Cuando elegimos una herramienta para procesar big data, consideramos diferentes opciones, tanto propietarias como de código abierto. Evaluamos las posibilidades de adaptación rápida, accesibilidad y flexibilidad de las tecnologías. Incluyendo migración entre versiones. Como resultado, elegimos la solución de código abierto Greenplum, que mejor cumplía con nuestros requisitos, pero requería la solución de un problema importante.

El hecho es que las versiones 4 y 5 de los archivos de la base de datos Greenplum no son compatibles entre sí y, por lo tanto, es imposible una simple actualización de una versión a otra. La migración de datos solo se puede realizar cargando y descargando datos. En esta publicación hablaré sobre las posibles opciones para esta migración.
Evaluar las opciones de migración
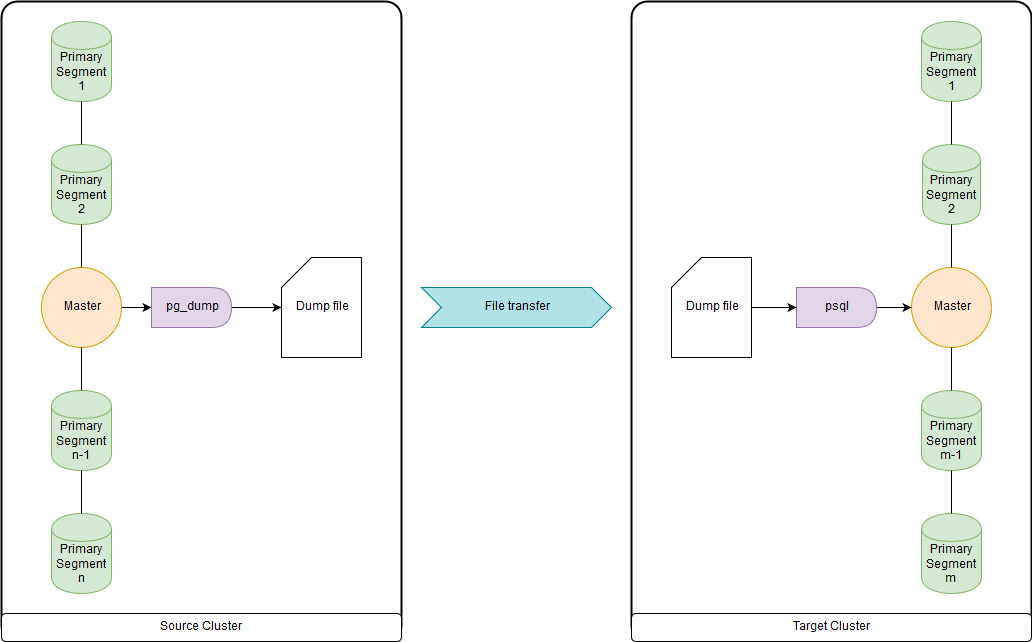
pg_dump y psql (o pg_restore)
Esto es demasiado lento cuando se trata de docenas de terabytes, ya que todos los datos se cargan y descargan a través de los nodos maestros. Pero lo suficientemente rápido como para migrar DDL y tablas pequeñas. Puede cargar ambos en un archivo y ejecutar pg_dump y psql al mismo tiempo a través de una tubería en un clúster de origen y un clúster de destino. pg_dump simplemente carga en un solo archivo que contiene comandos DDL y comandos de datos COPY. Los datos obtenidos se pueden procesar convenientemente, lo que se mostrará a continuación.
gptransfer
Requiere la versión Greenplum 4.2 o posterior. Es necesario que tanto el clúster de origen como el clúster de destino trabajen simultáneamente. La forma más rápida de migrar tablas de datos grandes para la versión de código abierto. Pero este método es muy lento para transferir tablas vacías y pequeñas debido a la alta sobrecarga.
gptransfer usa pg_dump para transferir DDL y gpfdist para transferir datos. El número de segmentos primarios en el clúster de destino no debe ser menor que el segmento de host en el clúster de origen. Esto es importante a tener en cuenta al crear clústeres de "caja de arena", si los datos de los clústeres principales se transferirán a ellos, y se planea el uso de la utilidad gptransfer. Incluso si los hosts de segmento son pocos, puede implementar el número requerido de segmentos en cada uno de ellos. El número de segmentos en el clúster de destino puede ser menor que en el clúster de origen, sin embargo, esto
afectará negativamente la velocidad de transferencia de datos. Entre los clústeres, se debe configurar la autenticación ssh en los certificados.
