Los autores son John Hennessey y David Patterson, ganadores del Premio Turing 2017 "por un enfoque innovador sistemático y medible para el diseño y verificación de arquitecturas informáticas que han tenido un impacto duradero en toda la industria de los microprocesadores". Artículo publicado en Communications of the ACM, febrero de 2019, Volumen 62, No. 2, pp. 48-60, doi: 10.1145 / 3282307 "Los que no recuerdan el pasado están condenados a repetirlo"
"Los que no recuerdan el pasado están condenados a repetirlo" - George Santayana, 1905
Comenzamos nuestra
conferencia de Turing el 4 de junio de 2018 con una revisión de la arquitectura de computadoras a partir de los años 60. Además de él, destacamos los problemas actuales e intentamos identificar oportunidades futuras que prometen una nueva era dorada en el campo de la arquitectura de computadoras en la próxima década. Lo mismo que en la década de 1980, cuando realizamos nuestra investigación para mejorar el costo, la eficiencia energética, la seguridad y el rendimiento de los procesadores, por lo que recibimos este honorable premio.
Ideas clave
- El progreso del software puede impulsar la innovación arquitectónica
- Aumentar el nivel de las interfaces de software y hardware crea oportunidades para la innovación arquitectónica.
- El mercado finalmente determina el ganador en la disputa de arquitectura
El software "habla" con el equipo a través de un diccionario llamado "arquitectura del conjunto de instrucciones" (ISA). A principios de la década de 1960, IBM tenía cuatro series de computadoras incompatibles, cada una con su propio ISA, pila de software, sistema de E / S y nicho de mercado, orientado a pequeñas empresas, grandes empresas, aplicaciones científicas y sistemas en tiempo real, respectivamente. Los ingenieros de IBM, incluido el ganador del Premio Turing, Frederick Brooks Jr., decidieron crear un ISA único que efectivamente une a los cuatro.
Necesitaban una solución técnica sobre cómo proporcionar un ISA igualmente rápido para computadoras con buses de 8 y 64 bits. En cierto sentido, los autobuses son los "músculos" de las computadoras: hacen el trabajo, pero son relativamente fáciles de "comprimir" y "expandir". Entonces y ahora el mayor desafío para los diseñadores es el "cerebro" del equipo de control del procesador. Inspirado por la programación, Maurice Wilkes, pionero en informática y ganador del Premio Turing, propuso opciones para simplificar este sistema. El control se presentó como una matriz bidimensional, a la que llamó el "almacén de control" (almacén de control).
Cada columna de la matriz correspondía a una línea de control, cada fila era microinstrucción y el registro de microinstrucciones se llamaba microprogramación . La memoria de control contiene un intérprete ISA escrito por microinstrucciones, por lo que la ejecución de una instrucción normal requiere varias microinstrucciones. La memoria de control se implementa, de hecho, en la memoria, y es mucho más barata que los elementos lógicos.
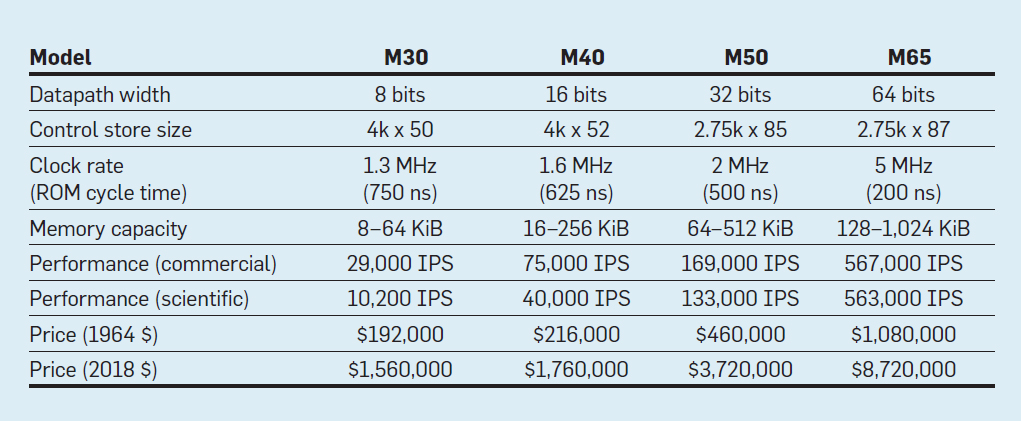 Características de los cuatro modelos de la familia IBM System / 360; IPS significa operaciones por segundo
Características de los cuatro modelos de la familia IBM System / 360; IPS significa operaciones por segundoLa tabla muestra cuatro modelos del nuevo ISA en System / 360 de IBM, presentado el 7 de abril de 1964. Los buses difieren en 8 veces, la capacidad de memoria es de 16, la velocidad del reloj es de casi 4, el rendimiento es de 50 y el costo es de casi 6. Las computadoras más caras tienen la memoria de control más extensa, porque los buses de datos más complejos utilizan más líneas de control . Las computadoras más baratas tienen menos memoria de control debido a un hardware más simple, pero necesitaban más microinstrucciones, ya que necesitaban más ciclos de reloj para ejecutar la instrucción System / 360.
Gracias a la microprogramación, IBM ha apostado a que la nueva ISA revolucionará la industria informática y ganó la apuesta. IBM dominaba sus mercados, y los descendientes de los viejos mainframes IBM de 55 años todavía generan $ 10 mil millones en ingresos anualmente.
Como se ha señalado repetidamente, aunque el mercado es un árbitro imperfecto como tecnología, pero dados los estrechos vínculos entre la arquitectura y las computadoras comerciales, en última instancia determina el éxito de las innovaciones arquitectónicas, que a menudo requieren una importante inversión en ingeniería.
Circuitos integrados, CISC, 432, 8086, PC IBM
Cuando las computadoras cambiaron a circuitos integrados, la ley de Moore significaba que la memoria de control podría hacerse mucho más grande. A su vez, esto permitió una ISA mucho más compleja. Por ejemplo, la memoria de control VAX-11/780 de Digital Equipment Corp. en 1977, tenía 5120 palabras en 96 bits, mientras que su predecesor usó solo 256 palabras en 56 bits.
Algunos fabricantes han habilitado el firmware para clientes seleccionados que pueden haber agregado funciones personalizadas. Esto se llama el almacén de control de escritura (WCS). La computadora WCS más famosa fue
Alto , que los ganadores del Premio Turing Chuck Tucker y Butler Lampson y sus colegas crearon para el Centro de Investigación Xerox Palo Alto en 1973. Realmente fue la primera computadora personal: aquí está la primera pantalla con imágenes elemento por elemento y la primera red Ethernet local. Los controladores para la innovadora pantalla y tarjeta de red eran microprogramas que se almacenan en el WCS con una capacidad de 4096 palabras en 32 bits.
En los años 70, los procesadores seguían siendo de 8 bits (por ejemplo, Intel 8080) y se programaban principalmente en ensamblador. Los competidores agregaron nuevas instrucciones para superarse mutuamente, mostrando sus logros con ejemplos de ensamblador.
Gordon Moore creía que el próximo ISA de Intel duraría para siempre para la compañía, por lo que contrató a muchos doctores inteligentes en informática y los envió a una nueva instalación en Portland para inventar el próximo gran ISA. El procesador 8800, como Intel lo llamó originalmente, se ha convertido en un proyecto de arquitectura de computadora absolutamente ambicioso para cualquier época, por supuesto, fue el proyecto más agresivo de los años 80. Incluía direccionamiento basado en capacidades de 32 bits, una arquitectura orientada a objetos, instrucciones de longitud variable y su propio sistema operativo en el nuevo lenguaje de programación Ada.
Desafortunadamente, este ambicioso proyecto requirió varios años de desarrollo, lo que obligó a Intel a lanzar un proyecto de respaldo de emergencia en Santa Clara para lanzar rápidamente un procesador de 16 bits en 1979. Intel le dio al nuevo equipo 52 semanas para desarrollar el nuevo ISA "8086", diseñar y construir el chip. Dado un calendario apretado, el diseño de ISA tomó solo 10 semanas-persona por tres semanas calendario regulares, principalmente debido a la expansión de registros de 8 bits y un conjunto de instrucciones 8080 a 16 bits. El equipo completó 8086 según lo programado, pero este procesador hecho a prueba de fallas se anunció sin mucha fanfarria.
