Hola de nuevo Hoy continuamos compartiendo material dedicado al lanzamiento del curso
"Ingeniero de redes" , que comienza ya a principios de marzo. Vemos que muchos estaban interesados en la
primera parte del artículo "Enfoque sinestésico de la máquina para detectar ataques DDoS de red" y hoy queremos compartir con ustedes la segunda, la parte final.
3.2 Clasificación de imagen en el problema de detección de anomalíasEl siguiente paso es resolver el problema de clasificación de la imagen resultante. En general, la solución al problema de detectar clases (objetos) en una imagen es usar algoritmos de aprendizaje automático para construir modelos de clase, y luego algoritmos para buscar clases (objetos) en una imagen.

La construcción de un modelo consta de dos etapas:
a) Extracción de características para una clase: trazar vectores de características para los miembros de la clase.

Fig. 1
b) Capacitación en las características del modelo obtenido para tareas de reconocimiento posteriores.
El objeto de clase se describe utilizando vectores de características. Los vectores se forman a partir de:
a) información de color (histograma de gradiente orientado);
b) información contextual;
c) datos sobre la disposición geométrica de partes del objeto.
El algoritmo de clasificación (pronóstico) se puede dividir en dos etapas:
a) Extraer características de la imagen. En esta etapa, se realizan dos tareas:
- Como la imagen puede contener objetos de muchas clases, necesitamos encontrar a todos los representantes. Para hacer esto, puede usar una ventana deslizante que pase a través de la imagen desde la esquina superior izquierda a la esquina inferior derecha.
- La imagen se escala porque la escala de los objetos en la imagen puede cambiar.
b) asociar una imagen con una clase particular. Se utiliza como entrada una descripción formal de la clase, es decir, un conjunto de características que se destacan por sus imágenes de prueba. En base a esta información, el clasificador decide si la imagen pertenece a la clase y evalúa el grado de certeza para la conclusión.
Métodos de clasificación. Los métodos de clasificación abarcan desde enfoques predominantemente heurísticos hasta procedimientos formales basados en métodos de estadística matemática. No existe una clasificación generalmente aceptada, pero se pueden distinguir varios enfoques para la clasificación de imágenes:
- métodos de modelado de objetos basados en detalles;
- métodos de la "bolsa de palabras";
- métodos de emparejar pirámides espaciales.
Para la implementación presentada en este artículo, los autores eligieron el algoritmo "bolsa de palabras", dadas las siguientes razones:
- Los algoritmos para el modelado basado en detalles y las pirámides espaciales coincidentes son sensibles a la posición de los descriptores en el espacio y su posición relativa. Estas clases de métodos son efectivos en las tareas de detección de objetos en una imagen; sin embargo, debido a las características de los datos de entrada, son poco aplicables al problema de clasificación de imágenes.
- El algoritmo de "bolsa de palabras" ha sido ampliamente probado en otros campos del conocimiento, muestra buenos resultados y es bastante simple de implementar.
Para analizar el flujo de video proyectado desde el tráfico, utilizamos el ingenuo clasificador Bayes [25]. A menudo se usa para clasificar textos usando el modelo de bolsa de palabras. En este caso, el enfoque es similar al análisis de texto, en lugar de palabras solo se utilizan descriptores. El trabajo de este clasificador se puede dividir en dos partes: la fase de entrenamiento y la fase de pronóstico.
Fase de aprendizaje . Cada cuadro (imagen) se alimenta a la entrada del algoritmo de búsqueda del descriptor, en este caso, la transformación de característica invariante de escala (SIFT) [26]. Después de eso, se realiza la tarea de correlación de puntos singulares entre cuadros. Un punto particular en la imagen de un objeto es un punto que probablemente aparezca en otras imágenes de este objeto.
