En la última reunión interna de Pyrus, hablamos sobre el almacenamiento distribuido moderno, y Maxim Nalsky, CEO y fundador de Pyrus, compartió su primera impresión de FoundationDB. En este artículo, hablamos sobre los matices técnicos que enfrenta al elegir una tecnología para escalar el almacenamiento de datos estructurados.
Cuando el servicio no está disponible para los usuarios durante algún tiempo, es muy desagradable, pero aún no mortal. Pero perder los datos del cliente es absolutamente inaceptable. Por lo tanto, evaluamos escrupulosamente cualquier tecnología para almacenar datos de dos a tres docenas de parámetros.
Algunos de ellos dictan la carga actual en el servicio.
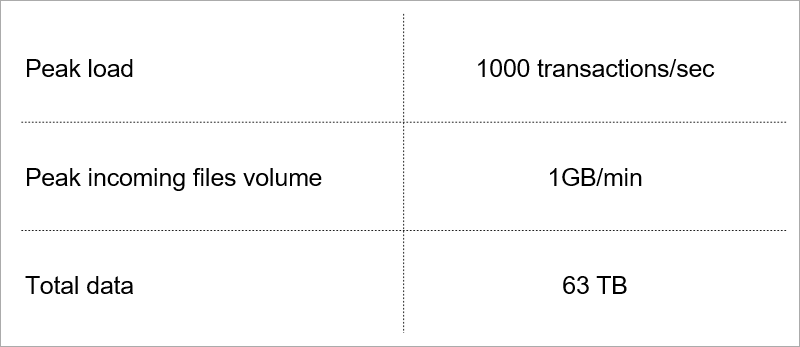 Carga actual. Seleccionamos tecnología teniendo en cuenta el crecimiento de estos indicadores.
Carga actual. Seleccionamos tecnología teniendo en cuenta el crecimiento de estos indicadores.Arquitectura del servidor del cliente
El modelo clásico de cliente-servidor es el ejemplo más simple de un sistema distribuido. Un servidor es un punto de sincronización; permite que varios clientes hagan algo juntos de manera coordinada.
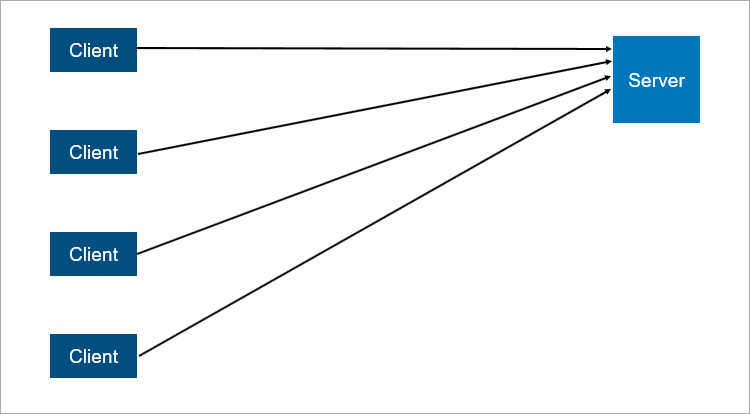 Un esquema muy simplificado de interacción cliente-servidor.
Un esquema muy simplificado de interacción cliente-servidor.¿Qué es poco confiable en la arquitectura cliente-servidor? Obviamente, el servidor puede fallar. Y cuando el servidor falla, todos los clientes no pueden trabajar. Para evitar esto, a la gente se le ocurrió una conexión maestro-esclavo (que ahora es
políticamente correcta llamada líder-seguidor ). La conclusión es que hay dos servidores, todos los clientes se comunican con el principal, y en el segundo todos los datos simplemente se replican.
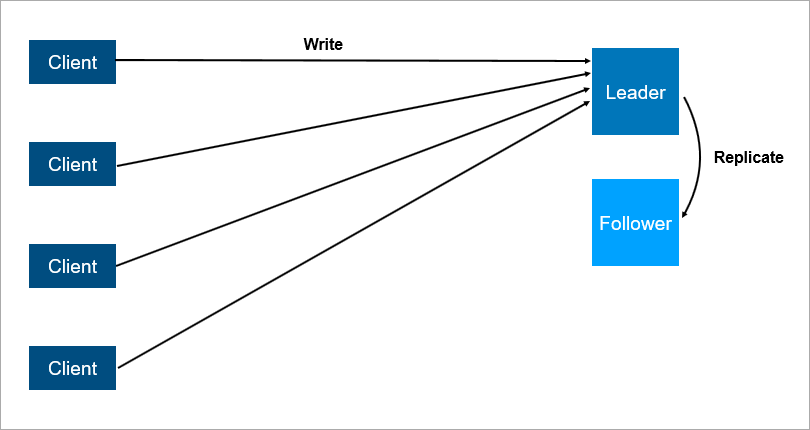 Arquitectura cliente-servidor con replicación de datos a seguidores.
