
Me gustaría presentar el concepto de
Programación Funcional a los principiantes de la manera más simple, destacando algunas de sus ventajas de las muchas otras que realmente harán que el código sea más legible y expresivo. Recogí algunas demostraciones interesantes para ti que están en
Playground en
Github .
Programación funcional: definición
En primer lugar, la
programación funcional no es un lenguaje o una sintaxis, sino una forma de resolver problemas dividiendo procesos complejos en procesos más simples y su posterior composición. Como su nombre lo indica, "
Programación funcional "
, la unidad de composición para este enfoque es una
función ; y el propósito de tal
función es evitar el cambio de estado o valores fuera de su
scope) .
En
Swift World, existen todas las condiciones para esto, porque las
funciones aquí son participantes tan completos en el proceso de programación como los
objetos, y el problema de la
mutation se resuelve a nivel del concepto de TIPOS de
value (
struct estructuras y
enum enumeración) que ayudan a gestionar la mutabilidad (
mutation ) y comunicar claramente cómo y cuándo puede suceder esto.
Sin embargo,
Swift no
Swift , en el sentido completo, el lenguaje de la
programación funcional , no lo obliga a la
programación funcional , aunque reconoce las ventajas de los enfoques
funcionales y encuentra formas de incorporarlos.
En este artículo, nos centraremos en utilizar los elementos integrados de la
Programación funcional en
Swift (es decir, "listos para usar") y en comprender cómo puede utilizarlos cómodamente en su aplicación.
Enfoques imperativos y funcionales: comparación
Para evaluar el Enfoque
Funcional , comparemos las soluciones a un problema simple de dos maneras diferentes. La primera solución es "
Imperativo "
, en el que el código cambia el estado dentro del programa.
Observe que manipulamos los valores dentro de la matriz mutable llamada
numbers y luego la imprimimos en la consola. Mirando este código, intente responder las siguientes preguntas que discutiremos en un futuro cercano:
- ¿Qué estás tratando de lograr con tu código?
- ¿Qué sucede si otro
thread intenta acceder a la matriz de numbers mientras se está ejecutando su código? - ¿Qué sucede si desea tener acceso a los valores originales en la matriz de
numbers ? - ¿Qué tan confiable se puede probar este código?
Ahora veamos un enfoque "
funcional " alternativo:
En este fragmento de código, obtenemos el mismo resultado en la consola, abordando la solución del problema de una manera completamente diferente. Tenga en cuenta que esta vez nuestra matriz de
numbers es inmutable gracias a la palabra clave
let . Hemos movido el proceso de multiplicar números de la matriz de
numbers al método
timesTen() , que se encuentra en la extensión de
extension la
Array . Todavía usamos un bucle
for y modificamos una variable llamada
output , pero el
scope esta variable está limitado solo por este método. De manera similar, nuestro argumento de entrada
self se pasa al método
timesTen() por valor (
by value ), teniendo el mismo alcance que la variable de
output . Se
timesTen() método
timesTen() , y podemos imprimir en la consola tanto la matriz de
numbers originales como el resultado de la matriz de
result .
Volvamos a nuestras 4 preguntas.
1. ¿Qué estás tratando de lograr con tu código?En nuestro ejemplo, realizamos una tarea muy simple multiplicando los números en la matriz de
numbers por
10 .
Con un enfoque
imperativo , para obtener una salida, debe pensar como una computadora, siguiendo las instrucciones en el bucle
for . En este caso, el código muestra
lograr el resultado. Con el enfoque
funcional , "
" se "envuelve" en el método
timesTen() . Siempre que este método se haya implementado en otro lugar, en realidad solo puede ver la expresión
numbers.timesTen() . Dicho código muestra claramente
logra con este código y no
se resuelve la tarea. Esto se llama
programación declarativa , y es fácil adivinar por qué este enfoque es atractivo.
El enfoque
imperativo hace que el desarrollador entienda
código para determinar
debe hacer.
El enfoque
funcional en comparación con el enfoque
imperativo es mucho más "expresivo" y le brinda al desarrollador una oportunidad de lujo de simplemente asumir que el método hace lo que dice hacer. (Obviamente, esta suposición se aplica solo al código previamente verificado).
2. ¿Qué sucede si otro thread intenta acceder a la matriz de numbers mientras se ejecuta el código?Los ejemplos presentados anteriormente existen en un espacio completamente aislado, aunque en un entorno complejo de subprocesos múltiples, es muy posible que dos
threads intenten acceder a los mismos recursos simultáneamente. En el caso del enfoque
Imperativo , es fácil ver que cuando otro
thread tiene acceso a la matriz de
numbers en el proceso de uso, el resultado será dictado por el orden en que los
threads acceden a la matriz de
numbers . Esta situación se denomina
race condition y puede conducir a un comportamiento impredecible e incluso a la inestabilidad y el bloqueo de la aplicación.
En comparación, el enfoque
funcional no tiene "efectos secundarios". En otras palabras, la salida del método de
output no cambia ningún valor almacenado en nuestro sistema y está determinada únicamente por la entrada. En este caso, cualquier subproceso (
threads ) que tenga acceso a la matriz de
numbers SIEMPRE recibirá los mismos valores y su comportamiento será estable y predecible.
3. ¿Qué sucede si desea tener acceso a los valores originales almacenados en la matriz de
numbers ?
Esta es una continuación de nuestra discusión sobre los "efectos secundarios". Obviamente, los cambios de estado no se rastrean. Por lo tanto, con el enfoque
imperativo , perdemos el estado inicial de nuestra matriz de
numbers durante el proceso de conversión. Nuestra solución, basada en el enfoque
funcional , guarda la matriz de
numbers originales y genera una nueva matriz de
result con las propiedades deseadas en la salida. Deja la matriz de
numbers original intacta y adecuada para el procesamiento futuro.
4. ¿Qué tan confiable puede ser probado este código?
Dado que el enfoque
funcional destruye todos los "efectos secundarios", la funcionalidad probada está completamente dentro del método. La entrada de este método NUNCA experimentará ningún cambio, por lo que puede probar varias veces usando el ciclo tantas veces como desee, y SIEMPRE obtendrá el mismo resultado. En este caso, la prueba es muy fácil. En comparación, probar la solución
Imperativa en un bucle cambiará el inicio de la entrada y obtendrá resultados completamente diferentes después de cada iteración.
Resumen de beneficios
Como vimos en un ejemplo muy simple, el Enfoque
Funcional es genial si se trata de un Modelo de Datos porque:
- Es declarativo
- Soluciona problemas relacionados con hilos como
race condition y puntos muertos - Deja el estado sin cambios, que se puede utilizar para transformaciones posteriores.
- Es fácil de probar.
