Hola% habrauser%!
Hoy quiero contarles sobre un excelente, en mi opinión, el marco de microservicios de
Moleculer .

Inicialmente, este marco se escribió en Node.js, pero luego apareció en puertos en otros lenguajes como Java, Go, Python y .NET y, muy probablemente, otras implementaciones
aparecerán en un futuro cercano. Lo hemos estado usando en producción en varios productos durante aproximadamente un año y es difícil describir con palabras lo bendecido que nos pareció después de usar Seneca y nuestras bicicletas. Tenemos todo lo que necesitamos fuera de la caja: recopilar métricas, almacenamiento en caché, equilibrio, tolerancia a fallas, seleccionar transportes, validación de parámetros, registro, declaraciones de métodos concisos, varias formas de interacción entre servicios, mixins y mucho más. Y ahora en orden.
Introduccion
El marco, de hecho, consta de tres componentes (de hecho, no, pero aprenderá más sobre esto a continuación).
Transportador
Responsable de descubrir servicios y comunicación entre ellos. Esta es una interfaz que puede implementar usted mismo si lo desea, o puede usar implementaciones listas para usar que son parte del marco en sí. Hay 7 transportes disponibles de la caja: TCP, Redis, AMQP, MQTT, NATS, NATS Streaming, Kafka.
Aquí puedes ver más. Usamos el transporte Redis, pero planeamos cambiar a TCP con su salida del estado experimental.
En la práctica, al escribir código, no interactuamos con este componente. Solo necesitas saber qué es él. El transporte utilizado se especifica en la configuración. Por lo tanto, para cambiar de un transporte a otro, simplemente cambie la configuración. Eso es todo. Algo como esto:
Los datos, por defecto, vienen en formato JSON. Pero puede usar cualquier cosa: Avro, MsgPack, Notepack, ProtoBuf, Thrift, etc.
Servicio
La clase de la que heredamos al escribir nuestros microservicios.
Aquí está el servicio más simple sin métodos, que, sin embargo, será detectado por otros servicios:
Corredor de servicios
El núcleo del marco.

Exagerando, podemos decir que esta es una capa entre el transporte y el servicio. Cuando un servicio quiere interactuar con otro servicio de alguna manera, lo hace a través de un intermediario (se darán ejemplos a continuación). El corredor se dedica al equilibrio de carga (admite varias estrategias, incluidas las personalizadas, por defecto, round-robin), teniendo en cuenta los servicios en vivo, los métodos disponibles en estos servicios, etc. Para esto, ServiceBroker usa otro componente bajo el capó: el Registro, pero no me detendré en él, no lo necesitaremos para conocerlo.
Tener un corredor nos da una cosa extremadamente conveniente. Ahora intentaré explicarlo, pero tendré que apartarme un poco. En el contexto del marco existe un nodo. En términos simples, un nodo es un proceso en el sistema operativo (es decir, lo que sucede cuando ingresamos "node index.js" en la consola, por ejemplo). Cada nodo es un ServiceBroker con un conjunto de uno o más microservicios. Sí, escuchaste bien. Podemos construir nuestra pila de servicios como lo desee nuestro corazón. ¿Por qué es esto conveniente? Para el desarrollo, comenzamos un nodo en el que todos los microservicios se lanzan a la vez (1 cada uno), solo un proceso en el sistema con la capacidad de conectar muy fácilmente la recarga en caliente, por ejemplo. En producción: un nodo separado para cada instancia del servicio. Bueno, o una combinación, cuando parte de los servicios en un nodo, parte en otro, etc. (aunque no sé por qué hacer esto, solo para entender que tú también puedes hacerlo).
