Gracias al análisis en tiempo real, nosotros, los empleados de Uber, tenemos una idea del estado de las cosas y la eficiencia del trabajo, y en base a los datos, decidimos cómo mejorar la calidad del trabajo en la plataforma de Uber. Por ejemplo, el equipo del proyecto monitorea el estado del mercado e identifica posibles problemas en nuestra plataforma; el software basado en modelos de aprendizaje automático predice las ofertas de pasajeros y la demanda de conductores; Los especialistas en procesamiento de datos están mejorando los modelos de aprendizaje automático, a su vez, para mejorar la calidad de los pronósticos.

En el pasado, para el análisis en tiempo real, utilizamos soluciones de bases de datos de otras compañías, pero ninguna cumplía con todos nuestros criterios de funcionalidad, escalabilidad, eficiencia, costo y requisitos operativos.
Lanzado en noviembre de 2018, AresDB es una herramienta de análisis en tiempo real de código abierto. Utiliza una fuente de alimentación no convencional, procesadores gráficos (GPU), que le permite aumentar la escala del análisis. La tecnología GPU, una prometedora herramienta de análisis en tiempo real, ha avanzado significativamente en los últimos años, por lo que es ideal para la computación paralela en tiempo real y el procesamiento de datos.
En las siguientes secciones, describimos la estructura de AresDB y cómo esta solución interesante para el análisis en tiempo real nos permitió unificar, simplificar y mejorar de manera más racional y más racional las soluciones de bases de datos de Uber para el análisis en tiempo real. ¡Esperamos que después de leer este artículo intente AresDB como parte de sus propios proyectos y también se asegure de su utilidad!
Aplicaciones de análisis en tiempo real de Uber
El análisis de datos es crítico para el éxito de Uber. Entre otras funciones, se utilizan herramientas analíticas para resolver las siguientes tareas:
- Creación de paneles de control para monitorear métricas de negocios.
- Tomar decisiones automáticas (por ejemplo, determinar el costo de un viaje e identificar casos de fraude ) en función de las métricas resumidas recopiladas.
- Cree consultas aleatorias para diagnosticar, solucionar problemas y resolver problemas de operaciones comerciales.
Clasificamos estas funciones con diferentes requisitos de la siguiente manera:

Los paneles de control y los sistemas de toma de decisiones utilizan sistemas de análisis en tiempo real para crear consultas similares en subconjuntos de datos relativamente pequeños pero muy importantes (con el nivel más alto de relevancia de datos) con QPS alto y baja latencia.
Necesidad de otro módulo analítico.
El problema más común que Uber utiliza herramientas de análisis en tiempo real para resolver es calcular las poblaciones de series de tiempo. Estos cálculos dan una idea de las interacciones del usuario para que podamos mejorar la calidad de los servicios en consecuencia. En base a ellos, solicitamos indicadores para ciertos parámetros (por ejemplo, día, hora, identificador de ciudad y estado del viaje) durante un cierto período de tiempo para datos filtrados al azar (o a veces combinados). Con los años, Uber ha implementado varios sistemas diseñados para resolver este problema de varias maneras.
Aquí hay algunas soluciones de terceros que utilizamos para resolver este tipo de problema:
- Apache Pinot , una base de datos analítica de código abierto distribuida escrita en Java, es adecuada para el análisis de datos a gran escala. Pinot utiliza una arquitectura lambda interna para consultar datos de paquetes y datos en tiempo real en el almacenamiento de columnas, un índice de bits invertido para el filtrado y un árbol de estrellas para almacenar en caché los resultados agregados. Sin embargo, no admite funciones de deduplicación, actualización o inserción, fusión o consulta avanzada basadas en claves, como el filtrado geoespacial. Además, dado que Pinot es una base de datos basada en JVM, las consultas son muy caras en términos de uso de memoria.
- Ustic utiliza Elasticsearch para resolver diversas tareas de análisis de transmisión. Está construido sobre la base de la biblioteca Apache Lucene , que almacena documentos, para la búsqueda de palabras clave de texto completo y un índice invertido. El sistema está extendido y ampliado para admitir datos agregados. Un índice invertido proporciona filtrado pero no está optimizado para almacenar y filtrar datos basados en rangos de tiempo. Los registros se almacenan en forma de documentos JSON, lo que impone costos adicionales para proporcionar acceso al repositorio y las solicitudes. Al igual que Pinot, Elasticsearch es una base de datos basada en JVM y, en consecuencia, no es compatible con la función de unión, y la ejecución de consultas ocupa una gran cantidad de memoria.
Aunque estas tecnologías tienen sus puntos fuertes, carecían de algunas de las características necesarias para nuestro caso de uso. Necesitábamos una solución unificada, simplificada y optimizada, y en su búsqueda trabajamos en una dirección no estándar (más precisamente, dentro de la GPU).
