Hola a todos
Decidí compartir una solución simple y amplia en mi opinión de una red neuronal en C ++.
¿Por qué debería ser interesante esta información?Respuesta: Traté de programar el trabajo del perceptrón multicapa en un conjunto mínimo, para que pudiera configurarse como quisiera en solo unas pocas líneas de código, y la implementación de los algoritmos básicos para trabajar en "C" le permitirá transferir fácilmente lenguajes orientados a "C" (en y a cualquier otro)
sin usar bibliotecas de terceros!Por favor, eche un vistazo a lo que surgió
No le diré sobre el
propósito de las redes neuronales , espero que no haya sido excluido de
Google y pueda encontrar la información que le interesa (propósito, capacidades, aplicaciones, etc.).
Encontrará el
código fuente al final del artículo, pero por ahora, en orden.
Comencemos el análisis
1) Arquitectura y detalles técnicos
-
perceptrón multicapa con la capacidad de configurar cualquier número de capas con un ancho dado. A continuación se presenta
ejemplo de configuraciónmyNeuero.cppinputNeurons = 100;
Tenga en cuenta que la configuración del ancho de entrada y salida para cada capa se realiza de acuerdo con una determinada regla: la entrada de la capa actual = la salida de la capa anterior. Una excepción es la capa de entrada.
Por lo tanto, tiene la oportunidad de configurar cualquier configuración manualmente o de acuerdo con una regla determinada antes de compilar o después de la compilación para leer datos de los archivos de origen.
- implementación del mecanismo de
propagación hacia atrás de errores con la capacidad de establecer la velocidad de aprendizaje
myNeuero.h #define learnRate 0.1
- instalación de
pesos inicialesmyNeuero.h #define randWeight (( ((float)qrand() / (float)RAND_MAX) - 0.5)* pow(out,-0.5))
Nota : si hay más de tres capas (nlCount> 4), se debe aumentar pow (out, -0.5) para que cuando la señal pase directamente, su energía no se reduzca a 0. Ejemplo pow (out, -0.2)
- la
base del código en C. Los algoritmos básicos y el almacenamiento de los coeficientes de ponderación se implementan como una estructura en C, todo lo demás es la cubierta de la función de llamada de esta estructura, también es un reflejo de cualquiera de las capas tomadas por separado
Estructura de la capamyNeuero.h struct nnLay{ int in; int out; float** matrix; float* hidden; float* errors; int getInCount(){return in;} int getOutCount(){return out;} float **getMatrix(){return matrix;} void updMatrix(float *enteredVal) { for(int ou =0; ou < out; ou++) { for(int hid =0; hid < in; hid++) { matrix[hid][ou] += (learnRate * errors[ou] * enteredVal[hid]); } matrix[in][ou] += (learnRate * errors[ou]); } }; void setIO(int inputs, int outputs) { in=inputs; out=outputs; hidden = (float*) malloc((out)*sizeof(float)); matrix = (float**) malloc((in+1)*sizeof(float)); for(int inp =0; inp < in+1; inp++) { matrix[inp] = (float*) malloc(out*sizeof(float)); } for(int inp =0; inp < in+1; inp++) { for(int outp =0; outp < out; outp++) { matrix[inp][outp] = randWeight; } } } void makeHidden(float *inputs) { for(int hid =0; hid < out; hid++) { float tmpS = 0.0; for(int inp =0; inp < in; inp++) { tmpS += inputs[inp] * matrix[inp][hid]; } tmpS += matrix[in][hid]; hidden[hid] = sigmoida(tmpS); } }; float* getHidden() { return hidden; }; void calcOutError(float *targets) { errors = (float*) malloc((out)*sizeof(float)); for(int ou =0; ou < out; ou++) { errors[ou] = (targets[ou] - hidden[ou]) * sigmoidasDerivate(hidden[ou]); } }; void calcHidError(float *targets,float **outWeights,int inS, int outS) { errors = (float*) malloc((inS)*sizeof(float)); for(int hid =0; hid < inS; hid++) { errors[hid] = 0.0; for(int ou =0; ou < outS; ou++) { errors[hid] += targets[ou] * outWeights[hid][ou]; } errors[hid] *= sigmoidasDerivate(hidden[hid]); } }; float* getErrors() { return errors; }; float sigmoida(float val) { return (1.0 / (1.0 + exp(-val))); } float sigmoidasDerivate(float val) { return (val * (1.0 - val)); }; };
2) aplicación
Probar el proyecto con el conjunto mnist fue exitoso, logramos una probabilidad de reconocimiento de escritura a mano condicional de 0.9795 (nlCount = 4, learnRate = 0.03 y varias eras). El objetivo principal de la prueba era probar el rendimiento de la red neuronal, con la que se enfrentó.
A continuación consideramos el trabajo en la
"tarea condicional" .