Avancemos un poco más en el aprendizaje de la programación
funcional en
Swift . Se supone que los principales "actores" son funciones, y deberían ser principalmente
objetos de la primera clase .
Funciones de primera clase y funciones de orden superior
Para que una función sea de primera clase, debe tener la capacidad de ser declarada como variable. Esto le permite administrar la función como un TIPO de datos normal y, al mismo tiempo, ejecutarla. Afortunadamente, en
Swift funciones son objetos de la primera clase, es decir, se admiten pasándolas como argumentos a otras funciones, devolviéndolas como resultado de otras funciones, asignándolas a variables o almacenándolas en estructuras de datos.
Debido a esto, tenemos otras funciones en
Swift : funciones de orden superior que se definen como funciones que toman otra función como argumento o devuelven una función. Hay muchos de ellos:
map ,
filter ,
reduce , para cada
forEach ,
flatMap ,
compactMap ,
sorted , etc. Los ejemplos más comunes de funciones de orden superior son
map ,
filter y
reduce . No son globales, todos están "unidos" a ciertos TIPOS. Funcionan en todos los TIPOS de
Sequence , incluida la
Collection , que está representada por estructuras de datos
Swift como una
Array , un
Dictionary y un
Set . En
Swift 5 , las funciones de orden superior también funcionan con un TIPO -
Result completamente nuevo.
map(_:)
En el
map(_:) Swift map(_:) toma una función como parámetro y convierte los valores de un determinado
acuerdo con esta función. Por ejemplo, al aplicar
map(_:) a una matriz de valores de
Array , aplicamos una función de parámetro a cada elemento de la matriz original y obtenemos una matriz de
Array , pero también los valores convertidos.
En el código anterior, creamos la función
timesTen (_:Int) , que toma un valor entero
Int y devuelve el valor entero
Int multiplicado por
10 , y lo usamos como parámetro de entrada a nuestra función de
map(_:) orden superior
map(_:) , aplicándolo a nuestra matriz
numbers Obtuvimos el resultado que necesitamos en la matriz de
result .
El nombre de la función de parámetro
timesTen para funciones de orden superior como
map(_:) no importa, el
parámetro de entrada y el valor de retorno son importantes, es decir, la firma
(Int) -> Int parámetro de entrada de función. Por lo tanto, podemos usar funciones anónimas en el
map(_:) - cierres - en cualquier forma, incluidos aquellos con nombres de argumentos acortados
$0 ,
$1 , etc.
Si miramos la función
map(_ :) para una
Array , podría verse así:
func map<T>(_ transform: (Element) -> T) -> [T] { var returnValue = [T]() for item in self { returnValue.append(transform(item)) } return returnValue }
Este es un código imperativo que nos es familiar, pero ya no es un problema de desarrollador, es un problema de
Apple , un problema de
Swift . La implementación de la función
map(_:) orden superior está optimizada por
Apple en términos de rendimiento, y nosotros, los desarrolladores, tenemos garantizada la funcionalidad
map(_:) , por lo que solo podemos expresar correctamente con el argumento de la función de
transform que queremos sin preocuparnos por
se implementará. Como resultado, obtenemos código perfectamente legible en forma de una sola línea, que funcionará mejor y más rápido.
El
devuelto por la función de parámetro puede no coincidir con el
elementos en la colección original.
En el código anterior, tenemos posibles números enteros
possibleNumbers , representados como cadenas, y queremos convertirlos a números enteros de
Int , utilizando el inicializador
failable Int(_ :String) representado por el cierre
{ str in Int(str) } . Hacemos esto usando
map(_:) y obtenemos una matriz
mapped de
Optional como salida:

No
convertir
elementos de nuestra matriz
possibleNumbers a enteros, como resultado, una parte recibió el valor
nil , lo que indica la imposibilidad de convertir la
String a un entero
Int , y la otra parte se convirtió en
Optionals , que tienen valores:
print (mapped)
compactMap(_ :)
Si la función de parámetro pasada a la función de orden superior tiene un valor
Optional en la salida, entonces puede ser más útil usar otra función de orden superior, similar en significado:
compactMap(_ :) , que hace lo mismo que
map(_:) , pero adicionalmente "expande" los valores recibidos en la salida
Optional y elimina los valores
nil de la colección.

En este caso, obtenemos una matriz de
compactMapped TYPE
[Int] , pero posiblemente más pequeña:
let possibleNumbers = ["1", "2", "three", "///4///", "5"] let compactMapped = possibleNumbers.compactMap(Int.init) print (compactMapped)
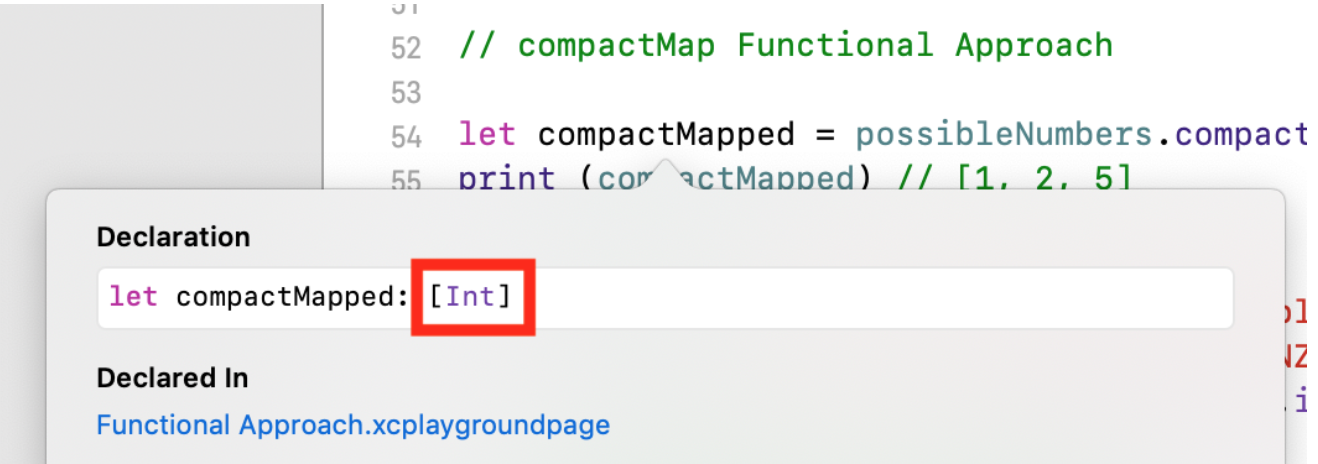
Siempre que use el
init?() Como la función de transformación, tendrá que usar
compactMap(_ :) :
Debo decir que hay razones más que suficientes para usar la función de orden superior
compactMap(_ :) .
