Hola a todos! Le presento una traducción del artículo de Analytics Vidhya con una descripción general de los eventos de AI / ML en las tendencias 2018 y 2019. El material es bastante grande, por lo que se divide en 2 partes. Espero que el artículo interese no solo a especialistas especializados, sino también a aquellos interesados en el tema de la IA. Que tengas una buena lectura!
Introduccion
Los últimos años para los entusiastas de la IA y los profesionales del aprendizaje automático han pasado en busca de un sueño. Estas tecnologías han dejado de ser nicho, se han convertido en la corriente principal y ya están afectando la vida de millones de personas en este momento. Los ministerios de IA fueron creados en diferentes países [
más detalles aquí - aprox. per.] y los presupuestos se asignan para mantenerse al día con esta carrera.
Lo mismo es cierto para los profesionales de la ciencia de datos. Hace un par de años, podría sentirse cómodo conociendo un par de herramientas y trucos, pero esta vez ha pasado. La cantidad de eventos recientes en ciencia de datos y la cantidad de conocimiento que se requiere para mantenerse al día con los tiempos en esta área son sorprendentes.
Decidí dar un paso atrás y observar los desarrollos en algunas áreas clave en el campo de la inteligencia artificial desde el punto de vista de los expertos en ciencia de datos. ¿Qué brotes han ocurrido? ¿Qué pasó en 2018 y qué esperar en 2019? ¡Lea este artículo para obtener respuestas!
PD Como en cualquier pronóstico, a continuación están mis conclusiones personales basadas en intentos de combinar fragmentos individuales en la imagen completa. Si su punto de vista es diferente al mío, me complacerá saber su opinión sobre qué más puede cambiar en ciencia de datos en 2019.
Las áreas que cubriremos en este artículo son:
- Procesamiento del lenguaje natural (PNL)
- Visión por computadora
- Herramientas y bibliotecas
- Aprendizaje de refuerzo
- Problemas de ética en la IA
Procesamiento de lenguaje natural (PNL)
Forzar a las máquinas a analizar palabras y oraciones siempre parecía un sueño imposible. Hay muchos matices y características en los idiomas que a veces son difíciles de entender incluso para las personas, pero 2018 fue un verdadero punto de inflexión para la PNL.
Vimos un gran avance tras otro: ULMFiT, ELMO, OpenAl Transformer, Google BERT, y esta no es una lista completa. La aplicación exitosa del aprendizaje de transferencia (el arte de aplicar modelos pre-entrenados a los datos) ha abierto la puerta a la PNL en una variedad de tareas.
Aprendizaje de transferencia: le permite adaptar un modelo / sistema previamente capacitado a su tarea específica utilizando una cantidad relativamente pequeña de datos.
Veamos algunos de estos desarrollos clave con más detalle.
ULMFiT
Desarrollado por Sebastian Ruder y Jeremy Howard (fast.ai), ULMFiT fue el primer marco para recibir el aprendizaje de transferencia este año. Para los no iniciados, el acrónimo ULMFiT significa "Ajuste del modelo de lenguaje universal". Jeremy y Sebastian con razón agregaron la palabra "universal" a ULMFiT: ¡este marco se puede aplicar a casi cualquier tarea de PNL!
¡Lo mejor de ULMFiT es que no necesita entrenar modelos desde cero! Los investigadores ya han hecho lo más difícil para usted: tomar y aplicar en sus proyectos. ULMFiT superó a otros métodos en seis tareas de clasificación de texto.
Puedes
leer el tutorial de Pratek Joshi [Pateek Joshi - aprox. trans.] sobre cómo comenzar a usar ULMFiT para cualquier tarea de clasificación de texto.
ELMo
¿Adivina qué significa la abreviatura ELMo? Acrónimo de incrustaciones de modelos de idiomas [archivos adjuntos de modelos de idiomas - aprox. trans.]. Y ELMo llamó la atención de la comunidad de ML justo después del lanzamiento.