Arquitectura cliente-servidor con replicación de datos a seguidores.Está claro que este es un sistema más confiable: si el servidor principal falla, entonces una copia de todos los datos está en el seguidor y se puede generar rápidamente.
Es importante comprender cómo funciona la replicación. Si es sincrónico, la transacción debe almacenarse simultáneamente en el líder y en el seguidor, y esto puede ser lento. Si la replicación es asíncrona, puede perder algunos de los datos después de una conmutación por error.
¿Y qué pasará si el líder cae de noche cuando todos están durmiendo? Hay datos sobre el seguidor, pero nadie le dijo que ahora es un líder y que los clientes no se conectan con él. Bien, dotemos al seguidor con la lógica de que comienza a considerarse lo más importante cuando se pierde la conexión con el líder. Entonces podemos obtener fácilmente un cerebro dividido, un conflicto cuando la conexión entre el líder y el seguidor se rompe, y ambos piensan que son los principales. Esto realmente sucede en muchos sistemas,
como RabbitMQ , la tecnología de colas más popular de la actualidad.
Para resolver estos problemas, organice la conmutación por error automática: agregue un tercer servidor (testigo, testigo). Asegura que solo tengamos un líder. Y si el líder se cae, el seguidor se enciende automáticamente con un tiempo de inactividad mínimo, que puede reducirse a unos segundos. Por supuesto, los clientes en este esquema deben conocer de antemano las direcciones del líder y seguidor e implementar la lógica de reconexión automática entre ellos.
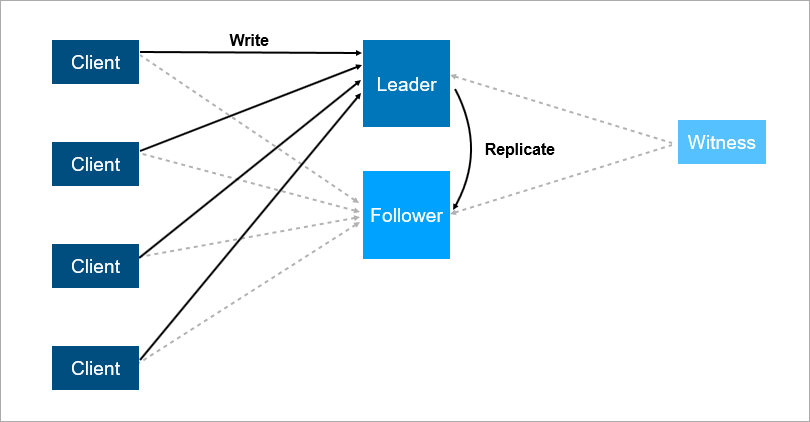 El testigo garantiza que solo hay un líder. Si el líder se cae, el seguidor se enciende automáticamente.
El testigo garantiza que solo hay un líder. Si el líder se cae, el seguidor se enciende automáticamente.Tal sistema ahora funciona con nosotros. Hay una base de datos principal, una base de datos de repuesto, hay un testigo y sí, a veces venimos por la mañana y vemos que el cambio ocurrió por la noche.
Pero este esquema también tiene inconvenientes. Imagine que está instalando service packs o actualizando el sistema operativo en un servidor líder. Antes de eso, cambiaste manualmente la carga en el seguidor y luego ... ¡se cae! Desastre, su servicio no está disponible. ¿Qué hacer para protegerte de esto? Agregue un tercer servidor de respaldo, otro seguidor. El tres es una especie de número mágico. Si desea que el sistema funcione de manera confiable, dos servidores no son suficientes, necesita tres. Uno para mantenimiento, el segundo cae, el tercero permanece.