Para resolver el problema de comparar puntos especiales de un objeto en diferentes imágenes, se utiliza un descriptor. Un descriptor es una estructura de datos, un identificador para un punto singular que lo distingue del resto. Puede o no ser invariante con respecto a las transformaciones de la imagen del objeto. En nuestro caso, el descriptor es invariante con respecto a las transformaciones de perspectiva, es decir, la escala. El controlador le permite comparar el punto de característica de un objeto en una imagen con el mismo punto de característica en otra imagen de este objeto.
Luego, el conjunto de descriptores obtenidos de todas las imágenes se clasifica en grupos por similitud utilizando el método de agrupación k-means [26, 27]. Esto se hace para entrenar al clasificador, que dará una conclusión sobre si la imagen representa un comportamiento anormal.
El siguiente es un algoritmo paso a paso para entrenar el clasificador del descriptor de imagen:
Paso 1 Extraiga todos los descriptores de conjuntos con y sin ataque.
Paso 2 Agrupación de todos los descriptores utilizando el método k-means en n agrupaciones.
Paso 3 Cálculo de la matriz A (m, k), donde m es el número de imágenes yk es el número de grupos. El elemento (i; j) almacenará el valor de la frecuencia con la que los descriptores del j-ésimo grupo aparecen en la i-ésima imagen. Tal matriz se llamará matriz de la frecuencia de ocurrencia.
Paso 4 Cálculo de los pesos de los descriptores mediante la fórmula tf idf [28]:
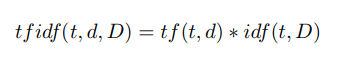
Aquí tf ("frecuencia de término") es la frecuencia de aparición del descriptor en esta imagen y se define como
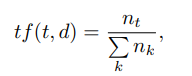
donde t es el descriptor, k es el número de descriptores en la imagen, nt es el número de descriptores t en la imagen. Además, idf ("frecuencia de documento inversa") es la frecuencia de imagen inversa con un descriptor dado en la muestra y se define como
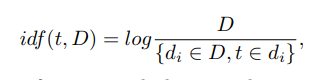
donde D es el número de imágenes con un descriptor dado en la muestra, {di ∈ D, t ∈ di} es el número de imágenes en D, donde t está en nt! = 0.
Paso 5 Sustituyendo los pesos correspondientes en lugar de los descriptores en la matriz A.
Paso 6 Clasificación Utilizamos amplificación de clasificadores ingenuos de Bayes (adaboost).
Paso 7 Guardar el modelo entrenado en un archivo.
Paso 8 Esto concluye la fase de entrenamiento.
Fase de predicción . Las diferencias entre la fase de entrenamiento y la fase de pronóstico son pequeñas: los descriptores se extraen de la imagen y se correlacionan con los grupos existentes. En base a esta relación, se construye un vector. Cada elemento de este vector es la frecuencia de aparición de los descriptores de este grupo en la imagen. Al analizar este vector, el clasificador puede hacer un pronóstico de ataque con una cierta probabilidad.
A continuación se presenta un algoritmo de pronóstico general basado en un par de clasificadores.
Paso 1 Extraer todos los descriptores de la imagen;
Paso 2 Agrupando el conjunto resultante de descriptores;
Paso 3 Cálculo del vector [1, k];
Paso 4 Cálculo del peso para cada descriptor de acuerdo con la fórmula tf idf presentada anteriormente;
Paso 5 Reemplazar la frecuencia de ocurrencia en vectores con su peso;
Paso 6 Clasificación del vector resultante de acuerdo con un clasificador previamente entrenado;
Paso 7 Conclusión sobre la presencia de anomalías en la red observada con base en el pronóstico del clasificador.
4. Evaluación de la eficiencia de detección.La tarea de evaluar la efectividad del método propuesto se resolvió experimentalmente. En el experimento, se utilizaron varios parámetros establecidos experimentalmente. Para la agrupación, se utilizaron 1000 agrupaciones. Las imágenes generadas tenían 1000 por 1000 píxeles.
4.1 Conjunto de datos experimentalesPara los experimentos, la instalación fue ensamblada. Consiste en tres dispositivos conectados por un canal de comunicación. El diagrama de bloques de instalación se muestra en la Figura 2.
