Recientemente, por necesidad, examiné todas las vacantes para desarrolladores de Go, y la mitad de ellas (al menos) mencionan la plataforma de procesamiento de mensajes
Apache Kafka y la base de datos
Redis NoSQL. Bueno, todos, por supuesto, quieren que el candidato conozca a Docker y a otros como él. Todos estos requisitos para nosotros, que hemos visto las opiniones de los ingenieros de sistemas, parecen de alguna manera insignificantes o algo así. Bueno, de hecho, ¿cómo difiere una línea de otra? La situación con las bases de datos NoSQL es, por supuesto, más diversa, pero aún así parecen más simples que cualquier servidor MS SQL. Todo esto, por supuesto, es mi personal, el
efecto Dunning - Kruger , mencionado muchas veces en el Habré.
Entonces, como todos los empleadores lo exigen, es necesario estudiar estas tecnologías. Pero comenzar con la lectura de toda la documentación de principio a fin no es muy interesante. En mi opinión, es más productivo leer la introducción, hacer un prototipo que funcione, corregir errores, encontrar problemas, resolverlos. Y después de todo esto, con comprensión, lea la documentación, o incluso un libro por separado.

Aquellos que estén interesados en poco tiempo para familiarizarse con las capacidades básicas de estos productos, sigan leyendo.
El programa de capacitación tendrá en cuenta los números. Consistirá en un generador de números grandes, un procesador de números, una cola, almacenamiento de columnas y un servidor web.
Durante el desarrollo, se aplicarán los siguientes patrones de diseño:
La arquitectura del sistema se verá así:
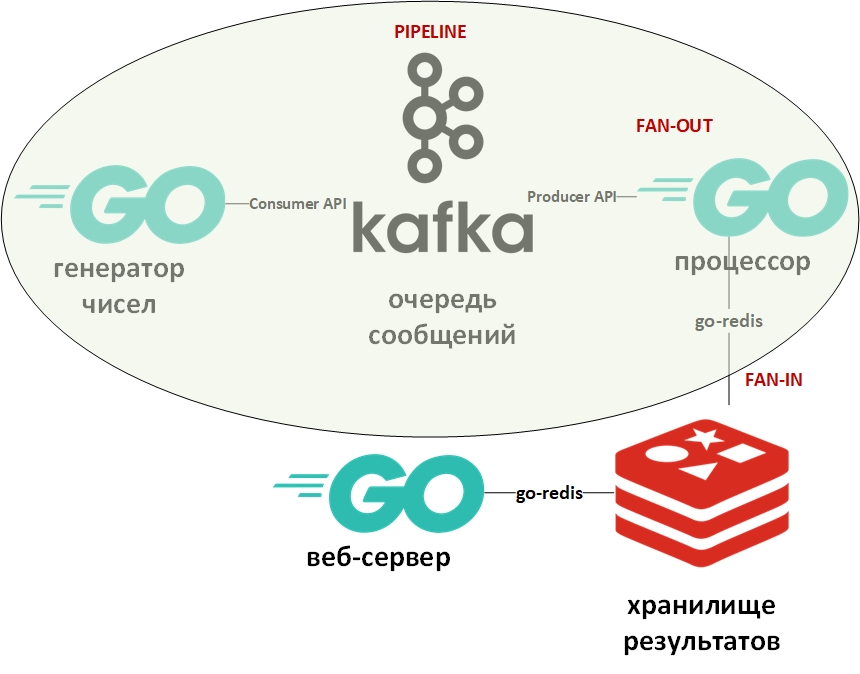
En la imagen, el óvalo indica el patrón de diseño del transportador. Me detendré en ello con más detalle.
La plantilla "transportador" supone que la información se presenta en forma de flujo y se procesa por etapas. Por lo general, hay algún generador (fuente de información) y uno o más procesadores (procesadores de información). En este caso, el generador será un programa en Go que pone en cola grandes números aleatorios. Y el procesador (el único) será un programa que toma datos de la cola y lleva a cabo la factorización. En Go puro, este patrón es bastante fácil de implementar usando canales (chan). Arriba hay un enlace a mi github con un ejemplo. Aquí, la cola de mensajes desempeñará el papel de canales.
Fan-In: las plantillas de Fan-Out generalmente se usan juntas y, según se aplica a Go, significan la paralelización de los cálculos usando gorutinas, seguidas de un resumen de los resultados y su transferencia, por ejemplo, hacia abajo. Un enlace a un ejemplo también se da arriba. Nuevamente, el canal fue reemplazado por la cola, las gorutinas permanecieron en su lugar.
Ahora algunas palabras sobre Apache Kafka. Kafka es un sistema de gestión de mensajes que tiene excelentes herramientas de agrupación, utiliza un registro de transacciones (exactamente como en un RDBMS) para almacenar mensajes y admite tanto el modelo de cola como el modelo de editor / suscriptor. Esto último se logra a través de grupos de destinatarios de mensajes. Cada mensaje recibe solo un miembro del grupo (procesamiento paralelo), pero el mensaje se entregará una vez a cada grupo. Puede haber muchos de esos grupos, así como también destinatarios dentro de cada grupo.
Para trabajar con Kafka utilizaré el paquete "github.com/segmentio/kafka-go".
Redis, por otro lado, es una base de datos de columnas de valor clave en la memoria que admite la capacidad de almacenar datos de forma permanente. El tipo de datos principal para claves y valores son las cadenas, pero hay algunos otros. Redis se considera una de las bases de datos más rápidas (o más) de su clase. Es bueno almacenar todo tipo de estadísticas, métricas, flujos de mensajes, etc.
Para trabajar con Redis usaré el paquete "github.com/go-redis/redis".
