Parte 2/3 aquí
Parte 3/3 aquí
Hola a todos! En este artículo quiero optimizar la información y compartir la experiencia de crear y usar el clúster interno de Kubernetes.
En los últimos años, esta tecnología de orquestación de contenedores ha dado un gran paso adelante y se ha convertido en una especie de estándar corporativo para miles de empresas. Algunos lo usan en producción, otros solo lo prueban en proyectos, pero las pasiones a su alrededor, no importa cómo lo digas, brillan con seriedad. Si nunca lo has usado antes, es hora de comenzar a salir.
0. Introducción
Kubernetes es una tecnología de orquestación escalable que puede comenzar con la instalación en un solo nodo y alcanzar el tamaño de grandes clústeres HA basados en varios cientos de nodos en su interior. Los proveedores de nube más populares proporcionan diferentes tipos de implementaciones de Kubernetes: toma y uso. Pero las situaciones son diferentes, y hay empresas que no usan las nubes y quieren obtener todas las ventajas de las tecnologías modernas de orquestación. Y aquí viene la instalación de Kubernetes en metal desnudo.

1. Introducción
En este ejemplo, crearemos un clúster de Kubernetes HA con la topología para varios maestros, con un clúster externo, etc. como capa base y un equilibrador de carga MetalLB dentro. En todos los nodos de trabajo, implementaremos GlusterFS como un simple almacenamiento de clúster distribuido interno. También intentaremos implementar varios proyectos de prueba en él utilizando nuestro registro personal de Docker.
En general, hay varias formas de crear un clúster de Kubernetes HA: la ruta difícil y profunda que se describe en el popular documento kubernetes-the-hard-way , o la forma más simple de usar la utilidad kubeadm .
Kubeadm es una herramienta creada por la comunidad de Kubernetes específicamente para simplificar la instalación de Kubernetes y facilitar el proceso. Anteriormente, Kubeadm se recomendaba solo para crear pequeños grupos de prueba con un nodo maestro, para comenzar. Pero durante el año pasado, se ha mejorado mucho, y ahora podemos usarlo para crear clústeres HA con varios nodos maestros. Según las noticias de la comunidad de Kubernetes, en el futuro, se recomendará Kubeadm como herramienta para instalar Kubernetes.
La documentación de Kubeadm ofrece dos formas básicas de implementar un clúster, con topologías de pila y externas, etc. Elegiré la segunda ruta con nodos externos, etc. debido a la tolerancia a fallas del clúster HA.
Aquí hay un diagrama de la documentación de Kubeadm que describe esta ruta:
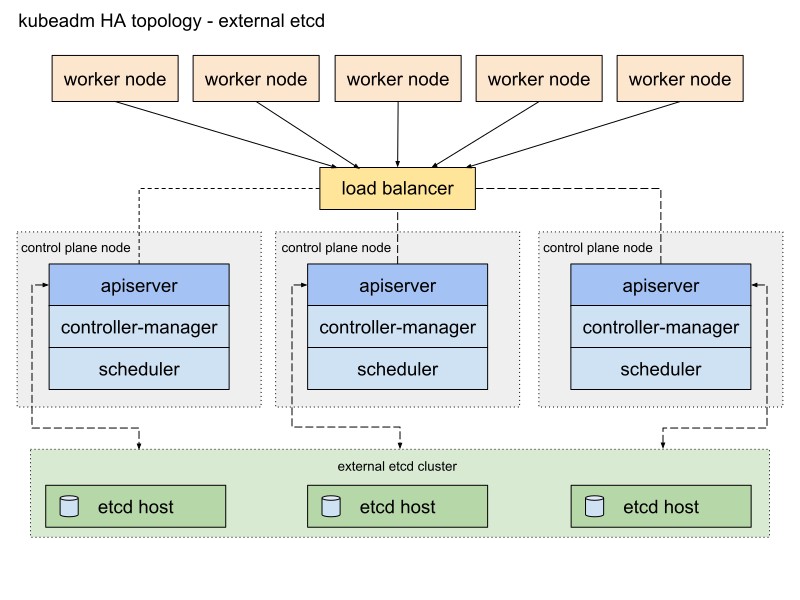
Lo cambiaré un poco. Primero, usaré un par de servidores HAProxy como equilibradores de carga con el paquete Heartbeat, que compartirá la dirección IP virtual. Heartbeat y HAProxy utilizan una pequeña cantidad de recursos del sistema, por lo que los colocaré en un par de nodos etcd para reducir ligeramente la cantidad de servidores para nuestro clúster.
Para este esquema de clúster de Kubernetes, se requieren ocho nodos. Tres servidores para un clúster externo, etcd (los servicios LB también usarán un par de ellos), dos para los nodos del plano de control (nodos maestros) y tres para los nodos de trabajo. Puede ser un metal desnudo o un servidor VM. En este caso, no importa. Puede cambiar fácilmente el esquema agregando más nodos maestros y colocando HAProxy con Heartbeat en nodos separados, si hay muchos servidores gratuitos. Aunque mi opción para la primera implementación del clúster HA es suficiente para los ojos.