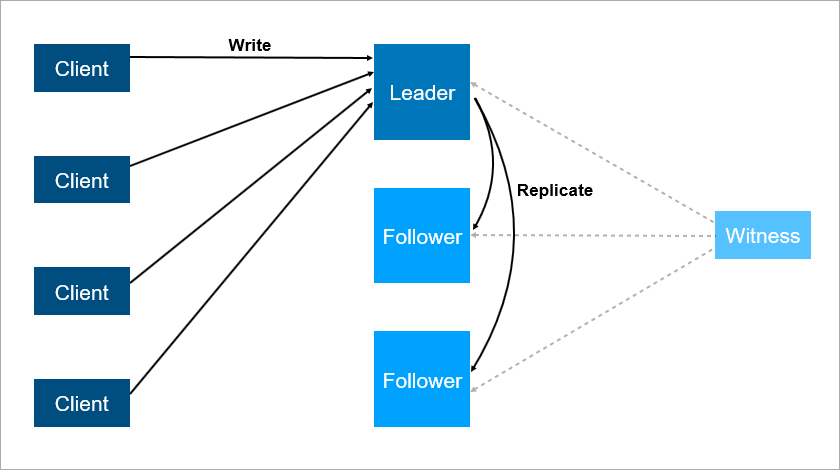 El tercer servidor proporciona un funcionamiento confiable si los dos primeros no están disponibles.
El tercer servidor proporciona un funcionamiento confiable si los dos primeros no están disponibles.Para resumir, la redundancia debe ser igual a dos. Una redundancia de uno no es suficiente. Por esta razón, en las matrices de discos, las personas comenzaron a usar el esquema RAID6 en lugar de RAID5, sobreviviendo la caída de dos discos a la vez.
Transacciones
Son bien conocidos cuatro requisitos básicos de transacción: atomicidad, consistencia, aislamiento y durabilidad (Atomicidad, Consistencia, Aislamiento, Durabilidad - ACID).
Cuando hablamos de bases de datos distribuidas, queremos decir que los datos deben ser escalados. La lectura se escala muy bien: miles de transacciones pueden leer datos en paralelo sin ningún problema. Pero cuando otras transacciones escriben datos al mismo tiempo que la lectura, son posibles varios efectos indeseables. Es muy fácil obtener una situación en la que una transacción leerá diferentes valores de los mismos registros. Aquí hay algunos ejemplos.
Lecturas sucias. En la primera transacción, enviamos la misma solicitud dos veces: tome todos los usuarios cuyo ID = 1. Si la segunda transacción cambia esta línea y luego revierte, la base de datos no verá ningún cambio por un lado, pero por otro la primera transacción leerá diferentes valores de edad para Joe.
 Lecturas no repetibles.
Lecturas no repetibles. Otro caso es si la transacción de escritura se completó con éxito y la transacción de lectura recibió datos diferentes durante la ejecución de la misma solicitud.

En el primer caso, el cliente leyó datos que generalmente estaban ausentes en la base de datos. En el segundo caso, el cliente lee ambas veces los datos de la base de datos, pero son diferentes, aunque la lectura se produce dentro de la misma transacción.
Las lecturas fantasmas son cuando volvemos a leer un rango dentro de la misma transacción y obtenemos un conjunto diferente de líneas. En algún lugar en el medio, otra transacción ingresó e insertó o eliminó registros.

Para evitar estos efectos indeseables, los DBMS modernos implementan mecanismos de bloqueo (una transacción restringe el acceso a los datos con los que está trabajando actualmente para otras transacciones) o el control de versiones multiversion,
MVCC (una transacción nunca cambia los datos grabados previamente y siempre crea una nueva versión).
El estándar ANSI / ISO SQL define 4 niveles de aislamiento para transacciones que afectan su grado de bloqueo mutuo. Cuanto mayor sea el nivel de aislamiento, menos efectos indeseables. El precio de esto es ralentizar la aplicación (ya que las transacciones a menudo esperan desbloquear los datos que necesitan) y aumentar la probabilidad de puntos muertos.
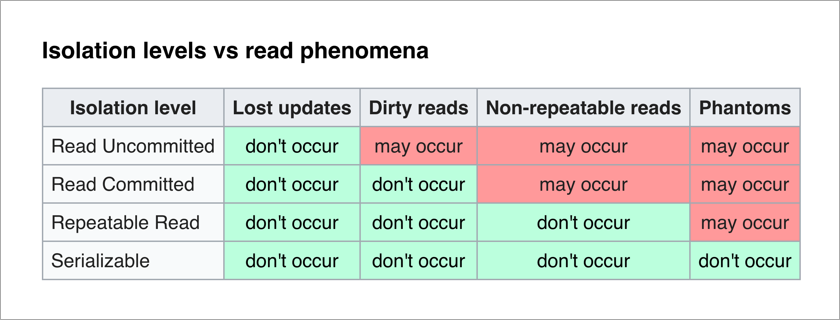
Lo más divertido para un programador de aplicaciones es el nivel Serializable: no hay efectos indeseables y toda la complejidad de garantizar la integridad de los datos se transfiere al DBMS.