ELMo utiliza modelos de lenguaje para recibir archivos adjuntos para cada palabra, y también tiene en cuenta el contexto en el que la palabra se ajusta a una oración o párrafo. El contexto es un aspecto crítico de la PNL, en el que la mayoría de los desarrolladores han fallado previamente. ELMo utiliza LSTM bidireccionales para crear archivos adjuntos.
La memoria a largo plazo (LSTM) es un tipo de arquitectura de redes neuronales recurrentes propuesta en 1997 por Sepp Hochreiter y Jürgen Schmidhuber. Como la mayoría de las redes neuronales recurrentes, una red LSTM es universal en el sentido de que, con un número suficiente de elementos de red, puede realizar cualquier cálculo que sea capaz de hacer una computadora normal, lo que requiere una matriz de peso adecuada que puede considerarse como un programa. A diferencia de las redes neuronales recurrentes tradicionales, la red LSTM es muy adecuada para la capacitación sobre los problemas de clasificación, procesamiento y predicción de series de tiempo en casos donde los eventos importantes están separados por retrasos con duración y límites indefinidos.
- fuente. Wikipedia
Al igual que ULMFiT, ELMo mejora significativamente la productividad al resolver una gran cantidad de tareas de PNL, como analizar el estado de ánimo del texto o responder preguntas.
BERT de Google
Muchos expertos señalan que el lanzamiento de BERT marcó el comienzo de una nueva era en la PNL. Después de ULMFiT y ELMo, BERT tomó la delantera, demostrando un alto rendimiento. Como dice el anuncio original: "BERT es conceptualmente simple y empíricamente poderoso".
¡BERT ha mostrado resultados sobresalientes en 11 tareas de PNL! Vea los resultados en las pruebas SQuAD:
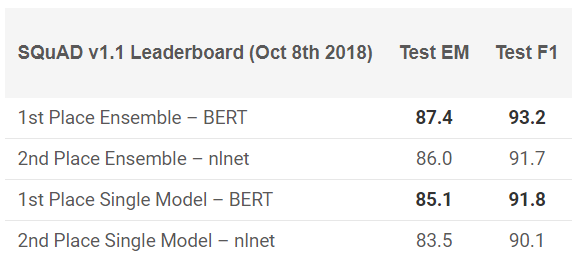
¿Quieres probarlo? Puede usar la reimplementación en PyTorch o el código TensorFlow de Google e intentar repetir el resultado en su máquina.
Facebook PyText
¿Cómo podría Facebook mantenerse alejado de esta carrera? La compañía ofrece su propio marco de PNL de código abierto llamado PyText. Según un estudio publicado por Facebook, PyText aumentó la precisión de los modelos de conversación en un 10% y redujo el tiempo de entrenamiento.
PyText está detrás de varios productos propios de Facebook, como Messenger. Por lo tanto, trabajar con él agregará un buen punto a su cartera y un conocimiento invaluable que sin duda obtendrá.
Puede probarlo usted mismo,
descargue el código de GitHub .
Google duplex
Es difícil creer que no haya oído hablar de Google Duplex. Aquí hay una demostración que durante mucho tiempo apareció en los titulares:
Dado que este es un producto de Google, hay pocas posibilidades de que tarde o temprano el código se publique para todos. Por supuesto, esta demostración plantea muchas preguntas: desde cuestiones éticas hasta cuestiones de privacidad, pero hablaremos de esto más adelante. Por ahora, solo disfruta de lo lejos que hemos llegado con ML en los últimos años.
Tendencias de PNL 2019
¿Quién mejor que el propio Sebastian Ruder puede dar una idea de hacia dónde se dirige la PNL en 2019? Aquí están sus hallazgos:
- El uso de modelos de inversión en idiomas previamente capacitados se generalizará; Los modelos avanzados sin soporte serán muy raros.
- Aparecerán vistas pre-entrenadas que pueden codificar información especializada que complementa los archivos adjuntos del modelo de lenguaje. Podremos agrupar diferentes tipos de presentaciones pre-entrenadas dependiendo de los requisitos de la tarea.
