Mientras trabajamos en el informe anual de este año, hemos decidido evitar volver a contar los titulares de las noticias del año anterior y, aunque es casi imposible ignorar absolutamente los recuerdos, queremos compartir con ustedes el resultado de un pensamiento claro y una visión estratégica para El punto donde todos vamos a llegar en el momento más cercano: el presente.
Dejando atrás las palabras de introducción, aquí están nuestros hallazgos clave:
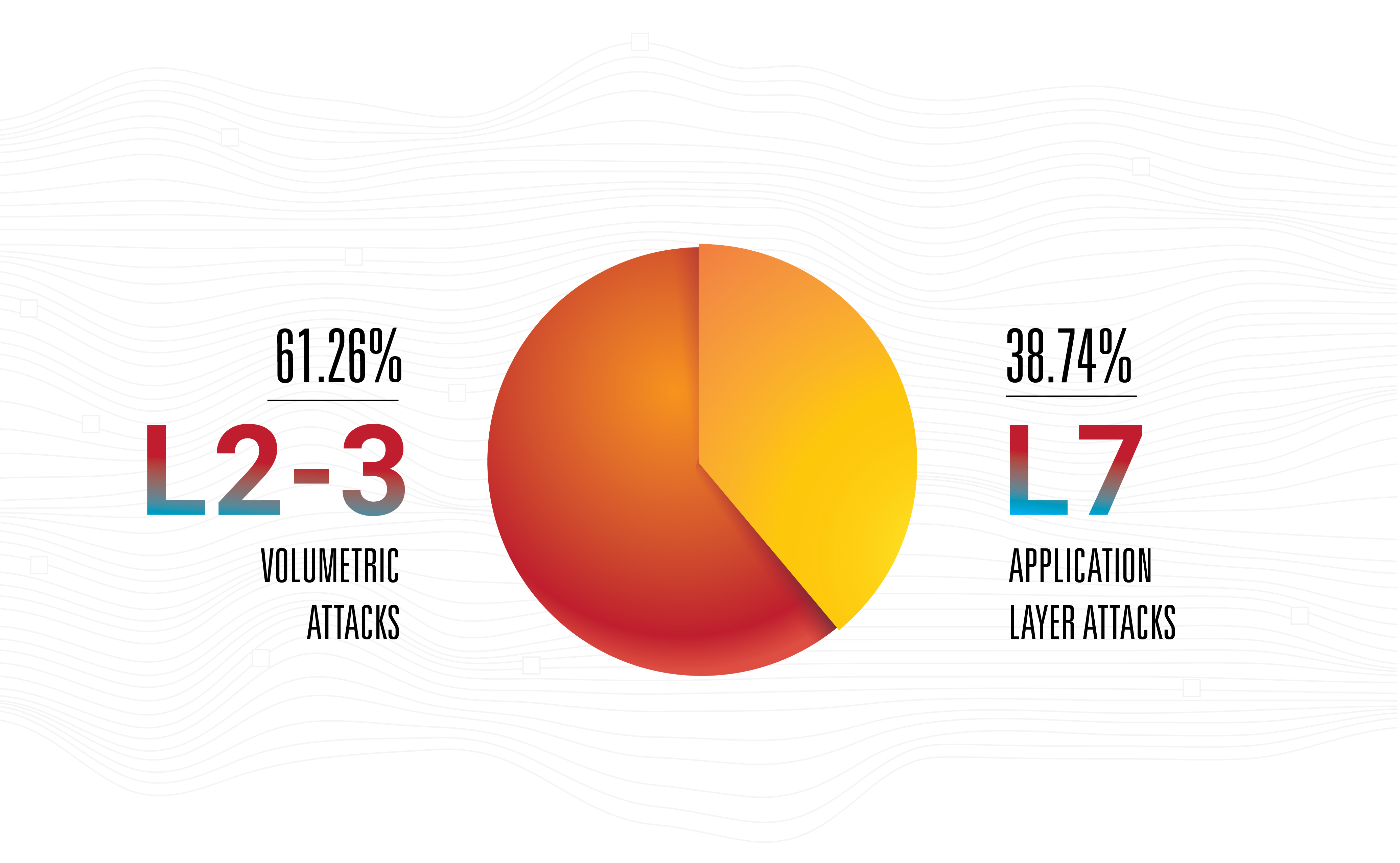
- La duración promedio del ataque DDoS se redujo a 2.5 horas;
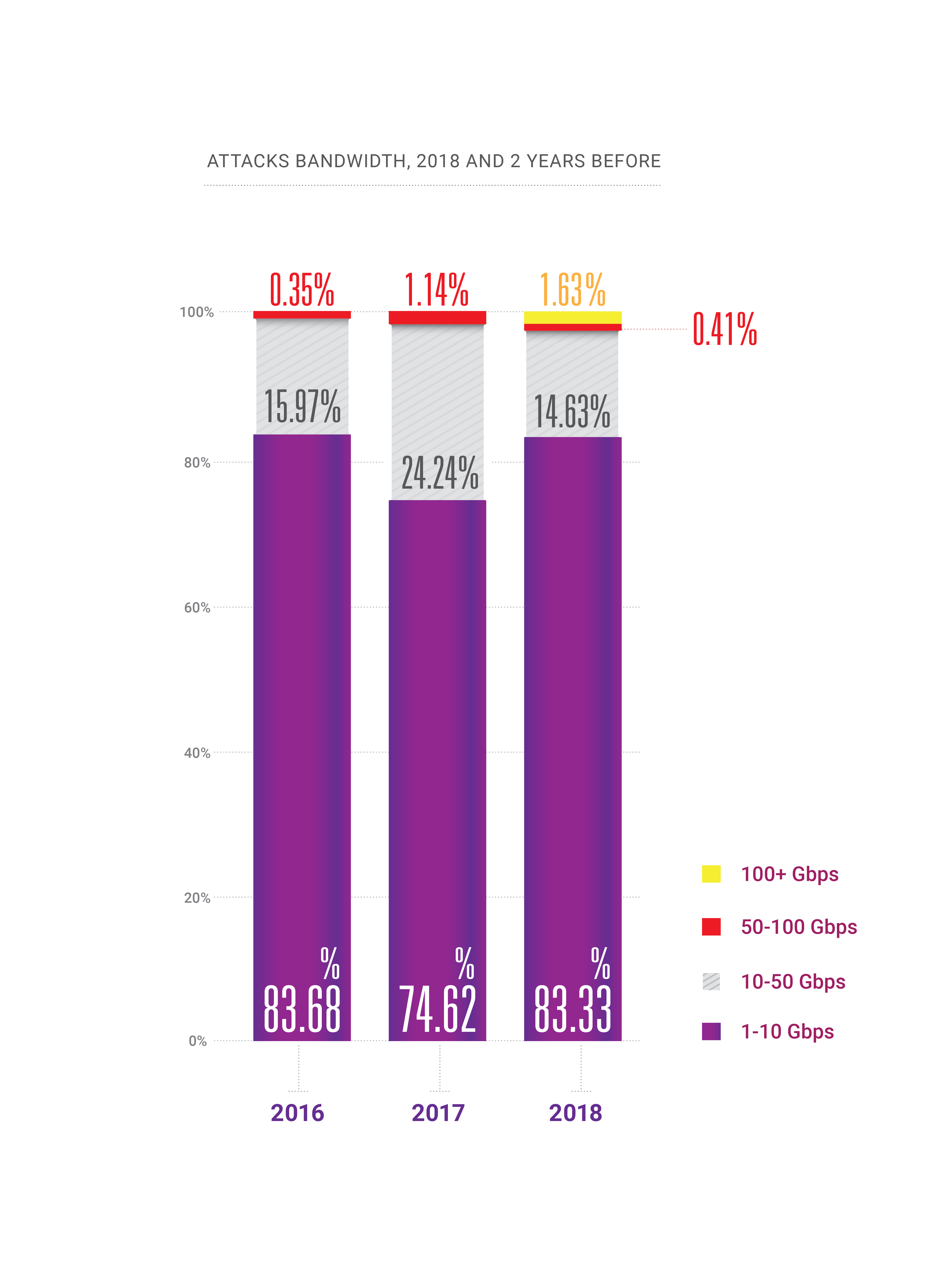
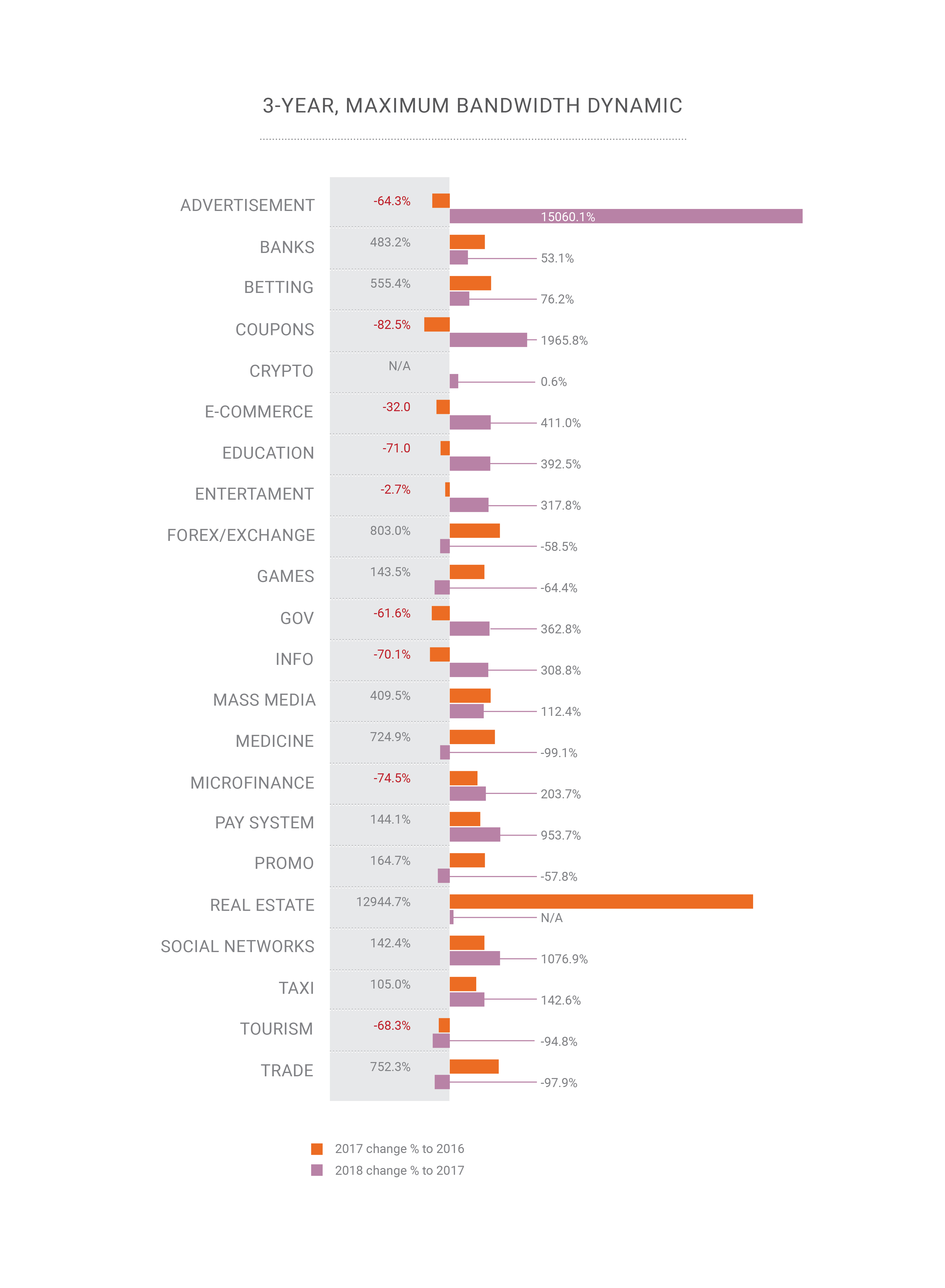
- Durante 2018, apareció la capacidad de ataques a cientos de gigabits por segundo dentro de un país o región, llevándonos al borde de la "teoría cuántica de la relatividad del ancho de banda";
