al azar, sino que de alguna manera las fragmentamos. Simplemente rompieron las operaciones de escritura en diferentes maestros y obtuvieron un sistema de consistencia eventual. Por ejemplo, las claves han cambiado de 1 a 10 en un maestro y de 11 a 20 en otro: los nodos intercambiarán sus registros y obtendrán exactamente los mismos datos.
Sharding implica que tenemos un cierto enrutador. No tiene que ser una entidad separada, el enrutador puede ser parte de la aplicación. Puede ser un fragmento que aplica operaciones de escritura a sí mismo o las transfiere a otro maestro de una forma u otra. Pero pasa de tal manera que los cambios en los valores asociados van a un maestro particular: un bloque de valor fue a un maestro, otro bloque a otro maestro. En este caso, las operaciones de lectura se pueden enviar a cualquier nodo del clúster. Y no se olvide de la replicación asincrónica: si grabó en el mismo maestro, es posible que también deba leerlo.
- Ordenamiento lógico de operaciones . Suponga que de acuerdo con las condiciones del problema, de alguna manera puede determinar la prioridad de la operación. Digamos, ponga una marca de tiempo, o versión, o alguna otra etiqueta que nos permita comprender qué operación ocurrió físicamente antes. Es decir, estamos hablando de una fuente externa de pedidos.
Tarantool tiene un desencadenador before_replace que se puede ejecutar durante la replicación. En este caso, no estamos limitados por la necesidad de enrutar solicitudes, podemos enviarlas a donde queramos. Pero cuando realizamos la replicación a la entrada del flujo de datos, tenemos un desencadenante. Lee la línea enviada, la compara con la línea que ya está almacenada y decide cuál de las líneas tiene mayor prioridad. Es decir, el activador ignora la solicitud de replicación o la aplica, posiblemente con las modificaciones requeridas. Ya aplicamos este enfoque, aunque también tiene sus inconvenientes. Primero, necesita una fuente de reloj externa. Supongamos que un operador en un salón de telefonía móvil realiza cambios en un suscriptor. Para tales operaciones, puede usar el tiempo en la computadora del operador, porque es poco probable que varios operadores realicen cambios en un suscriptor al mismo tiempo. Las operaciones pueden venir de diferentes maneras, pero si a cada una de ellas se le puede asignar una determinada versión, entonces, al pasar por los disparadores, solo permanecerán aquellos que sean relevantes.
El segundo inconveniente del método: dado que el disparador se aplica a cada delta que vino por la replicación para cada solicitud, esto crea una carga computacional adicional. Pero luego tendremos una copia consistente de los datos en una escala de clúster.
Sincronización
Nuestra replicación es asíncrona, es decir, mediante la ejecución de confirmación no sabe si estos datos ya están en algún otro nodo del clúster. Si realizó una confirmación en master, se le confirmó, y master por alguna razón dejó de funcionar inmediatamente, entonces no puede estar seguro de que los datos se hayan guardado en otro lugar. Para resolver este problema, el protocolo de replicación de Tarantool tiene un ACK. Cada maestro tiene conocimiento de qué último ACK vino de cada esclavo.
¿Qué es un ACK? Cuando el esclavo recibe el delta, que está marcado por el maestro lsn y su identificador, en respuesta envía un paquete ACK especial, en el que empaca su vclock local después de aplicar esta operación. Veamos cómo puede funcionar esto.
Tenemos un maestro que realizó 4 operaciones en sí mismo. Suponga que en algún momento el esclavo esclavo recibió las primeras tres líneas y su vclock aumentó a {3.0}.
ACK aún no ha llegado. Habiendo recibido estas tres líneas, el esclavo envía el paquete ACK al que ha cosido su vclock en el momento en que se envió el paquete. Deje que el esclavo maestro envíe otra línea en el mismo intervalo de tiempo, es decir, el vclock del esclavo ha aumentado. En base a esto, el maestro No. 1 sabe con certeza que las tres primeras operaciones que realizó ya se han aplicado a este esclavo. Estos estados se almacenan para todos los esclavos con los que trabaja el maestro; son completamente independientes.
