Hola habrozhiteli!
Decidimos compartir la traducción del capítulo “Sistemas basados en colas de tareas” De la próxima novedad “Sistemas distribuidos. Patrones de diseño ”(ya en la imprenta).
La forma más simple de procesamiento por lotes es la cola de tareas. En un sistema con una cola de tareas, hay un conjunto de tareas que deben completarse. Cada tarea es completamente independiente de las demás y se puede procesar sin ninguna interacción con ellas. En el caso general, el objetivo de un sistema con una cola de tareas es garantizar que cada etapa del trabajo se complete dentro de un período de tiempo determinado. El número de flujos de trabajo aumenta o disminuye de acuerdo con el cambio en la carga. El diagrama de cola de tareas generalizadas se muestra en la Fig. 10.1
Un sistema basado en una cola de tareas generalizadas
La línea de tareas es un ejemplo ideal que demuestra la potencia total de los patrones de diseño de sistemas distribuidos. La mayor parte de la lógica de la cola de tareas no depende del tipo de trabajo realizado. En muchos casos, lo mismo se aplica a la entrega de las tareas mismas.
Permítanos ilustrar esta declaración usando la cola de tareas que se muestra en la Fig. 10.1 Después de mirarlo nuevamente, determine qué funciones puede proporcionar un conjunto compartido de contenedores. Es evidente que la mayor parte de la implementación de una cola de tareas en contenedor puede ser utilizada por una amplia gama de usuarios.
La cola de tareas basada en contenedores requiere interfaces coincidentes entre los contenedores de la biblioteca y los contenedores con la lógica del usuario. Dentro de la cola de tareas en contenedor, se distinguen dos interfaces: la interfaz del contenedor de origen, que proporciona una secuencia de tareas que requieren procesamiento, y la interfaz del contenedor en ejecución, que sabe cómo manejarlas.
Interfaz de contenedor de origen
Cualquier cola de tareas opera sobre la base de un conjunto de tareas que requieren procesamiento. Dependiendo de la aplicación específica implementada sobre la base de la cola de tareas, hay muchas fuentes de tareas que se incluyen en ella. Pero después de recibir un conjunto de tareas, el esquema de operación de la cola es bastante simple. Por lo tanto, podemos separar la lógica específica de la aplicación del origen de la tarea del esquema generalizado de procesamiento de la cola de tareas. Recordando los patrones discutidos anteriormente de los grupos de contenedores, aquí puede ver la implementación del patrón Ambassador. El contenedor de la cola de tareas generalizadas es el contenedor principal de la aplicación, y el contenedor de origen específico de la aplicación es un embajador que transmite solicitudes desde el contenedor del gestor de colas a los ejecutores de tareas específicos. Este grupo de contenedores se muestra en la Fig. 10.2

Por cierto, aunque el contenedor embajador es específico de la aplicación (lo cual es obvio), también hay una serie de implementaciones generalizadas de la API de origen de la tarea. Por ejemplo, la fuente puede ser una lista de fotos ubicadas en algún almacenamiento en la nube, un conjunto de archivos en una unidad de red o incluso una cola en sistemas que funcionan con un principio de "publicación / suscripción", como Kafka o Redis. A pesar de que los usuarios pueden elegir los contenedores-embajadores más adecuados para su tarea, deben usar una implementación generalizada de "biblioteca" del contenedor. Esto minimizará la cantidad de trabajo y maximizará la reutilización del código.
API de cola de tareas Dado el mecanismo de interacción entre la cola de tareas y el contenedor dependiente de la aplicación, deberíamos formular una definición formal de la interfaz entre los dos contenedores. Existen muchos protocolos diferentes, pero las API RESTful de HTTP son fáciles de implementar y son el estándar de facto para tales interfaces. La cola de tareas espera que las siguientes URL se implementen en el contenedor posterior:
¿Por qué agregar v1 a su definición de API? ¿Habrá alguna vez una segunda versión de la interfaz? Parece ilógico, pero el costo de versionar la API cuando se define inicialmente es mínimo. Realizar la refactorización adecuada más adelante será extremadamente costoso. Establezca una regla para agregar versiones a todas las API, incluso si no está seguro de si alguna vez cambiarán. Dios salva la caja fuerte.