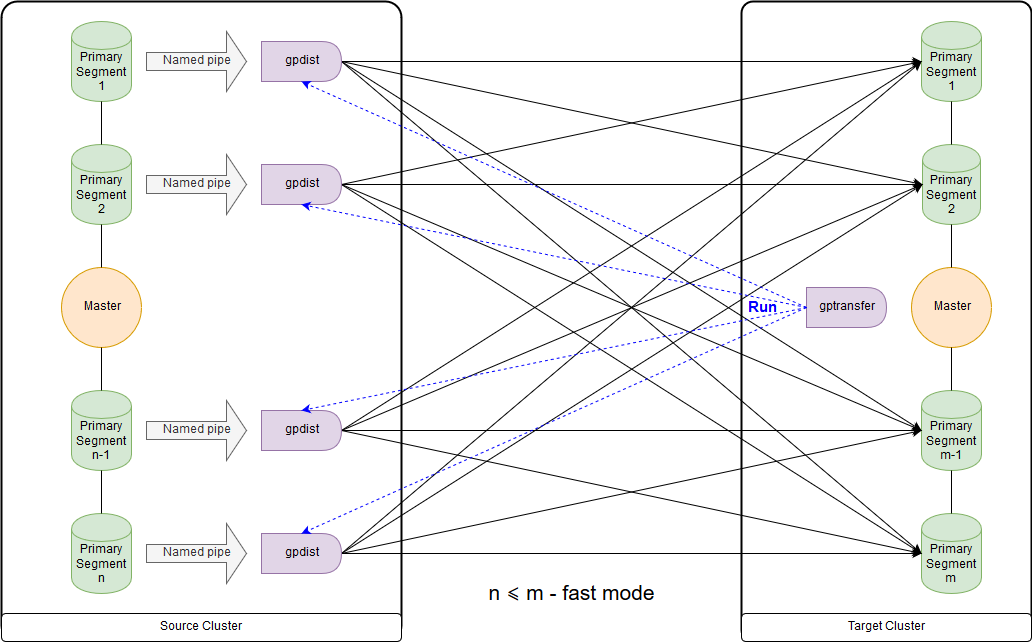
Este es el esquema para el modo rápido cuando el número de segmentos en el clúster de destino es mayor o igual que el número en el clúster de origen. El lanzamiento de la utilidad en sí se muestra en el diagrama en el nodo maestro del clúster receptor. En este modo, se crea una tabla de escritura externa en el clúster de origen, que escribe datos en cada segmento en la tubería con nombre. Se ejecuta el comando INSERT INTO en writable_external_table SELECT * FROM source_table. Gpfdist lee los datos de la canalización con nombre. También se crea una tabla externa en el clúster de destino, solo para lectura. La tabla indica los datos que proporciona gpfdist sobre
el protocolo del mismo nombre . Se ejecuta el comando INSERT INTO target_table SELECT * FROM external_gpfdist_table. Los datos se redistribuyen automáticamente entre segmentos del clúster de destino.