- La frecuencia de los ataques DDoS continúa creciendo;
- El crecimiento continuo de los ataques habilitados con HTTPS (SSL);
- La PC está muerta: la mayor parte del tráfico legítimo actual proviene de los teléfonos inteligentes, lo cual es un desafío para los actores de DDoS hoy y sería el próximo desafío para las compañías de mitigación de DDoS;
- BGP finalmente se convirtió en un vector de ataque, 2 años después de lo que esperábamos;
- La manipulación de DNS se ha convertido en el vector de ataque más dañino;
- Otros nuevos vectores de amplificación son posibles, como memcached & CoAP;
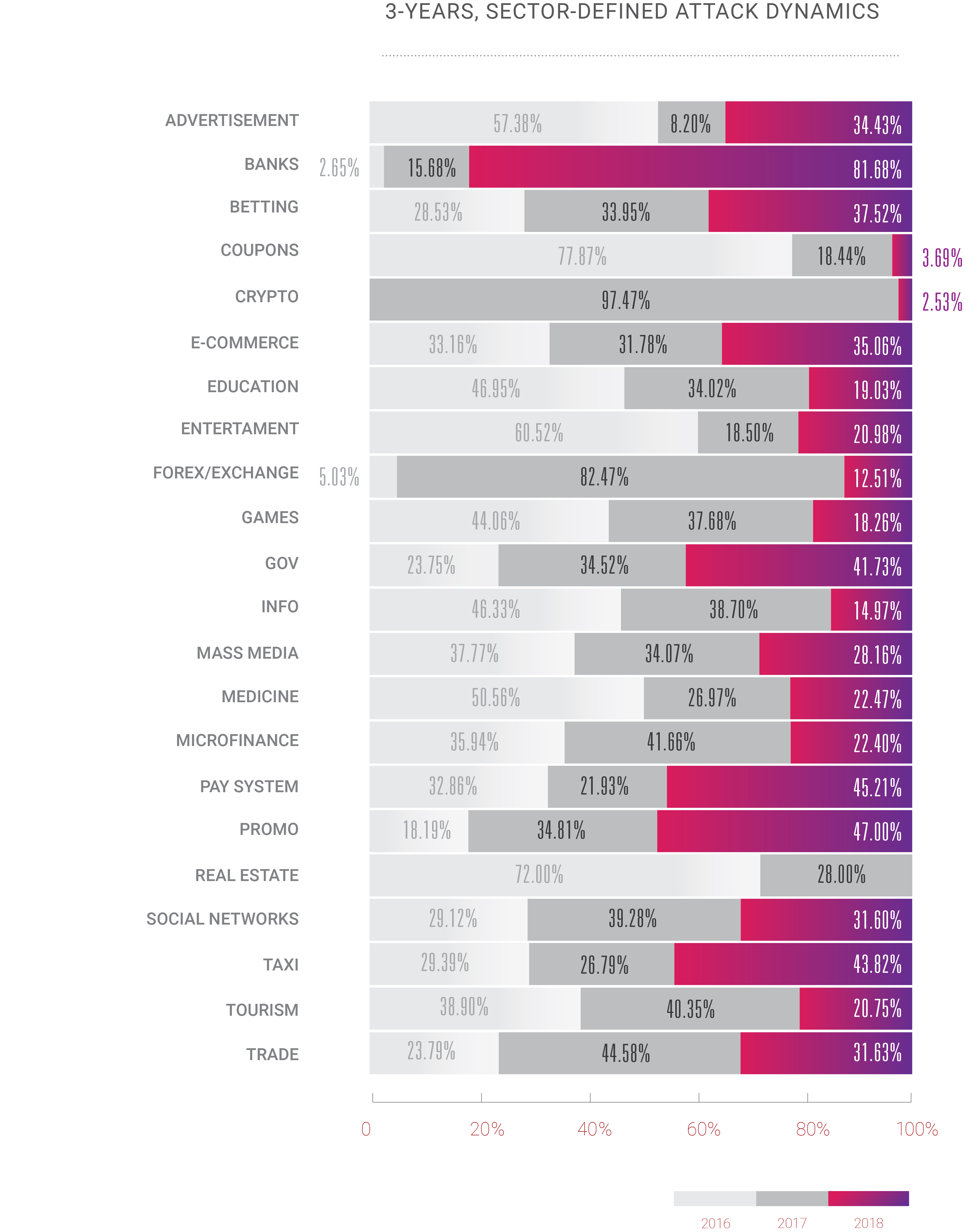
- No hay más "industrias seguras" que sean invulnerables a los ataques cibernéticos de ningún tipo.
