¿Cuán complejo es el tema del aprendizaje automático? Si eres bueno en matemáticas, pero la cantidad de conocimiento sobre el aprendizaje automático tiende a cero, ¿hasta dónde puedes llegar en una competencia seria en la plataforma
Kaggle ?

Sobre el sitio y la competencia
Kaggle es una comunidad de personas interesadas en ML (desde principiantes hasta profesionales geniales) y un lugar para concursos (a menudo con un impresionante premio acumulado).
Para sumergirme de inmediato en todos los encantos de ML, decidí elegir inmediatamente una competencia seria. Tal solo estaba disponible:
Two Sigma: Uso de noticias para predecir movimientos de acciones . La esencia del concurso en pocas palabras es predecir el precio de las acciones de varias compañías en función del estado del activo y las noticias relacionadas con este activo. El fondo de premios del concurso es de $ 100,000, que se distribuirá entre los participantes que ganaron los primeros 7 lugares.
La competencia es especial por dos razones:
- este es un concurso exclusivo de Kernels: solo puedes entrenar modelos en la nube de Kaggle Kernels;
- la distribución final de los asientos se conocerá solo seis meses después de la finalización de la toma de decisiones; durante este tiempo, las decisiones predecirán los precios en la fecha actual.
Sobre la tarea
Por condición, debemos predecir la confianza
en eso aumentará el rendimiento del activo. El rendimiento de un activo se considera en relación con el rendimiento del mercado en su conjunto. La métrica objetivo es personalizada: no es el
RMSE o el
MAE más familiares, sino
la relación de Sharpe , que en este caso se considera de la siguiente manera:
donde
,
- el rendimiento del activo i en relación con el mercado para el día t en un horizonte de 10 días,
- una variable booleana que indica si el i-ésimo activo está incluido en la valoración para el día t,
- valor medio
,
- desviación estándar
.
La relación de Sharpe es el rendimiento ajustado al riesgo, los valores del coeficiente muestran la efectividad del operador:
- menos de 1: bajo rendimiento
- 1 - 2: media, eficiencia normal,
- 2-3: excelente rendimiento,
- más de 3: perfecto.
Datos de movimiento del mercado- hora (datetime64 [ns, UTC]) - hora actual (en los datos sobre el movimiento del mercado en todas las líneas a las 22:00 UTC)
- assetCode (objeto) - identificador de activo
- assetName (categoría): un identificador de un grupo de activos para la comunicación con datos de noticias
- universo (float64): un valor booleano que indica si este activo se tendrá en cuenta en el cálculo de la puntuación
- volumen (float64) - volumen diario de negociación
- close (float64) - precio de cierre para este día
- abierto (float64) - precio abierto para este día
- returnClosePrevRaw1 (float64): rendimiento desde el cierre hasta el cierre del día anterior
- returnOpenPrevRaw1 (float64): rentabilidad desde la apertura hasta la apertura del día anterior
- returnClosePrevMktres1 (float64): rendimiento de cierre a cierre del día anterior, ajustado en relación con el movimiento del mercado en su conjunto
- returnOpenPrevMktres1 (float64): rentabilidad desde la apertura hasta la apertura del día anterior, ajustada en relación con el movimiento del mercado en su conjunto
- returnClosePrevRaw10 (float64) - rendimiento de cerca a cerrar durante los 10 días anteriores
- returnOpenPrevRaw10 (float64): rentabilidad desde la apertura hasta la apertura durante los 10 días anteriores
- returnClosePrevMktres10 (float64): rendimiento de cierre a cierre durante los 10 días anteriores, ajustado en relación con el movimiento del mercado en su conjunto
- returnOpenPrevMktres10 (float64): rendimiento de apertura a apertura durante los 10 días anteriores, ajustado en relación con el movimiento del mercado en su conjunto
- returnOpenNextMktres10 (float64): rendimiento de abierto a abierto durante los próximos 10 días, ajustado por el movimiento del mercado en su conjunto. Vamos a predecir este valor.
Datos de noticias- time (datetime64 [ns, UTC]) - hora en disponibilidad de datos UTC
- sourceTimestamp (datetime64 [ns, UTC]) - hora en las noticias de publicación UTC
- firstCreated (datetime64 [ns, UTC]) - hora en UTC de la primera versión de los datos
- sourceId (objeto) - identificador de registro
- título (objeto) - título
- urgencia (int8) - tipos de noticias (1: alerta, 3: artículo)
- takeSequence (int16) - parámetro no muy claro, número en alguna secuencia
- proveedor (categoría): identificador del proveedor de noticias
- temas (categoría): una lista de códigos de temas de noticias (puede ser un signo geográfico, evento, sector industrial, etc.)