Intel tuvo mucha suerte de que IBM estuviera desarrollando una computadora personal para competir con la Apple II y necesitara un microprocesador de 16 bits. IBM estaba mirando el Motorola 68000 con un ISA similar al IBM 360, pero estaba atrasado en el agresivo cronograma de IBM. En cambio, IBM cambió a la versión de 8 bits del bus 8086. Cuando IBM anunció la PC el 12 de agosto de 1981, esperaba vender 250,000 computadoras para 1986. En cambio, la compañía vendió 100 millones en todo el mundo, presentando un futuro muy prometedor para la ISA de emergencia de Intel.
El proyecto original Intel 8800 pasó a llamarse iAPX-432. Finalmente, se anunció en 1981, pero requirió varios chips y tuvo serios problemas de rendimiento. Se completó en 1986, un año después de que Intel expandió el ISA 8086 de 16 bits a 80386, aumentando los registros de 16 bits a 32 bits. Por lo tanto, la predicción de Moore con respecto a la ISA resultó ser correcta, pero el mercado eligió el 8086 hecho por la mitad, en lugar del ungido iAPX-432. Como se dieron cuenta los arquitectos de los procesadores Motorola 68000 e iAPX-432, el mercado rara vez puede mostrar paciencia.
De conjunto de instrucciones complejo a abreviado
A principios de la década de 1980, se realizaron varios estudios de computadoras con un conjunto de instrucciones complejas (CISC): tienen grandes microprogramas en una gran memoria de control. Cuando Unix demostró que incluso el sistema operativo se puede escribir en un lenguaje de alto nivel, la pregunta principal fue: "¿Qué instrucciones generarán los compiladores?" en lugar del anterior "¿Qué ensamblador usarán los programadores?" Un aumento significativo en el nivel de la interfaz hardware-software ha creado una oportunidad para la innovación en arquitectura.
El ganador del Premio Turing, John Kokk, y sus colegas han desarrollado compiladores de minicomputadoras e ISA más simples. Como experimento, reorientaron sus compiladores de investigación para usar el IBM 360 ISA para usar solo operaciones simples entre registros y cargar con memoria, evitando instrucciones más complejas. Notaron que los programas se ejecutan tres veces más rápido si usan un subconjunto simple. Emer y Clark
descubrieron que el 20% de las instrucciones VAX ocupan el 60% del microcódigo y solo toman el 0.2% del tiempo de ejecución. Un autor de este artículo (Patterson) pasó unas vacaciones creativas en DEC, ayudando a reducir los errores en el microcódigo VAX. Si los fabricantes de microprocesadores iban a seguir los diseños de ISA con un conjunto de comandos complejos de CISC en computadoras grandes, esperaban una gran cantidad de errores de microcódigo y querían encontrar una manera de solucionarlos. Escribió
un artículo así , pero
la revista
Computer lo rechazó. Los revisores sugirieron que la terrible idea de construir microprocesadores con ISA es tan compleja que necesitan repararse en el campo. Esta falla arroja dudas sobre el valor de CISC para los microprocesadores. Irónicamente, los microprocesadores CISC modernos incluyen mecanismos de recuperación de microcódigo, pero la negativa a publicar el artículo inspiró al autor a desarrollar un ISA menos complejo para microprocesadores: computadoras con un conjunto de instrucciones reducido (RISC).
Estos comentarios y la transición a lenguajes de alto nivel permitieron la transición de CISC a RISC. Primero, las instrucciones RISC se simplifican, por lo que no hay necesidad de un intérprete. Las instrucciones RISC suelen ser simples como microinstrucciones y pueden ejecutarse directamente por hardware. En segundo lugar, la memoria rápida que se utilizó anteriormente para el intérprete de microcódigo CISC se rediseñó en la memoria caché de instrucciones RISC (la memoria caché es una memoria pequeña y rápida que almacena las instrucciones ejecutadas recientemente, ya que es probable que dichas instrucciones se reutilicen en un futuro próximo). En tercer lugar,
los asignadores de registros basados en el esquema de colores del gráfico de Gregory Chaitin facilitaron en gran medida el uso eficiente de registros para compiladores, que se beneficiaron de estas NIA con operaciones de registro a registro. Finalmente, la ley de Moore condujo al hecho de que en la década de 1980 había suficientes transistores en un chip para acomodar un bus completo de 32 bits en un solo chip, junto con cachés para instrucciones y datos.
Por ejemplo, en la fig. La Figura 1 muestra los microprocesadores
RISC-I y
MIPS desarrollados en la Universidad de California en Berkeley y la Universidad de Stanford en 1982 y 1983, que demostraron los beneficios de RISC. Como resultado, en 1984 estos procesadores se presentaron en la conferencia líder sobre diseño de circuitos, la Conferencia Internacional de Circuitos de Estado Sólido IEEE (
1 ,
2 ). Fue un momento maravilloso cuando varios estudiantes graduados en Berkeley y Stanford crearon microprocesadores que excedieron las capacidades de la industria de esa época.
 Fig. 1. Procesadores RISC-I de la Universidad de California en Berkeley y MIPS de la Universidad de Stanford
Fig. 1. Procesadores RISC-I de la Universidad de California en Berkeley y MIPS de la Universidad de StanfordEsos chips académicos inspiraron a muchas compañías a crear microprocesadores RISC, que fueron los más rápidos en los próximos 15 años. La explicación está relacionada con la siguiente fórmula de rendimiento del procesador:
Tiempo / Programa = (Instrucciones / Programa) × (medidas / instrucción) × (tiempo / medida)Más tarde, los ingenieros de DEC
demostraron que para un programa, los CISC más complejos requieren el 75% del número de instrucciones RISC (el primer término en la fórmula), pero en una tecnología similar (tercer término) cada instrucción CISC toma 5-6 ciclos más (segundo término), que hace que los microprocesadores RISC sean aproximadamente 4 veces más rápidos.
No existían tales fórmulas en la literatura informática de los años 80, lo que nos hizo escribir el libro
Computer Architecture: A Quantitective Approach en 1989. El subtítulo explica el tema del libro: usar medidas y puntos de referencia para cuantificar las compensaciones, en lugar de confiar en la intuición y la experiencia del diseñador, como en el pasado. Nuestro enfoque cuantitativo también se inspiró en lo que hizo el
libro de Turing Laureate Donald Knuth para algoritmos.
VLIW, EPIC, Itanium
Se suponía que el próximo ISA innovador superaría el éxito de RISC y CISC. La
arquitectura de instrucciones de máquina muy larga
VLIW y su primo EPIC (Computación con paralelismo explícito de instrucciones de máquina) de Intel y Hewlett-Packard utilizaron instrucciones largas, cada una de las cuales consistía en varias operaciones independientes unidas entre sí. Los partidarios de VLIW y EPIC en ese momento creían que si una instrucción pudiera indicar, por ejemplo, seis operaciones independientes (dos transferencias de datos, dos operaciones de enteros y dos operaciones de punto flotante) y la tecnología del compilador podría asignar eficientemente operaciones a seis ranuras de instrucciones, entonces el equipo se puede simplificar. Similar al enfoque de RISC, VLIW y EPIC transfirieron el trabajo del hardware al compilador.
Juntos, Intel y Hewlett-Packard han desarrollado un procesador basado en EPIC de 64 bits para reemplazar la arquitectura x86 de 32 bits. Se fijaron grandes expectativas en el primer procesador EPIC llamado Itanium, pero la realidad no se correspondía con las primeras declaraciones de los desarrolladores. Aunque el enfoque EPIC funcionó bien para programas de punto flotante altamente estructurados, no pudo lograr un alto rendimiento para programas enteros con ramificaciones menos perdidas y menos predecibles. Como Donald Knuth
señaló más tarde: "Se suponía que Itanium era ... increíble, hasta que resultó que los compiladores deseados eran básicamente imposibles de escribir". Los críticos notaron retrasos en el lanzamiento de Itanium y lo denominaron Itanik en honor al desafortunado barco de pasajeros Titanic. El mercado nuevamente no mostró paciencia y adoptó la versión de 64 bits de x86, y no Itanium, como el sucesor.
La buena noticia es que VLIW sigue siendo adecuado para aplicaciones más especializadas que ejecutan pequeños programas con ramas más simples sin errores de caché, incluido el procesamiento de señales digitales.