En este artículo, hemos tratado de seleccionar todas las partes más interesantes de nuestro informe, aunque si desea leer la versión completa en inglés, el
PDF está disponible .
Retrospectiva
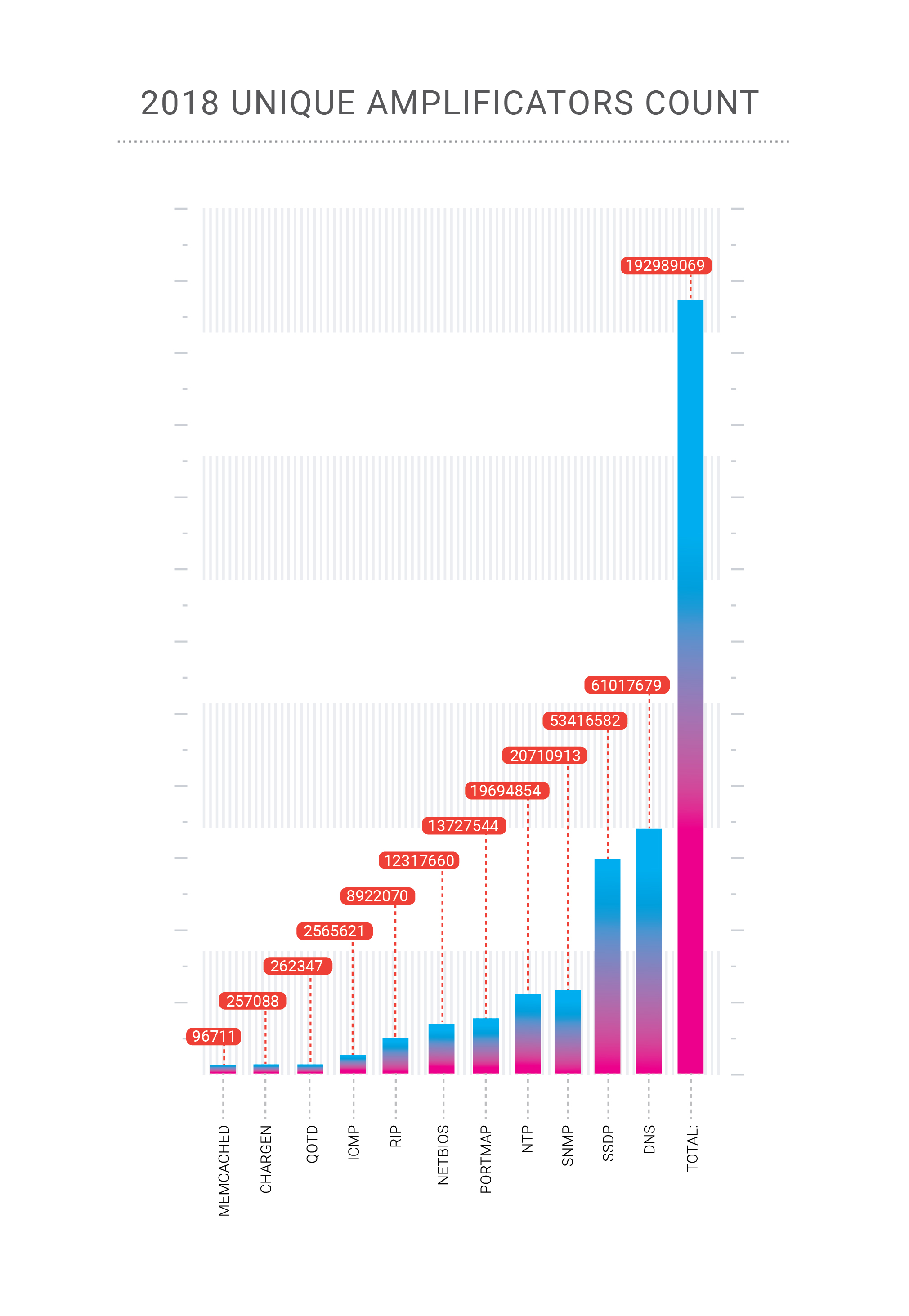
En 2018, nuestra compañía "celebró" dos ataques récord en su red. Los ataques de amplificación Memcached, que describimos en detalle a fines de febrero de 2018, alcanzaron los 500 Gbps en el caso de la plataforma de pago Qiwi, un cliente de Qrator Labs. Luego, a fines de octubre, recibimos un ataque de amplificación de DNS altamente concentrado en uno de nuestros clientes dentro de la Federación de Rusia.
La amplificación de DNS es un viejo y conocido vector de ataque DDoS que es principalmente volumétrico y plantea dos problemas. En caso de un ataque de cientos de gigabits por segundo, existe una alta probabilidad de sobrecargar nuestro canal ascendente. ¿Cómo luchar contra esto? Obviamente, tenemos que repartir esa carga entre muchos canales, lo que lleva al segundo problema: latencia adicional que resulta de cambiar el flujo de tráfico a nuestro punto de procesamiento. Afortunadamente, mitigamos con éxito ese ataque en particular con solo equilibrio de carga.
Aquí es donde el equilibrio de carga flexible demuestra su verdadero valor, y dado que Qrator Labs administra una red BGP de difusión ilimitada, Radar está modelando la propagación del tráfico a través de nuestra red después de ajustar el equilibrio de carga. BGP es un protocolo de vector de distancia, y conocemos esos estados porque el gráfico de distancia permanece estático. Analizando esas distancias y considerando los LCP y la ruta múltiple de igual costo, podemos estimar la ruta AS_ del punto A al punto B con alta confianza.