Si lo desea, agregue un pequeño servidor con la utilidad kubectl instalada para administrar este clúster o use su propio escritorio Linux para esto.
El diagrama para este ejemplo se verá así:
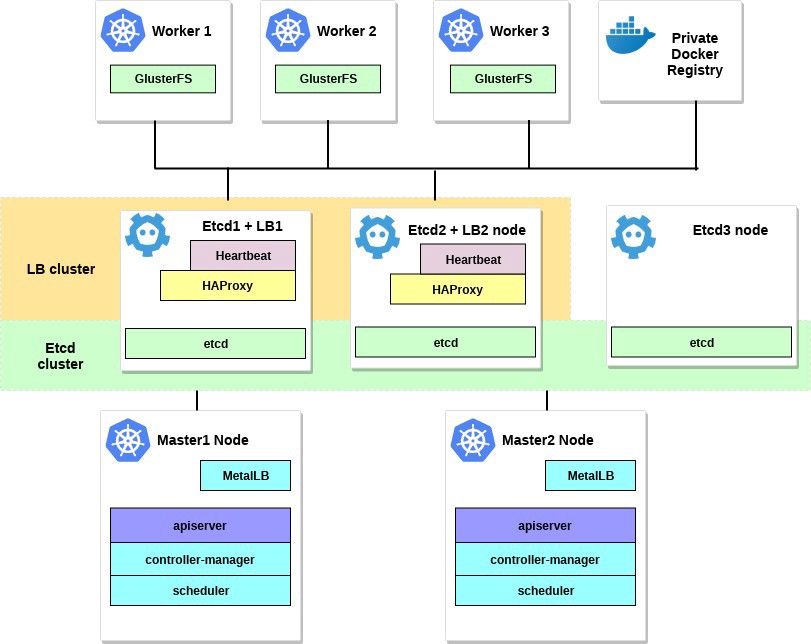
2. Requisitos
Necesitará dos nodos maestros Kubernetes con los requisitos mínimos del sistema recomendados: 2 CPU y 2 GB de RAM de acuerdo con la documentación de kubeadm . Para los nodos de trabajo, recomiendo usar servidores más potentes, ya que ejecutaremos todos nuestros servicios de aplicaciones en ellos. Y para Etcd + LB, también podemos tomar servidores con dos CPU y al menos 2 GB de RAM.
Seleccione una red pública o privada para este clúster; Las direcciones IP no importan; Es importante que todos los servidores sean accesibles entre sí y, por supuesto, para usted. Más tarde, dentro del clúster de Kubernetes, configuraremos una red superpuesta.
Los requisitos mínimos para este ejemplo son:
- 2 servidores con 2 procesadores y 2 GB de RAM para el nodo maestro
- 3 servidores con 4 procesadores y 4-8 GB de RAM para nodos de trabajo
- 3 servidores con 2 procesadores y 2 GB de RAM para Etcd y HAProxy
- 192.168.0.0/24: la subred.
192.168.0.1 - Dirección IP virtual HAProxy, 192.168.0.2 - 4 direcciones IP principales de nodos Etcd y HAProxy, 192.168.0.5 - 6 direcciones IP principales del nodo maestro Kubernetes, 192.168.0.7 - 9 direcciones IP principales de nodos de trabajo Kubernetes .
La base de datos Debian 9 está instalada en todos los servidores.
Recuerde también que los requisitos del sistema dependen de cuán grande y poderoso sea el clúster. Para obtener más información, consulte la documentación de Kubernetes.
3. Configure HAProxy y Heartbeat.
Tenemos más de un nodo maestro de Kubernetes y, por lo tanto, debe configurar un equilibrador de carga HAProxy frente a ellos para distribuir el tráfico. Este será un par de servidores HAProxy con una dirección IP virtual compartida. La tolerancia a fallos se proporciona con el paquete Heartbeat. Para la implementación, utilizaremos los dos primeros servidores etcd.
Instale y configure HAProxy con Heartbeat en el primer y segundo servidor etcd (192.168.0.2–3 en este ejemplo):
etcd1# apt-get update && apt-get upgrade && apt-get install -y haproxy etcd2# apt-get update && apt-get upgrade && apt-get install -y haproxy
Guarde la configuración original y cree una nueva:
etcd1# mv /etc/haproxy/haproxy.cfg{,.back} etcd1# vi /etc/haproxy/haproxy.cfg etcd2# mv /etc/haproxy/haproxy.cfg{,.back} etcd2# vi /etc/haproxy/haproxy.cfg
Agregue estas opciones de configuración para ambos HAProxy:
global user haproxy group haproxy defaults mode http log global retries 2 timeout connect 3000ms timeout server 5000ms timeout client 5000ms frontend kubernetes bind 192.168.0.1:6443 option tcplog mode tcp default_backend kubernetes-master-nodes backend kubernetes-master-nodes mode tcp balance roundrobin option tcp-check server k8s-master-0 192.168.0.5:6443 check fall 3 rise 2 server k8s-master-1 192.168.0.6:6443 check fall 3 rise 2
Como puede ver, ambos servicios HAProxy comparten la dirección IP: 192.168.0.1. Esta dirección IP virtual se moverá entre los servidores, por lo que seremos un poco astutos y habilitaremos el parámetro net.ipv4.ip_nonlocal_bind para permitir el enlace de los servicios del sistema a una dirección IP no local.
