Todos sabemos cómo comienza la patria, y el aprendizaje profundo comienza con los datos. Sin ellos, es imposible entrenar un modelo, evaluarlo y, de hecho, usarlo. Comprometidos en la investigación, aumentando el índice de Hirsch con artículos sobre nuevas arquitecturas de redes neuronales y experimentando, confiamos en las fuentes de datos locales más simples; usualmente archivos en varios formatos. Esto funciona, pero sería bueno recordar un sistema de combate que contiene terabytes de datos que cambian constantemente. Y esto significa que necesita simplificar y acelerar la transferencia de datos en la producción, así como poder trabajar con big data. Aquí es donde entra Apache Ignite.
Apache Ignite es una base de datos distribuida centrada en la memoria, así como una plataforma para el almacenamiento en caché y el procesamiento de operaciones relacionadas con transacciones, análisis y cargas de flujo. El sistema es capaz de moler petabytes de datos a la velocidad de la RAM. El artículo se centrará en la integración entre Apache Ignite y TensorFlow, que le permite utilizar Apache Ignite como fuente de datos para entrenar la red neuronal y la inferencia, así como un depósito de modelos entrenados y un sistema de gestión de clúster para el aprendizaje distribuido.
Fuente de datos de RAM distribuida
Apache Ignite le permite almacenar y procesar tantos datos como necesite en un clúster distribuido. Para aprovechar este Apache Ignite al entrenar redes neuronales en TensorFlow, use
Ignite Dataset .
Nota: Apache Ignite no es solo uno de los enlaces en la tubería ETL entre una base de datos o un almacén de datos y TensorFlow. Apache Ignite en sí mismo es
HTAP (un sistema híbrido para el procesamiento de datos transaccionales / analíticos). Al elegir Apache Ignite y TensorFlow, obtiene un único sistema para el procesamiento transaccional y analítico, y al mismo tiempo, la capacidad de utilizar datos operativos e históricos para entrenar la red neuronal y la inferencia.
Los siguientes puntos de referencia demuestran que Apache Ignite es muy adecuado para escenarios en los que los datos se almacenan en un solo host. Dicho sistema le permite lograr un rendimiento de más de 850 Mb / s, si el almacén de datos y el cliente se encuentran en el mismo nodo. Si el almacenamiento está en un host remoto, el rendimiento es de aproximadamente 800 Mb / s.
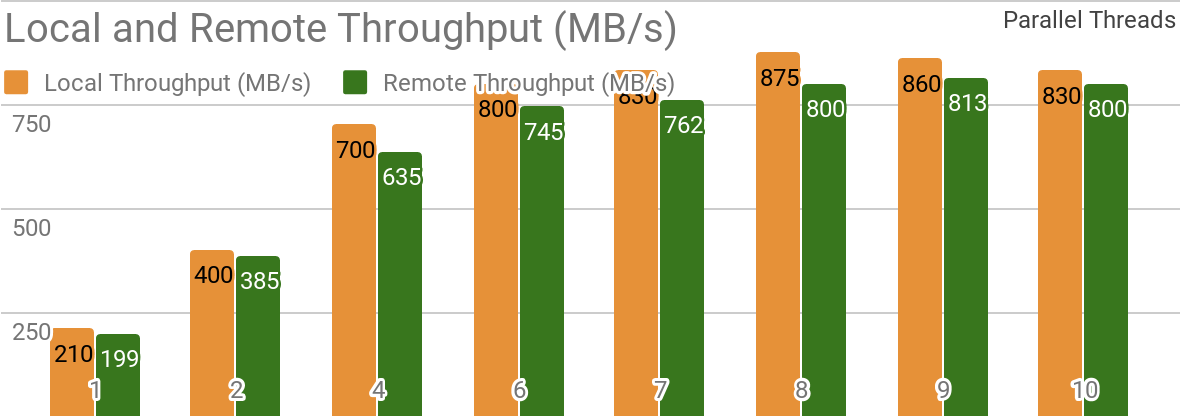
El gráfico muestra el ancho de banda para Ignite Dataset para un solo nodo Apache Ignite local. Estos resultados se obtuvieron en un procesador Xeon E5-2609 v4 1.7GHz de 2x con 16GB de RAM y en una red con un ancho de banda de 10GB / s (cada registro tiene un tamaño de 1MB, tamaño de página - 20MB).
Otro punto de referencia demuestra cómo funciona Ignite Dataset con un clúster Apache Ignite distribuido. Es esta configuración la que se selecciona de manera predeterminada cuando se usa Apache Ignite como un sistema HTAP y le permite lograr un ancho de banda para un solo cliente que exceda 1 GB / s en un clúster con un ancho de banda de 10 Gb / s.
