Nota perev. : Los empleados de Tinder recientemente compartieron algunos de los detalles técnicos de la migración de su infraestructura a Kubernetes. El proceso tomó casi dos años y resultó en el lanzamiento en K8 de una plataforma a gran escala que consta de 200 servicios alojados en 48 mil contenedores. ¿Qué dificultades interesantes enfrentaron los ingenieros de Tinder y qué resultados obtuvieron? Lea esta traducción.
Por qué
Hace casi dos años, Tinder decidió cambiar su plataforma a Kubernetes. Kubernetes permitiría al equipo de Tinder contenerizar y cambiar a operación con un mínimo esfuerzo a través de una
implementación inmutable . En este caso, el ensamblaje de aplicaciones, su despliegue y la infraestructura en sí misma serían determinados únicamente por el código.
También buscamos una solución al problema de escalabilidad y estabilidad. Cuando el escalado se volvió crítico, a menudo tuvimos que esperar varios minutos para lanzar nuevas instancias de EC2. Por lo tanto, la idea de lanzar contenedores y comenzar a servir el tráfico en segundos en lugar de minutos nos resultó muy atractiva.
El proceso no fue fácil. Durante la migración, a principios de 2019, el clúster de Kubernetes alcanzó una masa crítica y comenzamos a enfrentar varios problemas debido a la cantidad de tráfico, el tamaño del clúster y el DNS. En este viaje, resolvimos muchos problemas interesantes relacionados con la transferencia de 200 servicios y el mantenimiento del clúster Kubernetes, que consta de 1000 nodos, 15,000 pods y 48,000 contenedores de trabajo.
Como?
Desde enero de 2018, hemos pasado por varias etapas de migración. Comenzamos por contener todos nuestros servicios e implementarlos en entornos de prueba de Kubernetes. En octubre, comenzó el proceso de transferencia metódica de todos los servicios existentes a Kubernetes. En marzo del año siguiente, se completó la "reubicación" y ahora la plataforma Tinder se ejecuta exclusivamente en Kubernetes.
Crear imágenes para Kubernetes
Tenemos más de 30 repositorios de código fuente para microservicios que se ejecutan en un clúster de Kubernetes. El código en estos repositorios está escrito en diferentes idiomas (por ejemplo, Node.js, Java, Scala, Go) con muchos entornos de tiempo de ejecución para el mismo idioma.
El sistema de compilación está diseñado para proporcionar un "contexto de compilación" totalmente personalizable para cada microservicio. Generalmente consiste en un Dockerfile y una lista de comandos de shell. Sus contenidos son totalmente personalizables y, al mismo tiempo, todos estos contextos de compilación están escritos de acuerdo con un formato estandarizado. La estandarización de los contextos de compilación permite que un único sistema de compilación maneje todos los microservicios.
 Figura 1-1. Proceso de compilación estandarizado a través del constructor de contenedores (Builder)
Figura 1-1. Proceso de compilación estandarizado a través del constructor de contenedores (Builder)Para lograr la máxima consistencia entre tiempos de ejecución, se utiliza el mismo proceso de compilación durante el desarrollo y las pruebas. Nos enfrentamos a un problema muy interesante: tuvimos que desarrollar una forma de garantizar la consistencia del entorno de ensamblaje en toda la plataforma. Para hacer esto, todos los procesos de ensamblaje se llevan a cabo dentro de un contenedor especial de
Builder .
Su implementación requirió técnicas avanzadas para trabajar con Docker. Builder hereda el ID de usuario local y los secretos (como la clave SSH, las credenciales de AWS, etc.) necesarios para acceder a los repositorios privados de Tinder. Monta directorios locales que contienen la fuente para almacenar naturalmente los artefactos de ensamblaje. Este enfoque mejora el rendimiento al eliminar la necesidad de copiar artefactos de ensamblaje entre el contenedor del generador y el host. Los artefactos de ensamblaje almacenados se pueden reutilizar sin configuración adicional.
Para algunos servicios, tuvimos que crear otro contenedor para hacer coincidir el entorno de compilación con el tiempo de ejecución (por ejemplo, durante el proceso de instalación, la biblioteca bcrypt de Node.js genera artefactos binarios específicos de la plataforma). Durante la compilación, los requisitos pueden variar para diferentes servicios, y el Dockerfile final se compila sobre la marcha.
