Los gráficos por computadora, como saben, son la base de la industria del juego. En el proceso de creación de contenido gráfico, inevitablemente encontramos dificultades asociadas con la diferencia en su presentación en el entorno de creación y en la aplicación. A estas dificultades se agregan los riesgos del simple descuido humano. Dada la escala del desarrollo del juego, tales problemas surgen con frecuencia o en grandes cantidades.
Combatir tales dificultades nos llevó a pensar en la automatización y escribir artículos sobre este tema. La mayor parte del material se ocupará de trabajar con
Unity 3D , ya que esta es la principal herramienta de desarrollo en Plarium Krasnodar. En adelante, los modelos y texturas 3D se considerarán como contenido gráfico.
En este artículo, hablaremos sobre las características de acceder a datos que representan objetos 3D en
Unity . El material será útil principalmente para principiantes, así como para aquellos desarrolladores que rara vez interactúan con la representación interna de dichos modelos.

Acerca de los modelos 3D en Unity: para los más pequeños
En el enfoque estándar,
Unity utiliza los componentes
MeshFilter y
MeshRenderer para representar el modelo. MeshFilter se refiere al activo
Mesh que representa el modelo. Para la mayoría de los sombreadores, la información de geometría es un componente mínimo obligatorio para representar un modelo en la pantalla. Los datos de escaneo de textura y los huesos de animación pueden no estar disponibles si no están involucrados. La forma en que se implementa esta clase en el interior y cómo se almacena todo es un misterio para la
enésima cantidad de dinero en siete sellos.
En el exterior, la malla como objeto proporciona acceso a los siguientes conjuntos de datos:
- vértices : un conjunto de posiciones de vértices geométricos en un espacio tridimensional con su propio origen;
- normales, tangentes : conjuntos de vectores normales y tangentes a vértices que se usan comúnmente para calcular la iluminación;
- uv, uv2, uv3, uv4, uv5, uv6, uv7, uv8 : conjuntos de coordenadas para el escaneo de texturas;
- colores, colores32 : conjuntos de valores de color de vértices, cuyo ejemplo de libro de texto es mezclar textura por máscara;
- bindposes : conjuntos de matrices para colocar vértices en relación con los huesos;
- boneWeights - coeficientes de influencia de los huesos en la parte superior;
- triángulos : un conjunto de índices de vértices procesados 3 a la vez; cada uno de estos triples representa un polígono (en este caso, un triángulo) del modelo.
El acceso a la información sobre vértices y polígonos se implementa a través de las propiedades correspondientes, cada una de las cuales devuelve una matriz de estructuras. Para una persona que
no lee la documentación rara vez trabaja con mallas en
Unity , puede que no sea obvio que cada vez que se accede a los datos de vértice, se crea una copia del conjunto correspondiente en la memoria en forma de una matriz con una longitud igual al número de vértices. Este matiz se considera en un pequeño
bloque de documentación . Los comentarios sobre las propiedades de la clase
Mesh mencionadas anteriormente también advierten sobre esto. La razón de este comportamiento es la característica arquitectónica de
Unity en el contexto del tiempo de ejecución
Mono . Esquemáticamente, esto se puede representar de la siguiente manera:
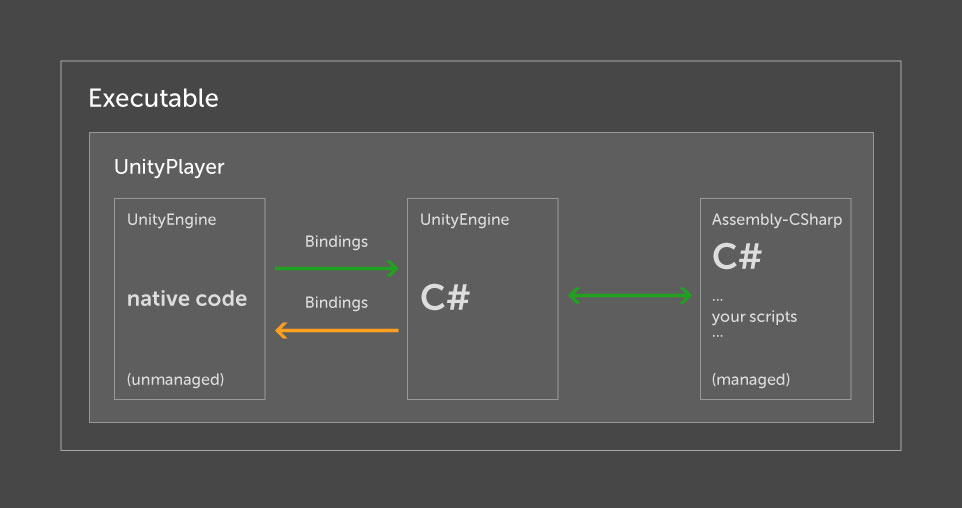
El núcleo del motor (UnityEngine (nativo)) está aislado de los scripts del desarrollador, y el acceso a su funcionalidad se implementa a través de la biblioteca UnityEngine (C #). De hecho, es un adaptador, ya que la mayoría de los métodos sirven como una capa para recibir datos del núcleo. En este caso, el núcleo y el resto, incluidos sus scripts, giran bajo diferentes procesos y la parte del script solo conoce la lista de comandos. Por lo tanto, no hay acceso directo a la memoria utilizada por el núcleo desde el script.
