La detección de ataques ha sido parte de la seguridad de la información durante décadas. Las primeras implementaciones conocidas del sistema de detección de intrusos (IDS) se remontan a principios de la década de 1980.
Hoy en día, existe toda una industria de detección de ataques. Existen varios tipos de productos, como IDS, IPS, WAF y soluciones de firewall, la mayoría de los cuales ofrecen detección de ataques basada en reglas. La idea de utilizar algún tipo de detección de anomalías estadísticas para identificar ataques en producción no parece tan realista como solía ser. Pero, ¿está justificado ese supuesto?
Detección de anomalías en aplicaciones web.
Los primeros firewalls diseñados para detectar ataques a aplicaciones web aparecieron en el mercado a principios de la década de 1990. Tanto las técnicas de ataque como los mecanismos de protección han evolucionado dramáticamente desde entonces, con los atacantes corriendo para dar un paso adelante.
La mayoría de los cortafuegos de aplicaciones web (WAF) actuales intentan detectar ataques de manera similar, con un motor basado en reglas incrustado en un proxy inverso de algún tipo. El ejemplo más destacado es mod_security, un módulo WAF para el servidor web Apache, que se creó en 2002. La detección basada en reglas tiene algunas desventajas: por ejemplo, no puede detectar nuevos ataques (días cero), aunque estos mismos ataques podría ser fácilmente detectado por un experto humano. Este hecho no es sorprendente, ya que el cerebro humano funciona de manera muy diferente a un conjunto de expresiones regulares.
Desde la perspectiva de un WAF, los ataques se pueden dividir en los basados en secuencia (series de tiempo) y los que consisten en una sola solicitud o respuesta HTTP. Nuestra investigación se centró en detectar el último tipo de ataques, que incluyen:
- Inyección SQL
- Secuencias de comandos entre sitios
- Inyección de entidad externa XML
- Recorrido transversal
- OS al mando
- Inyección de objetos
Pero primero preguntémonos: ¿cómo lo haría un humano?
¿Qué haría un humano al ver una sola solicitud?
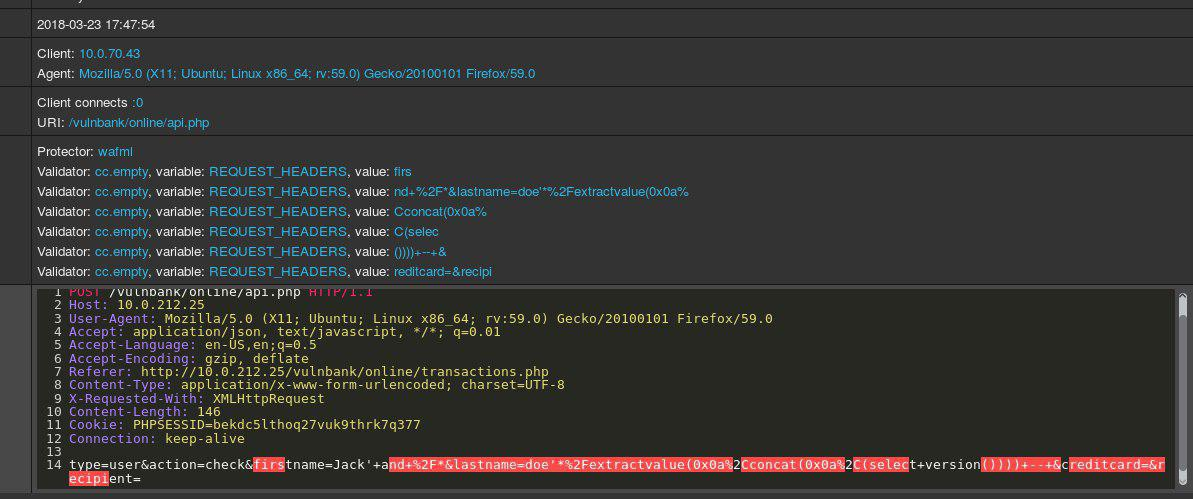
Eche un vistazo a una solicitud HTTP de muestra regular para alguna aplicación:
Si tuviera que detectar solicitudes maliciosas enviadas a una aplicación, lo más probable es que desee observar solicitudes benignas por un tiempo. Después de examinar las solicitudes de varios puntos finales de ejecución de aplicaciones, tendrá una idea general de cómo se estructuran las solicitudes seguras y qué contienen.