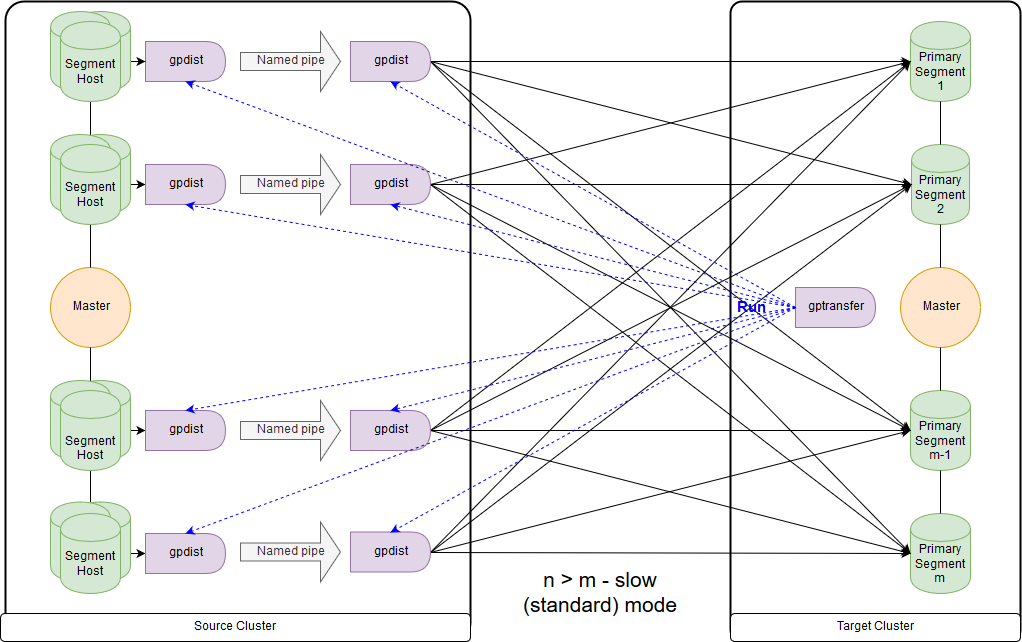
Y este es el esquema para el modo lento o, como dice gptransfer, el modo estándar. La principal diferencia es que en cada segmento-host del clúster de origen, se lanza un par gpfdist para todos los segmentos de este segmento-host. Una tabla de registro externa se refiere a gpfdist que actúa como receptor de datos. Además, si se indican varios valores para escribir en el parámetro LOCATION de la tabla externa, gpfdist distribuye los segmentos de manera uniforme al escribir datos. Los datos entre gpfdist en el segmento host se pasan a través de una canalización con nombre. Debido a esto, la velocidad de transferencia de datos es menor, pero aún resulta más rápida que cuando se transfieren datos solo a través del nodo maestro.
Al migrar datos de Greenplum 4 a Greenplum 5, gptransfer debe ejecutarse en el nodo maestro del clúster de destino. Si ejecutamos gptransfer en el clúster de origen, obtenemos el error de la ausencia del campo
san_mounts en la tabla
pg_catalog.gp_segment_configuration :
gptransfer -t big_db.public.test_table --dest-host=gpdb-target-master.local --dest-database=big_db --source-map-file=/data/master/gpseg-1/host_and_IP_segments --batch-size=10 --sub-batch-size=50 --truncate 20190109:12:46:13:010893 gptransfer:gpdb-source-master.local:gpadmin-[INFO]:-Starting gptransfer with args: -t big_db.public.test_table --dest-host=gpdb-target-master.local --dest-database=big_db --source-map-file=/data/master/gpseg-1/host_and_IP_segments --batch-size=10 --sub-batch-size=50 --truncate 20190109:12:46:13:010893 gptransfer:gpdb-source-master.local:gpadmin-[INFO]:-Validating options... 20190109:12:46:13:010893 gptransfer:gpdb-source-master.local:gpadmin-[INFO]:-Retrieving configuration of source Greenplum Database... 20190109:12:46:13:010893 gptransfer:gpdb-source-master.local:gpadmin-[INFO]:-Retrieving configuration of destination Greenplum Database... 20190109:12:46:14:010893 gptransfer:gpdb-source-master.local:gpadmin-[CRITICAL]:-gptransfer failed. (Reason='error 'ERROR: column "san_mounts" does not exist LINE 2: ... SELECT dbid, content, status, unnest(san_mounts... ^ ' in ' SELECT dbid, content, status, unnest(san_mounts) FROM pg_catalog.gp_segment_configuration WHERE content >= 0 ORDER BY content, dbid '') exiting...