Así es como se ve nuestro index.js const { resolve } = require('path'); const { ServiceBroker } = require('moleculer'); const config = require('./moleculer.config.js'); const { SERVICES, NODE_ENV, } = process.env; const broker = new ServiceBroker(config); broker.loadServices( resolve(__dirname, 'services'), SERVICES ? `*/@(${SERVICES.split(',').map(i => i.trim()).join('|')}).service.js` : '*/*.service.js', ); broker.start().then(() => { if (NODE_ENV === 'development') { broker.repl(); } });
En ausencia de una variable de entorno, todos los servicios del directorio se cargan, de lo contrario, por máscara. Por cierto, broker.repl () es otra característica conveniente del marco. Al comenzar en modo de desarrollo, allí mismo, en la consola, tenemos una interfaz para llamar a los métodos (lo que haría, por ejemplo, a través del cartero en su microservicio que se comunica a través de http), solo que aquí es mucho más conveniente: la interfaz está en la misma consola donde empezaron npm.
Interacción entre servicios
Se lleva a cabo de tres maneras:
llamar
Más comúnmente utilizado. Hizo una solicitud, recibió una respuesta (o error).
Como se mencionó anteriormente, las llamadas se equilibran automáticamente. Simplemente aumentamos el número requerido de instancias de servicio, y el marco en sí hará el equilibrio.

emitir
Se usa cuando solo queremos notificar a otros servicios sobre un evento, pero no necesitamos el resultado.
Otros servicios pueden suscribirse a este evento y responder en consecuencia. Opcionalmente, el tercer argumento, puede establecer explícitamente los servicios que están disponibles para recibir este evento.