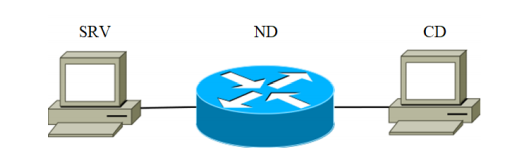
Fig. 1
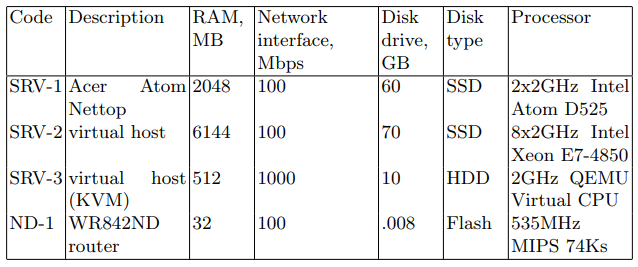
El dispositivo SRV actúa como el servidor atacante (en lo sucesivo, el servidor de destino). Los dispositivos enumerados en la Tabla 1 con el código SRV se utilizaron secuencialmente como el servidor de destino. El segundo es un dispositivo de red diseñado para transmitir paquetes de red. Las características del dispositivo se muestran en la Tabla 1 bajo el código ND-1.
Tabla 1. Especificaciones del dispositivo de red
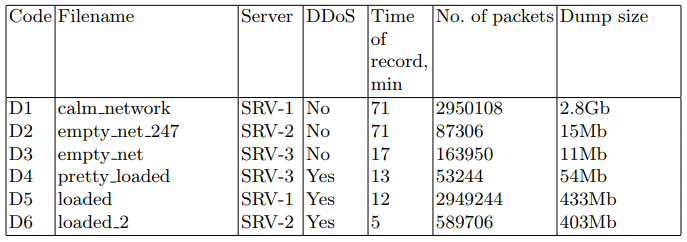
En los servidores de destino, los paquetes de red se escribieron en un archivo PCAP para su uso posterior en algoritmos de descubrimiento. La utilidad tcpdump se utilizó para esta tarea. Los conjuntos de datos se describen en la tabla 2.
Tabla 2. Conjuntos de paquetes de red interceptados
Se utilizó el siguiente software en los servidores de destino: distribución Linux, servidor web nginx 1.10.3, postgresql 9.6 DBMS. Se escribió una aplicación web especial para emular el arranque del sistema. La aplicación solicita una base de datos con una gran cantidad de datos. La solicitud está diseñada para minimizar el uso de varios caché. Durante los experimentos, se generaron solicitudes para esta aplicación web.
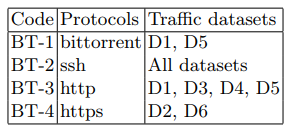
El ataque se realizó desde el tercer dispositivo cliente (tabla 1) utilizando la utilidad Apache Benchmark. La estructura del tráfico de fondo durante el ataque y el resto del tiempo se presenta en la Tabla 3.
Tabla 3. Funciones de tráfico de fondo
Como ataque, implementamos la versión distribuida de DoS de la inundación HTTP GET. Tal ataque, de hecho, es la generación de un flujo constante de solicitudes GET, en este caso desde un dispositivo CD-1. Para generarlo, utilizamos la utilidad ab del paquete apache-utils. Como resultado, se recibieron archivos que contienen información sobre el estado de la red. Las características principales de estos archivos se presentan en la tabla 2. Los parámetros principales del escenario de ataque se muestran en la tabla 4.
Del volcado de tráfico de red recibido, se obtuvieron conjuntos de imágenes generadas TD # 1 y TD # 2, que se utilizaron en la etapa de entrenamiento. Se usó la muestra TD # 3 para la fase de predicción. Un resumen de los conjuntos de datos de prueba se presenta en la tabla 5.
