Hackear música para democratizar el contenido derivadoDescargo de responsabilidad: toda la propiedad intelectual, diseños y métodos descritos en este artículo se divulgan en los documentos US10014002B2 y US9842609B2.
Ojalá pudiera volver a 1965, llamar a la puerta del estudio de Abby Road con un pase, entrar y escuchar las voces reales de Lennon y McCartney ... Bueno, intentémoslo. Entrada: MP3 de calidad media de los Beatles
Podemos solucionarlo . La pista superior es la mezcla de entrada, la pista inferior son las voces aisladas que nuestra red neuronal ha resaltado.
Formalmente, este problema se conoce como
separación de fuentes de sonido o
separación de la señal (separación de fuente de audio). Consiste en restaurar o reconstruir una o más de las señales originales, que, como resultado de un proceso
lineal o convolucional , se mezclan con otras señales. Este campo de investigación tiene muchas aplicaciones prácticas, incluida la mejora de la calidad del sonido (voz) y la eliminación del ruido, las mezclas de música, la distribución espacial del sonido, la remasterización, etc. Los ingenieros de sonido a veces llaman a esta técnica desmezcla. Hay muchos recursos sobre este tema, desde la separación de señales ciegas con análisis de componentes independientes (ICA) hasta la factorización semi-controlada de matrices no negativas y terminando con enfoques posteriores basados en redes neuronales. Puede encontrar buena información sobre los dos primeros puntos en
estas mini-guías de CCRMA, que en algún momento me fueron muy útiles.
Pero antes de sumergirse en el desarrollo ... bastante filosofía de aprendizaje automático aplicada ...Estaba involucrado en el procesamiento de señales e imágenes incluso antes de que el eslogan "el aprendizaje profundo resuelva todo" se haya extendido, por lo que puedo presentarle una solución como un viaje de
ingeniería de características y mostrar
por qué una red neuronal es el mejor enfoque para este problema en particular . Por qué Muy a menudo, veo que la gente escribe algo como esto:
“Con el aprendizaje profundo, ya no tiene que preocuparse por elegir funciones; lo hará por ti ".o peor ...
"La diferencia entre el aprendizaje automático y el aprendizaje profundo [oye ... ¡el aprendizaje profundo sigue siendo el aprendizaje automático!] Es
que en ML tú mismo extraes los atributos, y en el aprendizaje profundo esto ocurre automáticamente dentro de la red".Estas generalizaciones probablemente provienen del hecho de que los DNN pueden ser muy efectivos para explorar buenos espacios ocultos. Pero entonces es imposible generalizar. Estoy muy molesto cuando los recién graduados y practicantes sucumben a los conceptos erróneos anteriores y adoptan el enfoque de "aprendizaje profundo". Como, es suficiente arrojar un montón de datos sin procesar (incluso después de un pequeño procesamiento preliminar), y todo funcionará como debería. En el mundo real, debe ocuparse de cosas como el rendimiento, la ejecución en tiempo real, etc. Debido a tales conceptos erróneos, estará atrapado en el modo de experimento durante mucho tiempo ...
Feature Engineering sigue siendo una disciplina muy importante en el diseño de redes neuronales artificiales. Como en cualquier otra técnica de ML, en la mayoría de los casos, es lo que distingue las soluciones efectivas del nivel de producción de los experimentos fallidos o ineficaces. Una comprensión profunda de sus datos y su naturaleza aún significa mucho ...De la A a la Z
Ok, terminé el sermón. ¡Ahora veamos por qué estamos aquí! Al igual que con cualquier problema de procesamiento de datos, primero veamos cómo se ve. Eche un vistazo a la siguiente pieza de voz de la grabación original del estudio.
Voces de estudio 'One Last Time', Ariana GrandeNo es demasiado interesante, ¿verdad? Bueno, esto es porque visualizamos la señal
a tiempo . Aquí solo vemos cambios de amplitud con el tiempo. Pero puede extraer todo tipo de otras cosas, como las envolventes de amplitud (envoltura), los valores cuadrados medios de raíz (RMS), la tasa de cambio de valores positivos de amplitud a negativos (tasa de cruce por cero), etc., pero estos
signos son demasiado
primitivos y no lo suficientemente distintivos, para ayudar en nuestro problema Si queremos extraer las voces de una señal de audio, primero debemos determinar de alguna manera la estructura del habla humana. Afortunadamente, la
Transformada de Fourier de Ventana (STFT) viene al rescate.
Espectro de amplitud STFT - tamaño de ventana = 2048, superposición = 75%, escala de frecuencia logarítmica [Sonic Visualizer]Aunque me encanta el procesamiento del habla y definitivamente me encanta jugar con
simulaciones de filtros de entrada, cepstrums, sottotami, LPC, MFCC, etc., omitiremos todas estas tonterías y nos centraremos en los elementos principales relacionados con nuestro problema para que el artículo pueda ser entendido por la mayor cantidad de personas posible, no solo especialistas en procesamiento de señales.
Entonces, ¿qué nos dice la estructura del discurso humano?
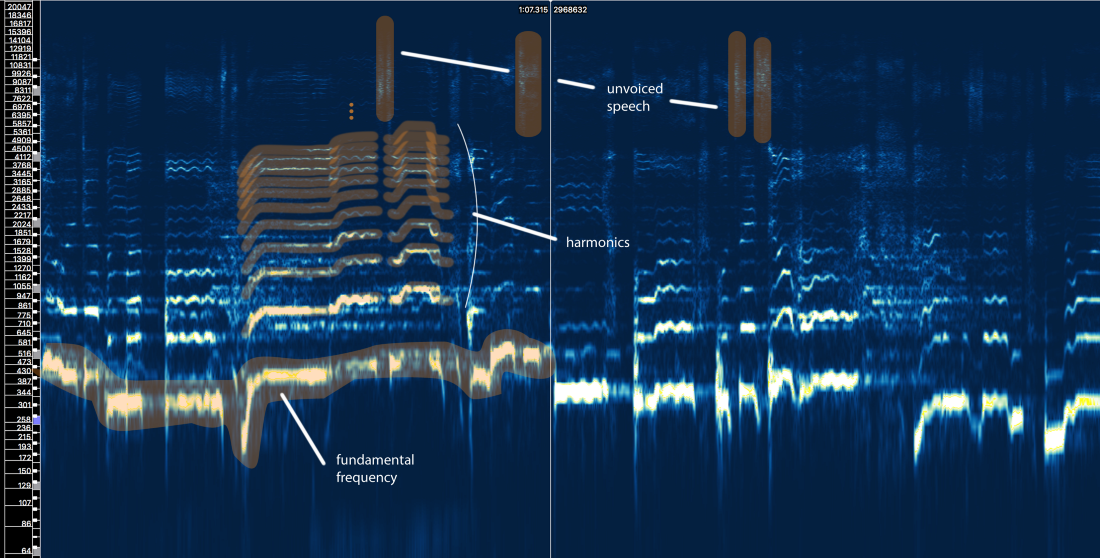
Bueno, podemos definir tres elementos principales aquí:
- La frecuencia fundamental (f0), que está determinada por la frecuencia de vibración de nuestras cuerdas vocales. En este caso, Ariana canta en el rango de 300-500 Hz.
