Hola Habr! En esta publicación, escribiremos una aplicación en Spring Boot 2 usando Apache Kafka en Linux, desde la instalación de JRE a una aplicación de microservicio que funcione.
Los colegas del departamento de desarrollo front-end que vieron el artículo se quejan de que no estoy explicando qué son Apache Kafka y Spring Boot. Creo que cualquiera que necesite ensamblar un proyecto terminado utilizando las tecnologías anteriores sabe qué es y por qué lo necesita. Si para el lector la pregunta no está inactiva, aquí hay excelentes artículos sobre Habr, qué son
Apache Kafka y
Spring Boot .
Podemos prescindir de largas explicaciones de lo que son Kafka, Spring Boot y Linux, y en su lugar, ejecutar el servidor Kafka desde cero en una máquina Linux, escribir dos microservicios y hacer que uno de ellos envíe mensajes al otro, en general, configure Arquitectura completa de microservicios.

La publicación constará de dos secciones. En el primero configuramos y ejecutamos Apache Kafka en una máquina Linux, en el segundo escribimos dos microservicios en Java.
En el inicio, en el que comencé mi carrera profesional como programador, había microservicios en Kafka, y uno de mis microservicios también trabajó con otros a través de Kafka, pero no sabía cómo funcionaba el servidor, si estaba escrito como una aplicación o si ya estaba completamente en caja producto. ¿Cuál fue mi sorpresa y decepción cuando resultó que Kafka todavía era un producto en caja, y mi tarea sería no solo escribir un cliente en Java (que me encanta hacer), así como implementar y configurar la aplicación terminada como devOps (que yo odio hacer). Sin embargo, incluso si pudiera subirlo al servidor virtual de Kafka en menos de un día, es realmente bastante simple hacerlo. Entonces
Nuestra aplicación tendrá la siguiente estructura de interacción:
Al final de la publicación, como de costumbre, habrá enlaces a git con código de trabajo.
Implemente Apache Kafka + Zookeeper en una máquina virtual
Traté de criar a Kafka en Linux local, en una amapola y en Linux remoto. En dos casos (Linux), tuve éxito bastante rápido. Con la amapola no pasó nada. Por lo tanto, elevaremos Kafka en Linux. Elegí Ubuntu 18.04.
Para que Kafka funcione, ella necesita un Zookeeper. Para hacer esto, debe descargarlo y ejecutarlo antes de iniciar Kafka.
Entonces
0. Instalar JRE
Esto se realiza mediante los siguientes comandos:
sudo apt-get update sudo apt-get install default-jre
Si todo salió bien, entonces puedes ingresar el comando
java -version
y asegúrese de que Java esté instalado.
1. Descargar Zookeeper
No me gustan los equipos mágicos en Linux, especialmente cuando solo dan algunos comandos y no está claro lo que están haciendo. Por lo tanto, describiré cada acción, qué hace exactamente. Por lo tanto, necesitamos descargar Zookeeper y descomprimirlo en una carpeta conveniente. Es aconsejable que todas las aplicaciones se almacenen en la carpeta / opt, es decir, en nuestro caso será / opt / zookeeper.
Usé el comando a continuación. Si conoce otros comandos de Linux que, en su opinión, le permitirán hacer esto más racialmente correctamente, úselos. Soy un desarrollador, no un despojo, y me comunico con servidores al nivel de "la cabra misma". Entonces, descargue la aplicación:
wget -P /home/xpendence/downloads/ "http://apache-mirror.rbc.ru/pub/apache/zookeeper/zookeeper-3.4.12/zookeeper-3.4.12.tar.gz"
La aplicación se descarga en la carpeta que especifique, creé la carpeta / home / xpendence / downloads para descargar allí todas las aplicaciones que necesito.
2. Desempaquete Zookeeper
Usé el comando:
tar -xvzf /home/xpendence/downloads/zookeeper-3.4.12.tar.gz
Este comando descomprime el archivo en la carpeta en la que se encuentra. Es posible que deba transferir la aplicación a / opt / zookeeper. Y puede entrar de inmediato y desde allí ya desempaquetar el archivo.