4.2 Criterios de rendimientoLos principales parámetros evaluados durante este estudio fueron:
Tabla 4. Características de un ataque DDoS

Tabla 5. Conjuntos de imágenes de prueba

a) DR (tasa de detección): la cantidad de ataques detectados en relación con la cantidad total de ataques. Cuanto mayor sea este parámetro, mayor será la eficiencia y la calidad de ADS.
b) FPR (tasa de falsos positivos): el número de objetos "normales", clasificados erróneamente como un ataque, en relación con el número total de objetos "normales". Cuanto menor sea este parámetro, mayor será la eficiencia y la calidad del sistema de detección de anomalías.
c) CR (tasa compleja) es un indicador complejo que tiene en cuenta la combinación de los parámetros DR y FPR. Dado que los parámetros DR y FPR se tomaron en igual importancia en el estudio, el indicador complejo se calculó de la siguiente manera: CR = (DR + FPR) / 2.
Se enviaron 1000 imágenes marcadas como "anormales" al clasificador. En función de los resultados del reconocimiento, se calculó la DR según el tamaño de la muestra de entrenamiento. Se obtuvieron los siguientes valores: para TD # 1 DR = 9.5% y para TD # 2 DR = 98.4%. Además, se clasificó la segunda mitad de las imágenes ("normal"). Con base en el resultado, se calculó FPR (para TD # 1 FPR = 3.2% y para TD # 2 FPR = 4.3%). Por lo tanto, se obtuvieron los siguientes indicadores integrales de rendimiento: para TD # 1 CR = 53.15% y para TD # 2 CR = 97.05%.
5. Conclusiones e investigaciones futuras.A partir de los resultados experimentales, se ve que el método propuesto para detectar anomalías muestra altos resultados en la detección de ataques. Por ejemplo, en una muestra grande, el valor de un indicador de rendimiento integral alcanza el 97%. Sin embargo, este método tiene algunas limitaciones en la aplicación:
1. Los valores de DR y FPR muestran la sensibilidad del algoritmo al tamaño del conjunto de entrenamiento, que es un problema conceptual para los algoritmos de aprendizaje automático. El aumento de la muestra mejora el rendimiento de detección. Sin embargo, no siempre es posible implementar un conjunto de entrenamiento suficientemente grande para una red en particular.
2. El algoritmo desarrollado es determinista, la misma imagen se clasifica cada vez con el mismo resultado.
3. Los indicadores de efectividad del enfoque son lo suficientemente buenos como para confirmar el concepto, pero el número de falsos positivos también es grande, lo que puede conducir a dificultades en la implementación práctica.
Para superar la limitación descrita anteriormente (punto 3), se supone que debe cambiar el ingenuo clasificador bayesiano a una red neuronal convolucional que, según los autores, debería aumentar la precisión del algoritmo de detección de anomalías.
Referencias1. Mohiuddin A., Abdun NM, Jiankun H .: Una encuesta sobre técnicas de detección de anomalías en la red. En: Revista de aplicaciones de redes y computadoras. Vol. 60, p. 21 (2016)
2. Afontsev E .: anomalías de la red, 2006
nag.ru/articles/reviews/15588 setevyie-anomalii.html
3. Berestov AA: Arquitectura de agentes inteligentes basada en un sistema de producción para proteger contra ataques de virus en Internet. En: XV Conferencia científica rusa sobre problemas de seguridad de la información en el sistema escolar superior ”, pp. 180? 276 (2008)
4. Galtsev AV: Análisis del sistema de tráfico para identificar condiciones de red anómalas: la tesis para el Grado de Ciencias Técnicas Candidato. Samara (2013)
5. Kornienko AA, Slyusarenko IM: Sistemas y métodos de detección de intrusiones: estado actual y dirección de mejora, 2008
citforum.ru/security internet / ids overview /