RISC vs. CISC en la era de PC y Post-PC
AMD e Intel necesitaban 500 equipos de diseño y tecnología de semiconductores superior para cerrar la brecha de rendimiento entre x86 y RISC. Nuevamente, en aras del rendimiento logrado a través de la canalización, un decodificador de instrucciones sobre la marcha traduce instrucciones complejas x86 en microinstrucciones internas tipo RISC. AMD e Intel luego crean una tubería para su implementación. Cualquier idea que los diseñadores de RISC usaran para mejorar el rendimiento (cachés de instrucciones e información separadas, cachés de segundo nivel en el chip, una tubería profunda y la recepción y ejecución simultánea de varias instrucciones) se incluyeron en x86. En la cima de la era de las computadoras personales en 2011, AMD e Intel enviaron alrededor de 350 millones de microprocesadores x86 anualmente. Los altos volúmenes y los bajos márgenes de la industria también significaron precios más bajos que las computadoras RISC.
Con cientos de millones de computadoras vendidas anualmente, el software se ha convertido en un gran mercado. Si bien los proveedores de software de Unix tuvieron que lanzar diferentes versiones de software para diferentes arquitecturas RISC (Alpha, HP-PA, MIPS, Power y SPARC), las computadoras personales tenían un ISA, por lo que los desarrolladores lanzaron software "reducido" que era compatible binariamente solo con la arquitectura x86. Debido a su base de software mucho más grande, rendimiento similar y precios más bajos, para el año 2000 la arquitectura x86 dominaba los mercados de escritorios y servidores pequeños.
Apple ayudó a marcar el comienzo de la era posterior a la PC con el iPhone en 2007. En lugar de comprar microprocesadores, las compañías de teléfonos inteligentes crearon sus propios sistemas en un chip (SoC) utilizando los desarrollos de otras personas, incluidos los procesadores RISC de ARM. Aquí, los diseñadores son importantes no solo en el rendimiento, sino también en el consumo de energía y el área de chips, lo que pone en desventaja la arquitectura CISC. Además, Internet de las cosas ha aumentado significativamente tanto el número de procesadores como las compensaciones necesarias en tamaño de chip, potencia, costo y rendimiento. Esta tendencia ha aumentado la importancia del tiempo de diseño y el costo, empeorando aún más la posición de los procesadores CISC. En la era actual posterior a la PC, los envíos anuales x86 han caído casi un 10% desde el pico de 2011, mientras que los chips RISC se han disparado a 20 mil millones. Hoy, el 99% de los procesadores de 32 y 64 bits en el mundo son RISC.
Concluyendo esta revisión histórica, podemos decir que el mercado ha resuelto la disputa entre RISC y CISC. Aunque CISC ganó las etapas posteriores de la era de la PC, RISC gana ahora que ha llegado la era posterior a la PC. No hay nuevas ISA en CISC durante décadas. Para nuestra sorpresa, el consenso general sobre los mejores principios ISA para los procesadores de propósito general de hoy todavía está a favor de RISC, 35 años después de su invención.
Retos modernos para la arquitectura del procesador
"Si un problema no tiene una solución, tal vez no sea un problema, sino un hecho con el que deberías aprender a vivir" - Shimon Peres
Aunque la sección anterior se centró en el desarrollo de una arquitectura de conjunto de instrucciones (ISA), la mayoría de los diseñadores de la industria no desarrollan nuevas ISA, sino que integran las ISA existentes en la tecnología de fabricación existente.
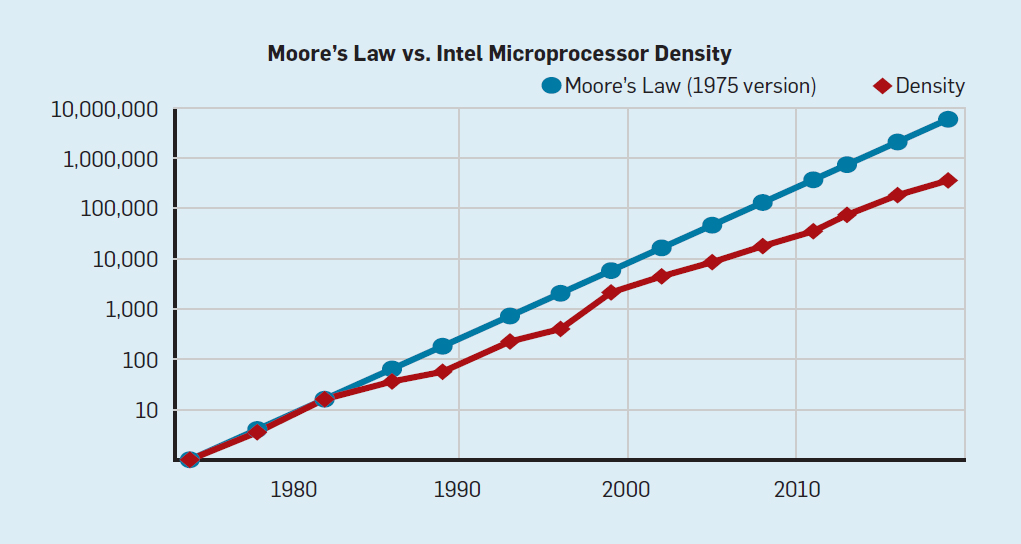
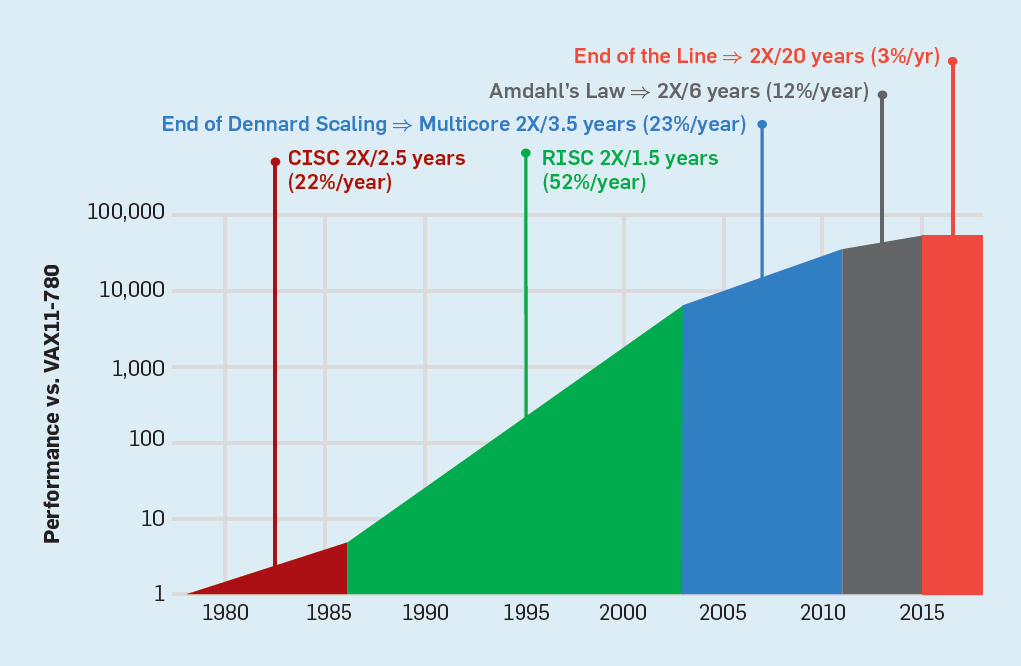
Desde finales de los años 70, la tecnología predominante ha sido los circuitos integrados en estructuras MOS (MOS), primero tipo n (nMOS) y luego complementario (CMOS). El sorprendente ritmo de mejora en la tecnología MOS, capturado por las predicciones de Gordon Moore, fue la fuerza impulsora que permitió a los diseñadores desarrollar métodos más agresivos para lograr el rendimiento de una determinada ISA. La predicción inicial de Moore en 1965 preveía una duplicación anual de la densidad del transistor; en 1975, lo revisó , prediciendo una duplicación cada dos años. Al final, este pronóstico comenzó a llamarse la ley de Moore. Dado que la densidad de los transistores crece cuadráticamente y la velocidad crece linealmente, el uso de más transistores puede aumentar la productividad.(. . 2), - 2000 , 2018 15-. 2003
, . , CMOS .