- Una serie de armónicos por encima de f0 que siguen una forma o patrón similar. Estos armónicos aparecen en frecuencias que son múltiplos de f0.
- Discurso sordo , que incluye consonantes como 't', 'p', 'k', 's' (que no se produce por la vibración de las cuerdas vocales), respiración, etc. Todo esto se manifiesta en forma de ráfagas cortas en la región de alta frecuencia.
Primer intento con reglas
Olvidemos por un segundo lo que se llama aprendizaje automático. ¿Se puede desarrollar un método de extracción vocal basado en nuestro conocimiento de la señal? Déjame intentarlo ...
Ingenuo aislamiento vocal V1.0:- Identificar áreas con voces. Hay muchas cosas en la señal original. Queremos centrarnos en aquellas áreas que realmente contienen contenido vocal e ignorar todo lo demás.
- Distinguir entre voz y voz no hablada. Como hemos visto, son muy diferentes. Probablemente necesiten ser manejados de manera diferente.
- Evaluar el cambio en la frecuencia fundamental a lo largo del tiempo.
- Basado en el pin 3, aplique algún tipo de máscara para capturar armónicos.
- Haz algo con fragmentos de discursos sordos ...

Si trabajamos dignamente, el resultado debe ser una
máscara suave o de
bits , cuya aplicación a la amplitud del STFT (multiplicación por elementos) da una reconstrucción aproximada de la amplitud de las voces STFT. Luego combinamos este STFT vocal con información sobre la fase de la señal original, calculamos el STFT inverso y obtenemos la señal de tiempo del vocal reconstruido.
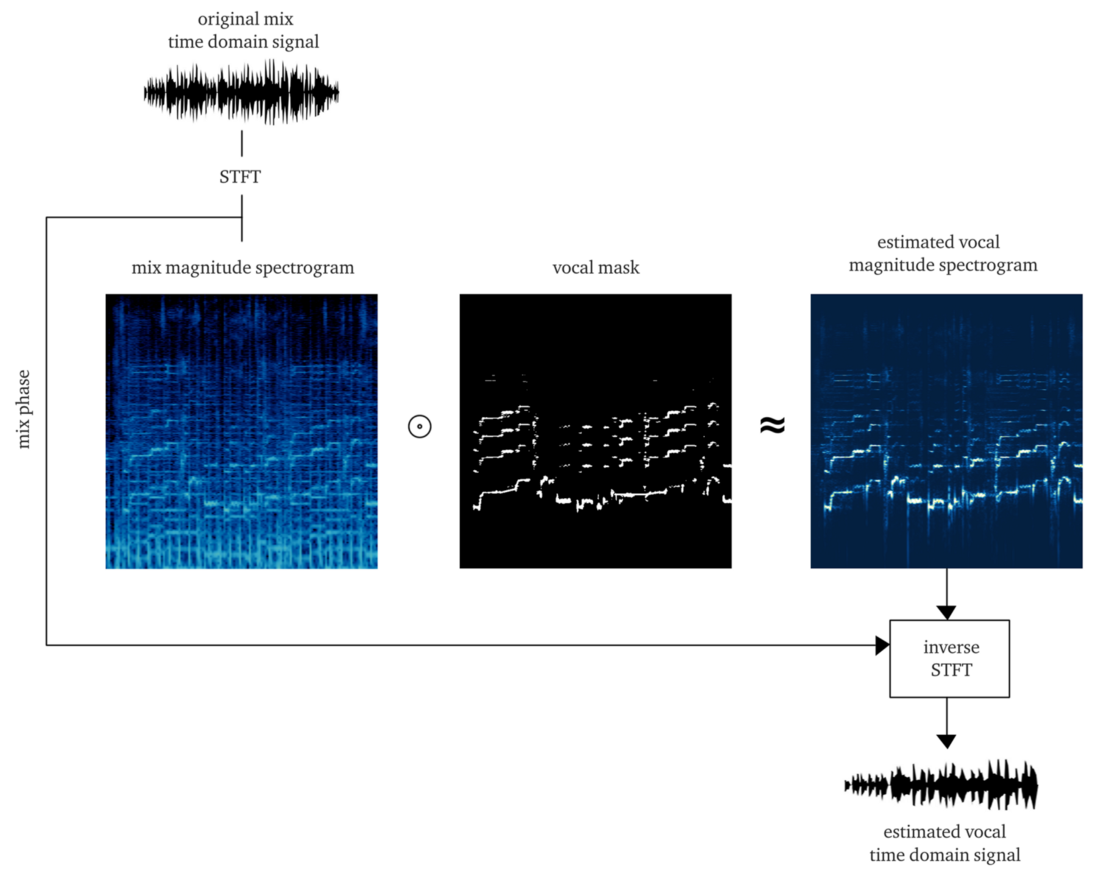
Hacerlo desde cero ya es un gran trabajo. Pero en aras de la demostración, la implementación del
algoritmo pYIN es aplicable . Aunque está destinado a resolver el paso 3, pero con la configuración correcta, realiza decentemente los pasos 1 y 2, rastreando la base vocal incluso en presencia de música. El siguiente ejemplo contiene la salida después de procesar este algoritmo, sin procesar el habla sin voz.
Y que ...? Parece haber hecho todo el trabajo, pero no hay buena calidad y cierre. Quizás al gastar más tiempo, energía y dinero, mejoraremos este método ...
