
Entre la fecha de los científicos, hay muchos holivars, y uno de ellos se refiere al aprendizaje automático competitivo. ¿El éxito de Kaggle realmente muestra la capacidad de un especialista para resolver tareas de trabajo típicas? Arseny
arseny_info (Líder del equipo de I + D @
WANNABY ,
Kaggle Master , más adelante en
A. ) y Arthur
n01z3 (Jefe de Visión por Computadora @
X5 Retail Group ,
Kaggle Grandmaster , más tarde en
N. ) escalaron el holivar a un nuevo nivel: en lugar de otra discusión en tomaron micrófonos en la sala de chat y mantuvieron una
discusión pública en la reunión , sobre la base de la cual nació este artículo.
Métricas, núcleos, tabla de clasificación
A:Me gustaría comenzar con el argumento esperado de que Kaggle no enseña lo más importante en el trabajo de una cita típica de un científico: la declaración del problema. Una tarea configurada correctamente ya contiene la mitad de la solución, y a menudo esta mitad es la más difícil, y codificar algún modelo y entrenarlo es mucho más fácil. Kaggle ofrece una tarea de un mundo ideal: los datos están listos, la métrica está lista, toma y entrena.
Sorprendentemente, incluso con esto, surgen problemas. No es difícil encontrar muchos ejemplos cuando los "kagglers" se confunden cuando ven una métrica desconocida / incomprensible.
N:Sí, esa es la esencia de kaggle. Los organizadores pensaron, formalizaron la tarea, recopilaron el conjunto de datos y determinaron la métrica. Pero si una persona tiene el comienzo del pensamiento crítico, entonces lo primero que pensará es por qué decidió que la métrica elegida o el objetivo propuesto es óptimo.
Los participantes fuertes a menudo redefinen la tarea ellos mismos y encuentran un mejor objetivo.
Y cuando descubrieron la métrica, determinaron el objetivo y recopilaron los datos, entonces la optimización de la métrica es lo que mejor hacen los kagglers. Después de cada competencia, el cliente puede creer con gran confianza que los participantes mostraron el "techo" para el algoritmo ideal con una velocidad máxima. Y para lograr esto, los kagglers prueban muchos enfoques e ideas diferentes, validándolos con iteraciones rápidas.
Este enfoque se convierte directamente en un trabajo exitoso en tareas reales. Además, los kugglers experimentados pueden seleccionar de forma intuitiva inmediata o de una experiencia pasada una lista de ideas que vale la pena probar en primer lugar para obtener el máximo beneficio. Y aquí todo el arsenal de la comunidad kaggle viene al rescate: artículos, holgura, foro, núcleos.
 A:
A:Usted mencionó "núcleos", y tengo una queja por separado para ellos. Muchas competiciones se han convertido en un desarrollo impulsado por el núcleo. No me enfocaré en casos degenerados en los que una medalla de oro podría obtenerse debido al lanzamiento exitoso de un guión público. Sin embargo, incluso en las competiciones de aprendizaje profundo ahora puede obtener algún tipo de medalla, casi sin escribir código. Puede tomar varias decisiones públicas, especialmente sin comprender el giro de algunos parámetros, probarse en la tabla de clasificación, promediar los resultados y obtener una buena métrica.
Anteriormente, incluso los éxitos moderados en las competiciones de "imágenes" (por ejemplo, una medalla de bronce, es decir, entrar en el 10% superior de la calificación final) mostraban que una persona es capaz de algo: había que escribir una tubería normal al menos desde el principio hasta el final , prevenir errores críticos. Ahora estos éxitos se han devaluado: Kaggle está promocionando su plataforma central con might and main, lo que reduce el umbral de entrada y le permite experimentar de alguna manera sin darse cuenta de qué es qué.
 N:
N:La medalla de bronce nunca ha sido citada. Este es el nivel de "Lancé algo allí, y aprendí". Y no es tan malo.