También debe verificar las variables GPHOME para que coincidan entre el clúster de origen y el clúster de destino. De lo contrario, obtenemos un
error bastante extraño (la utilidad gptransfer falla cuando el origen y el destino tienen una ruta GPHOME diferente).
gptransfer -t big_db.public.test_table --source-host=gpdb-source-master.local --dest-database=big_db --source-map-file=/data1/master/gpseg-1/source_host_and_IP_segments --b atch-size=10 --sub-batch-size=50 --truncate 20190109:14:12:07:031438 gptransfer:mdw:gpadmin-[INFO]:-Starting gptransfer with args: -t big_db.public.test_table --source-host=gpdb-spurce-master.local --dest-database=big_db --source-map-file=/data1/master/gpseg-1/source_host_and_IP_segments --b atch-size=10 --sub-batch-size=50 --truncate 20190109:14:12:07:031438 gptransfer:mdw:gpadmin-[INFO]:-Validating options... 20190109:14:12:07:031438 gptransfer:mdw:gpadmin-[ERROR]:-gptransfer: error: GPHOME directory does not exist on gpdb-source-master.local
Simplemente puede crear el enlace simbólico correspondiente y anular la variable GPHOME en la sesión en la que se inicia gptransfer.
Cuando se inicia gptransfer en el clúster de destino, la opción "--source-map-file" debe apuntar a un archivo que contenga una lista de hosts y sus direcciones IP con segmentos primarios del clúster de origen. Por ejemplo:
sdw1,192.0.2.1 sdw2,192.0.2.2 sdw3,192.0.2.3 sdw4,192.0.2.4
Con la opción "--full" es posible transferir no solo tablas, sino toda la base de datos, sin embargo, las bases de datos de usuarios no deben crearse en el clúster de destino. También debe recordar que hay problemas debido a los cambios de sintaxis al mover tablas externas.
Evaluemos la sobrecarga adicional, por ejemplo, copiando 10 tablas vacías (tablas de big_db.public.test_table_2 a big_db.public.test_table_11) usando gptarnsfer:
gptransfer -f temp_filelist.txt --source-host=gpdb-source-master.local --dest-database=big_db --source-map-file=/data1/master/gpseg-1/source_host_and_IP_segments_dev --batch-size=10 --sub-ba tch-size=50 --truncate 20190118:06:14:08:031521 gptransfer:mdw:gpadmin-[INFO]:-Starting gptransfer with args: -f temp_filelist.txt --source-host=gpdb-source-master.local --dest-database=big_db --source-map-file=/data1/master/gpseg-1/source_host_and_IP_segments_dev --batch-size=10 --sub-batch-size=50 --truncate 20190118:06:14:08:031521 gptransfer:mdw:gpadmin-[INFO]:-Validating options... 20190118:06:14:08:031521 gptransfer:mdw:gpadmin-[INFO]:-Retrieving configuration of source Greenplum Database... 20190118:06:14:08:031521 gptransfer:mdw:gpadmin-[INFO]:-Retrieving configuration of destination Greenplum Database... 20190118:06:14:09:031521 gptransfer:mdw:gpadmin-[INFO]:-Retrieving source tables... 20190118:06:14:12:031521 gptransfer:mdw:gpadmin-[INFO]:-Checking for gptransfer schemas... 20190118:06:14:22:031521 gptransfer:mdw:gpadmin-[INFO]:-Retrieving list of destination tables... 20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:-Reading source host map file... 20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:-Building list of source tables to transfer... 20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:-Number of tables to transfer: 10 20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:-gptransfer will use "standard" mode for transfer. 20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:-Validating source host map... 20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:-Validating transfer table set... 20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:-The following tables on the destination system will be truncated: 20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:- big_db.public.test_table_2 20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:- big_db.public.test_table_3 20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:- big_db.public.test_table_4 20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:- big_db.public.test_table_5 20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:- big_db.public.test_table_6 20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:- big_db.public.test_table_7 20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:- big_db.public.test_table_8 20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:- big_db.public.test_table_9 20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:- big_db.public.test_table_10 20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:- big_db.public.test_table_11 … 20190118:06:14:34:031521 gptransfer:mdw:gpadmin-[INFO]:-Using batch size of 10 20190118:06:14:34:031521 gptransfer:mdw:gpadmin-[INFO]:-Using sub-batch size of 16 20190118:06:14:34:031521 gptransfer:mdw:gpadmin-[INFO]:-Creating work directory '/home/gpadmin/gptransfer_31521' 20190118:06:14:34:031521 gptransfer:mdw:gpadmin-[INFO]:-Creating schema public in database edw_prod... 20190118:06:14:40:031521 gptransfer:mdw:gpadmin-[INFO]:-Starting transfer of big_db.public.test_table_5 to big_db.public.test_table_5... … 20190118:06:15:02:031521 gptransfer:mdw:gpadmin-[INFO]:-Validation of big_db.public.test_table_4 successful 20190118:06:15:02:031521 gptransfer:mdw:gpadmin-[INFO]:-Removing work directories... 20190118:06:15:02:031521 gptransfer:mdw:gpadmin-[INFO]:-Finished.