Swift "amores" Valores
Optional , se pueden obtener no solo usando el
failable "
init?() failable ", sino también usando el
as? "Fundición":
let views = [innerView,shadowView,logoView] let imageViews = views.compactMap{$0 as? UIImageView}
... y la
try? al procesar errores arrojados por algunos métodos. Debo decir que a
Apple preocupa que el uso de
try? muy a menudo conduce al doble
Optional y en
Swift 5 ahora deja solo un nivel
Optional después de aplicar
try? .
Hay una función más similar en nombre del
flatMap(_ :) orden
flatMap(_ :) , sobre el cual es un poco más bajo.
A veces, para usar el
map(_:) funciones de orden superior
map(_:) , es útil usar el método
zip (_:, _:) para crear una secuencia de pares a partir de dos secuencias diferentes.
Supongamos que tenemos una
view en la que se representan varios puntos, conectados entre sí y formando una línea discontinua:
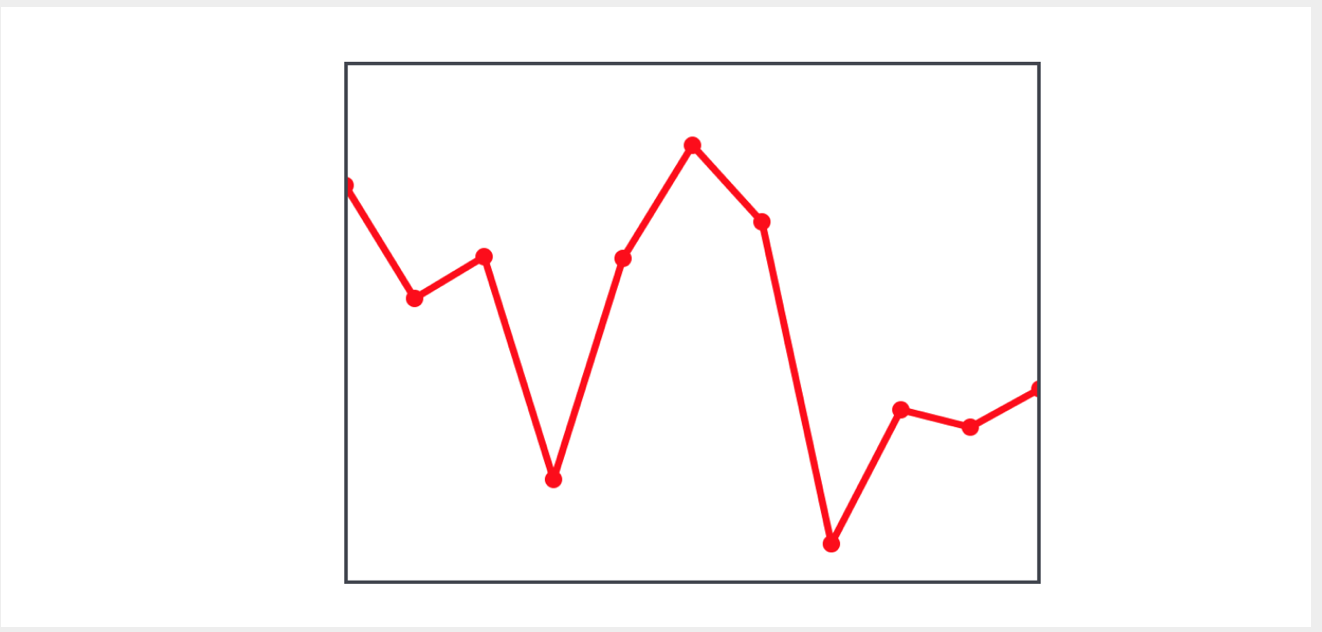
Necesitamos construir otra línea discontinua que conecte los puntos medios de los segmentos de la línea discontinua original:

Para calcular el punto medio de un segmento, debemos tener las coordenadas de dos puntos: el actual y el siguiente. Para hacer esto, podemos crear una secuencia que consista en pares de puntos, el actual y el siguiente, utilizando el método
zip (_:, _:) , en el que usaremos la matriz de puntos de inicio y la matriz de los siguientes
points.dropFirst() :
let pairs = zip (points,points.dropFirst()) let averagePoints = pairs.map { CGPoint(x: ($0.x + $1.x) / 2, y: ($0.y + $1.y) / 2 )}
Teniendo tal secuencia, calculamos muy fácilmente los puntos medios usando el
map(_:) funciones de orden superior
map(_:) y los mostramos en el gráfico.
filter (_:)
En
Swift , el
filter (_:) función de orden superior
filter (_:) está disponible para la mayoría de los
que está disponible la función de
map(_:) . Puede filtrar cualquier
Sequence secuencia con
filter (_:) , ¡esto es obvio! El método
filter (_:) toma otra función como parámetro, que es una condición para cada elemento de la secuencia, y si la condición se cumple, entonces el elemento se incluye en el resultado, y si no, no se incluye. Esta "otra función" toma un solo valor, un elemento de la
Sequence secuencia, y devuelve un
Bool , el llamado predicado.
Por ejemplo, para las matrices de matrices, el
filter (_:) función de orden superior
filter (_:) aplica la función de predicado y devuelve otra matriz que consta únicamente de aquellos elementos de la matriz original para los cuales la función de predicado de entrada devuelve
true .
Aquí, el
filter (_:) función de orden superior
filter (_:) toma cada elemento de la matriz de
numbers (representado por
$0 ) y verifica si este elemento es un número par. Si este es un número par, entonces los elementos de la matriz de
numbers caen en la nueva matriz
filted , de lo contrario no. En forma declarativa, informamos al programa
queremos obtener en lugar de preocuparnos por
debemos hacerlo.
Daré otro ejemplo del uso del
filter (_:) función de orden superior
filter (_:) para obtener solo los primeros
20 números de Fibonacci con valores
< 4000 :
let fibonacci = sequence(first: (0, 1), next: { ($1, $0 + $1) }) .prefix(20).map{$0.0} .filter {$0 % 2 == 0 && $0 < 4000} print (fibonacci)
Obtenemos una secuencia de tuplas que consta de dos elementos de la secuencia de Fibonacci: el n-ésimo y (n + 1) -ésimo:
(0, 1), (1, 1), (1, 2), (2, 3), (3, 5) …
Para un procesamiento adicional, limitamos el número de elementos a los veintiún elementos usando el
prefix (20) y tomamos el elemento
0 de la tupla generada usando el
map {$0.0 } , que corresponderá a la secuencia de Fibonacci que comienza con
0 :
0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, 233, 377, 610, 987, 1597, 2584,...
Podríamos tomar el
1 elemento de la tupla formada usando el
map {$0.1 } , que correspondería a la secuencia de Fibonacci que comienza con
1 :
1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, 233, 377, 610, 987, 1597, 2584,...
