
Cuando llegaron los orquestadores de contenedores como Kubernetes, el enfoque para desarrollar e implementar aplicaciones cambió drásticamente. Han aparecido microservicios, y para el desarrollador, la lógica de la aplicación ya no está conectada con la infraestructura: cree aplicaciones para usted y ofrezca nuevas funciones.
Kubernetes extrae de las computadoras físicas que controla. Solo dígale cuánta memoria y potencia de procesamiento necesita, y obtendrá todo. Infraestructura? No, no escuchado.
Administrar imágenes de Docker, Kubernetes y aplicaciones lo hace portátil. Después de haber desarrollado aplicaciones de contenedor con Kubernetes, puede implementarlas en cualquier lugar: en una nube abierta, localmente o en un entorno híbrido, sin cambiar el código.
Nos encanta Kubernetes por su escalabilidad, portabilidad y capacidad de administración, pero no almacena estados. Pero tenemos casi todas las aplicaciones con estado, es decir, necesitan almacenamiento externo.
Kubernetes tiene una arquitectura muy dinámica. Los contenedores se crean y destruyen según la carga y las instrucciones de los desarrolladores. Las vainas y los contenedores se autocuran y se replican. Son esencialmente efímeros.
El almacenamiento externo es demasiado resistente para tal variabilidad. No obedece las reglas de creación y destrucción dinámicas.
Solo necesito implementar una aplicación con estado en otra infraestructura: en otra nube allí, localmente o en un modelo híbrido, cómo tiene problemas de portabilidad. El almacenamiento externo se puede vincular a una nube específica.
Pero solo en estos almacenes para aplicaciones en la nube, el mismo diablo se romperá la pierna. Y ve a entender los significados ficticios y los significados de la terminología de almacenamiento en Kubernetes . Y hay repositorios propios de Kubernetes, plataformas de código abierto, servicios administrados o pagos ...
Estos son algunos ejemplos de almacenamiento en la nube CNCF :

Parece que implementa la base de datos en Kubernetes: solo necesita seleccionar la solución adecuada, empacarla en un contenedor para trabajar en el disco local e implementarla en el clúster como la próxima carga de trabajo. Pero la base de datos tiene sus propias peculiaridades, por lo que pensar no es un hielo.
Contenedores: están tan empedrados que no conservan su estado. Es por eso que son tan fáciles de iniciar y detener. Y como no hay nada que guardar y transferir, el clúster no se molesta con las operaciones de lectura y copia.
Deberá almacenar el estado con la base de datos. Si la base de datos implementada en el clúster en el contenedor no migra a ningún lado y no se inicia con demasiada frecuencia, la física del almacenamiento de datos entra en juego. Idealmente, los contenedores que usan datos deben estar en el mismo hogar que la base de datos.
En algunos casos, la base de datos, por supuesto, se puede implementar en un contenedor. En un entorno de prueba o en tareas donde hay poca información, las bases de datos viven cómodamente en grupos.
La producción generalmente requiere almacenamiento externo.
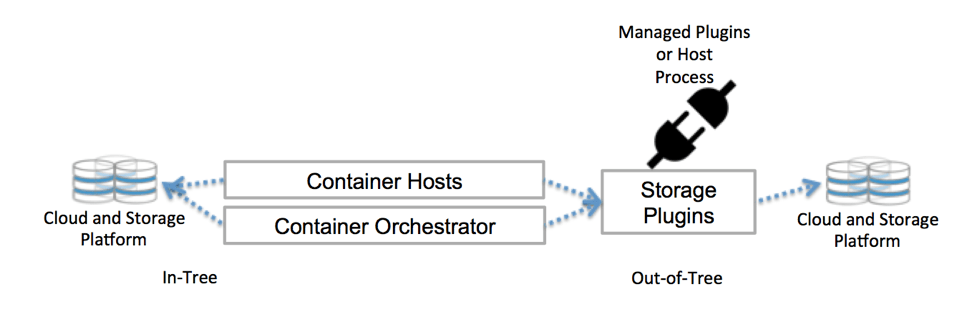
Kubernetes se comunica con el repositorio a través de interfaces de plano de control. Vinculan Kubernetes al almacenamiento externo. El almacenamiento externo conectado a Kubernetes se denomina complementos de volumen. Con ellos, puede abstraer el almacenamiento y transferir el almacenamiento.