Sobre el acceso a datos internos, o qué tan malas pueden ser las cosas
Para demostrar cuán malas pueden ser las cosas, analicemos la cantidad de memoria borrada por Garbage Collector utilizando un ejemplo de la documentación. Para simplificar la creación de perfiles, envuelva el mismo código en el método Actualizar.
public class MemoryTest : MonoBehaviour { public Mesh Mesh; private void Update() { for (int i = 0; i < Mesh.vertexCount; i++) { float x = Mesh.vertices[i].x; float y = Mesh.vertices[i].y; float z = Mesh.vertices[i].z; DoSomething(x, y, z); } } private void DoSomething(float x, float y, float z) {
Ejecutamos este script con una primitiva estándar: una esfera (515 vértices). Usando la herramienta
Profiler , en la pestaña
Memoria , puede ver cuánta memoria se ha marcado para la recolección de basura en cada marco. En nuestra máquina de trabajo, este valor era ~ 9.2 Mb.
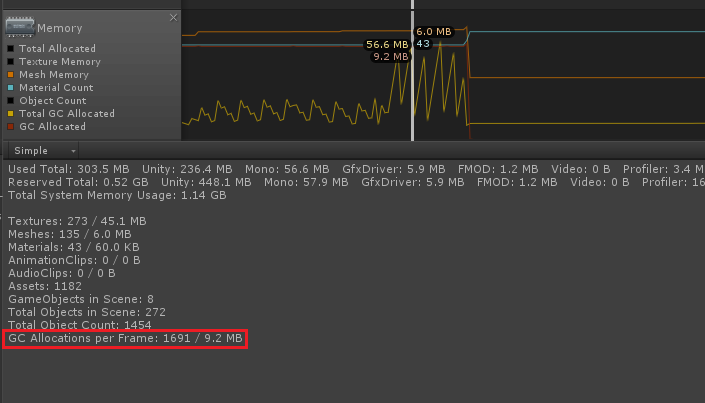
Esto es bastante incluso para una aplicación cargada, y aquí lanzamos una escena con un objeto en el que se monta el script más simple.
Es importante mencionar las características del compilador
.Net y la optimización del código. Al recorrer la cadena de llamadas, encontrará que llamar a
Mesh.vertices implica llamar al método
externo del motor. Esto evita que el compilador optimice el código dentro de nuestro método
Update () , a pesar de que
DoSomething () está vacío y las variables
x, y, z no se utilizan por este motivo.
Ahora almacenamos en caché la matriz de posiciones al comienzo.
public class MemoryTest : MonoBehaviour { public Mesh Mesh; private Vector3[] _vertices; private void Start() { _vertices = Mesh.vertices; } private void Update() { for (int i = 0; i < _vertices.Length; i++) { float x = _vertices[i].x; float y = _vertices[i].y; float z = _vertices[i].z; DoSomething(x, y, z); } } private void DoSomething(float x, float y, float z) {
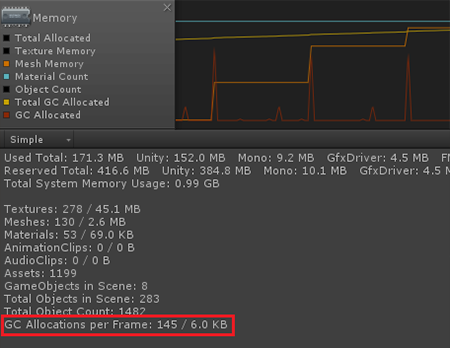
En promedio 6 Kb. Otra cosa!