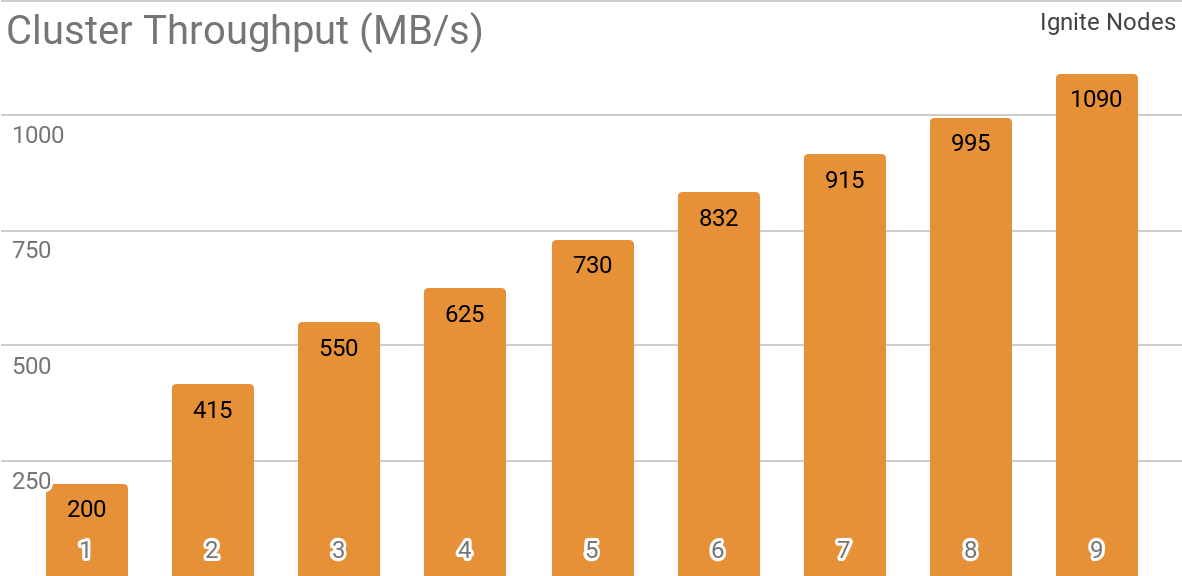
El gráfico muestra el rendimiento del conjunto de datos Ignite para un clúster Apache Ignite distribuido con un número diferente de nodos (de 1 a 9). Estos resultados se obtuvieron en un procesador Xeon E5-2609 v4 1.7GHz de 2x con 16GB de RAM y en una red con un ancho de banda de 10GB / s (cada registro tiene un tamaño de 1MB, tamaño de página - 20MB).
Se probó el siguiente escenario: el caché Apache Ignite (con un número variable de particiones en el primer conjunto de pruebas y con 2048 particiones en el segundo) se llena con 10K líneas de 1 MB cada una, después de lo cual el cliente TensorFlow lee los datos utilizando Ignite Dataset. El clúster fue construido a partir de máquinas con 2x Xeon E5-2609 v4 1.7 GHz, 16 GB de memoria y conectado a través de una red que funciona a una velocidad de 10 GB / s. En cada nodo, Apache Ignite trabajó en la
configuración estándar .
Apache Ignite es fácil de usar como una base de datos clásica con interfaz SQL y al mismo tiempo como fuente de datos para TensorFlow.
$ apache-ignite/bin/ignite.sh $ apache-ignite/bin/sqlline.sh -u "jdbc:ignite:thin://localhost:10800/"
CREATE TABLE KITTEN_CACHE (ID LONG PRIMARY KEY, NAME VARCHAR); INSERT INTO KITTEN_CACHE VALUES (1, 'WARM KITTY'); INSERT INTO KITTEN_CACHE VALUES (2, 'SOFT KITTY'); INSERT INTO KITTEN_CACHE VALUES (3, 'LITTLE BALL OF FUR');
import tensorflow as tf from tensorflow.contrib.ignite import IgniteDataset tf.enable_eager_execution() dataset = IgniteDataset(cache_name="SQL_PUBLIC_KITTEN_CACHE") for element in dataset: print(element)
{'key': 1, 'val': {'NAME': b'WARM KITTY'}} {'key': 2, 'val': {'NAME': b'SOFT KITTY'}} {'key': 3, 'val': {'NAME': b'LITTLE BALL OF FUR'}}
Objetos estructurados
Apache Ignite le permite almacenar objetos de cualquier tipo que se pueden construir en cualquier jerarquía. Puede trabajar con él a través de Ignite Dataset.