Los complementos de volumen solían crearse , vincularse, compilarse y entregarse utilizando la base de código de Kubernetes. Esto limitó enormemente a los desarrolladores y requirió mantenimiento adicional: si desea agregar nuevos repositorios, cambie la base de código de Kubernetes.
Ahora implemente complementos de volumen en el clúster; no quiero hacerlo. Y no necesita profundizar en la base del código. Gracias a CSI y Flexvolume.
Kubernetes Native Storage
¿Cómo resuelve Kubernetes los problemas de almacenamiento? Hay varias soluciones: opciones efímeras, almacenamiento persistente en volúmenes persistentes, consultas de reclamo de volumen persistente, clases de almacenamiento o StatefulSets. Ve a resolverlo, en general.
Los volúmenes persistentes (PV) son unidades de almacenamiento preparadas por el administrador. No dependen de hogares y sus vidas fugaces.
El reclamo de volumen persistente (PVC) son solicitudes de almacenamiento, es decir, PV. Con PVC, puede vincular el almacenamiento a un nodo, y este nodo lo usará.
Puede trabajar con almacenamiento de forma estática o dinámica.
Con un enfoque estático, el administrador prepara los PV que se supone que deben servirse de antemano, antes de las solicitudes, y estos PV se vinculan manualmente a módulos específicos mediante PVC explícitos.
En la práctica, los PV especialmente definidos no son compatibles con la estructura portátil de Kubernetes: el almacenamiento depende del entorno, como AWS EBS o un disco GCE permanente. Para enlazar manualmente, debe apuntar a un repositorio específico en el archivo YAML.
El enfoque estático generalmente contradice la filosofía de Kubernetes: las CPU y la memoria no se asignan de antemano y no están conectadas a pods o contenedores. Se emiten dinámicamente.
Para el aprovisionamiento dinámico, utilizamos clases de almacenamiento. El administrador del clúster no necesita crear el PV por adelantado. Crea varios perfiles de almacenamiento, como plantillas. Cuando un desarrollador realiza una solicitud de PVC, en el momento de la solicitud, se crea uno de estos patrones y se adjunta a la chimenea.

Entonces, en los términos más generales, Kubernetes trabaja con almacenamiento externo. Hay muchas otras opciones.
CSI - Interfaz de almacenamiento de contenedores
Existe tal cosa - Interfaz de almacenamiento de contenedores . CSI fue creado por el grupo de trabajo de bóveda CNCF, que decidió definir una interfaz de almacenamiento de contenedor estándar para que los controladores de bóveda funcionen con cualquier orquesta.
Las especificaciones CSI ya están adaptadas para Kubernetes, y hay toneladas de complementos de controladores para implementaciones en el clúster de Kubernetes. Debe acceder al repositorio a través de un controlador de volumen compatible con CSI; use el tipo de volumen csi en Kubernetes.
Con CSI, el almacenamiento puede considerarse otra carga de trabajo para la contenedorización y la implementación en el clúster de Kubernetes.
Para más detalles, escuche a Jie Yu hablar sobre CSI en nuestro podcast .
Proyectos de código abierto
Las herramientas y proyectos para tecnologías en la nube se multiplican rápidamente, y una parte justa de los proyectos de código abierto, lo cual es lógico, resuelve uno de los principales problemas de producción: trabajar con el almacenamiento en la arquitectura de la nube.
Los más populares son Ceph y Rook.
