
Cuando me presento y digo lo que está haciendo nuestra startup, el interlocutor inmediatamente plantea la pregunta: ¿trabajó anteriormente en Facebook o su desarrollo fue creado bajo la influencia de Facebook? Muchos conocen los esfuerzos de Facebook para mantener su gráfico social, porque la compañía ha publicado
varios artículos sobre la infraestructura de este gráfico, que ha construido cuidadosamente.
Google habló sobre
su gráfico de conocimiento , pero nada sobre la infraestructura interna. Sin embargo, la compañía también tiene subsistemas especializados para ello. De hecho, se está prestando mucha atención al gráfico de conocimiento. Personalmente, puse al menos dos de mis promociones en este caballo, y comencé a trabajar en un nuevo gráfico en 2010.
Google necesitaba construir la infraestructura no solo para servir relaciones complejas en el Gráfico de conocimiento, sino también para soportar todos los bloques temáticos de
OneBox en los resultados de búsqueda que tienen acceso a datos estructurados. La infraestructura es necesaria para 1) una elusión de calidad de los hechos con 2) un ancho de banda lo suficientemente alto y 3) un retraso lo suficientemente bajo como para capturar una buena parte de las consultas de búsqueda en la web. Resultó que ningún sistema o base de datos disponible puede realizar las tres acciones.
Ahora que he explicado por qué se necesita infraestructura, en el resto del artículo hablaré sobre mi experiencia en la construcción de dichos sistemas, incluso para
Knowledge Graph y
OneBox .
¿Cómo lo sé?
Me presentaré brevemente. Trabajé en Google de 2006 a 2013. Primero como pasante, luego como ingeniero de software en la infraestructura de búsqueda web. Google
adquirió Metaweb en 2010, y mi equipo acaba de lanzar
Caffeine . Quería hacer algo más, y comencé a trabajar con los chicos de Metaweb (en San Francisco), pasando tiempo viajando entre San Francisco y Mountain View. Quería descubrir cómo usar el gráfico de conocimiento para mejorar mi búsqueda en la web.
Ha habido proyectos de este tipo en Google antes que yo. Es de destacar que el proyecto llamado
Squared fue creado en una oficina de Nueva York, y se habló sobre las Tarjetas de Conocimiento. Luego hubo esfuerzos esporádicos de individuos / pequeños equipos, pero en ese momento no había una cadena de equipos establecida, lo que finalmente me obligó a abandonar Google. Pero volveremos a esto más tarde ...
Historia de metaweb
Como ya se mencionó, Google adquirió Metaweb en 2010. Metaweb creó un gráfico de conocimiento de alta calidad utilizando varios métodos, incluidos el rastreo y análisis de Wikipedia, así como un sistema de edición de estilo wiki de crowdsourcing con
Freebase . Todo esto funcionó sobre la base de la propia base de datos de gráficos de Graphd: el demonio de gráficos (ahora
publicado en GitHub).
Graphd tenía algunas propiedades bastante típicas. Como demonio, funcionaba en un servidor, almacenaba todos los datos en la memoria y podía emitir un sitio completo de Freebase. Después de la compra, Google estableció una de las tareas para continuar trabajando con Freebase.
Google construyó un imperio sobre hardware estándar y software distribuido. Un DBMS del lado del servidor nunca podría servir para rastrear, indexar y buscar resultados. Primero creó SSTable, luego Bigtable, que escala horizontalmente a cientos o miles de máquinas que comparten petabytes de datos. Las máquinas son asignadas por Borg (
K8 vino de aquí), se comunican a través de Stubby (gRPC vino de aquí) resolviendo direcciones IP a través del servicio de nombres Borg (BNC dentro de K8) y almacenan datos en el Sistema de archivos de Google (
GFS , puede decir Hadoop FS).
Los procesos pueden morir, las máquinas pueden romperse, pero el sistema en su conjunto es indestructible y continuará zumbando.Graphd se metió en ese entorno. La idea de una base de datos que sirve a un sitio web completo en un servidor es ajena a Google (incluido yo). En particular, Graphd necesitaba 64 GB o más de memoria para ejecutarse. Si le parece que esto es un poco, recuerde: esto es 2010. La mayoría de los servidores de Google estaban equipados con un máximo de 32 GB. De hecho, Google tuvo que comprar máquinas especiales con suficiente RAM para servir Graphd en su forma actual.
