Dodo IS es un sistema global que lo ayuda a administrar eficazmente su negocio en Dodo Pizza. Cierra los problemas de pedidos de pizza, ayuda al franquiciado a realizar un seguimiento del negocio, mejora la eficiencia de los empleados y, a veces, cae. Lo último es lo peor para nosotros. Cada minuto de tales caídas conduce a la pérdida de ganancias, la insatisfacción del usuario y las noches de insomnio de los desarrolladores.
Pero ahora dormimos mejor. Aprendimos a reconocer escenarios de apocalipsis sistémicos y procesarlos. A continuación, le diré cómo brindamos estabilidad al sistema.

Una serie de artículos sobre el colapso del sistema Dodo IS * :
1. El día que Dodo se detuvo. Script sincrónico.
2. El día en que Dodo se detuvo. Script asincrónico
* Los materiales fueron escritos en base a mi desempeño en DotNext 2018 en Moscú .
Dodo es
El sistema es una gran ventaja competitiva de nuestra franquicia, porque los franquiciados obtienen un modelo de negocio listo para usar. Estos son ERP, HRM y CRM, todo en uno.
El sistema apareció un par de meses después de la apertura de la primera pizzería. Es utilizado por gerentes, clientes, cajeros, cocineros, compradores misteriosos, empleados de centros de atención telefónica, eso es todo. Convencionalmente, Dodo IS se divide en dos partes. El primero es para clientes. Esto incluye un sitio web, una aplicación móvil, un centro de contacto. El segundo para los socios franquiciados, ayuda a administrar pizzerías. A través del sistema, las facturas de los proveedores, la gestión del personal, las personas que toman turnos, la contabilidad automática de la nómina, la capacitación en línea para el personal, la certificación de gerentes, un sistema de control de calidad y compradores misteriosos pasan por el sistema.
Rendimiento del sistema
Rendimiento del sistema Dodo IS = Confiabilidad = Tolerancia a fallas / Recuperación. Detengámonos en cada uno de los puntos.
Fiabilidad
No tenemos grandes cálculos matemáticos: necesitamos atender un cierto número de pedidos, hay ciertas zonas de entrega. El número de clientes no varía particularmente. Por supuesto, seremos felices cuando crezca, pero esto rara vez ocurre en grandes explosiones. Para nosotros, el rendimiento se reduce a la cantidad de fallas que se producen, a la confiabilidad del sistema.
Tolerancia a fallas
Un componente puede depender de otro componente. Si se produce un error en un sistema, el otro subsistema no debe caerse.
Resiliencia
Las fallas de los componentes individuales ocurren todos los días. Esto es normal Es importante cuán rápido podemos recuperarnos de una falla.
Escenario de falla del sistema síncrono
Que es esto
El instinto de una gran empresa es servir a muchos clientes al mismo tiempo. Del mismo modo que es imposible trabajar para una pizzería de cocina que trabaja para la entrega de la misma manera que una ama de casa en una cocina en casa, un código diseñado para la ejecución sincrónica no puede funcionar con éxito para el servicio al cliente en masa en un servidor.
Hay una diferencia fundamental entre ejecutar el algoritmo en una sola instancia y ejecutar el mismo algoritmo que un servidor en el marco del servicio masivo.
Echa un vistazo a la imagen de abajo. A la izquierda, vemos cómo ocurren las solicitudes entre dos servicios. Estas son llamadas RPC. La siguiente solicitud finaliza después de la anterior. Obviamente, este enfoque no escala: se alinean pedidos adicionales.
