Hola habr
Muchos lectores y autores habituales del sitio probablemente pensaron en el ciclo de vida de los artículos publicados aquí. Y aunque intuitivamente esto es más o menos claro (es obvio, por ejemplo, que el artículo en la primera página tiene el número máximo de visitas), pero ¿cuánto específicamente?
Para recopilar estadísticas, usaremos Python, Pandas, Matplotlib y Raspberry Pi.
Aquellos que estén interesados en lo que surgió, por favor, debajo del gato.
Recogida de datos
Primero, decidamos las métricas, lo que queremos saber. Todo es simple, cada artículo tiene 4 parámetros principales que se muestran en la página: esta es la cantidad de vistas, me gusta, marcadores y comentarios. Los analizaremos.
Aquellos que quieran ver los resultados inmediatamente, pueden pasar a la tercera parte, pero por ahora se tratará de la programación.
Plan general: analizaremos los datos necesarios de la página web, los guardaremos con CSV y veremos qué obtenemos durante un período de varios días. Primero, cargue el texto del artículo (manejo de excepciones omitido para mayor claridad):
link = "https://habr.com/ru/post/000001/" f = urllib.urlopen(link) data_str = f.read()
Ahora necesitamos extraer datos de la línea data_str (es, por supuesto, en HTML). Abra el código fuente en el navegador (se eliminan los elementos sin principios):
<ul class="post-stats post-stats_post js-user_" id="infopanel_post_438514"> <li class="post-stats__item post-stats__item_voting-wjt"> <span class="voting-wjt__counter voting-wjt__counter_positive js-score" title=" 448: ↑434 ↓14">+420</span> </li> <span class="btn_inner"><svg class="icon-svg_bookmark" width="10" height="16"><use xlink:href="https://habr.com/images/1550155671/common-svg-sprite.svg#book" /></svg><span class="bookmark__counter js-favs_count" title=" , ">320</span></span> <li class="post-stats__item post-stats__item_views"> <div class="post-stats__views" title=" "> <span class="post-stats__views-count">219k</span> </div> </li> <li class="post-stats__item post-stats__item_comments"> <a href="https://habr.com/ru/post/438514/#comments" class="post-stats__comments-link" <span class="post-stats__comments-count" title=" ">577</span> </a> </li> <li class="post-stats__item"> <span class="icon-svg_report"><svg class="icon-svg" width="32" height="32" viewBox="0 0 32 32" aria-hidden="true" version="1.1" role="img"><path d="M0 0h32v32h-32v-32zm14 6v12h4v-12h-4zm0 16v4h4v-4h-4z"/></svg> </span> </li> </ul>
Es fácil ver que el texto que necesitamos está dentro del bloque '<ul class = "post-stats post-stats_post js-user_>', y los elementos necesarios están en bloques con los nombres vote-wjt__counter, bookmark__counter, post-stats__views-count y post- stats__comments-count. Por nombre, todo es bastante obvio.
Heredaremos la clase str y le agregaremos el método de extracción de la subcadena ubicada entre las dos etiquetas:
class Str(str): def find_between(self, first, last): try: start = self.index(first) + len(first) end = self.index(last, start) return Str(self[start:end]) except ValueError: return Str("")
Podría prescindir de la herencia, pero esto le permitirá escribir código más conciso. Con él, toda la extracción de datos cabe en 4 líneas:
votes = data_str.find_between('span class="voting-wjt__counter voting-wjt__counter_positive js-score"', 'span').find_between('>', '<') bookmarks = data_str.find_between('span class="bookmark__counter js-favs_count"', 'span').find_between('>', '<') views = data_str.find_between('span class="post-stats__views-count"', 'span').find_between('>', '<') comments = data_str.find_between('span class="post-stats__comments-count"', 'span').find_between('>', '<')
Pero eso no es todo. Como puede ver, el número de comentarios o vistas se puede almacenar como una cadena como "12.1k", que no se traduce directamente a int.
