
Hola Habr! Mi nombre es Stanislav Semenov, estoy trabajando en tecnologías para extraer datos de documentos en R&D ABBYY. En este artículo hablaré sobre los enfoques básicos para el procesamiento de documentos semiestructurados (facturas, recibos de efectivo, etc.) que utilizamos recientemente y que estamos utilizando en este momento. Y hablaremos sobre cómo los métodos de aprendizaje automático son aplicables para resolver este problema.
Consideraremos las facturas como documentos, porque en el mundo están muy extendidos y tienen mayor demanda en términos de extracción de datos. Por cierto, el procesamiento automático de facturas es uno de los escenarios más populares entre nuestros clientes extranjeros. Por ejemplo, con ABBYY FlexiCapture, American PepsiCo Imaging Technology
redujo el tiempo de procesamiento de facturas y la cantidad de errores debidos al ingreso manual, mientras que el minorista europeo Sportina
comenzó a ingresar datos de cuentas en sistemas contables
2 veces más rápido .
Las facturas son documentos que se utilizan en la práctica comercial internacional y son de gran importancia para los negocios. Algo similar a una factura en Rusia es, por ejemplo, una hoja de ruta. Los datos de dichos documentos se encuentran en varios sistemas de contabilidad, y los errores allí, por decirlo suavemente, no son bienvenidos.
Una factura ordinaria puede considerarse bastante estructurada; contiene dos clases principales de objetos:
- varios campos del encabezado (número de documento, fecha, remitente, destinatario, total, etc.),
- Los datos tabulares son una lista de bienes y servicios (cantidad, precio, descripción, etc.).
Así es como se ve:
Millones de horas hombre se gastan anualmente en el procesamiento de facturas. Y es muy costoso. Según diversas estimaciones, para una empresa, el procesamiento de una factura en papel cuesta de $ 10 a $ 40, donde una parte importante de estos costos es mano de obra manual para ingresar y conciliar datos.
Hay empresas que procesan millones de facturas por mes. Para hacer esto, contienen un equipo completo de cientos, y algunas veces miles de personas. Es fácil estimar que un aumento en la precisión del reconocimiento o la eficiencia de extracción de datos de solo el 1% puede reducir los costos de las grandes empresas en cientos de miles e incluso millones de dólares anualmente.
Por otro lado, hay una cantidad catastrófica de documentos. En 2017, Billentis
estimó el número total de facturas / facturas generadas por año en el mundo en 400 mil millones. De estos, solo alrededor del 10% eran electrónicos, y el resto requiere una entrada totalmente manual o una participación humana intensiva. Si imprime 400 mil millones de documentos en papel A4 estándar, ¡son miles de camiones de papel por día, o una pila de papel de aproximadamente una altura humana por segundo!
Algunas palabras sobre cómo se desarrolló la tecnología

Muchas compañías están desarrollando software especializado que puede reconocer documentos y extraer datos de ellos. Pero la calidad del procesamiento de facturas aún no es perfecta. "¿Cuál es el problema?" - usted pregunta
Se trata de una gran variedad de facturas. No existen estándares para las facturas, y cada compañía es libre de crear su propia versión del documento: el tipo, la estructura y la ubicación de los campos.
Buscar campos por palabras clave
Los primeros intentos de extraer datos se redujeron a encontrar palabras clave especiales entre todas las palabras reconocidas, como, por ejemplo, Número de factura o Total, y luego en el pequeño vecindario de estas palabras, por ejemplo, a la derecha o al final, para encontrar los significados por sí mismas.
Ubicación del número de factura en diferentes facturas (se puede hacer clic):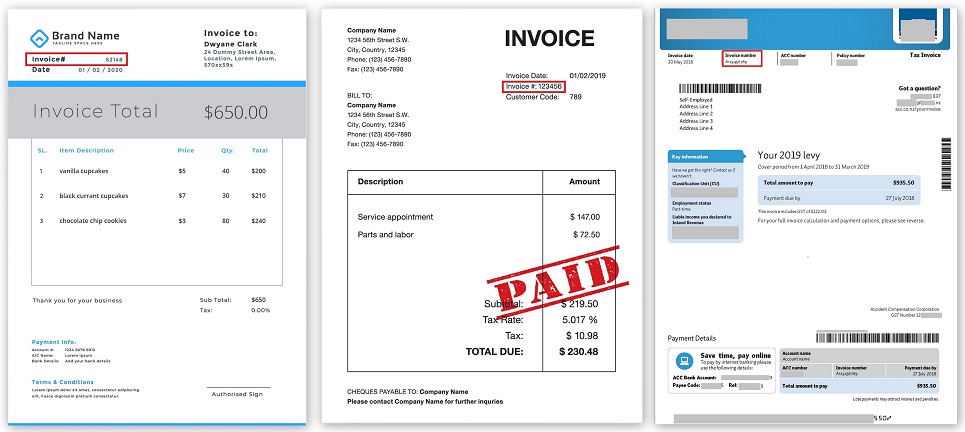
Se programó toda la lógica, que existen tales campos, están en tal y tal lugar del documento, alrededor de ellos hay otros campos a algunas distancias. Y esto de alguna manera funcionó hasta que apareció otra compañía, que comenzó a enviar sus documentos en una forma completamente diferente. O la compañía anterior cambió repentinamente el formato y todo dejó de funcionar.