- Aparecerá más trabajo en el campo de las aplicaciones multilingües y los modelos multilingües. En particular, confiando en la inclusión de palabras entre idiomas, veremos el surgimiento de profundas representaciones entre idiomas pre-entrenadas.
Visión por computadora

Hoy en día, la visión por computadora es el área más popular en el campo del aprendizaje profundo. Parece que los primeros frutos de la tecnología ya se han obtenido y estamos en la etapa de desarrollo activo. Independientemente de si esta imagen o video, vemos la aparición de muchos marcos y bibliotecas que resuelven fácilmente los problemas de la visión por computadora.
Aquí está mi lista de las mejores soluciones que podrían verse este año.
BigGANs Out
Ian Goodfellow diseñó las GAN en 2014, y el concepto generó una amplia variedad de aplicaciones. Año tras año, observamos cómo se finalizó el concepto original para su uso en casos reales. Pero una cosa permaneció sin cambios hasta este año: las imágenes generadas por computadora eran demasiado fáciles de distinguir. Siempre aparecía una cierta inconsistencia en el marco, lo que hacía la diferencia muy obvia.
En los últimos meses, han aparecido cambios en esta dirección y, con la
creación de BigGAN , estos problemas pueden resolverse de una vez por todas. Mira las imágenes generadas por este método:

Sin un microscopio, es difícil decir qué está mal con estas imágenes. Por supuesto, todos decidirán por sí mismos, pero no hay duda de que la GAN cambia la forma en que percibimos las imágenes digitales (y el video).
Como referencia: estos modelos fueron entrenados primero en el conjunto de datos ImageNet, y luego en el JFT-300M para demostrar que estos modelos se transfieren bien de un conjunto de datos a otro. Aquí hay un
enlace a una página de la lista de correo de GAN que explica cómo visualizar y comprender la GAN.
Modelo Fast.ai entrenado en ImageNet en 18 minutos
Esta es una implementación realmente genial. Existe una creencia generalizada de que, para realizar tareas de aprendizaje profundo, necesitará terabytes de datos y grandes recursos informáticos. Lo mismo es cierto para entrenar el modelo desde cero en los datos de ImageNet. La mayoría de nosotros pensamos de la misma manera antes de que algunas personas en ayuno no pudieran demostrar lo contrario a todos.
Su modelo dio un 93% de precisión con unos impresionantes 18 minutos. El hardware que utilizaron,
descrito en detalle
en su blog , consistía en 16 instancias públicas de nube de AWS, cada una con 8 GPU NVIDIA V100. Crearon un algoritmo utilizando las bibliotecas fast.ai y PyTorch.
¡El costo total de ensamblaje fue de solo $ 40! Jeremy describió sus
enfoques y métodos con más detalle
aquí . Esta es una victoria común!
vid2vid de NVIDIA
En los últimos 5 años, el procesamiento de imágenes ha avanzado mucho, pero ¿qué pasa con el video? Los métodos para convertir de un marco estático a uno dinámico resultaron ser un poco más complicados de lo esperado. ¿Puedes tomar una secuencia de cuadros de un video y predecir lo que sucederá en el próximo cuadro? Tales estudios se han realizado antes, pero las publicaciones fueron vagas en el mejor de los casos.

NVIDIA decidió hacer pública su decisión a principios de este año [2018 - aprox. per.], que fue evaluado positivamente por la sociedad. El propósito de vid2vid es obtener una función de visualización de un video de entrada dado para crear un video de salida que transmita el contenido del video de entrada con una precisión increíble.
Puede probar su implementación en PyTorch, llévelo
a GitHub aquí .
Tendencias de visión artificial para 2019
Como mencioné anteriormente, en 2019 es más probable que veamos el desarrollo de las tendencias de 2018, en lugar de nuevos avances: autos autónomos, algoritmos de reconocimiento facial, realidad virtual y más. ¿Puede estar en desacuerdo conmigo si tiene un punto de vista diferente o adiciones, compártelo con nosotros, qué más podemos esperar en 2019?