Esta característica se convirtió en una de las razones por las que tuvimos que implementar nuestra propia estructura para almacenar y procesar datos de malla.
Como lo hacemos
Durante el trabajo en grandes proyectos, surgió la idea de crear una herramienta para el análisis y la edición de contenido gráfico importado. Discutiremos los métodos de análisis y transformación en los siguientes artículos. Ahora veamos la estructura de datos que decidimos escribir para la conveniencia de implementar algoritmos, teniendo en cuenta las características de acceso a la información sobre la malla.
Inicialmente, esta estructura se veía así:
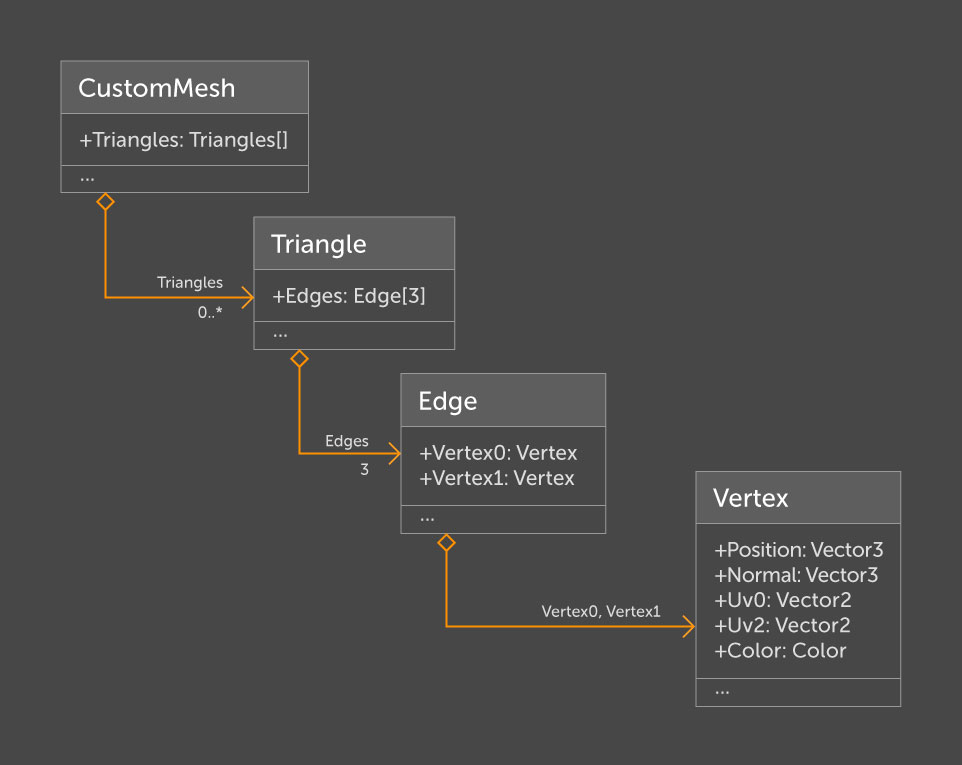
Aquí, la clase
CustomMesh representa la malla en sí. Por separado, en forma de
utilidad, implementamos la conversión de
UntiyEngine.Mesh y viceversa. Una malla se define por su conjunto de triángulos. Cada triángulo contiene exactamente tres aristas, que a su vez están definidas por dos vértices. Decidimos agregar a los vértices solo la información que necesitamos para el análisis, a saber: posición, normal, dos canales de exploración de textura (
uv0 para la textura principal,
uv2 para iluminación) y color.
Después de un tiempo, surgió la necesidad de ascender en la jerarquía. Por ejemplo, para descubrir desde un triángulo a qué malla pertenece. Además, la
degradación de
CustomMesh a
Vertex parecía pretenciosa, y la cantidad irrazonable y significativa de valores duplicados me puso nerviosa. Por estas razones, la estructura tuvo que ser rediseñada.