Y al final, el esclavo responde con un cuarto paquete ACK. Después de eso, el maestro sabe que el esclavo está sincronizado con él.
Este mecanismo se puede usar en el código de la aplicación. Cuando confirma una operación, no reconoce inmediatamente al usuario, sino que primero llama a una función especial. Espera a que el esclavo lsn conocido por el maestro sea igual al lsn de su maestro en el momento en que se completa la confirmación. Por lo tanto, no necesita esperar la sincronización completa, solo espere el momento mencionado.
Supongamos que nuestra primera llamada ha cambiado tres líneas y la segunda llamada ha cambiado una. Después de la primera llamada, desea asegurarse de que los datos estén sincronizados. El estado que se muestra arriba ya significa que la primera llamada se sincronizó en al menos un esclavo.
Dónde exactamente buscar información sobre esto, lo consideraremos en la siguiente sección.
Monitoreo
Cuando la replicación es síncrona, el monitoreo es muy simple: si se desmorona, se emiten errores en sus operaciones. Y si la replicación es asincrónica, la situación se vuelve confusa. Shifu le responde que todo está bien, funciona, aceptado, anotado. Pero al mismo tiempo, todas las réplicas están muertas, los datos no tienen redundancia y si pierde el maestro, perderá los datos. Por lo tanto, realmente quiero monitorear el clúster, entender lo que está sucediendo con la replicación asincrónica, dónde están las réplicas, en qué estado se encuentran.
Para el monitoreo básico, Tarantool tiene una entidad box.info. Vale la pena llamarlo en la consola, ya que verá datos interesantes.
id: 1 uuid: c35b285c-c5b1-4bbe-83b1-b825eb594aa4 lsn : 5 vclock : {2: 1, 1: 5} replication : 1: id: 1 uuid : c35b285c -c5b1 -4 bbe -83b1 - b825eb594aa4 lsn : 5 2: id: 2 uuid : 37 b12cb7 -d324 -4 d75 -b428 - cde92c18e708 lsn : 1 upstream : status : follow idle : 0.30358312401222 peer : lag: 3.6001205444336 e -05 downstream : vclock : {2: 1, 1: 5}
La métrica más importante es la identificación
id . En este caso, 1 significa que el lsn de este maestro se almacenará en la primera posición en todos los vclock. Una cosa muy útil. Si tiene un conflicto con JOIN, puede distinguir un maestro de otro solo por identificadores únicos. Además, las cantidades locales incluyen cantidades tales como lsn. Este es el número de la última línea que este maestro ejecutó y escribió en su registro. En nuestro ejemplo, el primer maestro realizó cinco operaciones. Vclock es el estado de las operaciones que sabe que se aplicó a sí mismo. Y finalmente, para el maestro número 2, realizó una de sus operaciones de replicación.
Después de los indicadores del estado local, puede ver lo que esta instancia sabe sobre el estado de la replicación del clúster; para esto, hay una sección de
replication . Enumera todos los nodos del clúster conocidos por la instancia, incluido él mismo. El primer nodo tiene el identificador 1, id corresponde a la instancia actual. El segundo nodo tiene el identificador 2, su lsn 1 corresponde al lsn que se escribe en vclock. En este caso, consideramos la replicación maestro-maestro, cuando el maestro No. 1 es el maestro para el segundo nodo del clúster y su esclavo, es decir, lo sigue.
- La esencia de
upstream . El atributo de status follow significa que el maestro 1 sigue al maestro 2. Inactivo es el tiempo que ha pasado localmente desde la última interacción con este maestro. No enviamos un flujo continuamente, el maestro envía un delta solo cuando se producen cambios en él. Cuando enviamos algún tipo de ACK, también nos comunicamos. Obviamente, si la inactividad aumenta (segundos, minutos, horas), entonces algo está mal. - Atributo de
lag . Hablamos sobre el retraso. Además de lsn y server id cada operación en el registro también está marcada con una marca de tiempo - hora local durante la cual esta operación se registró en vclock en el maestro que la realizó. Al mismo tiempo, Slave compara su marca de tiempo local con la marca de tiempo del delta que recibió. La última marca de tiempo actual recibida para la última línea, el esclavo se muestra en la supervisión. - Atributo
downstream . Muestra lo que el maestro sabe sobre su esclavo en particular. Este es el ACK que el esclavo le envía. El downstream presentado anteriormente significa que la última vez que su esclavo, también conocido como maestro en el número 2, le envió su vclock, que era 5.1. Este maestro sabe que las cinco líneas, que completó en su lugar, se fueron a otro nodo.
