¿Qué hacer si necesita trabajar con datos que aún no son Big data por volumen, pero que ya son más de lo que cabe en la memoria de la computadora y para los cuales las características de Excel son suficientes? Para los amantes de la bicicleta, la respuesta es obvia: debe escribir algo propio (sí, no estamos buscando formas fáciles).
Pero, ¿qué pasa si el código que escribió en el pasado es terrible y no le da la oportunidad de desarrollar el proyecto? Deje de lado los viejos desarrollos, dé paso a un nuevo, eterno y brillante (sí, sí, y aquí también, sin opciones).
 Cita de CF Matrix: "Una tableta es suficiente, Neo". Director: hermanos y hermanas Wachowski. 1999. Estados Unidos
Cita de CF Matrix: "Una tableta es suficiente, Neo". Director: hermanos y hermanas Wachowski. 1999. Estados UnidosHace más de 10 años, escribí un código para ASH Viewer (más sobre mi camino
aquí ), lo
publiqué primero en
sourceforge.net , y luego en
github para que las personas se conecten y puedan agregar funcionalidad, corregir errores. El proyecto fue construido usando Gradle, resolvió problemas con la visualización de gráficos: una lista casi completa de mejoras
por referencia .
Sin embargo, me di cuenta de que el código escrito hace diez años es, por decirlo suavemente, imperfecto. Exteriormente, todo se veía bien, la funcionalidad se desarrolló, las personas las usaron y agradecieron activamente. Pero dentro del programa contenía todos los errores de la primera experiencia de codificación y, por supuesto, esto impidió en gran medida el desarrollo del proyecto.
A todos los que estaban listos para comenzar a trabajar seriamente en la aplicación (por ejemplo,
dcvetkov ), les dije que el código requiere una alteración completa. Y con cada intento de implementar cualquier funcionalidad o corregir errores, me convencí de esto. Te informaré que editar el código heredado es una tortura terrible, especialmente la mía :). Espero que en el futuro los robots aprendan a reescribir todo ellos mismos, pero por ahora, se tomó una decisión decidida de comenzar desde cero, teniendo en cuenta la experiencia ya adquirida en la creación de programas y la escritura de código.
Desde su primer lanzamiento, ASH Viewer ha estado activo en esta área. Se realizaron tres proyectos bastante grandes basados en
JfreeChart para el análisis de datos. Además de estos proyectos, probé diferentes enfoques, paradigmas y bibliotecas. Como resultado, decidí que todo debería escribirse en Java puro, sin el uso de bibliotecas especialmente diseñadas para crear una interfaz gráfica desde cero. Pero aún así, el uso de bibliotecas de terceros para resolver algunas tareas altamente especializadas es bastante aceptable: esto le permitirá mantener el nivel necesario de flexibilidad y no requerirá una inversión significativa de tiempo para corregir errores y desarrollar la funcionalidad requerida con sus propias manos.
Como empezó todo
Siempre estaba preocupado, pero ¿hay algún ejemplo en el dominio público que ofrezca los conceptos básicos para escribir correctamente aplicaciones de complejidad media en Java Swing? Por supuesto, me enviaron a la biblioteca misma oa algunos ejemplos simples de libros de texto. Y de alguna manera tenían razón.
Pero busqué persistentemente el código de la aplicación que podría usarse como un ejemplo de "cómo hacerlo bien" en Java Swing. Y quería tener un sistema de trabajo ante mis ojos para que se pudiera "sentir".
Comenzó a estudiar el código fuente de las aplicaciones Java Swing (no se pueden contar todas). En algún lugar eran simples tareas pendientes, en algún lugar demasiado complicado (para mí en ese momento), en algunos fallaron en calidad, y a veces hubo ambos. Leí artículos sobre Habré, escribí un código. Pero aún faltaba algo. Quizás en ese momento estaba ganando una cantidad crítica de conocimiento para resolver este problema.