Kubernetes Cluster Architecture and Migration
Gestión de tamaño de clúster
Decidimos usar
kube-aws para implementar automáticamente el clúster en instancias de Amazon EC2. Al principio, todo funcionaba en un grupo común de nodos. Rápidamente nos dimos cuenta de la necesidad de separar las cargas de trabajo por tamaño y tipo de instancias para un uso más eficiente de los recursos. La lógica era que el lanzamiento de varias cápsulas de subprocesos múltiples cargados resultó ser más predecible en rendimiento que su coexistencia con una gran cantidad de unidades de subprocesos simples.
Como resultado, nos decidimos por:
- m5.4xlarge - para monitoreo (Prometeo);
- c5.4xlarge : para la carga de trabajo de Node.js (carga de trabajo de subproceso único);
- c5.2xlarge : para Java y Go (carga de trabajo multiproceso);
- c5.4xlarge : para el panel de control (3 nodos).
La migracion
Uno de los pasos preparatorios para migrar de la infraestructura anterior a Kubernetes fue redirigir la interacción directa existente entre los servicios a los nuevos equilibradores de carga (ELB, Elastic Load Balancers). Se crearon en una subred específica de la nube privada virtual (VPC). Esta subred se conectó a Kubernetes VPC. Esto nos permitió migrar los módulos gradualmente, sin tener en cuenta el orden específico de las dependencias del servicio.
Estos puntos finales se crearon utilizando conjuntos ponderados de registros DNS con CNAME que apuntan a cada ELB nuevo. Para cambiar, agregamos un nuevo registro que apunta a un nuevo ELB de servicio de Kubernetes con un peso de 0. Luego configuramos el Tiempo de vida (TTL) del conjunto de registros en 0. Después de eso, los pesos viejos y nuevos se ajustaron lentamente, y finalmente se envió el 100% de la carga. al nuevo servidor. Después de completar el cambio, el valor TTL volvió a un nivel más adecuado.
Nuestros módulos Java existentes manejaban DNS TTL bajo, pero las aplicaciones Node no. Uno de los ingenieros reescribió parte del código del grupo de conexiones, envolviéndolo en un administrador que actualizaba los grupos cada 60 segundos. El enfoque elegido funcionó muy bien y sin una disminución notable en el rendimiento.
Las lecciones
Restricciones de dispositivos de red
En las primeras horas de la mañana del 8 de enero de 2019, la plataforma Tinder se estrelló de repente. En respuesta a un aumento no relacionado en la latencia de la plataforma más temprano en la mañana, aumentó el número de pods y nodos en el clúster. Esto llevó al agotamiento de la caché ARP en todos nuestros nodos.
Hay tres opciones de Linux asociadas con el caché ARP:

(
fuente )
gc_thresh3 es un límite difícil. La aparición en el registro de entradas del formulario "desbordamiento de tabla vecina" significaba que incluso después de la recolección de basura sincrónica (GC) en el caché ARP, no había suficiente espacio para almacenar el registro vecino. En este caso, el núcleo simplemente descartó completamente el paquete.
Usamos
Flannel como
tejido de red en Kubernetes. Los paquetes se transmiten a través de VXLAN. VXLAN es un túnel L2, elevado sobre una red L3. La tecnología utiliza la encapsulación MAC-in-UDP (Protocolo de datagramas de dirección MAC en usuario) y le permite expandir los segmentos de red del segundo nivel. El protocolo de transporte en la red física del centro de datos es IP más UDP.