Pérdida de XLOG
Considere la situación con la caída del maestro.
lsn : 0 id: 3 replication : 1: <...> upstream : status: disconnected peer : lag: 3.9100646972656 e -05 idle: 1602.836148153 message: connect, called on fd 13, aka [::1]:37960 2: <...> upstream : status : follow idle : 0.65611373598222 peer : lag: 1.9550323486328 e -05 3: <...> vclock : {2: 2, 1: 5}
En primer lugar, el estado cambiará.
Lag no cambia porque la línea que aplicamos sigue siendo la misma, no obtuvimos ninguna nueva. Al mismo tiempo, el tiempo de
idle creciendo, en este caso ya es igual a 1602 segundos, tanto tiempo el maestro estuvo muerto. Y vemos un mensaje de error: no hay conexión de red.
¿Qué hacer en una situación similar? Descubrimos lo que sucedió con nuestro maestro, atraemos al administrador, reiniciamos el servidor, elevamos el nodo. Se realiza una replicación repetida, y cuando el maestro ingresa al sistema, nos conectamos a él, nos suscribimos a su XLOG, los obtenemos para nosotros y el clúster se estabiliza.
Pero hay un pequeño problema. Imagine que tenemos un esclavo, que por alguna razón se apagó y estuvo ausente durante mucho tiempo. Durante este tiempo, el maestro, que lo sirvió, eliminó el XLOG. Por ejemplo, el disco está lleno, el recolector de basura ha recopilado registros. ¿Cómo puede continuar un esclavo que regresa? De ninguna manera Porque los registros que necesita aplicar para sincronizarse con el clúster se han ido y no hay de dónde sacarlos. En este caso, veremos un error interesante: el estado ya no se
disconnected , sino que se
stopped . Y un mensaje específico: no hay ningún archivo de registro que coincida con tal lsn.
id: 3 replication : 1: <...> upstream : peer : status: stopped lag : 0.0001683235168457 idle : 9.4331328970147 message: 'Missing .xlog file between LSN 7 1: 5, 2: 2 and 8 1: 6, 2: 2' 2: <...> 3: <...> vclock : {2: 2, 1: 5}
De hecho, la situación no siempre es fatal. Supongamos que tenemos más de dos maestros, y en algunos de ellos estos registros aún se conservan. Los entregamos a todos los maestros a la vez, y no los almacenamos en uno solo. Luego resulta que esta réplica, que se conecta con todos los maestros que conoce, en algunos de ellos encontrará los registros que necesita. Ella realizará todas estas operaciones en casa, su vclock aumentará y alcanzará el estado actual del grupo. Después de eso, puedes intentar reconectarte.
Si no hay registros, no podemos continuar con la réplica. Solo queda reiniciarlo. Recuerde su identificador único, puede escribirlo en una hoja de papel o en un archivo. Luego limpiamos la réplica localmente: elimina sus imágenes, registros, etc. Después de eso, vuelva a conectar la réplica con el mismo UUID que tenía.
Elimine el clúster o reutilice el UUID para la nueva réplica:
box.cfg{instance_uuid = uuid} .
, . UUID space cluster, . , . UUID, master, JOIN, , UUID, , .
, UUID , space cluster , . . , , .
, - . , . , , .
Tarantool .
replication_connect_quorum: 2
replication_connect_timeout: 30
replication_sync_lag: 0.1, , , , , , master' 0,1 . 30 . , . 0,1 . , .
Keep alive
, ip tables drop. , - 30 30 , , . , keep alive-.
keep alive- :
box.cfg.replication_timeout .
master' , keep alive-, , . 4 master slave keep alive- , . master'.
, . 6 , 5 . 10 , 9 . .
, , . , master', . - . .
6 , 3. , . , 5 , 3 .
, :
, Telegram-, . , GitHub, .