Para atender muchos pedidos, necesitamos la opción correcta:
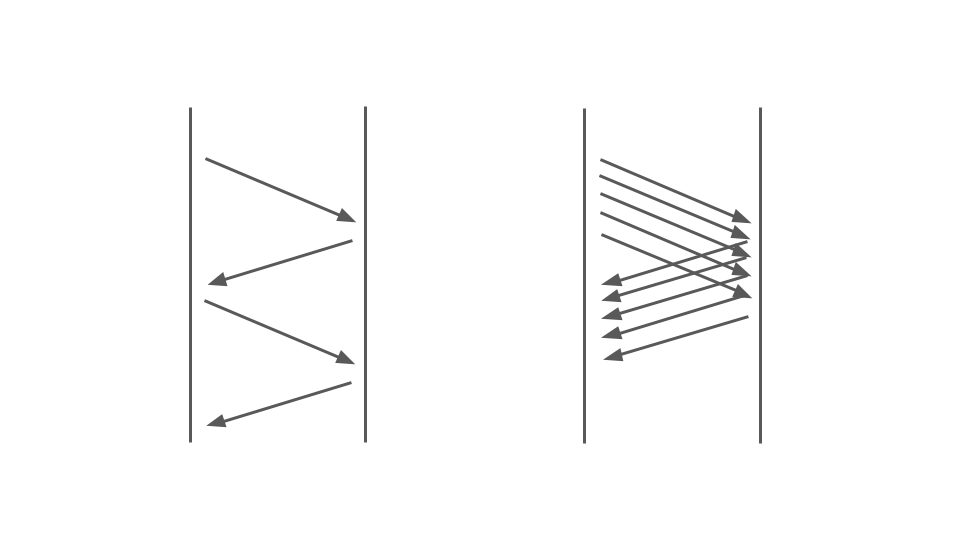
El funcionamiento del código de bloqueo en una aplicación síncrona se ve muy afectado por el modelo de subprocesamiento múltiple utilizado, es decir, la multitarea preventiva. Solo puede conducir a fracasos.
La multitarea simplificada y preventiva podría ilustrarse de la siguiente manera:

Los bloques de color son el trabajo real que hace la CPU, y vemos que el trabajo útil indicado por el verde en el diagrama es bastante pequeño en el contexto general. Necesitamos despertar el flujo, ponerlo a dormir, y esto está por encima. Tal sueño / vigilia ocurre durante la sincronización en cualquier primitiva de sincronización.
Obviamente, el rendimiento de la CPU disminuirá si diluye el trabajo útil con una gran cantidad de sincronizaciones. ¿Qué tan fuerte puede afectar la multitarea preventiva al rendimiento?
Considere los resultados de una prueba sintética:
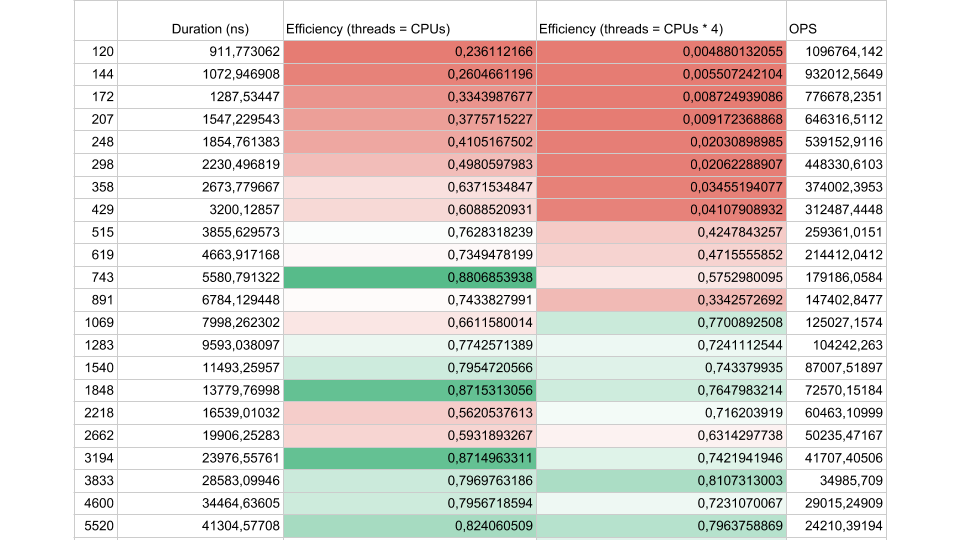
Si el intervalo de flujo entre sincronizaciones es de aproximadamente 1000 nanosegundos, la eficiencia es bastante pequeña, incluso si el número de subprocesos es igual al número de núcleos. En este caso, la eficiencia es de aproximadamente el 25%. Si el número de subprocesos es 4 veces mayor, la eficiencia cae drásticamente, al 0,5%.