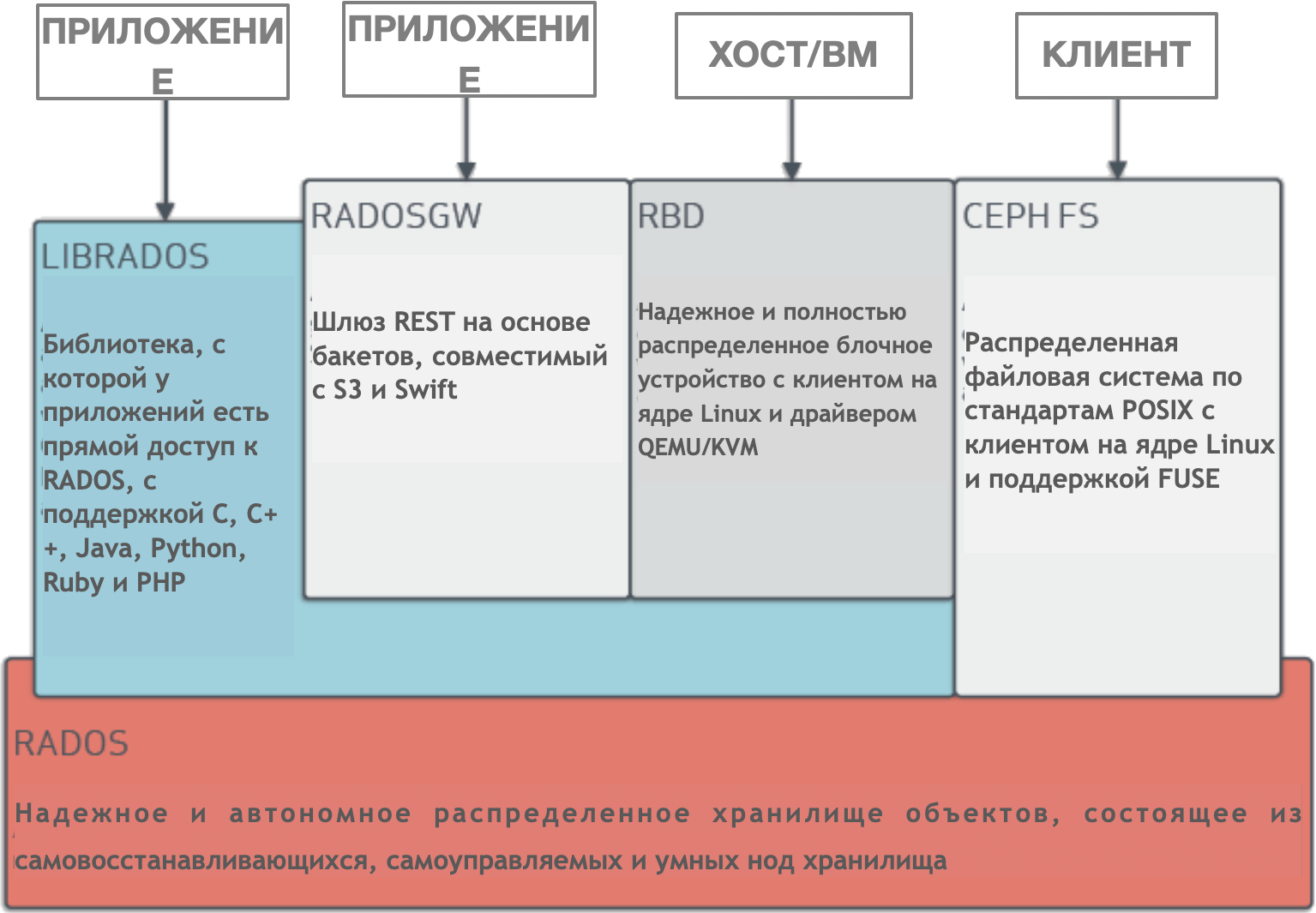
Ceph es un clúster de almacenamiento distribuido y administrado dinámicamente con escala horizontal. Ceph proporciona una abstracción lógica para los recursos de almacenamiento. No tiene un solo punto de falla, se maneja solo y funciona sobre la base del software. Ceph proporciona interfaces para almacenar bloques, objetos y archivos simultáneamente para un solo clúster de almacenamiento.