Usando GPU para análisis en tiempo real
Para una representación realista de imágenes con una alta velocidad de cuadros, las GPU procesan simultáneamente una gran cantidad de formas y píxeles a alta velocidad. Aunque la tendencia a aumentar la frecuencia de reloj de las unidades de procesamiento de datos en los últimos años ha comenzado a disminuir, la cantidad de transistores en el chip solo ha aumentado de acuerdo con la ley de Moore . Como resultado, la velocidad de cálculo de la GPU, medida en gigaflops por segundo (Gflops / s), está aumentando rápidamente. La Figura 1 a continuación muestra una comparación de la tendencia de velocidad teórica (Gflops / s) de la GPU NVIDIA y la CPU Intel a lo largo de los años:
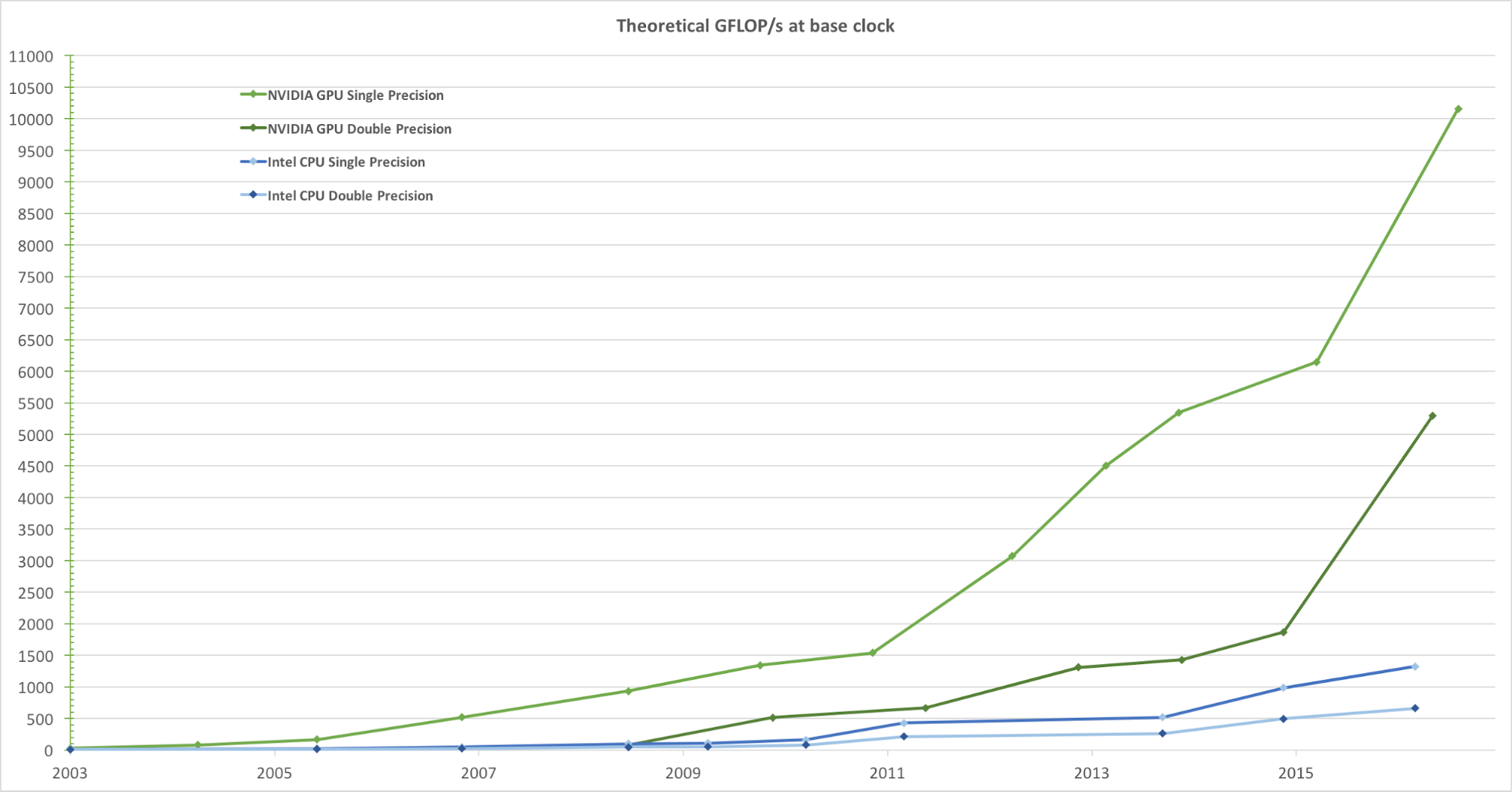
Figura 1. Comparación del rendimiento de CPU y GPU de punto flotante de precisión simple durante varios años. Imagen tomada de la Guía de programación CUDA C de Nvidia.
Al desarrollar el mecanismo de solicitud de análisis en tiempo real, la decisión de integrar la GPU fue natural. En Uber, una solicitud típica de análisis en tiempo real requiere procesar datos en pocos días con millones o incluso miles de millones de registros, luego filtrarlos y resumirlos en un corto período de tiempo. Esta tarea computacional encaja perfectamente en el modelo de procesamiento paralelo de GPU de propósito general, porque ellos:
- Procesan datos en paralelo con una velocidad muy alta.
- Proporcionan una mayor velocidad computacional (Gflops / s), lo que los hace excelentes para realizar tareas computacionales complejas (en bloques de datos) que se pueden paralelizar.
- Proporcionan un mayor rendimiento (sin demora) en el intercambio de datos entre la unidad de cómputo y el almacenamiento (ALU y GPU de memoria global) en comparación con las unidades de procesamiento central (CPU), lo que los hace ideales para procesar tareas de E / S de memoria paralela, que requiere una cantidad significativa de datos.
Centrándonos en el uso de una base de datos analítica basada en GPU, nosotros, desde el punto de vista de nuestras necesidades, evaluamos varias soluciones analíticas existentes que usan GPU:
- Kinetica , una herramienta analítica basada en GPU, salió al mercado en 2009, inicialmente para su uso en el Ejército de EE. UU. Y agencias de inteligencia. Aunque demuestra el alto potencial de la tecnología GPU en análisis, descubrimos que para nuestras condiciones de uso, faltan muchas funciones clave, incluido el cambio del esquema, la inserción o actualización parcial, la compresión de datos, la configuración del disco y la memoria a nivel de columna, y la conexión por relaciones geoespaciales
- OmniSci , un módulo de consulta SQL de código abierto, parecía una opción prometedora, pero al evaluar el producto, nos dimos cuenta de que carecía de algunas características importantes para su uso en Uber, como la deduplicación. Aunque OminiSci introdujo el código fuente abierto de su proyecto en 2017, después de analizar su solución basada en C ++, llegamos a la conclusión de que ni cambiar ni ramificar su base de código es prácticamente factible.
- Las herramientas de análisis en tiempo real basadas en GPU, incluidas GPUQP , CoGaDB , GPUDB , Ocelot , OmniDB y Virginian , a menudo se utilizan en instituciones educativas y de investigación. Sin embargo, dados sus objetivos académicos, estas decisiones se centran en desarrollar algoritmos y probar conceptos, en lugar de resolver problemas del mundo real. Por esta razón, no los tomamos en cuenta, en las condiciones de nuestro volumen y escala.
En general, estos sistemas demuestran la gran ventaja y el potencial de procesar datos utilizando la tecnología GPU, y nos inspiraron a crear nuestra propia solución de análisis en tiempo real basada en GPU, adaptada a las necesidades de Uber. En base a estos conceptos, desarrollamos y abrimos el código fuente de AresDB.
Descripción general de la arquitectura AresDB
En un nivel alto, AresDB almacena la mayoría de los datos en la memoria del host (RAM, que está conectada a la CPU), usa la CPU para procesar los datos recibidos y los discos para recuperarlos. Durante el período de solicitud, AresDB transfiere datos desde la memoria del host a la memoria de la GPU para el procesamiento paralelo en la GPU. Como se muestra en la Figura 2 a continuación, AresDB incluye almacenamiento de memoria, almacenamiento de metadatos y disco:

Figura 2. La arquitectura única de AresDB incluye almacenamiento en memoria, disco y almacenamiento de metadatos.
Mesas
A diferencia de la mayoría de los sistemas de gestión de bases de datos relacionales (RDBMS), AresDB no tiene un alcance de base de datos o esquema. Todas las tablas pertenecen al mismo ámbito en un clúster / instancia de AresDB, lo que permite a los usuarios acceder a ellas directamente. Los usuarios almacenan sus datos en forma de tablas de hechos y tablas de dimensiones.