 . 2. Intel
. 2. Intel,
« »que a medida que aumenta la densidad de los transistores, el consumo de energía del transistor disminuirá, por lo que el consumo por mm² de silicio será casi constante. A medida que la potencia informática de un milímetro de silicio crecía con cada nueva generación de tecnología, las computadoras se volvieron más eficientes energéticamente. La escala de Dennard comenzó a disminuir significativamente en 2007, y en 2012 prácticamente no había llegado a nada (ver Fig. 3).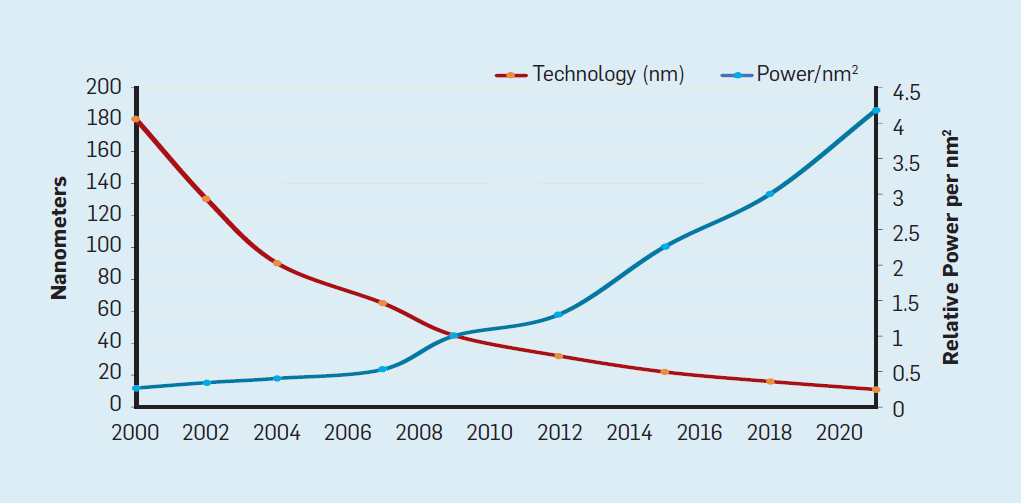 Fig. 3. El número de transistores por chip y el consumo de energía por mm²De 1986 a 2002, la concurrencia de nivel de instrucción (ILP) fue el principal método arquitectónico para aumentar la productividad. Junto con el aumento de la velocidad de los transistores, esto dio un aumento anual en la productividad de aproximadamente el 50%. El final de la escala de Dennard significaba que los arquitectos tenían que encontrar mejores formas de usar la concurrencia.
Fig. 3. El número de transistores por chip y el consumo de energía por mm²De 1986 a 2002, la concurrencia de nivel de instrucción (ILP) fue el principal método arquitectónico para aumentar la productividad. Junto con el aumento de la velocidad de los transistores, esto dio un aumento anual en la productividad de aproximadamente el 50%. El final de la escala de Dennard significaba que los arquitectos tenían que encontrar mejores formas de usar la concurrencia., ILP , ARM, Intel AMD. , 15- . , 60 , 15 , 25% . , , . — ILP, . , — — , , . , , .
Para comprender cuán complejo es un diseño de este tipo, imagine la dificultad de predecir correctamente los resultados de 15 ramas. Si el diseñador del procesador establece un límite de pérdida del 10%, el procesador debe predecir correctamente cada rama con una precisión del 99,3%. No hay muchos programas de sucursal de propósito general que puedan predecirse con tanta precisión., , . 4, , , , . SPEC Intel Core i7 19% . , , .
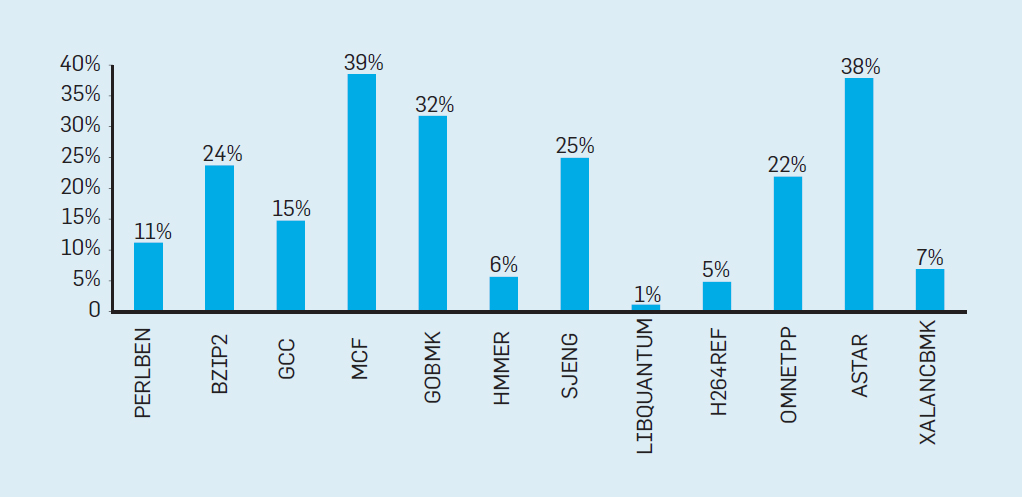 .4. , Intel Core i7 SPEC
.4. , Intel Core i7 SPEC, . .
En este concepto, la responsabilidad de identificar la concurrencia y decidir cómo usarla se transfiere al programador y al sistema de lenguaje. Multinúcleo no resuelve el problema de la computación eficiente en energía, que se agravó al final de la escala de Dennard. Cada núcleo activo consume energía, independientemente de si está involucrado en cálculos eficientes. El obstáculo principal es una vieja observación llamada ley de Amdahl. Dice que los beneficios de la computación paralela están limitados por la fracción de la computación secuencial. Para evaluar la importancia de esta observación, considere la Figura 5. Muestra cuánto más rápido funciona la aplicación con 64 núcleos en comparación con un núcleo, suponiendo una proporción diferente de cálculos secuenciales cuando solo un procesador está activo. Por ejemploSi el 1% de las veces el cálculo se realiza de forma secuencial, la ventaja de la configuración de 64 procesadores es solo del 35%. Desafortunadamente, el consumo de energía es proporcional a 64 procesadores, por lo que aproximadamente el 45% de la energía se desperdicia.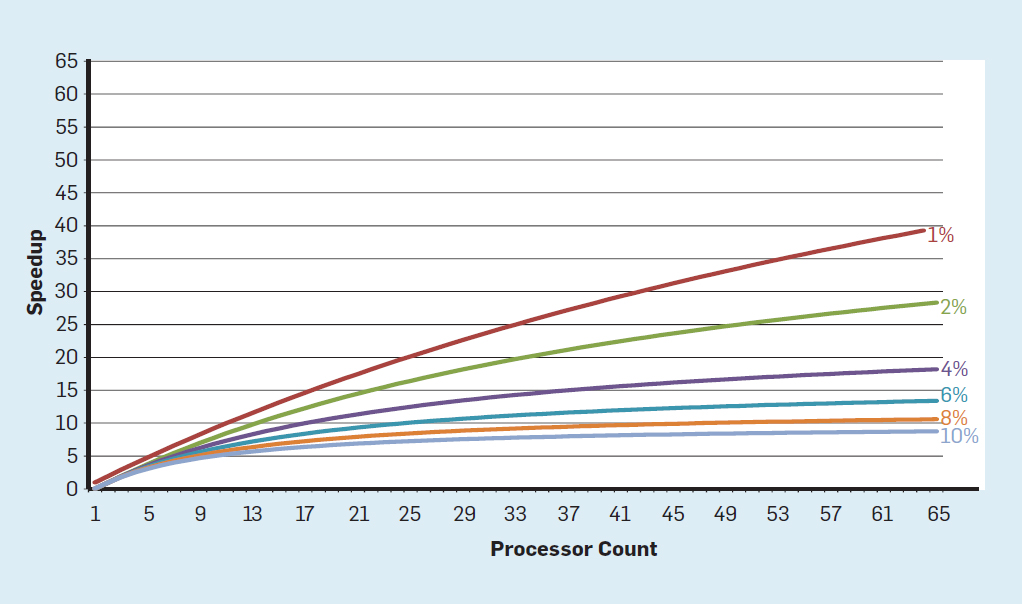 Fig. 5. El efecto de la ley de Amdahl sobre el aumento de la velocidad, teniendo en cuenta la proporción de medidas en modo secuencial.Por supuesto, los programas reales tienen una estructura más compleja. Hay fragmentos que le permiten usar un número diferente de procesadores en un momento dado. Sin embargo, la necesidad de interactuar periódicamente y sincronizarlos significa que la mayoría de las aplicaciones tienen algunas partes que solo pueden usar de manera eficiente parte de los procesadores. Aunque la ley de Amdahl tiene más de 50 años, sigue siendo un obstáculo difícil.