import tensorflow as tf from tensorflow.contrib.ignite import IgniteDataset tf.enable_eager_execution() dataset = IgniteDataset(cache_name="IMAGES") for element in dataset.take(1): print(element)
{ 'key': 'kitten.png', 'val': { 'metadata': { 'file_name': b'kitten.png', 'label': b'little ball of fur', 'width': 800, 'height': 600 }, 'pixels': [0, 0, 0, 0, ..., 0] } }
El entrenamiento de la red neuronal y otros cálculos requieren un procesamiento previo, que se puede hacer como parte de la tubería
tf.data si usa Ignite Dataset.
import tensorflow as tf from tensorflow.contrib.ignite import IgniteDataset tf.enable_eager_execution() dataset = IgniteDataset(cache_name="IMAGES").map(lambda obj: obj['val']['pixels']) for element in dataset: print(element)
[0, 0, 0, 0, ..., 0]
Entrenamiento distribuido
TensorFlow es un marco de aprendizaje automático que
admite el aprendizaje distribuido de redes neuronales, la inferencia y otros sistemas informáticos. Como saben, el entrenamiento de la red neuronal se basa en el cálculo de gradientes de la función de pérdida. En el caso de la capacitación distribuida, podemos calcular estos gradientes en cada partición y luego agregarlos. Es este método el que le permite calcular gradientes para nodos individuales en los que se almacenan los datos, resumirlos y, finalmente, actualizar los parámetros del modelo. Y, dado que eliminamos la transmisión de datos de muestra de entrenamiento entre nodos, la red no se convierte en el "cuello de botella" del sistema.
Apache Ignite utiliza particionamiento horizontal (fragmentación) para almacenar datos en un clúster distribuido. Al crear el caché Apache Ignite (o una tabla, en términos de SQL), puede especificar el número de particiones entre las que se distribuirán los datos. Por ejemplo, si un clúster Apache Ignite consta de 100 máquinas, y creamos un caché con 1000 particiones, cada máquina será responsable de aproximadamente 10 particiones con datos.
Ignite Dataset le permite utilizar estos dos aspectos para el entrenamiento distribuido de redes neuronales. Ignite Dataset es el nodo del
gráfico de cómputo que forma la base de la arquitectura TensorFlow. Y, como cualquier nodo en un gráfico, puede ejecutarse en un nodo remoto en el clúster. Dicho nodo remoto puede anular los parámetros de Ignite Dataset (por ejemplo,
host ,
port o
part ), configurando las variables de entorno apropiadas para el flujo de trabajo (por ejemplo,
IGNITE_DATASET_HOST ,
IGNITE_DATASET_PORT o
IGNITE_DATASET_PART ). Usando tal anulación, puede asignar una partición específica a cada nodo del clúster. Luego, un nodo es responsable de una partición y, al mismo tiempo, el usuario recibe una única fachada de trabajo con el conjunto de datos.
import tensorflow as tf from tensorflow.contrib.ignite import IgniteDataset dataset = IgniteDataset("IMAGES")
Apache Ignite también permite el aprendizaje distribuido utilizando la biblioteca
API de estimador de alto nivel TensorFlow. Esta funcionalidad se basa en el llamado
modo cliente independiente de aprendizaje distribuido en TensorFlow, donde Apache Ignite actúa como fuente de datos y sistema de gestión de clúster. El próximo artículo estará completamente dedicado a este tema.
Almacenamiento de puntos de control de aprendizaje
Además de las capacidades de la base de datos, Apache Ignite también tiene un sistema de archivos
IGFS distribuido. Funcionalmente, se asemeja al sistema de archivos Hadoop HDFS, pero solo en RAM. Junto con sus propias API, el sistema de archivos IGFS implementa la API Hadoop FileSystem y puede conectarse de forma transparente a Hadoop o Spark implementados. La biblioteca TensorFlow en Apache Ignite proporciona integración entre IGFS y TensorFlow. La integración se basa en el complemento del
sistema de archivos propio de TensorFlow y la
API IGFS nativa de Apache Ignite. Hay varios escenarios para su uso, por ejemplo:
- Los puntos de control de estado se almacenan en IGFS para confiabilidad y tolerancia a fallas.
- Los procesos de aprendizaje interactúan con TensorBoard escribiendo archivos de eventos en un directorio monitoreado por TensorBoard. IGFS asegura que tales comunicaciones estén operativas incluso cuando TensorBoard se esté ejecutando en otro proceso o en otra máquina.
Dicha funcionalidad apareció en el lanzamiento de TensorFlow 1.13.0.rc0, y también formará parte de
tensorflow / io en el lanzamiento de TensorFlow 2.0.