Patrones
Combatir esto, cada vez que reprogramaba algo, era irracional. Por lo tanto, un nuevo paradigma vino al rescate: el uso de plantillas.
Una plantilla es un conjunto de campos que deben encontrarse en un documento y un conjunto de reglas sobre cómo encontrar estos campos. La principal ventaja aquí es que las plantillas se crean visualmente. Por ejemplo, queremos buscar el Número de factura y el Total, seleccionar estos campos y configurar los parámetros para que tal y tal campo aparezca inmediatamente después de tal y tal palabra clave, se encuentra en la parte superior del documento y contiene números y signos de puntuación.
Se desarrollaron herramientas especializadas, los llamados editores de plantillas, donde los usuarios ya avanzados sin la ayuda de programadores podían establecer rápidamente algún tipo de lógica manualmente. Tan pronto como llegó un documento de un nuevo formulario, se creó una plantilla para él y todo comenzó a funcionar más o menos.
Plantilla de muestra (clicable):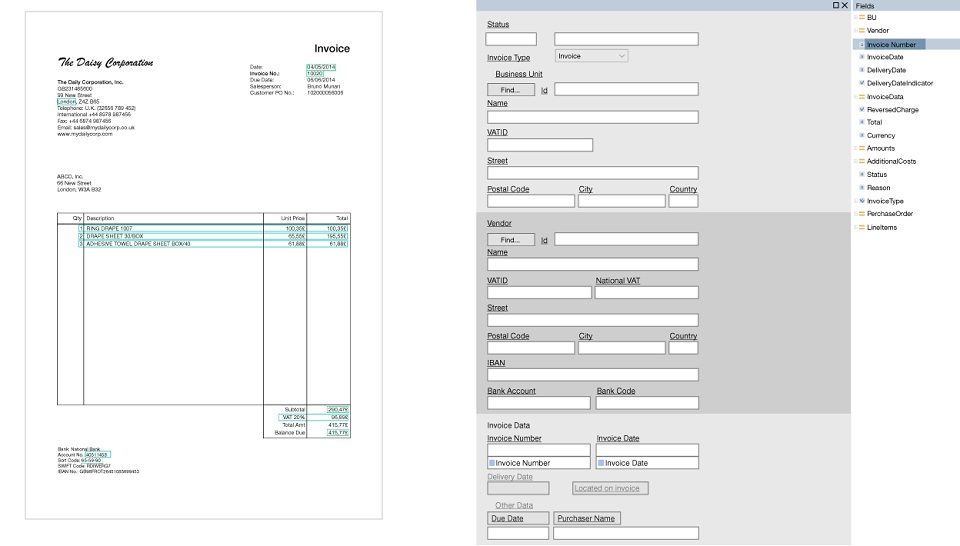
Pero para hacer una plantilla no es suficiente, deben hacerse cientos e incluso miles. Y, por lo tanto, configurar un producto para cada cliente a veces puede llevar mucho tiempo. Es imposible crear plantillas "universales" de antemano, que cubrirán toda la variedad de facturas.
Usando plantillas, puede mejorar significativamente la calidad de la recuperación de la tabla. Pero a menudo se encuentran estructuras de tablas complejas, con representación de datos no estándar, varios niveles de anidamiento, y las plantillas en estos casos no siempre funcionan bien. De nuevo, debe escribir algunos scripts que contienen muchos parámetros, condiciones, excepciones, etc. seleccionados manualmente.
Usando Machine Learning
La tecnología actual no se detiene, y con el desarrollo del aprendizaje automático, fue posible transferir la tarea de extraer datos de documentos a redes neuronales.