Fig. 5. El efecto de la ley de Amdahl sobre el aumento de la velocidad, teniendo en cuenta la proporción de medidas en modo secuencial.Por supuesto, los programas reales tienen una estructura más compleja. Hay fragmentos que le permiten usar un número diferente de procesadores en un momento dado. Sin embargo, la necesidad de interactuar periódicamente y sincronizarlos significa que la mayoría de las aplicaciones tienen algunas partes que solo pueden usar de manera eficiente parte de los procesadores. Aunque la ley de Amdahl tiene más de 50 años, sigue siendo un obstáculo difícil., . , . , (TDP) , . - , , . TDP « » (dark silicon), , . , .
, , , (. . 6).
 . 6. (SPECintCPU)
. 6. (SPECintCPU)— 80- 90- — , . , — .
En los años 70, los desarrolladores de procesadores garantizaron diligentemente la seguridad de la computadora con la ayuda de varios conceptos, que van desde anillos protectores hasta funciones especiales. Entendieron bien que la mayoría de los errores estarían en el software, pero creían que el soporte arquitectónico podría ayudar. Estas características no fueron utilizadas principalmente por sistemas operativos que funcionaban en entornos supuestamente seguros (como las computadoras personales). Por lo tanto, las funciones asociadas con una sobrecarga significativa han sido eliminadas. En la comunidad del software, muchos creían que las pruebas formales y los métodos como el uso de un microkernel proporcionarían mecanismos efectivos para crear software altamente seguro. Desafortunadamente, la escala de nuestros sistemas de software comunes y la búsqueda del rendimiento significaron que dichos métodos no podían mantenerse al día con el rendimiento. Como resultado, los grandes sistemas de software todavía tienen muchas fallas de seguridad, y el efecto se amplifica debido a la enorme y creciente cantidad de información personal en Internet y al uso de la computación en la nube, donde los usuarios comparten el mismo equipo físico con un atacante potencial.
Aunque los diseñadores de procesadores y otros pueden no haberse dado cuenta de la creciente importancia de la seguridad de inmediato, comenzaron a incluir soporte de hardware para máquinas virtuales y cifrado. Desafortunadamente, la predicción de rama introdujo una falla de seguridad desconocida pero significativa en muchos procesadores. En particular, las
vulnerabilidades Meltdown y Spectre explotan las características de microarquitectura, lo que permite la filtración de información protegida . Ambos usan los llamados ataques en canales de terceros cuando la información se filtra de acuerdo con la diferencia en el tiempo dedicado a la tarea. En 2018, los investigadores mostraron
cómo usar una de las opciones de Spectre para extraer información a través de la red sin descargar código al procesador de destino . Aunque este ataque, llamado NetSpectre, transfiere información lentamente, el solo hecho de que le permite atacar cualquier máquina en la misma red local (o en el mismo clúster en la nube) crea muchos nuevos vectores de ataque. Posteriormente, se informaron dos vulnerabilidades más en la arquitectura de las máquinas virtuales (
1 ,
2 ). Uno de ellos, llamado Foreshadow, le permite penetrar en los mecanismos de seguridad Intel SGX diseñados para proteger los datos más valiosos (como las claves de cifrado). Nuevas vulnerabilidades se encuentran mensualmente.
Los ataques a canales de terceros no son nuevos, pero en la mayoría de los casos los errores de software fueron la culpa antes. En Meltdown, Spectre y otros ataques, esta es una falla en la implementación del hardware. Hay una dificultad fundamental en cómo los arquitectos de procesadores determinan cuál es la implementación correcta de ISA porque la definición estándar no dice nada sobre los efectos de ejecución de una secuencia de instrucciones, solo el estado de ejecución arquitectónico visible de ISA. Los arquitectos deberían repensar su definición de la implementación correcta de ISA para evitar tales fallas de seguridad. Al mismo tiempo, deben repensar la atención que prestan a la seguridad informática y cómo los arquitectos pueden trabajar con los desarrolladores de software para implementar sistemas más seguros. Los arquitectos (y todos los demás) no deben tomar la seguridad de otra manera que no sea como una necesidad primaria.
Oportunidades futuras en arquitectura de computadoras
"Tenemos oportunidades increíbles disfrazadas de problemas insolubles". - John Gardner, 1965
Las ineficiencias inherentes de los procesadores de uso general, ya sea la tecnología ILP o los procesadores multinúcleo, combinados con la finalización de la escala de Dennard y la ley de Moore hacen improbable que los arquitectos y desarrolladores de procesadores puedan mantener un ritmo significativo de mejora del rendimiento para los procesadores de uso general. Dada la importancia de mejorar la productividad del software, debemos hacernos la pregunta: ¿qué otros enfoques prometedores existen?
Hay dos posibilidades obvias, así como una tercera creada al combinar las dos. Primero, los métodos de desarrollo de software existentes hacen un uso extensivo de lenguajes de alto nivel con escritura dinámica. Desafortunadamente, tales lenguajes generalmente se interpretan y ejecutan de manera extremadamente ineficiente. Para ilustrar esta ineficiencia, Leiserson y sus colegas
dieron un pequeño ejemplo: la multiplicación de matrices .
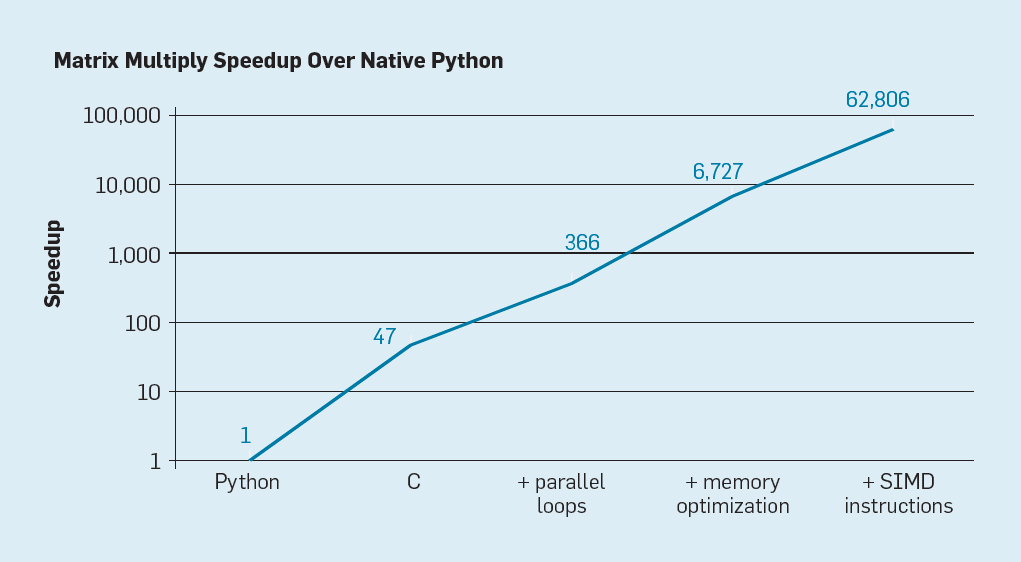 Fig. 7. Posible aceleración de la multiplicación de matrices de Python después de cuatro optimizaciones.
Fig. 7. Posible aceleración de la multiplicación de matrices de Python después de cuatro optimizaciones.Como se muestra en la fig. 7, simplemente reescribir el código de Python a C mejora el rendimiento en 47 veces. El uso de bucles paralelos en muchos núcleos da un factor adicional de aproximadamente 7. La optimización de la estructura de memoria para usar cachés da un factor de 20, y el último factor de 9 proviene del uso de extensiones de hardware para realizar operaciones SIMD paralelas que son capaces de realizar 16 instrucciones de 32 bits. Después de eso, la versión final altamente optimizada se ejecuta en el procesador multinúcleo de Intel 62.806 veces más rápido que la versión original de Python. Esto, por supuesto, es un pequeño ejemplo. Se puede suponer que los programadores utilizarán una biblioteca optimizada. Aunque la brecha de rendimiento es exagerada, probablemente hay muchos programas que pueden optimizarse 100-1000 veces.
Un área interesante de investigación es la cuestión de si es posible cerrar algunas brechas de rendimiento con la nueva tecnología de compilación, posiblemente con mejoras arquitectónicas. Aunque es difícil traducir y compilar eficientemente lenguajes de scripting de alto nivel como Python, la recompensa potencial es enorme. Incluso una pequeña optimización puede llevar al hecho de que los programas Python se ejecutarán decenas a cientos de veces más rápido. Este sencillo ejemplo muestra cuán grande es la brecha entre los lenguajes modernos centrados en el rendimiento del programador y los enfoques tradicionales que enfatizan el rendimiento.