Como resultado, la transferencia de 10 tablas vacías tomó aproximadamente 16 segundos (14: 40-15: 02), es decir, una tabla - 1.6 segundos. Durante este tiempo, en nuestro caso, se pueden descargar aproximadamente 100 MB de datos usando pg_dump y psql.
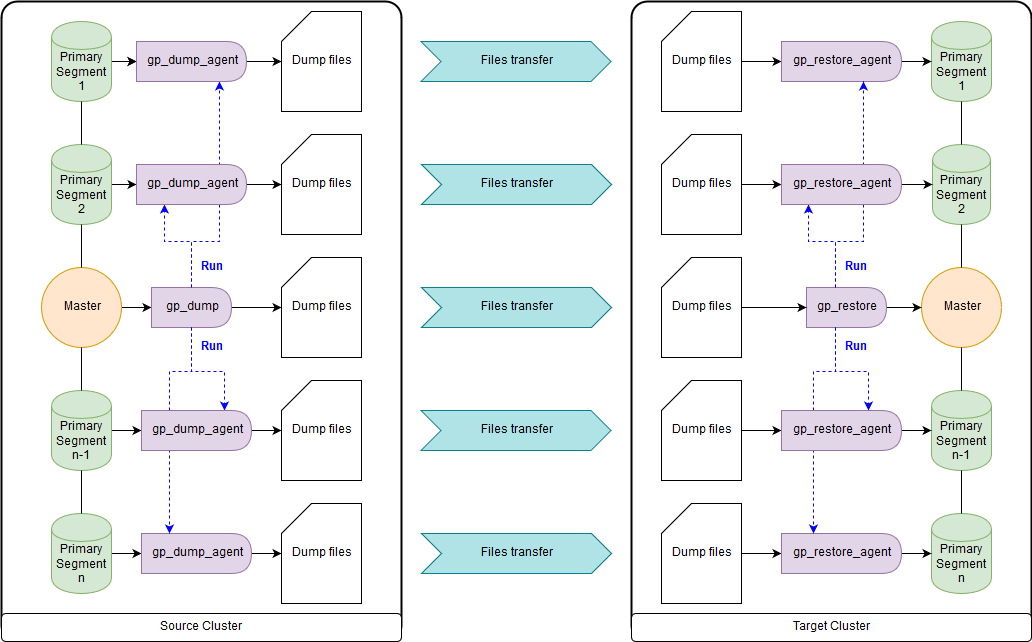
gp_dump & gp_restore
Como opción: use complementos sobre ellos, gpcrondump y gpdbrestore, ya que gp_dump y gp_restore se declaran obsoletos. Aunque gpcrondump y gpdbrestore mismos usan gp_dump y gp_restore en el proceso. Esta es la forma más universal, pero no la más rápida. Los archivos de copia de seguridad creados con gp_dump representan un conjunto de comandos DDL en el nodo maestro y en los segmentos primarios, principalmente conjuntos de comandos y datos COPY. Adecuado para casos en los que no es posible proporcionar una operación simultánea del clúster de destino y el clúster de origen. Hay versiones anteriores de Greenplum y nuevas:
gp_dump ,
gp_restore .