Obtenemos los elementos que necesitamos con la ayuda del
filter {$0 % 2 == 0 && $0 < 4000} función de orden superior
filter {$0 % 2 == 0 && $0 < 4000} , que devuelve una matriz de elementos de secuencia que satisfacen el predicado dado. En nuestro caso, será una matriz de enteros
[Int] :
[0, 2, 8, 34, 144, 610, 2584]
Hay otro ejemplo útil del uso del
filter (_:) para una
Collection .
Me encontré
con un problema real , cuando tienes una gran variedad de
images que se muestran con
CollectionView , y con la tecnología
Drag & Drop puedes recopilar un montón de imágenes y moverlas a todas partes, incluso soltarlas en " bote de basura ".

En este caso, la matriz de índices
removedIndexes índices
removedIndexes vertidas en el "bote de basura" son fijos, y usted necesita crear una nueva matriz de imágenes, excluyendo aquellos cuyos índices están en la matriz
removedIndexes . Supongamos que tenemos una matriz de
images de enteros que imita imágenes, y una matriz de índices de estos enteros
removedIndexes que deben eliminarse. Usaremos
filter (_:) para resolver nuestro problema:
var images = [6, 22, 8, 14, 16, 0, 7, 9] var removedIndexes = [2,5,0,6] var images1 = images .enumerated() .filter { !removedIndexes.contains($0.offset) } .map { $0.element } print (images1)
El método
enumerated() devuelve una secuencia de tuplas que consta de índices de
offset y valores de
element matriz.
Luego aplicamos un filtro filtera la secuencia resultante de tuplas, dejando solo aquellos cuyo índice $0.offsetno está contenido en la matriz removedIndexes. El siguiente paso, seleccionamos el valor de la tupla $0.elementy obtenemos la matriz que necesitamos images1.reduce (_:, _:)
El método reduce (_:, _:)también está disponible para la mayoría de los map(_:)y los métodos filter (_:). El método reduce (_:, _:)"colapsa" la secuencia Sequenceen un solo valor de acumulación y tiene dos parámetros. El primer parámetro es el valor de acumulación inicial, y el segundo parámetro es una función que combina el valor de acumulación con el elemento de secuencia Sequencepara obtener un nuevo valor de acumulación.La función del parámetro de entrada se aplica a cada elemento de la secuencia Sequence, uno tras otro, hasta que llega al final y crea el valor de acumulación final. let sum = Array (1...100).reduce(0, +)
Este es un ejemplo trivial clásico del uso de una función de orden superior reduce (_:, _:): contar la suma de los elementos de una matriz Array. 1 0 1 0 +1 = 1 2 1 2 2 + 1 = 3 3 3 3 3 + 3 = 6 4 6 4 4 + 6 = 10 . . . . . . . . . . . . . . . . . . . 100 4950 100 4950 + 100 = 5050
Usando la función, reduce (_:, _:)podemos calcular simplemente la suma de los números de Fibonacci que satisfacen una determinada condición: let fibonacci = sequence(first: (0, 1), next: { ($1, $0 + $1) }) .prefix(20).map{$0.0} .filter {$0 % 2 == 0 && $0 < 4000} print (fibonacci)
Pero hay aplicaciones más interesantes de una función de orden superior reduce (_:, _:).Por ejemplo, podemos determinar de manera muy simple y concisa un parámetro muy importante para UIScrollViewel tamaño del área "desplazable" contentSizeen función de su tamaño subviews: let scrollView = UIScrollView() scrollView.addSubview(UIView(frame: CGRect(x: 300.0, y: 0.0, width: 200, height: 300))) scrollView.addSubview(UIView(frame: CGRect(x: 100.0, y: 0.0, width: 300, height: 600))) scrollView.contentSize = scrollView.subviews .reduce(CGRect.zero,{$0.union($1.frame)}) .size
En esta demostración, el valor de acumulación es GCRect, y la operación de acumulación es la operación de combinar los unionrectángulos que son framenuestros subviews.A pesar de que una función de orden superior reduce (_:, _:)asume un carácter acumulativo, se puede usar en una perspectiva completamente diferente. Por ejemplo, para dividir una tupla en partes en una matriz de tuplas:
Swift 4.2introdujo un nuevo tipo de función de orden superior reduce (into:, _:). El método reduce (into:, _:)es preferible en eficiencia en comparación con el método reduce (:, :)si COW (copy-on-write) Arrayo se usa como la estructura resultante Dictionary.Puede usarse efectivamente para eliminar valores coincidentes en una matriz de enteros:
... o al contar el número de elementos diferentes en una matriz:
flatMap (_:)
Antes de pasar a esta función de orden superior, veamos una demostración muy simple. let maybeNumbers = ["42", "7", "three", "///4///", "5"] let firstNumber = maybeNumbers.map (Int.init).first
Si ejecutamos este código para ejecutarlo Playground, entonces todo se ve bien, y el nuestro firstNumberes igual 42: Pero, si no lo sabe, a
Pero, si no lo sabe, a Playgroundmenudo oculta el verdadero firstNumber. De hecho, la constante firstNumbertiene Optional: esto se debe a que
esto se debe a que map (Int.init)en la salida forma una matriz Optionalde valores TYPE [Int?], ya que no todas las líneas Stringpueden convertirse Inty el inicializador Int.intestá "cayendo" ( failable). Luego tomamos el primer elemento de la matriz formada usando la función firstpara la matriz Array, que también forma la salidaOptional, ya que la matriz puede estar vacía y no podremos obtener el primer elemento de la matriz. Como resultado, tenemos un doble Optional, es decirInt?? .