Piénselo, en la nube ordenó una máquina virtual con 72 núcleos. Cuesta dinero y usa menos de la mitad de un núcleo. Esto es exactamente lo que puede suceder en una aplicación multiproceso.
Si hay menos tareas, pero su duración es mayor, la eficiencia aumenta. Vemos que a 5,000 operaciones por segundo, en ambos casos la eficiencia es del 80-90%. Para un sistema multiprocesador, esto es muy bueno.
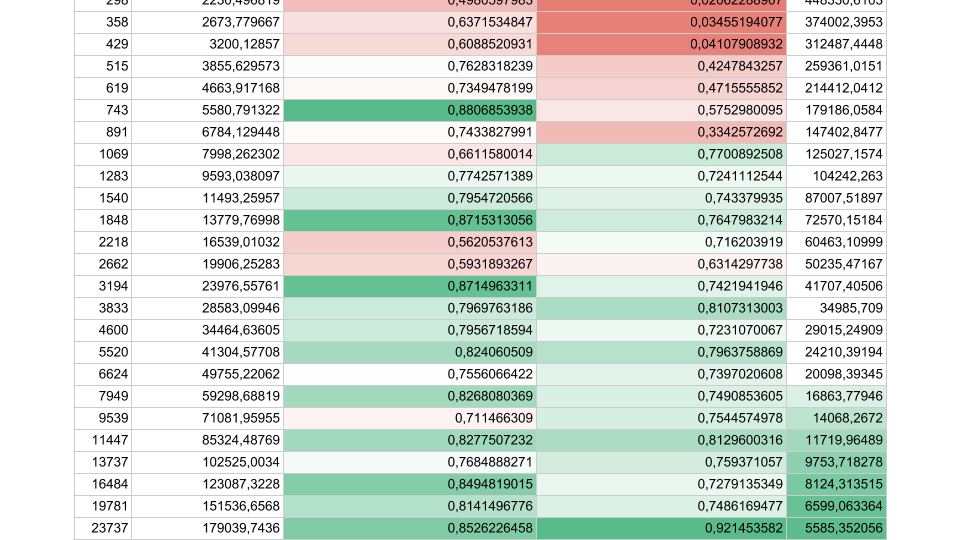
En nuestras aplicaciones reales, la duración de una operación entre sincronizaciones se encuentra en algún punto intermedio, por lo que el problema es urgente.
Que esta pasando
Presta atención al resultado de las pruebas de estrés. En este caso, fue la llamada "prueba de extrusión".