- audiencias (categoría) - lista de noticias de códigos de audiencia
- bodySize (int32): número de caracteres en el cuerpo de noticias
- companyCount (int8): número de empresas mencionadas explícitamente en las noticias
- headlineTag (objeto): cierta etiqueta de título de Thomson Reuters
- marketCommentary (bool): una señal de que las noticias se relacionan con las condiciones generales del mercado
- sentenceCount (int16) - número de ofertas en las noticias
- wordCount (int32): número de palabras y signos de puntuación en las noticias
- assetCodes (categoría): lista de activos mencionados en las noticias
- assetName (categoría) - código de grupo de activos
- firstMentionSentence (int16): una oración que primero menciona un activo:
- relevancia (float32): un número del 0 al 1, que muestra la relevancia de las noticias sobre el activo
- sentimentClass (int8) - clase de tonalidad de noticias
- sentimentNegative (float32) - probabilidad de que la tonalidad sea negativa
- sentimentNeutral (float32) - probabilidad de que el tono sea neutral
- sentimentPositive (float32) - probabilidad de que la clave sea positiva
- sentimentWordCount (int32): la cantidad de palabras en el texto que están relacionadas con el activo
- noveltyCount12H (int16) - noticias de "novedad" en 12 horas, calculadas en relación con las noticias anteriores sobre este activo
- novetyCount24H (int16) - mismo, en 24 horas
- noveltyCount3D (int16) - igual, en 3 días
- novetyCount5D (int16) - igual, en 5 días
- novetyCount7D (int16) - mismo, en 7 días
- volumeCounts12H (int16): la cantidad de noticias sobre este activo en 12 horas
- volumeCounts24H (int16) - igual, en 24 horas
- volumeCounts3D (int16) - igual, en 3 días
- volumeCounts5D (int16): igual, durante 5 días
- volumeCounts7D (int16) - igual, en 7 días
La tarea es esencialmente una tarea de clasificación binaria, es decir, predecimos un signo binario, ya sea que el rendimiento aumente (1 clase) o disminuya (clase 0).
Sobre herramientas
Kaggle Kernels es una plataforma de computación en la nube que admite la colaboración. Se admiten los siguientes tipos de núcleos:
- Script de Python
- R script
- Cuaderno Jupyter
- RMarkdown
Cada núcleo se ejecuta en su contenedor acoplable. Se instala una gran cantidad de paquetes en el contenedor,
aquí se puede encontrar una lista de Python. Las especificaciones técnicas son las siguientes:
- CPU: 4 núcleos,
- RAM: 17 GB,
- unidad: 5 GB permanentes y 16 GB temporales,
- tiempo máximo de ejecución del script: 9 horas (en el momento del inicio de la competencia eran 6 horas).
Las GPU también están disponibles en Kernels, sin embargo, la GPU estaba prohibida en este concurso.
Keras es un marco de red neuronal de alto nivel que se ejecuta sobre
TensorFlow ,
CNTK o
Theano . Es una API muy conveniente y comprensible, y es posible agregar sus topologías de red, funciones de pérdida y más utilizando la API de back-end.
Scikit-learn es una gran biblioteca de algoritmos de aprendizaje automático. Una fuente útil de preprocesamiento de datos y algoritmos de análisis de datos para su uso con marcos más especializados.
Validación del modelo
Antes de enviar un modelo para evaluación, debe verificar de alguna manera localmente qué tan bien funciona, es decir, encontrar una forma de validación local. Intenté los siguientes enfoques:
- validación cruzada versus división proporcional simple en conjuntos de entrenamiento / prueba;
- Cálculo local de la relación de Sharpe vs ROC AUC .
Como resultado, los resultados más cercanos a la evaluación competitiva, por extraño que parezca, mostraron una combinación de la partición proporcional (seleccionada empíricamente la partición 0.85 / 0.15) y AUC. La validación cruzada probablemente no sea muy adecuada, ya que el comportamiento del mercado es muy diferente en las primeras etapas de los datos de capacitación y en el período de evaluación. ¿Por qué las AUC funcionaron mejor que la relación de Sharpe? No puedo decir nada.
Primeros intentos
Dado que la tarea es predecir la serie temporal, se probó la primera solución clásica: una red neuronal recurrente (
RNN ), o más bien, sus variantes
LSTM y
GRU .
El principio principal de las redes recurrentes es que para cada valor de salida, no se ingresa una muestra, sino una secuencia completa. De esto se desprende que:
- necesitamos un preprocesamiento de los datos iniciales: la generación de estas mismas secuencias de duración t días para cada activo;
- un modelo basado en una red recurrente no puede predecir el valor de salida si no hay datos para los t días anteriores.
Generé secuencias para cada día, comenzando con t, por lo que para t bastante grande (de 20) el conjunto completo de muestras de entrenamiento dejó de caber en la memoria. El problema se resolvió usando generadores, ya que Keras puede usar generadores como conjuntos de datos de entrada y salida para entrenamiento y predicción.
La preparación inicial de los datos fue lo más ingenua posible: tomamos todos los datos del mercado y agregamos un par de características (día de la semana, mes, número de semana del año), y no tocamos los datos de las noticias en absoluto.