Tenemos una estructura anidada Optionalen Optionalla que es realmente más difícil trabajar y que, naturalmente, no queremos tener. Para obtener el valor de esta estructura anidada, tenemos que "sumergirnos" en dos niveles. Además, cualquier transformación adicional puede profundizar Optionalaún más el nivel .Obtener el valor del doble anidado es Optionalrealmente oneroso.Tenemos 3 opciones y todas ellas requieren un conocimiento profundo del idioma Swift.if let , ; «» «» Optional , — «» Optional :

if case let ( pattern match ) :

?? :

- ,
switch :
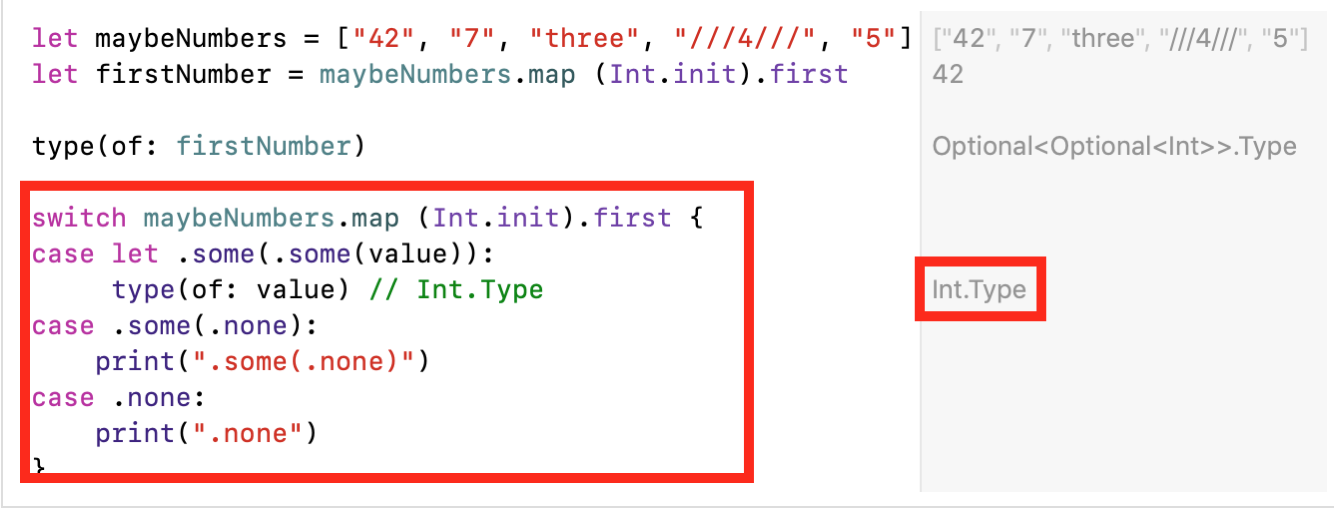
Peor aún, tales problemas de anidación genericcontenedores generalizados ( ) para los cuales se define una operación map. Por ejemplo, para matrices Array.Considere otro código de ejemplo. Supongamos que tenemos un texto de varias líneas multilineStringque queremos dividir en palabras escritas en minúsculas (pequeñas): let multilineString = """ , , ; , — , : — , . , , . . , , « » . , , ! """ let words = multilineString.lowercased() .split(separator: "\n") .map{$0.split(separator: " ")}
Para obtener una matriz de palabras words, primero hacemos letras mayúsculas (grandes) minúsculas (pequeñas) usando el método lowercased(), luego dividimos el texto en split(separatot: "\n")líneas usando el método y obtenemos una matriz de cadenas, y luego las usamos map {$0.split(separator: " ")}para separar cada línea en palabras separadas.Como resultado, obtenemos matrices anidadas: [["", ",", "", ","], ["", "", ";", "", "", "", "", ",", "—"], ["", ",", "", "", ":"], ["", "—", "", "", ",", "", "", "."], ["", "", ",", "", "", ","], ["", "", ".", "", ""], ["", ".", "", ",", ""], ["", "", "", ""], ["", "", ",", "", "«", "»"], ["", ".", "", ","], ["", ",", "", "", "!"]]
... y wordstiene Array: nuevamente obtuvimos una estructura de datos "anidada", pero esta vez no
nuevamente obtuvimos una estructura de datos "anidada", pero esta vez no Optional, pero Array. Si queremos continuar procesando las palabras recibidas words, por ejemplo, para encontrar el espectro de letras de este texto de varias líneas, primero tendremos que "enderezar" de alguna manera la matriz del doble Arrayy convertirla en una matriz única Array. Esto es similar a lo que hicimos con el doble Optionalpara una demostración al comienzo de esta sección sobre flatMap: let maybeNumbers = ["42", "7", "three", "///4///", "5"] let firstNumber = maybeNumbers.map (Int.init).first
Afortunadamente, Swiftno tenemos que recurrir a construcciones sintácticas complejas. Swiftnos proporciona una solución preparada para matrices Arrayy Optional. Esta es una función de orden superior flatMap! Es muy similar a map, pero tiene una funcionalidad adicional asociada con el "enderezado" posterior de los "archivos adjuntos" que aparecen durante la ejecución map. Y es por eso que se llama flatMap, "endereza" ( flattens) el resultado map.Intentemos aplicar flatMapa firstNumber: Realmente obtuvimos la salida con un solo nivel
Realmente obtuvimos la salida con un solo nivel Optional. Funcionaaún más interesante flatMappara una matriz Array. En nuestra expresión para, wordssimplemente reemplazamos mapconflatMap: ... y solo obtenemos una serie de palabras
... y solo obtenemos una serie de palabras wordssin ningún tipo de "anidamiento": ["", ",", "", ",", "", "", ";", "", "", "", "", ",", "—", "", ",", "", "", ":", "", "—", "", "", ",", "", "", ".", "", "", ",", "", "", ",", "", "", ".", "", "", "", ".", "", ",", "", "", "", "", "", "", "", ",", "", "«", "»", "", ".", "", ",", "", ",", "", "", "!"]
Ahora podemos continuar con el procesamiento que necesitamos de la matriz de palabras resultante words, pero tenga cuidado. Si lo aplicamos una vez más flatMapa cada elemento de la matriz words, obtendremos, tal vez, un resultado inesperado, pero bastante comprensible. Obtenemos una matriz única, no "anidada" de letras y símbolos
Obtenemos una matriz única, no "anidada" de letras y símbolos [Character]contenidos en nuestra frase de varias líneas: ["", "", "", "", "", "", "", "", "", "", "", "", ",", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", ",", "", "", "", "", "", "", "", "", "", "", "", "", "", "", ";", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", ...]