3. Editar configuración
En la carpeta / zookeeper / conf / hay un archivo zoo-sample.cfg, sugiero cambiarle el nombre a zoo.conf, es este archivo el que JVM buscará en el inicio. Lo siguiente debe agregarse a este archivo al final:
tickTime=2000 dataDir=/var/zookeeper clientPort=2181
Además, cree el directorio / var / zookeeper.
4. Inicie Zookeeper
Vaya a la carpeta / opt / zookeeper e inicie el servidor con el comando:
bin/zkServer.sh start
Debería aparecer "COMENZADO".
Después de lo cual, propongo verificar que el servidor esté funcionando. Nosotros escribimos:
telnet localhost 2181
Debería aparecer un mensaje de que la conexión fue un éxito. Si tiene un servidor débil y el mensaje no apareció, intente nuevamente, incluso cuando aparezca INICIADO, la aplicación comienza a escuchar el puerto mucho más tarde. Cuando intenté todo esto en un servidor débil, me sucedió todo el tiempo. Si todo está conectado, ingrese el comando
ruok
¿Qué significa: "¿Estás bien?" El servidor debe responder:
imok ( !)
y desconectar. Entonces, todo está de acuerdo al plan. Procedemos a lanzar Apache Kafka.
5. Crear un usuario bajo Kafka
Para trabajar con Kafka necesitamos un usuario separado.
sudo adduser --system --no-create-home --disabled-password --disabled-login kafka
6. Descargar Apache Kafka
Hay dos distribuciones: binaria y fuentes. Necesitamos un binario. En apariencia, el archivo con el binario es diferente en tamaño. El binario pesa 59 MB y pesa 6.5 MB.
Descargue el binario en el directorio allí, utilizando el siguiente enlace:
wget -P /home/xpendence/downloads/ "http://mirror.linux-ia64.org/apache/kafka/2.1.0/kafka_2.11-2.1.0.tgz"
7. Desempaquete Apache Kafka
El procedimiento de desempaque no es diferente del mismo para Zookeeper. También desempaquetamos el archivo en el directorio / opt y le cambiamos el nombre a kafka para que la ruta a la carpeta / bin sea / opt / kafka / bin
tar -xvzf /home/xpendence/downloads/kafka_2.11-2.1.0.tgz
8. Editar configuración
La configuración está en /opt/kafka/config/server.properties. Agrega una línea:
delete.topic.enable = true
Esta configuración parece ser opcional, funciona sin ella. Esta configuración le permite eliminar temas. De lo contrario, simplemente no puede eliminar temas a través de la línea de comando.
9. Damos acceso a los directorios kafka del usuario Kafka
chown -R kafka:nogroup /opt/kafka chown -R kafka:nogroup /var/lib/kafka
10. El tan esperado lanzamiento de Apache Kafka
Ingresamos el comando, después del cual Kafka debería comenzar:
/opt/kafka/bin/kafka-server-start.sh /opt/kafka/config/server.properties
Si las acciones habituales (Kafka está escrito en Java y Scala) no se desbordaron en el registro, entonces todo funcionó y puede probar nuestro servicio.
10.1 Problemas de servidor débiles
Para los experimentos en Apache Kafka, tomé un servidor débil con un núcleo y 512 MB de RAM (por solo 99 rublos), lo que resultó ser varios problemas para mí.
Sin memoria Por supuesto, no puede hacer overclock con 512 MB, y el servidor no pudo implementar Kafka debido a la falta de memoria. El hecho es que, por defecto, Kafka consume 1 GB de memoria. No es de extrañar que faltara :)
Vamos a kafka-server-start.sh, zookeeper-server-start.sh. Ya hay una línea que regula la memoria:
export KAFKA_HEAP_OPTS="-Xmx1G -Xms1G"
Cámbielo a:
export KAFKA_HEAP_OPTS="-Xmx256M -Xms128M"
Esto reducirá el apetito de Kafka y permitirá que se inicie el servidor.