Pero déjame preguntarte ...
¿Qué sucede si aparecen
algunas voces en la pista y, sin embargo, a menudo se encuentra en al menos el 50% de las pistas profesionales modernas?
¿Qué sucede si las voces son procesadas por
reverberación, retrasos y otros efectos? Echemos un vistazo al último coro de Ariana Grande de esta canción.
¿Ya sientes dolor ...? Yo soy
Tales métodos sobre reglas estrictas se convierten rápidamente en un castillo de naipes. El problema es muy complicado. Demasiadas reglas, demasiadas excepciones y demasiadas condiciones diferentes (efectos y configuraciones de mezcla). Un enfoque de varios pasos también implica que los errores en un paso extienden los problemas al siguiente paso. Mejorar cada paso será muy costoso: tomará una gran cantidad de iteraciones para hacerlo bien. Y por último, pero no menos importante, es probable que al final obtengamos un transportador muy intensivo en recursos, que en sí mismo puede negar todos los esfuerzos.
En tal situación, es hora de comenzar a pensar en un enfoque más integral y dejar que ML descubra parte de los procesos y operaciones básicos necesarios para resolver el problema. Pero aún tenemos que mostrar nuestras habilidades y participar en la ingeniería de características, y verá por qué.Hipótesis: use la red neuronal como una función de transferencia que traduce mezclas en voces
Mirando los logros de las redes neuronales convolucionales en el procesamiento de fotos, ¿por qué no aplicar el mismo enfoque aquí?
 Las redes neuronales resuelven con éxito problemas tales como la coloración de imágenes, el enfoque y la resolución.
Las redes neuronales resuelven con éxito problemas tales como la coloración de imágenes, el enfoque y la resolución.Al final, puedes imaginar la señal de sonido "como una imagen" usando la transformada de Fourier a corto plazo, ¿verdad? Aunque estas
imágenes de sonido no corresponden a la distribución estadística de imágenes naturales, todavía tienen patrones espaciales (en el espacio de tiempo y frecuencia) sobre los cuales entrenar la red.
 Izquierda: ritmo de batería y línea de base a continuación, varios sonidos de sintetizador en el medio, todos mezclados con voces. Derecha: solo voces
Izquierda: ritmo de batería y línea de base a continuación, varios sonidos de sintetizador en el medio, todos mezclados con voces. Derecha: solo vocesRealizar tal experimento sería una tarea costosa ya que es difícil obtener o generar los datos de capacitación necesarios. Pero en la investigación aplicada, siempre trato de usar este enfoque: primero,
para identificar un problema más simple que confirme los mismos principios , pero que no requiera mucho trabajo. Esto le permite evaluar la hipótesis, iterar más rápido y corregir el modelo con pérdidas mínimas si no funciona como debería.
La condición implícita es que la
red neuronal debe comprender la estructura del habla humana . Un problema más simple puede ser este: ¿
puede una red neuronal determinar la presencia del habla en un fragmento arbitrario de una grabación de sonido ? Estamos hablando de un
detector de actividad de voz (VAD) confiable, implementado en forma de un clasificador binario.
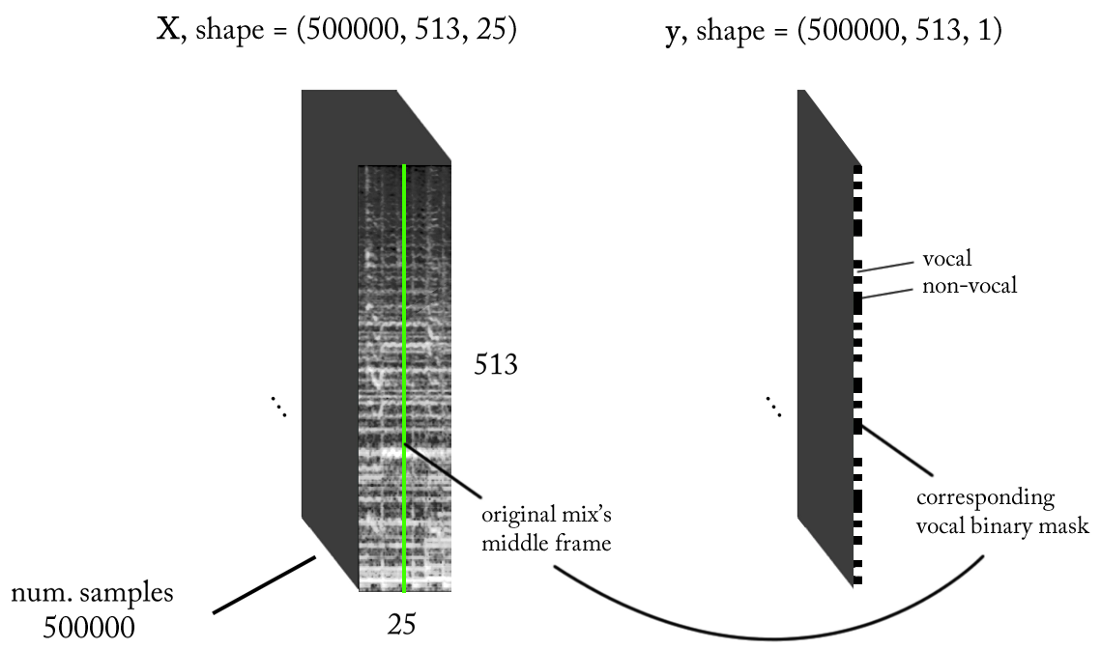
Diseñamos el espacio de los signos.
Sabemos que las señales de sonido, como la música y el habla humana, se basan en dependencias del tiempo. En pocas palabras, nada sucede de forma aislada en un momento dado. Si quiero saber si hay una voz en una pieza particular de grabación de sonido, entonces tengo que mirar las regiones vecinas. Tal
contexto de tiempo proporciona buena información sobre lo que está sucediendo en el área de interés. Al mismo tiempo, es deseable realizar una clasificación con incrementos de tiempo muy pequeños para reconocer una voz humana con la resolución de tiempo más alta posible.

Vamos a contar un poco ...