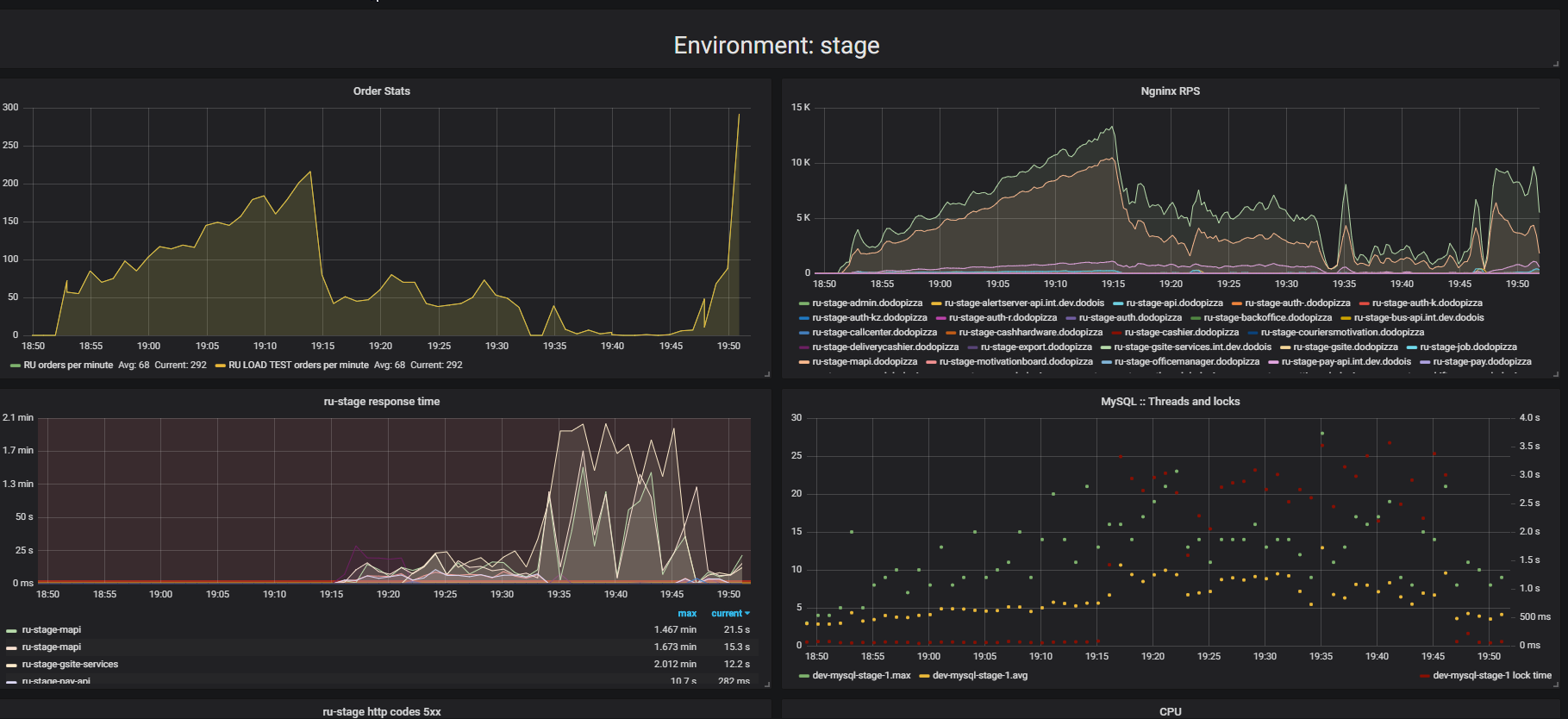
La esencia de la prueba es que al usar un soporte de carga, enviamos más y más solicitudes artificiales al sistema, tratamos de hacer tantos pedidos como sea posible por minuto. Intentamos encontrar el límite después del cual la aplicación se negará a atender solicitudes más allá de sus capacidades. Intuitivamente, esperamos que el sistema se ejecute al límite, descartando solicitudes adicionales. Esto es exactamente lo que sucedería en la vida real, por ejemplo, cuando se sirve en un restaurante que está lleno de clientes. Pero algo más sucede. Los clientes hicieron más pedidos y el sistema comenzó a servir menos. El sistema comenzó a servir tan pocas órdenes que puede considerarse un fallo completo, un colapso. Esto sucede con muchas aplicaciones, pero ¿debería ser?
En el segundo gráfico, el tiempo para procesar una solicitud aumenta, durante este intervalo se atienden menos solicitudes. Las solicitudes que llegaron antes se atienden mucho más tarde.