Tabla de hechos
La tabla de hechos almacena un flujo interminable de eventos de series de tiempo. Los usuarios usan una tabla de hechos para almacenar eventos / hechos que ocurren en tiempo real, y cada evento está asociado con la hora del evento, y la tabla a menudo se consulta por la hora del evento. Como un ejemplo del tipo de información que se almacena en la tabla de hechos, podemos nombrar viajes, donde cada viaje es un evento, y la hora de la solicitud de viaje a menudo se conoce como la hora del evento. Si varias marcas de tiempo están asociadas con un evento, solo una marca de tiempo se indica como la hora del evento y se muestra en la tabla de hechos.
Tabla de medidas
La tabla de medidas almacena las características actuales de las instalaciones (incluidas ciudades, clientes y conductores). Por ejemplo, los usuarios pueden almacenar información sobre la ciudad, en particular el nombre de la ciudad, la zona horaria y el país, en la tabla de medidas. A diferencia de las tablas de hechos, que están en constante crecimiento, las tablas de dimensiones siempre tienen un tamaño limitado (por ejemplo, para Uber, la tabla de ciudades está limitada por el número real de ciudades en el mundo). Las tablas de medición no requieren una columna de tiempo especial.
Tipos de datos
La siguiente tabla muestra los tipos de datos actuales admitidos por AresDB:
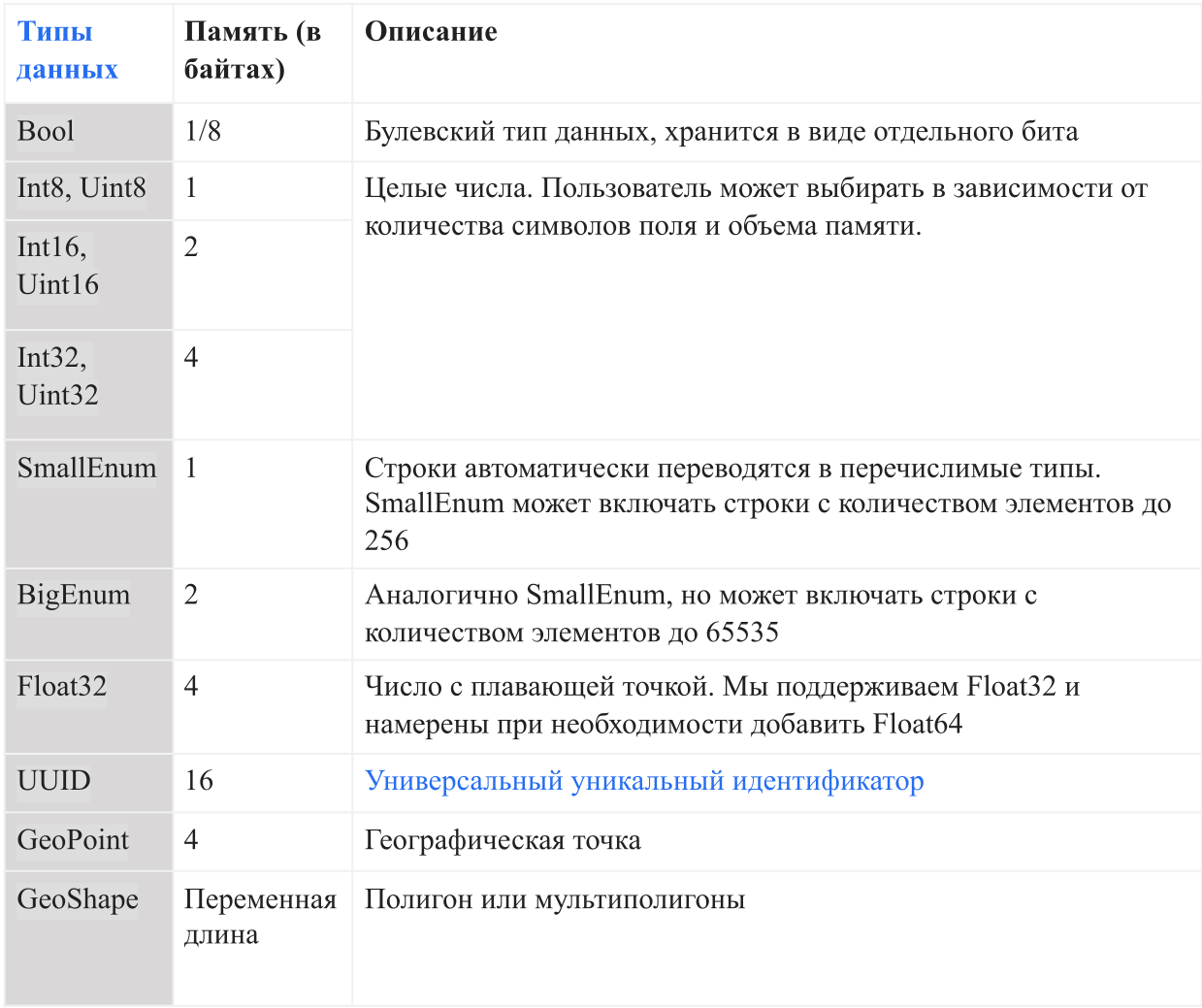
En AresDB, las cadenas se convierten en enumeraciones automáticamente antes de ingresar a la base de datos para aumentar la comodidad del almacenamiento y la eficiencia de la consulta. Esto permite verificaciones de igualdad que distinguen entre mayúsculas y minúsculas, pero no admite operaciones avanzadas como concatenación, subcadenas, máscaras y coincidencia de expresiones regulares. En el futuro, tenemos la intención de agregar la opción de soporte de línea completa.
Funciones principales
La arquitectura AresDB admite las siguientes características:
- Almacenamiento basado en columnas con compresión para aumentar la eficiencia del almacenamiento (menos memoria en bytes para el almacenamiento de datos) y la eficiencia de la consulta (menos intercambio de datos entre la memoria de la CPU y la memoria de la GPU al procesar una solicitud)
- Actualización o inserción en tiempo real con deduplicación de clave principal para mejorar la precisión de los datos y actualizar los datos en tiempo real en unos segundos
- Procesamiento de solicitud de GPU para procesamiento de datos de GPU altamente paralelo con baja latencia de solicitud (desde fracciones de segundo a varios segundos)
Columna de almacenamiento
Vector
AresDB almacena todos los datos en un formato de columna. Los valores de cada columna se almacenan como un vector de valores de columna. El marcador de confianza / incertidumbre de los valores en cada columna se almacena en un vector cero separado, mientras que el marcador de confianza de cada valor se presenta como un bit.