6. Kussul N., Sokolov A.: Detección de anomalías adaptativas en el comportamiento de los usuarios de sistemas informáticos utilizando cadenas de Markov de orden variable. Parte 2: Métodos para detectar anomalías y los resultados de los experimentos. En: Problemas informáticos y de control. Número 4, pp. 83-88 (2003)
7. Mirkes EM: Neurocomputadora: proyecto de norma. Science, Novosibirsk, pp. 150-176 (1999)
8. Tsvirko DA Predicción de una ruta de ataque de red utilizando métodos de modelo de producción, 2012
academy.kaspersky.com/downloads/academycup participantes / cvirko d. ppt
9. Somayaji A.: Respuesta automatizada utilizando retrasos en las llamadas al sistema. En: USENIX Security Symposium 2000, pp. 185-197, 2000
10. Ilgun K.: USTAT: un sistema de detección de intrusiones en tiempo real para UNIX. En: Simposio IEEE sobre Investigación en Seguridad y Privacidad, Universidad de California (1992)
11. Eskin E., Lee W. y Stolfo SJ: el sistema de modelado requiere la detección de intrusos con tamaños de ventana dinámicos. En: Conferencia y exposición de supervivencia de información DARPA (DISCEX II), junio de 2001
12. Ye N., Xu M. y Emran SM: redes probabilísticas con enlaces no dirigidos para la detección de anomalías. En: 2000 IEEE Workshop on Information Assurance and Security, West Point, NY (2000)
13. Michael CC y Ghosh A.: Dos enfoques basados en estado para la detección de anomalías basada en programas. En: Transacciones de ACM sobre información y seguridad del sistema. No 5 (2), 2002
14. Garvey TD, Lunt TF: Detección de intrusos basada en modelos. En: 14ª Conferencia de seguridad informática de la nación, Baltimore, MD (1991)
15. Theus M. y Schonlau M.: Detección de intrusiones basada en ceros estructurales. En: Boletín de computación estadística y gráficos. No 9 (1), págs. 12-17 (1998)
16. Tan K .: La aplicación de redes neuronales para unix seguridad informática. En: IEEE International Conference on Neural Networks. Vol. 1, pp. 476–481, Perth, Australia (1995)
17. Ilgun K., Kemmerer RA, Porras PA: Análisis de transición de estado: un sistema de detección de intrusiones basado en reglas. En: IEEE Trans. Ing. De software Vol. 21, no. 3, (1995)
18. Eskin E.: detección de anomalías sobre datos ruidosos utilizando distribuciones de probabilidad aprendidas. En: 17th International Conf. en Machine Learning, pp. 255? 262. Morgan Kaufmann, San Francisco, CA (2000)
19. Ghosh K., Schwartzbard A. y Schatz M.: Perfiles de comportamiento del programa de aprendizaje para la detección de intrusos. En: 1er taller de USENIX sobre detección de intrusiones y monitoreo de redes, pp. 51–62, Santa Clara, California (1999)
20. Ye N.: Un modelo de cadena de Markov de comportamiento temporal para la detección de anomalías. En: 2000 IEEE Systems, Man and Cybernetics, Information Assurance and Security Workshop (2000)
21. Axelsson S.: La falacia de la tasa base y sus implicaciones para la dificultad de la detección de intrusos. En: Conferencia ACM sobre seguridad informática y de comunicaciones, pp. 1–7 (1999)
22. Chikalov I, Moshkov M, Zielosko B.: Optimización de las reglas de decisión basadas en métodos de programación dinámica. En Vestnik de la Universidad Estatal Lobachevsky de Nizhni Novgorod, no. 6, pp. 195-200
23. Chen CH: Manual de reconocimiento de patrones y visión por computadora. Universidad de Massachusetts Dartmouth, EE. UU. (2015)
24. Gantmacher FR: Teoría de matrices, p. 227. Ciencia, Moscú (1968)
25. Murty MN, Devi VS: Reconocimiento de patrones: un algoritmo. Pp. 93-94 (2011)
Tradicionalmente, estamos esperando sus comentarios e invitamos a todos a una
jornada de puertas abiertas , que se realizará el próximo lunes.