Reemplazo gráfico
La lluvia de ideas comenzó sobre cómo mover datos graficados o reescribir el sistema para que funcione de manera distribuida. Pero, ya ves, los gráficos son complicados. Esta no es una base de datos de valores clave para usted, donde simplemente puede tomar un dato, moverlo a otro servidor y emitirlo cuando solicita una clave. Los gráficos realizan uniones eficientes y soluciones alternativas que requieren que el software funcione de una manera específica.
Una idea era usar un proyecto llamado MindMeld (IIRC). Se suponía que la memoria de otro servidor estaría disponible mucho más rápido a través del equipo de red. Debería haber sido más rápido que los RPC normales, lo suficientemente rápido como para seudo-replicar el acceso directo a la memoria requerido por la base de datos en memoria. Pero la idea no fue demasiado lejos.
Otra idea que en realidad se convirtió en un proyecto fue crear un sistema de servicio gráfico verdaderamente distribuido. Algo que no solo puede reemplazar Graphd para Freebase, sino que también funciona realmente en la producción.
Se llamaba Dgraph, un gráfico distribuido, invertido de Graphd (graph-daemon).Si estás interesado, entonces sí. Mi startup, Dgraph Labs, la compañía y el proyecto de código abierto Dgraph llevan el nombre de ese proyecto en Google (nota: Dgraph es una marca registrada de Dgraph Labs; hasta donde yo sé, Google no lanza proyectos con nombres que coincidan con los internos).
En casi todo el resto del texto, cuando menciono Dgraph, me refiero al proyecto interno de Google, y no al proyecto de código abierto que creamos. Pero más sobre
eso más tarde.
La historia de Cerebro: el motor del conocimiento
Crear inadvertidamente infraestructura para gráficosAunque generalmente sabía que Dgraph intentaba reemplazar Graphd, mi objetivo era crear algo para mejorar la búsqueda web. En Metaweb, conocí a un ingeniero de investigación de DH que creó
Cubed .
Como mencioné, un grupo heterogéneo de ingenieros de la división de Nueva York desarrolló Google
Squared . Pero el sistema DH era
mucho mejor. Empecé a pensar cómo implementarlo en Google. Google tenía piezas de rompecabezas que podía usar fácilmente.
La primera parte del rompecabezas es el motor de búsqueda. Esta es una manera de determinar con precisión qué palabras están relacionadas entre sí. Por ejemplo, cuando ve una frase como [películas de tom hanks], podría decirle que [tom] y [hanks] están relacionados. Del mismo modo, desde [san francisco weather] vemos una conexión entre [san] y [francisco]. Estas son cosas obvias para las personas, pero no tan obvias para los automóviles.
La segunda parte del rompecabezas es comprender la gramática. Cuando en la consulta [libros de autores franceses], la máquina puede interpretar esto como [libros] de [autores franceses], es decir, libros de esos autores que son franceses. Pero también puede interpretar esto como [libros en francés] de [autores], es decir, libros en francés de cualquier autor. Utilicé el etiquetador
Part-Of-Speech (POS) de la Universidad de Stanford para analizar mejor la gramática y construir el árbol.
La tercera parte del rompecabezas es comprender las entidades. [francés] puede significar mucho. Puede ser un país (región), nacionalidad (relacionada con el pueblo francés), cocina (relacionada con la comida) o idioma. Luego apliqué otro sistema para obtener una lista de entidades a las que puede corresponder una palabra o frase.
La cuarta parte del rompecabezas era comprender la relación entre entidades. Cuando se sabe cómo conectar las palabras con las frases, en qué orden se deben realizar las frases, es decir, su gramática y a qué entidades pueden corresponder, debe encontrar la relación entre estas entidades para crear interpretaciones automáticas. Por ejemplo, ejecutamos la consulta [libros de autores franceses], y POS dice que es [libros] de [autores franceses]. Tenemos varias entidades para [francés] y varias para [autores]: el algoritmo debe determinar cómo se relacionan. Por ejemplo, pueden estar relacionados por lugar de nacimiento, es decir, autores que nacieron en Francia (aunque pueden escribir en inglés). O podrían ser autores que son ciudadanos franceses. O autores que pueden hablar o escribir en francés (pero pueden no estar relacionados con Francia como país), o autores que simplemente aman la cocina francesa.
