Hola Habr! Le presento la traducción del artículo
"Todo lo que necesita saber sobre Gráficos de dispersión para visualización de datos" de George Seif.
Si está involucrado en el análisis y la visualización de datos, entonces tendrá que lidiar con gráficos de dispersión. A pesar de su simplicidad, los diagramas de dispersión son una herramienta poderosa para visualizar datos. Al manipular colores, tamaños y formas, se puede garantizar la flexibilidad y la representatividad de los diagramas de dispersión.
En este artículo, aprenderá casi todo lo que necesita saber sobre la visualización de datos mediante gráficos de dispersión. Intentaremos analizar todos los parámetros necesarios en su uso en código python. También puedes encontrar algunos trucos prácticos.
Edificio de regresión
Incluso el uso más primitivo de un gráfico de dispersión ya ofrece una visión general justa de nuestros datos. En la Figura 1, ya podemos ver islas de datos combinados e identificar rápidamente valores atípicos.
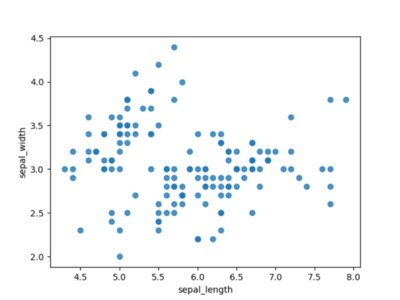 Figura 1
Figura 1
Las líneas de regresión apropiadas simplifican visualmente la tarea de identificar puntos cerca del medio. En la Figura 2, trazamos un gráfico lineal. Es bastante fácil ver que en este caso la función lineal no es representativa, ya que muchos puntos están bastante lejos de la línea.
 Figura 2
Figura 2
La Figura 3 usa un polinomio de orden 4 y parece mucho más prometedor. Parece que para modelar este conjunto de datos, definitivamente necesitamos un polinomio de orden 4.
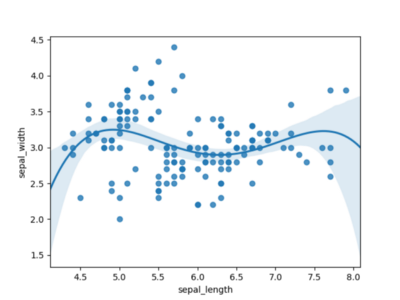 Figura 3
Figura 3
import seaborn as sns import matplotlib.pyplot as plt df = sns.load_dataset('iris')
Color y forma de puntos.
El color y la forma se pueden utilizar para visualizar las diferentes categorías en su conjunto de datos. El color y la forma son visualmente muy claros. Cuando observa un gráfico donde los grupos de puntos tienen diferentes colores de nuestras formas, inmediatamente se hace evidente que los puntos pertenecen a diferentes grupos.
La Figura 4 muestra las clases agrupadas por color. La Figura 5 muestra las clases, separadas por color y forma. En ambos casos, es mucho más fácil ver la agrupación. Ahora sabemos que será fácil separar la clase
setosa y en qué debemos centrarnos. También está claro que un solo gráfico de línea no podrá separar los puntos verde y naranja. Por lo tanto, necesitamos agregar algo para mostrar más dimensiones.
La elección entre color y forma se convierte en una cuestión de preferencia. Personalmente, el color me parece un poco más claro e intuitivo, pero la elección es siempre suya.
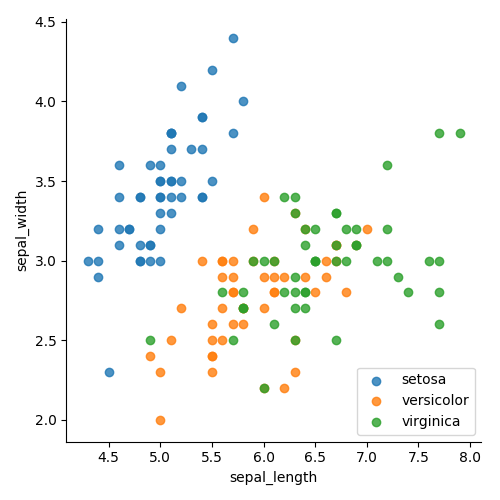 Figura 4
Figura 4
 Figura 5
Figura 5
import seaborn as sns import matplotlib.pyplot as plt df = sns.load_dataset('iris')
Histograma marginal
En la Figura 6 se muestra un ejemplo de un gráfico con histogramas marginales. Los histogramas marginales se superponen en la parte superior y lateral, lo que representa la distribución de puntos para objetos a lo largo de la abscisa y la ordenada. Esta pequeña adición es ideal para identificar puntos de distribución y valores atípicos.