Arquitecturas Especializadas
Un enfoque más orientado al hardware es el diseño de arquitecturas adaptadas a un área temática específica, donde demuestran una eficiencia significativa. Estas son arquitecturas especializadas de dominio específico (arquitecturas específicas de dominio, DSA). Por lo general, estos son procesadores programables y completos, pero teniendo en cuenta una clase específica de tareas. En este sentido, difieren de los circuitos integrados específicos de la aplicación (ASIC), que a menudo se usan para la misma función que el código que rara vez cambia. Los DSA a menudo se denominan aceleradores, ya que aceleran algunas aplicaciones en comparación con ejecutar toda la aplicación en una CPU de propósito general. Además, los DSA pueden proporcionar un mejor rendimiento porque se adaptan con mayor precisión a las necesidades de la aplicación. Los ejemplos de DSA incluyen procesadores gráficos (GPU), procesadores de redes neuronales utilizados para el aprendizaje profundo y procesadores para redes definidas por software (SDN). Los DSA logran un mayor rendimiento y una mayor eficiencia energética por cuatro razones principales.
Primero, los DSA usan una forma más eficiente de concurrencia para un área temática específica. Por ejemplo, SIMD (secuencia de instrucciones única, secuencia de datos múltiples) es
más eficiente que MIMD (secuencia de instrucciones múltiples, secuencia de datos múltiples). Aunque SIMD es menos flexible, es muy adecuado para muchos DSA. Los procesadores especializados también pueden usar los enfoques ILP de VLIW en lugar de mecanismos poco especulativos. Como se mencionó anteriormente, los
procesadores VLIW son poco adecuados para el código de uso general , pero para áreas estrechas son mucho más eficientes porque los mecanismos de control son más simples. En particular, la mayoría de los procesadores de propósito general de gama alta son excesivamente multiplexados, lo que requiere una lógica de control compleja para iniciar y completar las instrucciones. En contraste, VLIW realiza el análisis y la planificación necesarios en tiempo de compilación, lo que puede funcionar bien para un programa claramente paralelo.
Segundo, los servicios DSA hacen un mejor uso de la jerarquía de memoria. El acceso a la memoria se ha vuelto mucho más costoso que los cálculos aritméticos,
como señaló Horowitz . Por ejemplo, acceder a un bloque en un caché de 32 KB requiere aproximadamente 200 veces más energía que agregar enteros de 32 bits. Tal gran diferencia hace que la optimización del acceso a la memoria sea crítica para lograr una alta eficiencia energética. Los procesadores de propósito general ejecutan código en el que los accesos a la memoria exhiben típicamente una localidad espacial y temporal, pero por lo demás no son muy predecibles en el momento de la compilación. Por lo tanto, para aumentar el rendimiento, las CPU usan cachés de varios niveles y ocultan el retraso en DRAM relativamente lentas fuera del chip. Estos cachés de varios niveles a menudo consumen aproximadamente la mitad de la energía del procesador, pero evitan casi todas las llamadas a DRAM, lo que requiere aproximadamente 10 veces más energía que acceder al caché de último nivel.
Los cachés tienen dos defectos notables.
Cuando los conjuntos de datos son muy grandes . Las memorias caché simplemente no funcionan bien cuando los conjuntos de datos son muy grandes, tienen poca localidad temporal o espacial.
Cuando los cachés funcionan bien . Cuando los cachés funcionan bien, la localidad es muy alta, es decir, por definición, la mayor parte del caché está inactiva la mayor parte del tiempo.
En las aplicaciones donde los patrones de acceso a la memoria están bien definidos y son comprensibles en el momento de la compilación, lo cual es cierto para los lenguajes específicos de dominio (DSL) típicos, los programadores y compiladores pueden optimizar el uso de la memoria mejor que los cachés asignados dinámicamente. Por lo tanto, los DSA generalmente usan una jerarquía de memoria en movimiento que es controlada explícitamente por el software, similar a cómo funcionan los procesadores de vectores. En las aplicaciones correspondientes, el control de memoria de usuario "manual" le permite gastar mucha menos energía que el caché estándar.
En tercer lugar, DSA puede reducir la precisión de los cálculos si no se necesita una alta precisión. Las CPU de uso general generalmente admiten cálculos de enteros de 32 y 64 bits, así como datos de punto flotante (FP). Para muchas aplicaciones de aprendizaje automático y gráficos, esta es una precisión redundante. Por ejemplo, en redes neuronales profundas, el cálculo a menudo usa números de 4, 8 o 16 bits, mejorando tanto el rendimiento de datos como la potencia de procesamiento. Del mismo modo, los cálculos de punto flotante son útiles para entrenar redes neuronales, pero 32 bits, y a menudo 16 bits, son suficientes.
Finalmente, los DSA se benefician de los programas escritos en lenguajes específicos de dominio que permiten una mayor concurrencia, mejoran la estructura, la presentación del acceso a la memoria y simplifican la superposición eficiente de aplicaciones en un procesador dedicado.
Lenguas Orientadas a la Materia
Los DSA requieren que las operaciones de nivel superior se adapten a la arquitectura del procesador, pero es muy difícil hacerlo en un lenguaje de propósito general como Python, Java, C o Fortran. Los lenguajes específicos de dominio (DSL) ayudan con esto y le permiten programar de manera efectiva los DSA. Por ejemplo, los DSL pueden hacer explícitas las operaciones explícitas de vectores, matrices densas y matrices dispersas, lo que permite que el compilador DSL asigne eficientemente las operaciones al procesador. Entre los lenguajes específicos de dominio se encuentran Matlab, un lenguaje para trabajar con matrices, TensorFlow para programar redes neuronales, P4 para programar redes definidas por software y Halide para procesar imágenes con transformaciones de alto nivel.
El problema de DSL es cómo mantener suficiente independencia arquitectónica para que el software en él pueda ser portado a varias arquitecturas, mientras se logra una alta eficiencia al comparar el software con un DSA básico. Por ejemplo,
un sistema XLA traduce el código de
Tensorflow a sistemas heterogéneos con GPU Nvidia o procesadores de tensor (TPU). Equilibrar la portabilidad entre DSA mientras se mantiene la eficiencia es una tarea de investigación interesante para los desarrolladores de lenguaje, compiladores y DSA.
Ejemplo de DSA: TPU v1
Como ejemplo de DSA, considere Google TPU v1, que está diseñado para acelerar el funcionamiento de una red neuronal (
1 ,
2 ). Este TPU se ha producido desde 2015, y muchas aplicaciones se han estado ejecutando en él: desde consultas de búsqueda hasta traducción de texto y reconocimiento de imágenes en AlphaGo y AlphaZero, programas DeepMind para jugar go y ajedrez. El objetivo era aumentar la productividad y la eficiencia energética de las redes neuronales profundas en 10 veces.