Agregue esta característica al archivo /etc/sysctl.conf :
etcd1# vi /etc/sysctl.conf net.ipv4.ip_nonlocal_bind=1 etcd2# vi /etc/sysctl.conf net.ipv4.ip_nonlocal_bind=1
Ejecutar en ambos servidores:
sysctl -p
También ejecute HAProxy en ambos servidores:
etcd1# systemctl start haproxy etcd2# systemctl start haproxy
Asegúrese de que HAProxy se esté ejecutando y escuchando en la dirección IP virtual en ambos servidores:
etcd1# netstat -ntlp tcp 0 0 192.168.0.1:6443 0.0.0.0:* LISTEN 2833/haproxy etcd2# netstat -ntlp tcp 0 0 192.168.0.1:6443 0.0.0.0:* LISTEN 2833/haproxy
Capucha! Ahora instale Heartbeat y configure esta IP virtual.
etcd1# apt-get -y install heartbeat && systemctl enable heartbeat etcd2# apt-get -y install heartbeat && systemctl enable heartbeat
Es hora de crear varios archivos de configuración para él: para el primer y el segundo servidor, serán básicamente los mismos.
Primero cree el archivo /etc/ha.d/authkeys , en este archivo Heartbeat almacena datos para la autenticación mutua. El archivo debe ser el mismo en ambos servidores:
# echo -n securepass | md5sum bb77d0d3b3f239fa5db73bdf27b8d29a etcd1# vi /etc/ha.d/authkeys auth 1 1 md5 bb77d0d3b3f239fa5db73bdf27b8d29a etcd2# vi /etc/ha.d/authkeys auth 1 1 md5 bb77d0d3b3f239fa5db73bdf27b8d29a
Este archivo debe ser accesible solo para root:
etcd1# chmod 600 /etc/ha.d/authkeys etcd2# chmod 600 /etc/ha.d/authkeys
Ahora cree el archivo de configuración principal para Heartbeat en ambos servidores: para cada servidor será ligeramente diferente.
Cree /etc/ha.d/ha.cf :
etcd1
etcd1# vi /etc/ha.d/ha.cf # keepalive: how many seconds between heartbeats # keepalive 2 # # deadtime: seconds-to-declare-host-dead # deadtime 10 # # What UDP port to use for udp or ppp-udp communication? # udpport 694 bcast ens18 mcast ens18 225.0.0.1 694 1 0 ucast ens18 192.168.0.3 # What interfaces to heartbeat over? udp ens18 # # Facility to use for syslog()/logger (alternative to log/debugfile) # logfacility local0 # # Tell what machines are in the cluster # node nodename ... -- must match uname -n node etcd1_hostname node etcd2_hostname
etcd2
etcd2# vi /etc/ha.d/ha.cf # keepalive: how many seconds between heartbeats # keepalive 2 # # deadtime: seconds-to-declare-host-dead # deadtime 10 # # What UDP port to use for udp or ppp-udp communication? # udpport 694 bcast ens18 mcast ens18 225.0.0.1 694 1 0 ucast ens18 192.168.0.2 # What interfaces to heartbeat over? udp ens18 # # Facility to use for syslog()/logger (alternative to vlog/debugfile) # logfacility local0 # # Tell what machines are in the cluster # node nodename ... -- must match uname -n node etcd1_hostname node etcd2_hostname
Obtenga los parámetros de "nodo" para esta configuración ejecutando uname -n en ambos servidores Etcd. Utilice también el nombre de su tarjeta de red en lugar de ens18.
Finalmente, debe crear el archivo /etc/ha.d/haresources en estos servidores. Para ambos servidores, el archivo debe ser el mismo. En este archivo, establecemos nuestra dirección IP común y determinamos qué nodo es el maestro predeterminado:
etcd1# vi /etc/ha.d/haresources etcd1_hostname 192.168.0.1 etcd2# vi /etc/ha.d/haresources etcd1_hostname 192.168.0.1
Cuando todo esté listo, inicie los servicios Heartbeat en ambos servidores y verifique que hayamos recibido esta IP virtual declarada en el nodo etcd1:
etcd1# systemctl restart heartbeat etcd2# systemctl restart heartbeat etcd1# ip a ens18: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000 link/ether xx:xx:xx:xx:xx:xx brd ff:ff:ff:ff:ff:ff inet 192.168.0.2/24 brd 192.168.0.255 scope global ens18 valid_lft forever preferred_lft forever inet 192.168.0.1/24 brd 192.168.0.255 scope global secondary
Puede verificar que HAProxy funciona bien ejecutando nc en 192.168.0.1 6443. Debe haber agotado el tiempo de espera porque la API de Kubernetes aún no está escuchando en el lado del servidor. Pero esto significa que HAProxy y Heartbeat están configurados correctamente.