El segundo problema con una computadora débil es la falta de tiempo para conectarse a Zookeeper. Por defecto, esto tiene 6 segundos. Si el hierro es débil, esto, por supuesto, no es suficiente. En server.properties aumentamos el tiempo de conexión al zukipper:
zookeeper.connection.timeout.ms=30000
Me puse medio minuto.
11. Pruebe el servidor Kafka
Para hacer esto, abriremos dos terminales, en una lanzaremos al productor, a la otra: el consumidor.
En la primera consola, ingrese una línea:
/opt/kafka/bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test /opt/kafka/bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
Este ícono debería aparecer, indicando que el productor está listo para recibir mensajes de spam:
>
En la segunda consola, ingrese el comando:
/opt/kafka/bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning
Ahora, escribiendo en la consola del productor, cuando presiona Enter, aparecerá en la consola del consumidor.
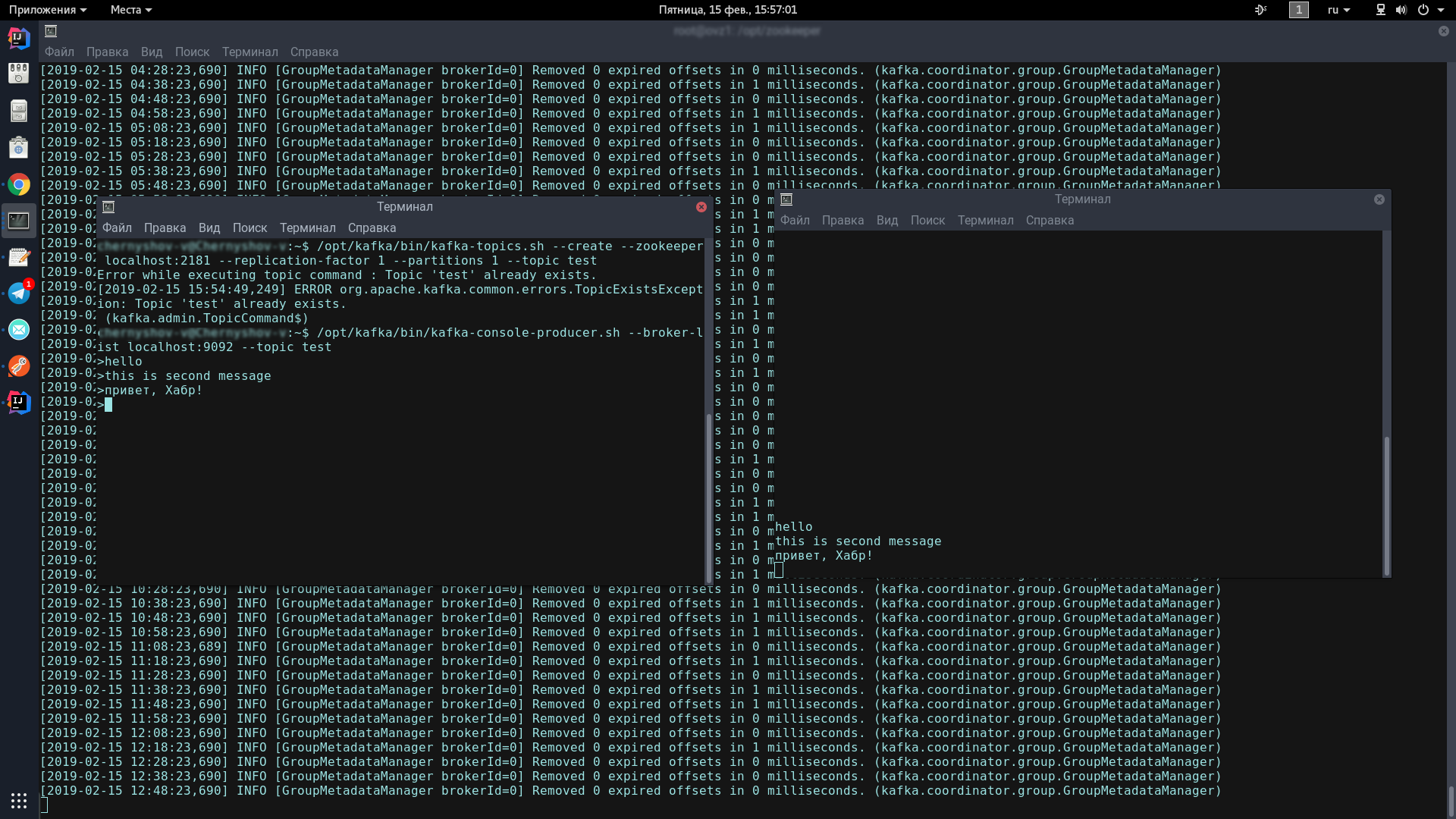
Si ve en la pantalla aproximadamente lo mismo que yo, felicidades, ¡lo peor ya pasó!
