El hardware y los compiladores modernos están listos para cambiar nuestro código, si solo funciona más rápido. Y sus fabricantes esconden cuidadosamente su cocina interior. Y todo está bien siempre que el código se ejecute en un hilo.
En un entorno de subprocesos múltiples, puede forzosamente observar cosas interesantes. Por ejemplo, la ejecución de las instrucciones del programa no está en el orden que está escrito en el código fuente. De acuerdo, es desagradable darse cuenta de que ejecutar el código fuente línea por línea es solo nuestra imaginación.
Pero todos ya se han dado cuenta, porque de alguna manera hay que vivir con eso. Y los programadores de Java incluso viven bien. Debido a que Java tiene un modelo de memoria, el Modelo de Memoria Java (JMM), que proporciona reglas bastante simples para escribir el código correcto de subprocesos múltiples.
Y estas reglas son suficientes para la mayoría de los programas. Si no los conoce, pero escribe o desea escribir programas multiproceso en Java, entonces es mejor familiarizarse con
ellos lo antes posible. Y si lo sabes, pero no tienes suficiente contexto o es interesante saber de dónde crecen las piernas de JMM, entonces este artículo puede ayudarte.
Y persiguiendo la abstracción
En mi opinión, hay un pastel o, más convenientemente, un iceberg. JMM es la punta del iceberg. El iceberg en sí es una teoría de la programación multiproceso bajo el agua. Debajo del iceberg está el infierno.

Un iceberg es una abstracción; si se filtra, ciertamente veremos el infierno. Aunque están sucediendo muchas cosas interesantes allí, en el artículo de revisión no llegaremos a esto.
En el artículo, estoy más interesado en los siguientes temas:
- Teoria y Terminologia
- ¿Cómo se refleja la teoría de la programación multiproceso en JMM?
- Modelos de programación competitiva
La teoría de la programación multiproceso le permite alejarse de la complejidad de los procesadores y compiladores modernos, le permite simular la ejecución de programas multiproceso y estudiar sus propiedades. Roman Elizarov hizo un excelente
informe , cuyo propósito es proporcionar una base teórica para comprender JMM. Recomiendo el informe a todos los que estén interesados en este tema.
¿Por qué es importante conocer la teoría? En mi opinión, espero solo para los míos, algunos programadores tienen la opinión de que JMM es una complicación del lenguaje y la reparación de algunos problemas de plataforma con subprocesos múltiples. La teoría muestra que Java no complicó, sino que simplificó y convirtió la programación multiproceso más compleja y predecible.
Competencia y concurrencia
Primero, veamos la terminología. Desafortunadamente, no hay consenso en la terminología: al estudiar diferentes materiales, puede encontrar diferentes definiciones de competencia y concurrencia.
El problema es que incluso si llegamos al fondo de la verdad y encontramos las definiciones exactas de estos conceptos, todavía no vale la pena esperar que todos signifiquen lo mismo con estos conceptos. No
encontrarás los extremos aquí.
Roman Elizarov, en un informe, la teoría de la programación paralela para profesionales sugiere que a veces estos conceptos son mixtos. La programación paralela a veces se distingue como un concepto general que se divide en competitivo y distribuido.
Me parece que en el contexto de JMM todavía necesita separar la competencia y el paralelismo, o más bien incluso comprender que hay dos paradigmas diferentes, sin importar cómo se llamen.
A menudo citado por Rob Pike, quien distingue entre conceptos de la siguiente manera:
- La competencia es una forma de resolver simultáneamente muchos problemas.
- La concurrencia es una forma de realizar diferentes partes de una sola tarea.
La opinión de Rob Pike no es un estándar, pero en mi opinión, es conveniente aprovecharla para seguir estudiando el tema. Lea más sobre las diferencias
aquí .
Lo más probable es que aparezca una mayor comprensión del problema si destacamos las características principales de un programa competitivo y paralelo. Hay muchos signos, considere los más significativos.
Señales de competencia.
- La presencia de varios flujos de control (por ejemplo, Thread en Java, corutina en Kotlin), si solo hay un flujo de control, entonces no puede haber una ejecución competitiva
- Resultado no determinista. El resultado depende de eventos aleatorios, implementación y cómo se realizó la sincronización. Incluso si cada secuencia es completamente determinista, el resultado final será no determinista
Un programa paralelo tendrá un conjunto diferente de características.
- Opcional tiene múltiples flujos de control
- Puede conducir a un resultado determinista, por ejemplo, el resultado de multiplicar cada elemento de la matriz por un número no cambiará si lo multiplica en partes en paralelo
Curiosamente, la ejecución en paralelo es posible en un solo flujo de control, e incluso en una arquitectura de un solo núcleo. El hecho es que el paralelismo a nivel de tareas (o flujos de control) a los que estamos acostumbrados no es la única forma de realizar cálculos en paralelo.
La concurrencia es posible a nivel de:
- bits (por ejemplo, en máquinas de 32 bits, la adición se realiza en una acción, procesando los 4 bytes de un número de 32 bits en paralelo)
- instrucciones (en un núcleo, en un hilo, el procesador puede ejecutar instrucciones en paralelo, a pesar de que el código es secuencial)
- datos (hay arquitecturas con procesamiento de datos paralelo (Datos múltiples de instrucción única) que pueden ejecutar una instrucción en un conjunto de datos grande)
- tareas (implica la presencia de múltiples procesadores o núcleos)
La concurrencia a nivel de instrucción es un ejemplo de optimizaciones que ocurren con la ejecución de código que están ocultas para el programador.
Se garantiza que el código optimizado será equivalente al original dentro del marco de un hilo, porque es imposible escribir código adecuado y predecible si no hace lo que el programador pretendía.
No todo lo que se ejecuta en paralelo es importante para JMM. La ejecución concurrente en el nivel de instrucción dentro de un solo hilo no se considera en JMM.
La terminología es muy inestable, con una presentación de Roman Elizarov llamada "Teoría de la programación
paralela para profesionales", aunque hay más sobre programación competitiva, si se atiene a lo anterior.
En el contexto de JMM, en el artículo me limitaré al término competencia, ya que la competencia es a menudo sobre el estado general. Pero aquí debe tener cuidado de no aferrarse a los términos, sino comprender que existen diferentes paradigmas.
Modelos con un estado común: "rotación de operaciones" y "sucedió antes"
En su
artículo, Maurice Herlichi (autor de la programación The Art Of Multiprocessor) escribe que un sistema competitivo contiene una colección de procesos secuenciales (en trabajos teóricos significa lo mismo que un hilo) que se comunican a través de la memoria compartida.
El modelo de estado general incluye cálculos con mensajes, donde el estado compartido es una cola de mensajes y cálculos con memoria compartida, donde el estado común son estructuras en la memoria.
Cada uno de los cálculos puede ser simulado.
El modelo se basa en una máquina de estados finitos. El modelo se centra exclusivamente en el estado compartido y los datos locales de cada uno de los flujos se ignoran por completo. Cada acción de flujos sobre un estado compartido es una función de la transición a un nuevo estado.
Entonces, por ejemplo, si 4 hilos escriben datos en una variable compartida, entonces habrá 4 funciones para la transición a un nuevo estado. Cuál de estas funciones se aplicará depende de la cronología de los eventos en el sistema.
Los cálculos de paso de mensajes se modelan de manera similar, solo el estado y las funciones de transición dependen del envío o recepción de mensajes.
Si el modelo le pareció complicado, en el ejemplo lo arreglaremos. Es realmente muy simple e intuitivo. Tanto es así que sin saber acerca de la existencia de este modelo, la mayoría de las personas aún analizará el programa como sugiere el modelo.
Tal modelo se llama modelo de
rendimiento a través de la alternancia de operaciones (el nombre se escuchó en un informe de Roman Elizarov).
En la intuición y naturalidad, puede anotar con seguridad las ventajas del modelo. Puede entrar en la naturaleza con las palabras clave
Consistencia secuencial y el
trabajo de Leslie Lamport.
Sin embargo, hay una aclaración importante sobre este modelo. El modelo tiene la limitación de que todas las acciones en un estado compartido deben ser instantáneas y, al mismo tiempo, las acciones no pueden ocurrir simultáneamente. Dicen que dicho sistema tiene un
orden lineal : todas las acciones en el sistema están ordenadas.
En la práctica, esto no sucede. La operación no ocurre instantáneamente, sino que se realiza en un intervalo; en los sistemas de múltiples núcleos, estos intervalos pueden cruzarse. Por supuesto, esto no significa que el modelo sea inútil en la práctica, solo necesita crear ciertas condiciones para su uso.
Mientras tanto, considere otro
modelo: "sucedió antes", que se centra no en el estado, sino en el conjunto de celdas de memoria de lectura y escritura durante la ejecución (historial) y sus relaciones.
El modelo dice que los eventos en diferentes flujos no son instantáneos y atómicos, sino paralelos, y que no es posible construir un orden entre ellos. Los eventos (escritura y lectura de datos compartidos) en flujos en una arquitectura multiprocesador o multinúcleo ocurren realmente en paralelo. No existe un concepto de tiempo global en el sistema, no podemos entender cuándo terminó una operación y comenzó otra.
En la práctica, esto significa que podemos escribir un valor en una variable en un hilo y hacerlo, por ejemplo, en la mañana, y leer el valor de esta variable en otro hilo en la noche, y no podemos decir que seguro leeremos el valor escrito en la mañana. En teoría, estas operaciones tienen lugar en paralelo y no está claro cuándo terminará una y comenzará otra operación.
Es difícil imaginar cómo resulta que las operaciones simples de lectura y escritura realizadas en diferentes momentos del día tienen lugar simultáneamente. Pero si lo piensa, realmente no nos importa cuándo ocurren los eventos de escritura y lectura, si no podemos garantizar que veremos el resultado de la grabación.
Y realmente no podemos ver el resultado de la grabación, es decir en una variable cuyo valor es
0 en la secuencia
P, escribimos
1 , y en la secuencia
Q leemos esta variable. No importa cuánto tiempo físico pase después de la grabación, aún podemos leer
0 .
Así es como funcionan las computadoras y el modelo lo refleja.El modelo es completamente abstracto y necesita una visualización conveniente para un trabajo conveniente. Para la visualización y solo para ello, se utiliza un modelo con tiempo global, con reservas de que al probar las propiedades de los programas, no se utiliza el tiempo global. En la visualización, cada evento se representa como un intervalo con un principio y un final.
Los eventos tienen lugar en paralelo, como descubrimos. Pero aún así, el sistema tiene un
orden parcial , ya que hay pares especiales de eventos que tienen un orden, en cuyo caso dicen que estos eventos tienen una relación "sucedió antes". Si escuchas por primera vez acerca de la relación "sucedió antes", entonces probablemente saber el hecho de que esta relación organiza los eventos no te ayudará mucho.
Intentando analizar un programa Java
Consideramos un mínimo teórico, tratemos de seguir adelante y consideremos un programa multiproceso en un lenguaje específico: Java, a partir de dos hilos con un estado mutable común.
Un ejemplo clásico
private static int x = 0, y = 0; private static int a = 0, b = 0; synchronized (this) { a = 0; b = 0; x = 0; y = 0; } Thread p = new Thread(() -> { a = 1; x = b; }); Thread q = new Thread(() -> { b = 1; y = a; }); p.start(); q.start(); p.join(); q.join(); System.out.println("x=" + x + ", y=" + y);
Necesitamos simular la ejecución de este programa y obtener todos los resultados posibles: los valores de las variables x e y. Habrá varios resultados, como recordamos de la teoría, tal programa no es determinista.
¿Cómo vamos a modelar? Inmediatamente quiero usar el modelo de operaciones entrelazado. Pero el modelo "sucedió antes" nos dice que los eventos en un hilo son paralelos a los eventos de otro hilo. Por lo tanto, el modelo de operaciones alternas aquí no es apropiado si no existe una relación "ocurrida antes" entre las operaciones.
El resultado de la ejecución de cada subproceso siempre está determinado, ya que los eventos en un subproceso siempre están ordenados, considere que reciben una relación "sucedió antes" de forma gratuita. Pero cómo los eventos en diferentes flujos pueden obtener la relación "sucedió antes" no es del todo obvio. Por supuesto, esta relación se formaliza en el modelo, todo el modelo está escrito en lenguaje matemático. Pero qué hacer con esto en la práctica, en un idioma en particular, no se entiende de inmediato.
Cuales son las opciones?
Ignorar restricciones y simular intercalación. Puedes probarlo, tal vez no pase nada malo.
Para comprender qué tipo de resultados se pueden obtener, simplemente enumeramos todas las posibles variantes de ejecución.
Todas las ejecuciones de programas posibles se pueden representar como una máquina de estados finitos.
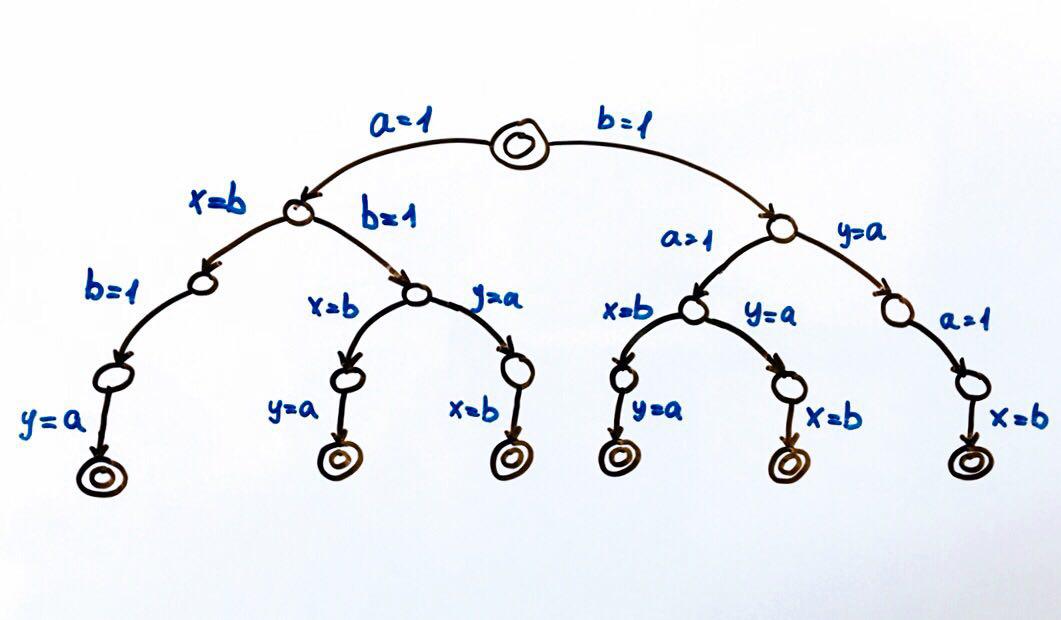
Cada círculo es un estado del sistema, en nuestro caso las variables
a, b, x, y . Una función de transición es una acción en un estado que coloca al sistema en un nuevo estado. Dado que dos flujos pueden realizar acciones en el estado general, habrá dos transiciones desde cada estado. Los círculos dobles son los estados finales e iniciales del sistema.
En total, son posibles 6 ejecuciones diferentes, que resultan en pares de valores x, y:
(1, 1), (1, 0), (0, 1)
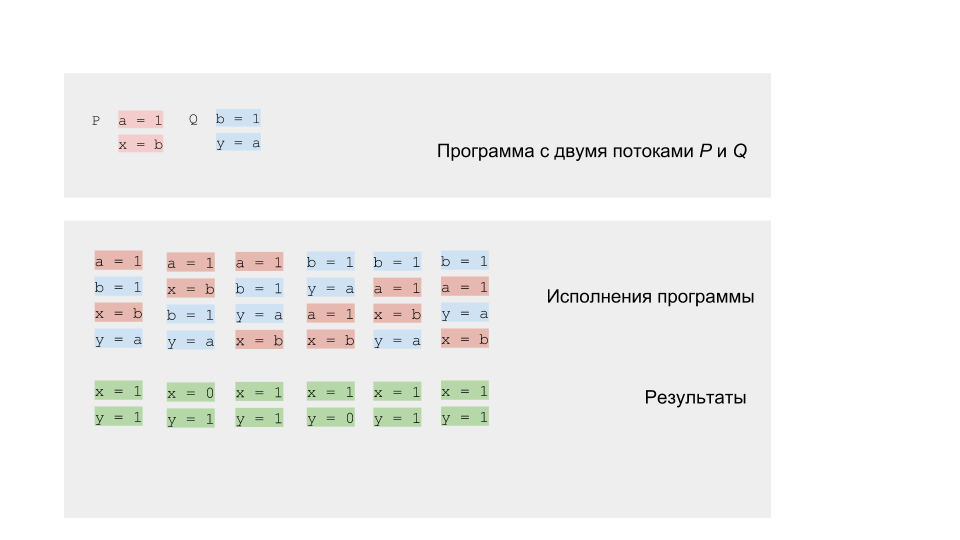
Podemos ejecutar el programa y verificar los resultados. Como corresponde a un programa competitivo, tendrá un resultado no determinista.
Para probar programas competitivos, es mejor usar herramientas especiales (
herramienta ,
informe ).
Pero puede intentar ejecutar el programa varios millones de veces, o incluso mejor, escribir un ciclo que lo haga por nosotros.
Si ejecutamos el código en una arquitectura de núcleo único o procesador único, entonces deberíamos obtener el resultado del conjunto que esperamos. El modelo de rotación funcionará bien. En la arquitectura multinúcleo, por ejemplo x86, podemos sorprendernos con el resultado: podemos obtener el resultado (0,0), que no puede ser de acuerdo con nuestro modelo.
La explicación de esto se puede encontrar en Internet por la palabra clave:
reordenamiento . Ahora es importante comprender que
el modelado entrelazado realmente no es adecuado en una situación en la que no podemos determinar el orden de acceso al estado compartido .
Teoría de la programación competitiva y JMM
Es hora de echar un vistazo más de cerca a la relación "sucedió antes" y cómo se hace amigo de JMM. La definición original de la relación "sucedió antes" se puede encontrar en Hora, Relojes y Ordenación de eventos en un sistema distribuido.
El modelo de memoria de lenguaje ayuda a escribir código competitivo, ya que determina qué operaciones están relacionadas con "sucedió antes". Una lista de tales operaciones se presenta en la
especificación en la sección Orden antes de que ocurra. De hecho, esta sección responde a la pregunta: ¿bajo qué condiciones veremos el resultado de la grabación en otra transmisión?
Hay varios pedidos en JMM. Alexei Shipilev habla muy vigorosamente sobre las reglas en uno de sus
informes .
En el modelo de tiempo global, todas las operaciones en el mismo hilo están en orden. Por ejemplo, los eventos de escribir y leer una variable se pueden representar como dos intervalos, luego el modelo garantiza que estos intervalos nunca se crucen dentro del marco de una sola secuencia. En JMM, este orden se llama Orden de programa (
PO ).
PO vincula acciones en un solo hilo y no dice nada sobre el orden de ejecución, solo habla sobre el orden en el código fuente. Esto es suficiente para garantizar el
determinismo para cada flujo por separado .
PO puede considerarse como datos sin procesar.
PO es siempre fácil de organizar en un programa: todas las operaciones (orden lineal) en el código fuente dentro de una sola secuencia tendrán
PO .
En nuestro ejemplo, obtenemos algo como lo siguiente:
P: a = 1 PO x = b - escribir en ay leer b tiene orden de pedido
Q: b = 1 PO y = a - escribe en b y lee a tiene orden de pedido
Vi esta forma de escribir
w (a, 1) PO r (b): 0. Realmente espero que nadie la haya patentado para informes. Sin embargo, la especificación tiene una forma similar.
Pero cada hilo individualmente no es particularmente interesante para nosotros, ya que los hilos tienen un estado común, estamos más interesados en la interacción de los flujos. Todo lo que queremos es asegurarnos de que veremos un registro de variables en otros hilos.
Permítame recordarle que esto no funcionó para nosotros, porque las operaciones de escritura y lectura de variables en diferentes flujos no son instantáneas (estos son segmentos que se cruzan), respectivamente, es imposible analizar dónde están el comienzo y el final de las operaciones.
La idea es simple: en el momento en que leemos la variable a en la secuencia
Q , el registro de esta misma variable en la secuencia
P podría no terminar todavía. Y no importa cuánto tiempo físico compartan estos eventos: un nanosegundo o unas pocas horas.
Para ordenar eventos, necesitamos la relación "sucedió antes". JMM define esta relación. La especificación corrige el orden en un hilo:
Si la operación x e y están en el mismo hilo y en PO x ocurre primero, y luego y, entonces x sucedió antes que y.
Mirando hacia el futuro, podemos decir que podemos reemplazar todas las
OP con Happens-before (
HB ):
P: w(a, 1) HB r(b) Q: w(b, 1) HB r(a)
Pero nuevamente volvemos dentro del marco de una secuencia.
HB es posible entre operaciones que ocurren en diferentes hilos, para tratar estos casos nos familiarizaremos con otras órdenes.
Orden de sincronización (
SO ): vincula las acciones de sincronización (
SA ), se proporciona una lista completa de
SA en la especificación, en la sección 17.4.2. Acciones Aquí hay algunos de ellos:
- Lectura de variable volátil
- Escribir variable volátil
- Monitor de bloqueo
- Desbloquear monitor
SO es interesante para nosotros, porque tiene la propiedad de que todas las lecturas en el orden
SO ven las últimas entradas en
SO . Y les recuerdo que solo lo estamos logrando.
En este lugar, repetiré lo que buscamos. Tenemos un programa multiproceso, queremos simular todas las ejecuciones posibles y obtener todos los resultados que puede dar. Hay modelos que permiten que esto se haga de manera bastante simple. Pero requieren que se ordenen todas las acciones en el estado compartido.
De acuerdo con la propiedad
SO : si todas las acciones del programa son
SA , alcanzaremos nuestro objetivo. Es decir Podemos establecer un
modificador volátil para todas las variables y podemos usar el modelo de alternancia. Si la intuición te dice que esto no vale la pena, entonces tienes toda la razón. Con estas acciones, simplemente prohibimos las optimizaciones sobre el código, por supuesto, a veces esta es una buena opción, pero definitivamente no es un caso general.
Considere otra orden Sincronizar con (
SW ): orden SO para desbloqueo / bloqueo específico, escritura / lectura de pares volátiles. No importa en qué flujos estarán estas acciones, lo principal es que están en el mismo monitor, variable volátil.
SW proporciona un puente entre hilos.
Y ahora llegamos al orden más interesante: sucede antes (
HB ).
HB es un cierre transitivo de la unión de
SW y
PO .
PO da un orden lineal dentro de la secuencia, y
SW proporciona un puente entre las secuencias.
HB es transitivo, es decir si
x HB y y HB z, x HB z
La especificación tiene una lista de relaciones
HB , puede familiarizarse con ella con más detalle, aquí hay algunas de la lista:
Dentro de un solo hilo, cualquier operación sucede antes que cualquier operación que la siga en el código fuente.
Sale de un bloque / método sincronizado antes de ingresar un bloque / método sincronizado en el mismo monitor.
Escribir un campo
volátil sucede antes de leer el mismo campo
volátil .
Volvamos a nuestro ejemplo:
P: a = 1 PO x = b Q: b = 1 PO y = a
Volvamos a nuestro ejemplo e intentemos analizar el programa, teniendo en cuenta los pedidos.
El análisis del programa utilizando JMM se basa en presentar cualquier hipótesis y confirmarla o refutarla.
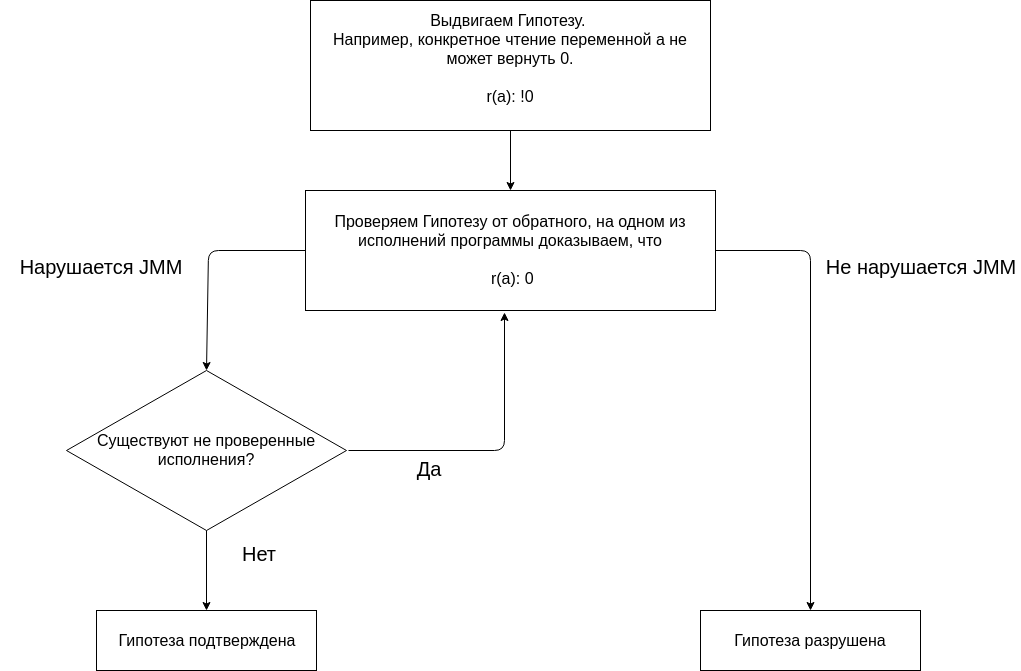
Comenzamos nuestro análisis con la hipótesis de que ni una sola ejecución del programa da el resultado (0, 0). La ausencia de un resultado (0, 0) en todas las ejecuciones es una supuesta propiedad del programa.
Probamos la hipótesis construyendo diferentes ejecuciones.
Vi la nomenclatura
aquí (a veces aparece en lugar de
… palabra
race con una flecha, Alexey mismo usa la flecha y la carrera de palabras en sus informes, pero advierte que este orden no existe en JMM y usa esta notación para mayor claridad).
Hacemos una pequeña reserva.
Dado que todas las acciones sobre variables comunes son importantes para nosotros, y en el ejemplo, las variables comunes son
a, b, x, y . Entonces, por ejemplo, la operación x = b debe considerarse como r (b) yw (x, b),
r(b) HB w(x,b) (basada en
PO ). Pero dado que la variable x no se lee en ninguna parte de los hilos (la lectura impresa al final del código no es interesante, porque después de la operación de unión en el hilo veremos el valor x), no podemos considerar la acción w (x, b).
Comprueba la primera actuación.
w(a, 1) HB r(b): 0 … w(b, 1) HB r(a): 0
En la secuencia
Q, leemos la variable a, escribimos en esta variable en la secuencia
P. No hay orden entre escribir y leer
(PO, SW, HB) .
Si la variable está escrita en un hilo y la lectura está en otro hilo y no hay una relación
HB entre operaciones, entonces dicen que la variable se lee en carrera. Y en la carrera según JMM podemos leer el último valor registrado en
HB o cualquier otro valor.
Tal actuación es posible. La ejecución
no viola JMM . Al leer la variable a, puede ver cualquier valor, ya que la lectura ocurre bajo la carrera y no hay garantía de que veremos la acción w (a, 1). Esto no significa que el programa funcione correctamente, simplemente significa que se espera ese resultado.
No tiene sentido considerar el resto de la ejecución, ya que la
hipótesis ya está destruida .
JMM dice que si el programa no tiene carreras de datos, entonces todas las ejecuciones pueden considerarse como secuenciales. Vamos a deshacernos de la carrera, para esto necesitamos simplificar las operaciones de lectura y escritura en diferentes hilos. Es importante comprender que un programa multiproceso, en contraste con uno secuencial, tiene varias ejecuciones. Y para decir que un programa tiene alguna propiedad, es necesario demostrar que el programa tiene esta propiedad no en una de las ejecuciones, sino en todas las ejecuciones.
Para demostrar que el programa no es de carreras, debe hacer esto para todas las actuaciones. Intentemos hacer
SA y marquemos la variable a con un
modificador volátil .
Las variables
volátiles tendrán el prefijo v.
Presentamos una nueva hipótesis . Si la variable a se vuelve
volátil , entonces ninguna ejecución del programa dará el resultado (0, 0).
w(va, 1) HB r(b): 0 … w(b, 1) HB r(va): 0
La ejecución
no viola JMM . Leer va sucede bajo la carrera. Cualquier raza destruye la transitividad de HB.
Presentamos otra hipótesis . Si la variable b se vuelve
volátil , ninguna ejecución del programa dará el resultado (0, 0).
w(a, 1) HB r(vb): 0 … w(vb, 1) HB r(a): 0
La ejecución no viola JMM. La lectura de ocurre bajo la carrera.
Probemos
la hipótesis de que si las variables a y b son
volátiles , ninguna ejecución del programa dará el resultado (0, 0).
Comprueba la primera actuación.
w(va, 1) SO r(vb): 0 SO w(vb, 1) SO r(va): 0
Dado que todas las acciones en el programa
SA (específicamente leer o escribir una variable
volátil ), obtenemos el orden
SO completo entre todas las acciones. Esto significa que r (va) debería ver w (va, 1). Esta
ejecución viola JMM .
Es necesario proceder a la siguiente ejecución para confirmar la hipótesis. Pero dado que habrá
SO para cualquier ejecución, puede desviarse del formalismo: es obvio que el resultado (0, 0) viola el JMM para cualquier ejecución.
Para usar el modelo de rotación, debe agregar
volátil para las variables a y b. Tal programa dará los resultados (1,1), (1,0) o (0,1).
Al final, podemos decir que los programas muy simples son bastante simples de analizar.
Pero los programas complejos con una gran cantidad de ejecuciones y datos compartidos son difíciles de analizar, ya que debe verificar todas las ejecuciones.
Otros modelos de ejecución competitiva
¿Por qué considerar otros modelos de programación competitivos?
El uso de hilos y primitivas de sincronización puede resolver todos los problemas. Todo esto es cierto, pero el problema es que examinamos un ejemplo de una docena de líneas de código, donde 4 líneas de código hacen un trabajo útil.
Y allí encontramos un montón de preguntas, hasta el punto de que sin la especificación ni siquiera podríamos calcular correctamente todos los resultados posibles. Los hilos y las primitivas de sincronización son una cosa muy difícil, cuyo uso ciertamente está justificado en algunos casos. Básicamente, estos casos están relacionados con el rendimiento.
Lo siento, me refiero mucho a Elizarov, pero ¿qué puedo hacer si una persona realmente tiene experiencia en este campo? Entonces, tiene otro
informe maravilloso
, "Millones de citas por segundo en Java puro", en el que dice que un estado inmutable es bueno, pero no copiaré mis millones de citas en cada transmisión, lo siento. Pero no todos tienen millones de citas, muchas tienen tareas más modestas. ¿Existen modelos de programación competitivos que le permitan olvidarse de JMM y aún así escribir código seguro y competitivo?
Si está realmente interesado en esta pregunta, le recomiendo el libro de Paul Butcher, "Siete modelos de competencia en siete semanas". Revelamos los secretos de los flujos ". Desafortunadamente, no fue posible encontrar suficiente información sobre el autor, pero el libro debería abrir los ojos a nuevos paradigmas. Desafortunadamente, no tengo experiencia con muchos otros modelos de competencia, así que obtuve la reseña de este libro.
Respondiendo la pregunta anterior. Según tengo entendido, existen modelos de programación competitivos que pueden al menos reducir en gran medida la necesidad de conocer los matices de JMM. Sin embargo, si hay un estado mutable y flujos, entonces no arruines ninguna abstracción sobre ellos, todavía habrá un lugar donde estos flujos deberían sincronizar el acceso al estado. Otra pregunta es que probablemente no tenga que sincronizar el acceso usted mismo, por ejemplo, un marco puede responder a esto. Pero como hemos dicho, tarde o temprano, puede ocurrir abstracción.
Puede excluir el estado mutable en absoluto. En el mundo de la programación funcional, esta es una práctica normal. Si no hay estructuras mutables, entonces probablemente no habrá problemas con la memoria compartida por definición. Hay representantes de lenguajes funcionales en la JVM, como Clojure. Clojure es un lenguaje funcional híbrido, porque todavía le permite cambiar las estructuras de datos, pero proporciona herramientas más eficientes y seguras para esto.
Los lenguajes funcionales son una gran herramienta para trabajar con código competitivo. Personalmente, no lo uso, porque mi área de actividad es el desarrollo móvil, y allí simplemente no es convencional. Aunque se pueden adoptar ciertos enfoques.
Otra forma de trabajar con datos mutables es evitar el intercambio de datos. Los actores son un modelo de programación. Los actores simplifican la programación al no permitir el acceso simultáneo a los datos. Esto se logra por el hecho de que una función que realiza trabajo en un momento puede funcionar en un solo hilo.
Sin embargo, un actor puede cambiar el estado interno. Dado que en el siguiente momento, el mismo actor puede ejecutarse en otro hilo, esto puede ser un problema. El problema se puede resolver de diferentes maneras, en lenguajes de programación como Erlang o Elixir, donde el modelo de actor es una parte integral del lenguaje, puede usar la recursión para llamar a un actor con un nuevo estado.
En Java, las recursiones pueden ser demasiado caras. Sin embargo, en Java existen marcos para un trabajo conveniente con este modelo, probablemente el más popular es Akka. Los desarrolladores de Akka se han ocupado de todo, puede ir a la sección de documentación de
Akka y el Modelo de memoria de Java y leer sobre dos casos en los que el acceso a un estado compartido puede ocurrir desde diferentes hilos. Pero lo más importante, la documentación dice qué eventos se relacionan con "sucedió antes". Es decir Esto significa que podemos cambiar el estado del actor tanto como queramos, pero cuando recibamos el siguiente mensaje y posiblemente lo procesemos en otro hilo, tenemos la garantía de ver todos los cambios realizados en otro hilo.
¿Por qué es tan popular el modelo de subprocesamiento?
Examinamos dos modelos de programación competitiva, de hecho, hay aún más de ellos que hacen que la programación competitiva sea más fácil y segura.
Pero, ¿por qué los hilos y las cerraduras siguen siendo tan populares?
Creo que la razón es la simplicidad del enfoque, por supuesto, por un lado, es fácil cometer muchos errores no obvios con las transmisiones, dispararse en el pie, etc. Pero, por otro lado
, no hay nada complicado en los flujos, especialmente si no piensa en las consecuencias .
En un momento dado, el núcleo puede ejecutar una instrucción (de hecho, hay paralelismo en el nivel de instrucción, pero ahora no importa), pero gracias a la multitarea, incluso en máquinas de un solo núcleo, se pueden ejecutar varios programas simultáneamente (por supuesto, pseudo simultáneamente).
Para que la multitarea funcione, necesita competencia. Como ya hemos descubierto, la competencia es imposible sin varios flujos de gestión.
¿Cuántos hilos cree usted que un programa que se ejecuta en un procesador de teléfono móvil de cuatro núcleos debe ser lo más rápido y receptivo posible?
Puede haber varias docenas. Ahora la pregunta es, ¿por qué necesitamos tantos subprocesos para un programa que se ejecuta en hardware que le permite ejecutar solo 2-4 subprocesos a la vez?
Para intentar responder a esta pregunta, suponga que solo nuestro programa se ejecuta en el dispositivo y nada más. ¿Cómo gestionaríamos los recursos que nos proporcionan?
Puede asignar un núcleo para la interfaz de usuario, el resto del núcleo para cualquier otra tarea.
Si uno de los hilos está bloqueado, por ejemplo, el hilo puede acceder al controlador de memoria y esperar una respuesta, entonces obtendremos un núcleo bloqueado.¿Qué tecnologías hay para resolver el problema?Hay hilos en Java, podemos crear muchos hilos, y luego otros hilos podrán realizar operaciones mientras algunos hilos están bloqueados. Con una herramienta como hilos, podemos simplificar nuestras vidas.El enfoque con subprocesos no es gratuito, la creación de subprocesos generalmente lleva tiempo (se decide por grupos de subprocesos), se les asigna memoria, el cambio entre subprocesos es una operación costosa. Pero es relativamente fácil de programar con ellos, por lo que esta es una tecnología masiva que se usa ampliamente en lenguajes generales, como Java.Java generalmente ama las transmisiones, no es necesario crear para cada acción una transmisión, hay cosas de nivel superior, como Executors, que le permiten trabajar con grupos y escribir código más escalable y flexible. Las transmisiones son realmente convenientes, puede realizar una solicitud de bloqueo a la red y escribir el procesamiento de resultados en la siguiente línea. Incluso si esperamos unos segundos para obtener el resultado, aún podemos realizar otras tareas, ya que el sistema operativo se encargará de la distribución del tiempo del procesador entre los subprocesos.Las transmisiones son populares no solo en el desarrollo de back-end, en el desarrollo móvil se considera bastante normal crear docenas de transmisiones para que pueda bloquear una transmisión durante un par de segundos, esperando que los datos se descarguen a través de la red o los datos del socket.Los lenguajes como Erlang o Clojure siguen siendo nicho y, por lo tanto, los modelos de programación competitivos que utilizan no son tan populares. Sin embargo, los pronósticos para ellos son los más optimistas.Conclusiones
Si está desarrollando en la plataforma JVM, debe aceptar las reglas del juego indicadas por la plataforma. La única forma de escribir código multiproceso normal. Es muy deseable comprender el contexto de todo lo que sucede, por lo que será más fácil aceptar las reglas del juego. Es incluso mejor mirar a su alrededor y conocer otros paradigmas, aunque no puede llegar a ningún lado desde el submarino, pero puede descubrir nuevos enfoques y herramientas.Materiales adicionales
Traté de colocar en el texto del artículo enlaces a fuentes de las cuales obtuve información.En general, el material JMM es fácil de encontrar en Internet. Aquí publicaré enlaces a algunos materiales adicionales que están asociados con JMM y que no pueden llamar mi atención de inmediato.Lectura- Blog de Alexey Shipilev : sé lo que es obvio, pero es un pecado sin mencionar
- El blog de Cheremin Ruslan : no ha escrito activamente últimamente, debe buscar sus entradas antiguas en el blog, créanme que vale la pena, hay una fuente
- Habr Gleb Smirnov : hay excelentes artículos sobre subprocesos múltiples y el modelo de memoria
- El blog de Roman Elizarov está abandonado, pero las excavaciones arqueológicas deben llevarse a cabo. En general, Roman hizo mucho para educar a la gente en la teoría de la programación multiproceso, búsquela en los medios.
Problemas de podcasts que me parecieron particularmente interesantes. No se trata de JMM, se trata del infierno, que está sucediendo en la glándula. Pero después de escucharlos, quiero besar a los creadores de JMM, que nos han protegido de todo esto.VideoAdemás de los discursos de las personas mencionadas anteriormente, preste atención al video académico.