# nc -v 192.168.0.1 6443 Connection to 93.158.95.90 6443 port [tcp/*] succeeded!
4. Preparación de nodos para Kubernetes
El siguiente paso es preparar todos los nodos de Kubernetes. Debe instalar Docker con algunos paquetes adicionales, agregar el repositorio de Kubernetes e instalar los paquetes kubelet , kubeadm , kubectl desde él. Esta configuración es la misma para todos los nodos de Kubernetes (maestro, trabajadores, etc.)
La principal ventaja de Kubeadm es que no hay mucha necesidad de software adicional. Instale kubeadm en todos los hosts y úselo ; al menos generar certificados de CA.
Instale Docker en todos los nodos:
Update the apt package index # apt-get update Install packages to allow apt to use a repository over HTTPS # apt-get -y install \ apt-transport-https \ ca-certificates \ curl \ gnupg2 \ software-properties-common Add Docker's official GPG key # curl -fsSL https://download.docker.com/linux/debian/gpg | sudo apt-key add - Add docker apt repository # apt-add-repository \ "deb [arch=amd64] https://download.docker.com/linux/debian \ $(lsb_release -cs) \ stable" Install docker-ce. # apt-get update && apt-get -y install docker-ce Check docker version # docker -v Docker version 18.09.0, build 4d60db4
Después de eso, instale los paquetes de Kubernetes en todos los nodos:
kubeadm : comando para cargar el clúster.kubelet : un componente que se ejecuta en todas las computadoras del clúster y realiza acciones como iniciar hogares y contenedores.kubectl : línea de comando util para comunicarse con el clúster.- kubectl — a voluntad; A menudo lo instalo en todos los nodos para ejecutar algunos comandos de Kubernetes para la depuración.
# curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | apt-key add - Add the Google repository # cat <<EOF >/etc/apt/sources.list.d/kubernetes.list deb https://apt.kubernetes.io/ kubernetes-xenial main EOF Update and install packages # apt-get update && apt-get install -y kubelet kubeadm kubectl Hold back packages # apt-mark hold kubelet kubeadm kubectl Check kubeadm version # kubeadm version kubeadm version: &version.Info{Major:"1", Minor:"13", GitVersion:"v1.13.1", GitCommit:"eec55b9dsfdfgdfgfgdfgdfgdf365bdd920", GitTreeState:"clean", BuildDate:"2018-12-13T10:36:44Z", GoVersion:"go1.11.2", Compiler:"gc", Platform:"linux/amd64"}
Después de instalar kubeadm y otros paquetes, no olvide deshabilitar el intercambio.
# swapoff -a # sed -i '/ swap / s/^/#/' /etc/fstab
Repita la instalación en los nodos restantes. Los paquetes de software son los mismos para todos los nodos del clúster, y solo la siguiente configuración determinará los roles que recibirán más adelante.
5. Configurar HA Etcd Cluster
Entonces, una vez finalizados los preparativos, configuraremos el clúster de Kubernetes. El primer bloque será el clúster HA Etcd, que también se configura con la herramienta kubeadm.
Antes de comenzar, asegúrese de que todos los nodos etcd se comuniquen a través de los puertos 2379 y 2380. Además, debe configurar el acceso ssh entre ellos para usar scp .
Comencemos con el primer nodo etcd, y luego simplemente copie todos los certificados necesarios y los archivos de configuración a los otros servidores.
En todos los nodos etcd , debe agregar un nuevo archivo de configuración systemd para la unidad kubelet con mayor prioridad:
etcd-nodes# cat << EOF > /etc/systemd/system/kubelet.service.d/20-etcd-service-manager.conf [Service] ExecStart= ExecStart=/usr/bin/kubelet --address=127.0.0.1 --pod-manifest-path=/etc/kubernetes/manifests --allow-privileged=true Restart=always EOF etcd-nodes# systemctl daemon-reload etcd-nodes# systemctl restart kubelet
Luego, pasaremos por ssh al primer nodo de etcd ; lo usaremos para generar todas las configuraciones de kubeadm necesarias para cada nodo de etcd y luego copiarlas.