Un día encontré el
Angry IP Scanner de los respetados
antonkeks de Anton
Keks , lo miré e inmediatamente me di cuenta: ¡aquí está! Java Swing, funcionalidad simple, código limpio, modularidad, ¡agradable de leer! En general, utilicé los enfoques utilizados al escribir uno de mis proyectos anteriores, y luego al reescribir ASH Viewer.
Software y bibliotecas que han ayudado a mejorar la calidad del código y simplificado el trabajo.
IDEA : He estado usando este IDE para la programación Java durante unos cinco años. Confirmo la opinión de la mayoría: este es un programa realmente útil y una herramienta muy conveniente para escribir código. Cuando me mudé a él desde Eclipse
www.eclipse.org/ide (y la primera versión fue escrita en este IDE), luego de un breve entrenamiento me di cuenta de que IDEA te guía y te dice cuándo intentas cambiar al lado oscuro :). Destacar las repeticiones en el código lo mantiene en buena forma y le impide hacer estúpidos copiar y pegar. Ave JetBrains!
Java 8 : expresiones lambda que permiten escribir código más corto, una nueva API de Time que le permite cancelar el uso de una biblioteca de Joda Time de terceros.
Daga 2 : marco de inyección de dependencia que nunca he usado antes. Pero de alguna manera vi cómo Anton
Antonkeks usa esta biblioteca y comencé a hacerlo de acuerdo con la plantilla. Divida el programa en módulos, donde sea posible, use inyección de dependencia. Cuando esto
no fue
posible , utilizó la creación de objetos de shell por adelantado, y luego estableció los atributos necesarios o simplemente no usó DI.
Sistema de construcción
Maven . Este es el sistema de compilación que es el estándar de facto, así que decidí agregar bibliotecas limpiamente a través de pom.xml y usar el sistema de módulos Maven para trabajar con código JFreeChart y Gantt en un proyecto.
Lombok : también una biblioteca increíblemente conveniente, para no escribir o apoyar los "pasos" del código uniforme (getters, setters, etc.). Es cierto que en algunos casos me negué a usarlo, ya que era necesario redefinir iguales y compareTo, pero no encontré cómo hacerlo rápidamente en Lombok.
Diario: hacer el programa Java perfecto? Por lo tanto, sin medios modernos de diario, en ninguna parte. Por lo tanto, tomamos
como base la
Simple Logging Facade para Java SLF4J y
Logback .
Administrador de diseño: principalmente uso
Miglayout . Es bastante difícil de aprender (en algunos lugares uso los administradores de diseño de Swing a la antigua usanza), pero es breve. Le permite hacer
efectos tan interesantes como en la pestaña Detalle.
Swingx de Swinglabs: la interfaz de usuario Java Swing abandonada hace mucho tiempo se iluminó. Estoy usando JXTable activamente. La selección arbitraria de las columnas de la tabla y una búsqueda integrada del contenido de las celdas facilitan un análisis detallado de los datos históricos de las sesiones activas.
ommons-dbcp2 : útil para crear un grupo de conexiones para conexiones de bases de datos. En la versión anterior, utilizaba una implementación modificada que encontré en Internet.
Bibliotecas que pasaron de la versión anterior
Oracle Berkeley DB Java Edition v. 5.0.73: almacenamiento de clave-valor incrustado. Para almacenar datos de historial agregados de sesiones activas.
JFreeChart : Miles de proyectos de análisis de datos escritos con esta biblioteca. Tomé la versión experimental, que está publicada en github, y la agregué como un módulo. Esto se hizo para la conveniencia de trabajar con el código, ya que se
requerían cambios para que el Gráfico apilado mostrara el gráfico según fuera necesario.
E-Gantt : una biblioteca para crear gráficos Gantt en Java Swing. Las huellas de esto ahora no se pueden encontrar incluso en Internet, por desgracia. También se coloca como un módulo Maven separado en el proyecto.