El tema de los drones, a la espera de la aprobación de los políticos y el gobierno, puede finalmente obtener luz verde en los Estados Unidos (India está muy por detrás en este asunto). Personalmente, me gustaría realizar más investigaciones en escenarios del mundo real. Conferencias como
CVPR e
ICML ofrecen una buena cobertura de los últimos logros en esta área, pero no está muy claro qué tan cerca están los proyectos de la realidad.
"Respuesta a preguntas visuales" y "sistemas de diálogo visual" finalmente pueden salir con un esperado debut. Estos sistemas carecen de la capacidad de generalizar, pero se espera que pronto veamos un enfoque multimodal integrado.
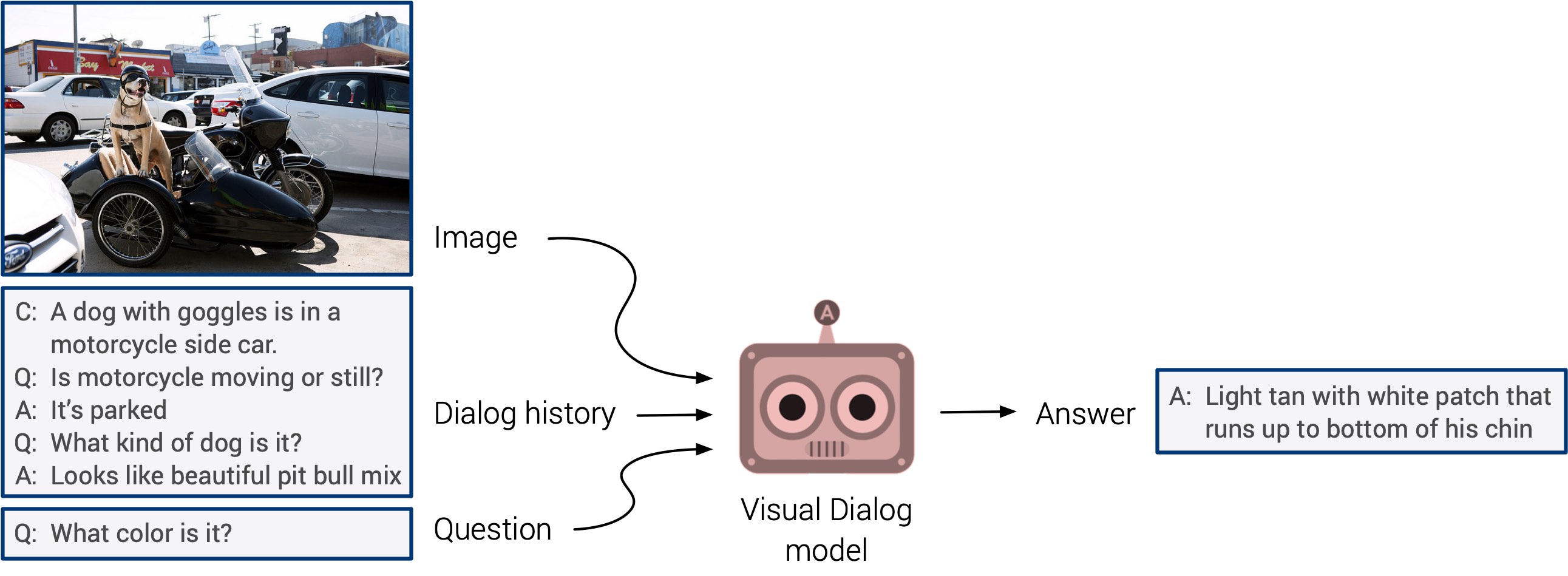
El auto entrenamiento se destacó este año. Apuesto a que el próximo año encontrará aplicación en un número mucho mayor de estudios. Esta es una dirección realmente genial: los signos se determinan directamente a partir de los datos de entrada, en lugar de perder el tiempo marcando manualmente las imágenes. ¡Mantengamos nuestros dedos cruzados!