# Export all our etcd nodes IP's as variables etcd1# export HOST0=192.168.0.2 etcd1# export HOST1=192.168.0.3 etcd1# export HOST2=192.168.0.4 # Create temp directories to store files for all nodes etcd1# mkdir -p /tmp/${HOST0}/ /tmp/${HOST1}/ /tmp/${HOST2}/ etcd1# ETCDHOSTS=(${HOST0} ${HOST1} ${HOST2}) etcd1# NAMES=("infra0" "infra1" "infra2") etcd1# for i in "${!ETCDHOSTS[@]}"; do HOST=${ETCDHOSTS[$i]} NAME=${NAMES[$i]} cat << EOF > /tmp/${HOST}/kubeadmcfg.yaml apiVersion: "kubeadm.k8s.io/v1beta1" kind: ClusterConfiguration etcd: local: serverCertSANs: - "${HOST}" peerCertSANs: - "${HOST}" extraArgs: initial-cluster: ${NAMES[0]}=https://${ETCDHOSTS[0]}:2380,${NAMES[1]}=https://${ETCDHOSTS[1]}:2380,${NAMES[2]}=https://${ETCDHOSTS[2]}:2380 initial-cluster-state: new name: ${NAME} listen-peer-urls: https://${HOST}:2380 listen-client-urls: https://${HOST}:2379 advertise-client-urls: https://${HOST}:2379 initial-advertise-peer-urls: https://${HOST}:2380 EOF done
Ahora cree la autoridad de certificación principal usando kubeadm
etcd1# kubeadm init phase certs etcd-ca
Este comando creará dos archivos ca.crt y ca.key en el directorio / etc / kubernetes / pki / etcd / .
etcd1# ls /etc/kubernetes/pki/etcd/ ca.crt ca.key
Ahora generaremos certificados para todos los nodos etcd :
### Create certificates for the etcd3 node etcd1# kubeadm init phase certs etcd-server --config=/tmp/${HOST2}/kubeadmcfg.yaml etcd1# kubeadm init phase certs etcd-peer --config=/tmp/${HOST2}/kubeadmcfg.yaml etcd1# kubeadm init phase certs etcd-healthcheck-client --config=/tmp/${HOST2}/kubeadmcfg.yaml etcd1# kubeadm init phase certs apiserver-etcd-client --config=/tmp/${HOST2}/kubeadmcfg.yaml etcd1# cp -R /etc/kubernetes/pki /tmp/${HOST2}/ ### cleanup non-reusable certificates etcd1# find /etc/kubernetes/pki -not -name ca.crt -not -name ca.key -type f -delete ### Create certificates for the etcd2 node etcd1# kubeadm init phase certs etcd-server --config=/tmp/${HOST1}/kubeadmcfg.yaml etcd1# kubeadm init phase certs etcd-peer --config=/tmp/${HOST1}/kubeadmcfg.yaml etcd1# kubeadm init phase certs etcd-healthcheck-client --config=/tmp/${HOST1}/kubeadmcfg.yaml etcd1# kubeadm init phase certs apiserver-etcd-client --config=/tmp/${HOST1}/kubeadmcfg.yaml etcd1# cp -R /etc/kubernetes/pki /tmp/${HOST1}/ ### cleanup non-reusable certificates again etcd1# find /etc/kubernetes/pki -not -name ca.crt -not -name ca.key -type f -delete ### Create certificates for the this local node etcd1# kubeadm init phase certs etcd-server --config=/tmp/${HOST0}/kubeadmcfg.yaml etcd1 #kubeadm init phase certs etcd-peer --config=/tmp/${HOST0}/kubeadmcfg.yaml etcd1# kubeadm init phase certs etcd-healthcheck-client --config=/tmp/${HOST0}/kubeadmcfg.yaml etcd1# kubeadm init phase certs apiserver-etcd-client --config=/tmp/${HOST0}/kubeadmcfg.yaml # No need to move the certs because they are for this node # clean up certs that should not be copied off this host etcd1# find /tmp/${HOST2} -name ca.key -type f -delete etcd1# find /tmp/${HOST1} -name ca.key -type f -delete
Luego copie los certificados y configuraciones de kubeadm a los nodos etcd2 y etcd3 .
Primero genere un par de claves ssh en etcd1 y agregue la parte pública a los nodos etcd2 y 3 . En este ejemplo, todos los comandos se ejecutan en nombre de un usuario que posee todos los derechos en el sistema.