Esto no quiere decir que la amplificación sea la amenaza más peligrosa: no, los ataques de la capa de aplicación siguen siendo los más efectivos, vanguardistas e invisibles, ya que la mayoría de ellos tienen poco ancho de banda.
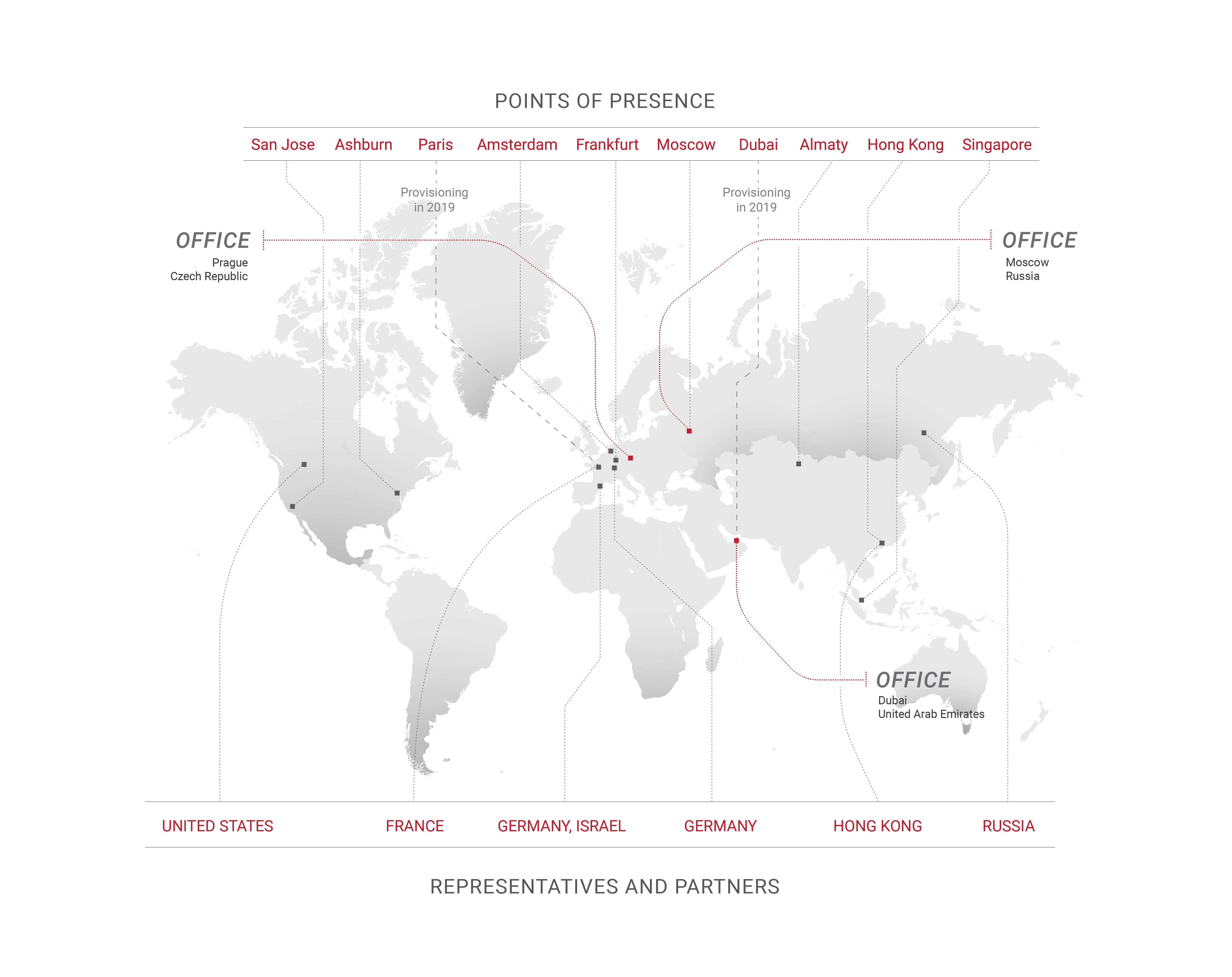
Esta es la razón principal por la que Qrator Labs actualiza las conexiones con los operadores en función de los puntos de presencia, al tiempo que amplía las áreas de presencia también. Ese es un paso natural para cualquier operador de red en estos días, suponiendo que sus números estén creciendo. Sin embargo, desde la perspectiva de los atacantes, creemos que es común recolectar una botnet mediocre y solo luego centrarnos en buscar la gama más amplia de amplificadores disponibles para atacar con todas las armas posibles, a la tasa de recarga más alta posible. Los ataques híbridos están aquí, creciendo en ancho de banda, velocidad de paquetes y frecuencia.
Las botnets evolucionaron significativamente en 2018 y sus maestros encontraron un nuevo trabajo para ellos: el fraude de clics. Con el auge del aprendizaje automático y los motores de navegador sin cabeza, el fraude de clics se volvió mucho más fácil de lograr que hace solo un par de años.
Un sitio web promedio de hoy recibe alrededor del 50% al 65% de su tráfico desde dispositivos móviles, navegadores de teléfonos inteligentes y aplicaciones. Para algunos servicios web, esta cifra es cercana al 90% o 100%, mientras que un sitio web solo para escritorio hoy en día es algo raro que se encuentra principalmente en entornos empresariales o en algunos casos límite.
La PC está básicamente muerta en 2019, lo que hace que algunos de los enfoques habituales, como el seguimiento del movimiento del mouse, sean completamente inútiles para el rastreo y filtrado de bots. De hecho, no solo la PC (con todas las computadoras portátiles brillantes y las máquinas de escritorio todo en uno) rara vez es una fuente de tráfico compartido importante con ciertos sitios web, sino que a menudo se está convirtiendo en un simple delincuente. A veces, solo negar el acceso a lo que no sea un navegador de teléfono inteligente adecuado es suficiente para mitigar un ataque de botnet que causa al mismo tiempo un impacto negativo nulo en los indicadores clave de rendimiento empresarial.
Los autores de botnets se utilizan para implementar o imitar el comportamiento de los navegadores de escritorio en su código malicioso, del mismo modo que los propietarios de sitios web creen que los navegadores de PC realmente importan. Este último ha cambiado recientemente, por lo que dentro de unos años, también debería ocurrir un cambio en el primero.
Ya dijimos que nada cambió significativamente durante 2018, pero el cambio y el progreso mantuvieron un ritmo constante. Uno de los ejemplos más significativos es el aprendizaje automático, donde las mejoras fueron especialmente evidentes, particularmente en el área de las redes adversas generativas. Lenta pero constantemente, ML está llegando al mercado de masas. El mundo del aprendizaje automático se ha vuelto más accesible y, a finales de año, ya no se limita a los académicos.
Esperábamos ver los primeros ataques DDoS basados en ML (o relacionados) para principios de 2019, pero aún no ha sucedido. Esperamos tal desarrollo debido al bajo costo de los datos generados por ML en este momento, pero aparentemente no es lo suficientemente bajo.
Si piensa en el estado actual de la industria "humana automatizada", poner la neuro-red encima de eso no es una mala idea. Dicha red aprendería el comportamiento humano real en el contexto de la gestión de los contenidos de la página web. Eso es algo que todos llamarían "experiencia de usuario de IA" y, por supuesto, una red de este tipo equipada con un motor de navegador podría producir un arsenal muy interesante para ambos lados, ofensiva y defensa.
