Hay una clase de tareas que no pueden acelerarse mediante la optimización de algoritmos, pero es necesario acelerar. En esta situación de casi punto muerto, los desarrolladores de procesadores vienen en nuestra ayuda, quienes han realizado comandos que nos permiten realizar operaciones en una gran cantidad de datos en una sola operación. En el caso de los procesadores x86, estas son instrucciones hechas en las extensiones MMX, SSE, SSE2, SSE3, SSE4, SSE4.1, SSE4.2, AVX, AVX2, AVX512.
Como un "conejillo de indias" tomé la siguiente tarea:
Hay una matriz arr desordenada con números de tipo uint16_t. Es necesario encontrar el número de ocurrencias del número v en la matriz arr.
Una solución clásica de tiempo lineal se ve así:
int64_t cnt = 0; for (int i = 0; i < ARR_SIZE; ++i) if (arr[i] == v) ++cnt;
Como tal, el punto de referencia muestra los siguientes resultados:
------------------------------------------------------------ Benchmark Time CPU Iterations ------------------------------------------------------------ BM_Count 2084 ns 2084 ns 333079
Debajo del corte, mostraré cómo acelerarlo más de 5 veces.
Entorno de prueba
Para las pruebas, utilicé una computadora portátil con un
Intel(R) Core(TM) i7-8750H CPU @ 2.20GHz . El compilador fue
clang version 6.0.0 . Para medir el rendimiento, elegí
libbenchmark de Google. El tamaño de la matriz tomó 1024 elementos, para no considerar el resto de los elementos de la manera clásica.
¿Qué es SIMD?
SIMD (Instrucción única, datos múltiples): secuencia de instrucciones única, secuencia de datos múltiples. En procesadores compatibles con x86, estos comandos se implementaron en varias generaciones de extensiones de procesador SSE y AVX. Hay muchos equipos, una lista completa de Intel se puede encontrar en
software.intel.com/sites/landingpage/IntrinsicsGuide . En los procesadores de escritorio AVX, las extensiones no están disponibles, así que centrémonos en SSE.
Para trabajar con SIMD en C / C ++, debe agregar código
#include <x86intrin.h>
Además, se debe informar al compilador que se deben usar extensiones, de lo contrario habrá errores del tipo
always_inline function '_popcnt32' requires target feature 'popcnt', but ... Hay varias formas de hacer esto:
- Enumere todas las
-mpopcnt necesarias, por ejemplo -mpopcnt - Especifique la arquitectura de destino del procesador que admite la función necesaria, por ejemplo
-march=corei7 - Ofrezca al compilador la capacidad de utilizar todas las extensiones del procesador en el que tiene lugar el ensamblaje:
-march=native
¿Qué se puede acelerar en el código de 3 líneas?
for (int i = 0; i < ARR_SIZE; ++i) if (arr[i] == v) ++cnt;
Sería bueno reducir el número de iteraciones y comparar de una vez con varios elementos en un ciclo. Abrimos el
sitio de Intel, seleccionamos solo extensiones SSE y la categoría "Comparar". El primero en la lista es la familia de funciones