Agregue una función para convertir dicha cadena en un número:
def to_int(self): s = self.lower().replace(",", ".") if s[-1:] == "k":
Solo queda agregar la marca de tiempo, y puede guardar los datos en csv:
timestamp = strftime("%Y-%m-%dT%H:%M:%S.000", gmtime()) str_out = "{},votes:{},bookmarks:{},views:{},comments:{};".format(timestamp, votes.to_int(), bookmarks.to_int(), views.to_int(), comments.to_int())
Como estamos interesados en analizar varios artículos, agregamos la capacidad de especificar un enlace a través de la línea de comando. También generaremos el nombre del archivo de registro por la ID del artículo:
link = sys.argv[1]
Y el último paso. Eliminamos el código en la función, en el bucle encuestamos los datos y escribimos los resultados en el registro.
delay_s = 5*60 while True:
Como puede ver, los datos se actualizaron cada 5 minutos para no crear una carga en el servidor. Guardé el archivo del programa con el nombre habr_parse.py, cuando se inicie, guardará datos hasta que se cierre el programa.
Además, es deseable guardar los datos, al menos durante unos días. Porque Somos reacios a mantener la computadora encendida durante varios días, tomamos la Raspberry Pi: es suficiente energía para tal tarea y, a diferencia de una PC, la Raspberry Pi no hace ruido y casi no consume electricidad. Repasamos SSH y ejecutamos nuestro script:
nohup python habr_parse.py https://habr.com/ru/post/0000001/ &
El comando nohup deja el script en segundo plano después de cerrar la consola.
Como beneficio adicional, puede ejecutar un servidor http en segundo plano ingresando el comando "nuhup python -m SimpleHTTPServer 8000 &". Esto le permitirá ver los resultados directamente en el navegador en cualquier momento, abriendo un enlace del formulario
http://192.168.1.101:8000 (la dirección, por supuesto, puede ser diferente).
Ahora puede dejar la Raspberry Pi encendida y volver al proyecto en unos días.
Análisis de datos
Si todo se hizo correctamente, la salida debería ser algo así como este registro:
2019-02-12T22:26:28.000,votes:12,bookmarks:0,views:448,comments:1; 2019-02-12T22:31:29.000,votes:12,bookmarks:0,views:467,comments:1; 2019-02-12T22:36:30.000,votes:14,bookmarks:1,views:482,comments:1; 2019-02-12T22:41:30.000,votes:14,bookmarks:2,views:497,comments:1; 2019-02-12T22:46:31.000,votes:14,bookmarks:2,views:513,comments:1; 2019-02-12T22:51:32.000,votes:14,bookmarks:2,views:527,comments:1; 2019-02-12T22:56:32.000,votes:14,bookmarks:2,views:543,comments:1; 2019-02-12T23:01:33.000,votes:14,bookmarks:2,views:557,comments:2; 2019-02-12T23:06:34.000,votes:14,bookmarks:2,views:567,comments:3; 2019-02-12T23:11:35.000,votes:13,bookmarks:2,views:590,comments:4; ... 2019-02-13T02:47:03.000,votes:15,bookmarks:3,views:1100,comments:20; 2019-02-13T02:52:04.000,votes:15,bookmarks:3,views:1200,comments:20;
Veamos cómo se puede procesar. Para comenzar, cargue csv en un marco de datos de pandas:
import pandas as pd import numpy as np import datetime log_path = "habr_data.txt" df = pd.read_csv(log_path, header=None, names=['datetime', 'votes', 'bookmarks', 'views', 'comments'])
Agregue funciones para la conversión y el promedio, y extraiga los datos necesarios:
def to_float(s):
El promedio es necesario porque el número de vistas en el sitio se muestra en incrementos de 100, lo que conduce a un horario "desgarrado". En principio, esto no es necesario, pero con el promedio se ve mejor. La zona horaria de Moscú también se agrega en el código (la hora en el Raspberry Pi resultó ser GMT).
Finalmente, puede mostrar los gráficos y ver qué sucedió.
import matplotlib.pyplot as plt
Resultados
Al comienzo de cada gráfico hay un espacio vacío, que se explica simplemente: cuando se lanzó el script, los artículos ya estaban publicados, por lo que los datos no se recopilaron desde cero. El punto "cero" se agregó manualmente a partir de la descripción del tiempo de publicación del artículo.
Todos los gráficos presentados son generados por matplotlib y el código anterior.
