Este artículo es una traducción autorizada de la publicación original . La traducción se realizó con la amable ayuda de los chicos de PVS-Studio. Gracias chicosLo que me animó a escribir este artículo es una cantidad significativa de materiales sobre análisis estático, que recientemente ha estado surgiendo cada vez más. En primer lugar, este es un
blog de PVS-Studio , que se promueve activamente en la publicación de revisiones de errores de Habr, encontradas por su herramienta en proyectos de código abierto. PVS-Studio ha implementado recientemente el
soporte de Java y, por supuesto, los desarrolladores de IntelliJ IDEA, cuyo analizador incorporado es probablemente el más avanzado para Java en la actualidad,
no pudieron mantenerse alejados .
Al leer estas reseñas, tengo la sensación de que estamos hablando de un elixir mágico: haga clic en el botón, y aquí está: la lista de defectos frente a sus ojos. Parece que a medida que los analizadores avanzan, se encontrarán más y más errores, y los productos, escaneados por estos robots, mejorarán cada vez más sin ningún esfuerzo de nuestra parte.
Bueno, pero no hay elixires mágicos. Me gustaría hablar sobre lo que generalmente no se habla en publicaciones como "aquí hay cosas que nuestro robot puede encontrar": lo que los analizadores no pueden hacer, cuál es su verdadera parte y lugar en el proceso de entrega de software y cómo implementar El análisis correctamente.
 Ratchet (fuente: Wikipedia ).
Ratchet (fuente: Wikipedia ).Lo que los analizadores estáticos nunca podrán hacer
¿Cuál es el análisis del código fuente desde el punto de vista práctico? Tomamos los archivos de origen y obtenemos información sobre la calidad del sistema en poco tiempo (mucho más corto que una ejecución de pruebas). La limitación principal y matemáticamente insuperable es que de esta manera solo podemos responder un subconjunto muy limitado de preguntas sobre el sistema analizado.
El ejemplo más famoso de una tarea, que no se puede resolver mediante análisis estático es un
problema detenido : este es un teorema, que demuestra que uno no puede elaborar un algoritmo general, que definiría si un programa con un código fuente dado se enlazó para siempre o se completó para El tiempo final. La extensión de este teorema es un
teorema de Rice , afirmando que para cualquier propiedad no trivial de funciones computables, la cuestión de determinar si un programa determinado calcula una función con esta propiedad es una tarea algorítmicamente insoluble. Por ejemplo, no puede escribir un analizador, que determina, basándose en el código fuente, si el programa analizado es una implementación de un algoritmo específico, por ejemplo, uno que calcula la cuadratura de un número entero.
Por lo tanto, la funcionalidad de los analizadores estáticos tiene limitaciones insuperables. El analizador estático nunca podrá detectar todos los casos de, por ejemplo, error de "excepción de puntero nulo" en idiomas sin la
seguridad nula . O detecte todas las apariciones de "atributo no encontrado" en lenguajes escritos dinámicamente. Todo lo que puede hacer el analizador estático más perfecto es detectar casos particulares. El número de ellos entre todos los posibles problemas con su código fuente, sin exagerar, es una gota en el océano.
El análisis estático no es una búsqueda de errores
Aquí hay una conclusión que se deduce de lo anterior: el análisis estático no es la forma de disminuir el número de defectos en un programa. Me aventuraría a afirmar lo siguiente: al aplicarse por primera vez a su proyecto, encontrará lugares "divertidos" en el código, pero lo más probable es que no encuentre ningún defecto que afecte la calidad de su programa.
Los ejemplos de defectos encontrados automáticamente por los analizadores son impresionantes, pero no debemos olvidar que estos ejemplos se encontraron al escanear un gran conjunto de bases de código contra el conjunto de reglas relativamente simples. Del mismo modo, los piratas informáticos, que tienen la oportunidad de probar varias contraseñas simples en una gran cantidad de cuentas, eventualmente encuentran las cuentas con una contraseña simple.
¿Significa esto que no es necesario aplicar el análisis estático? Por supuesto que no! Debe aplicarse por el mismo motivo por el que es posible que desee verificar cada contraseña nueva en la lista de detención de contraseñas no seguras.
El análisis estático es más que la búsqueda de errores
De hecho, las tareas que el análisis puede resolver en la práctica son mucho más amplias. Porque, en términos generales, el análisis estático representa cualquier verificación del código fuente, realizada antes de ejecutarlo. Aquí hay algunas cosas que puede hacer:
- Una comprobación del estilo de codificación en el sentido más amplio de esta palabra. Incluye tanto una verificación del formato como una búsqueda del uso de paréntesis vacíos / innecesarios, el establecimiento de valores de umbral para métricas como una serie de líneas / complejidad ciclomática de un método, etc., todo lo que complica la legibilidad y la facilidad de mantenimiento del código. En Java, Checkstyle representa una herramienta con dicha funcionalidad, en Python -
flake8 . Dichos programas generalmente se denominan "linters". - No solo se puede analizar el código ejecutable. Los recursos como archivos JSON, YAML, XML y
.properties pueden (y deben) verificarse automáticamente para verificar su validez. La razón de esto es que es mejor descubrir el hecho de que, por ejemplo, la estructura JSON se rompe debido a las comillas no emparejadas en la etapa inicial de la verificación automática de una solicitud de extracción que durante la ejecución de las pruebas o en tiempo de ejecución, no eso? Hay algunas herramientas relevantes, por ejemplo, YAMLlint , JSONLint y xmllint . - La compilación (o análisis de lenguajes de programación dinámica) también es un tipo de análisis estático. Por lo general, los compiladores pueden emitir advertencias que indican problemas con la calidad del código fuente, y no deben ignorarse.
- A veces, la compilación se aplica no solo al código ejecutable. Por ejemplo, si tiene documentación en el formato AsciiDoctor , en el proceso de compilarlo en HTML / PDF, el AsciiDoctor ( complemento Maven ) puede emitir advertencias, por ejemplo, en enlaces internos rotos. Esta es una razón importante para no aceptar una solicitud de extracción con cambios en la documentación.
- La corrección ortográfica también es un tipo de análisis estático. La utilidad aspell puede verificar la ortografía no solo en la documentación, sino también en el código fuente de los programas (comentarios y literales) en varios lenguajes de programación, incluidos C / C ++, Java y Python. ¡El error de ortografía en la interfaz de usuario o la documentación también es un defecto!
- Las pruebas de configuración en realidad representan una forma de análisis estático, ya que no ejecutan el código fuente durante el proceso de ejecución, a pesar de que las pruebas de configuración se ejecutan como pruebas unitarias de
pytest .
Como podemos ver, la búsqueda de errores tiene el papel menos significativo en esta lista y todo lo demás está disponible cuando se utilizan herramientas gratuitas de código abierto.
¿Cuál de estos tipos de análisis estático debe usarse en su proyecto? Claro, cuanto más mejor! Lo importante aquí es una implementación adecuada, que se discutirá más a fondo.
Una tubería de entrega como un filtro multietapa y el análisis estático como su primera etapa
Una tubería con un flujo de cambios (comenzando desde los cambios del código fuente hasta la entrega en producción) es una metáfora clásica de integración continua. La secuencia estándar de etapas de esta tubería se ve de la siguiente manera:
- análisis estático
- compilación
- pruebas unitarias
- pruebas de integración
- Pruebas de IU
- verificación manual
Los cambios rechazados en la N-ésima etapa de la tubería no se pasan en la etapa N + 1.
¿Por qué así y no de otra manera? En la parte de la tubería, que se ocupa de las pruebas, los evaluadores reconocen la conocida pirámide de pruebas:
 Prueba de pirámide. Fuente: el artículo de Martin Fowler.
Prueba de pirámide. Fuente: el artículo de Martin Fowler.En la parte inferior de esta pirámide hay pruebas que son más fáciles de escribir, que se ejecutan más rápido y no tienden a producir falsos positivos. Por lo tanto, debería haber más, deberían cubrir la mayor parte del código y deberían ejecutarse primero. En la parte superior de la pirámide, la situación es bastante opuesta, por lo que el número de pruebas de integración y UI debe reducirse al mínimo necesario. Las personas en esta cadena son el recurso más costoso, lento y poco confiable, por lo que se encuentran al final y hacen el trabajo solo si los pasos anteriores no han detectado ningún defecto. En las partes no relacionadas con las pruebas, la tubería se construye con los mismos principios.
Me gustaría sugerir la analogía en forma de un sistema de filtración de agua en varias etapas. Se suministra agua sucia (cambios con defectos) en la entrada, y como salida necesitamos agua limpia, que no contendrá todas las contaminaciones no deseadas.
 Filtro multietapa. Fuente: Wikimedia Commons
Filtro multietapa. Fuente: Wikimedia CommonsComo ya sabrá, los filtros de purificación están diseñados para que cada etapa posterior pueda eliminar partículas contaminantes de menor tamaño. Las etapas de entrada de la purificación aproximada tienen un mayor rendimiento y un menor costo. En nuestra analogía, significa que las puertas de calidad de entrada tienen un mayor rendimiento, requieren menos esfuerzo de lanzamiento y tienen menos costos operativos. El papel del análisis estático, que (como ahora entendemos) es capaz de eliminar solo los defectos más graves, es el papel del filtro de sumidero como la primera etapa de los purificadores de etapas múltiples.
El análisis estático no mejora la calidad del producto final por sí solo, al igual que el "sumidero" no hace que el agua sea potable. Sin embargo, en conjunción con otros elementos de la tubería, su importancia es obvia. Aunque en un filtro de varias etapas, las etapas de salida pueden eliminar todo lo que pueden hacer las entradas: somos conscientes de las consecuencias que se producirán al intentar pasar solo con etapas de purificación fina, sin etapas de entrada.
El propósito del "sumidero" es descargar las etapas posteriores de la captura de defectos muy ásperos. Por ejemplo, una persona que realiza la revisión del código no debe distraerse con código incorrectamente formateado y violación de los estándares del código (como paréntesis redundantes o ramificaciones demasiado anidadas). Las pruebas unitarias deben detectar errores como el NPE, pero si antes el analizador indica que inevitablemente aparecerá un error, esto acelerará significativamente su reparación.
Supongo que ahora está claro por qué el análisis estático no mejora la calidad del producto cuando se aplica ocasionalmente, y debe aplicarse continuamente para filtrar cambios con defectos graves. La pregunta de si la aplicación de un analizador estático mejora la calidad de su producto es más o menos equivalente a la pregunta "si tomamos agua de estanques sucios, ¿mejorará su calidad de bebida cuando la pasemos por un colador?"
Introducción en un proyecto heredado
Una cuestión práctica importante: ¿cómo implementar el análisis estático en el proceso de integración continua, como una "puerta de calidad"? En el caso de las pruebas automatizadas, todo está claro: hay un conjunto de pruebas, una falla de cualquiera de ellas es una razón suficiente para creer que una compilación no ha pasado una puerta de calidad. Un intento de establecer la puerta de la misma manera por los resultados del análisis estático falla: hay demasiadas advertencias de análisis en el código heredado, no desea ignorarlas a todas, por otro lado, es imposible detener la entrega del producto solo porque Hay advertencias del analizador en él.
Para cualquier proyecto, el analizador emite una gran cantidad de advertencias que se aplican por primera vez. La mayoría de las advertencias no tienen nada que ver con el correcto funcionamiento del producto. Será imposible arreglarlos todos y muchos de ellos no tienen que arreglarse en absoluto. Al final, sabemos que nuestro producto realmente funciona incluso antes de la introducción del análisis estático.
Como resultado, muchos desarrolladores se limitan a sí mismos mediante el uso ocasional de análisis estático o usándolo solo en el modo informativo que implica obtener un informe del analizador al construir un proyecto. Esto es equivalente a la ausencia de cualquier análisis, porque si ya tenemos muchas advertencias, la aparición de otro (por serio que sea) no se nota al cambiar el código.
Estas son las formas conocidas de introducción de puertas de calidad:
- Establecer el límite del número total de advertencias o el número de advertencias, dividido por el número de líneas de código. Funciona mal, ya que tal puerta permite cambios con nuevos defectos hasta que se excede su límite.
- Marcado de todas las advertencias antiguas en el código como ignorado en un momento determinado y falla de compilación cuando aparecen nuevas advertencias. PVS-Studio y algunas otras herramientas pueden proporcionar dicha funcionalidad, por ejemplo, Codacy. No he pasado a trabajar con PVS-Studio. En cuanto a mi experiencia con Codacy, su principal problema es que la distinción de un error antiguo y uno nuevo es un algoritmo complicado y no siempre funciona, especialmente si los archivos cambian significativamente o cambian de nombre. Que yo sepa, Codacy podría pasar por alto nuevas advertencias en una solicitud de extracción y al mismo tiempo impedir una solicitud de extracción debido a advertencias, no relacionadas con cambios en el código de este RP.
- En mi opinión, la solución más efectiva es el método de "trinquete" descrito en el libro " Entrega continua ". La idea básica es que el número de advertencias de análisis estático es una propiedad de cada versión y solo se permiten tales cambios, que no aumentan el número total de advertencias.
Trinquete
Funciona de la siguiente manera:
- En la fase inicial, se agrega una entrada sobre una serie de advertencias encontradas por los analizadores de código en los metadatos de la versión. Por lo tanto, al compilar la rama principal, no solo la "versión 7.0.2" está escrita en su administrador de repositorios, sino la "versión 7.0.2, que contiene 100500 advertencias de Checkstyle". Si está utilizando un administrador de repositorios avanzado (como Artifactory), es fácil mantener esos metadatos sobre su lanzamiento.
- Al construir, cada solicitud de extracción compara el número de advertencias resultantes con su número en una versión actual. Si un RP conduce a un crecimiento de este número, el código no pasa la puerta de calidad en el análisis estático. Si el número de advertencias se reduce o no cambia, entonces pasa.
- Durante la próxima versión, el número recalculado se volverá a escribir en los metadatos.
Por lo tanto, lenta pero segura, el número de advertencias convergerá a cero. Por supuesto, el sistema puede ser engañado introduciendo una nueva advertencia y corrigiendo la de otra persona. Esto es normal, porque a la larga da el resultado: las advertencias se arreglan, generalmente no una por una, sino por grupos de cierto tipo, y todas las advertencias fáciles de resolver se resuelven con bastante rapidez.
Este gráfico muestra el número total de advertencias de Checkstyle durante seis meses de tal "trinquete" en
uno de nuestros proyectos OpenSource . ¡El número de advertencias se ha reducido significativamente, y sucedió naturalmente, en paralelo con el desarrollo del producto!
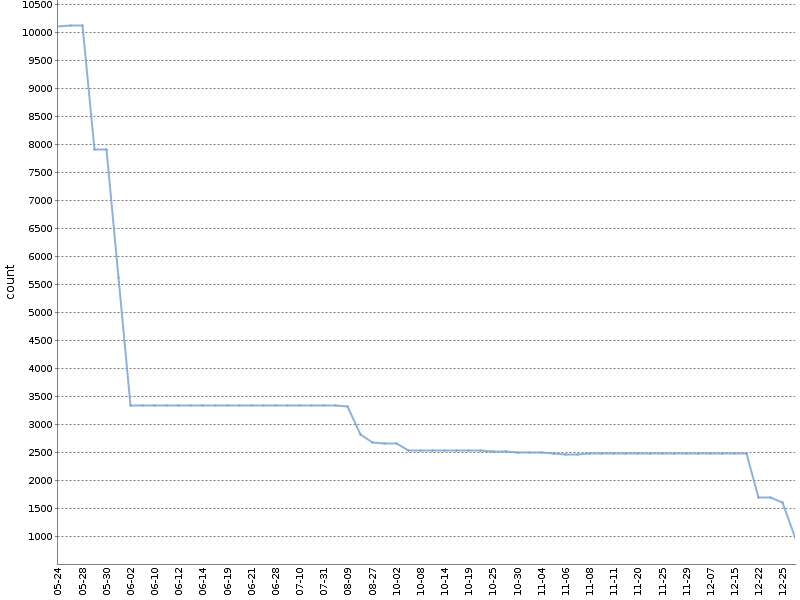
Aplico la versión modificada de este método. Cuento las advertencias por separado para diferentes módulos de proyecto y herramientas de análisis. El archivo YAML con metadatos sobre la compilación, que se forma al hacerlo, tiene el siguiente aspecto:
celesta-sql: checkstyle: 434 spotbugs: 45 celesta-core: checkstyle: 206 spotbugs: 13 celesta-maven-plugin: checkstyle: 19 spotbugs: 0 celesta-unit: checkstyle: 0 spotbugs: 0
En cualquier sistema CI avanzado se puede implementar un "trinquete" para cualquier herramienta de análisis estático, sin depender de complementos y herramientas de terceros. Cada uno de los analizadores emite su informe en un texto simple o formato XML, que será fácilmente analizado. Lo único que se debe hacer después es escribir la lógica necesaria en un script de CI. Puede echar un vistazo y ver
aquí o
aquí cómo se implementa en nuestros proyectos fuente basados en Jenkins y Artifactory. Ambos ejemplos dependen de la biblioteca
ratchetlib : el método
countWarnings() de la manera habitual cuenta las etiquetas xml en los archivos generados por Checkstyle y Spotbugs, y
compareWarningMaps() implementa ese mismo trinquete, arrojando un error en el caso, si el número de advertencias en cualquiera de Las categorías están aumentando.
Una forma interesante de implementación de "trinquete" es posible para analizar la ortografía de comentarios, textos literales y documentación usando aspell. Como sabrá, al revisar la ortografía, no todas las palabras desconocidas para el diccionario estándar son incorrectas, se pueden agregar al diccionario personalizado. Si hace que un diccionario personalizado forme parte del proyecto de código fuente, entonces la puerta de calidad para la ortografía se puede formular de la siguiente manera: ejecutar aspell con un diccionario estándar y personalizado
no debería encontrar ningún error ortográfico.
La importancia de arreglar la versión del analizador
En conclusión, es necesario tener en cuenta lo siguiente: cualquiera que sea la forma en que elija introducir el análisis en su canal de entrega, la versión del analizador debe ser fija. Si deja que el analizador se actualice espontáneamente, al generar otra solicitud de extracción pueden surgir nuevos defectos, que no se relacionan con el código modificado, sino con el hecho de que el nuevo analizador simplemente puede detectar más defectos. Esto interrumpirá su proceso de verificación de solicitud de extracción. La actualización del analizador debe ser una acción consciente. De todos modos, la fijación de la versión rígida de cada componente de compilación es un requisito general y un tema para otro tema.
Conclusiones
- El análisis estático no encontrará errores y no mejorará la calidad de su producto como resultado de una sola ejecución. Solo su funcionamiento continuo en el proceso de entrega producirá un efecto positivo.
- La búsqueda de errores no es el objetivo principal del análisis en absoluto. La gran mayoría de las funciones útiles está disponible en herramientas de código abierto.
- Introduzca puertas de calidad por los resultados del análisis estático en la primera etapa de la tubería de entrega, utilizando el "trinquete" para el código heredado.
Referencias
- Entrega continua
- Alexey Kudryavtsev: Análisis del programa: ¿eres un buen desarrollador? ¡Informe sobre diferentes métodos de análisis de código, no solo estático!
Extractos de la discusión del artículo original.
Evgeniy RyzhkovIvan, gracias por el artículo y por ayudarnos a hacer nuestro trabajo, que es popularizar la tecnología de análisis de código estático. Tiene toda la razón en que los artículos del blog PVS-Studio, en caso de mentes inmaduras, pueden afectarlos y llevar a conclusiones tales como "Comprobaré el código solo una vez, arreglaré los errores y eso funcionará". Este es mi dolor personal, que no sé cómo superar desde hace varios años. El hecho es que los artículos sobre verificaciones de proyectos:
- Causar efecto wow en las personas. A la gente le gusta leer cómo los desarrolladores de compañías como Google, Epic Games, Microsoft y otras compañías a veces fallan. A la gente le gusta pensar que cualquiera puede estar equivocado, incluso los líderes de la industria cometen errores. A la gente le gusta leer tales artículos.
- Además, los autores pueden escribir artículos sobre el flujo, sin tener que pensar mucho. Por supuesto, no quiero ofender a nuestros muchachos que escriben estos artículos. Pero presentar un nuevo artículo cada vez es mucho más difícil que escribir un artículo sobre la verificación de un proyecto (una docena de errores, un par de bromas, mezclarlo con imágenes de unicornios).
Escribiste un muy buen artículo. También tengo un par de artículos sobre este tema. También lo tienen otros colegas. Además, visito varias empresas con un informe sobre el tema "Filosofía del análisis de código estático", en el que estoy hablando sobre el proceso en sí, pero no sobre errores específicos.
Pero no es posible escribir 10 artículos sobre el proceso. Bueno, para promocionar nuestro producto necesitamos escribir mucho regularmente. Me gustaría comentar algunos puntos más del artículo con un comentario por separado para que la discusión sea más conveniente.
Este breve
artículo trata sobre "Filosofía del análisis de código estático", que es mi tema cuando visito diferentes empresas.
Ivan PonomarevEvgeniy, muchas gracias por la revisión informativa del artículo. Sí, ¡tienes mi preocupación en la publicación sobre el impacto en las "mentes inmaduras" absolutamente correctamente!
Aquí no hay nadie a quien culpar, ya que los autores de los artículos / informes sobre
analizadores no pretenden hacer artículos / informes sobre el
análisis . Pero después de un par de publicaciones recientes de
Andrey2008 y
lany , decidí que ya no podía permanecer en silencio.
Evgeniy RyzhkovIvan, como escribió anteriormente, comentaré tres puntos del artículo. Significa que estoy de acuerdo con los que no comento.
1.
La secuencia estándar de etapas de esta tubería se ve de la siguiente manera ...No estoy de acuerdo en que el primer paso es el análisis estático, y solo el segundo es la compilación. Creo que, en promedio, la verificación de compilación es más rápida y lógica que una ejecución inmediata de análisis estático "más pesado". Podemos discutir si piensas lo contrario.
2.
No he pasado a trabajar con PVS-Studio. En cuanto a mi experiencia con Codacy, su principal problema es que la distinción de un error antiguo y uno nuevo es un algoritmo complicado y no siempre funciona, especialmente si los archivos cambian significativamente o cambian de nombre.En PVS-Studio se hace increíblemente útil. Esta es una de las características principales del producto, que, desafortunadamente, es difícil de describir en los artículos, por eso la gente no está muy familiarizada con él. Recopilamos información sobre los errores existentes en una base. Y no solo "el nombre del archivo y la línea", sino también información adicional (marca de hash de tres líneas: actual, anterior, siguiente), de modo que en caso de cambiar el fragmento de código, aún podríamos encontrarlo. Por lo tanto, cuando tenemos modificaciones menores, entendemos que es un error antiguo. Y el analizador no se queja de eso. Ahora alguien puede decir: "Bueno, ¿qué pasa si el código ha cambiado mucho, entonces esto no funcionaría y usted se queja como si fuera el nuevo escrito?" Si Nos quejamos Pero en realidad este es un código nuevo. Si el código ha cambiado mucho, ahora es un código nuevo, en lugar del antiguo.
Gracias a esta característica, participamos personalmente en la implementación del proyecto con 10 millones de líneas de código C ++, que cada día es "tocado" por un grupo de desarrolladores. Todo salió sin problemas. Por lo tanto, recomendamos utilizar esta función de PVS-Studio a cualquier persona que introduzca un análisis estático en su proceso. La opción de fijar el número de advertencias según un lanzamiento parece ser menos agradable para mí.
3.
Cualquiera que sea la forma en que elija presentar su análisis de la tubería de entrega, la versión del analizador debe ser fijaNo puedo estar de acuerdo con esto. Un adversario definitivo de tal enfoque. Recomiendo actualizar el analizador en modo automático. A medida que agregamos nuevos diagnósticos y mejoramos los antiguos. Por qué En primer lugar, recibirá advertencias de nuevos errores reales. En segundo lugar, algunos viejos falsos positivos podrían desaparecer si los superamos.
No actualizar el analizador es lo mismo que no actualizar las bases de datos antivirus ("¿y si comienzan a notificar sobre virus")? No discutiremos aquí la verdadera utilidad del software antivirus en su conjunto.
Si después de actualizar la versión del analizador tiene muchas advertencias nuevas, suprímalas, como escribí anteriormente, a través de esa función. Pero no para actualizar la versión ... Como regla general, tales clientes (seguro, hay algunos) no actualizan la versión del analizador durante años. No hay tiempo para eso. PAGAN por la renovación de la licencia, pero no usan las nuevas versiones. Por qué Porque una vez decidieron fijar una versión. El producto hoy y hace tres años es de día y de noche. Resulta como "compraré el boleto, pero no vendré".
Ivan Ponomarev1. Aquí tienes razón. ¡Estoy listo para estar de acuerdo con un compilador / analizador al principio y esto incluso debería cambiarse en el artículo! Por ejemplo, los notorios
spotbugs no pueden actuar de una manera diferente, ya que analiza el
spotbugs compilado. Hay casos exóticos, por ejemplo, en la tubería para libros de jugadas Ansible, es mejor establecer el análisis estático antes de analizar porque es más claro allí. Pero esto es lo exótico en sí mismo)
2.
La opción de fijar el número de advertencias según un lanzamiento parece ser menos agradable para mí ... - bueno, sí, es menos agradable, menos técnico pero muy práctico :-) Lo principal es que es un método general, mediante el cual puedo implementar efectivamente el análisis estático en cualquier lugar, incluso en el proyecto más aterrador, tener cualquier base de código y cualquier analizador (no necesariamente el suyo), utilizando Groovy o scripts de bash en CI. Por cierto, ahora estamos contando las advertencias por separado para diferentes módulos y herramientas de proyecto, pero si las dividimos de una manera más granuladora (para archivos), estará mucho más cerca del método de comparación de las nuevas / viejas. Pero nos sentimos así y me gustó ese trinquete porque estimula a los desarrolladores a monitorear el número total de advertencias y disminuir lentamente este número. Si tuviéramos el método de los antiguos / nuevos, ¿motivaría a los desarrolladores a monitorear la curva del número de advertencias? - Probablemente, sí, puede ser, no.
En cuanto al punto 3, aquí hay un ejemplo real de mi experiencia. Mira
este compromiso . ¿De donde vino? Establecemos linters en el script TravisCI. Trabajaron allí como puertas de calidad. Pero de repente, cuando una nueva versión de Ansible-lint que estaba encontrando más advertencias, algunas compilaciones de solicitudes de extracción comenzaron a fallar debido a advertencias en el código, que no habían cambiado. Al final, el proceso se interrumpió y las solicitudes urgentes de extracción se fusionaron sin pasar por puertas de calidad.
Nadie dice que no es necesario actualizar los analizadores. Por supuesto que lo es! Como todos los demás componentes de compilación. Pero debe ser un proceso consciente, reflejado en el código fuente. Y cada vez que las acciones dependan de las circunstancias (ya sea que arreglemos las advertencias detectadas nuevamente o simplemente reiniciemos el "trinquete")
Evgeniy RyzhkovCuando me preguntan: "¿Existe la posibilidad de verificar cada confirmación en PVS-Studio?", Respondo que sí. Y luego agregue: "¡Solo por el amor de Dios, no falle la construcción si PVS-Studio encuentra algo!" Porque de lo contrario, tarde o temprano, PVS-Studio será percibido como algo disruptivo. Y hay situaciones en las que ES NECESARIO comprometerse rápidamente, en lugar de luchar con las herramientas, que no dejan pasar el compromiso.
Mi opinión de que es malo fallar la compilación en este caso. Es bueno enviar mensajes a los autores del código del problema.
Ivan PonomarevMi opinión es que no existe tal cosa como "tenemos que comprometernos rápidamente". Todo esto es solo un proceso pobre. Un buen proceso genera velocidad no porque rompamos un proceso / puertas de calidad, cuando necesitamos "hacerlo rápidamente".
Esto no contradice el hecho de que podemos hacerlo sin fallar en la construcción de algunas clases de resultados de análisis estático. Simplemente significa que la puerta está configurada de la manera en que se ignoran ciertos tipos de hallazgos y para otros hallazgos tenemos tolerancia cero.
Mi commitstrip favorito sobre el tema "rápidamente".Evgeniy RyzhkovSoy un adversario definitivo del enfoque para usar la versión antigua del analizador. ¿Qué pasa si un usuario encuentra un error en esa versión? Escribe a un desarrollador de herramientas y un desarrollador de herramientas incluso lo arreglará. Pero en la nueva versión. Nadie admitirá la versión anterior para algunos clientes. Si no estamos hablando de contratos por valor de millones de dólares.
Ivan PonomarevEvgeniy, no estamos hablando de esto en absoluto. Nadie dice que debemos mantenerlos viejos. Se trata de arreglar versiones de dependencias de componentes de compilación para su actualización controlada: es una disciplina común, se aplica a todo, incluidas las bibliotecas y las herramientas.
Evgeniy RyzhkovEntiendo cómo "debería hacerse en teoría". Pero solo veo dos elecciones hechas por los clientes. O se adhieren al nuevo o al viejo. Así que casi NO tenemos tales situaciones cuando "tenemos disciplina y nos quedamos atrás de la versión actual en dos lanzamientos". No es importante para mí decir en este momento si es bueno o malo. Solo digo lo que veo.
Ivan PonomarevLo tengo De todos modos, todo depende en gran medida de las herramientas / procesos que tengan sus clientes y cómo los usen. Por ejemplo, no sé nada sobre cómo funciona todo en el mundo C ++.