etcd1# scp -r /tmp/${HOST1}/* ${HOST1}: etcd1# scp -r /tmp/${HOST2}/* ${HOST2}: ### login to the etcd2 or run this command remotely by ssh etcd2# cd /root etcd2# mv pki /etc/kubernetes/ ### login to the etcd3 or run this command remotely by ssh etcd3# cd /root etcd3# mv pki /etc/kubernetes/
Antes de iniciar el clúster etcd, asegúrese de que los archivos existan en todos los nodos:
Lista de archivos requeridos en etcd1 :
/tmp/192.168.0.2 └── kubeadmcfg.yaml --- /etc/kubernetes/pki ├── apiserver-etcd-client.crt ├── apiserver-etcd-client.key └── etcd ├── ca.crt ├── ca.key ├── healthcheck-client.crt ├── healthcheck-client.key ├── peer.crt ├── peer.key ├── server.crt └── server.key
Para el nodo etcd2, esto es:
/root └── kubeadmcfg.yaml --- /etc/kubernetes/pki ├── apiserver-etcd-client.crt ├── apiserver-etcd-client.key └── etcd ├── ca.crt ├── healthcheck-client.crt ├── healthcheck-client.key ├── peer.crt ├── peer.key ├── server.crt └── server.key
Y el último nodo es etcd3 :
/root └── kubeadmcfg.yaml --- /etc/kubernetes/pki ├── apiserver-etcd-client.crt ├── apiserver-etcd-client.key └── etcd ├── ca.crt ├── healthcheck-client.crt ├── healthcheck-client.key ├── peer.crt ├── peer.key ├── server.crt └── server.key
Cuando todos los certificados y configuraciones están en su lugar, creamos manifiestos. En cada nodo, ejecute el comando kubeadm para generar un manifiesto estático para el clúster etcd :
etcd1# kubeadm init phase etcd local --config=/tmp/192.168.0.2/kubeadmcfg.yaml etcd1# kubeadm init phase etcd local --config=/root/kubeadmcfg.yaml etcd1# kubeadm init phase etcd local --config=/root/kubeadmcfg.yaml
Ahora el clúster, etcd , en teoría, está configurado y en buen estado. Verifique ejecutando el siguiente comando en el nodo etcd1:
etcd1# docker run --rm -it \ --net host \ -v /etc/kubernetes:/etc/kubernetes quay.io/coreos/etcd:v3.2.24 etcdctl \ --cert-file /etc/kubernetes/pki/etcd/peer.crt \ --key-file /etc/kubernetes/pki/etcd/peer.key \ --ca-file /etc/kubernetes/pki/etcd/ca.crt \ --endpoints https://192.168.0.2:2379 cluster-health ### status output member 37245675bd09ddf3 is healthy: got healthy result from https://192.168.0.3:2379 member 532d748291f0be51 is healthy: got healthy result from https://192.168.0.4:2379 member 59c53f494c20e8eb is healthy: got healthy result from https://192.168.0.2:2379 cluster is healthy
El clúster etcd ha aumentado, así que sigue adelante.
6. Configuración de nodos maestros y de trabajo
Configure los nodos maestros de nuestro clúster: copie estos archivos del primer nodo etcd al primer nodo maestro:
etcd1# scp /etc/kubernetes/pki/etcd/ca.crt 192.168.0.5: etcd1# scp /etc/kubernetes/pki/apiserver-etcd-client.crt 192.168.0.5: etcd1# scp /etc/kubernetes/pki/apiserver-etcd-client.key 192.168.0.5:
Luego vaya ssh al nodo maestro master1 y cree el archivo kubeadm-config.yaml con el siguiente contenido:
master1# cd /root && vi kubeadm-config.yaml apiVersion: kubeadm.k8s.io/v1beta1 kind: ClusterConfiguration kubernetesVersion: stable apiServer: certSANs: - "192.168.0.1" controlPlaneEndpoint: "192.168.0.1:6443" etcd: external: endpoints: - https://192.168.0.2:2379 - https://192.168.0.3:2379 - https://192.168.0.4:2379 caFile: /etc/kubernetes/pki/etcd/ca.crt certFile: /etc/kubernetes/pki/apiserver-etcd-client.crt keyFile: /etc/kubernetes/pki/apiserver-etcd-client.key
Mueva los certificados y la clave previamente copiados al directorio apropiado en el nodo master1, como en la descripción de la configuración.
master1# mkdir -p /etc/kubernetes/pki/etcd/ master1# cp /root/ca.crt /etc/kubernetes/pki/etcd/ master1# cp /root/apiserver-etcd-client.crt /etc/kubernetes/pki/ master1# cp /root/apiserver-etcd-client.key /etc/kubernetes/pki/
Para crear el primer nodo maestro, haga:
master1# kubeadm init --config kubeadm-config.yaml
Si todos los pasos anteriores se completan correctamente, verá lo siguiente:
You can now join any number of machines by running the following on each node as root: kubeadm join 192.168.0.1:6443 --token aasuvd.kw8m18m5fy2ot387 --discovery-token-ca-cert-hash sha256:dcbaeed8d1478291add0294553b6b90b453780e546d06162c71d515b494177a6
Copie esta salida de inicialización de kubeadm en cualquier archivo de texto, usaremos este token en el futuro cuando adjuntemos el segundo maestro y los nodos de trabajo a nuestro clúster.
Ya he dicho que el clúster de Kubernetes usará algún tipo de red superpuesta para hogares y otros servicios, por lo que en este punto debe instalar algún tipo de complemento CNI. Recomiendo el complemento Weave CNI . La experiencia ha demostrado que es más útil y menos problemático, pero puede elegir otro, por ejemplo, Calico.