Según los resultados, dividí los artículos investigados en 3 grupos. La división es condicional, aunque todavía tiene algún sentido.
Artículo caliente
Este artículo trata sobre un tema popular y relevante, con un título como "Cómo MTS deduce dinero" o "Roskomnadzor bloqueó
el centro de git
porno ".
Dichos artículos tienen una gran cantidad de puntos de vista y comentarios, pero el "bombo" dura un máximo de varios días. También puede ver una ligera diferencia en el crecimiento en el número de vistas durante el día y la noche (pero no tan significativo como se esperaba, aparentemente, Habr se lee desde casi todas las zonas horarias).
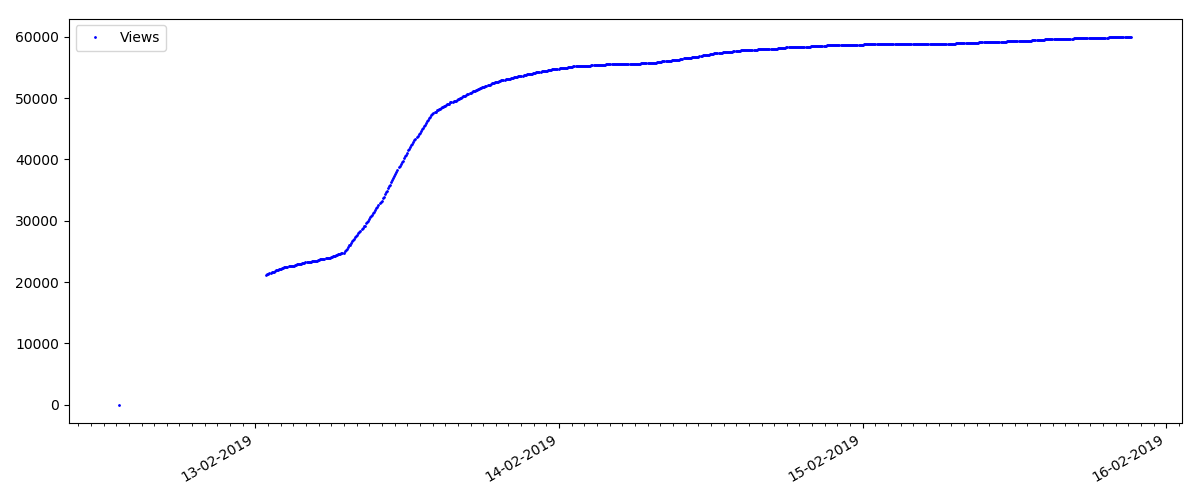
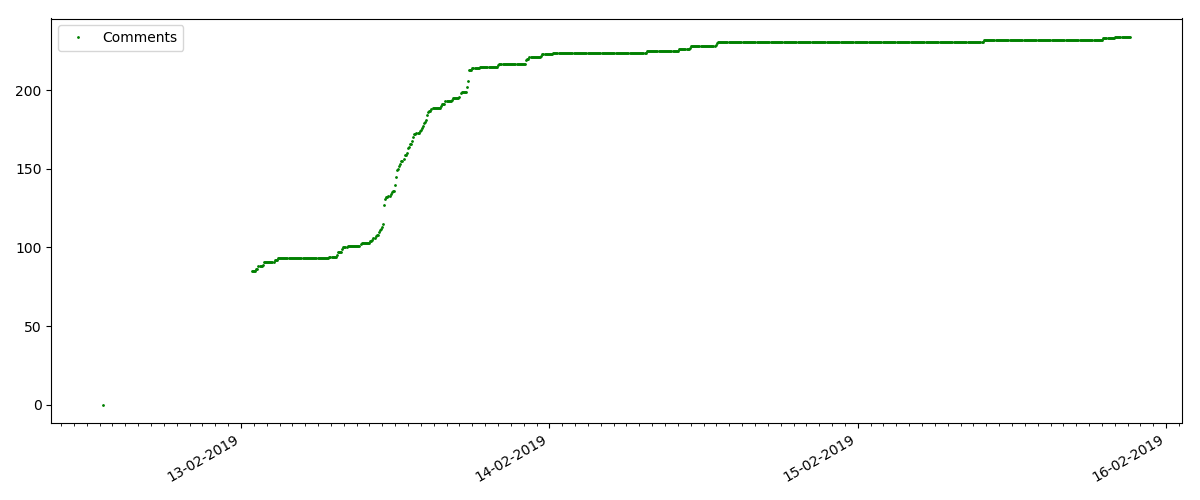
El número de "me gusta" está creciendo significativamente, mientras que el número de marcadores está disminuyendo notablemente. Esto es lógico porque A alguien le puede gustar el artículo, pero la especificidad del texto es tal que simplemente no es necesario marcarlo.