Claro, enseñar la red es costoso, pero distribuir y externalizar dicho sistema podría ser muy asequible y, posiblemente, gratuito, especialmente si se considera malware, aplicaciones pirateadas, etc. Potencialmente, dicho cambio podría afectar a toda la industria, de la misma manera que las GAN transformaron lo que pensamos de "realidad visual" y "confiabilidad".
Dado que esta es también una carrera entre los motores de búsqueda con Google en primer lugar y todos los demás que intentan aplicar ingeniería inversa a los algoritmos, podría llegar a una situación en la que un bot no imitaría a un ser humano al azar, sino a una persona específica, como la que generalmente sentado detrás de una computadora vulnerable seleccionada. Las versiones de Captcha y Recaptcha podrían servir como ejemplos de cómo los atacantes mejoran sus herramientas y técnicas de ataque.
Después de memcached, se habló mucho sobre la posibilidad de una nueva clase de arma de ataque DDoS: una vulnerabilidad, bot, servicio comprometido, algo que podría enviar eternamente datos particulares a una dirección específica elegida por el atacante. Un comando del atacante podría liberar un flujo continuo de tráfico continuo, como syslog o una inundación masiva. Eso es solo una teoría. No podemos decir si tales servidores o dispositivos existen realmente, pero si lo hacen, sería un eufemismo decir que podrían representar un arma extremadamente peligrosa en las manos equivocadas.
En 2018, también vimos un mayor interés en la gobernanza de Internet y los servicios asociados de todo tipo de gobiernos y organizaciones sin fines de lucro de todo el mundo. Vemos esto como un desarrollo neutral hasta el punto en que las libertades fundamentales podrían ser suprimidas, lo que esperamos no suceda, especialmente en las naciones desarrolladas.
Después de años de recopilar y analizar el tráfico de ataque a nivel mundial, Qrator Labs ahora está implementando el primer bloque de solicitud. Los modelos que utilizamos para predecir el comportamiento malicioso nos permiten determinar con gran confianza si un usuario es legítimo o no. Nos adherimos a nuestra filosofía central de experiencia de usuario ininterrumpida, sin desafíos de JavaScript o captchas y en 2019, esperamos lograr la capacidad de bloquear la primera solicitud maliciosa para que no infrinja nuestras defensas.
Mellanox
Elegimos los interruptores 100G Mellanox como resultado de nuestras pruebas internas en años anteriores. Todavía seleccionamos equipos que satisfagan nuestras necesidades en situaciones específicas. En primer lugar, los conmutadores no deberían descartar ningún paquete pequeño mientras trabajan a velocidad de línea; no puede haber ninguna degradación en absoluto. En segundo lugar, nos gustó el precio. Sin embargo, eso no es todo. El costo siempre se justifica por la forma en que el vendedor reacciona a sus especificaciones.
Los conmutadores Mellanox funcionan bajo Switchdev, convirtiendo sus puertos en interfaces Linux normales. Al ser parte del núcleo principal de Linux, Switchdev se describe en la documentación como "un modelo de controlador en el núcleo para dispositivos de conmutación que descargan el plano de datos de reenvío desde el núcleo". Este enfoque es muy conveniente, ya que todas las herramientas que hemos usado están disponibles en una API que es extremadamente natural para cada programador, desarrollador e ingeniero de redes moderno. Cualquier programa que use la API de red estándar de Linux puede ejecutarse en el conmutador. Todas las herramientas de monitoreo y control de red creadas para servidores Linux, incluidas las caseras, están disponibles. Por ejemplo, implementar cambios en la tabla de rutas es mucho más cómodo en comparación con cómo se hizo antes de Switchdev. Hasta el nivel del chip de red, todo el código es visible y transparente, lo que permite aprender y realizar modificaciones, hasta el momento específico en que debe saber exactamente cómo está construido el chip, o al menos la interfaz externa.
Un dispositivo Mellanox bajo el control Switchdev es la combinación que encontramos más adecuada para nuestras necesidades, ya que la compañía brinda soporte completo para el sistema operativo de código abierto ya robusto.
Mientras probamos el equipo antes de ejecutarlo en producción, descubrimos que se eliminó parte del tráfico reenviado. Nuestra investigación mostró que fue causada por el tráfico en una interfaz enrutada a través del procesador de control, que por supuesto no podía manejar grandes volúmenes. No sabíamos la causa exacta de tal comportamiento, pero supusimos que estaba relacionado con el manejo de redireccionamientos ICMP. Mellanox confirmó la causa del problema y les pedimos que hicieran algo al respecto. Mellanox reaccionó rápidamente, brindándonos una solución de trabajo a corto plazo.
¡Buen trabajo, Mellanox!
Protocolos y código abierto
DNS-over-HTTPS es una tecnología más compleja que DNS-over-TLS. Vemos que la primera florece y la segunda se olvida lentamente. Es un claro ejemplo donde "más complejo" significa "más eficiente", ya que el tráfico DoH es indistinguible de cualquier otro HTTPS. Ya vimos esto con la integración de datos RPKI, cuando inicialmente se posicionó como una solución anti-secuestro y no terminó bien, pero luego reapareció como un arma poderosa contra errores como fugas estáticas y configuraciones de enrutamiento incorrectas. El ruido se transformó en señal y ahora RPKI es compatible con los IX más grandes, lo cual es una excelente noticia.
TLS 1.3 ha llegado. Qrator Labs, así como la industria de TI en general, observaron de cerca el proceso de desarrollo desde el borrador inicial hasta cada etapa dentro de IETF para convertirse en un protocolo comprensible y manejable que estamos listos para respaldar en 2019. El respaldo ya es evidente en el mercado, y queremos mantener el ritmo en la implementación de este protocolo de seguridad robusto y comprobado. No sabemos cómo los productores de hardware de mitigación de DDoS se adaptarán a las realidades de TLS 1.3, pero, debido a la complejidad técnica del soporte de protocolo, podría llevarles algún tiempo.
Estamos siguiendo HTTP / 2 también. Por ahora, Qrator Labs no admite la versión más reciente del protocolo HTTP, debido a la base de código existente en torno a este protocolo. Los errores y vulnerabilidades aún se encuentran con bastante frecuencia en el nuevo código; Como proveedor de servicios de seguridad, todavía no estamos listos para admitir dicho protocolo bajo el acuerdo de nivel de servicio que estamos de acuerdo con nuestros consumidores.
La verdadera pregunta de 2018 para Qrator Labs fue: “¿Por qué la gente quiere tanto HTTP / 2? Y fue objeto de acalorados debates durante todo el año. La gente todavía tiende a pensar en el dígito "2" como la versión "más rápida, más fuerte, mejor", lo cual no es necesariamente el caso en todos los aspectos de ese protocolo en particular. Sin embargo, DoH recomienda HTTP / 2 y aquí es donde ambos protocolos pueden tener mucho impulso.
Una preocupación sobre el desarrollo de las suites y características de protocolo de próxima generación es que generalmente depende en gran medida de la investigación académica, y el estado de eso para la industria de mitigación de DDoS es bastante pobre. La Sección 4.4 del borrador de IETF “Capacidad de administración de QUIC”, que es parte del futuro conjunto de protocolos QUIC, podría verse como un ejemplo perfecto de eso: establece que “las prácticas actuales en la detección y mitigación de [ataques DDoS] generalmente implican pasividad medición utilizando datos de flujo de red ", siendo este último muy raramente un caso en entornos empresariales de la vida real (y solo en parte para configuraciones de ISP), y de ninguna manera difícilmente es un" caso general "en la práctica, pero definitivamente es un caso general en trabajos de investigación académica que, la mayoría de las veces, no están respaldados por implementaciones adecuadas y pruebas del mundo real contra toda la gama de posibles ataques DDoS, incluidos los de la capa de aplicación (que, debido al progreso en el despliegue mundial de TLS, obviamente nunca podría manejarse con cualquier tipo de medida pasiva). Establecer una tendencia de investigación académica adecuada es otro desafío para los operadores de mitigación de DDoS en 2019.