El hecho es que la cadena Stringes una colección de Collectioncaracteres [Character]y, aplicando flatMapa cada palabra individual, una vez más bajamos el nivel de "anidamiento" y llegamos a una serie de caracteres flattenCharacters.Tal vez esto es exactamente lo que quieres, o tal vez no. Presta atención a esto.Poniendo todo junto: resolviendo algunos problemas
TAREA 1
Podemos continuar el procesamiento que necesitamos de la matriz de palabras obtenida en la sección anterior words, y calcular la frecuencia de aparición de letras en nuestra frase de varias líneas. Primero, peguemos todas las palabras de la matriz wordsen una línea grande y excluyamos todos los signos de puntuación, es decir, deje solo las letras: let wordsString = words.reduce ("",+).filter { "" .contains($0)}
Entonces, tenemos todas las letras que necesitamos. Ahora hagamos un diccionario de ellos, donde la clave keyes la letra, y el valor valuees la frecuencia de su aparición en el texto.Podemos hacer esto de dos maneras.El primer método está asociado con el uso de una nueva Swift 4.2variedad de una función de orden superior que ha aparecido en reduce (into:, _:). Este método es bastante adecuado para que organicemos un diccionario letterCountcon la frecuencia de aparición de letras en nuestra frase de varias líneas: let letterCount = wordsString.reduce(into: [:]) { counts, letter in counts[letter, default: 0] += 1} print (letterCount)
Como resultado, obtendremos un diccionario letterCount [Character : Int]en el que las claves keyson los caracteres encontrados en la frase en estudio, y como el valor valuees el número de estos caracteres.El segundo método consiste en inicializar el diccionario usando la agrupación, que da el mismo resultado: let letterCountDictionary = Dictionary(grouping: wordsString ){ $0}.mapValues {$0.count} letterCount == letterCountDictionary
Nos gustaría ordenar el diccionario letterCountalfabéticamente: let lettersStat = letterCountDictionary .sorted(by: <) .map{"\($0.0):\($0.1)"} print (lettersStat)
Pero no podemos ordenar el diccionario directamente Dictionary, ya que fundamentalmente no es una estructura de datos ordenada. Si aplicamos la función sorted (by:)al diccionario Dictionary, nos devolverá los elementos de la secuencia ordenados con el predicado dado en forma de un conjunto de tuplas con nombre, que mapconvertiremos en un conjunto de cadenas que [":17", ":5", ":18", ...]reflejan la frecuencia de aparición de la letra correspondiente.Vemos que esta vez sorted (by:)solo el operador " <" se pasa como un predicado a una función de orden superior . La función sorted (by:)espera una "función de comparación" como único argumento en la entrada. Se utiliza para comparar dos valores adyacentes y decidir si están ordenados correctamente (en este caso, devuelvetrue) o no (devuelve false). Podemos dar a esta "función de comparación" funciones sorted (by:)en forma de cierre anónimo: sorted(by: {$0.key < $1.key}
Y podemos darle el operador " <", que tiene la firma que necesitamos, como se hizo anteriormente. Esta también es una función, y la clasificación por clave está en progreso key.Si queremos ordenar el diccionario por valores valuey descubrir qué letras se encuentran con más frecuencia en esta frase, entonces tendremos que usar el cierre para la función sorted (by:): let countsStat = letterCountDictionary .sorted(by: {$0.value > $1.value}) .map{"\($0.0):\($0.1)"} print (countsStat )
Si echamos un vistazo a la solución al problema de determinar el espectro de letras de una frase multilínea en su conjunto ... let multilineString = """ , , ; , — , : — , . , , . . , , « » . , , ! """ let words = multilineString.lowercased() .split(separator: "\n") .flatMap{$0.split(separator: " ")} let wordsString = words.reduce ("",+).filter { "" .contains($0)} let letterCount = wordsString.reduce(into: [:]) { counts, letter in counts[letter, default: 0] += 1} let lettersStat = letterCountDictionary .sorted(by: <) .map{"\($0.0):\($0.1)"} print (lettersStat)
... luego notaremos que en este fragmento de código básicamente no hay variables (no var, solo let)todos los nombres de las funciones utilizadas reflejan ACCIONES (funciones) en cierta información, sin preocuparse en absoluto de CÓMO se implementan estas acciones:split- dividir,map- transformarflatMap- transformar con alineación (mediante la eliminación de un nivel de anidamiento),filter- filtro,sorted- clasificación,reduce- para convertir los datos en una cierta estructura por medio de una operación específicaen este fragmento de cada línea de código explica el nombre de la función que usamos si estamos en. rellenos transformación "pura" se utiliza mapsi realizamos se utiliza la conversión del nivel de anidamientoflatMap, si queremos seleccionar solo ciertos datos, los usamos filter, etc. Todas estas funciones de "orden superior" están diseñadas y probadas Appleteniendo en cuenta la optimización del rendimiento. Entonces, este código es muy confiable y conciso: no necesitábamos más de 5 oraciones para resolver nuestro problema. Este es un ejemplo de programación funcional.El único inconveniente de aplicar el enfoque funcional en esta demostración es que, en aras de la inmutabilidad, la capacidad de prueba y la legibilidad, perseguimos repetidamente nuestro texto a través de varias funciones de orden superior. En el caso de una gran cantidad de artículos de colección, el Collectionrendimiento puede caer en picado. Por ejemplo, si primero usamos filter(_:)y, y luego - first.EnSwift 4 Se han agregado algunas opciones de funciones nuevas para mejorar el rendimiento, y aquí hay algunos consejos para escribir código más rápido.1. Uso contains, NOfirst( where: ) != nil
La verificación de que un objeto está en una colección Collectionse puede hacer de muchas maneras. El mejor rendimiento es proporcionado por la función contains.CÓDIGO CORRECTO let numbers = [0, 1, 2, 3] numbers.contains(1)
CÓDIGO INCORRECTO let numbers = [0, 1, 2, 3] numbers.filter { number in number == 1 }.isEmpty == false numbers.first(where: { number in number == 1 }) != nil
2. Use validación isEmpty, NO una comparación countcon cero
Dado que para algunas colecciones el acceso a la propiedad countse realiza iterando sobre todos los elementos de la colección.CÓDIGO CORRECTO let numbers = [] numbers.isEmpty
CÓDIGO INCORRECTO let numbers = [] numbers.count == 0
3. Verifique la cadena vacía StringconisEmpty
String Stringin Swiftes una colección de personajes [Character]. Esto significa que para cadenas también es Stringmejor usar isEmpty.CÓDIGO CORRECTO myString.isEmpty
CÓDIGO INCORRECTO myString == "" myString.count == 0
4. Obtener el primer elemento que satisface ciertas condiciones.
La iteración sobre toda la colección para obtener el primer objeto que satisfaga ciertas condiciones se puede realizar utilizando el método filterseguido por el método first, pero el método es el mejor en términos de velocidad first (where:). Este método deja de iterar sobre la colección tan pronto como cumple con la condición necesaria. El método filtercontinuará iterando sobre toda la colección, independientemente de si cumple con los elementos necesarios o no.Obviamente, lo mismo es cierto para el método last (where:).CÓDIGO CORRECTO let numbers = [3, 7, 4, -2, 9, -6, 10, 1] let firstNegative = numbers.first(where: { $0 < 0 })
CÓDIGO INCORRECTO let numbers = [0, 2, 4, 6] let allEven = numbers.filter { $0 % 2 != 0 }.isEmpty
A veces, cuando la colección Collectiones muy grande y el rendimiento es crítico para usted, vale la pena volver a comparar los enfoques imperativos y funcionales y elegir el que más le convenga.TAREA 2
Hay otro gran ejemplo de un uso muy conciso de una función de orden superior reduce (_:, _:)que he encontrado. Este es un juego SET .Aquí están sus reglas básicas. El nombre del juego SETproviene de la palabra inglesa "set" - "set". SET81 cartas participan en el juego , cada una con una imagen única: cada carta tiene 4 atributos, que se enumeran a continuación:Cantidad : cada carta tiene uno, dos o tres símbolos.Tipo de caracteres : óvalos, rombos u ondas.Color : los símbolos pueden ser rojos, verdes o morados.Relleno : los caracteres pueden estar vacíos, sombreados o sombreados.Propósito del juego.