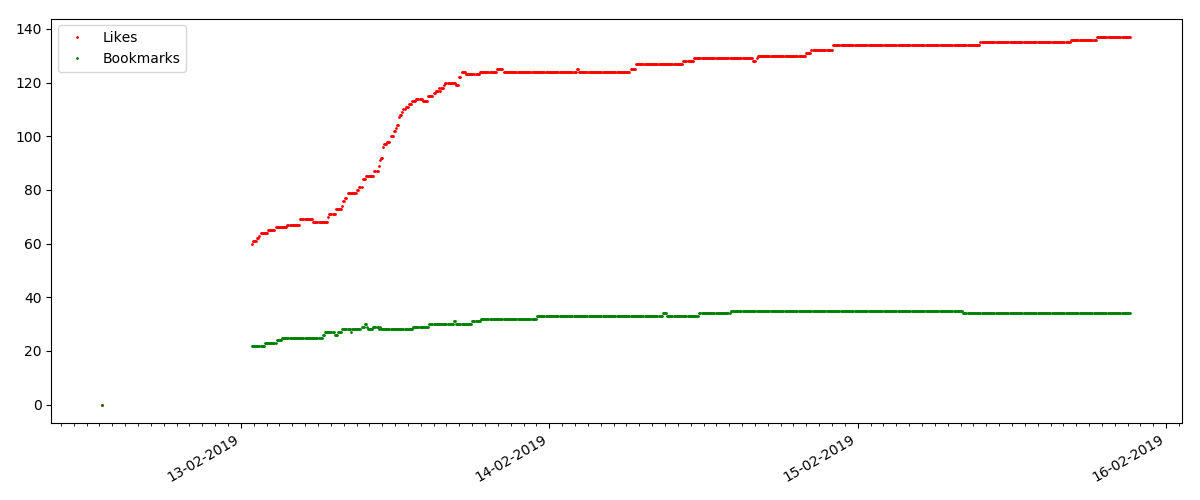
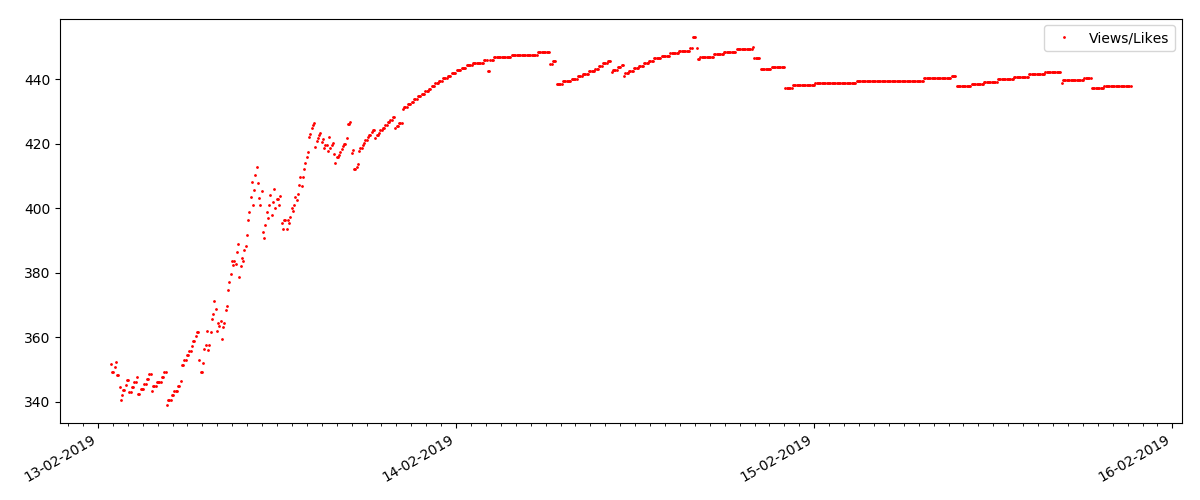
La proporción de vistas y me gusta sigue siendo aproximadamente la misma y es aproximadamente 400: 1:
Artículo "técnico"
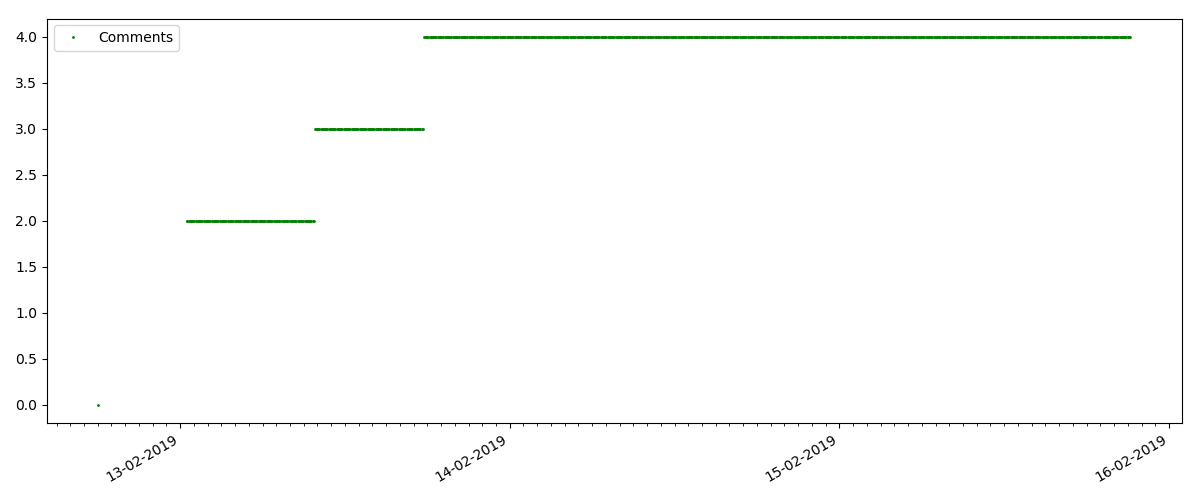
Este es un artículo más especializado, como "Configuración de scripts para el nodo JS". Tal artículo, por supuesto, gana muchas veces menos visitas que el "hot", el número de comentarios también es notablemente menor (en este caso, solo hubo 4).