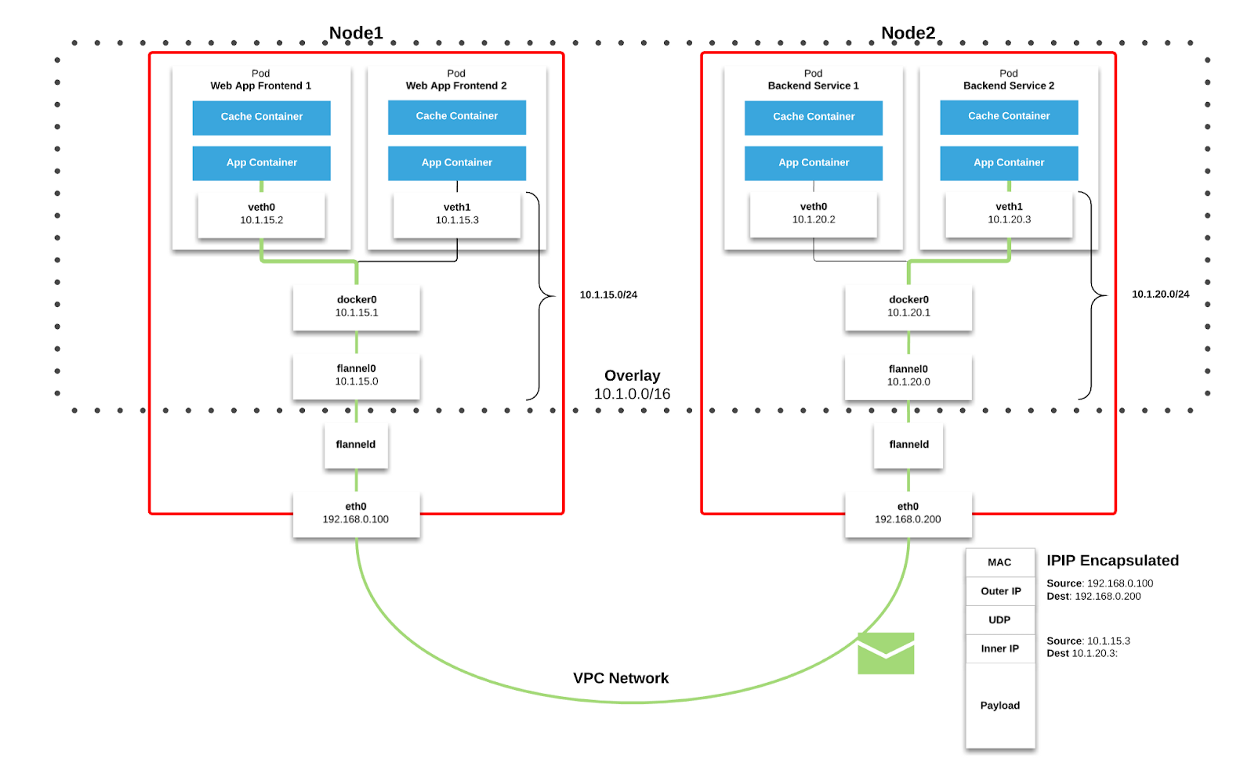 Figura 2–1. Gráfico de franela ( fuente )
Figura 2–1. Gráfico de franela ( fuente ) Figura 2–2. Paquete VXLAN ( fuente )
Figura 2–2. Paquete VXLAN ( fuente )Cada nodo de trabajo de Kubernetes asigna un espacio de dirección virtual con máscara / 24 del bloque más grande / 9. Para cada nodo, esto
significa una entrada en la tabla de enrutamiento, una entrada en la tabla ARP (en la interfaz de
franela.1 ) y una entrada en la tabla de conmutación (FDB). Se agregan cuando el nodo de trabajo se inicia por primera vez o cuando se detecta cada nuevo nodo.
Además, la conexión nodo-pod (o pod-pod) finalmente pasa por la interfaz
eth0 (como se muestra en el diagrama de franela anterior). Esto da como resultado una entrada adicional en la tabla ARP para cada fuente y destino correspondiente del nodo.
En nuestro entorno, este tipo de comunicación es muy común. Para los objetos de tipo de servicio en Kubernetes, se crea un ELB y Kubernetes registra cada nodo en el ELB. ELB no sabe nada sobre los pods y el nodo seleccionado puede no ser el destino final del paquete. El hecho es que cuando un nodo recibe un paquete de ELB, lo considera teniendo en cuenta las reglas de
iptables para un servicio en particular y selecciona aleatoriamente el pod en otro nodo.
En el momento de la falla, el clúster tenía 605 nodos. Por las razones indicadas anteriormente, esto fue suficiente para superar el
valor predeterminado de gc_thresh3 . Cuando esto sucede, no solo los paquetes comienzan a descartarse, sino que todo el espacio de dirección virtual de Franela con la máscara / 24 desaparece de la tabla ARP. Las comunicaciones del nodo de nodo y las consultas DNS se interrumpen (DNS está alojado en un clúster; consulte el resto de este artículo para obtener más detalles).
Para resolver este problema, aumente los valores de
gc_thresh1 ,
gc_thresh2 y
gc_thresh3 y reinicie Flannel para volver a registrar las redes que faltan.