Ahora se le presenta la siguiente solicitud:

Inmediatamente intuyes que algo está mal. Lleva más tiempo entender qué es exactamente, y tan pronto como localice la parte exacta de la solicitud que es anómala, puede comenzar a pensar qué tipo de ataque es. Esencialmente, nuestro objetivo es hacer que nuestra IA de detección de ataques aborde el problema de una manera que se asemeje a este razonamiento humano.
Para complicar nuestra tarea, parte del tráfico, aunque pueda parecer malicioso a primera vista, en realidad podría ser normal para un sitio web en particular.
Por ejemplo, veamos la siguiente solicitud:
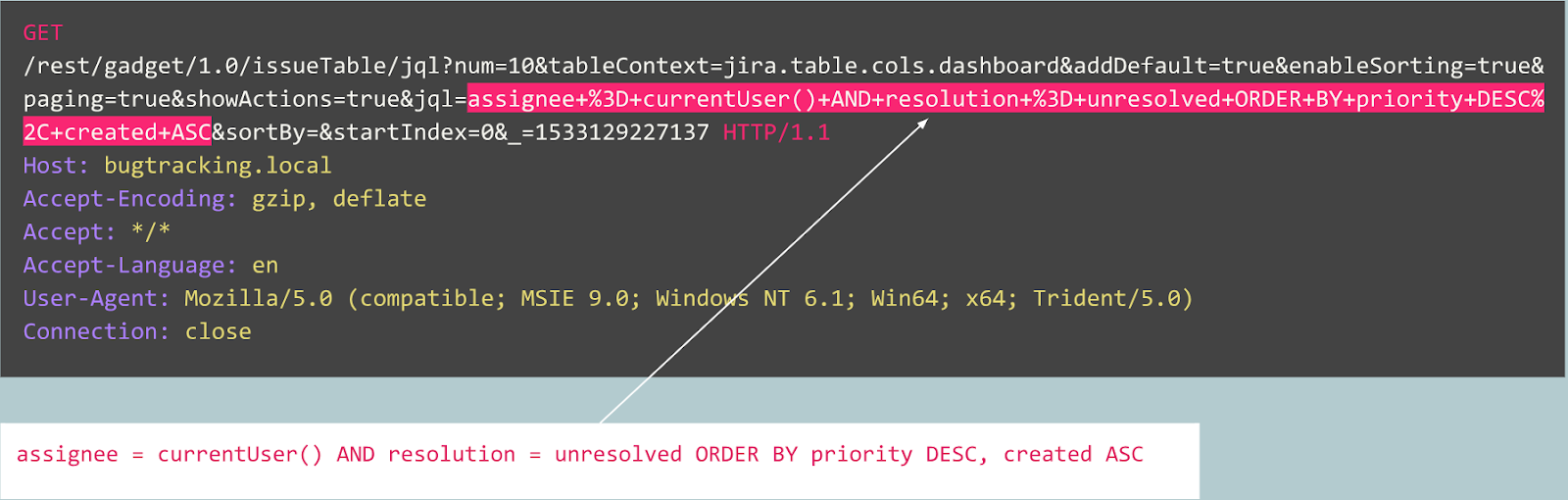
¿Es una anomalía? En realidad, esta solicitud es benigna: es una solicitud típica relacionada con la publicación de errores en el rastreador de errores de Jira.
Ahora echemos un vistazo a otro caso:

Al principio, la solicitud se parece al registro de usuario típico en un sitio web desarrollado por Joomla CMS. Sin embargo, la operación solicitada es "user.register" en lugar del normal "registration.register". La primera opción está en desuso y contiene una vulnerabilidad que permite a cualquiera registrarse como administrador.