Bajar el nivel de entrada debido a los núcleos y la presencia de GPU en ellos crea competencia y eleva el nivel general de conocimiento más alto. Si hace un año era posible obtener oro usando Vanilla Unet, ahora no puedes prescindir de más de 5 modificaciones y trucos. Y estos trucos funcionan no solo en Kaggle, sino también más allá. Por ejemplo, en
Aerial-Inria, nuestros tipos de ods.ai se levantaron y mostraron el estado del arte simplemente con sus poderosas tuberías de segmentación desarrolladas por Kaggle. Esto muestra la aplicabilidad de tales enfoques en el trabajo real.
 A:
A:El problema es que
en tareas reales no hay tabla de clasificación . Por lo general, no hay un número único que muestre que todo salió mal o, por el contrario, todo está bien. A menudo hay varios números, se contradicen entre sí, vincularlos en un sistema es otro desafío.
N:Pero las métricas son de alguna manera importantes. Muestran un rendimiento objetivo del algoritmo. Sin algoritmos con métricas por encima de un umbral utilizable, es imposible crear servicios basados en ML.
A:Pero solo si reflejan honestamente el estado del producto, que no siempre es el caso. Sucede que debe arrastrar la métrica a un mínimo higiénico, y
las mejoras adicionales de la métrica "técnica" ya no corresponden a mejoras del producto (el usuario no nota estas +0.01 IoU), se pierde la correlación entre la métrica y las sensaciones del usuario.
Además, los métodos clásicos de kaggle para aumentar la métrica no son aplicables en el trabajo normal. No es necesario buscar "caras", no es necesario reproducir el marcado y encontrar las respuestas correctas mediante hash de archivos.

Validación confiable y conjuntos de modelos atrevidos
N:Kaggle te enseña a validar correctamente, incluso debido a la presencia de caras. Debes tener muy claro cómo ha mejorado la velocidad en la tabla de clasificación. También es
necesario construir una validación local representativa que refleje la parte privada de la tabla de clasificación o la distribución de datos en producción, si estamos hablando de trabajo real.
Otra cosa de la que a menudo se culpa a los Kagglers es a los conjuntos. Una solución de Kaggle generalmente consiste en un grupo de modelos, y es imposible arrastrar el producto. Sin embargo, olvidan que es imposible hacer una solución sólida sin modelos únicos fuertes. Y para ganar, no solo necesitas un conjunto, sino un conjunto de modelos individuales diversos y fuertes.
El enfoque de "mezclar todo en una fila" nunca da un resultado decente. A:
A:El concepto de "modelo único simple" en la reunión de Kaggle y para el entorno de producción puede ser muy diferente. En el marco de la competencia, esta será una arquitectura entrenada en 5/10 pliegues, con un codificador extendido, en el tiempo que puede esperar el aumento del tiempo de prueba. Según los estándares de competencia, esta es una solución realmente simple.
Pero la producción a menudo
necesita soluciones un par de órdenes de magnitud más fáciles , especialmente cuando se trata de aplicaciones móviles o IoT. Por ejemplo, en mi caso, los modelos Kaggle generalmente ocupan más de 100 megabytes, y en el trabajo del modelo a menudo ni siquiera se consideran unos pocos megabytes; Hay una brecha similar en los requisitos para la tasa de inferencia.
N:Sin embargo, si la fecha en que el científico sabe cómo entrenar una grilla pesada, las mismas técnicas también son adecuadas para entrenar modelos livianos. En una primera aproximación, puede tomar solo una malla similar más fácil o una versión móvil de la misma arquitectura. Cuantización de escalas y poda más allá de la competencia de Kagglers, sin duda aquí. Pero estas ya son habilidades muy específicas, que están lejos de ser siempre urgentemente necesarias en producción.
Pero una situación mucho más frecuente en problemas reales es que hay un pequeño conjunto de datos etiquetado
(como sus pantalones) y la mayoría de los datos no asignados o un flujo continuo de datos nuevos. Y aquí la capacidad de soldar un conjunto grande y preciso se adapta perfectamente. Con él, puedes hacer pseudo-atenuación o destilación para entrenar a un modelo liviano. El aumento del conjunto de datos de esta manera garantiza la mejora del rendimiento de cualquier modelo.