Sistema de gráficos de índice de búsqueda
Para determinar si hay una conexión entre los objetos y cómo están conectados, necesita un sistema de gráficos. Graphd nunca iba a escalar al nivel de Google, pero podría usar la búsqueda en sí. Los datos del Gráfico de conocimiento se almacenan en formato
Triples triples, es decir, cada hecho está representado por tres partes: sujeto (entidad), predicado (relación) y objeto (otra entidad). Las solicitudes van como
[SP] → [O] o
[PO] → [S] , y a veces
[SO] → [P] .
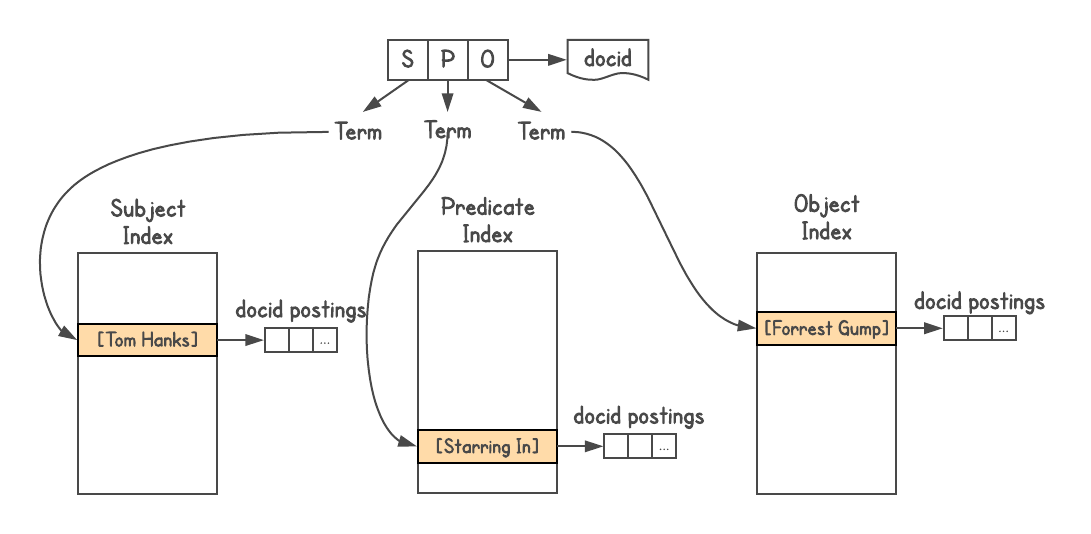
Usé el
índice de búsqueda de Google , asigné un documento a cada triple y construí tres índices, uno para S, P y O. Además, el índice es anidable, por lo que agregué información sobre el tipo de cada entidad (es decir, actor, libro, persona y etc.)
Creé un sistema de este tipo, aunque vi un problema con la profundidad de las uniones (que se explica a continuación) y no es adecuado para consultas complejas. En realidad, cuando alguien del equipo de Metaweb me pidió que publicara un sistema para colegas, me negué.Para determinar la relación, puede ver cuántos resultados da cada consulta. Por ejemplo, ¿cuántos resultados dan [francés] y [autor]? Tomamos estos resultados y vemos cómo se relacionan con [libros], etc. Por lo tanto, aparecieron muchas interpretaciones automáticas de la consulta. Por ejemplo, la consulta [películas de Tom Hanks] genera una variedad de interpretaciones, como [películas dirigidas por Tom Hanks], [películas protagonizadas por Tom Hanks], [películas producidas por Tom Hanks], pero rechaza automáticamente interpretaciones como [películas llamadas Tom Hanks].
Cada interpretación genera una lista de resultados, entidades válidas en el gráfico, y también devuelve sus tipos (presentes en archivos adjuntos). Esto demostró ser una función extremadamente poderosa porque comprender el tipo de resultados abrió posibilidades como el filtrado, la clasificación o una mayor expansión. Puede ordenar las películas con el año de lanzamiento, la duración de la película (corto, largo), idioma, premios recibidos, etc.
El proyecto parecía tan inteligente que nosotros (DH también participó parcialmente como experto en el gráfico de conocimiento) lo llamamos Cerebro, en honor al dispositivo del mismo nombre de la película
"X-Men" .