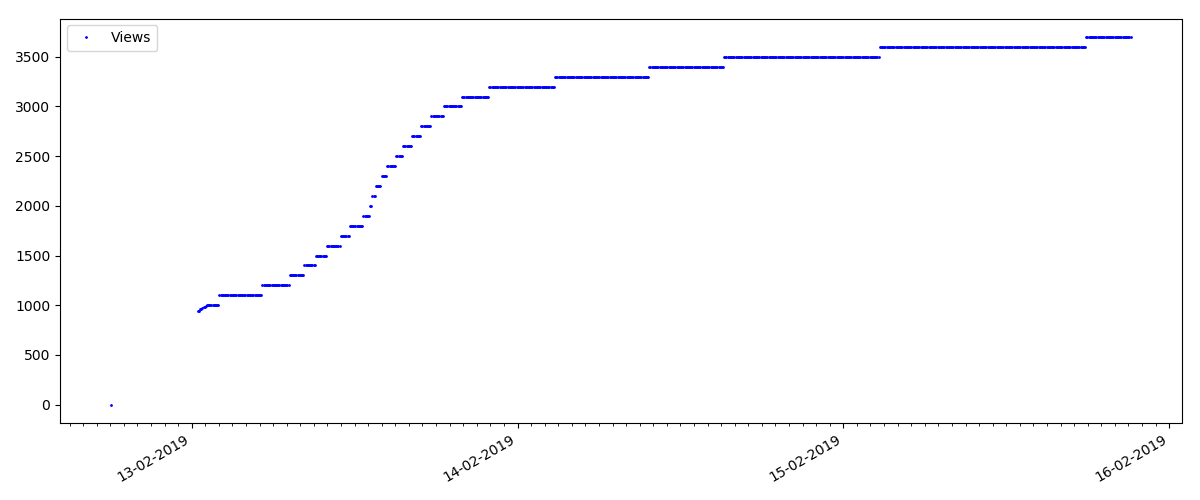
Pero el siguiente punto es más interesante: el número de "me gusta" para tales artículos está creciendo notablemente más lento que el número de "marcadores". Aquí es al revés en comparación con la versión anterior: muchos encuentran útil el artículo para guardarlo en el futuro, pero el lector no tiene que hacer clic en "me gusta".