Almacenamiento activo
AresDB almacena datos de columna sin comprimir y sin clasificar (vectores activos) en almacenamiento activo. Los registros de datos en el almacenamiento activo se dividen en paquetes (activos) de un volumen dado. Los nuevos paquetes se crean cuando se reciben datos, mientras que los paquetes antiguos se eliminan después de archivar registros. El índice de clave principal se utiliza para localizar deduplicación y actualizar registros. La Figura 3 a continuación muestra cómo organizamos los registros activos y utilizamos el valor de la clave principal para determinar su ubicación:
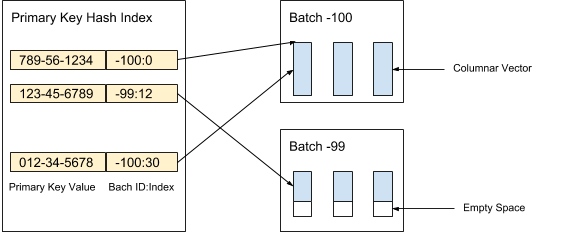
Figura 3. Usamos el valor de la clave primaria para determinar la ubicación del paquete y la posición de cada registro dentro del paquete.
Los valores de cada columna en el paquete se almacenan como un vector de columna. El marcador de confiabilidad / incertidumbre de los valores en cada vector de valores se almacena como un vector cero separado, y el marcador de confiabilidad de cada valor se presenta como un bit. En la Figura 4 a continuación, ofrecemos un ejemplo con cinco valores para la columna city_id :
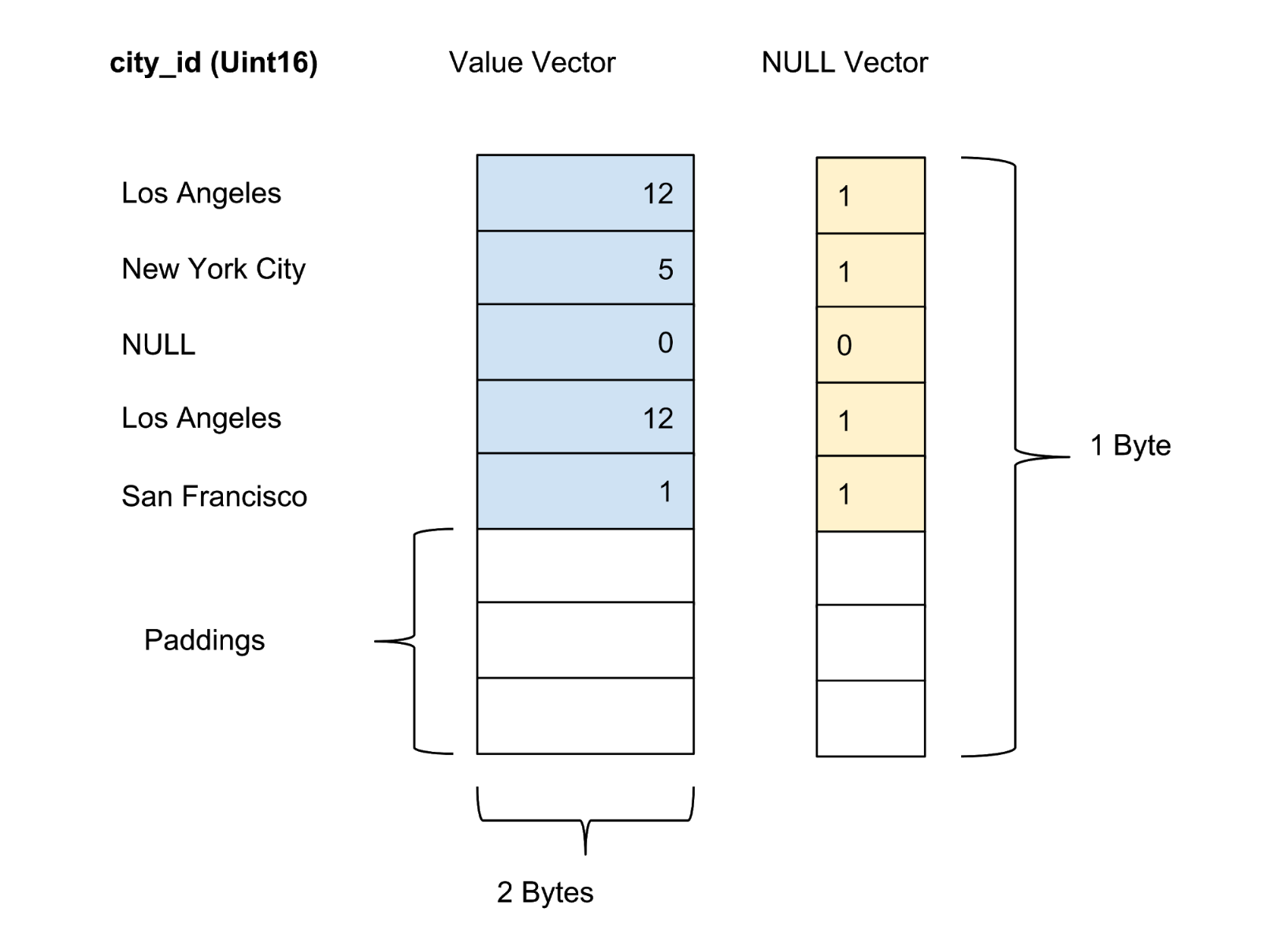
Figura 4. Almacenamos valores (valor real) y vectores cero (marcador de confianza) de columnas sin comprimir en la tabla de datos.
Almacenamiento de archivos
AresDB también almacena datos de columna completados, ordenados y comprimidos (vectores de archivo) en el almacenamiento de archivos a través de tablas de hechos. Los registros en el almacenamiento de archivos también se distribuyen en lotes. A diferencia de los paquetes activos, el paquete de archivo almacena registros por día de acuerdo con el Tiempo Universal Coordinado (UTC). Un paquete de archivo ha estado usando la cantidad de días como identificador de paquete desde Unix Epoch.