El primer modelo usó t = 10 y se veía así:
model = Sequential() model.add(LSTM(256, activation=act.tanh, return_sequences=True, input_shape=(data.timesteps, data.features))) model.add(LSTM(256, activation=act.relu)) model.add(Dense(data.assets, activation=act.relu)) model.add(Dense(data.assets))
No se sacó nada adecuado de este modelo, el puntaje fue cercano a cero (incluso un poco menos).
Redes Convolucionales Temporales
Una solución de red neuronal más moderna para la predicción de series temporales es TCN. La esencia de esta topología es muy simple: tomamos una red convolucional unidimensional y la aplicamos a nuestra secuencia de longitud t. Las opciones más avanzadas utilizan varias capas convolucionales con dilatación diferente. La implementación de TCN se copió parcialmente (a veces a nivel de idea)
desde aquí (visualización de la pila de TCN tomada del
artículo de Wavenet ).
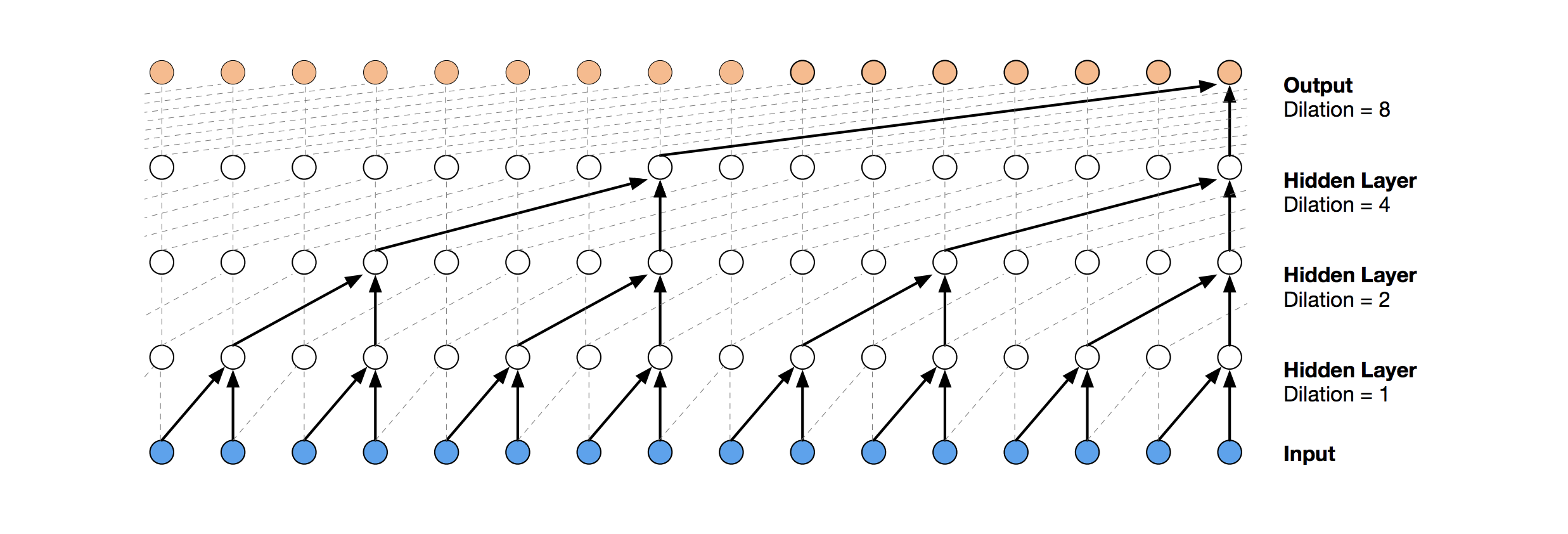
La primera solución relativamente exitosa fue este modelo, que incluye una capa GRU sobre TCN:
model = Sequential() model.add(Conv1D(512,3, activation=act.relu, padding='causal', input_shape=(data.timesteps, data.features))) model.add(Conv1D(100,3, activation=act.relu, padding='causal', dilation_rate=2)) model.add(Conv1D(100,3, activation=act.relu, padding='causal', dilation_rate=4)) model.add(GRU(256)) model.add(Dense(data.assets, activation=act.relu))
Tal modelo produce una puntuación = 0.27668. Con un poco de ajuste (número de filtros TCN, tamaño de lote) y un aumento de t a 100, ya obtenemos 0.41092:
batch_size = 512 model = Sequential() model.add(Conv1D(8,3, activation=act.relu, padding='causal', input_shape=(data.timesteps, data.features))) model.add(Conv1D(4,3, activation=act.relu, padding='causal', dilation_rate=2)) model.add(Conv1D(4,3, activation=act.relu, padding='causal', dilation_rate=4)) model.add(GRU(16)) model.add(Dense(1, activation=act.sigmoid))
A continuación, agregamos normalización y abandono:
Código batch_size = 512 dropout_rate = 0.05 def channel_normalization(x): max_values = K.max(K.abs(x), 2, keepdims=True) + 1e-5 out = x / max_values return out model = Sequential() if(data.timesteps > 1): model.add(Conv1D(16,2, activation=act.relu, padding='valid', input_shape=(data.timesteps, data.features))) model.add(Lambda(channel_normalization)) model.add(SpatialDropout1D(dropout_rate)) model.add(Conv1D(16,1, padding='valid')) for i in range(1, 6): model.add(Conv1D(16,2, activation=act.relu, padding='valid', dilation_rate=2**i)) model.add(Lambda(channel_normalization)) model.add(SpatialDropout1D(dropout_rate)) model.add(Conv1D(16,1, padding='valid')) model.add(Flatten()) else: model.add(Flatten(input_shape=(data.timesteps, data.features))) model.add(Dense(256, activation=act.relu)) model.add(Dense(1, activation=act.sigmoid))
Aplicando este modelo, incluso en los primeros pasos (con t = 1), obtenemos una puntuación = 0.53578.