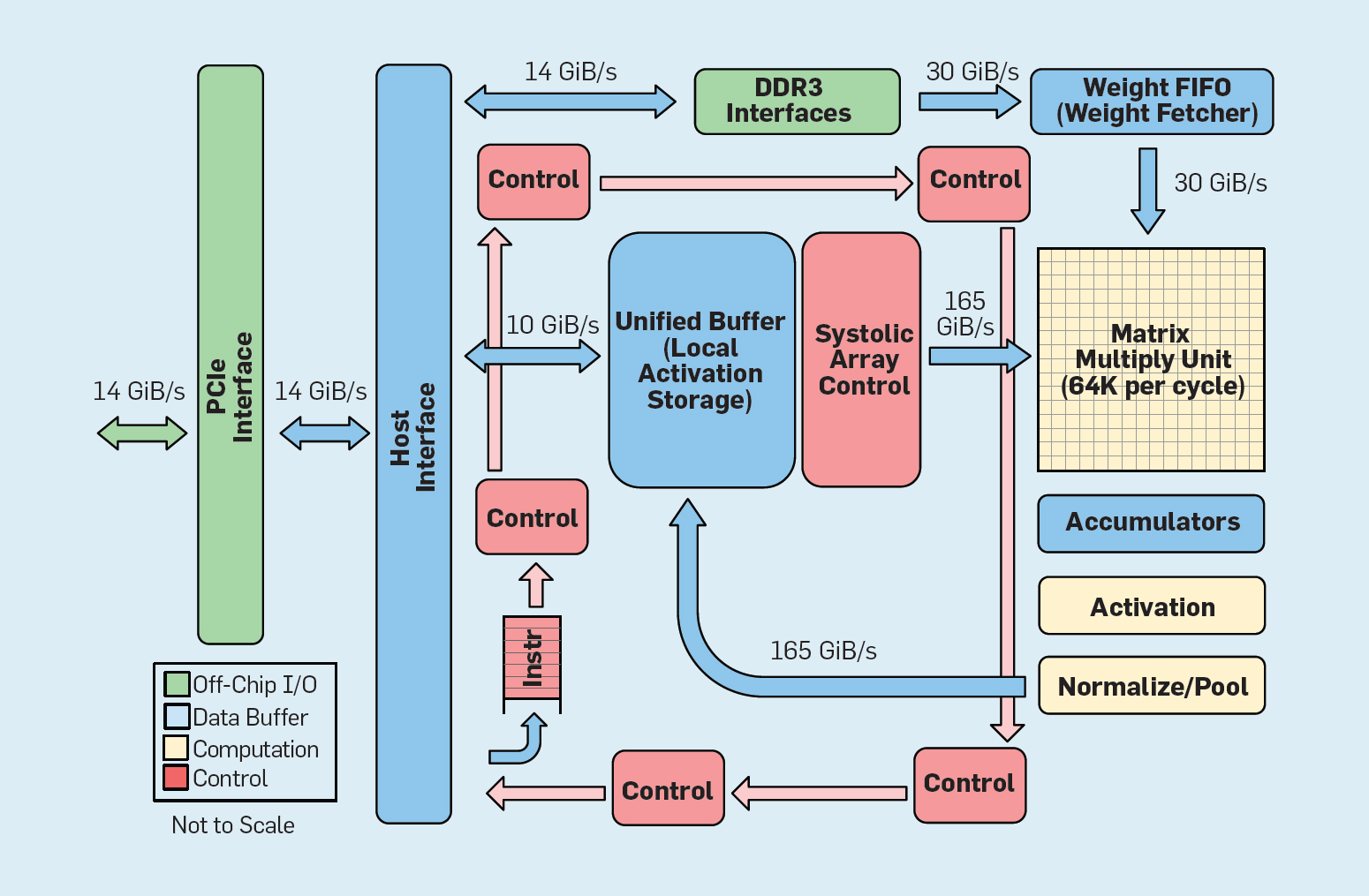 Fig. 8. Organización funcional Unidad de procesamiento de tensor de Google (TPU v1)
Fig. 8. Organización funcional Unidad de procesamiento de tensor de Google (TPU v1)Como se muestra en la Figura 8, la organización de una TPU es radicalmente diferente de la de un procesador de propósito general. La unidad de computación principal es la unidad de matriz, la
estructura de las matrices sistólicas , que cada ciclo produce 256 × 256 de acumulación múltiple. La combinación de precisión de 8 bits, una estructura sistólica altamente eficiente, control SIMD y la asignación de una parte significativa del chip para esta función ayudan a realizar aproximadamente 100 veces más operaciones de multiplicación de acumulación por ciclo que un núcleo de CPU de uso general. En lugar de cachés, TPU usa 24 MB de memoria local, que es aproximadamente el doble que los cachés de CPU de uso general de 2015 con el mismo TDP. Finalmente, tanto la memoria de activación neuronal como la memoria de equilibrio de la red neuronal (incluida la estructura FIFO que almacena los pesos) están conectadas a través de canales de alta velocidad controlados por el usuario. El rendimiento promedio ponderado de TPU para seis problemas típicos de salida lógica de redes neuronales en los centros de datos de Google es 29 veces mayor que el de los procesadores de propósito general. Dado que los TPU requieren menos de la mitad de la potencia, su eficiencia energética para esta carga de trabajo es más de 80 veces mayor que la de los procesadores de uso general.
Resumen
Examinamos dos enfoques diferentes para mejorar el rendimiento del programa al aumentar la eficiencia del uso de tecnologías de hardware. En primer lugar, al aumentar la productividad de los lenguajes modernos de alto nivel que generalmente se interpretan. En segundo lugar, mediante la creación de arquitecturas para áreas temáticas específicas, que mejoran significativamente el rendimiento y la eficiencia en comparación con los procesadores de uso general. Los lenguajes específicos de dominio son otro ejemplo de cómo mejorar la interfaz hardware-software que permite innovaciones arquitectónicas como DSA. Para lograr un éxito significativo utilizando tales enfoques, se requerirá un equipo de proyecto integrado verticalmente que esté versado en aplicaciones, lenguajes orientados a temas y tecnologías de compilación relacionadas, arquitectura de computadora, así como tecnología de implementación básica. La necesidad de integración vertical y la toma de decisiones de diseño en diferentes niveles de abstracción era típica de la mayoría de los primeros trabajos en el campo de la tecnología informática antes de que la industria se estructurara horizontalmente. En esta nueva era, la integración vertical se ha vuelto más importante. Se darán ventajas a los equipos que pueden encontrar y aceptar compromisos complejos y optimizaciones.
Esta oportunidad ya ha llevado a un aumento en la innovación arquitectónica, atrayendo muchas filosofías arquitectónicas competidoras:
GPU Las GPU Nvidia
usan múltiples núcleos, cada uno con grandes archivos de registro, múltiples flujos de hardware y cachés.
TPU Las
TPU de Google se
basan en grandes conjuntos sistólicos bidimensionales y memoria programable en chip.
FPGA Microsoft Corporation en sus centros de datos
implementa arreglos de puertas programables por el usuario (FPGA), que se utilizan en aplicaciones de redes neuronales.
CPU Intel ofrece procesadores con muchos núcleos, una gran memoria caché multinivel e instrucciones SIMD unidimensionales, de forma similar al FPGA de Microsoft, y el
nuevo neuroprocesador está más cerca de TPU que de CPU .
Además de estos actores principales,
docenas de nuevas empresas implementan sus propias ideas . Para satisfacer la creciente demanda, los diseñadores están combinando cientos y miles de chips para crear supercomputadoras de redes neuronales.
Esta avalancha de arquitecturas de redes neuronales indica que ha llegado un momento interesante en la historia de la arquitectura de computadoras. En 2019, es difícil predecir cuál de estas áreas ganará (si es que alguien gana), pero el mercado definitivamente determinará el resultado, tal como ha establecido el debate arquitectónico del pasado.
Arquitectura abierta
Siguiendo el ejemplo del software exitoso de código abierto, ISA abierto representa una oportunidad alternativa en la arquitectura de computadoras. Son necesarios para crear una especie de "Linux para procesadores", de modo que la comunidad pueda crear núcleos de código abierto además de compañías individuales que posean núcleos propietarios. Si muchas organizaciones diseñan procesadores utilizando el mismo ISA, más competencia puede conducir a una innovación aún más rápida. El objetivo es proporcionar arquitectura para procesadores que cuestan desde unos pocos centavos hasta $ 100.
El primer ejemplo es RISC-V (RISC Five), la
quinta arquitectura RISC desarrollada en la Universidad de California en Berkeley . Ella es apoyada por una comunidad dirigida por
la Fundación RISC-V .
La arquitectura abierta permite que la evolución de la ISA tenga lugar en el ojo público, con la participación de expertos hasta que se tome una decisión final. Una ventaja adicional de un fondo abierto es que es poco probable que ISA se expanda principalmente por razones de marketing, porque a veces esta es la única explicación para la expansión de sus propios conjuntos de instrucciones.RISC-V — . , , . 32- 64- . RISC-V ; , . «» : , , . RISC-V , , . , ::
RISC-V ISA. , ARMv8, ARM:
- . RISC-V . 50 , RISC-I . (M, A, F D) 53 , C 34, 137. , ARMv8 500 .
- . RISC-V : , ARMv8 14.
La simplicidad simplifica tanto el diseño del diseño de los procesadores como la verificación de su corrección. Debido a que RISC-V se enfoca en todo, desde centros de datos hasta dispositivos IoT, la validación del diseño puede ser una parte importante de los costos de desarrollo.Cuarto, RISC-V es un diseño de hoja limpia después de 25 años, donde los arquitectos aprenden de los errores de sus predecesores. A diferencia de la arquitectura RISC de primera generación, evita la microarquitectura o las funciones que dependen de la tecnología (como ramas diferidas y descargas diferidas) o innovaciones (como ventanas de registro), que fueron suplantadas por los avances del compilador.Finalmente, RISC-V admite DSA, reservando un amplio espacio de código de operación para aceleradores personalizados.Además de RISC-V, Nvidia también anunció (en 2017)Una arquitectura libre y abierta , lo llama Nvidia Deep Learning Accelerator (NVDLA). Es un DSA escalable y personalizable para inferencia en el aprendizaje automático. Los parámetros de configuración incluyen el tipo de datos (int8, int16 o fp16) y el tamaño de la matriz de multiplicación bidimensional. La escala del sustrato de silicio varía de 0,5 mm² a 3 mm², y el consumo de energía es de 20 mW a 300 mW. ISA, la pila de software y la implementación están abiertos.. -, , , . , . , . , RISC-V . , , , FPGA , , . FPGA 10 , , . , .