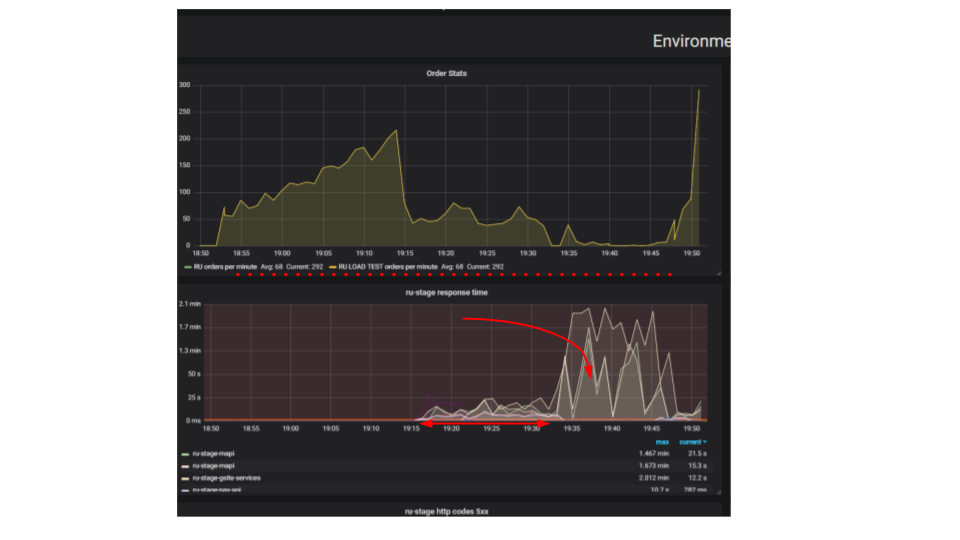
¿Por qué se detiene la aplicación? Había un algoritmo, funcionó. Lo iniciamos desde nuestra máquina local, funciona muy rápido. Creemos que si tomamos una máquina cien veces más potente y ejecutamos cien solicitudes idénticas, entonces deberían ejecutarse al mismo tiempo. Resulta que las solicitudes de diferentes clientes chocan. Entre ellos, surge la Contención y este es un problema fundamental en las aplicaciones distribuidas. Las solicitudes separadas luchan por los recursos.
Formas de encontrar un problema
Si el servidor no funciona, primero intentaremos encontrar y solucionar los problemas triviales de los bloqueos dentro de la aplicación, en la base de datos y durante la E / S de archivo. Todavía hay toda una clase de problemas en las redes, pero hasta ahora nos limitaremos a estos tres, esto es suficiente para aprender a reconocer problemas similares, y estamos interesados principalmente en los problemas que causan contención: la lucha por los recursos.
Cerraduras en proceso
Aquí hay una solicitud típica en una aplicación de bloqueo.
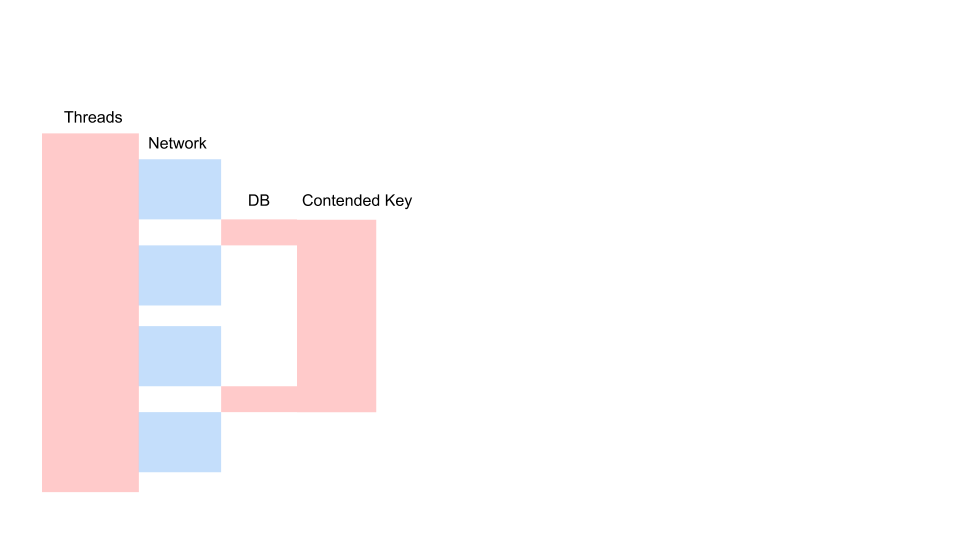
Esta es una variación del diagrama de secuencia que describe el algoritmo para la interacción del código de la aplicación y la base de datos como resultado de alguna operación condicional. Vemos que se está realizando una llamada a la red, luego ocurre algo en la base de datos: la base de datos se usa ligeramente. Luego se hace otra solicitud. Para todo el período, se utiliza una transacción en la base de datos y una clave común a todas las solicitudes. Pueden ser dos clientes diferentes o dos pedidos diferentes, pero un mismo objeto de menú de restaurante, almacenado en la misma base de datos que los pedidos de los clientes. Trabajamos utilizando una transacción para mantener la coherencia; dos consultas tienen contención en la clave del objeto común.