Switchdev cumplió plenamente las expectativas que expresamos hace un año. Esperamos que el trabajo continuo para mejorar Switchdev se fortalezca en los próximos años, ya que la comunidad es fuerte y está creciendo.
Qrator Labs continúa con la habilitación de Linux XDP para ayudar a aumentar aún más la eficiencia del procesamiento de paquetes. La descarga de algunos patrones de filtración de tráfico malicioso de la CPU a la NIC, e incluso al conmutador de red, parece bastante prometedora, y esperamos continuar nuestra investigación y desarrollo en esta área.
Inmersión profunda con bots
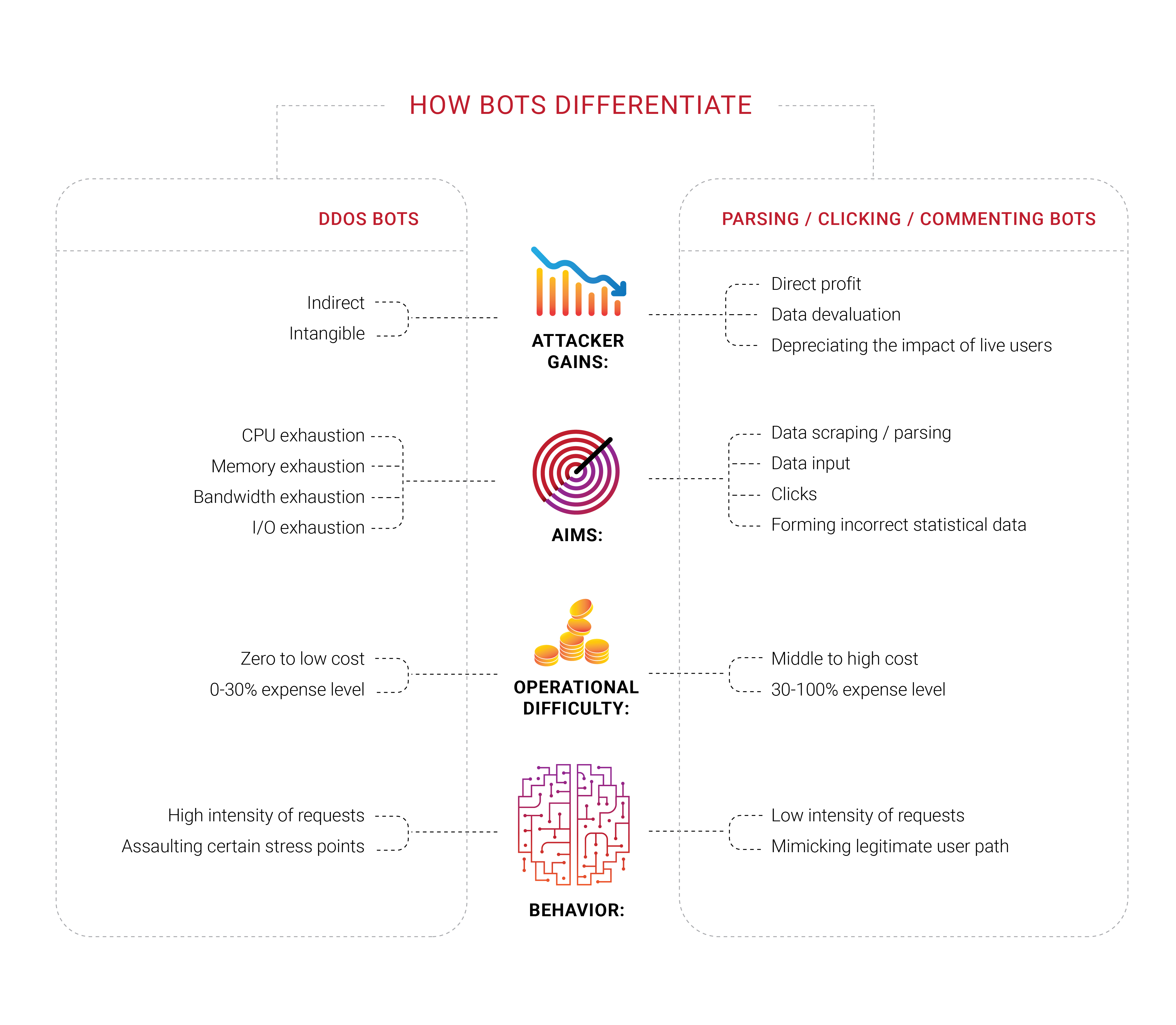
Muchas compañías buscan protección contra bots, y no es sorprendente que hayamos grupos trabajando en diferentes áreas de ese campo en 2018. Lo que nos pareció interesante es que una gran parte de estas compañías nunca experimentó un ataque DDoS dirigido, al menos una negación típica de intento de servicio para drenar recursos finitos como el ancho de banda o la capacidad de la CPU. Se sienten amenazados por los bots, pero no pueden distinguirlos de los usuarios reales ni determinar qué están haciendo realmente. Solo saben que quieren deshacerse de los bots percibidos.
Los problemas con los robots y los rascadores también tienen un componente económico importante. Si el 30% del tráfico es ilegítimo y se origina en la máquina, se desperdicia el 30% de los costos de soportar ese tráfico. Hoy, esto puede verse como un impuesto inevitable adicional en las empresas de Internet. Es difícil disminuir el número exactamente a cero, pero los dueños de negocios preferirían verlo lo más bajo posible.
La identificación se convierte en un problema importante en Internet hoy en día, ya que los mejores robots ya no tienen que imitar a los seres humanos: ocupan el mismo espacio, como los parásitos. Hemos estado repitiendo durante algún tiempo que cualquier información disponible públicamente, sin autorización o autenticación, es y terminaría como propiedad común; nadie podría evitar eso.
En 2018 nos concentramos en problemas de identidad y gestión de bots. Sin embargo, el alcance más amplio aquí es diferente; Vivimos en una era en la que no hay una forma exacta de saber la razón por la que un cliente solicita la respuesta del servidor. Lo has leído bien: en última instancia, todas las empresas quieren que un cliente compre algo, esa es la razón de existir y el objetivo, por lo que algunas empresas quieren profundizar en quién solicita qué al servidor, si hay una persona real detrás.
No es de extrañar que los dueños de negocios a menudo aprendan de los técnicos que una parte significativa del tráfico de su sitio web es originada por bots, no por clientes.
Los humanos automatizados que mencionamos anteriormente también podrían apuntar a algún recurso de red específico con un complemento de navegador instalado, y creemos que la mayoría de esas extensiones se instalan a propósito, para perseguir un objetivo específico, conocido solo por los creadores de esas redes. Fraude de clics, manipulación de anuncios, análisis: tales tareas se realizan de manera eficiente con la ayuda de seres humanos reales en el punto donde falla la automatización. Solo imagine cómo cambiaría la situación si el aprendizaje automático se aplicara al eslabón correcto de la cadena.