__m128i _mm_cmpeq_epi* (__m128i a, __m128i b) .
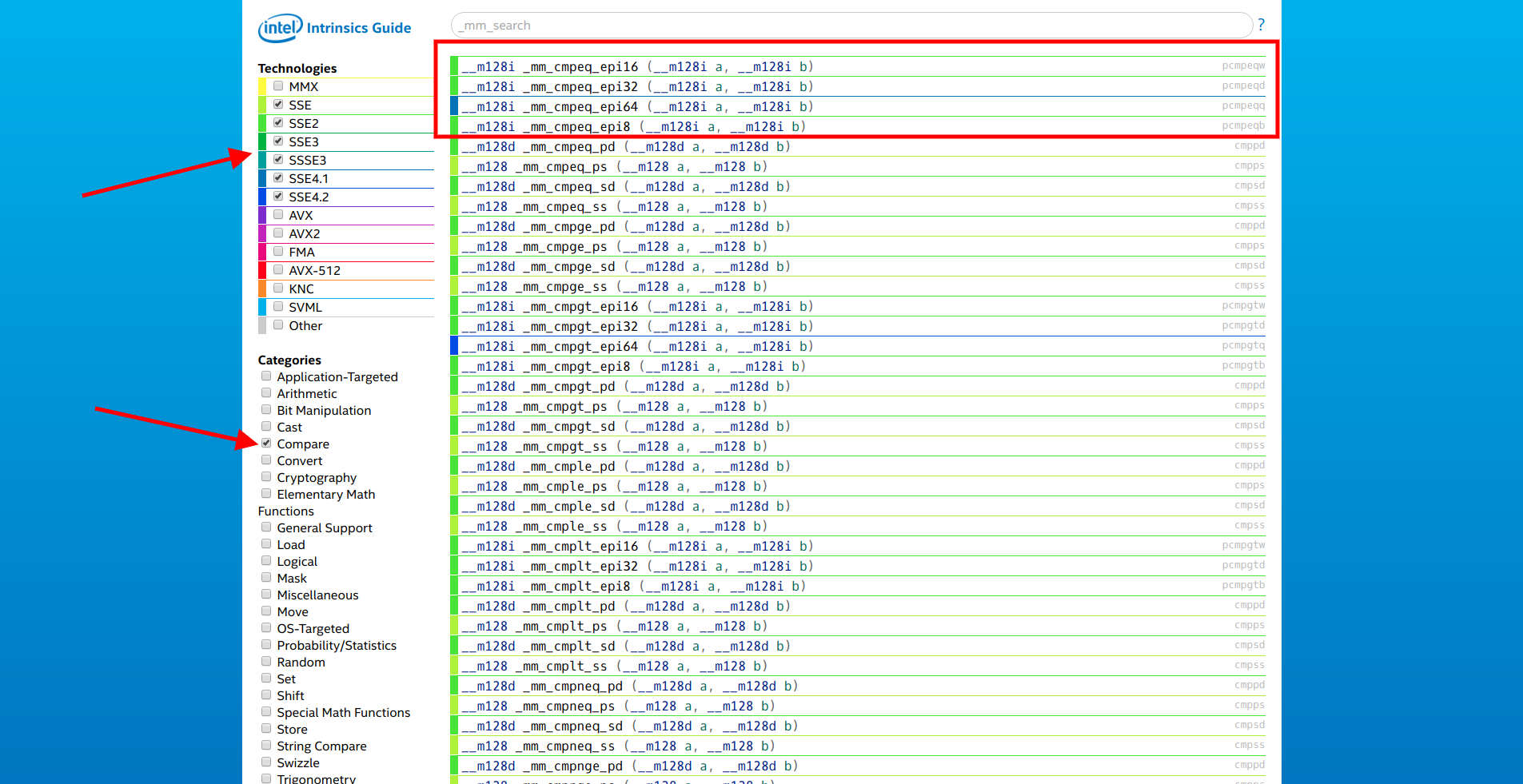
Abrimos la documentación del primero de ellos y vemos:
Compare enteros de 16 bits empaquetados en ayb para la igualdad, y almacene los resultados en dst.
Lo que necesitas! Solo queda convertir
[]int16_t en
__m128i . Para esto, se utilizan las funciones de las categorías "Establecer" y "Cargar".
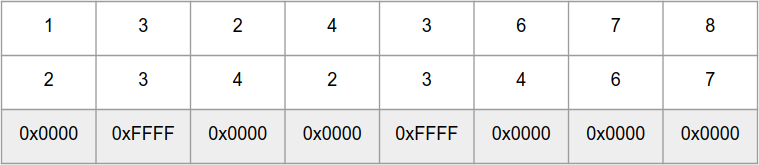
Entonces, la función
_mm_cmpeq_epi16 compara en paralelo 8 números
int16_t en las "matrices"
b , y devuelve una "matriz" de números 0xFFFF para los mismos elementos y 0x0000 para diferentes:
Para el cálculo rápido del número de bits en un número, hay funciones
_popcnt32 y
_popcnt64 que funcionan con números de 32 y 64 bits, respectivamente. Pero, desafortunadamente, no hay una función que pueda llevar el resultado de
_mm_cmpeq_epi16 a una máscara de bits, pero hay una función
_mm_movemask_epi8 que realiza la misma operación para una "matriz" de 16 números
int8_t . Pero
_mm_movemask_epi8 se puede usar para una "matriz" de 8 números
int16_t , justo al final el resultado deberá dividirse por 2.