Cerebro a menudo revelaba hechos muy interesantes que originalmente no estaban en la consulta de búsqueda. Por ejemplo, a petición de [los presidentes de EE. UU.], Cerebro se dará cuenta de que los presidentes son personas y que las personas tienen crecimiento. Esto nos permite clasificar a los presidentes por crecimiento y demostrar que Abraham Lincoln es el presidente más alto de los Estados Unidos. Además, las personas pueden ser filtradas por nacionalidad. En este caso, Estados Unidos y el Reino Unido aparecen en la lista, porque Estados Unidos tenía un presidente británico, George Washington. (Descargo de responsabilidad: los resultados se basan en el estado del gráfico de conocimiento en el momento del experimento; no puedo dar fe de su corrección).
Enlaces azules versus conocimiento
Cerebro fue capaz de comprender realmente las solicitudes de los usuarios. Una vez recibidos los datos de todo el gráfico, podríamos generar interpretaciones automáticas de la consulta, generar una lista de resultados y comprender mucho de estos resultados para seguir estudiando el gráfico. Se explicó anteriormente: tan pronto como el sistema comprende que se trata de películas, personas o libros, etc., se pueden activar ciertos tipos de filtros. Incluso puede recorrer los nodos y mostrar información relacionada: desde [presidentes de EE. UU.] A [escuelas a las que asistieron] o [niños que engendraron]. Aquí hay algunas otras consultas que el sistema mismo generó: [mujeres políticas afroamericanas], [actores de Bollywood casados con políticos], [hijos de nosotros presidentes], [películas protagonizadas por Tom Hanks estrenadas en los años 90]
DH demostró esta oportunidad de pasar de una lista a otra en otro proyecto llamado
Parallax .
Cerebro mostró un resultado muy impresionante, y la gerencia de Metaweb lo apoyó. Incluso en términos de infraestructura, resultó ser eficiente y funcional. Lo llamé
el motor de conocimiento (como un motor de búsqueda). Pero en Google, nadie abordó específicamente este tema. Era de poco interés para mi gerente, me aconsejaron que hablara con una persona y luego con otra, y como resultado tuve la oportunidad de demostrar el sistema a un gerente de búsqueda superior muy alto.
La respuesta no era la que esperaba . Para demostrar los resultados del motor de conocimiento de [libros de autores franceses], realizó una búsqueda en Google, mostró diez líneas con enlaces azules y dijo que Google podría hacer lo mismo. Además, no quieren tomar tráfico de los sitios porque se enojan.
Si cree que tiene razón, piense en esto: cuando Google realiza una búsqueda en Internet, realmente no comprende la solicitud. El sistema busca las palabras correctas en la posición correcta, teniendo en cuenta el peso de la página, etc. Este es un sistema muy complejo, pero no comprende ni la consulta ni los resultados. El usuario mismo hace todo el trabajo: leer, analizar, extraer la información necesaria de los resultados y búsquedas adicionales, agregar una lista completa de resultados, etc.
Por ejemplo, para [libros de autores franceses] una persona primero intentará encontrar una lista exhaustiva, aunque no se encuentre una página con dicha lista. Luego, clasifique estos libros por años de publicación o filtre por editores, etc. Todo esto requiere que una persona procese una gran cantidad de información, numerosas búsquedas y procese los resultados. Cerebro puede reducir estos esfuerzos y hacer que la interacción del usuario sea simple e impecable.
Pero entonces no hubo una comprensión completa de la importancia del gráfico de conocimiento. El manual no estaba seguro de su utilidad o de cómo relacionarlo con la búsqueda.
Este nuevo enfoque del conocimiento no es fácil para la organización que ha logrado un éxito tan significativo al proporcionar a los usuarios enlaces a páginas web.En el transcurso del año, luché con un malentendido de los gerentes, y finalmente me di por vencido. Un gerente de la oficina de Shanghai se dirigió a mí y le entregué el proyecto en junio de 2011. Le puso un equipo de 15 ingenieros. Pasé una semana en Shanghai, pasando a los ingenieros todo lo que creé y aprendí. DH también estuvo involucrado en este negocio, y dirigió el equipo durante mucho tiempo.
Problema de profundidad de unión
En el sistema de gráficos Cerebro, había un problema con la profundidad de la unión. La unión se realiza cuando se necesita el resultado de una consulta temprana para completar una posterior. Una unión típica incluye algunos
SELECT , es decir, un filtro en ciertos resultados de un conjunto de datos universal, y luego estos resultados se utilizan para filtrar por otra parte del conjunto de datos. Lo explicaré con un ejemplo.