URL / items / devuelve una lista de todas las tareas:
{ kind: ItemList, apiVersion: v1, items: [ "item-1", "item-2", …. ] }
La URL / items / <item-name> proporciona información detallada sobre una tarea específica:
{ kind: Item, apiVersion: v1, data: { "some": "json", "object": "here", } }
Tenga en cuenta que la API no proporciona ningún mecanismo para corregir el hecho de la tarea. Se podría desarrollar una API más compleja y transferir la mayor parte de la implementación a un embajador de contenedores. Sin embargo, recuerde que nuestro objetivo es concentrar la mayor parte de la implementación general posible dentro del administrador de colas de tareas. A este respecto, el gestor de colas de tareas debe supervisar qué tareas ya se han procesado y cuáles aún no se han procesado.
De esta API obtenemos información sobre una tarea específica y luego pasamos el valor del campo item.data de la interfaz del contenedor del ejecutor.
Ejecutar interfaz de contenedor
Tan pronto como el gestor de colas reciba la siguiente tarea, debe confiarla a algún ejecutor. Esta es la segunda interfaz en la cola de tareas generalizadas. El contenedor en sí y su interfaz son ligeramente diferentes de la interfaz del contenedor de origen por varias razones. En primer lugar, es una API única. El trabajo del ejecutor comienza con una sola llamada, y durante el ciclo de vida del contenedor, no se realizan más llamadas. En segundo lugar, el contenedor de ejecución y el gestor de colas de tareas están en diferentes grupos de contenedores. El ejecutor del contenedor se inicia a través de la API del orquestador del contenedor en su propio grupo. Esto significa que el administrador de colas de tareas debe realizar una llamada remota para iniciar el contenedor de ejecución. También significa que debe tener más cuidado con los problemas de seguridad, ya que un usuario malintencionado del clúster puede cargarlo con trabajo innecesario.
En el contenedor de origen, utilizamos una simple llamada HTTP para enviar la lista de tareas al administrador de tareas. Esto se hizo suponiendo que esta llamada a la API debía hacerse varias veces, y no se tuvieron en cuenta los problemas de seguridad, ya que todo funcionaba dentro del marco localhost. La API del contenedor debe llamarse solo una vez y es importante asegurarse de que otros usuarios del sistema no puedan agregar trabajo a los ejecutores, incluso por accidente o por intención maliciosa. Por lo tanto, para el contenedor en ejecución, utilizaremos el archivo API. Tras la creación, le pasaremos al contenedor una variable de entorno llamada WORK_ITEM_FILE, cuyo valor se refiere a un archivo en el sistema de archivos interno del contenedor. Este archivo contiene datos sobre la tarea a completar. Este tipo de API, como se muestra a continuación, puede ser implementado por el objeto ConfigMap Kubernetes. Se puede montar en un grupo de contenedores como un archivo (Fig. 10.3).
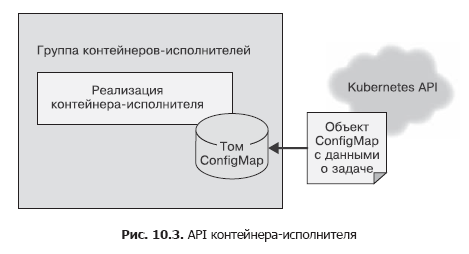
Tal mecanismo de API de archivo es más fácil de implementar usando un contenedor. Un ejecutor dentro de una cola de tareas es a menudo un simple script de shell que accede a varias herramientas. No es práctico crear un servidor web completo para la gestión de tareas; esto lleva a una complicación de la arquitectura. Como en el caso de las fuentes de tareas, la mayoría de los contenedores-ejecutores serán contenedores especializados para ciertas tareas, pero también hay ejecutores generalizados aplicables para resolver varias tareas diferentes.