Ahora hay todo para comenzar a probar SIMD.
Opcion 1
int64_t cnt = 0;
El punto de referencia mostró los siguientes resultados:
------------------------------------------------------------ Benchmark Time CPU Iterations ------------------------------------------------------------ BM_Count 2084 ns 2084 ns 333079 BM_SSE_COUNT_SET_EPI 937 ns 937 ns 746435
Solo 2 veces más rápido, y prometí 5+.
Para entender dónde puede haber cuellos de botella, debe bajar al nivel de ensamblador.
--------------- 8 sseArr --------------- auto sseArr = _mm_set_epi16(arr[i + 7], arr[i + 6], arr[i + 5], arr[i + 4], arr[i + 3], arr[i + 2], 40133a: 48 8b 05 77 1d 20 00 mov 0x201d77(%rip),%rax # 6030b8 <_ZL3arr> arr[i + 1], arr[i]); 401341: 48 63 8d 9c fe ff ff movslq -0x164(%rbp),%rcx auto sseArr = _mm_set_epi16(arr[i + 7], arr[i + 6], arr[i + 5], arr[i + 4], arr[i + 3], arr[i + 2], 401348: 66 8b 54 48 0e mov 0xe(%rax,%rcx,2),%dx 40134d: 66 8b 74 48 0c mov 0xc(%rax,%rcx,2),%si 401352: 66 8b 7c 48 0a mov 0xa(%rax,%rcx,2),%di 401357: 66 44 8b 44 48 08 mov 0x8(%rax,%rcx,2),%r8w 40135d: 66 44 8b 4c 48 06 mov 0x6(%rax,%rcx,2),%r9w 401363: 66 44 8b 54 48 04 mov 0x4(%rax,%rcx,2),%r10w arr[i + 1], arr[i]); 401369: 66 44 8b 1c 48 mov (%rax,%rcx,2),%r11w 40136e: 66 8b 5c 48 02 mov 0x2(%rax,%rcx,2),%bx auto sseArr = _mm_set_epi16(arr[i + 7], arr[i + 6], arr[i + 5], arr[i + 4], arr[i + 3], arr[i + 2], 401373: 66 89 55 ce mov %dx,-0x32(%rbp) 401377: 66 89 75 cc mov %si,-0x34(%rbp) 40137b: 66 89 7d ca mov %di,-0x36(%rbp) 40137f: 66 44 89 45 c8 mov %r8w,-0x38(%rbp) 401384: 66 44 89 4d c6 mov %r9w,-0x3a(%rbp) 401389: 66 44 89 55 c4 mov %r10w,-0x3c(%rbp) 40138e: 66 89 5d c2 mov %bx,-0x3e(%rbp) 401392: 66 44 89 5d c0 mov %r11w,-0x40(%rbp) 401397: 44 0f b7 75 c0 movzwl -0x40(%rbp),%r14d 40139c: c4 c1 79 6e c6 vmovd %r14d,%xmm0 4013a1: 44 0f b7 75 c2 movzwl -0x3e(%rbp),%r14d 4013a6: c4 c1 79 c4 c6 01 vpinsrw $0x1,%r14d,%xmm0,%xmm0 4013ac: 44 0f b7 75 c4 movzwl -0x3c(%rbp),%r14d 4013b1: c4 c1 79 c4 c6 02 vpinsrw $0x2,%r14d,%xmm0,%xmm0 4013b7: 44 0f b7 75 c6 movzwl -0x3a(%rbp),%r14d 4013bc: c4 c1 79 c4 c6 03 vpinsrw $0x3,%r14d,%xmm0,%xmm0 4013c2: 44 0f b7 75 c8 movzwl -0x38(%rbp),%r14d 4013c7: c4 c1 79 c4 c6 04 vpinsrw $0x4,%r14d,%xmm0,%xmm0 4013cd: 44 0f b7 75 ca movzwl -0x36(%rbp),%r14d 4013d2: c4 c1 79 c4 c6 05 vpinsrw $0x5,%r14d,%xmm0,%xmm0 4013d8: 44 0f b7 75 cc movzwl -0x34(%rbp),%r14d 4013dd: c4 c1 79 c4 c6 06 vpinsrw $0x6,%r14d,%xmm0,%xmm0 4013e3: 44 0f b7 75 ce movzwl -0x32(%rbp),%r14d 4013e8: c4 c1 79 c4 c6 07 vpinsrw $0x7,%r14d,%xmm0,%xmm0 4013ee: c5 f9 7f 45 b0 vmovdqa %xmm0,-0x50(%rbp) 4013f3: c5 f9 6f 45 b0 vmovdqa -0x50(%rbp),%xmm0 4013f8: c5 f9 7f 85 80 fe ff vmovdqa %xmm0,-0x180(%rbp) 4013ff: ff --------------- --------------- cnt += _popcnt32(_mm_movemask_epi8(_mm_cmpeq_epi16(sseVal, sseArr))); 401400: c5 f9 6f 85 a0 fe ff vmovdqa -0x160(%rbp),%xmm0 401407: ff 401408: c5 f9 6f 8d 80 fe ff vmovdqa -0x180(%rbp),%xmm1 40140f: ff 401410: c5 f9 7f 45 a0 vmovdqa %xmm0,-0x60(%rbp) 401415: c5 f9 7f 4d 90 vmovdqa %xmm1,-0x70(%rbp) 40141a: c5 f9 6f 45 a0 vmovdqa -0x60(%rbp),%xmm0 40141f: c5 f9 6f 4d 90 vmovdqa -0x70(%rbp),%xmm1 401424: c5 f9 75 c1 vpcmpeqw %xmm1,%xmm0,%xmm0 401428: c5 f9 7f 45 80 vmovdqa %xmm0,-0x80(%rbp) 40142d: c5 f9 6f 45 80 vmovdqa -0x80(%rbp),%xmm0 401432: c5 79 d7 f0 vpmovmskb %xmm0,%r14d 401436: 44 89 b5 7c ff ff ff mov %r14d,-0x84(%rbp) 40143d: 44 8b b5 7c ff ff ff mov -0x84(%rbp),%r14d 401444: f3 45 0f b8 f6 popcnt %r14d,%r14d 401449: 49 63 c6 movslq %r14d,%rax 40144c: 48 03 85 b8 fe ff ff add -0x148(%rbp),%rax 401453: 48 89 85 b8 fe ff ff mov %rax,-0x148(%rbp)
Se puede ver que muchas instrucciones del procesador toman elementos de matriz de copia en
sseArr .
Opción 2
En lugar de la función
_mm_set_epi16 , puede usar
_mm_loadu_si128 . Descripción de la función:
Cargue 128 bits de datos enteros de la memoria no alineada en dst
Se espera un puntero a la memoria en la entrada, lo que sugiere una copia más óptima de los datos en la variable. Comprobar:
int64_t cnt = 0; auto sseVal = _mm_set1_epi16(VAL); for (int i = 0; i < ARR_SIZE; i += 8) { auto sseArr = _mm_loadu_si128((__m128i *) &arr[i]); cnt += _popcnt32(_mm_movemask_epi8(_mm_cmpeq_epi16(sseVal, sseArr))); }
El punto de referencia mostró una mejora de ~ 2 veces:
------------------------------------------------------------ Benchmark Time CPU Iterations ------------------------------------------------------------ BM_Count 2084 ns 2084 ns 333079 BM_SSE_COUNT_SET_EPI 937 ns 937 ns 746435 BM_SSE_COUNT_LOADU 454 ns 454 ns 1548455
El código de la máquina se ve así:
auto sseArr = _mm_loadu_si128((__m128i *) &arr[i]); 401695: 48 8b 05 1c 1a 20 00 mov 0x201a1c(%rip),%rax # 6030b8 <_ZL3arr> 40169c: 48 63 8d bc fe ff ff movslq -0x144(%rbp),%rcx 4016a3: 48 8d 04 48 lea (%rax,%rcx,2),%rax 4016a7: 48 89 45 d8 mov %rax,-0x28(%rbp) 4016ab: 48 8b 45 d8 mov -0x28(%rbp),%rax 4016af: c5 fa 6f 00 vmovdqu (%rax),%xmm0 4016b3: c5 f9 7f 85 a0 fe ff vmovdqa %xmm0,-0x160(%rbp) 4016ba: ff cnt += _popcnt32(_mm_movemask_epi8(_mm_cmpeq_epi16(sseVal, sseArr))); 4016bb: c5 f9 6f 85 c0 fe ff vmovdqa -0x140(%rbp),%xmm0 4016c2: ff 4016c3: c5 f9 6f 8d a0 