Este exploit se conoce como "Joomla <3.6.4 Creación de cuenta / Escalada de privilegios" (CVE-2016-8869, CVE-2016-8870).

Como empezamos
Primero echamos un vistazo a investigaciones anteriores, ya que se han hecho muchos intentos de crear diferentes algoritmos estadísticos o de aprendizaje automático para detectar ataques a lo largo de las décadas. Uno de los enfoques más frecuentes es resolver la tarea de asignación a una clase ("solicitud benigna", "inyección de SQL", "XSS", "CSRF", etc.). Si bien se puede lograr una precisión decente con la clasificación de un conjunto de datos determinado, este enfoque no resuelve algunos problemas muy importantes:
- La elección del conjunto de clases . ¿Qué sucede si su modelo durante el aprendizaje se presenta con tres clases (“benigno,“ “SQLi”, “XSS”) pero en la producción encuentra un ataque CSRF o incluso una técnica de ataque completamente nueva?
- El significado de estas clases . Suponga que necesita proteger a 10 clientes, cada uno de ellos ejecutando aplicaciones web completamente diferentes. Para la mayoría de ellos, no tendría idea de cómo se ve realmente un solo ataque de "inyección SQL" contra su aplicación. Esto significa que tendría que construir artificialmente sus conjuntos de datos de aprendizaje, lo cual es una mala idea, porque terminará aprendiendo de datos con una distribución completamente diferente a sus datos reales.
- Interpretabilidad de los resultados de su modelo . Genial, así que al modelo se le ocurrió la etiqueta "Inyección SQL", ¿y ahora qué? Usted y, lo que es más importante, su cliente, que es el primero en ver la alerta y generalmente no es un experto en ataques web, tiene que adivinar qué parte de la solicitud el modelo considera malicioso.
Teniendo esto en cuenta, decidimos probar la clasificación de todos modos.
Como el protocolo HTTP está basado en texto, era obvio que teníamos que echar un vistazo a los clasificadores de texto modernos. Uno de los ejemplos bien conocidos es el análisis de sentimientos del conjunto de datos de revisión de películas IMDB. Algunas soluciones utilizan redes neuronales recurrentes (RNN) para clasificar estas revisiones. Decidimos usar un modelo de clasificación RNN similar con algunas pequeñas diferencias. Por ejemplo, los RNN de clasificación de lenguaje natural usan incrustaciones de palabras, pero no está claro qué palabras hay en un lenguaje no natural como HTTP. Es por eso que decidimos usar incrustaciones de personajes en nuestro modelo.
Las incrustaciones listas para usar son irrelevantes para resolver el problema, por lo que utilizamos asignaciones simples de caracteres a códigos numéricos con varios marcadores internos como
GO y
EOS .
Después de que terminamos el desarrollo y las pruebas del modelo, todos los problemas previstos se cumplieron, pero al menos nuestro equipo pasó de la reflexión inactiva a algo productivo.
Como procedimos
A partir de ahí, decidimos intentar hacer que los resultados de nuestro modelo sean más interpretables. En algún momento nos encontramos con el mecanismo de "atención" y comenzamos a integrarlo en nuestro modelo. Y eso arrojó algunos resultados prometedores: finalmente, todo se unió y obtuvimos algunos resultados interpretables por humanos. Ahora nuestro modelo comenzó a generar no solo las etiquetas sino también los coeficientes de atención para cada carácter de la entrada.
Si eso se pudiera visualizar, por ejemplo, en una interfaz web, podríamos colorear el lugar exacto donde se ha encontrado un ataque de "Inyección SQL". Ese fue un resultado prometedor, pero los otros problemas seguían sin resolverse.
Comenzamos a ver que podríamos beneficiarnos yendo en la dirección del mecanismo de atención y alejándonos de la clasificación. Después de leer una gran cantidad de investigaciones relacionadas (por ejemplo, "La atención es todo lo que necesita", Word2Vec y codificador - arquitecturas decodificadoras) en modelos de secuencia y al experimentar con nuestros datos, pudimos crear un modelo de detección de anomalías que funcionaría en más o menos de la misma manera que un experto humano.