Conexión SSL
Apache Ignite le permite proteger los canales de datos mediante
SSL y autenticación. Ignite Dataset admite conexiones SSL con y sin autenticación. Consulte la documentación de
Apache Ignite SSL / TLS para obtener más detalles.
import tensorflow as tf from tensorflow.contrib.ignite import IgniteDataset tf.enable_eager_execution() dataset = IgniteDataset(cache_name="IMAGES", certfile="client.pem", cert_password="password", username="ignite", password="ignite")
Soporte de Windows
Ignite Dataset es totalmente compatible con Windows. Se puede usar como parte de TensorFlow en una estación de trabajo de Windows, así como en sistemas Linux / MacOS.
Pruébalo tú mismo
Los siguientes ejemplos lo ayudarán a comenzar con el módulo.
Encender conjunto de datos
La forma más fácil de comenzar con Ignite Dataset es iniciar el contenedor
Docker con Apache Ignite y descargar datos
MNIST , y luego trabajar con él usando Ignite Dataset. Dicho contenedor está disponible en el Docker Hub:
dmitrievanthony / ignite-with-mnist . Necesita ejecutar el contenedor en su máquina:
docker run -it -p 10800:10800 dmitrievanthony/ignite-with-mnist
Después de eso, puede trabajar con él de la siguiente manera:
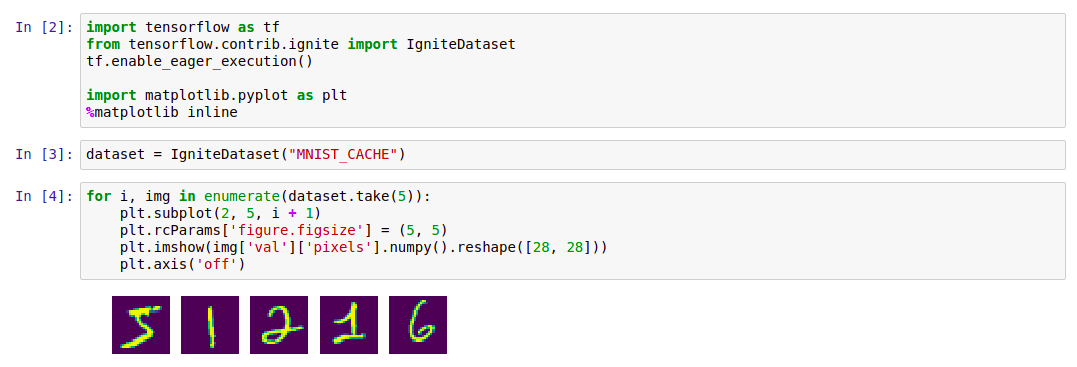
Código import tensorflow as tf from tensorflow.contrib.ignite import IgniteDataset tf.enable_eager_execution() import matplotlib.pyplot as plt %matplotlib inline dataset = IgniteDataset("MNIST_CACHE") for i, img in enumerate(dataset.take(5)): plt.subplot(2, 5, i + 1) plt.rcParams['figure.figsize'] = (5, 5) plt.imshow(img['val']['pixels'].numpy().reshape([28, 28])) plt.axis('off')
IGFS
El soporte de TensorFlow IGFS apareció en la versión TensorFlow 1.13.0rc0 y también formará parte de la
versión tensorflow / io en TensorFlow 2.0. Para probar IGFS con TensorFlow, la forma más fácil de iniciar el contenedor
Docker es con Apache Ignite + IGFS, y luego trabajar con él usando TensorFlow
tf.gfile . Dicho contenedor está disponible en Docker Hub:
dmitrievanthony / ignite-with-igfs . Este contenedor se puede ejecutar en su máquina:
docker run -it -p 10500:10500 dmitrievanthony/ignite-with-igfs
Entonces puedes trabajar así:
import tensorflow as tf import tensorflow.contrib.ignite.python.ops.igfs_ops with tf.gfile.Open("igfs:///hello.txt", mode='w') as w: w.write("Hello, world!") with tf.gfile.Open("igfs:///hello.txt", mode='r') as r: print(r.read())
Hello, world!
Limitaciones
Actualmente, cuando se trabaja con Ignite Dataset, se supone que todos los objetos en el caché tienen la misma estructura (objetos homogéneos), y que el caché contiene al menos un objeto necesario para recuperar el esquema. Otra limitación concierne a los objetos estructurados: Ignite Dataset no admite UUID, mapas y matrices de objetos, que pueden ser parte de un objeto. Eliminar estas restricciones, así como estabilizar y sincronizar las versiones de TensorFlow y Apache Ignite, es una de las tareas del desarrollo continuo.
Versión esperada de TensorFlow 2.0
Los próximos cambios a TensorFlow 2.0 resaltarán estas características en el módulo
tensorflow / io . Después de lo cual, trabajar con ellos se puede construir de manera más flexible. Los ejemplos cambiarán un poco, y esto se reflejará en el gihab y en la documentación.