Utilidades gpbackup y gprestore
Creado como un reemplazo para gp_dump y gp_restore. Para su trabajo, se requiere la versión mínima 4.3.17 de Greenplum (
const MINIMUM_GPDB4_VERSION = "4.3.17" ). El esquema de trabajo es similar a gpbackup & gprestore, mientras que la velocidad de trabajo es mucho más rápida. La forma más rápida de obtener comandos DDL para grandes bases de datos. Por defecto, transfiere objetos globales, para la recuperación necesita especificar "gprestore --with-globals". El parámetro opcional "--jobs" puede establecer el número de trabajos (y sesiones en la base de datos) al crear una copia de seguridad. Debido al hecho de que se crean varias sesiones, es importante garantizar la coherencia de los datos hasta que se reciban todos los bloqueos. También hay una opción útil "--with-stats", que le permite transferir estadísticas sobre objetos utilizados para construir planes de ejecución. Más información
aquí .
Utilidad gpcopy
Para copiar bases de datos hay una utilidad gpcopy, un reemplazo para gptansfer. Pero se incluye solo en la versión patentada de Greenplum de Pivotal, a partir de 4.3.26; en la versión de código abierto,
esta utilidad no . Mientras trabaja en el clúster de origen, se ejecuta el comando COPY source_table TO PROGRAM 'gpcopy_helper ...' ON SEGMENT CSV IGNORE EXTERNAL PARTITIONS. En el lado del clúster receptor, se crea una tabla externa temporal CREAR TABLA DE TEMPERATURA WEB EXTERNA external_temp_table (LIKE target_table) EXECUTE '... gpcopy_helper –listen ...' y se ejecuta el comando INSERT INTO target_table SELECT * FROM external_temp_table. Como resultado, gpcopy_helper con el parámetro –listen se inicia en cada segmento del clúster de destino, que recibe datos de gpcopy_helper de segmentos del clúster de origen. Debido a este esquema de transmisión de datos, así como a la compresión, la velocidad de transmisión es mucho mayor. Entre los clústeres, la autenticación ssh en los certificados también debe configurarse. También quiero señalar que gpcopy tiene una opción conveniente "--truncate-source-after" (y "--validate") para los casos en que los clústeres de origen y destino se encuentran en los mismos servidores.
Estrategia de transferencia de datos
Para determinar la estrategia de transferencia, necesitamos determinar qué es más importante para nosotros: transferir datos rápidamente, pero con más trabajo y posiblemente menos confiable (gpbackup, gptransfer o una combinación de los mismos) o con menos trabajo, pero más lento (gpbackup o gptransfer sin combinar).
La forma más rápida de transferir datos, cuando hay un clúster de origen y un clúster de destino, es la siguiente:
- Obtenga DDL usando gpbackup --metadata-only, convierta y cargue a través de la tubería usando psql
- Eliminar índices
- Transfiera tablas con un tamaño de 100 MB o más utilizando gptransfer
- Transfiera tablas con un tamaño de menos de 100 MB utilizando pg_dump | psql como en el primer párrafo
- Crear de nuevo índices eliminados
Este método resultó estar en nuestras mediciones al menos 2 veces más rápido que gp_dump y gp_restore. Métodos alternativos: transferir todas las bases de datos usando gptransfer –full, gpbackup & gprestore, o gp_dump & gp_restore.