Pensemos en la implementación ingenua del nivel Serializable: con cada transacción, simplemente bloqueamos a todos los demás. Teóricamente, cada transacción de escritura puede realizarse en 50 µs (el tiempo de una operación de escritura en discos SSD modernos). Y queremos guardar datos en tres máquinas, ¿recuerdas? Si están en el mismo centro de datos, la grabación durará de 1 a 3 ms. Y si, por confiabilidad, se encuentran en diferentes ciudades, la grabación puede tomar fácilmente 10-12 ms (el tiempo de viaje de un paquete de red de Moscú a San Petersburgo y viceversa). Es decir, con una implementación ingenua del nivel Serializable mediante grabación secuencial, no podemos realizar más de 100 transacciones por segundo. ¡Mientras que un SSD separado le permite realizar aproximadamente 20,000 operaciones de escritura por segundo!
Conclusión: las transacciones de escritura deben realizarse en paralelo, y para escalarlas, necesita un buen mecanismo de resolución de conflictos.
Sharding
¿Qué hacer cuando los datos dejan de llegar a un servidor? Hay dos mecanismos de zoom estándar:
- Vertical cuando solo agregamos memoria y discos a este servidor. Esto tiene sus límites, en términos de la cantidad de núcleos por procesador, la cantidad de procesadores y la cantidad de memoria.
- Horizontal, cuando usamos muchas máquinas y distribuimos datos entre ellas. Los conjuntos de tales máquinas se denominan grupos. Para colocar los datos en un clúster, deben estar fragmentados, es decir, para cada registro, determinar en qué servidor se ubicará.
Una clave de particionamiento es un parámetro mediante el cual los datos se distribuyen entre servidores, por ejemplo, un identificador de cliente u organización.
Imagine que necesita registrar datos sobre todos los habitantes de la Tierra en un grupo. Como clave de fragmento, puede tomar, por ejemplo, el año de nacimiento de la persona. Entonces serán suficientes 116 servidores (y cada año será necesario agregar un nuevo servidor). O puede tomar como clave el país donde vive la persona, luego necesitará aproximadamente 250 servidores. Aún así, la primera opción es preferible, porque la fecha de nacimiento de la persona no cambia y nunca necesitará transferir datos sobre él entre los servidores.
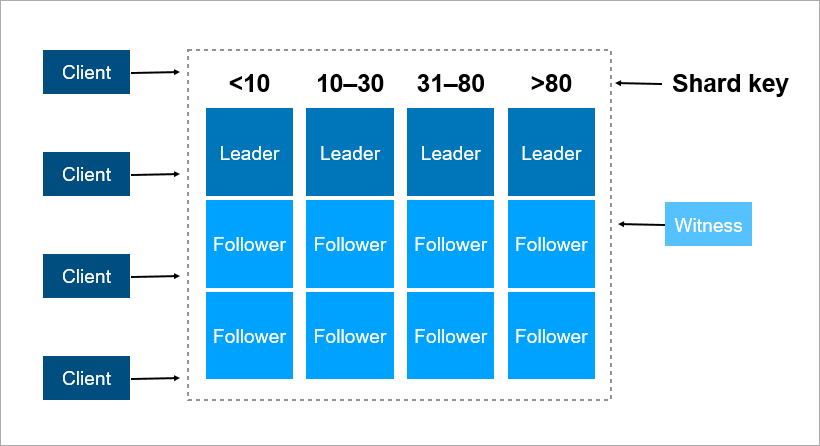
En Pyrus, puede tomar una organización como clave de fragmentación. Pero son muy diferentes en tamaño: hay un enorme Sovcombank (más de 15 mil usuarios) y miles de pequeñas empresas. Cuando asigna a una organización un servidor específico, no sabe de antemano cómo crecerá. Si la organización es grande y usa el servicio de manera activa, tarde o temprano sus datos dejarán de colocarse en un servidor y tendrá que volver a compartirlos. Y esto no es fácil si los datos son terabytes. Imagínese: un sistema cargado, las transacciones continúan cada segundo, y en estas condiciones necesita mover datos de un lugar a otro. No puede detener el sistema, ese volumen puede bombearse durante varias horas y los clientes comerciales no sobrevivirán a un tiempo de inactividad tan largo.