Ahora solo tenemos que escribir un par de clientes en Spring Boot que se comunicarán entre sí a través de Apache Kafka.
Escribir una aplicación en Spring Boot
Escribiremos dos aplicaciones que intercambiarán mensajes a través de Apache Kafka. El primer mensaje se llamará kafka-server y contendrá tanto al productor como al consumidor. El segundo se llamará kafka-tester, está diseñado para que tengamos una arquitectura de microservicio.
servidor kafka
Para nuestros proyectos creados a través de Spring Initializr, necesitamos el módulo Kafka. Agregué Lombok y Web, pero eso es cuestión de gustos.
El cliente Kafka consta de dos componentes: el productor (envía mensajes al servidor Kafka) y el consumidor (escucha al servidor Kafka y toma nuevos mensajes desde allí sobre los temas a los que está suscrito). Nuestra tarea es escribir ambos componentes y hacer que funcionen.
Consumidor:
@Configuration public class KafkaConsumerConfig { @Value("${kafka.server}") private String kafkaServer; @Value("${kafka.group.id}") private String kafkaGroupId; @Bean public KafkaListenerContainerFactory<?> batchFactory() { ConcurrentKafkaListenerContainerFactory<Long, AbstractDto> factory = new ConcurrentKafkaListenerContainerFactory<>(); factory.setConsumerFactory(consumerFactory()); factory.setBatchListener(true); factory.setMessageConverter(new BatchMessagingMessageConverter(converter())); return factory; } @Bean public KafkaListenerContainerFactory<?> singleFactory() { ConcurrentKafkaListenerContainerFactory<Long, AbstractDto> factory = new ConcurrentKafkaListenerContainerFactory<>(); factory.setConsumerFactory(consumerFactory()); factory.setBatchListener(false); factory.setMessageConverter(new StringJsonMessageConverter()); return factory; } @Bean public ConsumerFactory<Long, AbstractDto> consumerFactory() { return new DefaultKafkaConsumerFactory<>(consumerConfigs()); } @Bean public KafkaListenerContainerFactory<?> kafkaListenerContainerFactory() { return new ConcurrentKafkaListenerContainerFactory<>(); } @Bean public Map<String, Object> consumerConfigs() { Map<String, Object> props = new HashMap<>(); props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, kafkaServer); props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, LongDeserializer.class); props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class); props.put(ConsumerConfig.GROUP_ID_CONFIG, kafkaGroupId); props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, true); return props; } @Bean public StringJsonMessageConverter converter() { return new StringJsonMessageConverter(); } }
Necesitamos 2 campos inicializados con datos estáticos de kafka.properties.
kafka.server=localhost:9092 kafka.group.id=server.broadcast
kafka.server es la dirección en la que se cuelga nuestro servidor, en este caso, local. Por defecto, Kafka escucha en el puerto 9092.
kafka.group.id es un grupo de consumidores, dentro del cual se entrega una instancia del mensaje. Por ejemplo, tiene tres correos en un grupo, y todos escuchan el mismo tema. Tan pronto como aparece un nuevo mensaje en el servidor con este tema, se entrega a alguien del grupo. Los dos consumidores restantes no están recibiendo el mensaje.
A continuación, estamos creando una fábrica para consumidores: ConsumerFactory.
@Bean public ConsumerFactory<Long, AbstractDto> consumerFactory() { return new DefaultKafkaConsumerFactory<>(consumerConfigs()); }
Inicializado con las propiedades que necesitamos, servirá como una fábrica estándar para los consumidores en el futuro.