Los analizadores y raspadores, que son parte del problema más amplio de los bots, se convirtieron en un problema en el que nos sumergimos durante 2018, en primer lugar gracias a nuestros clientes, que se acercaron a nosotros con sus experiencias y nos dieron la opción de investigar más a fondo qué estaba sucediendo con sus recursos. Es posible que tales robots ni siquiera se registren en métricas típicas, como el ancho de banda o la carga de la CPU del servidor. Actualmente estamos probando una variedad de enfoques, pero en última instancia está claro lo que los clientes necesitan: bloquear a estos intrusos en su primera solicitud.
Durante la epidemia de raspado que vimos en Rusia y la CEI, quedó claro que los bots involucrados son capaces de cifrar. Una solicitud por minuto es una tasa que fácilmente podría pasar desapercibida sin un análisis de solicitud del tráfico entrante. En nuestra humilde opinión, el cliente debe decidir el siguiente paso después de obtener nuestro análisis y marcado. Ya sea para bloquearlos, dejarlos pasar o engañarlos (engañarlos), no nos corresponde a nosotros decidir.

Sin embargo, existen ciertos problemas con automatizaciones puras, o "bots", como estamos acostumbrados a llamarlos. Si está seguro de que el bot malicioso generó una solicitud específica, lo primero que la mayoría decide hacer es bloquearlo, sin enviar ninguna respuesta del servidor. Hemos llegado a la conclusión de que esto no tiene sentido porque tales acciones solo dan más retroalimentación a la automatización, lo que le permite adaptarse y encontrar una solución alternativa. A menos que los bots estén intentando un ataque de denegación de servicio, recomendamos no bloquear tales automatizaciones de inmediato, ya que el resultado de tales juegos de gato y ratón no podría ser más que una gran pérdida de tiempo y esfuerzo.
Esta es la razón principal por la que Qrator Labs elige marcar el tráfico sospechoso y / o malicioso y dejar la decisión sobre los próximos pasos al propietario del recurso teniendo en cuenta su audiencia, servicio y objetivos comerciales. Un ejemplo de ello es la extensión del navegador de bloqueo de anuncios. La mayoría de los anuncios son scripts y al bloquear scripts no necesariamente está bloqueando anuncios y podría bloquear algo más, como un desafío de JavaScript. Es fácil imaginar cómo esto podría escalar, resultando en la pérdida de ingresos para un importante grupo de negocios en Internet.
Cuando los atacantes son bloqueados y reciben la retroalimentación que necesitan, pueden adaptarse rápidamente, aprender y atacar nuevamente. Las tecnologías de Qrator Labs se basan en la filosofía simple de que a la automatización no se le puede dar ninguna retroalimentación que puedan usar: no debe bloquearlas ni pasarlas, solo marcarlas. Después de hacer tales marcas, debe considerar su objetivo real: ¿qué quieren? y ¿Por qué están visitando ese recurso específico o página web? ¿Tal vez podrías alterar ligeramente el contenido de la página web de una manera que ningún humano sentiría la diferencia, pero la realidad del bot se volvería al revés? Si son analizadores, podrían obtener información de análisis engañosa en forma de datos incorrectos.
Mientras discutíamos esos problemas a lo largo de 2018, etiquetamos tales ataques como el ataque directo de métricas comerciales. Su sitio web y servidores pueden parecer correctos, sin quejas de los usuarios, pero siente que algo cambia ... como el precio de CPA de un anuncio que toma de alguna plataforma programática lentamente, pero que dirige constantemente a los anunciantes a otros lugares.
Matar el incentivo de los atacantes es la única forma de contrarrestar eso. Intentar detener los bots solo da como resultado una pérdida de tiempo y dinero. Si hacen clic en algo de lo que se beneficia, haga que esos clics sean ineficientes; si lo analizan, proporcione información poco confiable que no distinguirán de datos legítimos y confiables.
Clickhouse
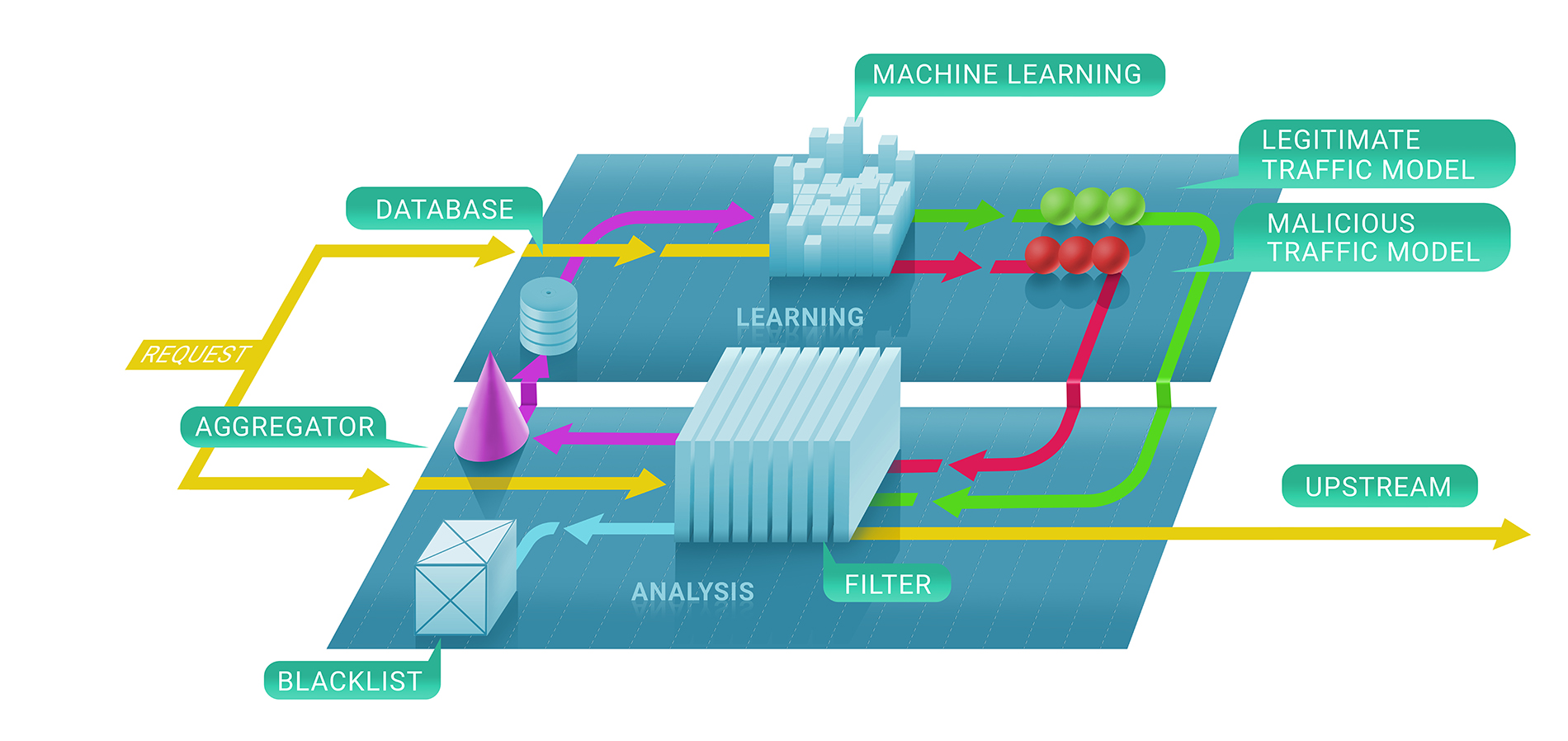
En general, el servicio de filtrado de Qrator Labs implica dos etapas: primero, evaluamos inmediatamente si una solicitud es maliciosa con la ayuda de comprobaciones sin estado y con estado, y, en segundo lugar, decidimos si mantener o no la fuente en la lista negra y durante cuánto tiempo. La lista negra resultante podría representarse como la lista de direcciones IP únicas.