Digamos que quieres saber [las personas en SF que comen sushi]. A todas las personas se les asignan algunos datos, incluido quién vive en qué ciudad y qué tipo de alimentos comen.
La consulta anterior es una combinación de un solo nivel. Si la aplicación accede a la base de datos, realizará una solicitud para el primer paso. Luego, algunas consultas (una consulta para cada resultado) para averiguar qué come cada persona, eligiendo solo a quienes comen sushi.
El segundo paso sufre el problema del despliegue. Si el primer paso da un millón de resultados (la población de San Francisco), entonces el segundo paso se debe dar a todos, previa solicitud, preguntando por sus hábitos alimenticios y luego aplicando un filtro.

Los ingenieros de sistemas distribuidos generalmente resuelven este problema por
difusión , es decir, por distribución ubicua. Acumulan los resultados correspondientes y realizan una solicitud a cada servidor del clúster. Esto proporciona una unión, pero causa problemas con la latencia de la solicitud.
La difusión no funciona bien en un sistema distribuido.
Jeff Dean de Google explica mejor este problema en su discurso "Lograr una respuesta rápida en grandes servicios en línea" (
videos ,
diapositivas ). El retraso total siempre es mayor que el retraso del componente más lento.
El deslumbramiento pequeño en las computadoras individuales causa demoras, y la inclusión de muchas computadoras en la consulta aumenta drásticamente la probabilidad de demoras.Considere un servidor con un retraso de más de 1 ms en el 50% de los casos, y más de 1 s en el 1% de los casos. Si la solicitud va solo a uno de esos servidores, solo el 1% de las respuestas exceden un segundo. Pero si la solicitud va a cientos de dichos servidores, el 63% de las respuestas exceden un segundo.
Por lo tanto, la transmisión de una solicitud aumenta considerablemente el retraso. Ahora piense, y si necesita dos, tres o más asociaciones? Es demasiado lento para ejecutar en tiempo real.
El problema de la implementación del ventilador cuando la transmisión de solicitud es inherente a la mayoría de las bases de datos de gráficos de bases de datos no nativas, incluido el
gráfico Janus ,
Twitter FlockDB y
Facebook TAO .
Las asociaciones distribuidas son un problema complejo. Las bases de datos de gráficos nativas permiten evitar este problema almacenando un conjunto de datos universal dentro de un único servidor (base de datos independiente) y realizando todas las uniones sin acceder a otros servidores. Por ejemplo,
Neo4j hace esto.
Dgraph: sindicatos con profundidad arbitraria
Después de completar el trabajo en Cerebro y tener experiencia en la construcción de un sistema de gestión de gráficos, participé en el proyecto Dgraph, convirtiéndome en uno de los tres gerentes técnicos del proyecto. Aplicamos conceptos innovadores que resolvieron el problema de la profundidad de la unión.
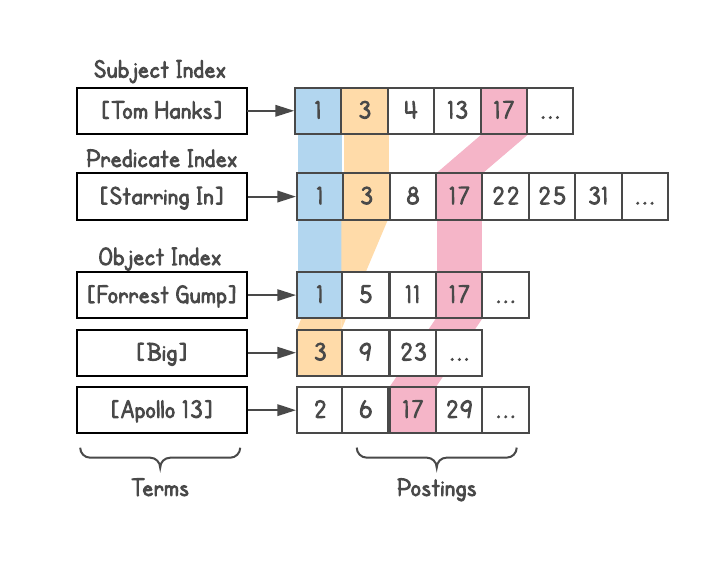
En particular, Dgraph separa los datos del gráfico para que cada combinación pueda ser realizada completamente por una máquina. Volviendo al
subject-predicate-object (SPO), cada instancia de Dgraph contiene todos los sujetos y objetos correspondientes a cada predicado en esta instancia. Varios predicados se almacenan en una instancia, cada uno completamente almacenado.