El punto importante es que el evento recibirá solo una instancia de cada tipo de servicio, es decir, Si tenemos 10 servicios de "correo" y 5 de "suscripción" que están suscritos a este evento, de hecho solo lo recibirán 2 copias, un "correo" y una "suscripción". Esquemáticamente se ve así:
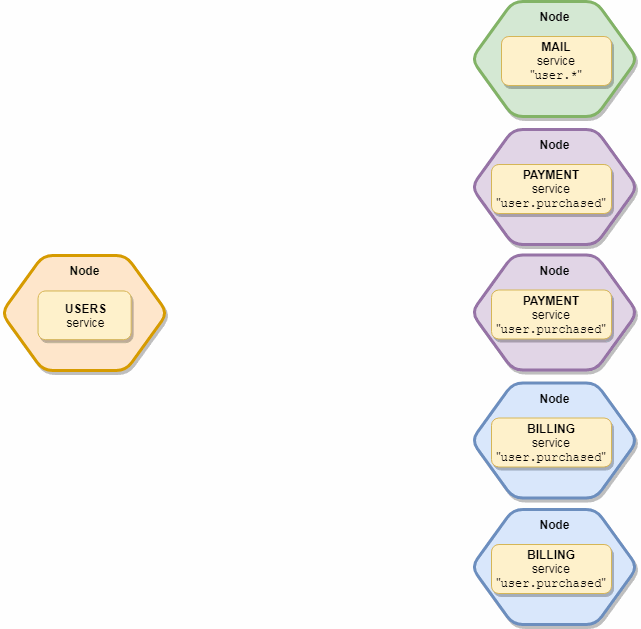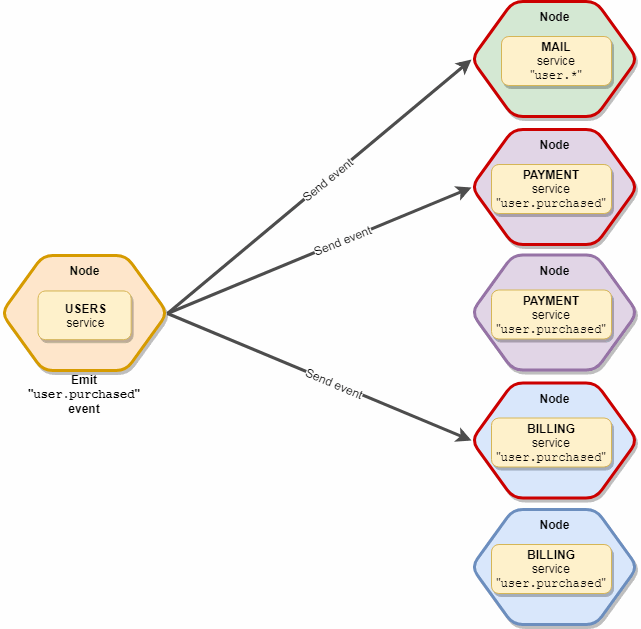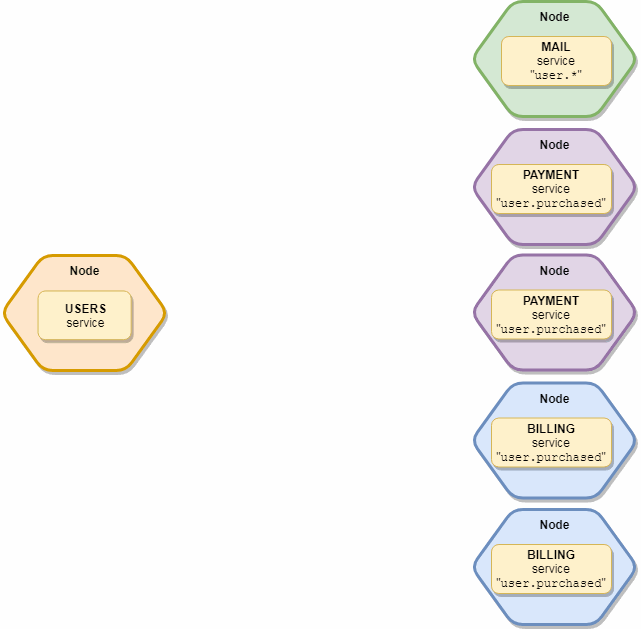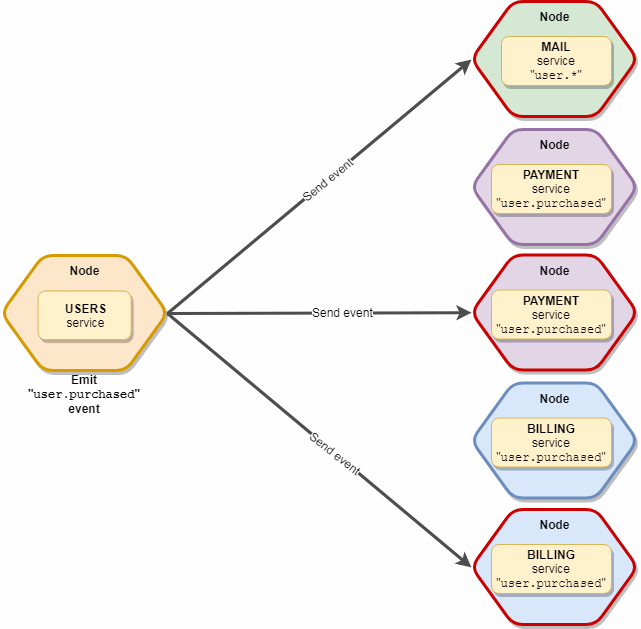
transmitir
Lo mismo que emitir, pero sin restricciones. Los 10 servicios de correo y 5 de suscripción captarán este evento.
Validación de parámetros
Por defecto,
el validador más rápido se utiliza para validar los parámetros, parece ser muy rápido. Pero nada impide usar otro, por ejemplo, el mismo joi, si necesita una validación más avanzada.
Cuando escribimos un servicio, heredamos de la clase base del Servicio, declaramos métodos con lógica de negocios, pero estos métodos son "privados", no se pueden llamar desde el exterior (desde otro servicio) hasta que queramos explícitamente, declarándolos en sección de acciones especiales durante la inicialización del servicio (los métodos públicos de servicios en el contexto del marco se denominan acciones).
Ejemplo de una declaración de método con validación. module.exports = class JobService extends Service { constructor(broker) { super(broker); this.parseServiceSchema({ name: 'job', actions: { update: { params: { id: { type: 'number', convert: true }, name: { type: 'string', empty: false, optional: true }, data: { type: 'object', optional: true }, }, async handler(ctx) { return this.update(ctx.params); }, }, }, }); } async update({ id, name, data }) {
Mixins
Se usa, por ejemplo, para inicializar una conexión de base de datos. Evite la duplicación de código de un servicio a otro.