Considere el ejemplo de un contenedor en ejecución que descarga un archivo del almacenamiento en la nube, ejecuta un script de shell en él y luego copia el resultado nuevamente en el almacenamiento en la nube. Tal contenedor puede ser en su mayor parte general, pero se le puede pasar un escenario específico como parámetro. Por lo tanto, la mayoría del código de manejo de archivos puede ser reutilizado por muchos usuarios / colas de tareas. El usuario final solo necesita proporcionar un script que contenga los detalles del procesamiento de archivos.
Infraestructura común de colas de tareas
¿Qué queda por implementar en una implementación de cola reutilizable si ya tiene implementaciones de las dos interfaces de contenedor descritas anteriormente? El algoritmo básico de la cola de tareas es bastante simple.
- Descargue las tareas disponibles actualmente del contenedor de origen.
- Aclare el estado de la cola de tareas para las tareas que ya se han completado o que aún se están realizando.
- Para cada una de las tareas no resueltas, cree contenedores de contenedores con una interfaz adecuada.
- Al completar con éxito el contenedor en ejecución, registre que la tarea se ha completado.
Este algoritmo es simple en palabras, pero en realidad no es tan fácil de implementar. Afortunadamente, la orquesta de Kubernetes tiene varias características que simplifican enormemente su implementación. A saber: Kubernetes tiene un objeto Job que garantiza un funcionamiento confiable de la cola de tareas. Puede configurar el objeto Trabajo para que inicie el contenedor de ejecución correspondiente una sola vez o hasta que la tarea se complete con éxito. Si configura el contenedor de ejecución para que se ejecute antes de que se complete la tarea, incluso cuando la máquina en el clúster falla, la tarea finalmente se completará con éxito.
Por lo tanto, la cola de tareas se simplifica enormemente, ya que la orquesta se responsabiliza de la ejecución confiable de las tareas.
Además, Kubernetes le permite anotar tareas, lo que nos permite marcar cada objeto de tarea con el nombre del elemento de la cola de tareas procesadas. Cada vez es más fácil distinguir entre las tareas que se procesan y se completan con éxito y con un error.
Esto significa que podemos implementar la cola de tareas sobre el orquestador de Kubernetes sin usar nuestro propio repositorio. Todo esto simplifica enormemente la tarea de construir la infraestructura de la cola de tareas.
Por lo tanto, un algoritmo detallado para la operación del contenedor, el administrador de colas de tareas, es el siguiente.
Repite sin cesar.
- Obtenga la lista de tareas a través de la interfaz del contenedor, la fuente de las tareas.
- Obtenga una lista de tareas que sirven a esta cola de tareas.
- Sobre la base de estas listas, seleccione una lista de tareas no procesadas.
- Para cada tarea no procesada, cree un objeto Job que genere el contenedor de ejecución correspondiente.
Aquí hay un script de Python que implementa esta cola:
import requests import json from kubernetes import client, config import time namespace = "default" def make_container(item, obj): container = client.V1Container() container.image = "my/worker-image" container.name = "worker" return container def make_job(item): response = requests.get("http://localhost:8000/items/{}".format(item)) obj = json.loads(response.text) job = client.V1Job() job.metadata = client.V1ObjectMeta() job.metadata.name = item job.spec = client.V1JobSpec() job.spec.template = client.V1PodTemplate() job.spec.template.spec = client.V1PodTemplateSpec() job.spec.template.spec.restart_policy = "Never" job.spec.template.spec.containers = [ make_container(item, obj) ] return job def update_queue(batch): response = requests.get("http://localhost:8000/items") obj = json.loads(response.text) items = obj['items'] ret = batch.list_namespaced_job(namespace, watch=False) for item in items: found = False for i in ret.items: if i.metadata.name == item: found = True if not found: # Job, # job = make_job(item) batch.create_namespaced_job(namespace, job) config.load_kube_config() batch = client.BatchV1Api() while True: update_queue(batch) time.sleep(10)
Taller Implementación de un generador de miniaturas para archivos de video
Como ejemplo de uso de la cola de tareas, considere la tarea de generar miniaturas de archivos de video. Con base en estas miniaturas, los usuarios deciden qué videos quieren ver.