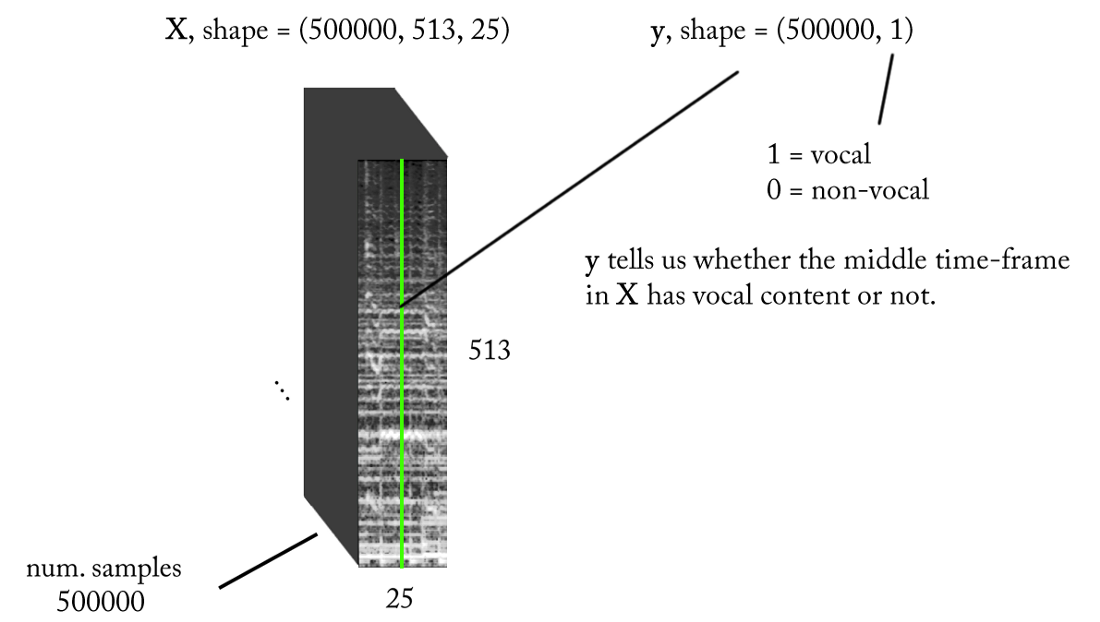
- Frecuencia de muestreo (fs): 22050 Hz (disminuimos la muestra de 44100 a 22050)
- Diseño STFT: tamaño de ventana = 1024, tamaño de salto = 256, interpolación de la escala de tiza para el filtro de ponderación, teniendo en cuenta la percepción. Dado que nuestra entrada es real , puede trabajar con la mitad de STFT (una explicación está más allá del alcance de este artículo ...) mientras mantiene el componente DC (opcional), que nos da 513 bins de frecuencia.
- Resolución de clasificación de destino: un cuadro STFT (~ 11,6 ms = 256/22050)
- Contexto de tiempo objetivo: ~ 300 milisegundos = 25 cuadros STFT.
- El número objetivo de ejemplos de entrenamiento: 500 mil.
- Suponiendo que usemos una ventana deslizante en incrementos de 1 marco de tiempo STFT para generar datos de entrenamiento, necesitamos aproximadamente 1.6 horas de sonido etiquetado para generar 500 mil muestras de datos
Con los requisitos anteriores, la entrada y salida de nuestro clasificador binario son las siguientes:
Modelo
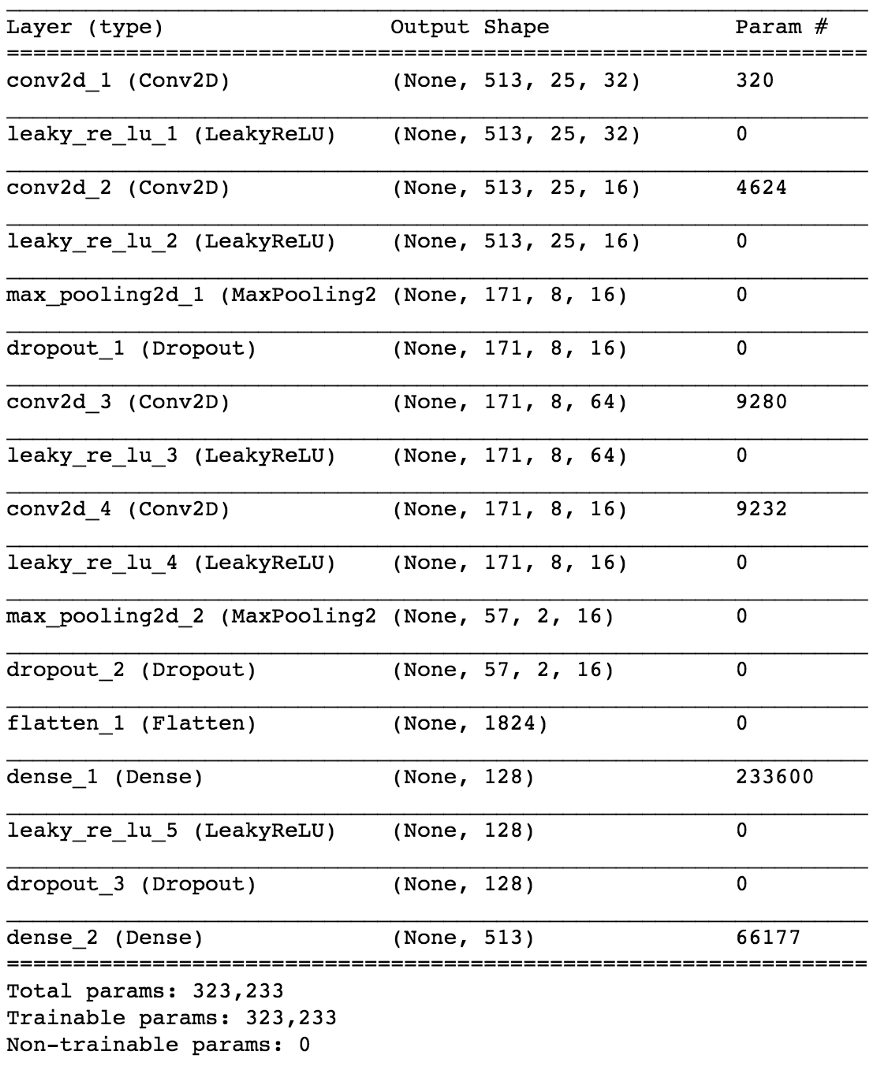
Usando Keras, construiremos un pequeño modelo de una red neuronal para probar nuestra hipótesis.