De lo interesante en el código, a qué puedes prestar atención
Cambios arquitectónicos:- Ahora la configuración se almacena en una base de datos integrada separada, no en archivos de texto sin formato. Como no hay muchos datos, se utiliza un patrón EAV avanzado para almacenar la configuración de conexión;
- Para almacenar datos de monitoreo, decidí hacer una apariencia de un motor OLAP. Primero, para acelerar la visualización del desglose de Gantt por SQL_ID / SESSION_ID sobre el rango seleccionado. En segundo lugar, para la posibilidad de obtener un desglose rápido en SQL_ID / SESSION_ID en gráficos apilados y Gantt. En tercer lugar, la formación de una visión futura del historial de sesiones activas (Top en expectativas, profundizar en expectativas, profundizar en SQL_ID / SESSION_ID). Todo se almacena en una entidad (los datos para un segundo, 15 segundos y, en el futuro, para otros intervalos extendidos están físicamente separados);
- Un efecto secundario de la arquitectura limpia es la capacidad de soportar el monitoreo del historial de sesiones activas de otras bases de datos. Actualmente implementado soporte Postgres. Para conectar otras bases de datos, necesita una interfaz preparada para los datos del historial de sesiones activas (que se agregó a Postgres o una implementación de este tipo ) o una colección autoconfigurada del historial de sesiones activas en una tabla separada, a la que se puede acceder más adelante.
Cómo habilitar el soporte para otra base de datos- Cree una nueva clase e implemente la interfaz IProfile. Haga lo mismo que en el caso de Postgres;
- Agregue la implementación para la nueva versión de la base de datos al procedimiento loadProfile de la clase ConnectToDbArea y la función enum de la clase ConstantManager ;
- Conéctese y verifique la aplicación.
GUI
Formulario de conexión a la base de datos.Completamente reescrito desde cero, utilizó previamente las mejores prácticas del proyecto abierto
Squirrel-sql . Ahora todo está en
un archivo. Belleza!
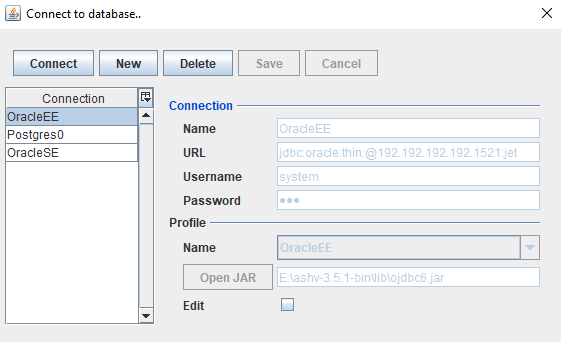
Cómo conectarse a la base de datos- Crea una nueva conexión;
- Especifique el nombre, URL (JDBC es estándar para Oracle: jdbc: oracle: thin: @host: port: SID, para Postgres: jdbc: postgresql: // host: port: database), nombre de usuario / contraseña, perfil y seleccione la biblioteca jdbc;
- Para Oracle, todo funciona con ojdbc6.jar; para PostgresDB, se verifica el trabajo con postgresql-42.2.5
Actividad principal / Interfaz de detalleAquí, sin cambios significativos, similar a la versión anterior, solo sin ver la historia.