Para implementar las miniaturas, necesita dos contenedores. El primero es para la fuente de las tareas. Será más fácil colocar tareas en una unidad de red compartida conectada, por ejemplo, a través de NFS (Sistema de archivos de red, sistema de archivos de red). El origen de la tarea recibe una lista de archivos en este directorio y los pasa a la persona que llama.
Daré un programa simple en NodeJS:
const http = require('http'); const fs = require('fs'); const port = 8080; const path = process.env.MEDIA_PATH; const requestHandler = (request, response) => { console.log(request.url); fs.readdir(path + '/*.mp4', (err, items) => { var msg = { 'kind': 'ItemList', 'apiVersion': 'v1', 'items': [] }; if (!items) { return msg; } for (var i = 0; i < items.length; i++) { msg.items.push(items[i]); } response.end(JSON.stringify(msg)); }); } const server = http.createServer(requestHandler); server.listen(port, (err) => { if (err) { return console.log(' ', err); } console.log(` ${port}`) });
Esta fuente define la lista de películas a procesar. La utilidad ffmpeg se usa para extraer miniaturas.
Puede crear un contenedor que ejecute el siguiente comando:
ffmpeg -i ${INPUT_FILE} -frames:v 100 thumb.png
El comando extrae uno de cada 100 fotogramas (-frames: v 100 parámetro) y lo guarda en formato PNG (por ejemplo, thumb1.png, thumb2.png, etc.).
Este tipo de procesamiento se puede implementar en función de la imagen existente de ffmpeg Docker. La
imagen de jrottenberg / ffmpeg es popular.
Al definir un contenedor de origen simple y un ejecutor de contenedor aún más simple, es fácil ver los beneficios de un sistema genérico de gestión de colas orientado a contenedores. Reduce significativamente el tiempo entre el diseño y la implementación de la cola de tareas.
Escalado dinámico de artistas.
La cola de tareas considerada anteriormente es adecuada para procesar tareas a medida que estén disponibles, pero puede provocar una carga abrupta en los recursos del orquestador del clúster de contenedores. Esto es bueno cuando tiene muchos tipos diferentes de tareas que crean picos de carga en diferentes momentos y, por lo tanto, distribuyen uniformemente la carga en el clúster a lo largo del tiempo.
Pero si no tiene suficientes tipos de carga, el enfoque "luego grueso y luego vacío" para escalar la cola de tareas puede requerir reservar recursos adicionales para soportar ráfagas de carga. El resto del tiempo, los recursos estarán inactivos, vaciando innecesariamente su billetera.
Para resolver este problema, puede limitar el número total de objetos de trabajo generados por la cola de tareas. Esto limitará naturalmente el número de trabajos procesados en paralelo y, en consecuencia, reducirá el uso de recursos durante las cargas máximas. Por otro lado, la duración de cada tarea individual aumentará con una carga alta en el clúster.
Si la carga es espasmódica, esto no da miedo, porque los intervalos de tiempo de inactividad se pueden usar para completar las tareas acumuladas. Sin embargo, si la carga constante es demasiado alta, la cola de tareas no tendrá tiempo para procesar las tareas entrantes y se dedicará cada vez más a su implementación.
En tal situación, deberá ajustar dinámicamente el número máximo de tareas paralelas y, en consecuencia, los recursos informáticos disponibles para mantener el nivel de rendimiento requerido. Afortunadamente, existen fórmulas matemáticas que le permiten determinar cuándo es necesario escalar la cola de tareas para procesar más solicitudes.
Considere una cola de tareas en la que una tarea nueva aparece en promedio una vez por minuto, y su finalización demora un promedio de 30 segundos. Dicha cola puede hacer frente al flujo de tareas que ingresan. Incluso si llega un gran paquete de tareas a la vez, creando un atasco de tráfico, el atasco se eliminará con el tiempo, porque antes de que llegue la siguiente tarea, la cola logra procesar un promedio de dos tareas.