En la primera etapa de este proceso, alistamos técnicas de aprendizaje automático para comprender mejor el flujo natural del tráfico para un recurso dado, ya que parametrizamos el servicio para cada cliente individualmente en función de los datos que recopilamos.
Ahí es donde entra Clickhouse. Para comprender con precisión por qué se le prohibió a una dirección IP comunicarse con un recurso, debemos seguir el modelo de aprendizaje automático de Clickhouse DB. Funciona muy rápido con grandes fragmentos de datos (considere un ataque DDoS de 500 Gbps, continuando durante algunas horas entre pausas), y los almacena de una manera que es naturalmente compatible con los marcos de aprendizaje automático que usamos en Qrator Labs. Más registros y más tráfico de ataques conducen a resultados mejores y más robustos de nuestros modelos para usar en el perfeccionamiento del servicio en tiempo real, bajo los ataques más peligrosos.
Usamos el DB de Clickhouse para almacenar todos los registros de tráfico de ataques (ilegítimos) y patrones de comportamiento de bot. Implementamos esta solución específica porque prometía una capacidad impresionante para procesar conjuntos de datos masivos en un estilo de base de datos, rápido. Utilizamos estos datos para el análisis y para construir los patrones que usamos en el filtrado DDoS y para aplicar el aprendizaje automático para mejorar los algoritmos de filtrado.
Una ventaja significativa de Clickhouse, en comparación con otras bases de datos, es que no lee toda la cadena de datos; podría tomar solo el segmento necesario, mucho más pequeño, si está almacenando todo según las pautas.
Conclusión

Durante bastante tiempo, hemos estado viviendo con ataques multifactoriales que exploran múltiples protocolos de ataque para hacer que un objetivo no esté disponible.
La higiene digital y las medidas de seguridad actualizadas deberían y de hecho podrían cubrir el 99% de los riesgos reales que una entidad individual probablemente enfrentará, excepto en casos extremos o específicos, y evitar que un servicio de internet "promedio" experimente problemas.
Por otro lado, los ataques DDoS son capaces de cortar la conexión a Internet de cualquier país del mundo, aunque solo unos pocos podrían ser atacados de manera externa. Ese no es el caso en el BGP, donde es posible cerrar solo una serie de puntos en cualquier mapa que desee dibujar.
El conocimiento de la seguridad de la red continúa creciendo, lo cual es excelente. Sin embargo, una vez que miras los números vinculados a los amplificadores en las redes u opciones para engañar a alguien más, ¡no están bajando! Esto se debe a que cada año la cantidad de tiempo que los estudiantes pasan en la escuela de seguridad de Internet, es decir, las personas que comienzan a preocuparse por cómo escriben código y crean sus aplicaciones, no coincide con la cantidad de tiempo necesaria para garantizar que no estén creando vulnerabilidades que permitir que alguien use dichos recursos para organizar un ataque DDoS exitoso, o algo peor.
Uno de los hallazgos más significativos de 2018 fue que la mayoría de las personas todavía esperan mucho más de la tecnología de lo que se puede ofrecer actualmente. No siempre fue así, pero en este momento vemos una fuerte tendencia a preguntar demasiado, independientemente de las características del software o hardware. La gente sigue esperando más, lo que probablemente no cambiará debido a las promesas hechas en las campañas de marketing. Sin embargo, la gente está comprando esas promesas, y las compañías sienten que deberían trabajar para cumplirlas.
Tal vez, esa es la naturaleza del progreso y la evolución. En estos días, las personas se sienten frustradas y decepcionadas por no tener lo que estaban "garantizados" y por lo que pagaron. Entonces, aquí es donde se originan los problemas actuales, donde no podemos comprar "completamente" un dispositivo y todo su software que hará lo que queremos, o donde los servicios "gratuitos" tienen un alto precio en términos de datos personales .
El consumismo nos dice que queremos algo y que debemos pagarlo con nuestras vidas. ¿Necesitamos los tipos de productos o servicios que se actualizan a sí mismos para vendernos mejores ofertas en el futuro en función de los datos que recopilaron sobre nosotros de formas que quizás no nos gusten? Podríamos anticipar que en 2019, después de los casos Equifax y Cambridge Analytica, podemos ver una explosión final de adquisición y abuso de datos personales.
Después de diez años, no hemos cambiado nuestras creencias centrales sobre la arquitectura de la red interconectada. Esa es la razón por la que seguimos respaldando los principios más fundamentales de la red de filtrado de Qrator Labs: BGP-anycast, la capacidad de procesar tráfico encriptado, evitar captchas y otros obstáculos, más visibilidad para usuarios legítimos en comparación con atacar bots.
Mirando lo que sigue sucediendo con los expertos en seguridad cibernética y las empresas en el campo, queremos enfatizar otro problema: cuando se trata de seguridad, no es aplicable un enfoque ingenuo, simple o rápido.
Esta es la razón principal por la que Qrator Labs no tiene cientos o incluso docenas de puntos de presencia, en comparación con los CDN. Al mantener un número menor de centros de depuración todos conectados a los ISP de clase Tier-1, logramos una verdadera descentralización del tráfico. Esa es también la razón por la que no intentamos construir firewalls, que son completamente diferentes de lo que hace Qrator Labs: conectividad.
Hemos estado contando historias sobre captchas y pruebas y comprobaciones de JavaScript durante algún tiempo y aquí estamos: las redes neuronales se están volviendo extremadamente útiles para resolver el primero, y el segundo nunca fue un problema para el atacante experto y persistente.
Este año también sentimos un cambio bastante emocionante: durante años, DDoS fue un problema solo para un número limitado de áreas de negocios, generalmente, aquellas en las que el dinero está por encima del nivel del agua: comercio electrónico, comercio / acciones, banca / sistemas de pago. Sin embargo, con el crecimiento continuo de Internet, observamos que los ataques DDoS ahora se aplican a todos los demás servicios de Internet disponibles. La era DDoS comenzó con aumentos en el ancho de banda y la cantidad de computadoras personales en uso en todo el mundo; No es sorprendente que en 2018, con microchips de silicio en todos los dispositivos que nos rodean, el panorama de ataques evolucione tan rápido.
Si alguien espera que esta tendencia cambie, probablemente esté equivocado. Tal como nosotros, quizás, también lo somos. Nadie puede decir cómo Internet realmente evolucionará y difundirá su impacto y poder en los próximos años, pero de acuerdo con lo que vimos en 2018 y continuamos observando en 2019, todo se multiplicará. Para 2020, se espera que el número de dispositivos conectados en Internet supere los 30 mil millones, además del hecho de que ya hemos superado el punto en el que la humanidad generó más tráfico que la automatización que creó. Entonces, pronto, tendremos que decidir cómo manejar toda esta "inteligencia", artificial o no, ya que todavía vivimos en el mundo donde solo un ser humano puede ser responsable de que algo esté bien o mal.
2018 fue un año de oportunidades para aquellos en el lado oscuro. Vemos crecimiento en ataques y hacks en términos de complejidad, volumen y frecuencia. Crooks obtuvo algunas herramientas poderosas y aprendió a usarlas. Los buenos hicieron poco más que solo mirar estos desarrollos. Esperamos ver ese cambio este año, al menos en las preguntas más dolorosas.