Por ejemplo, en la Figura 6, obviamente vemos una alta concentración de puntos alrededor del marcado 3.0. Y gracias a este histograma, puede determinar el nivel de concentración. En el lado derecho, puede ver que alrededor del marcado 3.0 hay al menos tres veces más puntos que para cualquier otro rango discreto. Además, utilizando el histograma del lado derecho, se puede reconocer claramente que los valores atípicos obvios están por encima de la marca de 3.75. El diagrama superior muestra que la distribución de puntos a lo largo del eje X es más uniforme, con la excepción de los valores atípicos en la esquina derecha.
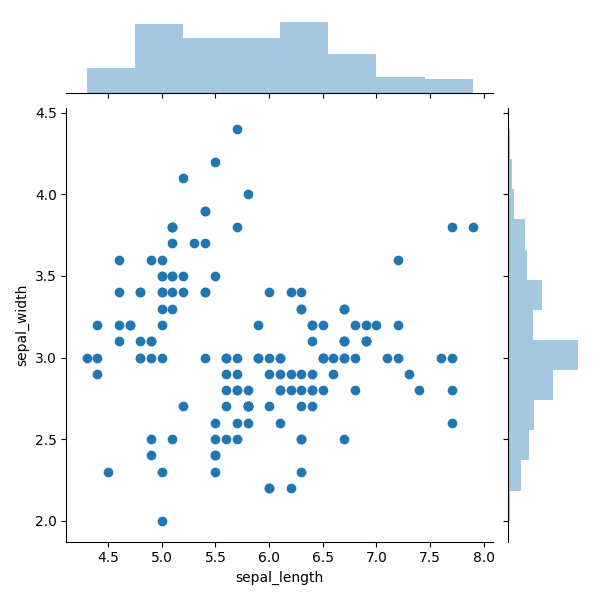 Figura 6
Figura 6
import seaborn as sns import matplotlib.pyplot as plt df = sns.load_dataset('iris') sns.jointplot(x=df["sepal_length"], y=df["sepal_width"], kind='scatter') plt.show()
Gráficos de burbujas
Usando gráficos de burbujas, necesitamos usar varias variables para codificar información. El nuevo parámetro inherente a este tipo de visualización es el tamaño. En la Figura 7 mostramos la cantidad de papas fritas consumidas por la altura y el peso de las personas que comieron. Tenga en cuenta que un gráfico de dispersión es solo una herramienta de visualización bidimensional, pero cuando usamos gráficos de burbujas, podemos mostrar hábilmente información con tres dimensiones.
Aquí usamos el
color, la posición y el tamaño , donde la posición de las burbujas determina la altura y el peso de la persona, el color determina el género y el tamaño está determinado por la cantidad de papas fritas consumidas. El gráfico de burbujas nos permite combinar fácilmente todos los atributos en un gráfico para que podamos ver información de gran tamaño en una forma bidimensional.
 Figura 7
Figura 7
import numpy as np import matplotlib.pyplot as plt import matplotlib.patches as mpatches x = np.array([100, 105, 110, 124, 136, 155, 166, 177, 182, 196, 208, 230, 260, 294, 312]) y = np.array([54, 56, 60, 60, 60, 72, 62, 64, 66, 80, 82, 72, 67, 84, 74]) z = (x*y) / 60 for index, val in enumerate(z): if index < 10: color = 'g' else: color = 'r' plt.scatter(x[index], y[index], s=z[index]*5, alpha=0.5, c=color) red_patch = mpatches.Patch(color='red', label='Male') green_patch = mpatches.Patch(color='green', label='Female') plt.legend(handles=[green_patch, red_patch]) plt.title("French fries eaten vs height and weight") plt.xlabel("Weight (pounds)") plt.ylabel("Height (inches)") plt.show()