Máquinas de refuerzo de gradiente
En esta etapa, las ideas terminaron y decidí hacer lo que debía hacerse desde el principio: ver las decisiones públicas de otros participantes. La mayoría de las buenas soluciones no usaban redes neuronales en absoluto, prefiriendo GBM.
Gradient Boosting es un método de ML, en el que obtenemos un conjunto de modelos simples (con mayor frecuencia árboles de decisión). Debido a la gran cantidad de modelos tan simples, la función de pérdida está optimizada. Puede leer más sobre Gradient Boosting, por ejemplo,
aquí .
Como la implementación de GBM utilizó
lightgbm , un marco bastante conocido de Microsoft.
El modelo y el preprocesamiento de datos tomados
de aquí dan inmediatamente una puntuación de aproximadamente 0,64:
Código def prepare_data(marketdf, newsdf):
El preprocesamiento aquí ya incluye datos de noticias, combinándolos con datos de mercado (sin embargo, al hacerlo de manera bastante ingenua, solo se tiene en cuenta un código de activo de todos los que se mencionan en las noticias). Tomé esta opción de preprocesamiento como base para todas las decisiones posteriores.
Al agregar una pequeña característica (firstMentionSentence, marketCommentary, sentimentClass) y también reemplazar la métrica con
ROC AUC , obtenemos un puntaje de 0.65389.
Conjunto
La siguiente decisión exitosa fue utilizar un conjunto compuesto por un modelo de red neuronal y GBM (aunque "conjunto" es un gran nombre para dos modelos). La predicción resultante se obtiene promediando las predicciones de los dos modelos, aplicando así el mecanismo de votación suave. Esta decisión permitió obtener un puntaje de 0,66879.