@Bean public Map<String, Object> consumerConfigs() { Map<String, Object> props = new HashMap<>(); props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, kafkaServer); props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, LongDeserializer.class); props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class); props.put(ConsumerConfig.GROUP_ID_CONFIG, kafkaGroupId); props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, true); return props; }
consumerConfigs son solo configuraciones de mapas. Proporcionamos la dirección del servidor, el grupo y los deserializadores.
Además, uno de los puntos más importantes para un consumidor. El consumidor puede recibir tanto objetos individuales como colecciones, por ejemplo, StarshipDto y List. Y si obtenemos StarshipDto como JSON, entonces obtenemos List como, más o menos, como una matriz JSON. Por lo tanto, tenemos al menos dos fábricas de mensajes: para mensajes individuales y para matrices.
@Bean public KafkaListenerContainerFactory<?> singleFactory() { ConcurrentKafkaListenerContainerFactory<Long, AbstractDto> factory = new ConcurrentKafkaListenerContainerFactory<>(); factory.setConsumerFactory(consumerFactory()); factory.setBatchListener(false); factory.setMessageConverter(new StringJsonMessageConverter()); return factory; }
Instanciamos ConcurrentKafkaListenerContainerFactory, escribimos Long (clave de mensaje) y AbstractDto (valor de mensaje abstracto), e inicializamos sus campos con propiedades. Nosotros, por supuesto, inicializamos la fábrica con nuestra fábrica estándar (que ya contiene configuraciones de Mapa), luego marcamos que no escuchamos paquetes (las mismas matrices) y especificamos un convertidor JSON simple como el convertidor.
Cuando creamos una fábrica para paquetes / matrices (lote), la principal diferencia (aparte del hecho de que marcamos que escuchamos paquetes) es que especificamos como convertidor un convertidor de paquete especial que convertirá paquetes que consisten en de cadenas JSON.
@Bean public KafkaListenerContainerFactory<?> batchFactory() { ConcurrentKafkaListenerContainerFactory<Long, AbstractDto> factory = new ConcurrentKafkaListenerContainerFactory<>(); factory.setConsumerFactory(consumerFactory()); factory.setBatchListener(true); factory.setMessageConverter(new BatchMessagingMessageConverter(converter())); return factory; } @Bean public StringJsonMessageConverter converter() { return new StringJsonMessageConverter(); }
Y una cosa más. Al inicializar los Spring beans, el contenedor bajo el nombre kafkaListenerContainerFactory puede no contarse y la aplicación se arruinará. Seguramente hay opciones más elegantes para resolver el problema, escriba sobre ellos en los comentarios, por ahora acabo de crear un contenedor descargado con funcionalidad con el mismo nombre:
@Bean public KafkaListenerContainerFactory<?> kafkaListenerContainerFactory() { return new ConcurrentKafkaListenerContainerFactory<>(); }
El consumidor está configurado. Pasamos al productor.
@Configuration public class KafkaProducerConfig { @Value("${kafka.server}") private String kafkaServer; @Value("${kafka.producer.id}") private String kafkaProducerId; @Bean public Map<String, Object> producerConfigs() { Map<String, Object> props = new HashMap<>(); props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, kafkaServer); props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, LongSerializer.class); props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, JsonSerializer.class); props.put(ProducerConfig.CLIENT_ID_CONFIG, kafkaProducerId); return props; } @Bean public ProducerFactory<Long, StarshipDto> producerStarshipFactory() { return new DefaultKafkaProducerFactory<>(producerConfigs()); } @Bean public KafkaTemplate<Long, StarshipDto> kafkaTemplate() { KafkaTemplate<Long, StarshipDto> template = new KafkaTemplate<>(producerStarshipFactory()); template.setMessageConverter(new StringJsonMessageConverter()); return template; } }
De las variables estáticas, necesitamos la dirección del servidor kafka y el ID del productor. Él puede ser cualquier cosa.