fe ff vmovdqa -0x160(%rbp),%xmm1 4016ca: ff 4016cb: c5 f9 7f 45 c0 vmovdqa %xmm0,-0x40(%rbp) 4016d0: c5 f9 7f 4d b0 vmovdqa %xmm1,-0x50(%rbp) 4016d5: c5 f9 6f 45 c0 vmovdqa -0x40(%rbp),%xmm0 4016da: c5 f9 6f 4d b0 vmovdqa -0x50(%rbp),%xmm1 4016df: c5 f9 75 c1 vpcmpeqw %xmm1,%xmm0,%xmm0 4016e3: c5 f9 7f 45 a0 vmovdqa %xmm0,-0x60(%rbp) 4016e8: c5 f9 6f 45 a0 vmovdqa -0x60(%rbp),%xmm0 4016ed: c5 f9 d7 d0 vpmovmskb %xmm0,%edx 4016f1: 89 55 9c mov %edx,-0x64(%rbp) 4016f4: 8b 55 9c mov -0x64(%rbp),%edx 4016f7: f3 0f b8 d2 popcnt %edx,%edx 4016fb: 48 63 c2 movslq %edx,%rax 4016fe: 48 03 85 d8 fe ff ff add -0x128(%rbp),%rax 401705: 48 89 85 d8 fe ff ff mov %rax,-0x128(%rbp)
Opción 3
Las instrucciones SSE funcionan con memoria de 16 bytes alineados. La función _mm_loadu_si128 evita esta limitación, pero si asigna memoria para la matriz utilizando la función
aligned_alloc(16, SZ) , puede pasar directamente la dirección a la instrucción SSE:
int64_t cnt = 0; auto sseVal = _mm_set1_epi16(VAL); for (int i = 0; i < ARR_SIZE; i += 8) { auto sseArr = *(__m128i *) &allignedArr[i]; cnt += _popcnt32(_mm_movemask_epi8(_mm_cmpeq_epi16(sseVal, sseArr))); }
Tal optimización ofrece un poco más de rendimiento:
------------------------------------------------------------ Benchmark Time CPU Iterations ------------------------------------------------------------ BM_Count 2084 ns 2084 ns 333079 BM_SSE_COUNT_SET_EPI 937 ns 937 ns 746435 BM_SSE_COUNT_LOADU 454 ns 454 ns 1548455 BM_SSE_COUNT_DIRECT 395 ns 395 ns 1770803
Esto sucedió debido al guardado de 3 instrucciones:
auto sseArr = *(__m128i *) &allignedArr[i]; 40193c: 48 8b 05 7d 17 20 00 mov 0x20177d(%rip),%rax # 6030c0 <_ZL11allignedArr> 401943: 48 63 8d cc fe ff ff movslq -0x134(%rbp),%rcx 40194a: c5 f9 6f 04 48 vmovdqa (%rax,%rcx,2),%xmm0 40194f: c5 f9 7f 85 b0 fe ff vmovdqa %xmm0,-0x150(%rbp) 401956: ff cnt += _popcnt32(_mm_movemask_epi8(_mm_cmpeq_epi16(sseVal, sseArr))); 401957: c5 f9 6f 85 d0 fe ff vmovdqa -0x130(%rbp),%xmm0 40195e: ff 40195f: c5 f9 6f 8d b0 fe ff vmovdqa -0x150(%rbp),%xmm1 401966: ff 401967: c5 f9 7f 45 d0 vmovdqa %xmm0,-0x30(%rbp) 40196c: c5 f9 7f 4d c0 vmovdqa %xmm1,-0x40(%rbp) 401971: c5 f9 6f 45 d0 vmovdqa -0x30(%rbp),%xmm0 401976: c5 f9 6f 4d c0 vmovdqa -0x40(%rbp),%xmm1 40197b: c5 f9 75 c1 vpcmpeqw %xmm1,%xmm0,%xmm0 40197f: c5 f9 7f 45 b0 vmovdqa %xmm0,-0x50(%rbp) 401984: c5 f9 6f 45 b0 vmovdqa -0x50(%rbp),%xmm0 401989: c5 f9 d7 d0 vpmovmskb %xmm0,%edx 40198d: 89 55 ac mov %edx,-0x54(%rbp) 401990: 8b 55 ac mov -0x54(%rbp),%edx 401993: f3 0f b8 d2 popcnt %edx,%edx 401997: 48 63 c2 movslq %edx,%rax 40199a: 48 03 85 e8 fe ff ff add -0x118(%rbp),%rax 4019a1: 48 89 85 e8 fe ff ff mov %rax,-0x118(%rbp)
Conclusión
Todos estos listados de ensamblaje se obtuvieron después de la compilación con -O0. Si habilita -O3, el compilador optimiza el código bastante bien y no habrá tal división de tiempo:
------------------------------------------------------------ Benchmark Time CPU Iterations ------------------------------------------------------------ BM_Count 129 ns 129 ns 5359145 BM_SSE_COUNT_SET_EPI 70 ns 70 ns 9936200 BM_SSE_COUNT_LOADU 49 ns 49 ns 14187659 BM_SSE_COUNT_DIRECT 53 ns 53 ns 13401612
Código de referencia #include <benchmark/benchmark.h> #include <x86intrin.h> #include <cstring> #define ARR_SIZE 1024 #define VAL 50 static int16_t *getRandArr() { auto res = new int16_t[ARR_SIZE]; for (int i = 0; i < ARR_SIZE; ++i) { res[i] = static_cast<int16_t>(rand() % (VAL * 2)); } return res; } static auto arr = getRandArr(); static int16_t *getAllignedArr() { auto res = aligned_alloc(16, sizeof(int16_t) * ARR_SIZE); memcpy(res, arr, sizeof(int16_t) * ARR_SIZE); return static_cast<int16_t *>(res); } static auto allignedArr = getAllignedArr(); static void BM_Count(benchmark::State &state) { for (auto _ : state) { int64_t cnt = 0; for (int i = 0; i < ARR_SIZE; ++i) if (arr[i] == VAL) ++cnt; benchmark::DoNotOptimize(cnt); } } BENCHMARK(BM_Count); static void BM_SSE_COUNT_SET_EPI(benchmark::State &state) { for (auto _ : state) { int64_t cnt = 0; auto sseVal = _mm_set1_epi16(VAL); for (int i = 0; i < ARR_SIZE; i += 8) { auto sseArr = _mm_set_epi16(arr[i + 7], arr[i + 6], arr[i + 5], arr[i + 4], arr[i + 3], arr[i + 2], arr[i + 1], arr[i]); cnt += _popcnt32(_mm_movemask_epi8(_mm_cmpeq_epi16(sseVal, sseArr))); } benchmark::DoNotOptimize(cnt >> 1); } } BENCHMARK(BM_SSE_COUNT_SET_EPI); static void BM_SSE_COUNT_LOADU(benchmark::State &state) { for (auto _ : state) { int64_t cnt = 0; auto sseVal = _mm_set1_epi16(VAL); for (int i = 0; i < ARR_SIZE; i += 8) { auto sseArr = _mm_loadu_si128((__m128i *) &arr[i]); cnt += _popcnt32(_mm_movemask_epi8(_mm_cmpeq_epi16(sseVal, sseArr))); } benchmark::DoNotOptimize(cnt >> 1); } } BENCHMARK(BM_SSE_COUNT_LOADU); static void BM_SSE_COUNT_DIRECT(benchmark::State &state) { for (auto _ : state) { int64_t cnt = 0; auto sseVal = _mm_set1_epi16(VAL); for (int i = 0; i < ARR_SIZE; i += 8) { auto sseArr = *(__m128i *) &allignedArr[i]; cnt += _popcnt32(_mm_movemask_epi8(_mm_cmpeq_epi16(sseVal, sseArr))); } benchmark::DoNotOptimize(cnt >> 1); } } BENCHMARK(BM_SSE_COUNT_DIRECT); BENCHMARK_MAIN();
Parte 2