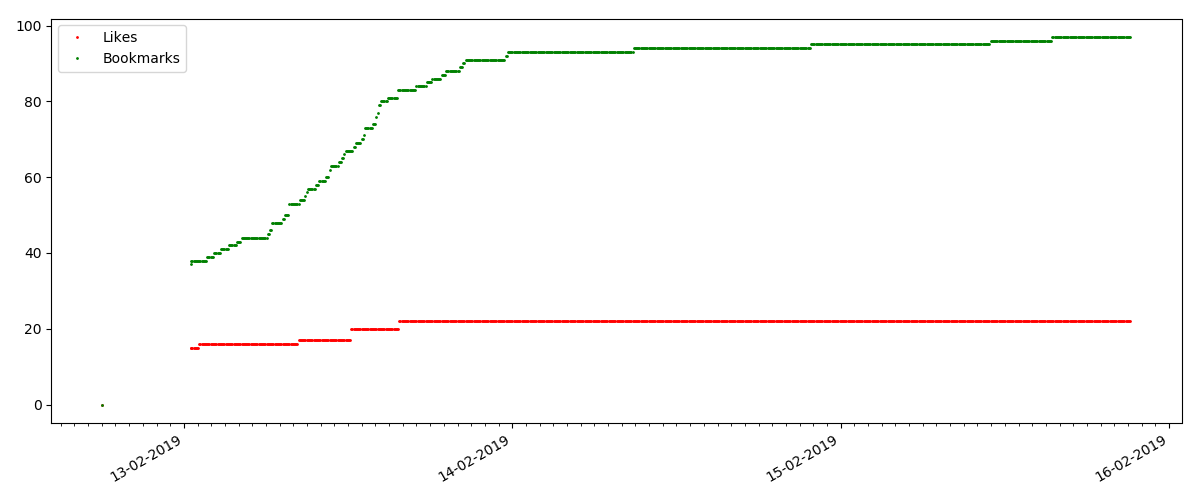
Por cierto, en este punto me gustaría llamar la atención de los administradores del sitio: al calcular las calificaciones de los artículos, debe contar los marcadores en paralelo con los me gusta (por ejemplo, combinando conjuntos por OR). De lo contrario, esto lleva a un sesgo en la calificación, cuando un artículo conocido tiene muchos marcadores (es decir, a los lectores definitivamente les gustó), pero estas personas olvidaron o fueron demasiado flojas para hacer clic en "me gusta".
Y finalmente, la proporción de vistas y me gusta: puede ver que es notablemente más alta que en la primera realización y es aproximadamente 150: 1, es decir La calidad del contenido también puede considerarse indirectamente como superior.