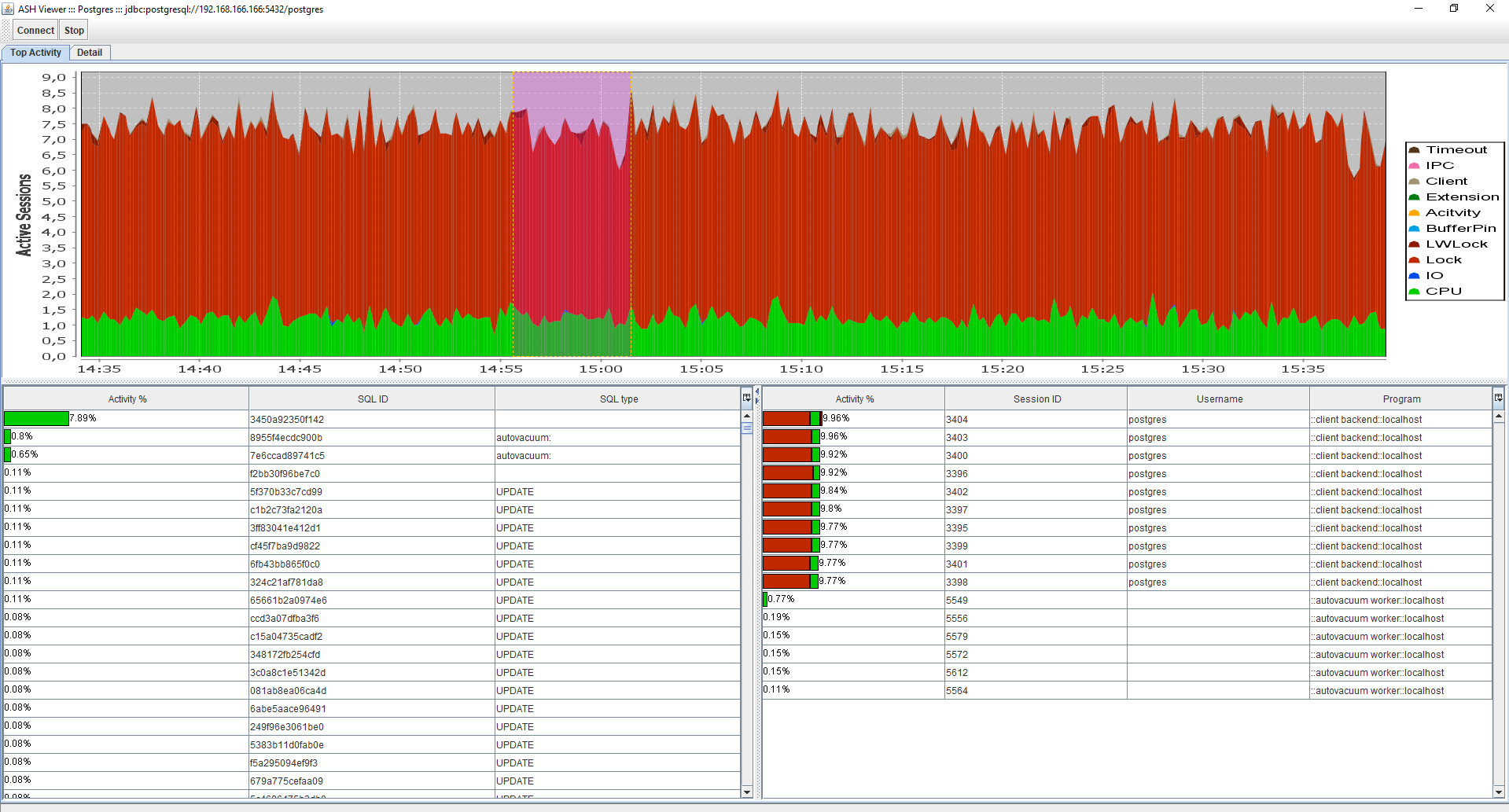 Explorar por SQL_ID / SESSION_IDSQL
Explorar por SQL_ID / SESSION_IDSQL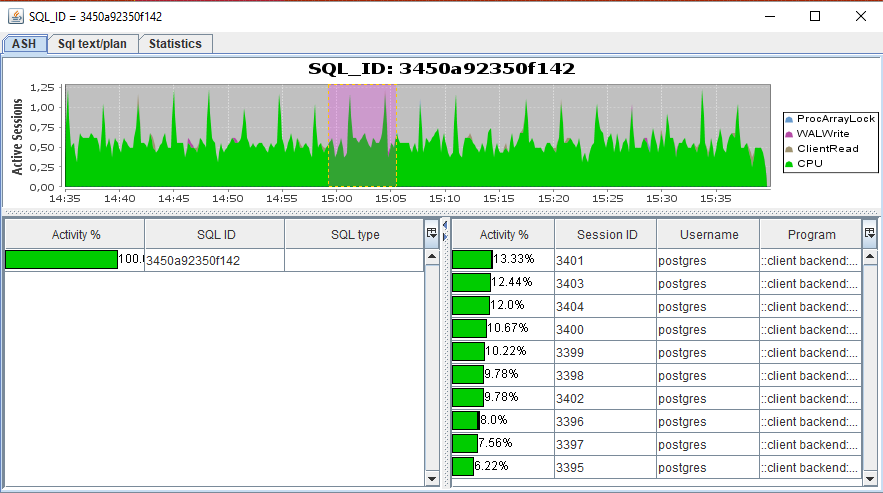 ASH
ASH : gráfico de actividad para un SQL_ID específico, llamado haciendo doble clic en la fila con SQL_ID del gráfico de Gantt.