Hoy en día, hay varios enfoques básicos que se utilizan en la práctica:
- El primer enfoque es trabajar directamente con la imagen de entrada del documento. Es decir, una imagen (imagen) o fragmento se alimenta a la entrada de la red, y la red aprende a encontrar áreas pequeñas donde se encuentran los campos necesarios, y luego el texto en estas áreas se reconoce utilizando las tecnologías clásicas de OCR (reconocimiento óptico de caracteres). Esta es una solución integral que se puede implementar rápidamente. Puede tomar una red preparada para buscar objetos en imágenes, por ejemplo, YOLO o F-R-CNN más rápida y entrenarla en imágenes marcadas de documentos.
La desventaja de este enfoque no es la mejor calidad de los datos extraídos y la dificultad de extraer tablas. De hecho, este enfoque es de alguna manera similar a la tarea de encontrar las palabras correctas en la imagen (localización de palabras), un problema fundamental del campo de la visión por computadora, solo que aquí no buscamos las palabras, sino los campos necesarios. - El segundo enfoque es procesar el texto extraído del documento. Puede ser texto de un PDF o un documento OCR de página completa. Utiliza la tecnología de procesamiento de lenguaje natural (PNL) . Las líneas se ensamblan a partir de palabras individuales, varios fragmentos de texto, párrafos o columnas se forman a partir de líneas, y en ellos la red ya está aprendiendo a distinguir varias entidades nombradas NER (Reconocimiento de entidades con nombre).
Son posibles varias formas de formar fragmentos de texto. Puede combinar el primer y el segundo enfoque, entrenar una red para encontrar bloques grandes con cierta información en las imágenes, por ejemplo, datos sobre el remitente o datos sobre el destinatario, que contiene inmediatamente el nombre, dirección, detalles, etc., y luego transferir el texto de cada bloque a la segunda red NER.
La calidad de este enfoque puede ser más alta que solo en el primer enfoque, pero es bastante difícil construir un modelo efectivo. Hoy en día, hay modelos bastante avanzados, por ejemplo, LSTM-CRF para NER, que pueden etiquetar palabras en el texto y definir entidades. - El tercer enfoque es construir una representación semántica del documento sin referencia al tipo de documento, es decir. cuando no sabemos cuál es el documento que tenemos delante, pero tratamos de entenderlo durante el procesamiento. Un conjunto de palabras del documento con sus diversos atributos (por ejemplo, si la palabra contiene solo letras o es un número), la disposición geométrica de las palabras (coordenadas, sangrías) y con varios delimitadores y conexiones identificadas durante el análisis de imagen, se alimenta a la entrada de la red y la salida se obtiene para Cada palabra tiene su propio conjunto específico de características. En función de las características obtenidas, se forman varios conjuntos de hipótesis de posibles campos o tablas, que se clasifican y evalúan mediante un clasificador adicional. Luego se selecciona la hipótesis más confiable de la estructura y el contenido del documento.
Esto es técnicamente la solución más difícil, pero puede resolver el problema de extraer datos de documentos de manera general.
¿Cómo usamos las redes neuronales?
En ABBYY no solo monitoreamos de cerca los logros de la ciencia y la tecnología, sino que también creamos nuestras propias tecnologías avanzadas y las implementamos en varios productos.
La siguiente figura muestra la arquitectura general de nuestra solución utilizando redes neuronales.
Imagen en la que se puede hacer clic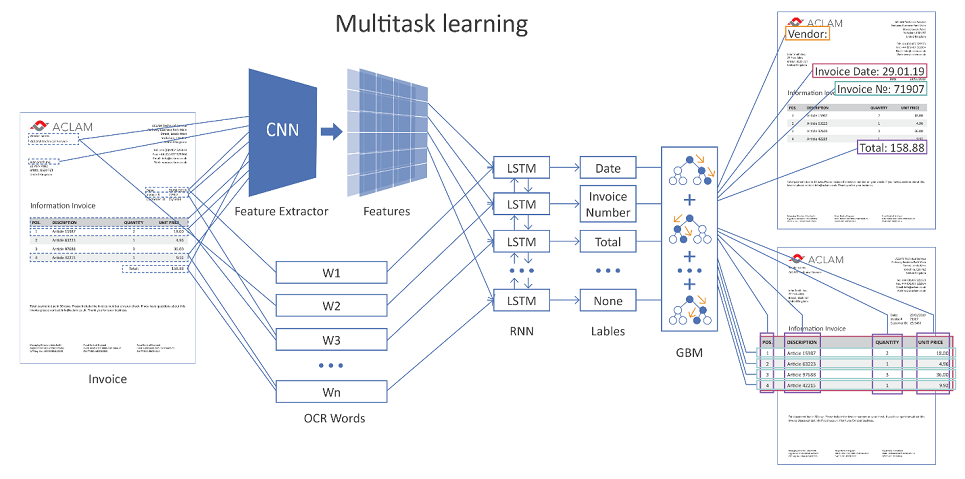
Toda la página del documento se alimenta a la entrada de red. Usando capas convolucionales (CNN), se forman varias características geométricas, por ejemplo, la posición relativa de las palabras entre sí. Además, estos signos se combinan con la representación vectorial de palabras reconocidas (incrustaciones de palabras) y se sirven en capas recurrentes (LSTM) y completamente conectadas. Hay varias capas de salida diferentes (aprendizaje de tareas múltiples), cada salida resuelve su propio problema:
- determinación del tipo de campo al que puede corresponder la palabra,
- hipótesis de los límites de la mesa,
- hipótesis de filas de tablas, límites de columnas, etc.