Como clave de fragmentación, es mejor elegir datos que rara vez cambian. Sin embargo, lejos de ser siempre una tarea aplicada, esto es fácil de hacer.
Consenso en el cluster
Cuando hay muchas máquinas en el clúster y algunas pierden contacto con las otras, ¿cómo decidir quién almacena la última versión de los datos? Simplemente asignar un servidor testigo no es suficiente, porque también puede perder contacto con todo el clúster. Además, en una situación de cerebro dividido, varias máquinas pueden registrar diferentes versiones de los mismos datos, y usted necesita determinar de alguna manera cuál es la más relevante. Para resolver este problema, a las personas se les ocurrieron algoritmos de consenso. Permiten que varias máquinas idénticas lleguen a un solo resultado en cualquier tema mediante votación. En 1989, se publicó el primer algoritmo de este tipo,
Paxos , y en 2014, los muchachos de Stanford idearon una
balsa más simple para implementar. Estrictamente hablando, para que un grupo de servidores (2N + 1) llegue a un consenso, es suficiente que al mismo tiempo no tenga más de N fallas. Para sobrevivir a 2 fallas, el clúster debe tener al menos 5 servidores.
Escala relacional de DBMS
La mayoría de las bases de datos a las que los desarrolladores están acostumbrados a trabajar con soporte de álgebra relacional. Los datos se almacenan en tablas y, en ocasiones, debe unir los datos de diferentes tablas mediante la operación JOIN. Considere un ejemplo de una base de datos y una consulta simple.
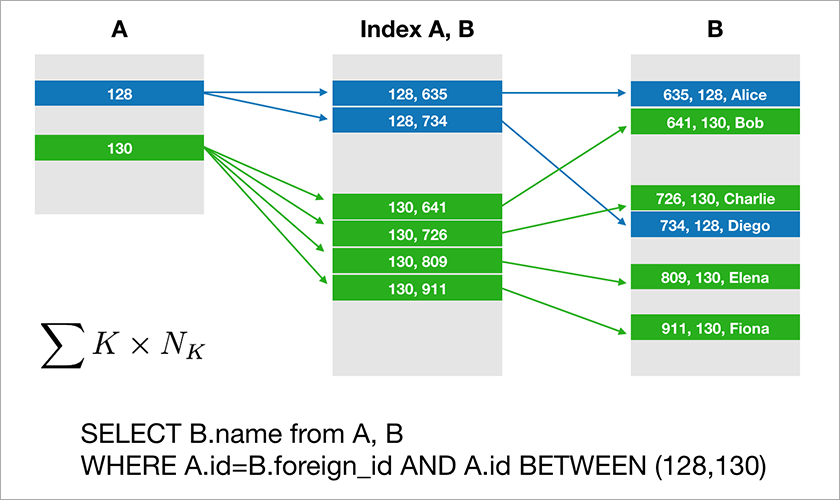
Suponga que A.id es una clave primaria con un índice agrupado. Luego, el optimizador creará un plan que probablemente primero seleccionará los registros necesarios de la tabla A y luego tomará los enlaces apropiados a los registros de la tabla B desde un índice adecuado (A, B). El tiempo de ejecución de esta consulta aumenta logarítmicamente a partir del número de registros en las tablas.