A:El pseudo-dabbing es útil, pero en las competiciones no se usa para una buena vida, solo porque es imposible cambiar el tamaño de los datos. Los datos obtenidos mediante pseudo-atenuación, aunque mejoran la métrica, no son tan útiles como volver a marcar manualmente los datos faltantes.
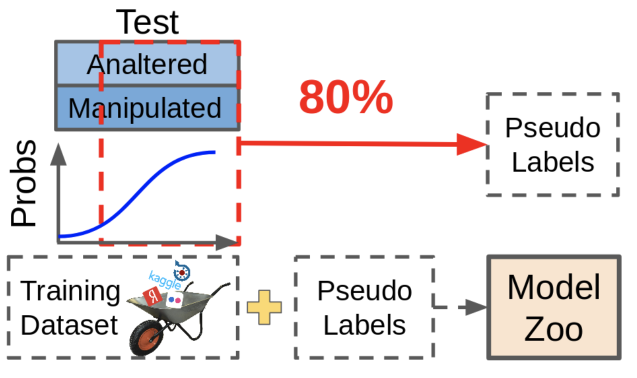
¿Qué es pseudo-dabbing? Tomamos modelos existentes, miramos dónde dan predicciones confiables, arrojamos estas muestras junto con las predicciones en nuestro conjunto de datos. En este caso, las muestras difíciles para el modelo permanecen sin etiquetar, porque Estas predicciones no son lo suficientemente buenas ahora. Círculo vicioso!
En la práctica, es mucho más útil encontrar aquellas muestras que hacen que la red produzca predicciones inciertas y cambiar su tamaño. Requiere mucho trabajo manual, pero el efecto lo vale.
Sobre la belleza del código y el trabajo en equipo
A:Otro problema es la calidad del código y la cultura de desarrollo. Kaggle no solo no te enseña a escribir código, sino que también proporciona muchos malos ejemplos. La mayoría de los núcleos tienen un código poco estructurado, ilegible e ineficiente que se copia sin pensar. Algunas personalidades populares de Kaggle incluso practican cargar su código en Google Drive en lugar del repositorio.

Las personas son buenas en el aprendizaje no supervisado. Si observa mucho el código incorrecto, puede acostumbrarse a la idea de que debería ser así. Esto es especialmente peligroso para los principiantes, que son bastante en Kaggle.
N:La calidad del código es un punto discutible en el abrazo, estoy de acuerdo. Sin embargo, también conocí a personas que escribieron ductos muy valiosos que podrían reutilizarse para otras tareas. Pero esta es más bien la excepción: en el fragor de la pelea, la calidad del código se sacrifica a favor de la verificación rápida de nuevas ideas, especialmente hacia el final de la competencia.
Pero Kaggle enseña trabajo en equipo. Y nada une a las personas como una causa común, un objetivo comprensible común. Puedes intentar competir con un montón de personas diferentes, involucrarte y desarrollar habilidades blandas.
 A:
A:Los equipos al estilo Kaggle también son muy diferentes. Es bueno si realmente hay algún tipo de separación de tareas por roles, interacción constructiva, y todos hacen una contribución. Sin embargo, los equipos en los que todos hacen su propia gran bola de barro, y en los últimos días de la competencia, todo esto se mezcla frenéticamente, también son suficientes, y esto tampoco enseña nada bueno: el desarrollo real del software (incluida la ciencia de datos) es así No hecho por mucho tiempo.
Resumen
Resumamos
Sin lugar a dudas, la participación en concursos brinda sus bonificaciones que son útiles en el trabajo diario: en primer lugar, es la capacidad de iterar rápidamente, exprimir todo de los datos dentro del marco de la métrica y no dudar en utilizar enfoques de última generación.
Por otro lado, el abuso de los enfoques de Kaggle a menudo conduce a un código subóptimo ilegible, prioridades de trabajo dudosas y un poco de bling.
Sin embargo, en cualquier fecha que el científico sepa que para crear con éxito un conjunto, debe combinar una variedad de modelos. Por lo tanto, en un equipo
vale la pena combinar personas con diferentes conjuntos de habilidades , y uno o dos Kagglers experimentados serán útiles para casi cualquier equipo.