Ejemplo de mezcla para inicializar una conexión a Redis const Redis = require('ioredis'); module.exports = ({ key = 'redis', options } = {}) => ({ settings: { [key]: options, }, created() { this[key] = new Redis(this.settings[key]); }, async started() { await this[key].connect(); }, stopped() { this[key].disconnect(); }, });
Usando mixin en el servicio const { Service, Errors } = require('moleculer'); const redis = require('../../mixins/redis'); const server = require('../../mixins/server'); const router = require('./router'); const { REDIS_HOST, REDIS_PORT, REDIS_PASSWORD, } = process.env; const redisOpts = { host: REDIS_HOST, port: REDIS_PORT, password: REDIS_PASSWORD, lazyConnect: true, }; module.exports = class AuthService extends Service { constructor(broker) { super(broker); this.parseServiceSchema({ name: 'auth', mixins: [redis({ options: redisOpts }), server({ router })], }); } }
Almacenamiento en caché
Las llamadas de método (acciones) se pueden almacenar en caché de varias maneras: LRU, Memoria, Redis. Opcionalmente, puede especificar qué llamadas clave se almacenarán en caché (de forma predeterminada, el hash de objeto se usa como clave de almacenamiento en caché) y con qué TTL.
Ejemplo de declaración de método en caché module.exports = class InventoryService extends Service { constructor(broker) { super(broker); this.parseServiceSchema({ name: 'inventory', actions: { getInventory: { params: { steamId: { type: 'string', pattern: /^76\d{15}$/ }, appId: { type: 'number', integer: true }, contextId: { type: 'number', integer: true }, }, cache: { keys: ['steamId', 'appId', 'contextId'], ttl: 15, }, async handler(ctx) { return true; }, }, }, }); }
El método de almacenamiento en caché se establece a través de la configuración de ServiceBroker.
Registro
Aquí, sin embargo, todo también es bastante simple. Hay un registrador incorporado bastante bueno que escribe en la consola, es posible especificar un formato personalizado. Nada impide robar ningún otro registrador popular, ya sea winston o bunyan. Un manual detallado está en la
documentación . Personalmente, utilizamos el registrador incorporado, el formateador personalizado para un par de líneas de código que el correo no deseado en la consola JSON simplemente se corta en el producto, después de lo cual ingresan a Graylog utilizando el controlador de registro de Docker.
Métricas
Si lo desea, puede recopilar métricas para cada método y rastrearlo todo en algún zipkin. Aquí
está la lista completa de exportadores disponibles. Actualmente hay cinco de ellos: Zipkin, Jaeger, Prometheus, Elastic, Console. Se configura, como el almacenamiento en caché, al declarar un método (acción).
Los ejemplos de visualización para el paquete elasticsearch + kibana usando el módulo
elastic-apm-node se pueden ver en
este enlace en Github.
La forma más fácil, por supuesto, es usar la opción de consola. Se ve así:

Tolerancia a fallos
El marco tiene un interruptor automático incorporado, que se controla a través de la configuración de ServiceBroker. Si algún servicio falla y el número de estas fallas excede un cierto umbral, se marcará como no saludable, las solicitudes se limitarán severamente hasta que deje de cometer errores.
Como beneficio adicional, también hay un respaldo individualmente ajustable para cada método (acción), en caso de que supongamos que el método puede fallar y, por ejemplo, enviar datos almacenados en caché o un código auxiliar.
Conclusión
La introducción de este marco para mí se convirtió en un soplo de aire fresco, lo que ahorró una gran cantidad de golpes (excepto por el hecho de que la arquitectura de microservicios es un gran toque) y el ciclismo, hizo que escribir el siguiente microservicio fuera simple y transparente. No hay nada superfluo, es simple y muy flexible, y puede escribir el primer servicio dentro de una o dos horas después de leer la documentación. Me alegrará si este material es útil para usted y en su próximo proyecto querrá probar este milagro, como lo hicimos nosotros (y aún no me he arrepentido). Bueno para todos!
Además, si está interesado en este marco, únase al chat en Telegram -
@moleculerchat