Veamos cómo se escala.
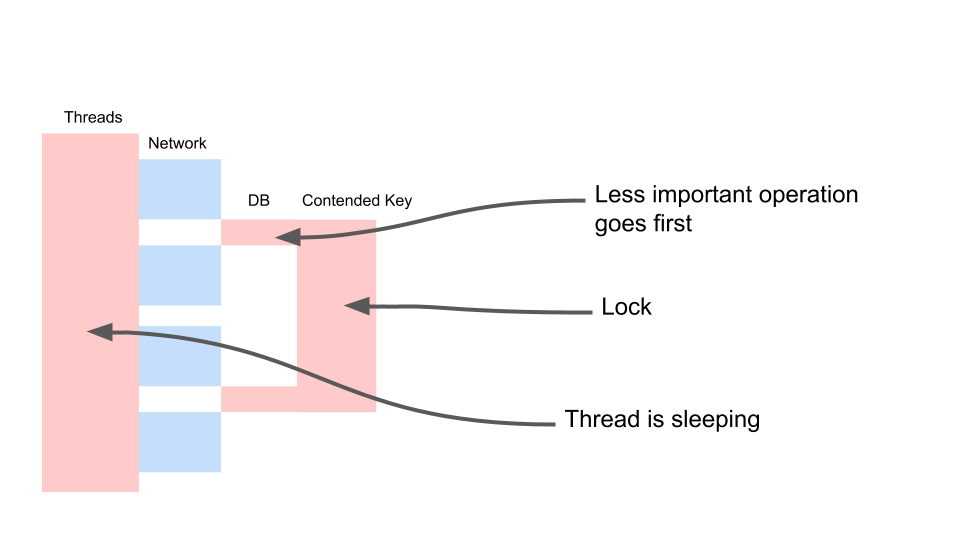
El hilo duerme la mayor parte del tiempo. Él, de hecho, no hace nada. Tenemos una cerradura que interfiere con otros procesos. Lo más molesto es que la operación menos útil en una transacción que ha bloqueado una clave se produce desde el principio. Alarga las transacciones de alcance en el tiempo.
Lucharemos de esta manera.
var fallback = FallbackPolicy<OptionalData> .Handle<OperationCancelledException>() .FallbackAsync<OptionalData>(OptionalData.Default); var optionalDataTask = fallback .ExecuteAsync(async () => await CalculateOptionalDataAsync());
Esta es la consistencia eventual. Asumimos que algunos de nuestros datos pueden ser menos recientes. Para hacer esto, necesitamos trabajar con el código de manera diferente. Debemos aceptar que los datos son de diferente calidad. No veremos lo que sucedió antes: el gerente cambió algo en el menú o el cliente hizo clic en el botón "pagar". Para nosotros, no importa cuál de ellos presionó el botón dos segundos antes. Y para los negocios no hay diferencia.