Escalado de DNS inesperado
Durante el proceso de migración, utilizamos activamente DNS para administrar el tráfico y transferir gradualmente los servicios de la infraestructura anterior a Kubernetes. Establecimos valores TTL relativamente bajos para RecordSets relacionados en Route53. Cuando la infraestructura anterior se estaba ejecutando en instancias EC2, nuestra configuración de resolución apuntaba a DNS de Amazon. Lo dimos por sentado y el impacto del bajo TTL en nuestros servicios de Amazon (como DynamoDB) pasó casi desapercibido.
A medida que los servicios se migraron a Kubernetes, descubrimos que DNS maneja 250,000 consultas por segundo. Como resultado, las aplicaciones comenzaron a experimentar tiempos de espera constantes y serios para las consultas de DNS. Esto sucedió a pesar de los increíbles esfuerzos para optimizar y cambiar el proveedor de DNS a CoreDNS (que alcanzó 1000 pods ejecutándose en 120 núcleos en la carga máxima).
Al explorar otras posibles causas y soluciones, encontramos
un artículo que describe las condiciones de carrera que afectan el marco de filtrado de paquetes de
netfilter en Linux. Los tiempos de espera que observamos, junto con el creciente contador
insert_failed en la interfaz de Flannel, correspondían a las conclusiones del artículo.
El problema surge en la etapa de traducción de direcciones de red de origen y destino (SNAT y DNAT) y la posterior entrada en la tabla
conntrack . Una de las soluciones discutidas dentro de la empresa y propuesta por la comunidad fue la transferencia de DNS al propio nodo de trabajo. En este caso:
- SNAT no es necesario porque el tráfico permanece dentro del nodo. No necesita enrutarse a través de la interfaz eth0 .
- No se necesita DNAT, porque la IP de destino es local para el host, y no un pod seleccionado al azar según las reglas de iptables .
Decidimos mantener este enfoque. CoreDNS se implementó como DaemonSet en Kubernetes e implementamos un servidor DNS host local en
resolv.conf de cada pod configurando el
indicador --cluster-dns del comando
kubelet . Esta solución ha demostrado ser efectiva para los tiempos de espera de DNS.
Sin embargo, aún observamos la pérdida de paquetes y un aumento en el contador
insert_failed en la interfaz de Flannel. Esta situación continuó después de la introducción de la solución, ya que pudimos excluir SNAT y / o DNAT solo para el tráfico DNS. Las condiciones de carrera persistieron para otros tipos de tráfico. Afortunadamente, la mayoría de nuestros paquetes son TCP, y cuando ocurre un problema, simplemente se retransmiten. Todavía estamos tratando de encontrar una solución adecuada para todo tipo de tráfico.
Uso de Envoy para un mejor equilibrio de carga
A medida que migramos los servicios de back-end a Kubernetes, comenzamos a sufrir una carga desequilibrada entre los pods. Descubrimos que debido a HTTP Keepalive, las conexiones ELB colgaban en los primeros módulos listos para usar de cada implementación de implementación. Por lo tanto, la mayor parte del tráfico pasó por un pequeño porcentaje de los pods disponibles. La primera solución que probamos fue establecer el parámetro MaxSurge al 100% en nuevas implementaciones para los peores casos. El efecto fue insignificante y poco prometedor en términos de despliegues más grandes.
Otra solución que utilizamos fue aumentar artificialmente las solicitudes de recursos para servicios de misión crítica. En este caso, las vainas adyacentes tendrían más margen de maniobra que otras vainas pesadas. A la larga, tampoco funcionaría debido al desperdicio de recursos. Además, nuestras aplicaciones Node tenían un solo subproceso y, en consecuencia, solo podían usar un núcleo. La única solución real era utilizar un mejor equilibrio de carga.