Autoencoders
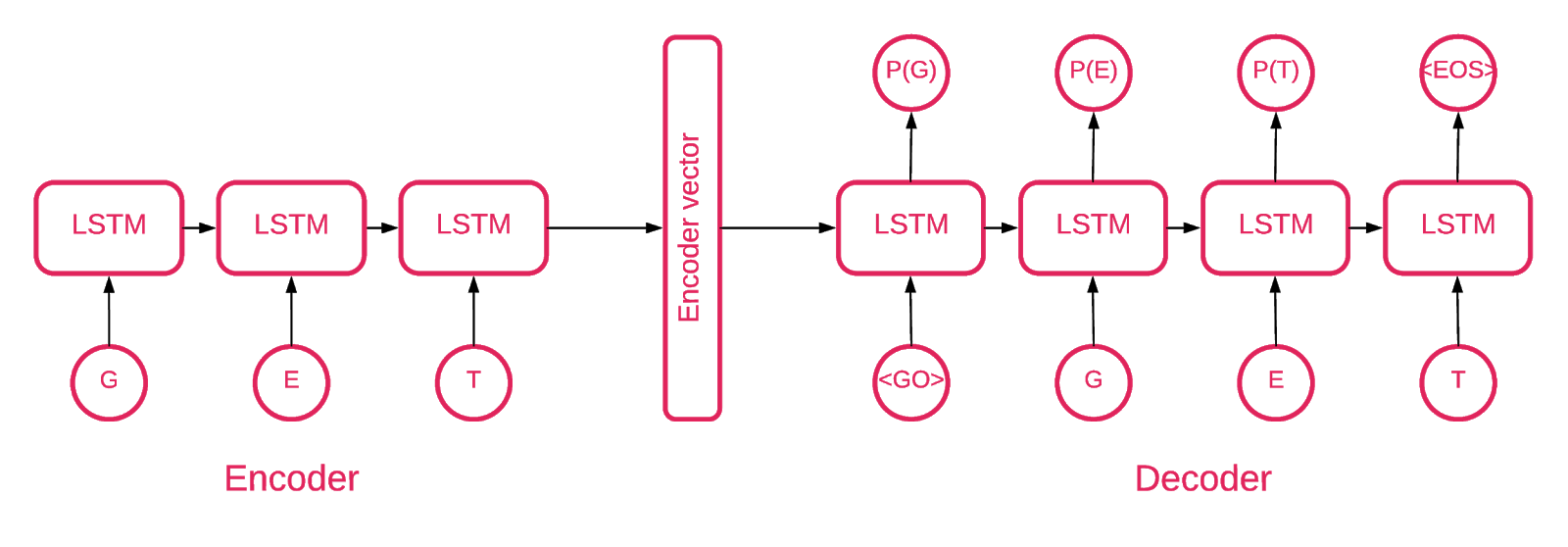
En algún momento quedó claro que un codificador automático de secuencia a secuencia se ajustaba mejor a nuestro propósito.
Un modelo de secuencia a secuencia consta de dos modelos de memoria a largo plazo (LSTM) multicapa: un codificador y un decodificador. El codificador asigna la secuencia de entrada a un vector de dimensionalidad fija. El decodificador decodifica el vector objetivo usando esta salida del codificador.
Entonces, un autoencoder es un modelo de secuencia a secuencia que establece sus valores objetivo iguales a sus valores de entrada. La idea es enseñar a la red a recrear cosas que ha visto o, en otras palabras, aproximar una función de identidad. Si el autoencoder capacitado recibe una muestra anómala, es probable que la vuelva a crear con un alto grado de error debido a que nunca antes ha visto una muestra de este tipo.
El codigo
Nuestra solución se compone de varias partes: inicialización del modelo, capacitación, predicción y validación.
La mayor parte del código ubicado en el repositorio se explica por sí mismo, nos centraremos solo en partes importantes.