Análisis exploratorio de datos e ingeniería de características
Otra cosa para comenzar fue EDA. Después de leer que es importante comprender la correlación entre las características, creamos una imagen de este tipo (se puede hacer clic en las imágenes de esta sección):
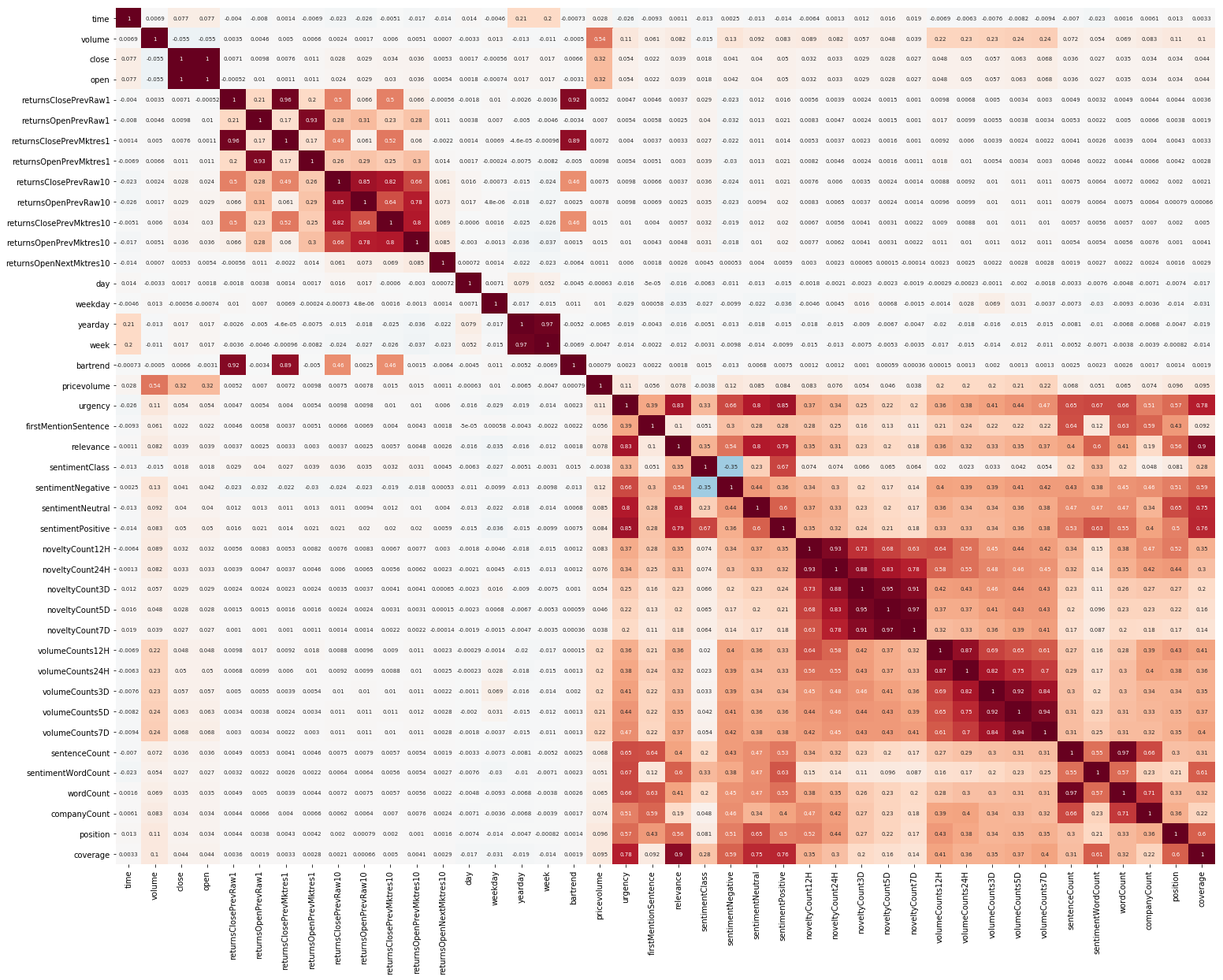
Aquí se ve claramente que la correlación por separado dentro del mercado y los datos de noticias es bastante alta, sin embargo, solo los valores de los rendimientos se correlacionan con el valor objetivo al menos de alguna manera. Dado que los datos representan una serie de tiempo, tiene sentido considerar también la autocorrelación del valor objetivo:
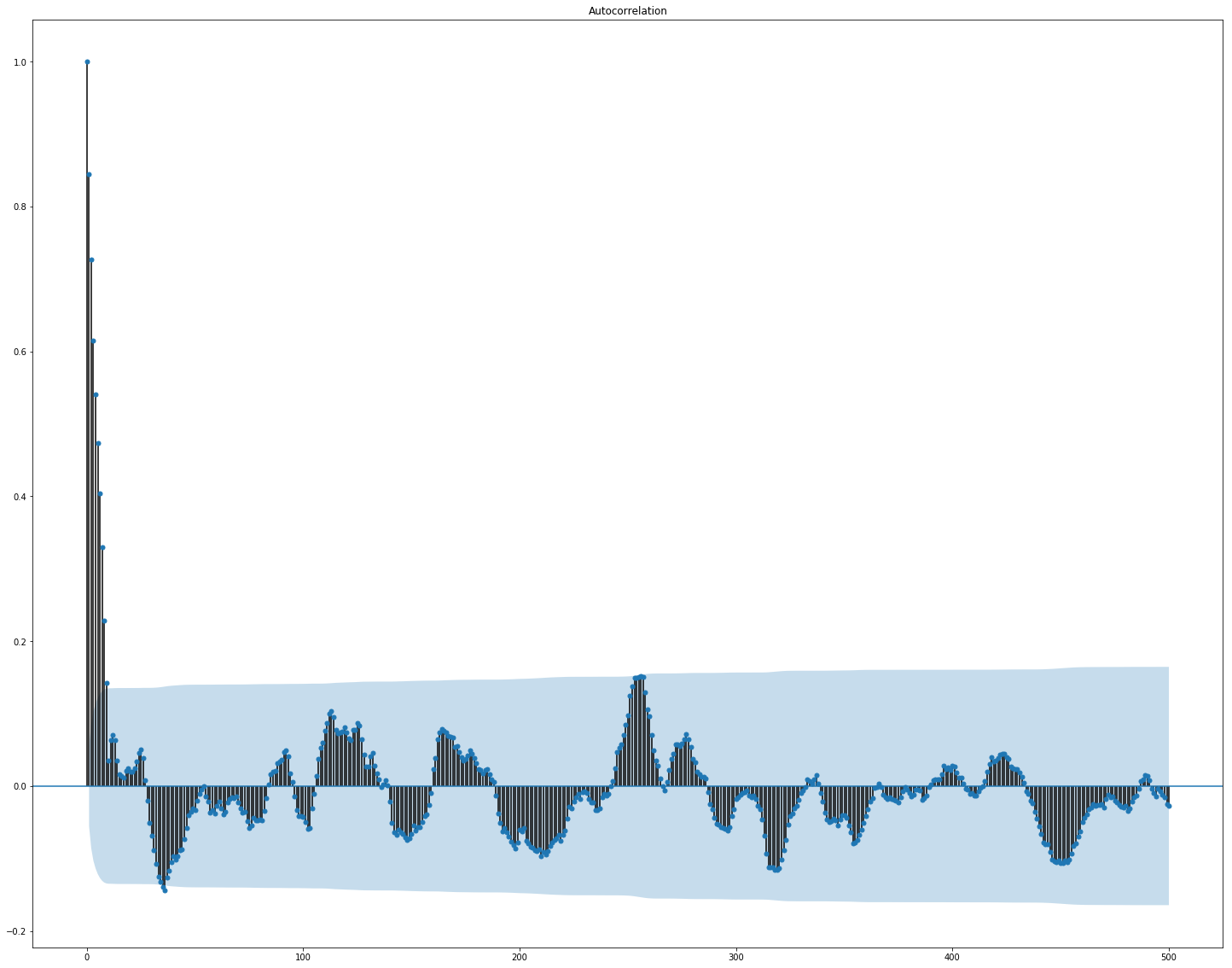
Se puede ver que después de un período de 10 días, la dependencia disminuye significativamente. Esto es probablemente lo que hace que GBM funcione bien, teniendo en cuenta solo las características con un retraso de 10 días (que ya están en el conjunto de datos original).
La selección de características y el preprocesamiento son cruciales para todos los algoritmos de ML. Intentemos utilizar formas automáticas para extraer características, a saber,
el análisis de componentes principales (
PCA ):
from sklearn.decomposition import PCA from sklearn.preprocessing import StandardScaler market_x = market_data.loc[:,features] scaler = StandardScaler() scaler.fit(market_x) market_x = scaler.transform(market_x) pca = PCA(.95) pca.fit(market_x) market_pca = pca.transform(market_x)
Veamos qué características genera la PCA:

Vemos que el método no funciona muy bien en nuestros datos, ya que la correlación final de las nuevas características con el valor objetivo es pequeña.
Ajuste fino y si es necesario
Muchos modelos de ML tienen una cantidad bastante grande de hiperparámetros, es decir, "configuraciones" del algoritmo mismo. Se pueden seleccionar manualmente, pero también hay mecanismos de selección automática. Para este último, hay una biblioteca de
hiperoptos que implementa dos algoritmos de coincidencia: búsqueda aleatoria y
estimador de Parzen estructurado en árbol (TPE) . Traté de optimizar:
- parámetros lightgbm (tipo de algoritmo, número de hojas, tasa de aprendizaje y otros),
- parámetros de modelos de redes neuronales (número de filtros TCN , número de bloques de memoria GRU , tasa de abandono, tasa de aprendizaje, tipo de solucionador).
Como resultado, todas las soluciones encontradas usando esta optimización dieron una puntuación más baja, aunque funcionaron mejor en los datos de la prueba. Probablemente, la razón radica en el hecho de que los datos para los cuales se considera el puntaje no son muy similares a los datos de validación seleccionados de la capacitación. Por lo tanto, para esta tarea, el ajuste fino no es muy adecuado, ya que conduce a la reentrenamiento del modelo.
Decisión final
De acuerdo con las reglas de la competencia, los participantes pueden elegir dos soluciones para la etapa final. Mis decisiones finales son casi las mismas y contienen un conjunto de dos modelos:
GBM y
GRU multicapa. La única diferencia es que una solución no usa datos de noticias en absoluto, y la otra los usa, sino solo para el modelo de red neuronal.