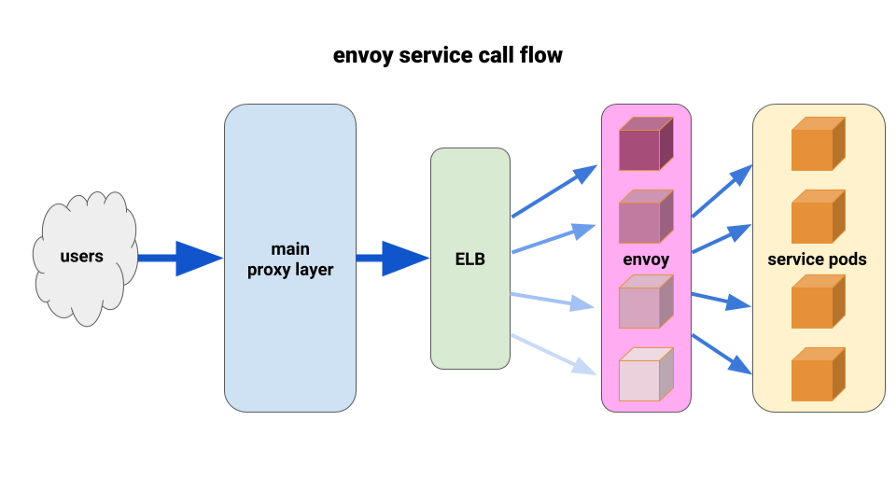
Durante mucho tiempo hemos querido apreciar plenamente a
Envoy . La situación actual nos permitió implementarlo de manera muy limitada y obtener resultados inmediatos. Envoy es un proxy de séptimo nivel de código abierto y alto rendimiento diseñado para grandes aplicaciones SOA. Es capaz de aplicar técnicas avanzadas de equilibrio de carga, incluidos reintentos automáticos, disyuntores y límites de velocidad globales.
( Nota de traducción : para obtener más detalles, consulte el artículo reciente sobre Istio, la malla de servicios, que se basa en Envoy).Se nos ocurrió la siguiente configuración: tener un sidecar Envoy para cada pod y una ruta única, y el clúster: conectarse al contenedor localmente por puerto. Para minimizar la cascada potencial y mantener un pequeño radio de "daño", utilizamos el parque de pod de proxy frontal Envoy, uno para cada Zona de disponibilidad (AZ) para cada servicio. Recurrieron a un mecanismo de descubrimiento de servicio simple escrito por uno de nuestros ingenieros, que simplemente devolvió una lista de pods en cada AZ para un servicio dado.
Luego, los enviados frontales del servicio utilizaron este mecanismo de descubrimiento de servicios con un clúster y una ruta aguas arriba. Establecimos tiempos de espera adecuados, aumentamos la configuración de todos los disyuntores y agregamos una configuración de reintento mínima para ayudar con fallas individuales y garantizar implementaciones sin problemas. Antes de cada uno de estos enviados frontales de servicio, colocamos un ELB TCP. Incluso si el keepalive de nuestra capa de proxy principal colgara en algunas cápsulas de Envoy, aún podrían manejar la carga mucho mejor y se establecerían para equilibrarse al menos a través de la solicitud en el backend.
Para la implementación, utilizamos el gancho preStop tanto en los pods de aplicaciones como en los sidecar. El enlace inició un error al verificar el estado del punto final de administración ubicado en el contenedor del sidecar y "durmió" durante un tiempo para permitir que se completen las conexiones activas.
Una de las razones por las que hemos podido avanzar tan rápido en la resolución de problemas está relacionada con las métricas detalladas que pudimos integrar fácilmente en una instalación estándar de Prometheus. Con ellos se hizo posible ver exactamente lo que estaba sucediendo mientras seleccionábamos los parámetros de configuración y redistribuíamos el tráfico.
Los resultados fueron inmediatos y obvios. Comenzamos con los servicios más desequilibrados y, en este momento, ya funciona antes que los 12 servicios más importantes del clúster. Este año planeamos pasar a una malla de servicio completa con descubrimiento de servicio más avanzado, interrupción de circuitos, detección de valores atípicos, limitación de velocidad y rastreo.