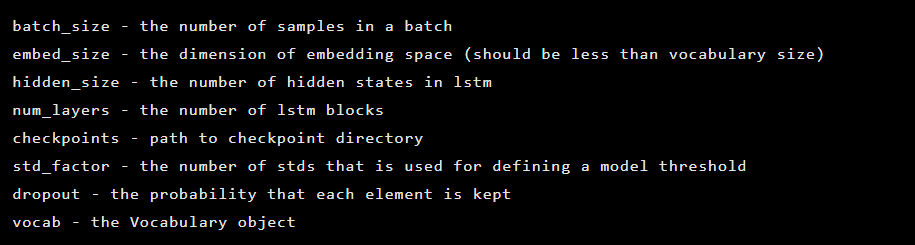
El modelo se inicializa como una instancia de la clase Seq2Seq, que tiene los siguientes argumentos de constructor:
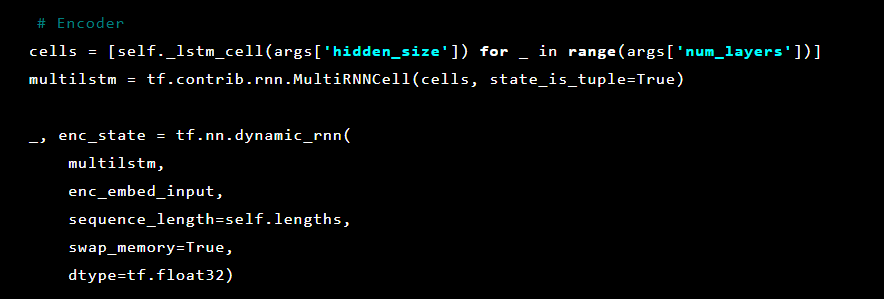
Después de eso, las capas del autoencoder se inicializan. Primero, el codificador:
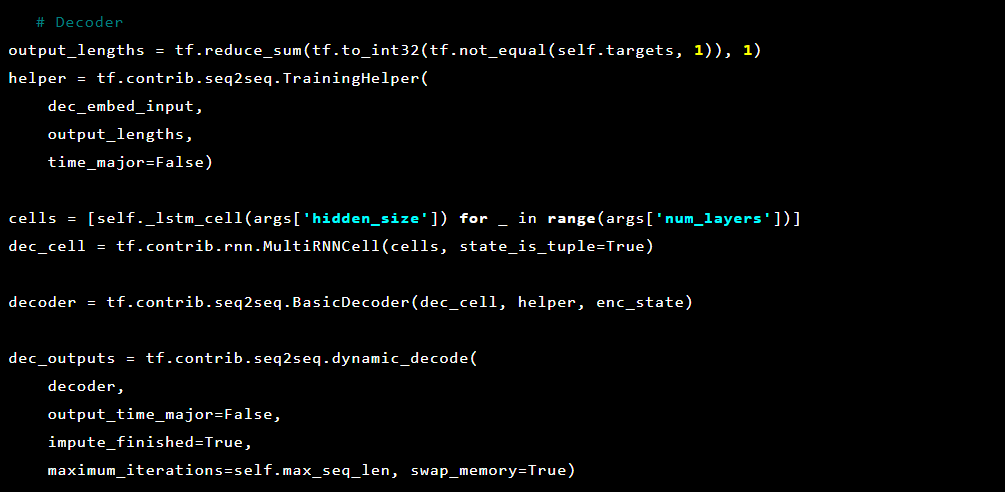
Y luego el decodificador:
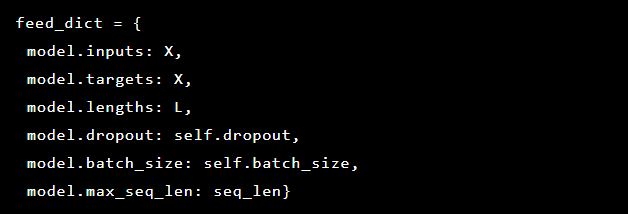
Como estamos tratando de resolver la detección de anomalías, los objetivos y las entradas son los mismos. Por lo tanto, nuestro feed_dict tiene el siguiente aspecto:
Después de cada época, el mejor modelo se guarda como un punto de control, que luego se puede cargar para hacer predicciones. Para fines de prueba, el modelo configuró y protegió una aplicación web en vivo para que fuera posible probar si los ataques reales tuvieron éxito o no.