Texto / plan SQL : para Oracle / Postgres es posible obtener el texto completo de la solicitud. Solo para Oracle se proporcionan planes de ejecución de consultas para todo plan_hash_value.
Estadísticas : datos de la tabla por SQL_ID: buscar desde V $ SQL. El código tiene la capacidad de agregar más entidades para las cuales puede hacer una selección (ver
implementación ). pero debe tener mucho cuidado, ya que puede haber problemas de rendimiento: por ejemplo, la
recuperación de
V $ SQLAREA en sistemas cargados es muy lenta).
Sesión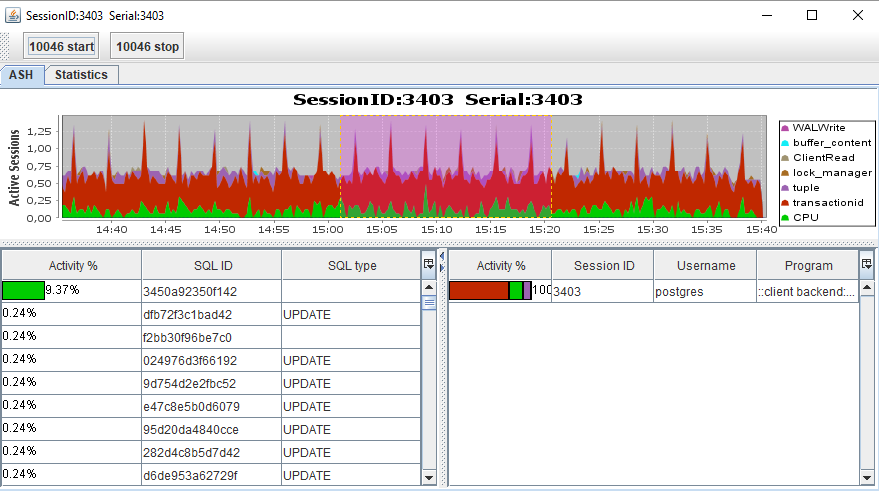 ASH
ASH : gráfico de actividad para session_id, de manera similar a SQL, haga doble clic en la línea de sesión desde el gráfico de Gantt.
Estadísticas : datos de la tabla por SQL_ID: obtener de V $ SESSION y V $ PROCESS. El código tiene la capacidad de agregar más entidades para las cuales puede hacer una selección (ver
implementación ).
Planes adicionales
- Instala la API. Realizar la refactorización del código final. Implemente el almacenamiento dinámico de los datos de monitoreo iniciales, que no dependerían de las versiones y tipos de la base de datos;
- Realmente no hay suficientes pruebas para probar los módulos clave del sistema, CI y otras mejores prácticas.
Código de proyecto Github,
archivos de proyecto;
Enlace al grupo en Telegram
t.me/ashviewer para informar sobre las últimas actualizaciones;
PD: ¿Quién decide conectarse con el desarrollo? Escriba al PM, sin demasiada emoción y sin crear un flechazo, por supuesto :).
Eso es todo. Gracias por su atencion!