Dado que este artículo es un comienzo rápido, implementaremos ambos sistemas con Docker utilizando imágenes ya preparadas de DockerHub. Uso docker-compose en Windows 10 en modo contenedor en una máquina virtual Linux (creada automáticamente por Docker VM) con este archivo docker-compose.yml como este:
version: '2' services: zookeeper: image: wurstmeister/zookeeper ports: - "2181:2181" kafka: image: wurstmeister/kafka:latest ports: - "9092:9092" environment: KAFKA_ADVERTISED_HOST_NAME: 127.0.0.1 KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181 KAFKA_CREATE_TOPICS: "Generated:1:1,Solved:1:1,Unsolved:1:1" KAFKA_DELETE_TOPIC_ENABLE: "true" volumes: - /var/run/docker.sock:/var/run/docker.sock redis: image: redis ports: - "6379:6379"
Guarde este archivo, vaya al directorio con él y ejecute:
docker-compose up -d
Se deben descargar e iniciar tres contenedores: Kafka (cola), Zookeeper (servidor de configuración para Kafka) y (Redis).
Puede verificar que los contenedores funcionan con el comando:
docker-compose ps
Debería ser algo como:
Name State Ports -------------------------------------------------------------------------------------- docker-compose_kafka_1 Up 0.0.0.0:9092->9092/tcp docker-compose_redis_1 Up 0.0.0.0:6379->6379/tcp docker-compose_zookeeper_1 Up 0.0.0.0:2181->2181/tcp, 22/tcp, 2888/tcp, 3888/tcp
Según el archivo yml, se deben crear automáticamente tres colas, puede verlas con el comando:
docker exec kafka-container_kafka_1 /opt/kafka_2.12-2.1.0/bin/kafka-topics.sh --list --zookeeper zookeeper:2181
Debe haber colas (temas - temas en términos de Kafka) generados, resueltos y no resueltos.
El generador de datos pone en cola infinitamente los números con un retraso aleatorio. Su código es extremadamente simple. Puede verificar la presencia de mensajes en la cola Generada usando el comando:
docker exec kafka-container_kafka_1 /opt/kafka_2.12-2.1.0/bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic Generated --from-beginning
El siguiente es el
procesador : aquí debe prestar atención a la paralelización del procesamiento de valores de la cola en el siguiente bloque de código:
var wg sync.WaitGroup c := 0
Como la lectura de la cola de mensajes bloquea el programa, creé un objeto context.Context con un tiempo de espera de 15 segundos. Este tiempo de espera terminará el programa si la cola está vacía durante mucho tiempo.
Además, para cada gorutina que factoriza el número, también se establece el tiempo de funcionamiento máximo. Quería que los números que podían factorizar se escribieran en una base de datos. Y los números que no se pudieron factorizar en el tiempo asignado se transfirieron a otra base de datos.
Para determinar el tiempo aproximado, se utilizó el punto de referencia:
func BenchmarkFactorize(b *testing.B) { ch := make(chan []int) var factors []int for i := 1; i < bN; i++ { num := 2345678901234 go factorize(num, ch) factors = <-ch b.Logf("\n%d %+v\n\n", num, factors) } }
Los puntos de referencia en Go son variedades de pruebas y se colocan en un archivo con pruebas. En base a esta medición, se seleccionó el número máximo para el generador de números aleatorios. En mi computadora, parte de los números tuvieron tiempo de factorizarse, y parte no.
Esos números que podrían descomponerse se escribieron en DB No. 0, números no descompuestos en DB No. 1.
Aquí debo decir que en Redis no hay tablas y tablas en el sentido clásico. Por defecto, el DBMS contiene 16 bases de datos disponibles para el programador. Estas bases difieren en sus números, de 0 a 15.
El límite de tiempo para goroutines en el procesador se proporcionó utilizando el contexto y la instrucción select:
Este es otro de los trucos de desarrollo típicos en Go. Su significado es que la instrucción select itera sobre los canales y ejecuta el código correspondiente al primer canal activo. En este caso, goroutine mostrará el resultado en su canal o se cerrará el canal de contexto con un tiempo de espera. En lugar de contexto, puede utilizar un canal arbitrario que actuará como administrador y proporcionará la terminación forzada de goroutines.
Las subrutinas para escribir en la base de datos ejecutan el comando para seleccionar la base de datos deseada (0 o 1) y escribir pares de la forma (número - factores) para números analizados o (número - número) para números sin descomponer.
func storeSolved(item data) (err error) {
La última parte será un
servidor web , que mostrará una lista de números descompuestos y no descompuestos en forma de json. Tendrá dos puntos finales:
http.HandleFunc("/solved", solvedHandler) http.HandleFunc("/unsolved", unsolvedHandler)
El controlador de solicitud http con la recepción de datos de Redis y devolverlo como json se ve así:
func solvedHandler(w http.ResponseWriter, r *http.Request) { w.Header().Set("Content-Type", "application/json") w.Header().Set("Access-Control-Allow-Origin", "*") w.Header().Set("Access-Control-Allow-Methods", "GET") w.Header().Set("Access-Control-Allow-Headers", "Accept, Content-Type, Content-Length, Accept-Encoding, X-CSRF-Token, Authorization")
El resultado de la solicitud en:
localhost / resuelto [{ "Key": "1604388558816", "Val": "[1,2,3,227]" }, { "Key": "545232916387", "Val": "[1,545232916387]" }, { "Key": "1786301239076", "Val": "[1,2]" }, { "Key": "698495534061", "Val": "[1,3,13,641,165331]" }]
Ahora puede profundizar en la documentación y literatura especializada. Espero que el artículo haya sido útil.
Pido a los expertos que no sean demasiado vagos y señalen mis errores.