import keras from keras.models import Sequential from keras.layers import Dense, Dropout, Flatten, Conv2D, MaxPooling2D from keras.optimizers import SGD from keras.layers.advanced_activations import LeakyReLU model = Sequential() model.add(Conv2D(16, (3,3), padding='same', input_shape=(513, 25, 1))) model.add(LeakyReLU()) model.add(Conv2D(16, (3,3), padding='same')) model.add(LeakyReLU()) model.add(MaxPooling2D(pool_size=(3,3))) model.add(Dropout(0.25)) model.add(Conv2D(16, (3,3), padding='same')) model.add(LeakyReLU()) model.add(Conv2D(16, (3,3), padding='same')) model.add(LeakyReLU()) model.add(MaxPooling2D(pool_size=(3,3))) model.add(Dropout(0.25)) model.add(Flatten()) model.add(Dense(64)) model.add(LeakyReLU()) model.add(Dropout(0.5)) model.add(Dense(1, activation='sigmoid')) sgd = SGD(lr=0.001, decay=1e-6, momentum=0.9, nesterov=True) model.compile(loss=keras.losses.binary_crossentropy, optimizer=sgd, metrics=['accuracy'])
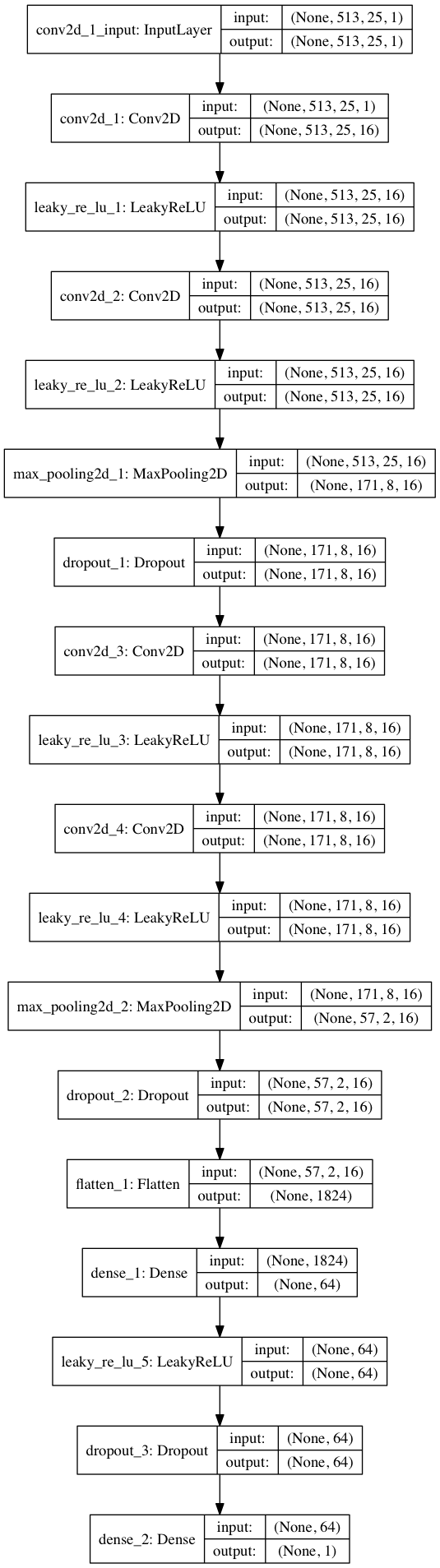
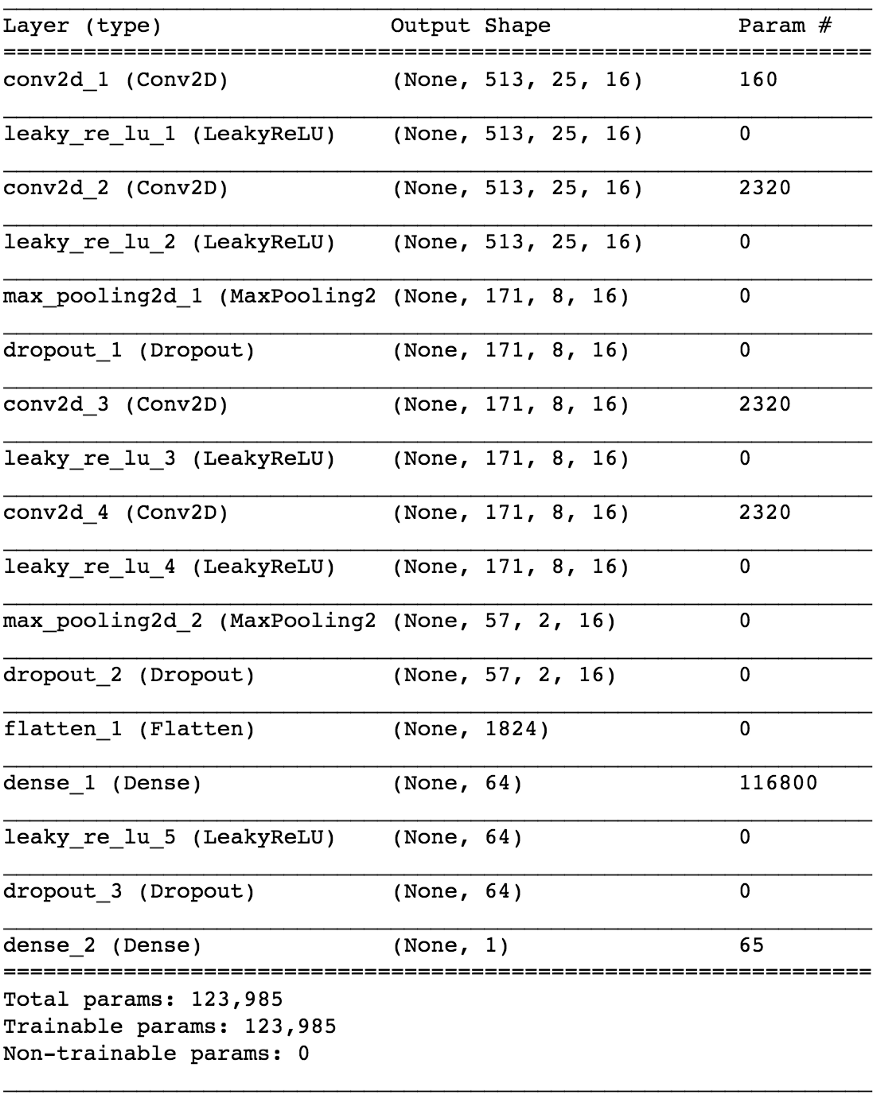
Al dividir los datos 80/20 en entrenamiento y pruebas después de ~ 50 épocas, obtenemos la
precisión al probar ~ 97% . Esto es evidencia suficiente de que nuestro modelo es capaz de distinguir entre voces en fragmentos de sonido musical (y fragmentos sin voces). Si revisamos algunos mapas de características de la cuarta capa convolucional, podemos concluir que la red neuronal parece haber optimizado sus núcleos para realizar dos tareas: filtrar música y filtrar voces ...