Los registros se almacenan en forma ordenada de acuerdo con un orden de clasificación de columnas definido por el usuario. Como se muestra en la Figura 5 a continuación, clasificamos primero por la columna city_id y luego por la columna de estado:
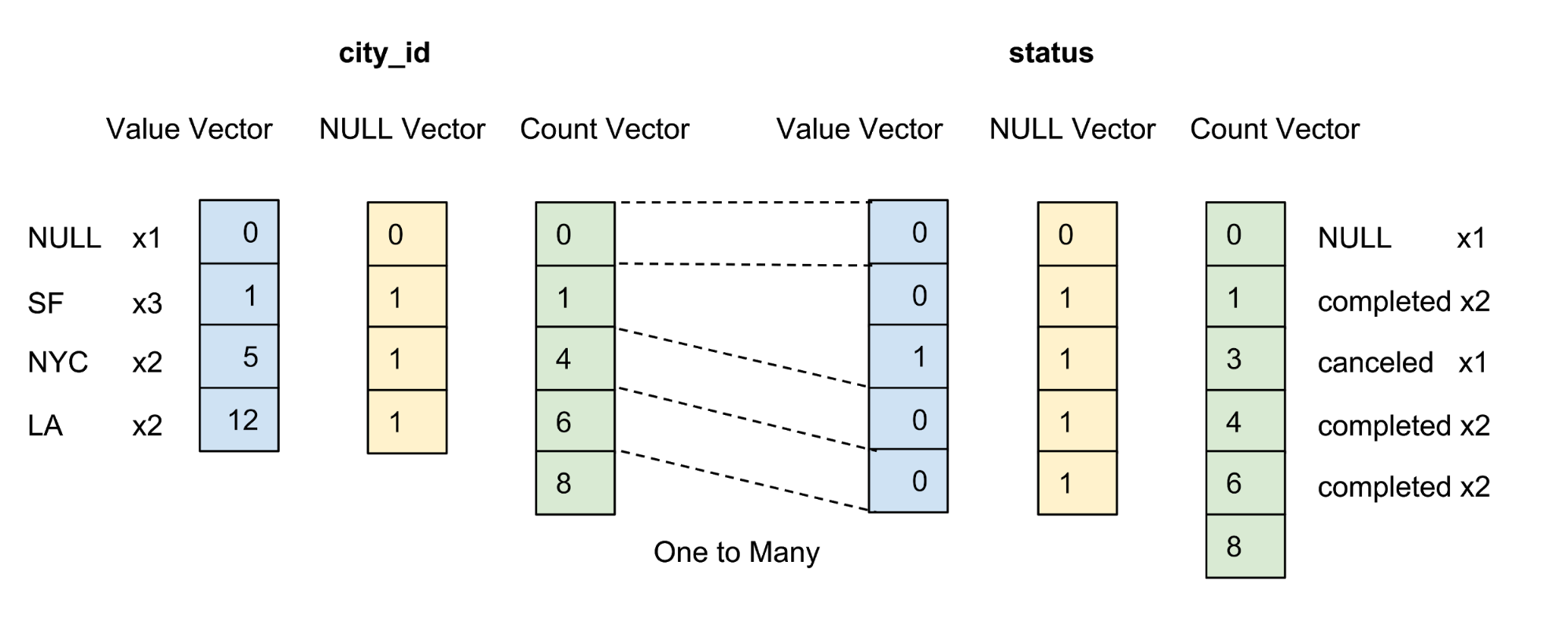
Figura 5. Clasificamos todas las filas por city_id, luego por estado y luego comprimimos cada columna por codificación de grupo. Después de ordenar y comprimir, cada columna recibirá un vector de contabilidad.
El objetivo de establecer el orden de clasificación del usuario para las columnas es el siguiente:
- Maximizando el efecto de compresión ordenando columnas con una pequeña cantidad de elementos en primer lugar. La compresión máxima mejora la eficiencia del almacenamiento (se requieren menos bytes para almacenar datos) y la eficiencia de la consulta (se transfieren menos bytes entre la memoria de la CPU y la memoria de la GPU).
- Proporciona un prefiltrado conveniente basado en rango para filtros equivalentes comunes, por ejemplo, city_id = 12. El prefiltrado minimiza la cantidad de bytes necesarios para transferir datos entre la memoria de la CPU y la memoria de la GPU, lo que maximiza la eficiencia de la consulta.
Una columna se comprime solo si está presente en el orden de clasificación especificado por el usuario. No estamos tratando de comprimir columnas con una gran cantidad de elementos, ya que esto ahorra poca memoria.
Después de ordenar, los datos para cada columna calificada se comprimen utilizando una opción de codificación de grupo específica. Además del vector de valor y el vector cero, introducimos un vector de contabilidad para representar el mismo valor.
Recepción de datos en tiempo real con soporte para funciones de actualización e inserción.
Los clientes reciben datos a través de la API HTTP al publicar un paquete de servicio. Un paquete de servicio es un formato binario ordenado especial que minimiza el uso del espacio mientras mantiene el acceso aleatorio a los datos.
Cuando AresDB recibe el paquete de servicio, primero lo escribe en el registro de la operación de recuperación. Cuando se agrega un service pack al final del registro de eventos, AresDB identifica y omite las entradas tardías en las tablas de hechos para su uso en el almacenamiento activo. Un registro se considera "tardío" si la hora del evento es anterior a la hora archivada del evento de desconexión. Para los registros que no se consideran "tardíos", AresDB usa el índice de clave principal para ubicar el paquete dentro del almacén activo donde desea insertarlos. Como se muestra en la Figura 6 a continuación, los nuevos registros (no encontrados previamente en función del valor de la clave primaria) se insertan en un espacio vacío, y los registros existentes se actualizan directamente:
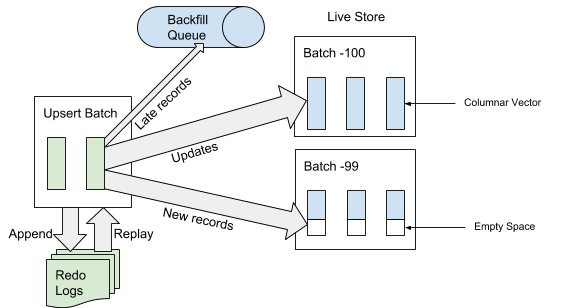
Figura 6. Cuando se reciben datos, después de agregar el paquete de servicio al registro de eventos, las entradas "tardías" se agregan a la cola inversa y otras entradas al almacenamiento activo.
Archivado
Cuando se reciben datos, los registros se agregan / actualizan en el almacenamiento activo o se agregan a la cola inversa, esperando su ubicación en el almacenamiento de archivos.
Periódicamente, iniciamos un proceso programado, denominado archivado, en relación con los registros del almacenamiento activo para adjuntar nuevos registros (registros que nunca se han archivado antes) al almacenamiento de archivos. El proceso de archivo solo procesa registros en el almacenamiento activo con el tiempo de evento en el rango entre el tiempo de apagado anterior (tiempo de apagado del último proceso de archivo) y el nuevo tiempo de apagado (nuevo tiempo de apagado basado en el parámetro de retraso de archivo en el esquema de la tabla).
El tiempo de evento de registro se usa para determinar en qué registros de paquete de archivo se deben combinar al empacar datos de archivo en paquetes diarios. El archivado no requiere la deduplicación del índice del valor de la clave primaria durante la fusión, ya que solo se archivan los registros en el rango entre el tiempo de apagado antiguo y el nuevo.
La Figura 7 a continuación muestra un gráfico de acuerdo con el momento del evento de un registro en particular.