cada carta tiene 4 atributos, que se enumeran a continuación:Cantidad : cada carta tiene uno, dos o tres símbolos.Tipo de caracteres : óvalos, rombos u ondas.Color : los símbolos pueden ser rojos, verdes o morados.Relleno : los caracteres pueden estar vacíos, sombreados o sombreados.Propósito del juego.SET: Entre las 12 cartas dispuestas sobre la mesa, debe encontrar SET(un conjunto) que consta de 3 cartas, en las que cada uno de los signos coincide completamente o difiere por completo en las 3 cartas. Todas las señales deben cumplir completamente con esta regla.Por ejemplo, el número de caracteres en las 3 cartas debe ser igual o diferente, el color en las 3 cartas debe ser igual o diferente, y así sucesivamente ...En este ejemplo, solo nos interesará el Modelo de mapa SET struct SetCardy el algoritmo para determinar SETpor 3er mapas isSet( cards:[SetCard]): struct SetCard: Equatable { let number: Variant
Los modelos cada característica - número number , tipo de símbolo shape , de color color y de llenado fill - presentados lista Variantque tiene tres valores posibles var1, var2y var3que corresponde a la 3ª enteros rawValue- 1,2,3. De esta forma, rawValuees fácil de operar. Si tomamos una indicación, por ejemplo color, a continuación, añadir todo rawValuede colors3 cartas, nos encontramos con que si colorslos 3 cartas son iguales, la cantidad será igual a 3, 6o 9, si son diferentes, entonces la cantidad será iguales 6. En cualquiera de estos casos, tenemos la multiplicidad de la tercera suma rawValueparacolorsLas 3 cartas. Sabemos que este es un requisito previo para lo que componen 3 cartas SET. Para que 3 cartas sean realmente SETnecesarias, para todos los signos SetCard(Cantidad number, Tipo de símbolo shape, Color colory Relleno fill) su suma debe rawValueser un múltiplo de la 3ra.Por lo tanto, en el staticmétodo, isSet( cards:[SetCard])primero calculamos la matriz sumsde las sumas rawValuepara todos los 3 mapas para todos mapa 4 rendimiento utilizando función de orden superior reducecon un valor inicial igual a 0, y la acumulación de funciones {$0 + $1.number.rawValue}, {$0 + $1.color.rawValue}, {$0 + $1.shape.rawValue}, { {$0 + $1.fill.rawValue}. Cada elemento de la matriz sumsdebe ser un múltiplo de 3er, y nuevamente usamos la funciónreduce, pero esta vez con un valor inicial igual truey que acumula la función lógica " AND" {$0 && ($1 % 3) == 0}. En Swift 5, para probar la multiplicidad de un número por otro, se introduce una función en isMultiply(of:)lugar del operador %restante. También mejorará la legibilidad del código: { $0 && ($1.isMultiply(of:3) }.Este código fantásticamente corto para descubrir si 3 SetCardcartas son las SETi-ésimas se obtiene gracias al enfoque " funcional ", y podemos asegurarnos de que funcione en Playground: Cómo
Cómo SETconstruir la interfaz de usuario ( UI) en este Modelo de juego aquí , aquí y aquí .Características puras y efectos secundarios.
Una función pura cumple dos condiciones. Siempre devuelve el mismo resultado con los mismos parámetros de entrada. Y el cálculo del resultado no causa efectos secundarios asociados con la salida de datos externos (por ejemplo, al disco) o con el préstamo de datos fuente del exterior (por ejemplo, el tiempo). Esto le permite optimizar significativamente el código.Este tema se Swiftexpone perfectamente en point.free en los primeros episodios de " Funciones " y " Efectos secundarios " , que se traducen al ruso y se presentan como " Funciones " y "Efectos secundarios" .Composición de la función
En un sentido matemático, esto significa aplicar una función al resultado de otra función. En una Swiftfunción, pueden devolver un valor que puede usar como entrada para otra función. Esta es una práctica de programación común.Imagine que tenemos una matriz de enteros y queremos obtener una matriz de cuadrados de números pares únicos en la salida. Por lo general, implementamos esto de la siguiente manera: var integerArray = [1, 2, 3, 4, 5, 6, 7, 8, 9, 1, 4, 5] func unique(_ array: [Int]) -> [Int] { return array.reduce(into: [], { (results, element) in if !results.contains(element) { results.append(element) } }) } func even(_ array: [Int]) -> [Int] { return array.filter{ $0%2 == 0} } func square(_ array: [Int]) -> [Int] { return array.map{ $0*$0 } } var array = square(even(unique(integerArray)))
Este código nos da el resultado correcto, pero ve que la legibilidad de la última línea de código no es tan fácil. La secuencia de funciones (de derecha a izquierda) es la opuesta a la que estamos acostumbrados (de izquierda a derecha) y nos gustaría ver aquí. Necesitamos dirigir nuestra lógica primero a la parte más interna de las incrustaciones múltiples: a una matriz inegerArray, luego a una función externa a esta matriz unique, luego subimos un nivel más: una función eveny, finalmente, una función en conclusión square.Y aquí la "composición" de funciones >>>y operadores nos ayuda |>, lo que nos permite escribir el código de una manera muy conveniente, representando el procesamiento de la matriz original integerArraycomo un "transportador" de funciones: var array1 = integerArray |> unique >>> even >>> square
Casi todos los lenguajes de programación tales como funcional especializada F#, Elixiry Elmutilizar estos operadores para las funciones de "composición".No Swifthay operadores integrados de la "composición" de funciones >>>y |>, pero podemos obtenerlos fácilmente con la ayuda de Genericsclosures ( closure) y el infixoperador: precedencegroup ForwardComposition{ associativity: left higherThan: ForwardApplication } infix operator >>> : ForwardComposition func >>> <A, B, C>(left: @escaping (A) -> B, right: @escaping (B) -> C) -> (A) -> C { return { right(left($0)) } } precedencegroup ForwardApplication { associativity: left } infix operator |> : ForwardApplication func |> <A, B>(a: A, f: (A) -> B) -> B { return f(a) }
A pesar de los costos adicionales, en algunos casos esto puede aumentar significativamente el rendimiento, la legibilidad y la capacidad de prueba de su código. Por ejemplo, cuando dentro de mapusted coloca una cadena completa de funciones utilizando el operador "composición" en >>>lugar de perseguir una matriz a través de numerosos map: var integerArray1 = [1, 2, 3, 4, 5, 6, 7, 8, 9, 1, 4, 5] let b = integerArray1.map( { $0 + 1 } >>> { $0 * 3 } >>> String.init) print (b)
Pero no siempre un enfoque funcional da un efecto positivo.Al principio, cuando apareció Swiften 2014, todos se apresuraron a escribir bibliotecas con operadores para la "composición" de funciones y resolver una tarea difícil para ese momento, como analizar JSONusando operadores de programación funcional en lugar de usar construcciones infinitamente anidadas if let. Yo mismo traduje el artículo sobre el análisis funcional JSON que me deleitó con su elegante solución y era fanático de la biblioteca Argo .Pero los desarrolladores Swifttomaron un camino completamente diferente y propusieron, sobre la base de la tecnología orientada al protocolo, una forma mucho más concisa de escribir código. Para "entregar" los JSONdatos directamente aCodable, que implementa automáticamente este protocolo, si el modelo se compone de las conocidas Swiftestructuras de datos: String, Int, URL, Array, Dictionary, etc. struct Blog: Codable { let id: Int let name: String let url: URL }
Tener JSONdatos de ese famoso artículo ... [ { "id" : 73, "name" : "Bloxus test", "url" : "http://remote.bloxus.com/" }, { "id" : 74, "name" : "Manila Test", "url" : "http://flickrtest1.userland.com/" } ]
... en este momento solo necesita una línea de código para obtener una variedad de blogs blogs: let blogs = Bundle.main.path(forResource: "blogs", ofType: "json") .map(URL.init(fileURLWithPath:)) .flatMap { try? Data.init(contentsOf: $0) } .flatMap { try? JSONDecoder().decode([Blog].self, from: $0) } print ("\(blogs!)")