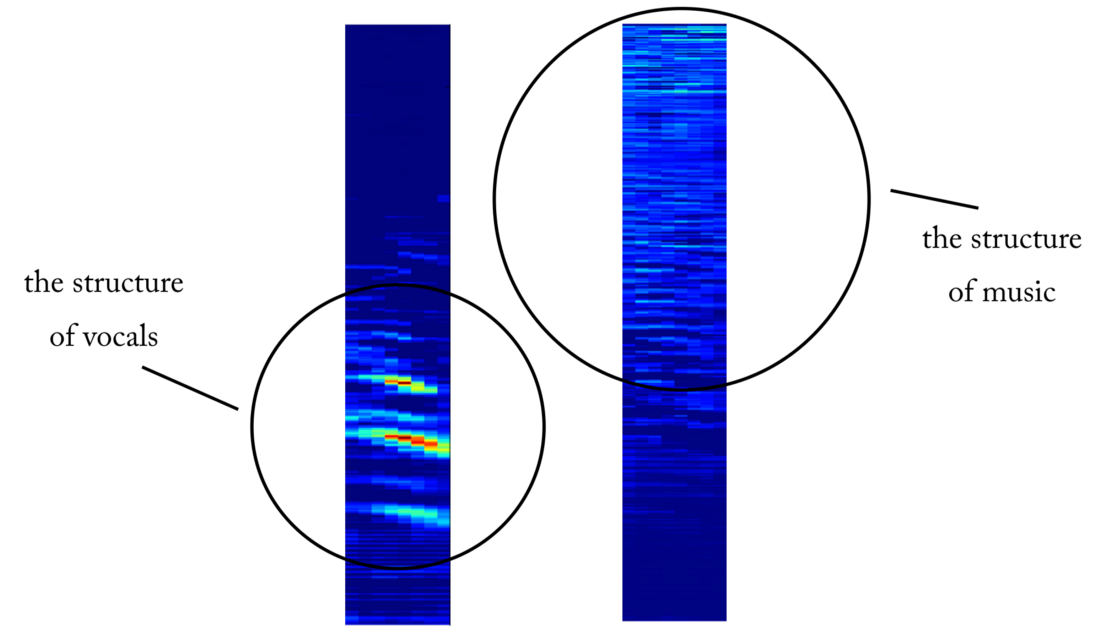 Un ejemplo de un mapa de objetos a la salida de la cuarta capa convolucional. Aparentemente, la salida a la izquierda es el resultado de las operaciones del núcleo en un intento de preservar el contenido vocal mientras se ignora la música. Los valores altos se asemejan a la estructura armoniosa del habla humana. El mapa de objetos a la derecha parece ser el resultado de la tarea opuesta.
Un ejemplo de un mapa de objetos a la salida de la cuarta capa convolucional. Aparentemente, la salida a la izquierda es el resultado de las operaciones del núcleo en un intento de preservar el contenido vocal mientras se ignora la música. Los valores altos se asemejan a la estructura armoniosa del habla humana. El mapa de objetos a la derecha parece ser el resultado de la tarea opuesta.Del detector de voz a la señal de desconexión
Habiendo resuelto el problema de clasificación más simple, ¿cómo podemos pasar a la separación real de las voces de la música? Bueno, mirando el primer método
ingenuo , todavía queremos obtener de alguna manera un espectrograma de amplitud para las voces. Ahora esto se está convirtiendo en una tarea de regresión. Lo que queremos hacer es calcular el espectro de amplitud correspondiente para las voces en este marco de tiempo a partir del STFT de la señal original, es decir, de la mezcla (con un contexto de tiempo suficiente).
¿Qué pasa con el conjunto de datos de entrenamiento? (puedes preguntarme en este momento)Maldición ... ¿por qué? ¡Iba a considerar esto al final del artículo para no distraerme del tema!