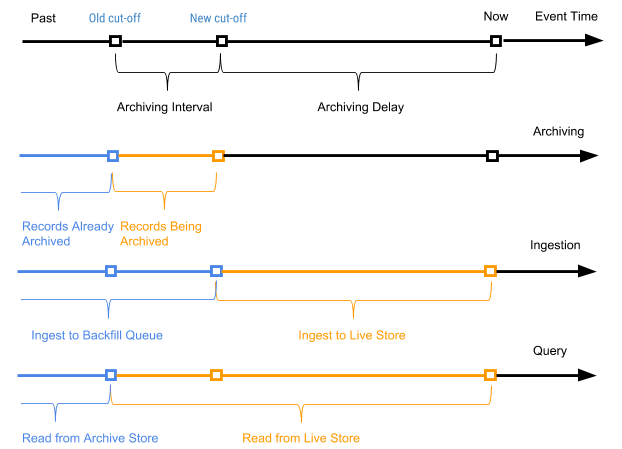
Figura 7. Utilizamos el tiempo del evento y el tiempo del viaje para definir los registros como nuevos (activos) y antiguos (el tiempo del evento es anterior al tiempo archivado del evento del viaje).
En este caso, el intervalo de archivado es el intervalo de tiempo entre los dos procesos de archivado, y el retraso de archivado es el período posterior al momento del evento, pero hasta que el evento se archiva. Ambos parámetros se definen en la configuración del esquema de la tabla AresDB.
Relleno
Como se muestra en la Figura 7 anterior, los registros antiguos (cuyo tiempo de evento es anterior al tiempo archivado del evento de apagado) para las tablas de hechos se agregan a la cola inversa y finalmente se procesan como parte del proceso de reposición. Los desencadenantes de este proceso también son el tiempo o el tamaño de la cola inversa, si alcanza un nivel de umbral. En comparación con el proceso de agregar datos al almacenamiento activo, el relleno es asíncrono y relativamente más costoso en términos de recursos de CPU y memoria. El relleno se usa en los siguientes escenarios:
- Procesamiento de datos aleatorios, muy tardíos
- Captura manual de datos históricos de un flujo de datos aguas arriba
- Introducción de datos históricos en columnas agregadas recientemente
A diferencia del archivo, el proceso de reposición es idempotente y requiere deduplicación basada en el valor de la clave primaria. Los datos rellenables serán visibles en última instancia para las consultas.
La cola inversa se mantiene en la memoria con un tamaño predefinido, y con una gran carga de relleno, el proceso se bloqueará para el cliente hasta que se borre la cola al iniciar el proceso de relleno.
Procesamiento de solicitudes
En la implementación actual, el usuario necesita usar el Ares Query Language (AQL) creado por Uber para ejecutar consultas en AresDB. AQL es un lenguaje efectivo para consultas analíticas de series de tiempo y no sigue la sintaxis SQL estándar como "SELECCIONAR DONDE GRUPO POR" como otros lenguajes similares a SQL. En cambio, AQL se usa en campos estructurados y se puede incluir en objetos JSON, YAML y Go. Por ejemplo, en lugar de la /SELECT (*) /FROM /GROUP BY city_id, /WHERE = «» /AND request_at >= 1512000000 , la variante AQL equivalente en JSON se escribe de la siguiente manera:
{ “table”: “trips”, “dimensions”: [ {“sqlExpression”: “city_id”} ], “measures”: [ {“sqlExpression”: “count(*)”} ], ;”> “rowFilters”: [ “status = 'completed'” ], “timeFilter”: { “column”: “request_at”, “from”: “2 days ago” } }
En formato JSON, AQL ofrece a los desarrolladores de un tablero y sistema de toma de decisiones un algoritmo de consulta de programa más conveniente que SQL, permitiéndoles componer consultas y manipularlas fácilmente usando código sin preocuparse por cosas como la inyección SQL. Actúa como un formato de consulta universal para arquitecturas típicas de navegadores web, servidores externos e internos hasta la base de datos (AresDB). Además, AQL proporciona una sintaxis conveniente para filtrar por tiempo y por lotes con soporte para su propia zona horaria. Además, el lenguaje admite una serie de funciones, como subconsultas implícitas, para evitar errores comunes en las consultas y facilita el proceso de análisis y reescritura de consultas para desarrolladores de la interfaz interna.
A pesar de los muchos beneficios que ofrece AQL, somos conscientes de que la mayoría de los ingenieros están más familiarizados con SQL. Proporcionar una interfaz SQL para ejecutar consultas es uno de los próximos pasos que consideraremos como parte de nuestros esfuerzos para mejorar la interacción con los usuarios de AresDB.
El diagrama de flujo de ejecución de consultas AQL se muestra en la Figura 8 a continuación:
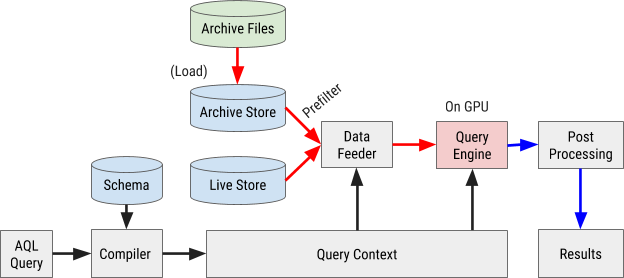
Figura 8. El diagrama de flujo de consultas de AresDB utiliza nuestro propio lenguaje de consulta AQL para procesar y recuperar datos de manera rápida y eficiente.
Compilación de consultas
Una consulta AQL se compila en el contexto de consulta interna. Las expresiones en filtros, medidas y parámetros se analizan en árboles de sintaxis abstracta (AST) para su posterior procesamiento a través de un procesador de gráficos (GPU).
Carga de datos
AresDB utiliza prefiltros para filtrar datos de archivos a bajo precio antes de enviarlos a la GPU para su procesamiento en paralelo. Debido a que los datos archivados se ordenan de acuerdo con el orden de las columnas configuradas, algunos filtros pueden usar este orden de clasificación y el método de búsqueda binaria para determinar el rango apropiado de coincidencia. En particular, los filtros equivalentes para todas las columnas X clasificadas inicialmente y un filtro de rango opcional para columnas clasificadas X + 1 se pueden usar como filtros preliminares, como se muestra en la Figura 9 a continuación.

Figura 9. AresDB prefiltra los datos de la columna antes de enviarlos a la GPU para su procesamiento.
Después del prefiltrado, solo los valores verdes (que cumplan la condición del filtro) deben enviarse a la GPU para el procesamiento en paralelo. Los datos de entrada se cargan en la GPU y se procesan un paquete a la vez. Esto incluye paquetes activos y paquetes de archivo.