En las configuraciones, como vemos, no hay nada especial. Casi lo mismo. Pero con respecto a las fábricas, hay una diferencia significativa. Debemos registrar una plantilla para cada clase, cuyos objetos enviaremos al servidor, así como una fábrica para ello. Tenemos uno de esos pares, pero puede haber docenas de ellos.
En la plantilla, marcamos que serializaremos objetos en JSON, y esto, tal vez, es suficiente.
Tenemos un consumidor y un productor, queda por escribir un servicio que enviará mensajes y los recibirá.
@Service @Slf4j public class StarshipServiceImpl implements StarshipService { private final KafkaTemplate<Long, StarshipDto> kafkaStarshipTemplate; private final ObjectMapper objectMapper; @Autowired public StarshipServiceImpl(KafkaTemplate<Long, StarshipDto> kafkaStarshipTemplate, ObjectMapper objectMapper) { this.kafkaStarshipTemplate = kafkaStarshipTemplate; this.objectMapper = objectMapper; } @Override public void send(StarshipDto dto) { kafkaStarshipTemplate.send("server.starship", dto); } @Override @KafkaListener(id = "Starship", topics = {"server.starship"}, containerFactory = "singleFactory") public void consume(StarshipDto dto) { log.info("=> consumed {}", writeValueAsString(dto)); } private String writeValueAsString(StarshipDto dto) { try { return objectMapper.writeValueAsString(dto); } catch (JsonProcessingException e) { e.printStackTrace(); throw new RuntimeException("Writing value to JSON failed: " + dto.toString()); } } }
Solo hay dos métodos en nuestro servicio, son suficientes para que podamos explicar el trabajo del cliente. Autoconectamos los patrones que necesitamos:
private final KafkaTemplate<Long, StarshipDto> kafkaStarshipTemplate;
Método del productor:
@Override public void send(StarshipDto dto) { kafkaStarshipTemplate.send("server.starship", dto); }
Todo lo que se requiere para enviar un mensaje al servidor es llamar al método de envío en la plantilla y transferir el tema (asunto) y nuestro objeto allí. El objeto se serializará en JSON y volará al servidor bajo el tema especificado.
El método de escucha se ve así:
@Override @KafkaListener(id = "Starship", topics = {"server.starship"}, containerFactory = "singleFactory") public void consume(StarshipDto dto) { log.info("=> consumed {}", writeValueAsString(dto)); }
Marcamos este método con la anotación @KafkaListener, donde indicamos cualquier ID que nos guste, temas escuchados y una fábrica que convertirá el mensaje recibido a lo que necesitamos. En este caso, dado que aceptamos un objeto, necesitamos una sola fábrica. Para Lista <?>, Especifique batchFactory. Como resultado, enviamos el objeto al servidor kafka usando el método de envío y lo obtenemos usando el método de consumo.
Puede escribir una prueba en 5 minutos que demostrará la fuerza completa de Kafka, pero iremos más allá: pase 10 minutos y escriba otra aplicación que enviará mensajes al servidor que escuchará nuestra primera aplicación.
kafka-tester
Teniendo la experiencia de escribir la primera aplicación, podemos escribir fácilmente la segunda, especialmente si copiamos el paquete pegar y el paquete dto, registramos solo al productor (solo enviaremos mensajes) y agregaremos el único método de envío al servicio. Usando el siguiente enlace, puede descargar fácilmente el código del proyecto y asegurarse de que no haya nada complicado allí.
@Scheduled(initialDelay = 10000, fixedDelay = 5000) @Override public void produce() { StarshipDto dto = createDto(); log.info("<= sending {}", writeValueAsString(dto)); kafkaStarshipTemplate.send("server.starship", dto); } private StarshipDto createDto() { return new StarshipDto("Starship " + (LocalTime.now().toNanoOfDay() / 1000000)); }
Después de los primeros 10 segundos, kafka-tester comienza a enviar mensajes con los nombres de naves espaciales al servidor Kafka cada 5 segundos (se puede hacer clic en la imagen).