Ceph tiene una arquitectura muy compleja con algoritmos RADOS, librados, RADOSGW, RDB, CRUSH y varios componentes (monitores, OSD, MDS). No profundizaremos en la arquitectura, es suficiente entender que Ceph es un clúster de almacenamiento distribuido que simplifica la escalabilidad, elimina un solo punto de falla sin sacrificar el rendimiento y proporciona un almacenamiento único con acceso a objetos, bloques y archivos.
Naturalmente, Ceph está adaptado para la nube. Puede implementar un clúster Ceph de diferentes maneras, por ejemplo, usando Ansible o en un clúster de Kubernetes a través de CSI y PVC.
Arquitectura Ceph
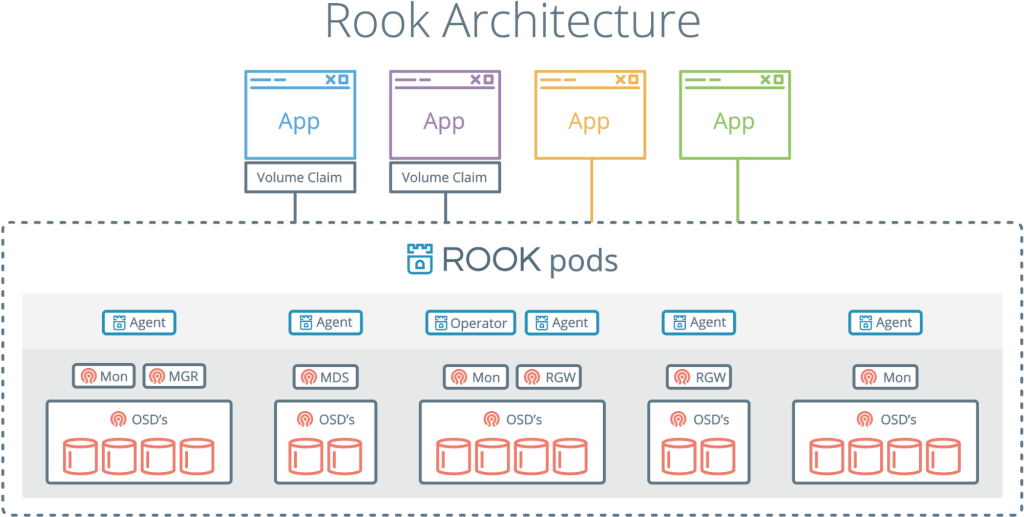
Rook es otro proyecto interesante y popular. Combina Kubernetes con su computación y Ceph con sus repositorios en un clúster.
Rook es un orquestador de almacenamiento en la nube que complementa a Kubernetes. Empacan Ceph en contenedores con él y usan la lógica de administración de clúster para un funcionamiento confiable de Ceph en Kubernetes. Rook automatiza la implementación, el arranque, el ajuste, el escalado, el reequilibrio, en general, todo lo que hace el administrador del clúster.
Con Rook, se puede implementar un clúster Ceph desde yaml, como Kubernetes. En este archivo, el administrador describe lo que necesita en el clúster. Rook lanza un clúster y comienza a monitorear activamente. Esto es algo así como un operador o controlador: garantiza que se cumplan todos los requisitos de yaml. Rook funciona con ciclos de sincronización: ve el estado y toma medidas si hay desviaciones.
Él no tiene su estado permanente y no necesita ser controlado. Está en el espíritu de Kubernetes.
Rook, que combina Ceph y Kubernetes, es una de las soluciones de almacenamiento en la nube más populares: 4.000 estrellas en Github, 16,3 millones de descargas y más de cien colaboradores.
El proyecto Rook ya ha sido aceptado en CNCF, y recientemente terminó en una incubadora .
Bassam Tabara le contará más sobre Rook en nuestro episodio de repositorio de Kubernetes .
Si la aplicación tiene un problema, debe conocer los requisitos y crear un sistema o tomar las herramientas necesarias. Esto también se aplica al almacenamiento en la nube. Y aunque el problema no es simple, las herramientas y los enfoques se han quedado cortos. La tecnología en la nube continúa evolucionando y seguramente nos esperan nuevas soluciones.