AresDB utiliza flujos CUDA para canalización y procesamiento de datos. Para cada solicitud, se aplican dos flujos alternativamente para el procesamiento en dos etapas superpuestas. En la Figura 10 a continuación, ofrecemos un gráfico que ilustra este proceso.
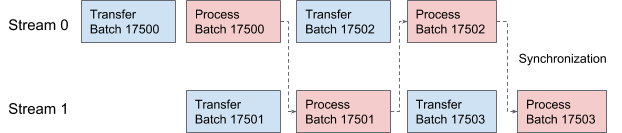
Figura 10. En AresDB, dos subprocesos CUDA transmiten y procesan datos alternativamente.
Ejecución de la consulta
Para simplificar, AresDB usa la biblioteca Thrust para implementar procedimientos de ejecución de consultas, que ofrece bloques de un algoritmo paralelo finamente ajustado para una rápida implementación de consultas en la herramienta actual.
En Thrust, los datos vectoriales de entrada y salida se evalúan utilizando iteradores de acceso aleatorio. Cada subproceso GPU busca iteradores de entrada en su posición de trabajo, lee los valores y realiza cálculos, y luego escribe el resultado en la posición correspondiente en el iterador de salida.
Para evaluar las expresiones AresDB, sigue el modelo de "un operador por núcleo" (OOPK).
En la Figura 11 a continuación, este procedimiento se demuestra utilizando el ejemplo AST generado a partir de la expresión de dimensión request_at – request_at % 86400 en la etapa de compilación de la solicitud:
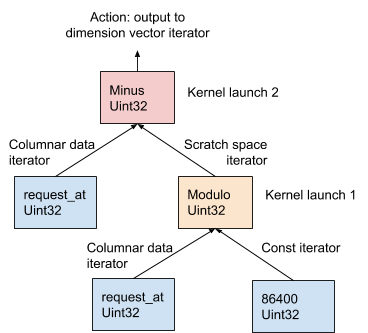
Figura 11. AresDB usa el modelo OOPK para evaluar expresiones.
En el modelo OOPK, el motor de consulta AresDB omite cada nodo hoja del árbol AST y devuelve un iterador para el nodo fuente. Si el nodo raíz también es finito, la acción raíz se realiza directamente en el iterador de entrada.
Para cada nodo no final no raíz ( operación de módulo en este ejemplo), se asigna un vector de espacio de trabajo temporal para almacenar el resultado intermedio obtenido de la expresión request_at% 86400 . Usando Thrust, se inicia una función de kernel para calcular el resultado de esta declaración en la GPU. Los resultados se almacenan en el iterador del espacio de trabajo.
Para un nodo raíz, la función del núcleo se ejecuta de la misma manera que para un nodo no raíz, no finito. Se realizan varias acciones de salida en función del tipo de expresión, que se describe en detalle a continuación:
- Filtrado para reducir la cantidad de elementos vectoriales de entrada
- Registro de datos de salida de medición en un vector de medición para la posterior fusión de datos
- Registre la salida de parámetros en el vector de parámetros para la posterior fusión de datos
Después de evaluar la expresión, se realizan la clasificación y la transformación para finalmente combinar los datos. En las operaciones de ordenación y transformación, utilizamos los valores del vector de dimensión como valores clave para la ordenación y transformación, y los valores del vector de parámetros como valores para combinar datos. Por lo tanto, las filas con valores de dimensión similares se agrupan y combinan. La Figura 12 a continuación muestra este proceso de clasificación y conversión.
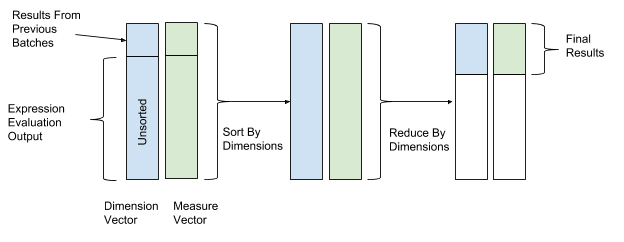
Figura 12. Después de evaluar la expresión, AresDB clasifica y convierte los datos de acuerdo con los valores clave de los vectores de medición (valor clave) y los parámetros (valor).
AresDB también admite las siguientes funciones de consulta avanzadas:
Gestión de recursos
Como una base de datos basada en memoria interna, AresDB debe administrar los siguientes tipos de uso de memoria:
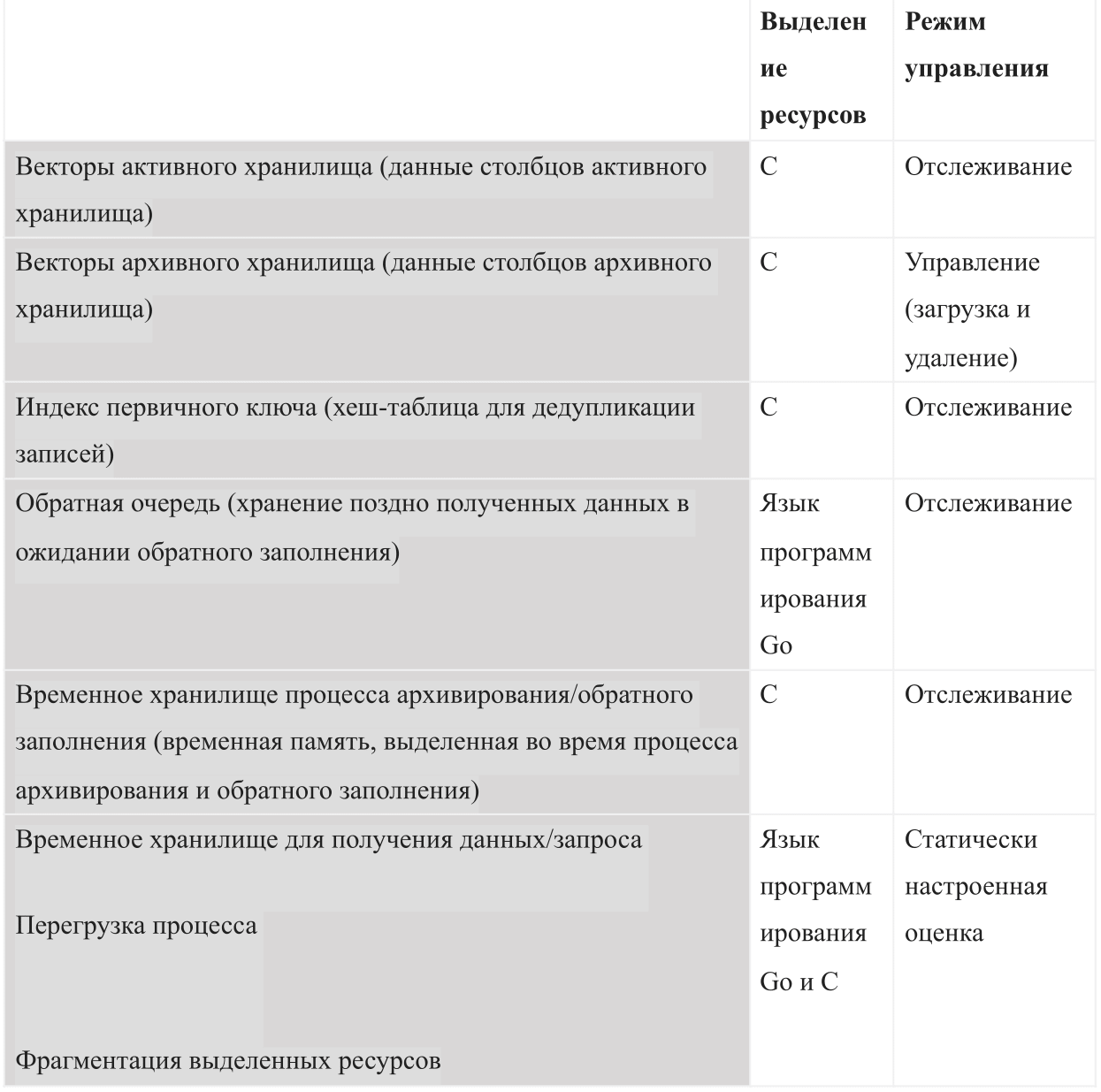
Cuando se inicia AresDB, utiliza el presupuesto de memoria compartida configurado. El presupuesto se divide en los seis tipos de memoria y también debe dejar suficiente espacio para el sistema operativo y otros procesos. Este presupuesto también incluye una estimación de congestión configurada estáticamente, un almacén de datos activo monitoreado por el servidor y datos archivados que el servidor puede decidir descargar y eliminar según el presupuesto de memoria restante.