Esto nos permitió cumplir solicitudes con una profundidad arbitraria de asociaciones , eliminando el problema del despliegue del ventilador durante la transmisión. Por ejemplo, la consulta [personas en SF que comen sushi] generará un
máximo de dos llamadas de red en la base de datos, independientemente del tamaño del clúster. El primer desafío será encontrar a todas las personas que viven en San Francisco. La segunda solicitud enviará esta lista para cruzarse con todas las personas que comen sushi. Luego puede agregar restricciones o extensiones adicionales, cada paso aún no permite más de una llamada de red.

Esto crea el problema de predicados muy grandes en el mismo servidor, pero se puede resolver dividiendo aún más los predicados entre dos o más instancias a medida que crece el tamaño. En el peor de los casos, un predicado se dividirá en todo el clúster. Pero esto sucederá solo en una situación fantástica, cuando todos los datos correspondan a un solo predicado. En otros casos, este enfoque puede reducir significativamente el retraso de las solicitudes en sistemas reales.
Sharding no fue la única innovación en Dgraph. A todos los objetos se les asignaron identificadores enteros, se ordenaron y guardaron en forma de una lista (lista de publicaciones) para cruzar rápidamente dichas listas más adelante. Esto le permite filtrar rápidamente durante la fusión, encontrar enlaces comunes, etc. Las ideas de los motores de búsqueda de Google también son útiles aquí.
Combinando todos los bloques de OneBox a través de Plasma
El dgraph de Google no era una base de datos . Este fue uno de los subsistemas, que también respondió a las actualizaciones. Entonces ella necesitaba indexación. Tengo una amplia experiencia trabajando con sistemas de indexación incremental en tiempo real que se ejecutan con
cafeína .
Comencé un proyecto para unificar todos los OneBox dentro de este sistema de indexación de gráficos, incluidos el clima, los horarios de vuelos, los eventos, etc. Es posible que no conozca el término OneBox, pero definitivamente lo vio: esta es una ventana separada que aparece cuando se ejecutan ciertos tipos de consultas, donde Google devuelve información más rica. Para ver OneBox en acción, intente [
weather in sf ].
Anteriormente, cada OneBox trabajaba en un backend autónomo y contaba con el apoyo de diferentes grupos de desarrollo.
Había un rico conjunto de datos estructurados, pero las unidades OneBox no intercambiaban datos entre sí. En primer lugar, diferentes backends aumentaron los costos laborales muchas veces. En segundo lugar, la falta de intercambio de información limitó el rango de solicitudes a las que Google podría responder.
Por ejemplo, [eventos en SF] podría mostrar eventos y [weather in SF] podría mostrar el clima. Pero si [los eventos en SF] entendieron que estaba lloviendo ahora, entonces podría filtrar u ordenar los eventos por tipo "en interiores" o "al aire libre" (
quizás es mejor ir al cine en lugar de fútbol en una lluvia intensa) )
Con la ayuda del equipo Metaweb, comenzamos a convertir todos estos datos al formato SPO e indexarlos con un solo sistema. Lo llamé
Plasma, un motor de indexación de gráficos en tiempo real para servir Dgraph.
Gestión de Leapfrog
Al igual que Cerebro, el proyecto Plasma recibió pocos recursos, pero continuó ganando impulso. Al final, cuando la gerencia se dio cuenta de que los bloques OneBox eran inevitablemente parte de nuestro proyecto, inmediatamente decidió poner a las
"personas adecuadas" para administrar el sistema de gráficos. En el apogeo del juego político, tres líderes fueron reemplazados, cada uno de los cuales tenía cero experiencia trabajando con gráficos.
Durante este salto de Dgraph, los gerentes de proyecto de
Spanner llamaron a Dgraph
un sistema
demasiado complejo . Como referencia, Spanner es una base de datos SQL distribuida en todo el mundo que necesita su propio reloj GPS para garantizar la coherencia global.