Ahora imagine que los datos se distribuyen a través de cuatro servidores en el clúster y que necesita ejecutar la misma consulta:
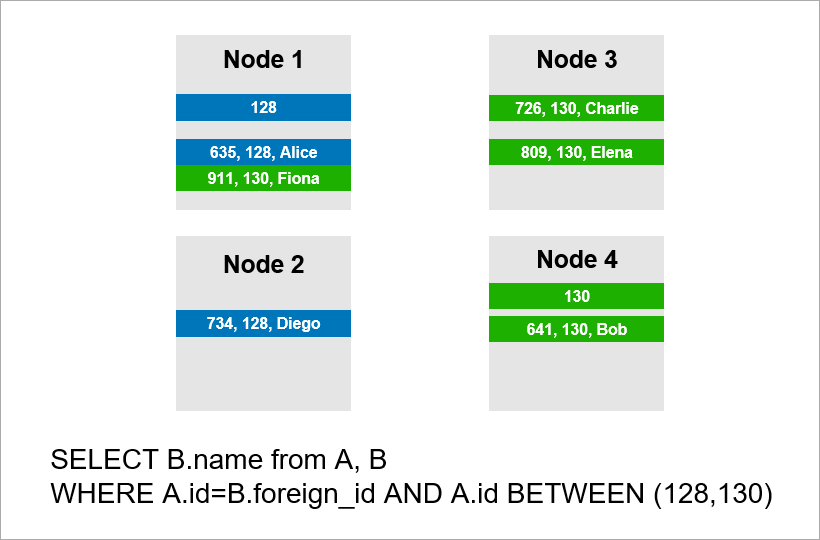
Si el DBMS no quiere ver todos los registros de todo el clúster, entonces probablemente intentará encontrar registros con A.id igual a 128, 129 o 130 y buscar los registros apropiados para ellos en la tabla B. Pero si A.id no es una clave de fragmento, entonces el DBMS por adelantado no se puede saber en qué servidor se encuentran los datos de la tabla A. De todos modos, tendrá que ponerse en contacto con todos los servidores para averiguar si hay registros A.id adecuados para nuestra condición. Luego, cada servidor puede hacer una UNIÓN dentro de sí mismo, pero esto no es suficiente. Usted ve, necesitamos el registro en el nodo 2 en la muestra, pero no hay registro con A.id = 128? Si los nodos 1 y 2 se unirán independientemente, entonces el resultado de la consulta estará incompleto; no recibiremos parte de los datos.
Por lo tanto, para cumplir con esta solicitud, cada servidor debe recurrir a todos los demás. El tiempo de ejecución crece de forma cuadrática con el número de servidores. (Tiene suerte si puede fragmentar todas las tablas con la misma clave, entonces no necesita rastrear todos los servidores. Sin embargo, en la práctica esto no es realista: siempre habrá consultas en las que la recuperación no se base en la clave de fragmentación).
Por lo tanto, las operaciones de JOIN escalan fundamentalmente deficientemente y este es un problema fundamental del enfoque relacional.
Enfoque NoSQL
Las dificultades para escalar los DBMS clásicos han llevado a las personas a crear bases de datos NoSQL que no tienen operaciones JOIN. No se une, no hay problema. Pero no hay propiedades ACID, pero no mencionaron esto en los materiales de marketing.
Artesanos rápidamente
encontrados que prueban la fuerza de varios sistemas distribuidos y
publican los resultados públicamente . Resultó que hay escenarios en los que el
clúster Redis pierde el 45% de los datos almacenados, el clúster RabbitMQ - 35% de los mensajes ,
MongoDB - 9% de los registros ,
Cassandra - hasta el 5% . Y estamos hablando
de la pérdida después de que el clúster informó al cliente sobre el guardado exitoso. Por lo general, espera un mayor nivel de confiabilidad de la tecnología elegida.
Google ha desarrollado la base de datos
Spanner , que opera globalmente en todo el mundo. Spanner garantiza propiedades ACID, serialización y más. Tienen relojes atómicos en los centros de datos que proporcionan una hora precisa, y esto le permite crear un orden global de transacciones sin tener que reenviar paquetes de red entre continentes. La idea de Spanner es que es mejor para los programadores abordar los problemas de rendimiento que surgen con una gran cantidad de transacciones que las muletas en torno a la falta de transacciones. Sin embargo, Spanner es una tecnología cerrada, no le conviene si por alguna razón no desea depender de un proveedor.
Los nativos de Google desarrollaron un análogo de código abierto de Spanner y lo llamaron CockroachDB ("cucaracha" en inglés "cucaracha", que debería simbolizar la capacidad de supervivencia de la base de datos). Sobre Habré
ya escribió sobre la falta de disponibilidad del producto para la producción, porque el clúster estaba perdiendo datos. Decidimos revisar la nueva versión 2.0 y llegamos a una conclusión similar. No perdimos los datos, pero algunas de las consultas más simples se ejecutaron sin razón.
Como resultado, hoy existen bases de datos relacionales que se escalan bien solo verticalmente, lo cual es costoso. Y hay soluciones NoSQL sin transacciones y sin garantías ACID (si desea ACID, escriba muletas).
¿Cómo hacer aplicaciones de misión crítica en las que los datos no caben en un servidor? Aparecen nuevas soluciones en el mercado, y sobre una de ellas,
FoundationDB , le contaremos más en el próximo artículo.