No hay diferencia, podemos hacer tal cosa. Condicionalmente llámelo opcionalData. Es decir, algún valor que podemos prescindir. Tenemos una reserva: el valor que tomamos del caché o pasamos algún valor predeterminado. Y para la operación más importante (la variable requerida) haremos esperar. Lo esperaremos firmemente, y solo entonces esperaremos una respuesta a las solicitudes de datos opcionales. Esto nos permitirá acelerar el trabajo. Hay otro punto importante: esta operación puede no realizarse en absoluto por alguna razón. Suponga que el código para esta operación no es óptimo, y en este momento hay un error. Si la operación falló, haga una reserva. Y luego trabajamos con esto como con el significado habitual.
DB Locks
Obtenemos aproximadamente el mismo diseño cuando reescribimos en asíncrono y cambiamos el modelo de consistencia.
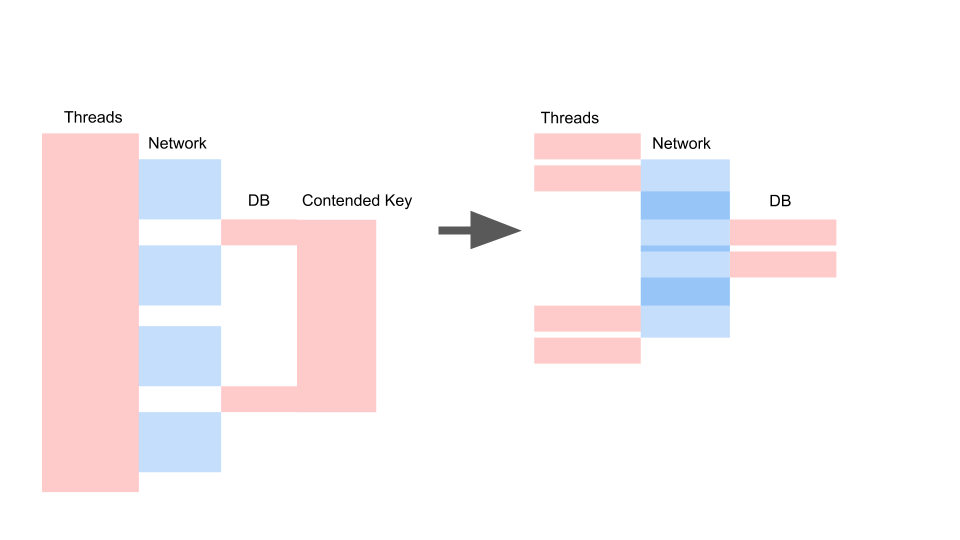
Lo que importa aquí no es que la solicitud se haya vuelto más rápida en el tiempo. Lo importante es que no tenemos contención. Si agregamos solicitudes, solo el lado izquierdo de la imagen está saturado con nosotros.
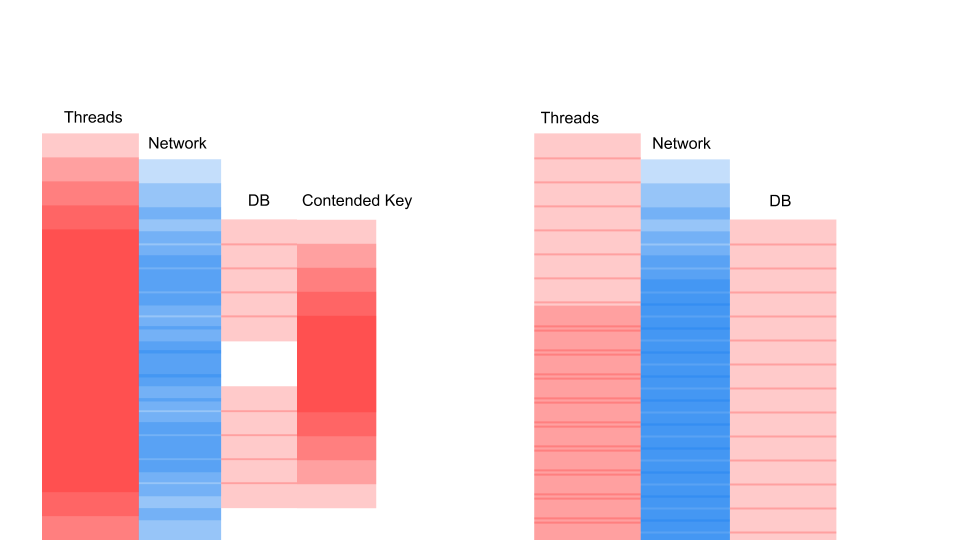
Esta es una solicitud de bloqueo. Aquí los hilos se superponen y las teclas en las que se produce la contención. A la derecha, no tenemos ninguna transacción en la base de datos y se ejecutan en silencio. El caso correcto puede funcionar en este modo indefinidamente. Izquierda hará que el servidor se bloquee.