Solución de datos de noticias:
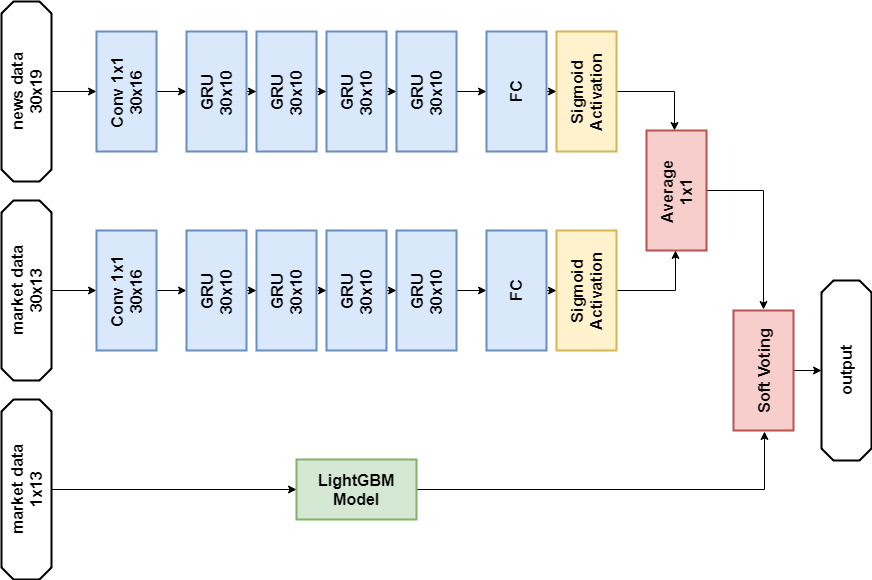
Importaciones import numpy as np import pandas as p import itertools import functools from kaggle.competitions import twosigmanews from sklearn.preprocessing import StandardScaler, LabelEncoder import tensorflow as tf from keras.models import Sequential, Model from keras.layers import Dense, GRU, LSTM, Conv1D, Reshape, Flatten, SpatialDropout1D, Lambda, Input, Average from keras.optimizers import Adam, SGD, RMSprop from keras import losses as ls from keras import activations as act import keras.backend as K import lightgbm as lgb
Preprocesamiento de datos Modelo de red neuronal def buildRNN(timesteps, features): i = Input(shape=(timesteps, features)) x1 = Lambda(lambda x: x[:,:,:13])(i) x1 = Conv1D(16,1, padding='valid')(x1) x1 = GRU(10, return_sequences=True)(x1) x1 = GRU(10, return_sequences=True)(x1) x1 = GRU(10, return_sequences=True)(x1) x1 = GRU(10)(x1) x1 = Dense(1, activation=act.sigmoid)(x1) x2 = Lambda(lambda x: x[:,:,13:])(i) x2 = Conv1D(16,1, padding='valid')(x2) x2 = GRU(10, return_sequences=True)(x2) x2 = GRU(10, return_sequences=True)(x2) x2 = GRU(10, return_sequences=True)(x2) x2 = GRU(10)(x2) x2 = Dense(1, activation=act.sigmoid)(x2) x = Average()([x1, x2]) model = Model(inputs=i, outputs=x) return model def train_model_time_series(model, data, val_data=None): print('Building model...') batch_size = 4096 optimizer = RMSprop()
Modelo GBM def train_model(data, val_data=None): print('Building model...') params = { "objective" : "binary", "metric" : "auc", "num_leaves" : 60, "max_depth": -1, "learning_rate" : 0.01, "bagging_fraction" : 0.9,
Entrenamiento n_timesteps = 30 market_data, news_data = cleanData(market_train_df, news_train_df) dates = market_data['time'].unique() train = range(len(dates))[:int(0.85*len(dates))] val = range(len(dates))[int(0.85*len(dates)):] train_data_prepared = prepareData(market_data.loc[market_data['time'].isin(dates[train])], news_data.loc[news_data['time'] <= max(dates[train])]) val_data_prepared = prepareData(market_data.loc[market_data['time'].isin(dates[val])], news_data.loc[news_data['time'] > max(dates[train])], scaler=train_data_prepared.scaler) model_gbm = train_model(train_data_prepared, val_data_prepared) train_data_ts = generateTimeSeries(train_data_prepared, n_timesteps=n_timesteps) val_data_ts = generateTimeSeries(val_data_prepared, n_timesteps=n_timesteps) rnn = buildRNN(train_data_ts.timesteps, train_data_ts.features) model_rnn = train_model_time_series(rnn, train_data_ts, val_data_ts)
Predicción def make_predictions(data, template, model): if(hasattr(data, 'gen')): prediction = (model.predict(data.gen(data.samples)) * 2 - 1)[:,-1] else: prediction = model.predict(data.x) * 2 - 1 predsdf = p.DataFrame({'ast':data.assets,'conf':prediction}) template['confidenceValue'][template['assetCode'].isin(predsdf.ast)] = predsdf['conf'].values return template day = 1 days_data = p.DataFrame({}) days_data_len = [] days_data_n = p.DataFrame({}) days_data_n_len = [] for (market_obs_df, news_obs_df, predictions_template_df) in env.get_prediction_days(): print(f'Predicting day {day}') days_data = p.concat([days_data, market_obs_df], ignore_index=True, copy=False, sort=False) days_data_len.append(len(market_obs_df)) days_data_n = p.concat([days_data_n, news_obs_df], ignore_index=True, copy=False, sort=False) days_data_n_len.append(len(news_obs_df)) data = prepareData(market_obs_df, news_obs_df, scaler=train_data_prepared.scaler) predictions_df = make_predictions(data, predictions_template_df.copy(), model_gbm) if(day >= n_timesteps): data = prepareData(days_data, days_data_n, scaler=train_data_prepared.scaler) data = generateTimeSeries(data, n_timesteps=n_timesteps) predictions_df_s = make_predictions(data, predictions_template_df.copy(), model_rnn) predictions_df['confidenceValue'] = (predictions_df['confidenceValue'] + predictions_df_s['confidenceValue']) / 2 days_data = days_data[days_data_len[0]:] days_data_n = days_data_n[days_data_n_len[0]:] days_data_len = days_data_len[1:] days_data_n_len = days_data_n_len[1:] env.predict(predictions_df) day += 1 env.write_submission_file()
Solución sin datos de noticias:

Código (solo un método diferente) def buildRNN(timesteps, features): i = Input(shape=(timesteps, features)) x1 = Lambda(lambda x: x[:,:,:13])(i) x1 = Conv1D(16,1, padding='valid')(x1) x1 = GRU(10, return_sequences=True)(x1) x1 = GRU(10, return_sequences=True)(x1) x1 = GRU(10, return_sequences=True)(x1) x1 = GRU(10)(x1) x1 = Dense(1, activation=act.sigmoid)(x1) model = Model(inputs=i, outputs=x1) return model
Ambas decisiones dieron un resultado similar (aproximadamente 0,69) en la primera etapa de la competencia, que correspondió a 566 de 2,927 lugares. Después del primer mes de nuevos datos, las posiciones en la lista de participantes se mezclaron, y la solución con datos de noticias se ubicó en el lugar 65 de los 697 equipos restantes con el resultado de 3.19251, y lo que sucederá en los próximos cinco meses, nadie lo sabe.