Al estar inspirados por el mecanismo de atención, tratamos de aplicarlo al autoencoder pero notamos que la salida de probabilidades de la última capa funciona mejor para marcar las partes anómalas de una solicitud.

En la etapa de prueba con nuestras muestras obtuvimos muy buenos resultados: la precisión y la recuperación fueron cercanas a 0,99. Y la curva ROC era de alrededor de 1. Definitivamente una buena vista!
Los resultados
Nuestro modelo de codificador automático Seq2Seq descrito demostró ser capaz de detectar anomalías en solicitudes HTTP con alta precisión.
Este modelo actúa como lo hace un humano: aprende solo las solicitudes de usuario "normales" enviadas a una aplicación web. Detecta anomalías en las solicitudes y resalta el lugar exacto en la solicitud considerada anómala. Evaluamos este modelo contra ataques a la aplicación de prueba y los resultados parecen prometedores. Por ejemplo, la captura de pantalla anterior muestra cómo nuestro modelo detectó la inyección SQL dividida en dos parámetros de formulario web. Dichas inyecciones SQL están fragmentadas, ya que la carga útil de ataque se entrega en varios parámetros HTTP. Los WAF clásicos basados en reglas no logran detectar intentos de inyección de SQL fragmentados porque generalmente inspeccionan cada parámetro por sí mismos.
El código del modelo y los datos del tren / prueba se han publicado como un cuaderno Jupyter para que cualquiera pueda reproducir nuestros resultados y sugerir mejoras.
Conclusión
Creemos que nuestra tarea era bastante trivial: encontrar una forma de detectar ataques con un mínimo esfuerzo. Por un lado, buscamos evitar complicar demasiado la solución y crear una forma de detectar ataques que, como por arte de magia, aprendan a decidir por sí mismos qué es bueno y qué es malo. Al mismo tiempo, queríamos evitar problemas con el factor humano cuando un experto (falible) está decidiendo qué indica un ataque y qué no. Y, en general, el autoencoder con arquitectura Seq2Seq parece resolver bastante bien nuestro problema de detección de anomalías.
También queríamos resolver el problema de la interpretabilidad de los datos. Cuando se utilizan arquitecturas complejas de redes neuronales, es muy difícil explicar un resultado particular. Cuando se aplica una serie completa de transformaciones, la identificación de los datos más importantes detrás de una decisión se vuelve casi imposible. Sin embargo, después de repensar el enfoque de interpretación de datos por parte del modelo, pudimos obtener probabilidades para cada personaje de la última capa.
Es importante tener en cuenta que este enfoque no es una versión lista para producción. No podemos revelar los detalles de cómo este enfoque podría implementarse en un producto real. Pero le advertiremos que no es posible simplemente tomar este trabajo y "enchufarlo". Hacemos esta advertencia porque después de publicar en GitHub, comenzamos a ver a algunos usuarios que intentaron simplemente implementar nuestra solución actual al por mayor en sus propios proyectos, con resultados fallidos (y poco sorprendentes).
La prueba de concepto está disponible
aquí (github.com).
Autores: Alexandra Murzina (
murzina_a ), Irina Stepanyuk (
GitHub ), Fedor Sakharov (
GitHub ), Arseny Reutov (
Raz0r )
Lectura adicional
- Comprender las redes LSTM
- Atención y redes neuronales recurrentes aumentadas
- La atención es todo lo que necesitas
- La atención es todo lo que necesitas (anotado)
- Tutorial de traducción automática neuronal (seq2seq)
- Autoencoders
- Secuencia a secuencia de aprendizaje con redes neuronales
- Construcción de codificadores automáticos en Keras