Datos de origen:-2 vectores de entrada aleatorios de 100 valores
red neuronal con generación aleatoria de pesas
-2 establecer objetivos
El código en la función main ()
{
El resultado de la red neuronal.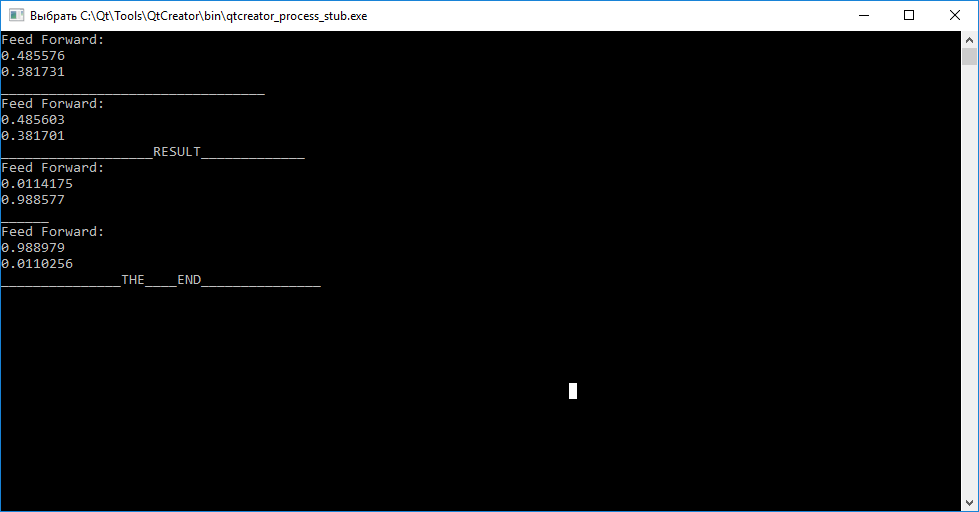
Resumen
Como puede ver, llamar a la función de consulta (entradas) antes de entrenar para cada uno de los vectores no nos permite juzgar sus diferencias. Además, al llamar a la función de tren (entrada, objetivo), para entrenar con el objetivo de organizar coeficientes de peso para que la red neuronal pueda distinguir posteriormente entre los vectores de entrada.
Después de completar el entrenamiento, observamos que el intento de mapear el vector "abc" a "tar1" y "cba" a "tar2" falló.
¡Tiene la oportunidad, usando el código fuente, de probar independientemente el rendimiento y experimentar con la configuración!PD: este código fue escrito desde QtCreator, espero que pueda reemplazar fácilmente la salida, dejar sus comentarios y comentarios.
PPS: si alguien está interesado en un análisis detallado del trabajo de struct nnLay {} write, habrá una nueva publicación.
PPPS: Espero que alguien pueda usar el código orientado "C" para portar a otras herramientas.
Código fuentemain.cpp #include <QCoreApplication> #include <QDebug> #include <QTime> #include "myneuro.h" int main(int argc, char *argv[]) { QCoreApplication a(argc, argv); myNeuro *bb = new myNeuro(); //----------------------------------INPUTS----GENERATOR------------- qsrand((QTime::currentTime().second())); float *abc = new float[100]; for(int i=0; i<100;i++) { abc[i] =(qrand()%98)*0.01+0.01; } float *cba = new float[100]; for(int i=0; i<100;i++) { cba[i] =(qrand()%98)*0.01+0.01; } //---------------------------------TARGETS----GENERATOR------------- float *tar1 = new float[2]; tar1[0] =0.01; tar1[1] =0.99; float *tar2 = new float[2]; tar2[0] =0.99; tar2[1] =0.01; //--------------------------------NN---------WORKING--------------- bb->query(abc); qDebug()<<"_________________________________"; bb->query(cba); int i=0; while(i<100000) { bb->train(abc,tar1); bb->train(cba,tar2); i++; } qDebug()<<"___________________RESULT_____________"; bb->query(abc); qDebug()<<"______"; bb->query(cba); qDebug()<<"_______________THE____END_______________"; return a.exec(); }
myNeuro.cpp #include "myneuro.h" #include <QDebug> myNeuro::myNeuro() { //-------- inputNeurons = 100; outputNeurons =2; nlCount = 4; list = (nnLay*) malloc((nlCount)*sizeof(nnLay)); inputs = (float*) malloc((inputNeurons)*sizeof(float)); targets = (float*) malloc((outputNeurons)*sizeof(float)); list[0].setIO(100,20); list[1].setIO(20,6); list[2].setIO(6,3); list[3].setIO(3,2); //----------------- // inputNeurons = 100; // outputNeurons =2; // nlCount = 2; // list = (nnLay*) malloc((nlCount)*sizeof(nnLay)); // inputs = (float*) malloc((inputNeurons)*sizeof(float)); // targets = (float*) malloc((outputNeurons)*sizeof(float)); // list[0].setIO(100,10); // list[1].setIO(10,2); } void myNeuro::feedForwarding(bool ok) { list[0].makeHidden(inputs); for (int i =1; i<nlCount; i++) list[i].makeHidden(list[i-1].getHidden()); if (!ok) { qDebug()<<"Feed Forward: "; for(int out =0; out < outputNeurons; out++) { qDebug()<<list[nlCount-1].hidden[out]; } return; } else { // printArray(list[3].getErrors(),list[3].getOutCount()); backPropagate(); } } void myNeuro::backPropagate() { //-------------------------------ERRORS-----CALC--------- list[nlCount-1].calcOutError(targets); for (int i =nlCount-2; i>=0; i--) list[i].calcHidError(list[i+1].getErrors(),list[i+1].getMatrix(), list[i+1].getInCount(),list[i+1].getOutCount()); //-------------------------------UPD-----WEIGHT--------- for (int i =nlCount-1; i>0; i--) list[i].updMatrix(list[i-1].getHidden()); list[0].updMatrix(inputs); } void myNeuro::train(float *in, float *targ) { inputs = in; targets = targ; feedForwarding(true); } void myNeuro::query(float *in) { inputs=in; feedForwarding(false); } void myNeuro::printArray(float *arr, int s) { qDebug()<<"__"; for(int inp =0; inp < s; inp++) { qDebug()<<arr[inp]; } }
myNeuro.h #ifndef MYNEURO_H #define MYNEURO_H #include <iostream> #include <math.h> #include <QtGlobal> #include <QDebug> #define learnRate 0.1 #define randWeight (( ((float)qrand() / (float)RAND_MAX) - 0.5)* pow(out,-0.5)) class myNeuro { public: myNeuro(); struct nnLay{ int in; int out; float** matrix; float* hidden; float* errors; int getInCount(){return in;} int getOutCount(){return out;} float **getMatrix(){return matrix;} void updMatrix(float *enteredVal) { for(int ou =0; ou < out; ou++) { for(int hid =0; hid < in; hid++) { matrix[hid][ou] += (learnRate * errors[ou] * enteredVal[hid]); } matrix[in][ou] += (learnRate * errors[ou]); } }; void setIO(int inputs, int outputs) { in=inputs; out=outputs; hidden = (float*) malloc((out)*sizeof(float)); matrix = (float**) malloc((in+1)*sizeof(float)); for(int inp =0; inp < in+1; inp++) { matrix[inp] = (float*) malloc(out*sizeof(float)); } for(int inp =0; inp < in+1; inp++) { for(int outp =0; outp < out; outp++) { matrix[inp][outp] = randWeight; } } } void makeHidden(float *inputs) { for(int hid =0; hid < out; hid++) { float tmpS = 0.0; for(int inp =0; inp < in; inp++) { tmpS += inputs[inp] * matrix[inp][hid]; } tmpS += matrix[in][hid]; hidden[hid] = sigmoida(tmpS); } }; float* getHidden() { return hidden; }; void calcOutError(float *targets) { errors = (float*) malloc((out)*sizeof(float)); for(int ou =0; ou < out; ou++) { errors[ou] = (targets[ou] - hidden[ou]) * sigmoidasDerivate(hidden[ou]); } }; void calcHidError(float *targets,float **outWeights,int inS, int outS) { errors = (float*) malloc((inS)*sizeof(float)); for(int hid =0; hid < inS; hid++) { errors[hid] = 0.0; for(int ou =0; ou < outS; ou++) { errors[hid] += targets[ou] * outWeights[hid][ou]; } errors[hid] *= sigmoidasDerivate(hidden[hid]); } }; float* getErrors() { return errors; }; float sigmoida(float val) { return (1.0 / (1.0 + exp(-val))); } float sigmoidasDerivate(float val) { return (val * (1.0 - val)); }; }; void feedForwarding(bool ok); void backPropagate(); void train(float *in, float *targ); void query(float *in); void printArray(float *arr,int s); private: struct nnLay *list; int inputNeurons; int outputNeurons; int nlCount; float *inputs; float *targets; }; #endif // MYNEURO_H
UPD:
Las fuentes para verificar en mnist son por
el enlace1) proyecto
"
Github.com/mamkin-itshnik/simple-neuro-network "
También hay una descripción gráfica del trabajo. Brevemente, al sondear la red con datos de prueba, se le da el valor de cada una de las neuronas de salida (10 neuronas corresponden a números del 0 al 9). Para tomar una decisión sobre la figura representada, debe conocer el índice de la neurona máxima. Dígito = índice + 1 (no olvide de dónde están numerados los números en las matrices))
2) MNIST
"
Www.kaggle.com/oddrationale/mnist-in-csv " (si necesita usar un conjunto de datos más pequeño, simplemente limite el contador while al leer el archivo CSV de la PS: hay un ejemplo para git)