Instalación del complemento de red Weave en el primer nodo maestro:
master1# kubectl --kubeconfig /etc/kubernetes/admin.conf apply -f "https://cloud.weave.works/k8s/net?k8s-version=$(kubectl version | base64 | tr -d '\n')" The connection to the server localhost:8080 was refused - did you specify the right host or port? serviceaccount/weave-net created clusterrole.rbac.authorization.k8s.io/weave-net created clusterrolebinding.rbac.authorization.k8s.io/weave-net created role.rbac.authorization.k8s.io/weave-net created rolebinding.rbac.authorization.k8s.io/weave-net created daemonset.extensions/weave-net created
Espere un momento y luego ingrese el siguiente comando para verificar que se inicien los hogares de componentes:
master1# kubectl --kubeconfig /etc/kubernetes/admin.conf get pod -n kube-system -w NAME READY STATUS RESTARTS AGE coredns-86c58d9df4-d7qfw 1/1 Running 0 6m25s coredns-86c58d9df4-xj98p 1/1 Running 0 6m25s kube-apiserver-master1 1/1 Running 0 5m22s kube-controller-manager-master1 1/1 Running 0 5m41s kube-proxy-8ncqw 1/1 Running 0 6m25s kube-scheduler-master1 1/1 Running 0 5m25s weave-net-lvwrp 2/2 Running 0 78s
- Se recomienda adjuntar nuevos nodos del plano de control solo después de la inicialización del primer nodo.
Para verificar el estado del clúster, haga lo siguiente:
master1# kubectl --kubeconfig /etc/kubernetes/admin.conf get nodes NAME STATUS ROLES AGE VERSION master1 Ready master 11m v1.13.1
Genial El primer nodo maestro se levantó. Ahora está listo y terminaremos de crear el clúster de Kubernetes: agregaremos un segundo nodo maestro y nodos de trabajo.
Para agregar un segundo nodo maestro, cree una clave ssh en master1 y agregue la parte pública a master2 . Realice un inicio de sesión de prueba y luego copie algunos archivos del primer nodo maestro al segundo:
master1# scp /etc/kubernetes/pki/ca.crt 192.168.0.6: master1# scp /etc/kubernetes/pki/ca.key 192.168.0.6: master1# scp /etc/kubernetes/pki/sa.key 192.168.0.6: master1# scp /etc/kubernetes/pki/sa.pub 192.168.0.6: master1# scp /etc/kubernetes/pki/front-proxy-ca.crt @192.168.0.6: master1# scp /etc/kubernetes/pki/front-proxy-ca.key @192.168.0.6: master1# scp /etc/kubernetes/pki/apiserver-etcd-client.crt @192.168.0.6: master1# scp /etc/kubernetes/pki/apiserver-etcd-client.key @192.168.0.6: master1# scp /etc/kubernetes/pki/etcd/ca.crt 192.168.0.6:etcd-ca.crt master1# scp /etc/kubernetes/admin.conf 192.168.0.6: ### Check that files was copied well master2# ls /root admin.conf ca.crt ca.key etcd-ca.crt front-proxy-ca.crt front-proxy-ca.key sa.key sa.pub
En el segundo nodo maestro, mueva los certificados y claves previamente copiados a los directorios apropiados:
master2# mkdir -p /etc/kubernetes/pki/etcd mv /root/ca.crt /etc/kubernetes/pki/ mv /root/ca.key /etc/kubernetes/pki/ mv /root/sa.pub /etc/kubernetes/pki/ mv /root/sa.key /etc/kubernetes/pki/ mv /root/apiserver-etcd-client.crt /etc/kubernetes/pki/ mv /root/apiserver-etcd-client.key /etc/kubernetes/pki/ mv /root/front-proxy-ca.crt /etc/kubernetes/pki/ mv /root/front-proxy-ca.key /etc/kubernetes/pki/ mv /root/etcd-ca.crt /etc/kubernetes/pki/etcd/ca.crt mv /root/admin.conf /etc/kubernetes/admin.conf
Conecte el segundo nodo maestro al clúster. Para hacer esto, necesita la salida del comando de conexión, que kubeadm init nos pasó previamente en el primer nodo.
Ejecute el nodo maestro master2 :
master2# kubeadm join 192.168.0.1:6443 --token aasuvd.kw8m18m5fy2ot387 --discovery-token-ca-cert-hash sha256:dcbaeed8d1478291add0294553b6b90b453780e546d06162c71d515b494177a6 --experimental-control-plane
--experimental-control-plane agregar la --experimental-control-plane . Automatiza la conexión de datos maestros a un clúster. Sin este indicador, simplemente se agregará el nodo de trabajo habitual.