Todo el mundo se ha olvidado de usar los operadores de la "composición" de funciones para analizar JSON, si hay otra manera más fácil y comprensible de hacerlo mediante protocolos.Si todo es tan fácil, entonces podemos "subir" JSONdatos a modelos más complejos. Supongamos que tenemos un archivo de JSONdatos que tiene un nombre user.jsony se encuentra en nuestro directorio Resources.. Contiene datos sobre un usuario: { "email": "blob@pointfree.co", "id": 42, "name": "Blob" }
Y tenemos un Codable Usercon un inicializador de los datos json: struct User: Codable { let email: String let id: Int let name: String init?(json: Data) { if let newValue = try? JSONDecoder().decode(User.self, from: json) { self = newValue } else { return nil } } }
Podemos obtener fácilmente un nuevo usuario newUsercon un código funcional aún más simple: let newUser = Bundle.main.path(forResource: "user", ofType: "json") .map(URL.init(fileURLWithPath:)) .flatMap { try? Data.init(contentsOf: $0) } .flatMap { User.init(json: $0) }
Obviamente, newUserhabrá un TIPO Optional, es decir User?: supongamos que en nuestro directorio
supongamos que en nuestro directorio Resourceshay otro archivo con un nombre invoices.jsony contiene datos sobre las facturas de este usuario. [ { "amountPaid": 1000, "amountDue": 0, "closed": true, "id": 1 }, { "amountPaid": 500, "amountDue": 500, "closed": false, "id": 2 } ]
Podemos cargar estos datos exactamente como lo hicimos con User. Definamos la estructura como un modelo de factura struct Invoice... struct Invoice: Codable { let amountDue: Int let amountPaid: Int let closed: Bool let id: Int }
... y decodifica la JSONmatriz de facturas presentada anteriormente invoices, cambiando solo la ruta del archivo y la lógica de decodificación decode: let invoices = Bundle.main.path(forResource: "invoices", ofType: "json") .map( URL.init(fileURLWithPath:) ) .flatMap { try? Data.init(contentsOf: $0) } .flatMap { try? JSONDecoder().decode([Invoice].self, from: $0) }
invoicesserá [Invoice]?: Ahora nos gustaría conectar al usuario
Ahora nos gustaría conectar al usuario usercon sus facturas invoices, si no son iguales nil, y guardar, por ejemplo, en la estructura del sobre UserEnvelopeque se envía al usuario junto con sus facturas: struct UserEnvelope { let user: User let invoices: [Invoice] }
En lugar de actuar dos veces if let... if let newUser = newUser, let invoices = invoices { }
... escribamos un análogo funcional del doble if letcomo una Genericfunción auxiliar zipque convierte dos Optionalvalores en una Optionaltupla: func zip<A, B>(_ a: A?, _ b: B?) -> (A, B)? { if let a = a, let b = b { return (a, b) } return nil }
¡Ahora no tenemos ninguna razón para asignar algo a las variables newUsery invoices, simplemente construimos todo en nuestra nueva función zip, usamos el inicializador UserEnvelope.inity todo funcionará! let userEnv = zip( Bundle.main.path(forResource: "user", ofType: "json") .map(URL.init(fileURLWithPath:)) .flatMap { try? Data.init(contentsOf: $0) } .flatMap { User.init(json: $0) }, Bundle.main.path(forResource: "invoices", ofType: "json") .map(URL.init(fileURLWithPath:)) .flatMap { try? Data.init(contentsOf: $0) } .flatMap { try? JSONDecoder().decode([Invoice].self, from: $0) } ).flatMap (UserEnvelope.init) print ("\(userEnv!)")
En una sola expresión, se empaqueta un algoritmo completo para entregar JSONdatos a uno complejo struct UserEnvelope.zip , , . user , JSON , invoices , JSON . .map , , «» .flatMap , , , .
Operaciones zip, mapy flatMaprepresentan un tipo de lenguaje específico de dominio (DSL) para la conversión de datos.Podemos desarrollar aún más esta demostración para representar la lectura asíncrona del contenido de un archivo como una función especial que puede ver en pointfree.co .No soy un fanático de la programación funcional en todas partes y en todo, pero me parece aconsejable su uso moderado.Conclusión
Di ejemplos de varios programación funcional dispone de Swft «fuera de la caja", basado en el uso de funciones de orden superior map, flatMap, reduce, filtery el otro para las secuencias Sequence, Optionaly Result. Pueden ser los "caballos de batalla" de la creación de código, ,especialmente si las structy las enumeraciones están involucradas allí enum. Un desarrollador de iOSaplicaciones debe poseer esta herramienta.Todas las demos compiladas Playgroundse pueden encontrar en Github . Si tiene problemas con el lanzamiento Playground, puede ver este artículo:Cómo deshacerse de los errores de "congelación" de Xcode Playground con los mensajes "Launching Simulator" y "Running Playground".Referencias
Functional Programming in Swift: An Introduction.An Introduction to Functional Programming in Swift.The Many Faces of Flat-Map: Part 3Inside the Standard Library: Sequence.map()Practical functional programming in Swift