Sincronizar io
A veces necesitamos registros de archivos. Sorprendentemente, el sistema de registro puede dar fallas tan desagradables. Latencia en disco en Azure: 5 milisegundos. Si escribimos un archivo en una fila, son solo 200 solicitudes por segundo. Eso es todo, la aplicación se ha detenido.

Es solo que tu cabello se pone de punta cuando ves esto: más de 2000 hilos se han creado en la aplicación. El 78% de todos los hilos son la misma pila de llamadas. Se detuvieron en el mismo lugar e intentan ingresar al monitor. Este monitor delimita el acceso al archivo donde todos iniciamos sesión. Por supuesto, esto debe ser cortado.

Esto es lo que debe hacer en NLog para configurarlo. Hacemos un objetivo asincrónico y le escribimos. Y el objetivo asincrónico escribe en el archivo real. Por supuesto, podemos perder una cierta cantidad de mensajes en el registro, pero ¿qué es más importante para las empresas? Cuando el sistema cayó durante 10 minutos, perdimos un millón de rublos. Probablemente sea mejor perder varios mensajes en el registro del servicio, que fallaron y se reiniciaron.
Todo es muy malo
La contención es un gran problema en las aplicaciones de subprocesos múltiples, lo que no le permite escalar simplemente una aplicación de subprocesos únicos. Las fuentes de contención deben ser capaces de identificar y eliminar. Una gran cantidad de subprocesos son desastrosos para las aplicaciones, y las llamadas de bloqueo deben reescribirse para sincronizarse.
Tuve que reescribir una gran cantidad de legado del bloqueo de llamadas en asíncrono, a menudo yo mismo inicié dicha actualización. Muy a menudo, alguien aparece y pregunta: "Escucha, hemos estado reescribiendo durante dos semanas, casi todo asíncrono. ¿Y cuánto funcionará más rápido? Chicos, los molestaré, no funcionará más rápido. Se volverá aún más lento. Después de todo, TPL es un modelo competitivo por encima de otro: multitarea cooperativa sobre multitarea preventiva, y esto es una sobrecarga. En uno de nuestros proyectos, aproximadamente + 5% al uso de CPU y carga en GC.
Hay una mala noticia más: la aplicación puede funcionar mucho peor después de reescribir en asíncrono, sin darse cuenta de las características del modelo competitivo. Hablaré de estas características con gran detalle en el próximo artículo.
Esto plantea la pregunta: ¿es necesario reescribir?
El código síncrono se reescribe en asíncrono para desbloquear el modelo de concurrencia y deshacerse del modelo multitarea preventivo. Vimos que la cantidad de subprocesos puede afectar negativamente el rendimiento, por lo que debe liberarse de la necesidad de aumentar la cantidad de subprocesos para aumentar la concurrencia. Incluso si tenemos Legacy, y no queremos reescribir este código, esta es la razón principal para reescribirlo.
La buena noticia al final es que ahora sabemos algo sobre cómo deshacerse de los problemas triviales de la contención del código de bloqueo. Si encuentra tales problemas en su aplicación de bloqueo, es hora de deshacerse de ellos antes de reescribirlos a asíncrono, porque allí no desaparecerán por sí solos.