Espere un poco hasta que el nodo se una al clúster y verifique el nuevo estado del clúster:
master1# kubectl --kubeconfig /etc/kubernetes/admin.conf get nodes NAME STATUS ROLES AGE VERSION master1 Ready master 32m v1.13.1 master2 Ready master 46s v1.13.1
También asegúrese de que todos los pods de todos los nodos maestros se inicien normalmente:
master1# kubectl — kubeconfig /etc/kubernetes/admin.conf get pod -n kube-system -w NAME READY STATUS RESTARTS AGE coredns-86c58d9df4-d7qfw 1/1 Running 0 46m coredns-86c58d9df4-xj98p 1/1 Running 0 46m kube-apiserver-master1 1/1 Running 0 45m kube-apiserver-master2 1/1 Running 0 15m kube-controller-manager-master1 1/1 Running 0 45m kube-controller-manager-master2 1/1 Running 0 15m kube-proxy-8ncqw 1/1 Running 0 46m kube-proxy-px5dt 1/1 Running 0 15m kube-scheduler-master1 1/1 Running 0 45m kube-scheduler-master2 1/1 Running 0 15m weave-net-ksvxz 2/2 Running 1 15m weave-net-lvwrp 2/2 Running 0 41m
Genial Ya casi hemos terminado con la configuración del clúster de Kubernetes. Y lo último que debe hacer es agregar los tres nodos de trabajo que preparamos anteriormente.
Ingrese los nodos de trabajo y ejecute el comando de unión kubeadm sin la --experimental-control-plane .
worker1-3# kubeadm join 192.168.0.1:6443 --token aasuvd.kw8m18m5fy2ot387 --discovery-token-ca-cert-hash sha256:dcbaeed8d1478291add0294553b6b90b453780e546d06162c71d515b494177a6
Verifique nuevamente el estado del clúster:
master1# kubectl --kubeconfig /etc/kubernetes/admin.conf get nodes NAME STATUS ROLES AGE VERSION master1 Ready master 1h30m v1.13.1 master2 Ready master 1h59m v1.13.1 worker1 Ready <none> 1h8m v1.13.1 worker2 Ready <none> 1h8m v1.13.1 worker3 Ready <none> 1h7m v1.13.1
Como puede ver, tenemos un clúster Kubernetes HA totalmente configurado con dos nodos maestros y tres nodos de trabajo. Está construido sobre la base del clúster HA etcd con un equilibrador de carga a prueba de fallas frente a los nodos maestros. Suena bastante bien para mi.
7. Configuración de la gestión remota del clúster
Otra acción que queda por considerar en esta primera parte del artículo es configurar la utilidad kubectl remota para administrar el clúster. Anteriormente, ejecutamos todos los comandos desde el nodo maestro master1 , pero esto solo es adecuado por primera vez, al configurar el clúster. Sería bueno configurar un nodo de control externo. Puede usar una computadora portátil u otro servidor para esto.
Inicie sesión en este servidor y ejecute:
Add the Google repository key control# curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | apt-key add - Add the Google repository control# cat <<EOF >/etc/apt/sources.list.d/kubernetes.list deb https://apt.kubernetes.io/ kubernetes-xenial main EOF Update and install kubectl control# apt-get update && apt-get install -y kubectl In your user home dir create control# mkdir ~/.kube Take the Kubernetes admin.conf from the master1 node control# scp 192.168.0.5:/etc/kubernetes/admin.conf ~/.kube/config Check that we can send commands to our cluster control# kubectl get nodes NAME STATUS ROLES AGE VERSION master1 Ready master 6h58m v1.13.1 master2 Ready master 6h27m v1.13.1 worker1 Ready <none> 5h36m v1.13.1 worker2 Ready <none> 5h36m v1.13.1 worker3 Ready <none> 5h36m v1.13.1
Ok, ahora ejecutemos una prueba en nuestro clúster y verifiquemos cómo funciona.
control# kubectl create deployment nginx --image=nginx deployment.apps/nginx created control# kubectl get pods NAME READY STATUS RESTARTS AGE nginx-5c7588df-6pvgr 1/1 Running 0 52s
Felicidades Acabas de desplegar Kubernetes. Y eso significa que su nuevo clúster HA está listo. De hecho, el proceso de configurar un clúster de Kubernetes usando kubeadm es bastante simple y rápido.
En la siguiente parte del artículo, agregaremos almacenamiento interno configurando GlusterFS en todos los nodos de trabajo, configurando un equilibrador de carga interno para nuestro clúster Kubernetes y también ejecutando ciertas pruebas de estrés, desconectando algunos nodos y verificando la estabilidad del clúster.
Epílogo
Sí, trabajando en este ejemplo, encontrará una serie de problemas. No debe preocuparse: para deshacer los cambios y devolver los nodos a su estado original, simplemente ejecute kubeadm reset : los cambios que realizó anteriormente Kubeadm se restablecerán y podrá volver a configurarlos. Además, no olvide verificar el estado de los contenedores Docker en los nodos del clúster; asegúrese de que todos se inicien y funcionen sin errores. Para obtener más información sobre los contenedores dañados, use el comando docker logs containerid .
Eso es todo por hoy. Buena suerte