Si el documento es de varias páginas, la red realiza su predicción para cada página individual y, a continuación, los resultados se combinan.
Luego, las hipótesis se forman a partir de la posible disposición de campos y tablas, con la ayuda de una función de regresión entrenada por separado, se evalúan y gana la hipótesis más segura.
Para aumentar la precisión de la extracción de datos, además de separar los documentos por tipo (cheque, factura, contrato, etc.), se produce una agrupación adicional dentro de su tipo de acuerdo con características adicionales.
Por ejemplo, para las facturas puede ser un proveedor o simplemente una apariencia (de acuerdo con el grado de similitud de la ubicación de los campos). Y luego, dependiendo de un grupo particular (clúster), se aplican configuraciones de algoritmos específicos. Técnicamente, al tener ejemplos de facturas marcadas correctamente para diferentes grupos, es posible en el lado del usuario volver a capacitar los mecanismos para evaluar y elegir las hipótesis correctas.
Para configurar todo tipo de parámetros de nuestros algoritmos y redes neuronales, utilizamos el método de evolución diferencial, que se ha demostrado muy bien en la práctica.
Nuestros resultados de aprendizaje automático

- El método desarrollado para extraer datos de documentos estructurados utilizando el aprendizaje automático en muchos casos muestra mejores resultados que las soluciones programadas basadas en heurística. La ganancia de calidad en varias métricas varía de varias unidades a decenas de por ciento en varias entidades extraíbles.
- Existe una ventaja innegable sobre el enfoque clásico: la capacidad de volver a capacitar a la red con nuevos datos. En el caso de una variedad de formas de documentos, ahora esto no es un problema, sino más bien una necesidad. Cuantos más, mejor; cuanto mayor sea la capacidad de la red para generalizar y mayor será la calidad.
- Hubo una oportunidad para lanzar la llamada solución "lista para usar", cuando el usuario simplemente instala el producto (de hecho, una red capacitada), y todo comienza a funcionar inmediatamente con un resultado aceptable. No hay necesidad de programar nada, personalizar largas y dolorosamente las plantillas, seleccionar todo tipo de parámetros.
Un detalle importante que también me gustaría mencionar son los datos. Ningún aprendizaje automático puede suceder sin datos de calidad. El aprendizaje automático ofrece mejores resultados que la ingeniería del conocimiento, solo si hay una cantidad suficiente de datos etiquetados. En el caso de las facturas, se trata de decenas de miles de documentos etiquetados manualmente, y esta cifra está en constante crecimiento.
Además, utilizamos mecanismos avanzados de aumento de datos, cambiamos los nombres de organizaciones, direcciones, listas de productos y tipos de servicios en tablas, fechas, diversas características cuantitativas, como precio, cantidad, costo, etc. También cambiamos la secuencia de varias entidades en los documentos, lo que nos permite generar millones de documentos completamente diferentes para la capacitación.
En lugar de una conclusión
En conclusión, podemos decir que la programación, por supuesto, no ha desaparecido, sino que está cambiando gradualmente su papel. Con cada nuevo día, el aprendizaje automático comienza a hacer frente a las tareas que se le asignan cada vez mejor en una variedad de industrias, desplazando los enfoques clásicos. La ventaja innegable del aprendizaje automático en la eficiencia: docenas de años de trabajo intelectual cuestan docenas de horas de aprendizaje. Por lo tanto, en el futuro cercano vemos un mayor desarrollo y aplicabilidad de las redes en todos nuestros desarrollos. Y si está interesado, siempre estamos abiertos a sugerencias y
cooperación .