Los tamaños de tabla se pueden obtener mediante la siguiente consulta:
SELECT nspname AS "schema", coalesce(tablename, relname) AS "name", SUM(pg_total_relation_size(class.oid)) AS "size" FROM pg_class class JOIN pg_namespace namespace ON namespace.oid = class.relnamespace LEFT JOIN pg_partitions parts ON class.relname = parts.partitiontablename AND namespace.nspname = parts.schemaname WHERE nspname NOT IN ('pg_catalog', 'information_schema', 'pg_toast', 'pg_bitmapindex', 'pg_aoseg', 'gp_toolkit') GROUP BY nspname, relkind, coalesce(tablename, relname), pg_get_userbyid(class.relowner) ORDER BY 1,2;
Conversiones necesarias
Los archivos de copia de seguridad en Greenplum versiones 4 y 5 tampoco son totalmente compatibles. Entonces, en Greenplum 5, debido a un cambio en la sintaxis, los comandos CREATE EXTERNAL TABLE y COPY no tienen el parámetro INTO ERROR TABLE, y debe establecer el parámetro SET gp_ignore_error_table en true para que la restauración de la copia de seguridad no falle por error. Con el conjunto de parámetros, solo recibimos una advertencia.
Además, la quinta versión introdujo un protocolo diferente para interactuar con tablas pxf externas, y para usarlo, debe cambiar el parámetro LOCATION, así como configurar el servicio pxf.
También vale la pena señalar que en los archivos de copia de seguridad gp_dump y gp_restore tanto en el nodo maestro como en cada segmento primario, el parámetro SET gp_strict_xml_parse se establece en falso. No existe dicho parámetro en Greenplum 5 y, como resultado, recibimos un mensaje de error.
Si el protocolo gphdfs se usó para tablas externas, debe verificar la lista de origen en los archivos de respaldo en el parámetro LOCATION para tablas externas mediante la línea 'gphdfs: //'. Por ejemplo, solo debería haber 'gphdfs: //hadoop.local: 8020'. Si hay otras líneas, deben agregarse al script de reemplazo en el nodo maestro por analogía.
grep -o gphdfs\:\/\/.*\/ /data1/master/gpseg-1/db_dumps/20181206/gp_dump_-1_1_20181206122002.gz | cut -d/ -f1-3 | sort | uniq gphdfs://hadoop.local:8020
Hacemos reemplazos en el nodo maestro (usando el archivo de datos gp_dump como ejemplo):
mv /data1/master/gpseg-1/db_dumps/20181206/big_db_gp_dump_1_1_20181206080001.gz /data1/master/gpseg-1/db_dumps/20181206/big_db_gp_dump_1_1_20181206080001.old.gz gunzip -c /data1/master/gpseg-1/db_dumps/20181206/big_db_gp_dump_1_1_20181206080001.old.gz | sed "s#'gphdfs://hadoop.local:8020#'pxf:/#g" | sed "s/\(^.*pxf\:\/\/.*'\)/\1\\&\&\?PROFILE=HdfsTextSimple'/" |sed "s#'&#g" | sed 's/SET gp_strict_xml_parse = false;/SET gp_ignore_error_table = true;/g' | gzip -1 > /data1/master/gpseg-1/db_dumps/20181206/big_db_gp_dump_1_1_20181206080001.gz nets
En versiones recientes, el nombre del perfil HdfsTextSimple se
declara obsoleto , el nuevo nombre es hdfs: text.
Resumen
La conversión implícita de texto , el nuevo mecanismo de gestión de recursos del clúster de
grupos de recursos, que reemplaza las colas de recursos, el optimizador
GPORCA , que se incluye por defecto en Greenplum 5, los problemas menores con los clientes quedaron fuera del alcance del artículo.
Espero con ansias el lanzamiento de la sexta versión de Greenplum, que está programada para la primavera de 2019: nivel de compatibilidad con PostgreSQL 9.4, Búsqueda de texto completo, Soporte de índice GIN, Tipos de rango, JSONB, Compresión zStd. Además, se conocieron los planes preliminares para Greenplum 7: nivel de compatibilidad con PostgreSQL mínimo 9.6, seguridad de nivel de fila, conmutación por error maestra automatizada. Los desarrolladores también prometen la disponibilidad de utilidades de actualización de bases de datos para actualizar entre versiones principales, por lo que será más fácil vivir.
Este artículo fue preparado por el equipo de gestión de datos de Rostelecom