La ironía de esto sigue soplando mi techo.Dgraph fue cancelado, el plasma sobrevivió. Y al frente del proyecto, pusieron un nuevo equipo con un nuevo líder, con una jerarquía clara y reportando al CEO. El nuevo equipo, con una comprensión deficiente de los gráficos y los problemas relacionados, decidió crear un subsistema de infraestructura basado en el índice de búsqueda de Google existente (como lo hice para Cerebro). Sugerí usar el sistema que ya hice para Cerebro, pero fue rechazado. Modifiqué Plasma para rastrear y expandir cada nodo de conocimiento en varios niveles para que el sistema pueda verlo como un documento web. Llamaron a este sistema TS (
abreviatura ).
Esto significaba que el nuevo subsistema no podría realizar asociaciones profundas. Nuevamente, esta es una maldición que veo en muchas compañías porque los ingenieros comienzan con la idea equivocada de que "los gráficos son un problema simple que se puede resolver simplemente construyendo una capa encima de otro sistema".
Unos meses más tarde, en mayo de 2013, abandoné Google después de trabajar en Dgraph / Plasma durante unos dos años.
Epílogo
- Unos años más tarde, la unidad de "Infraestructura de búsqueda de Internet" pasó a llamarse "Infraestructura de búsqueda de Internet y Gráfico de conocimiento", y el líder a quien una vez le mostré a Cerebro encabezó la dirección de "Gráfico de conocimiento", hablando sobre cómo pretenden reemplazar los simples enlaces de conocimiento azul para responder preguntas de los usuarios directamente con la mayor frecuencia posible.
- Cuando el equipo de Shanghai que trabajaba en Cerebro estaba cerca de ponerlo en producción, el proyecto les fue quitado y entregado a la división de Nueva York. Al final, se lanzó como Knowledge Strip. Si está buscando [ películas de tom hanks ], lo verá en la parte superior. Ha mejorado un poco desde el primer lanzamiento, pero aún no admite el nivel de filtrado y clasificación establecido en Cerebro.
- Los tres gerentes técnicos que trabajaron en Dgraph (incluido yo mismo) finalmente abandonaron Google. Hasta donde yo sé, el resto ahora está trabajando en Microsoft y LinkedIn.
- Logré obtener dos promociones en Google, y se suponía que obtendría una tercera cuando saliera de la compañía como ingeniero de software senior (ingeniero de software senior).
- A juzgar por algunos rumores fragmentarios, la versión actual de TS está realmente muy cerca del diseño del sistema de gráficos Cerebro, y cada sujeto, predicado y objeto tiene un índice. Por lo tanto, ella todavía sufre el problema de la profundidad de la unificación.
- Desde entonces, el plasma se ha reescrito y renombrado, pero continúa funcionando como un sistema de indexación de gráficos en tiempo real para TS. Juntos, continúan publicando y procesando todos los datos estructurados en Google, incluido el Gráfico de conocimiento.
- La incapacidad de Google para hacer sindicatos profundos es visible en muchos lugares. Por ejemplo, todavía no vemos el intercambio de datos entre los bloques de OneBox: [ciudades por la mayor cantidad de lluvia en Asia] no da una lista de ciudades, aunque todos los datos están en la columna de conocimiento (en cambio, la página web se cita en los resultados de búsqueda); [los eventos en SF] no se pueden filtrar por clima; Los resultados [de los presidentes de EE. UU.] No se ordenan, filtran ni amplían por otros hechos: sus hijos o las escuelas donde estudiaron. Creo que esta fue una de las razones de la interrupción del soporte de Freebase .
Dgraph: Ave Fénix
Dos años después de dejar Google, decidí
desarrollar Dgraph . En otras compañías, veo la misma indecisión con respecto a los gráficos que en Google. Hubo muchas soluciones inacabadas en el espacio gráfico, en particular, muchas soluciones personalizadas apresuradamente ensambladas sobre bases de datos relacionales o NoSQL, o como una de las muchas características de bases de datos multimodelo. Si había una solución nativa, entonces sufría problemas de escalabilidad.
Nada de lo que vi tenía una historia coherente con un diseño productivo y escalable.
Construir una base de datos de gráficos escalables horizontalmente con baja latencia y uniones arbitrarias de profundidad es una tarea extremadamente difícil , y quería asegurarme de que construimos el Dgraph correctamente.
El equipo de Dgraph pasó los últimos tres años no solo estudiando mi propia experiencia, sino también dedicando muchos de sus esfuerzos al diseño, creando una base de datos gráfica que no tiene análogos en el mercado. Por lo tanto, las empresas tienen la oportunidad de utilizar una solución confiable, escalable y productiva en lugar de otra solución a medio terminar.