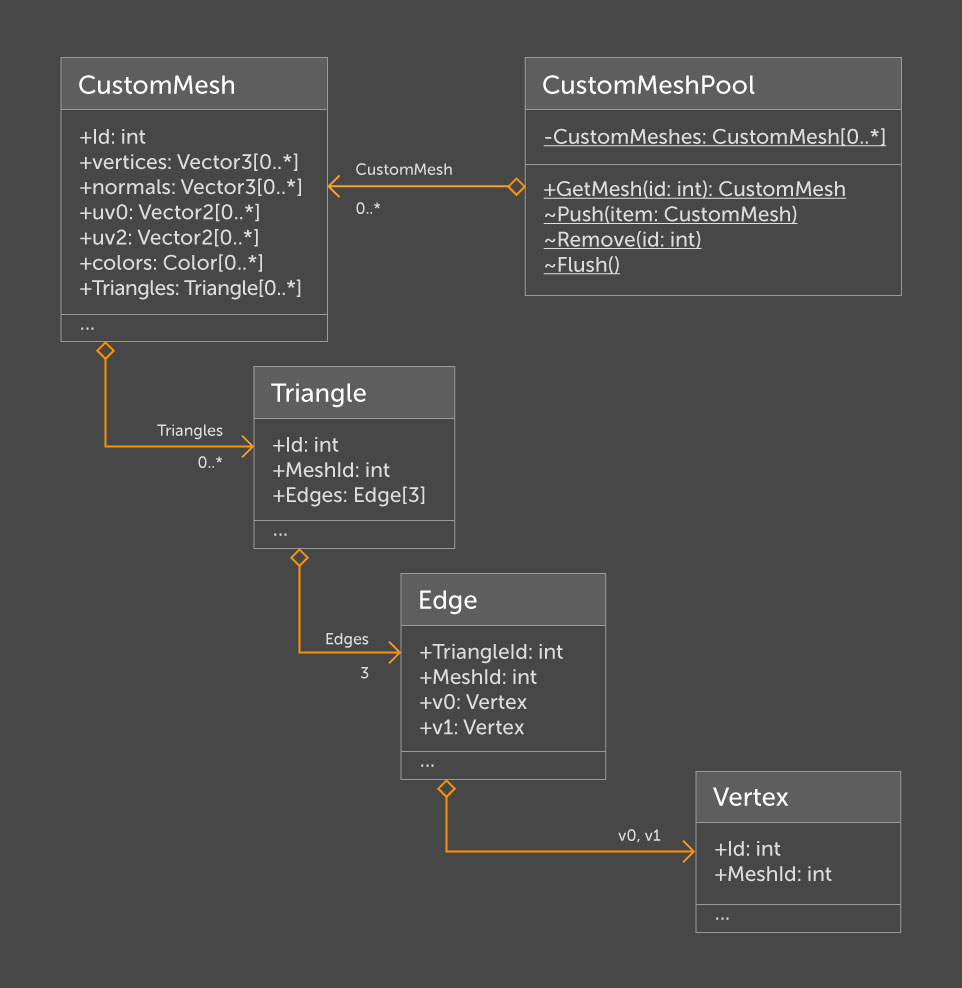 CustomMeshPool
CustomMeshPool implementa métodos para una administración conveniente y acceso a todos los
CustomMesh procesados. Debido al campo
MeshId , cada entidad tiene acceso a la información de toda la malla. Esta estructura de datos cumple los requisitos para las tareas iniciales. Es fácil de expandir agregando el conjunto de datos apropiado a
CustomMesh y los métodos necesarios a
Vertex .
Vale la pena señalar que este enfoque no es óptimo en rendimiento. Al mismo tiempo, la mayoría de los algoritmos que hemos implementado se centran en analizar el contenido en el editor de
Unity , por lo que no es necesario pensar a menudo en la cantidad de memoria utilizada. Por esta razón, literalmente almacenamos en caché todo lo que es posible. Primero probamos el algoritmo implementado, y luego refactorizamos sus métodos y, en algunos casos, simplificamos las estructuras de datos para optimizar el tiempo de ejecución.
Eso es todo por ahora. En el próximo artículo, hablaremos sobre cómo editar modelos 3D ya agregados al proyecto, y utilizaremos la estructura de datos considerada.