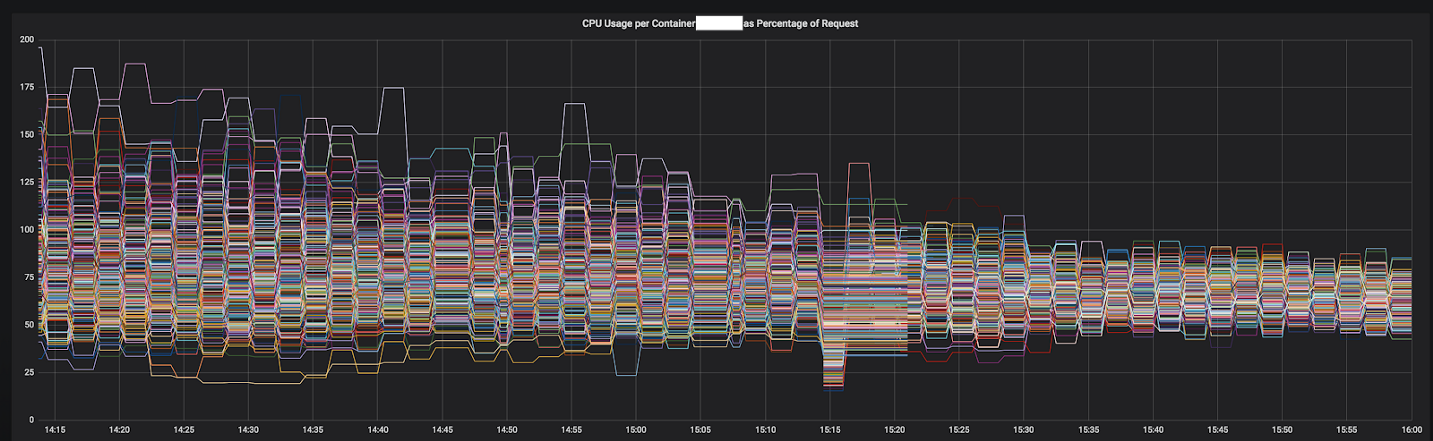 Figura 3–1. Convergencia de CPU de un servicio durante la transición a Envoy
Figura 3–1. Convergencia de CPU de un servicio durante la transición a Envoy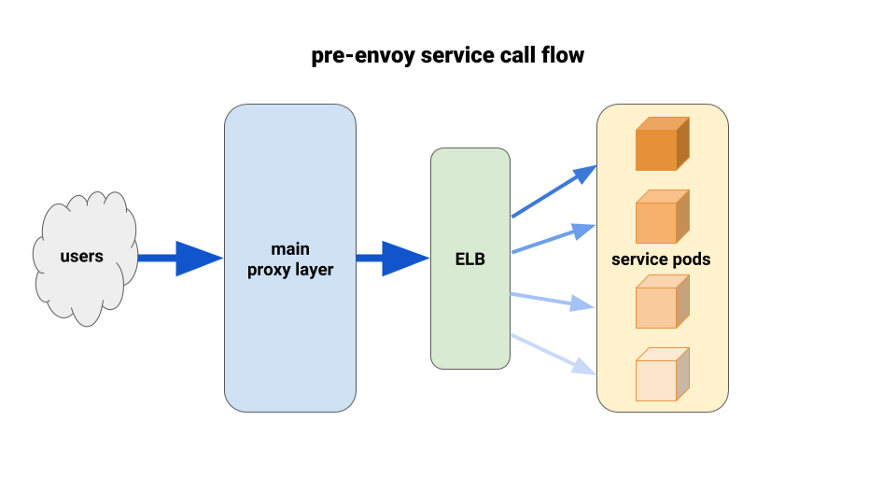
Resultado final
Gracias a nuestra experiencia e investigación adicional, hemos creado un fuerte equipo de infraestructura con buenas habilidades para diseñar, implementar y operar grandes grupos de Kubernetes. Ahora todos los ingenieros de Tinder tienen el conocimiento y la experiencia sobre cómo empacar contenedores e implementar aplicaciones en Kubernetes.
Cuando surgió la necesidad de capacidades adicionales en la infraestructura anterior, tuvimos que esperar varios minutos para lanzar nuevas instancias de EC2. Ahora los contenedores se inician y comienzan a procesar el tráfico durante varios segundos en lugar de minutos. La programación de múltiples contenedores en una sola instancia de EC2 también proporciona una concentración horizontal mejorada. Como resultado, en 2019, pronosticamos una reducción significativa en los costos de EC2 en comparación con el año pasado.
La migración tardó casi dos años, pero la completamos en marzo de 2019. Actualmente, la plataforma Tinder se ejecuta exclusivamente en el clúster Kubernetes, que consta de 200 servicios, 1000 nodos, 15,000 pods y 48,000 contenedores en ejecución. La infraestructura ya no es responsabilidad exclusiva de los equipos operativos. Todos nuestros ingenieros comparten esta responsabilidad y controlan el proceso de construcción e implementación de sus aplicaciones utilizando solo código.
PD del traductor
Lea también nuestra serie de artículos en nuestro blog: