Hace unos meses, nuestros colegas de Google
celebraron un concurso en Kaggle para crear un clasificador de las imágenes recibidas en el aclamado
juego "Quick, Draw!". El equipo, en el que participó el desarrollador de Yandex, Roman Vlasov, ocupó el cuarto lugar en la competencia. En la sesión de entrenamiento de máquina de enero, Roman compartió las ideas de su equipo, la implementación final del clasificador y las prácticas interesantes de los rivales.
- Hola a todos! Mi nombre es Roma Vlasov, hoy te hablaré sobre Quick, Draw! Doodle Reconocimiento Challenge.

Había cinco personas en nuestro equipo. Me uní a ella justo en frente de la fecha límite de fusión. Tuvimos mala suerte, nos sacudimos un poco, pero estábamos a la sombra del dinero, y ellos estaban en la posición de oro. Y tomamos un honorable cuarto lugar.
(Durante la competencia, los equipos se observaron en la calificación, que se formó de acuerdo con los resultados mostrados en una parte del conjunto de datos propuesto. La calificación final, a su vez, se formó en la otra parte del conjunto de datos. Esto se hace para que los participantes de la competencia no ajusten sus algoritmos a datos específicos. Por lo tanto, en las finales, cuando se cambia entre clasificaciones, las posiciones "tiemblan" un poco (del inglés shake up - shuffle): en otros datos y el resultado puede ser diferente. El equipo de Roman fue el primero entre los tres primeros. AU troika - es el dinero, la zona ranking de dinero, ya que sólo los tres primeros lugares se basó premio Después de que el equipo de "sacudida apa 'ya estaba en el cuarto lugar de la misma manera que el otro equipo perdió la victoria, la posición de oro -... Ed) ..
La competencia también fue significativa porque Yevgeny Babakhnin recibió grandes maestros para él, Ivan Sosin - maestros, Roman Solovyov siguió siendo un gran maestro, Alex Parinov recibió un maestro, me convertí en un experto y ahora ya soy un maestro.
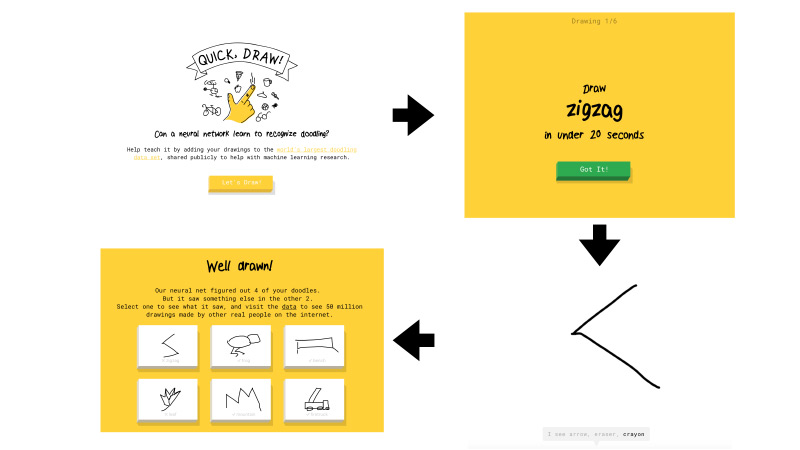
¿Qué es esto Quick, Draw? Este es un servicio de Google. Google tenía como objetivo popularizar la IA y con este servicio quería mostrar cómo funcionan las redes neuronales. Vaya allí, haga clic en Dibujemos y aparecerá una nueva página donde se le indicará: dibuje un zigzag, tiene 20 segundos para hacerlo. Intenta dibujar un zigzag en 20 segundos, como aquí, por ejemplo. Si todo te funciona, la red dice que es un zigzag y sigues adelante. Solo hay seis de esas fotos.
Si la red de Google no pudo reconocer lo que dibujó, se colocó una cruz en la tarea. Más adelante te diré qué significará en el futuro si la red reconoce o no el dibujo.
Este servicio reunió un número bastante grande de usuarios, y se registraron todas las imágenes que los usuarios dibujaron.

Fue posible recolectar casi 50 millones de imágenes. A partir de esto, se formaron el tren y la fecha de prueba para nuestra competencia. Por cierto, la cantidad de datos en la prueba y el número de clases no están en vano en negrita. Hablaré de ellos un poco más tarde.
El formato de los datos fue el siguiente. Estas no son solo imágenes RGB, sino, más o menos, el registro de todo lo que hizo el usuario. Word es nuestro objetivo, el código de país es de donde proviene el doodle, la marca de tiempo es el tiempo. La etiqueta reconocida solo muestra si la red de Google reconoció la imagen o no. Y dibujar es una secuencia, una aproximación de la curva que el usuario dibuja con puntos. Y horarios. Este es el momento desde el comienzo del dibujo.
Los datos se presentaron en dos formatos. Este es el primer formato, y el segundo está simplificado. A partir de ahí cortaron los tiempos y aproximaron este conjunto de puntos con un conjunto de puntos más pequeño. Para hacer esto, utilizaron
el algoritmo Douglas-Pecker . Tiene un gran conjunto de puntos que simplemente se aproxima a una línea recta, y en realidad puede aproximar esta línea con solo dos puntos. Esta es la idea del algoritmo.
Los datos se distribuyeron de la siguiente manera. Todo es uniforme, pero hay algunos valores atípicos. Cuando resolvimos el problema, no lo miramos. Lo principal es que no hubo clases que sean realmente pocas, no tuvimos que hacer muestreadores ponderados y sobremuestreo de datos.

¿Cómo se veían las fotos? Esta es la clase de aeronave y sus ejemplos están etiquetados como reconocidos y no reconocidos. Su proporción era de 1 a 9. Como puede ver, los datos son bastante ruidosos. Sugeriría que este es un avión. Si observa no reconocido, en la mayoría de los casos es solo ruido. Alguien incluso trató de escribir "avión", pero aparentemente en francés.
La mayoría de los participantes simplemente tomaron cuadrículas, renderizaron datos de esta secuencia de líneas como imágenes RGB y las arrojaron a la red. Pinté aproximadamente de la misma manera: tomé una paleta de colores, pinté la primera línea con un color, que estaba al comienzo de esta paleta, la última, con otra, que estaba al final de la paleta, y en todas partes interpoladas en esta paleta. Por cierto, esto dio un mejor resultado que si dibujas como en la primera diapositiva, solo negro.
Otros miembros del equipo, como Ivan Sosin, probaron enfoques de dibujo ligeramente diferentes. Con un canal, simplemente dibujó una imagen gris, con otro canal, dibujó cada trazo con un gradiente de principio a fin, de 32 a 255, y el tercer canal dibujó un gradiente en todos los trazos de 32 a 255.
Otra cosa interesante es que Alex Parinov arrojó información a la red a través del código de país.
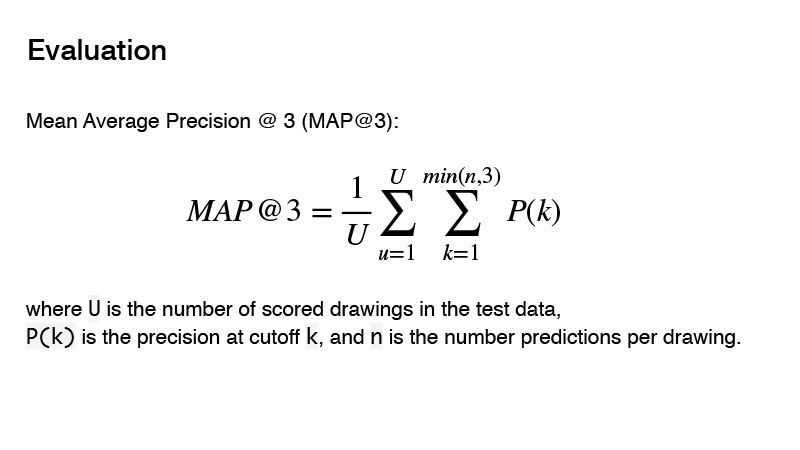
La métrica utilizada en la competencia es la precisión media promedio. ¿Cuál es la esencia de esta métrica para la competencia? Puedes dar tres predictores, y si estos tres predictores no son correctos, obtienes 0. Si hay uno correcto, entonces se toma en cuenta su orden. Y el resultado para el objetivo se considerará 1, dividido por el orden de su predicción. Por ejemplo, hiciste tres predicciones, y la primera es la correcta, luego divides 1 por 1 y obtienes 1. Si el predictor es correcto y su orden es 2, entonces 1 divide por 2, obtienes 0.5. Bueno, etc.

Con el preprocesamiento de datos, cómo dibujar imágenes, etc., decidimos un poco. ¿Qué arquitecturas utilizamos? Intentamos utilizar arquitecturas audaces como PNASNet, SENet y arquitecturas ya clásicas como SE-Res-NeXt, cada vez entran más en nuevas competencias. También hubo ResNet y DenseNet.



¿Cómo enseñamos esto? Todos los modelos que tomamos, nos llevamos pre-entrenados en imagenet. Aunque hay muchos datos, 50 millones de imágenes, pero aún así, si toma una red pre-entrenada en imagenet, muestra un mejor resultado que si la entrena desde cero.
¿Qué técnicas de entrenamiento utilizamos? Esto está costando recocer con reinicios cálidos, hablaré de eso un poco más tarde. Esta es una técnica que uso en casi todas mis últimas competiciones, y con ellas resulta bastante bueno entrenar las redes, para lograr un buen mínimo.

A continuación, reduzca la tasa de aprendizaje en meseta. Comienza a entrenar la red, establece una tasa de aprendizaje específica, luego la aprende, luego su pérdida gradualmente converge a algún valor específico. Verifica esto, por ejemplo, durante diez eras, la pérdida no ha cambiado. Reduce su tasa de aprendizaje en algún valor y continúa aprendiendo. De nuevo, cae un poco, converge en un cierto mínimo, y nuevamente baja la tasa de aprendizaje, y así sucesivamente, hasta que su red finalmente converge.
Otra técnica interesante: no decaiga la velocidad de aprendizaje, aumente el tamaño del lote. Hay un artículo del mismo nombre. Cuando entrena la red, no tiene que disminuir la tasa de aprendizaje, solo puede aumentar el tamaño del lote.
Esta técnica, por cierto, fue utilizada por Alex Parinov. Comenzó con un lote igual a 408, y cuando la red llegó a una meseta, simplemente duplicó el tamaño del lote, etc.
En realidad, no recuerdo qué valor alcanzó el tamaño de lote, pero curiosamente, había equipos en Kaggle que usaban la misma técnica, su tamaño de lote era de aproximadamente 10,000. Por cierto, marcos modernos para el aprendizaje profundo, como PyTorch, por ejemplo, le permite hacer esto de manera muy simple. Usted genera su lote y lo envía a la red no como es, en su totalidad, sino que lo divide en trozos para que quepa en su tarjeta de video, cuente los gradientes y, después de calcular el gradiente para todo el lote, actualice las escalas.
Por cierto, los grandes tamaños de lote todavía entraron en esta competencia, porque los datos eran bastante ruidosos, y un gran tamaño de lote le ayudó a aproximar el gradiente con mayor precisión.
También se usó pseudo-dabbing; en su mayor parte, fue utilizado por Roman Soloviev. Muestreó en algún lugar la mitad de los datos de la prueba, y en tales lotes entrenó a la grilla.
El tamaño de las imágenes jugó un papel importante, pero el hecho es que tiene muchos datos, necesita entrenar durante mucho tiempo y, si el tamaño de su imagen es bastante grande, entrenará durante mucho tiempo. Pero esto no aportó mucho a la calidad de su clasificador final, por lo que valió la pena usar algunas compensaciones. Y probaron solo imágenes de tamaño no muy grande.
¿Cómo aprendió todo? Al principio, se tomaron fotos de un tamaño pequeño, se corrieron varias eras sobre ellas, rápidamente tomó tiempo. Luego se entregaron imágenes grandes, se capacitó a la red, y luego incluso más, incluso más para no entrenarla desde cero y no perder mucho tiempo.
Sobre optimizadores. Utilizamos SGD y Adam. De esta manera, fue posible obtener un solo modelo, que dio una velocidad de 0.941-0.946 en una tabla de clasificación pública, lo cual es bastante bueno.
Si ensamblas modelos de alguna manera, entonces obtienes 0.951. Si aplica otra técnica, obtendrá la velocidad final en el tablero público 0.954, tal como la recibimos. Pero más sobre eso más tarde. A continuación, le contaré cómo ensamblamos los modelos y cómo se logró esa velocidad final.
A continuación, me gustaría hablar sobre Cosing Recocido con reinicios cálidos o Descenso de gradiente estocástico con reinicios cálidos. En términos generales, en principio, puede pegar cualquier optimizador, pero la conclusión es esta: si solo entrena una red y gradualmente converge a un mínimo, entonces todo está bien, obtendrá una red, comete ciertos errores, pero puedes enseñarle un poco diferente. Establecerá una tasa de aprendizaje inicial y la reducirá gradualmente de acuerdo con esta fórmula. Lo subestimas, tu red llega a un cierto mínimo, luego ahorras peso y vuelves a establecer la tasa de aprendizaje, que era al comienzo del entrenamiento, por lo tanto, desde este mínimo, ve a algún lugar y nuevamente subestimes tu tasa de aprendizaje.
Por lo tanto, puede visitar varios mínimos a la vez, en los que tendrá la pérdida más o menos lo mismo. Pero el hecho es que las redes con estos pesos darán diferentes errores en su fecha. Al promediarlos, obtendrá una cierta aproximación y su velocidad será mayor.
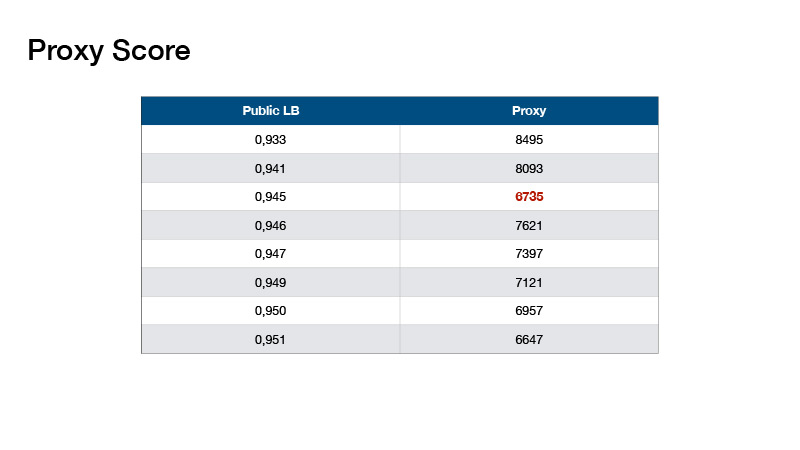
Sobre cómo ensamblamos nuestros modelos. Al comienzo de la presentación, le dije que prestara atención a la cantidad de datos en la prueba y al número de clases. Si agrega 1 al número de objetivos en el conjunto de prueba y divide por el número de clases, obtiene el número 330, y se escribió sobre esto en el foro: que las clases en la prueba están equilibradas. Esto podría ser usado.
En base a esto, Roman Solovyov inventó la métrica, la llamamos Proxy Score, que se correlacionó bastante bien con la tabla de clasificación. La conclusión es: usted hace una predicción, toma el top-1 de sus predicciones y cuenta el número de objetos para cada clase. Resta 330 de cada valor y suma los valores absolutos resultantes.
Tales valores resultaron. Esto nos ayudó a no hacer una tabla de clasificación de pruebas, sino a validar localmente y seleccionar coeficientes para nuestros conjuntos.
Con el conjunto podrías obtener tal velocidad. Que mas hacer Supongamos que usó la información de que las clases en su prueba están equilibradas.
El equilibrio fue diferente.
Un ejemplo de uno de ellos es el equilibrio de los muchachos que ganaron el primer lugar.
Que hicimos Nuestro equilibrio fue bastante simple, fue propuesto por Evgeny Babakhnin. Primero clasificamos nuestras predicciones por los primeros 1 y seleccionamos candidatos de ellos, de modo que el número de clases no excediera de 330. Pero para algunas clases, resulta que hay menos predicciones que 330. De acuerdo, clasifiquemos por top-2 y top 3, y también elegir candidatos.
¿En qué difería nuestro equilibrio del primer lugar? Utilizaron un enfoque iterativo, tomaron la clase más popular y redujeron las probabilidades para esta clase en un pequeño número, hasta que esta clase no se convirtió en la más popular. Tomaron la siguiente clase más popular. Así que más y bajó hasta que el número de todas las clases se volvió igual.
Todos usaron un enfoque más o menos uno para las redes de capacitación, pero no todos usaron el equilibrio. Usando el equilibrio, puedes entrar en oro, y si tienes suerte, entonces en mani.
¿Cómo preprocesar una fecha? Todos preprocesaron la fecha más-menos de la misma manera: hicieron funciones artesanales, trataron de codificar los tiempos con diferentes colores de trazos, etc. Alexey Nozdrin-Plotnitsky, que ocupó el octavo lugar, estaba hablando de esto.

Lo hizo de manera diferente. Dijo que todas estas funciones artesanales no funcionan, no necesita hacer esto, su red debe aprender todo esto usted mismo. Y, en cambio, se le ocurrieron módulos de aprendizaje que preprocesaron sus datos. Lanzó en ellos los datos de origen sin preprocesamiento: las coordenadas de puntos y tiempos.
Además, tomó la diferencia en las coordenadas y la promedió sobre los tiempos. Y obtuvo una matriz bastante larga. Usó la convolución 1D varias veces para obtener una matriz de 64xn, donde n es el número total de puntos, y 64 está hecho para alimentar la matriz resultante a una capa de alguna red convolucional que acepta 64 canales. resultó ser una matriz de 64xn, luego de esto fue necesario componer un tensor de algún tamaño para que el número de canales fuera 64. Normalizó todos los puntos X, Y en el rango de 0 a 32 para hacer un tensor de tamaño 32x32. No sé por qué quería 32x32, sucedió. Y en esta coordenada puso un fragmento de esta matriz de tamaño 64xn. Por lo tanto, simplemente recibió el tensor de 32x32x64, que podría introducirse más en su red neuronal convolucional. Lo tengo todo