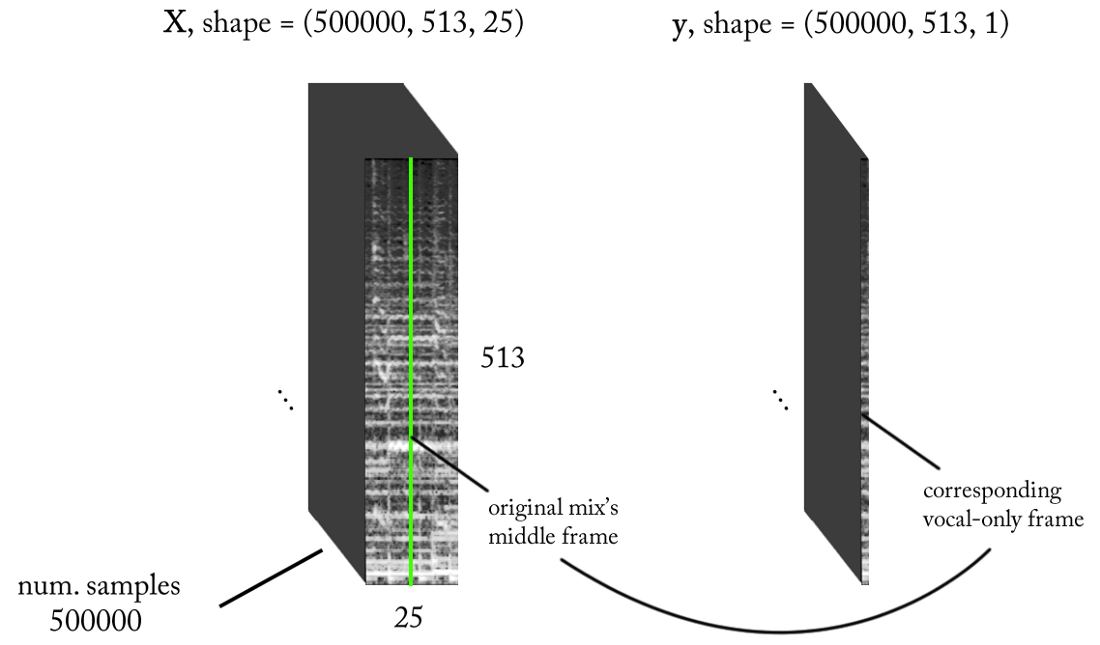
Si nuestro modelo está bien entrenado, entonces, para una conclusión lógica, solo necesita implementar una ventana deslizante simple para la mezcla STFT. Después de cada pronóstico, mueva la ventana hacia la derecha en 1 período de tiempo, prediga el siguiente cuadro con las voces y asócielo con la predicción previa. En cuanto al modelo, tomamos el mismo modelo que se utilizó para el detector de voz y hacemos pequeños cambios: la forma de la señal de salida es ahora (513.1), activación lineal en la salida, MSE en función de las pérdidas. Ahora comenzamos a entrenar.
No te alegres todavía ...Aunque esta representación de E / S tiene sentido, después de entrenar nuestro modelo varias veces, con varios parámetros y normalizaciones de datos, no hay resultados. Parece que estamos pidiendo demasiado ...
Hemos pasado de un clasificador binario a
regresión en un vector de 513 dimensiones. Aunque la red está estudiando el problema hasta cierto punto, las voces restauradas aún tienen artefactos obvios e interferencia de otras fuentes. Incluso después de agregar capas adicionales y aumentar el número de parámetros del modelo, los resultados no cambian mucho. Y luego surge la pregunta:
¿cómo "simplificar" la tarea para la red mediante el engaño, y al mismo tiempo lograr los resultados deseados?¿Qué sucede si, en lugar de estimar la amplitud de las voces STFT, entrenamos a la red para obtener una máscara binaria, que cuando se aplica a la mezcla STFT nos da un espectrograma de amplitud de las voces simplificado, pero
perceptualmente aceptable ?
Experimentando con varias heurísticas, se nos ocurrió un método muy simple (y ciertamente poco ortodoxo en términos de procesamiento de señales ...) para extraer voces de mezclas utilizando máscaras binarias. Sin entrar en detalles, la esencia es la siguiente. Imagine la salida como una imagen binaria, donde el valor '1' indica la
presencia predominante de contenido vocal en una frecuencia y marco de tiempo dados, y el valor '0' indica la presencia predominante de música en una ubicación dada. Podemos llamarlo la
binarización de la percepción , solo para encontrar un nombre. Visualmente, se ve bastante feo, para ser sincero, pero los resultados son sorprendentemente buenos.
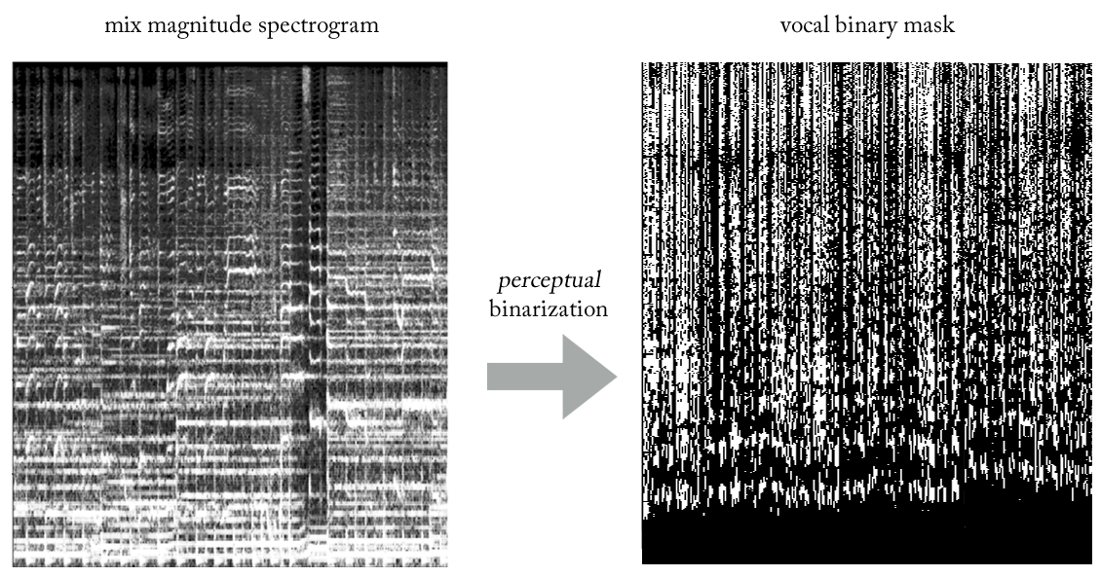
Ahora nuestro problema se convierte en una especie de regresión-clasificación híbrida (más o menos ...). Le pedimos al modelo que "clasifique píxeles" en la salida como vocal o no vocal, aunque conceptualmente (así como desde el punto de vista de la función de pérdida MSE utilizada) la tarea sigue siendo regresiva.
Aunque esta distinción puede parecer inapropiada para algunos, de hecho es de gran importancia en la capacidad del modelo para estudiar la tarea, la segunda de las cuales es más simple y más limitada. Al mismo tiempo, esto nos permite mantener nuestro modelo relativamente pequeño en términos de la cantidad de parámetros, dada la complejidad de la tarea, algo muy deseable para trabajar en tiempo real, que en este caso era un requisito de diseño. Después de algunos ajustes menores, el modelo final se ve así.
¿Cómo recuperar una señal de dominio de tiempo?