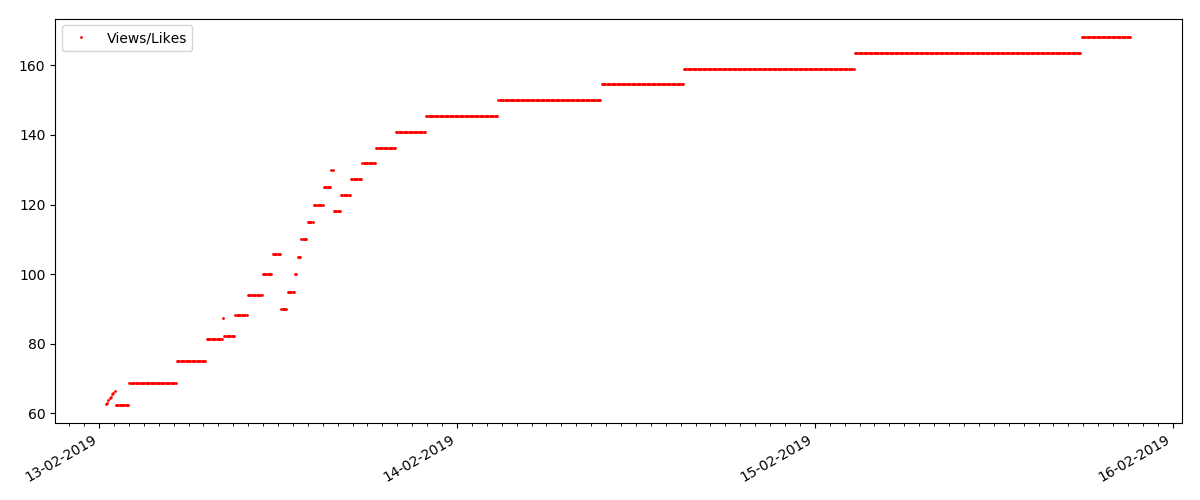
Artículo "sospechoso" (pero esto no es exacto)
Para el siguiente artículo examinado, el número de "me gusta" aumentó en un tercio en un intervalo de 5 minutos (inmediatamente en 10 con un total de 30 anotados durante todos los días).
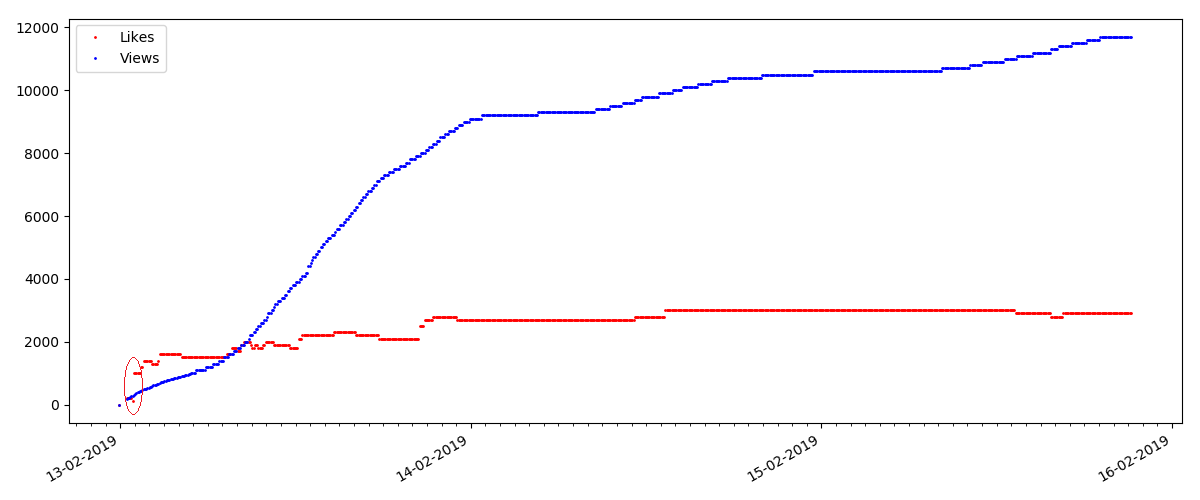
Uno podría sospechar un engaño, pero la "teoría de colas" en principio permite tales oleadas. O tal vez el autor acaba de enviar el enlace a todos sus 10 amigos, lo que, por supuesto, no está prohibido por las reglas.
Conclusiones
La conclusión principal es que todo es descomposición y maya. Incluso el material más popular, que gana miles de visitas, irá "en el pasado" en solo 3-4 días. Tales, por desgracia, los detalles de la Internet moderna, y probablemente de toda la industria de los medios modernos en su conjunto. Y estoy seguro de que las cifras que se muestran son específicas no solo para Habr, sino también para cualquier recurso similar de Internet.
De lo contrario, es más probable que este análisis sea de naturaleza "viernes" y, por supuesto, no pretende ser un estudio serio. También espero que alguien haya encontrado algo nuevo al usar Pandas y Matplotlib.
Gracias por su atencion