¿Qué más probé?
Métricas personalizadas
Dado que las decisiones se evalúan utilizando la relación de Sharpe, es lógico intentar utilizarla como una métrica para la finalización temprana del entrenamiento.
Métrica para lightgbm:
def sharpe_metric(y_pred, train_data): y_true = train_data.get_label() * 2 - 1 std = np.std(y_true * y_pred) mean = np.mean(y_true * y_pred) sharpe = np.divide(mean, std, out=np.zeros_like(mean), where=std!=0) return "sharpe", sharpe, True
La verificación mostró que dicha métrica funciona peor en este problema que AUC.
Mecanismo de atención
El mecanismo de atención permite que la red neuronal se centre en las características "más importantes" en los datos de origen. Técnicamente, la atención está representada por un vector de pesos (generalmente obtenido usando una capa completamente conectada con activación
softmax ), que se multiplica por la salida de otra capa. Utilicé una implementación en la que se aplica la atención al eje del tiempo:
def buildRNN(timesteps, features): def attention_3d_block(inputs): a = Permute((2, 1))(inputs) a = Dense(timesteps, activation=act.softmax)(a) a = Permute((2, 1))(a) mul = Multiply()([inputs, a]) return mul i = Input(shape=(timesteps, features)) x1 = Lambda(lambda x: x[:,:,:13])(i) x1 = Conv1D(16,1, padding='valid')(x1) x1 = GRU(10, return_sequences=True)(x1) x1 = attention_3d_block(x1) x1 = GRU(10, return_sequences=True)(x1) x1 = attention_3d_block(x1) x1 = GRU(10, return_sequences=True)(x1) x1 = attention_3d_block(x1) x1 = GRU(10)(x1) x1 = Dense(1, activation=act.sigmoid)(x1) model = Model(inputs=i, outputs=x1) return model
Este modelo se ve bastante bonito, pero este enfoque no dio un aumento en la puntuación, resultó ser de aproximadamente 0,67.
Lo que no tuvo tiempo de hacer
Varias áreas que parecen prometedoras:
Conclusiones
Nuestra aventura ha llegado a su fin, puedes intentar resumirla. La competencia resultó ser difícil, pero no pudimos enfrentar la suciedad. Esto sugiere que el umbral para ingresar al ML no es tan alto, pero, como en cualquier negocio, la magia real (y hay mucho en el aprendizaje automático) ya está disponible para los profesionales.
Resultados en números:
- El puntaje máximo en la primera etapa: ~ 0.69 contra ~ 1.5 en primer lugar. Algo así como el promedio del hospital, unos pocos superaron el valor de 0.7, el puntaje máximo de la decisión pública también fue ~ 0.69, un poco más que el mío.
- Lugar en la primera etapa: 566 de 2927.
- Puntuación en la segunda etapa: 3.19251 después del primer mes.
- Lugar en la segunda etapa: 65 de 697 después del primer mes.
Le llamo la atención sobre el hecho de que los números en la segunda etapa no hablan particularmente de nada, ya que todavía hay muy pocos datos para una evaluación cualitativa de las decisiones.
Referencias
La solución final usando noticiasTwo Sigma: Uso de noticias para predecir movimientos de acciones - Página del concurso
Keras -
Marco de red neuronal
LightGBM - Marco GBM
Scikit-learn - biblioteca de algoritmos de aprendizaje automático
Hyperopt - biblioteca para optimizar hiperparámetros
Artículo sobre WaveNet