De hecho, como en el
método ingenuo . En este caso, para cada pase, predecimos un marco de tiempo de la máscara de voz binaria. Nuevamente, al darnos cuenta de una ventana deslizante simple con un paso de un marco de tiempo, continuamos evaluando y combinando marcos de tiempo sucesivos, que finalmente forman la máscara binaria vocal completa.

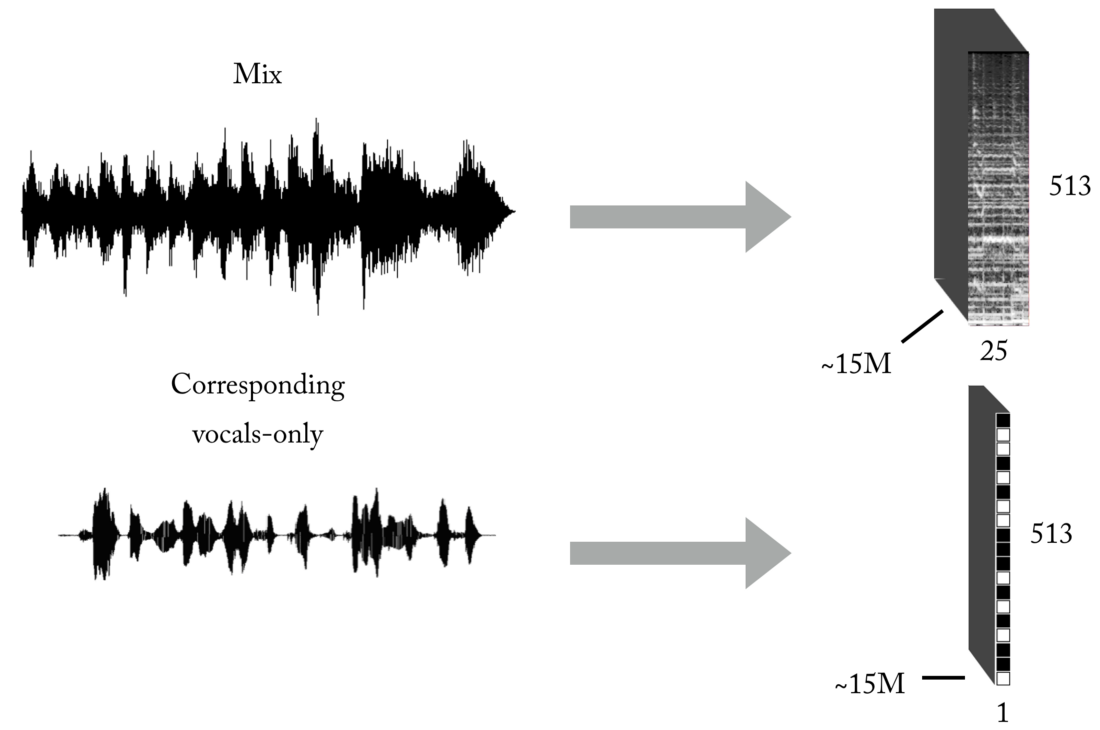
Crea un conjunto de entrenamiento
Como saben, uno de los principales problemas cuando se enseña con un maestro (deje estos ejemplos de juguetes con conjuntos de datos listos para usar) es la información correcta (en cantidad y calidad) para el problema específico que está tratando de resolver. Según las representaciones de entrada y salida descritas, para entrenar nuestro modelo, primero necesitará un número significativo de mezclas y sus correspondientes pistas vocales perfectamente alineadas y normalizadas. Este conjunto se puede crear de varias maneras, y utilizamos una combinación de estrategias, desde la creación manual de pares [mezclar <-> voces] basadas en varias capillas encontradas en Internet, hasta la búsqueda de material de música de banda de rock y álbumes de recortes de Youtube. Solo para darle una idea de lo laborioso y doloroso que es este proceso, parte del proyecto fue el desarrollo de una herramienta para crear pares automáticamente [mezclar voces <->]:

Se necesita una gran cantidad de datos para que la red neuronal aprenda la función de transferencia para transmitir mezclas a voces. Nuestro conjunto final consistió en aproximadamente 15 millones de muestras de mezclas de 300 ms y sus correspondientes máscaras binarias vocales.
Arquitectura de tubería
Como probablemente sepa, crear un modelo de ML para una tarea específica es solo la mitad de la batalla. En el mundo real, debe pensar en la arquitectura del software, especialmente si necesita trabajar en tiempo real o cerca de ella.
En esta implementación particular, la reconstrucción en el dominio del tiempo puede ocurrir inmediatamente después de predecir la máscara de voz binaria completa (modo independiente) o, lo que es más interesante, en modo de subprocesos múltiples, donde recibimos y procesamos datos, restauramos voces y reproducimos sonido, todo en segmentos pequeños, cerca de transmisión e incluso casi en tiempo real, procesando música que se graba sobre la marcha con un retraso mínimo. En realidad, este es un tema separado, y lo dejaré para otro artículo
sobre tuberías de ML en tiempo real ...
Supongo que dije lo suficiente, ¿por qué no escuchar un par de ejemplos?
Daft Punk - Get Lucky (grabación de estudio)
Aquí puedes escuchar algunas interferencias mínimas de la batería ...Adele: prende fuego a la lluvia (¡grabación en vivo!)
Observe cómo al principio nuestro modelo extrae los gritos de la multitud como contenido vocal :). En este caso, hay alguna interferencia de otras fuentes. Como se trata de una grabación en vivo, parece aceptable que las voces extraídas sean de peor calidad que las anteriores.Sí, y "algo más" ...
Si el sistema funciona para voces, ¿por qué no aplicarlo a otros instrumentos ...?
El artículo ya es bastante extenso, pero dado el trabajo realizado, mereces escuchar la última demostración. Con la misma lógica que cuando extraemos voces, podemos tratar de dividir la música estéreo en componentes (batería, bajos, voces, otros), haciendo algunos cambios en nuestro modelo y, por supuesto, teniendo el conjunto de entrenamiento apropiado :).
Gracias por leer Como nota final: como puede ver, el modelo real de nuestra red neuronal convolucional no es tan especial. El éxito de este trabajo fue determinado por
Feature Engineering y el claro proceso de prueba de hipótesis, sobre el que escribiré en futuros artículos.