Desarrollo de hardware flexible.
El Manifiesto de Desarrollo de Software Flexible (2001) Beck et al. Revolucionaron el desarrollo de software al eliminar los problemas de un sistema de cascada tradicional basado en la planificación y la documentación. Pequeños equipos de programadores crean rápidamente prototipos funcionales pero incompletos, y reciben comentarios de los clientes antes de comenzar la siguiente iteración. La versión Scrum de Agile reúne equipos de cinco a diez programadores que corren de dos a cuatro semanas por iteración.Habiendo tomado nuevamente la idea del desarrollo de software, es posible organizar un desarrollo de hardware flexible. La buena noticia es que las herramientas modernas de diseño electrónico asistido por computadora (ECAD) han aumentado el nivel de abstracción, permitiendo un desarrollo flexible. Este mayor nivel de abstracción también aumenta el nivel de reutilización del trabajo entre diferentes diseños.Los sprints de cuatro semanas parecen inverosímiles para los procesadores, dados los meses entre la creación del diseño y la producción del chip. En la fig. La Figura 9 muestra cómo puede funcionar un método flexible modificando un prototipo a un nivel apropiado .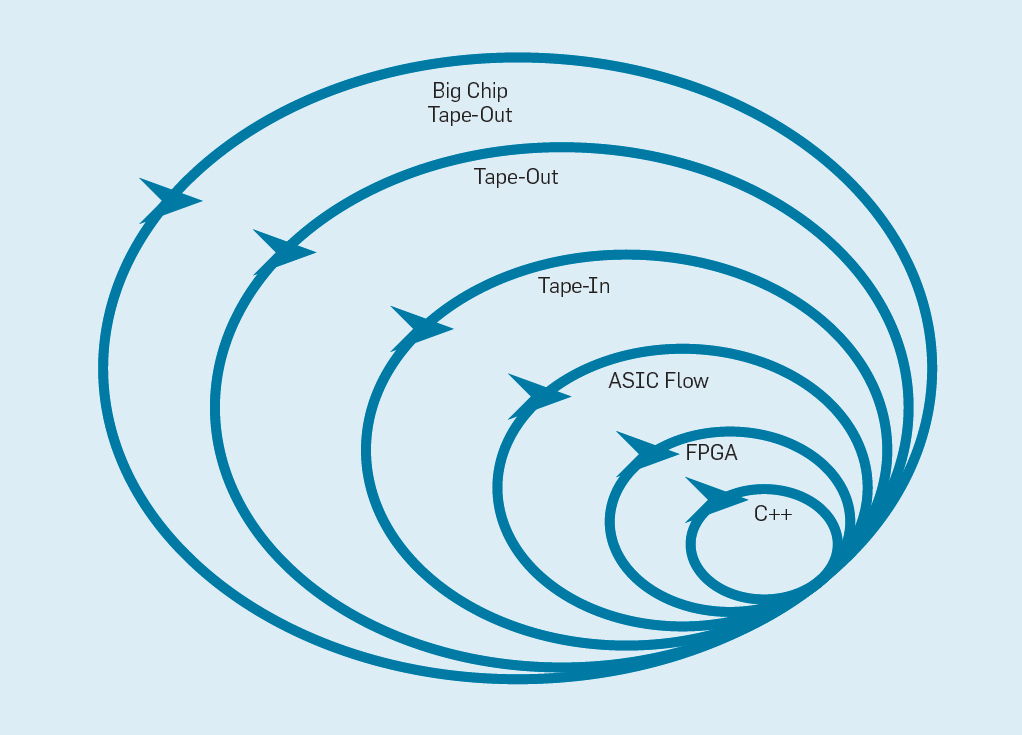 Fig. 9. Metodología de desarrollo de equipos flexibles.El nivel más interno es un simulador de software, el lugar más fácil y rápido para realizar cambios. El siguiente nivel son los chips FPGA, que pueden funcionar cientos de veces más rápido que un simulador de software detallado. Los FPGA pueden trabajar con sistemas operativos y puntos de referencia completos, como la Standard Performance Evaluation Corporation (SPEC), que permite una evaluación mucho más precisa de los prototipos. Amazon Web Services ofrece FPGA en la nube, por lo que los arquitectos pueden usar FPGA sin tener que comprar primero equipo y configurar un laboratorio. El siguiente nivel utiliza herramientas ECAD para generar un circuito de chip, para documentar el tamaño y el consumo de energía. Incluso después de que las herramientas funcionen, es necesario seguir algunos pasos manuales para refinar los resultados antes de enviar el nuevo procesador a producción.Los desarrolladores de procesadores llaman a esto el siguiente nivel.en la cinta . Estos primeros cuatro niveles admiten sprints de cuatro semanas.Para fines de investigación, podríamos detenernos en el nivel cuatro, ya que las estimaciones de área, energía y rendimiento son muy precisas. Pero es como si un corredor corriera una maratón y se detuviera 5 metros antes del final, porque su tiempo de finalización ya está despejado. A pesar de la difícil preparación para la maratón, extrañará la emoción y el placer de cruzar la línea de meta. Una de las ventajas de los ingenieros de hardware sobre los ingenieros de software es que crean cosas físicas. Obtener chips de la fábrica: medir, ejecutar programas reales, mostrarlos a amigos y familiares es una gran alegría para el diseñador.Muchos investigadores creen que deberían detenerse porque la fabricación de chips es demasiado asequible. Pero si el diseño es pequeño, es sorprendentemente económico. Los ingenieros pueden ordenar 100 microchips de 1 mm² por solo $ 14,000. A 28 nm, un chip de 1 mm² contiene millones de transistores: esto es suficiente para el procesador RISC-V y el acelerador NVLDA. El nivel más externo es costoso si el diseñador pretende crear un chip grande, pero se pueden demostrar muchas ideas nuevas en chips pequeños.
Fig. 9. Metodología de desarrollo de equipos flexibles.El nivel más interno es un simulador de software, el lugar más fácil y rápido para realizar cambios. El siguiente nivel son los chips FPGA, que pueden funcionar cientos de veces más rápido que un simulador de software detallado. Los FPGA pueden trabajar con sistemas operativos y puntos de referencia completos, como la Standard Performance Evaluation Corporation (SPEC), que permite una evaluación mucho más precisa de los prototipos. Amazon Web Services ofrece FPGA en la nube, por lo que los arquitectos pueden usar FPGA sin tener que comprar primero equipo y configurar un laboratorio. El siguiente nivel utiliza herramientas ECAD para generar un circuito de chip, para documentar el tamaño y el consumo de energía. Incluso después de que las herramientas funcionen, es necesario seguir algunos pasos manuales para refinar los resultados antes de enviar el nuevo procesador a producción.Los desarrolladores de procesadores llaman a esto el siguiente nivel.en la cinta . Estos primeros cuatro niveles admiten sprints de cuatro semanas.Para fines de investigación, podríamos detenernos en el nivel cuatro, ya que las estimaciones de área, energía y rendimiento son muy precisas. Pero es como si un corredor corriera una maratón y se detuviera 5 metros antes del final, porque su tiempo de finalización ya está despejado. A pesar de la difícil preparación para la maratón, extrañará la emoción y el placer de cruzar la línea de meta. Una de las ventajas de los ingenieros de hardware sobre los ingenieros de software es que crean cosas físicas. Obtener chips de la fábrica: medir, ejecutar programas reales, mostrarlos a amigos y familiares es una gran alegría para el diseñador.Muchos investigadores creen que deberían detenerse porque la fabricación de chips es demasiado asequible. Pero si el diseño es pequeño, es sorprendentemente económico. Los ingenieros pueden ordenar 100 microchips de 1 mm² por solo $ 14,000. A 28 nm, un chip de 1 mm² contiene millones de transistores: esto es suficiente para el procesador RISC-V y el acelerador NVLDA. El nivel más externo es costoso si el diseñador pretende crear un chip grande, pero se pueden demostrar muchas ideas nuevas en chips pequeños.Conclusión
« — » — , 1650
, , , / . iAPX-432 Itanium , , S/360, 8086 ARM , .
, — , , , , , . - , , , . . , , RISC, . , , , , .
En la próxima década, se producirá una explosión cámbrica de nuevas arquitecturas informáticas, lo que significa tiempos emocionantes para los arquitectos informáticos en la academia y la industria.