Si llega una nueva tarea cada minuto y se tarda un promedio de 1 minuto en procesar una tarea, entonces dicho sistema está idealmente equilibrado, pero no responde bien a los cambios en la carga. Es capaz de hacer frente a los estallidos de carga, pero le llevará bastante tiempo. El sistema no estará inactivo, pero no habrá reserva de tiempo de computadora para compensar el aumento a largo plazo en la velocidad de recepción de nuevas tareas. Para mantener la estabilidad del sistema, es necesario tener una reserva en caso de crecimiento de la carga a largo plazo o retrasos imprevistos en las tareas de procesamiento.
Finalmente, considere un sistema en el que llega una tarea por minuto, y el procesamiento de la tarea lleva dos minutos. Tal sistema perderá constantemente rendimiento. La longitud de la cola de tareas crecerá junto con el retraso entre la recepción y el procesamiento de las tareas (y el grado de molestia de los usuarios).
Los valores de estos dos indicadores deben ser monitoreados constantemente. Al promediar el tiempo entre la recepción de tareas durante un largo período de tiempo, por ejemplo, en función del número de tareas por día, obtenemos una estimación del intervalo entre tareas. También es necesario monitorear el tiempo promedio de procesamiento de la tarea (excluyendo el tiempo pasado en la cola). En una cola de tareas estable, el tiempo promedio de procesamiento de tareas debe ser menor que el intervalo entre tareas. Para garantizar que se cumpla esta condición, es necesario ajustar dinámicamente el número de colas disponibles de recursos informáticos. Si los trabajos se procesan en paralelo, el tiempo de procesamiento debe dividirse por el número de trabajos procesados en paralelo. Por ejemplo, si una tarea se procesa por minuto, pero cuatro tareas se procesan en paralelo, el tiempo de procesamiento efectivo de una tarea es de 15 segundos, lo que significa que el intervalo entre tareas debe ser de al menos 16 segundos.
Este enfoque le permite crear fácilmente un módulo para escalar la cola de tareas hacia arriba. Reducir es algo más problemático. Sin embargo, es posible utilizar los mismos cálculos que antes, además de la reserva de recursos informáticos determinados por la forma heurística. Por ejemplo, puede reducir el número de tareas paralelas hasta que el tiempo de procesamiento para una tarea sea del 90% del intervalo entre tareas.
Patrón de múltiples trabajadores
Uno de los temas principales de este libro es el uso de contenedores para encapsular y reutilizar código. También es relevante para los patrones de colas de tareas descritos en este capítulo. Además de los contenedores que administran la cola en sí, puede reutilizar grupos de contenedores que conforman la implementación de los ejecutantes. Suponga que necesita procesar cada tarea en una cola de tres maneras diferentes. Por ejemplo, para detectar rostros en una fotografía, combínelos con personas específicas y luego difumine las partes correspondientes de la imagen. Puede poner todo el procesamiento en un contenedor de ejecución, pero esta es una solución única que no se puede reutilizar. Para ocultar algo más, como los automóviles, en la foto, tendrá que crear un artista contenedor desde cero.
La posibilidad de este tipo de reutilización se puede lograr aplicando el patrón Multi-Worker, que en realidad es un caso especial del patrón Adaptador descrito al comienzo del libro. El patrón Multi-Worker convierte un conjunto de contenedores en un contenedor común con la interfaz de software del contenedor en ejecución. Este contenedor compartido delega el procesamiento a varios contenedores reutilizables separados. Este proceso se muestra esquemáticamente en la Fig. 10.4
Al reutilizar el código combinando la ejecución de contenedores, se reduce el trabajo de las personas que diseñan sistemas de procesamiento por lotes distribuidos.
»Se puede encontrar más información sobre el libro en
el sitio web del editor»
Contenidos»
ExtractoPara habrozhitelami 20% de descuento en el cupón -
Sistemas distribuidos .