La Figura 13 a continuación muestra el modelo de memoria del host AresDB.
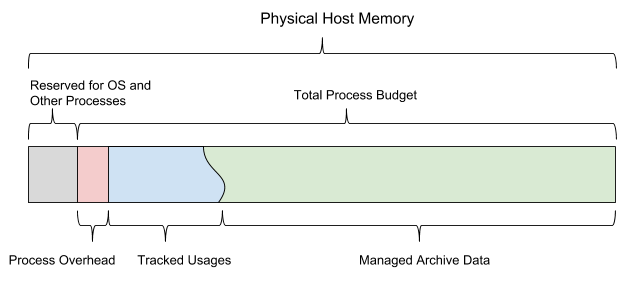
Figura 13. AresDB administra su propio uso de memoria para que no exceda el presupuesto total del proceso configurado.
AresDB permite a los usuarios establecer días de precarga y prioridades a nivel de columna para tablas de hechos y precargar datos archivados solo en días de precarga. Los datos que no se han descargado previamente se cargan en la memoria desde el disco a pedido. Cuando se llena, AresDB también elimina los datos archivados de la memoria del host. Los principios de eliminación de AresDB se basan en los siguientes parámetros: el número de días de precarga, las prioridades de las columnas, el día de compilación del paquete y el tamaño de la columna.
AresDB también gestiona múltiples dispositivos GPU y simula recursos del dispositivo como hilos de GPU y memoria del dispositivo, rastreando el uso de la memoria GPU para procesar solicitudes. AresDB administra los dispositivos GPU a través de un administrador de dispositivos que modela los recursos del dispositivo GPU en dos dimensiones (subprocesos GPU y memoria del dispositivo) y rastrea el uso de memoria cuando procesa las solicitudes. Después de compilar la solicitud, AresDB permite a los usuarios estimar la cantidad de recursos necesarios para completar la solicitud. Los requisitos de memoria del dispositivo deben cumplirse antes de que se resuelva la solicitud; Si actualmente no hay suficiente memoria en algún dispositivo, la solicitud debe esperar. Actualmente, AresDB puede ejecutar una o más solicitudes en el mismo dispositivo GPU al mismo tiempo si el dispositivo cumple con todos los requisitos de recursos.
En la implementación actual, AresDB no almacena en caché la entrada en la memoria del dispositivo para su reutilización en múltiples solicitudes. AresDB tiene como objetivo admitir consultas contra conjuntos de datos que se actualizan constantemente en tiempo real y se almacenan en caché de forma incorrecta correctamente. En futuras versiones de AresDB, tenemos la intención de implementar funciones para el almacenamiento en caché de datos en la memoria de la GPU, lo que ayudará a optimizar el rendimiento de las consultas.
En Uber, utilizamos AresDB para crear paneles para obtener información comercial en tiempo real. AresDB es responsable de almacenar eventos primarios con actualizaciones constantes y calcular métricas críticas para ellos en una fracción de segundo gracias a los recursos de GPU a bajo costo, para que los usuarios puedan usar paneles interactivamente. Por ejemplo, varios servicios actualizan los datos de viaje anónimos que tienen un período de validez largo en el almacén de datos, incluidos nuestro sistema de despacho, sistemas de pago y precios. Para hacer un uso eficiente de los datos de viaje, los usuarios dividen y dividen los datos en diferentes dimensiones para obtener información sobre soluciones en tiempo real.
Cuando se utiliza AresDB, el panel de Uber es un panel de análisis generalizado que utilizan los equipos dentro de la empresa para producir métricas relevantes y respuestas en tiempo real para mejorar la experiencia del usuario.
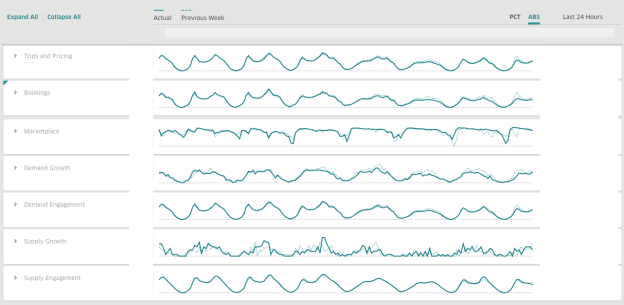
14. Uber AresDB .
, , :
( )

( )

AresDB
, , AresDB :

, , , , , .
AresDB , Apache Kafka , , Apache Flink Apache Spark .
AresDB
, « » « ». , -. 24 AQL:

:
, , .

, AresDB , , . AresDB , , .
AresDB Uber , . , , AresDB .
:
- : AresDB, , , .
- : AresDB 2018 , , AresDB .
- : , , , .
- : , (LLVM) GPU.
AresDB Apache. AresDB .
, .
Agradecimientos
(Kate Zhang), (Jennifer Anderson), (Nikhil Joshi), (Abhi Khune), (Shengyue Ji), (Chinmay Soman), (Xiang Fu), (David Chen) (Li Ning) , !