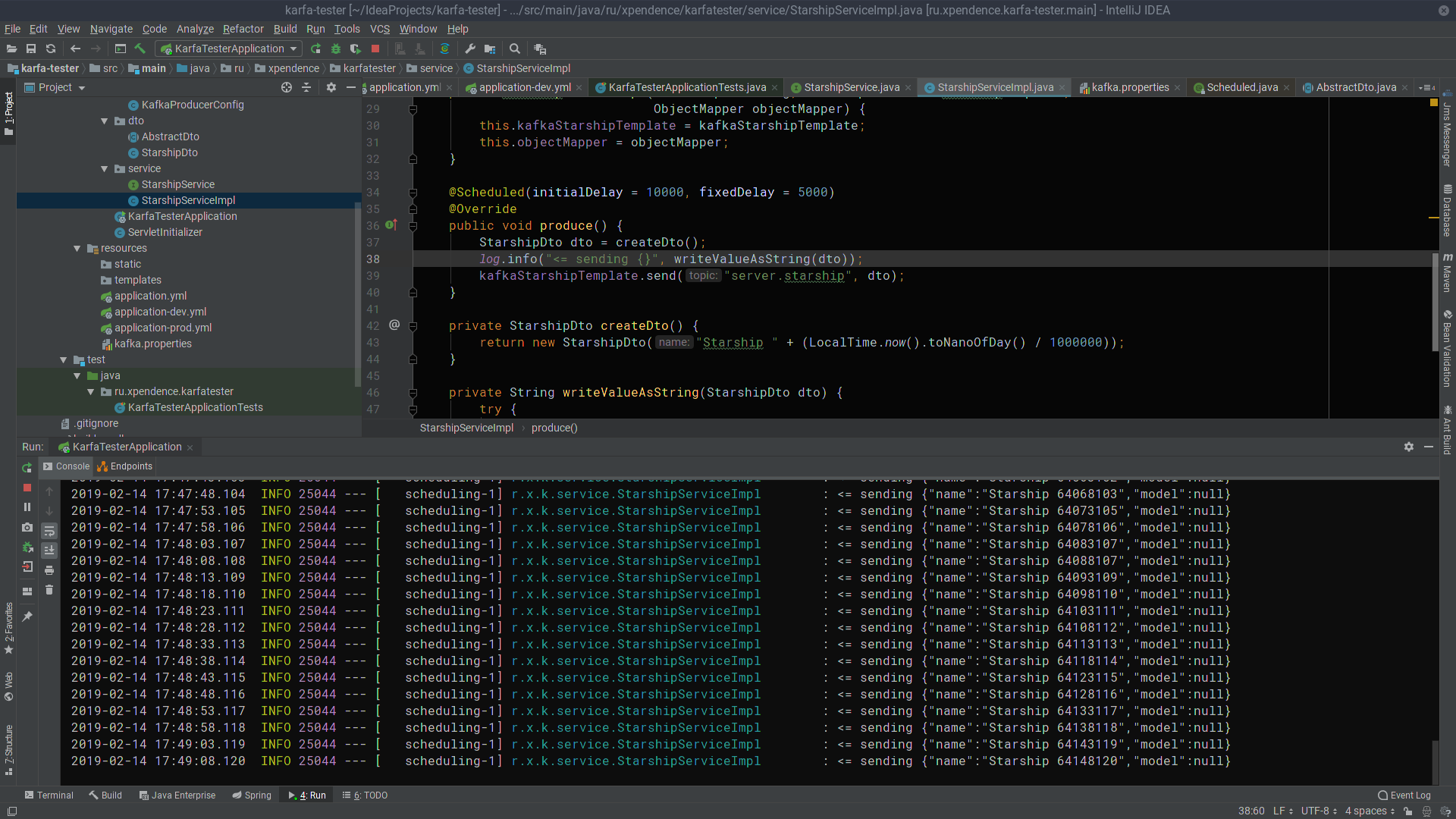
Allí, son escuchados y recibidos por el servidor kafka (también se puede hacer clic en la imagen).

Espero que aquellos que sueñan con comenzar a escribir microservicios en Kafka tengan éxito tan fácilmente como yo. Y aquí están los enlaces a los proyectos:
→
servidor kafka→
kafka-tester