"En el modo de rastreo, el programador ve la secuencia de ejecución del comando y los valores de las variables en este paso de la ejecución del programa, lo que facilita la detección de errores", nos dice Wikipedia. Como fanáticos de Linux, nos encontramos regularmente con la pregunta de qué herramientas específicas son las mejores para implementarlo. Y queremos compartir la traducción de un artículo del programador Hongley Lai que recomienda bpftrace. Mirando hacia el futuro, diré que el artículo termina sucintamente: "bpftrace es el futuro". Entonces, ¿por qué impresionó tanto al colega de Lai? Una respuesta detallada debajo del corte.
Hay dos herramientas principales de rastreo en Linux:
strace le permite ver qué llamadas al sistema se están realizando;
ltrace le permite ver qué bibliotecas dinámicas se están llamando.
A pesar de su utilidad, estas herramientas son limitadas. ¿Y si necesita averiguar qué sucede dentro de un sistema o una llamada a la biblioteca? ¿Y si necesita no solo compilar una lista de llamadas, sino también, por ejemplo, recopilar estadísticas sobre cierto comportamiento? ¿Y si necesita rastrear varios procesos y comparar datos de varias fuentes?
En 2019, finalmente obtuvimos una respuesta decente a estas preguntas en Linux:
bpftrace basado en la tecnología
eBPF . Bpftrace le permite escribir pequeños programas que se ejecutan cada vez que ocurre un evento.
En este artículo describiré cómo instalar bpftrace y enseñaré su aplicación básica. También daré una descripción general de cómo se ve el ecosistema de rastreo (por ejemplo, “¿qué es eBPF?”) Y cómo ha evolucionado hasta convertirse en lo que tenemos hoy.
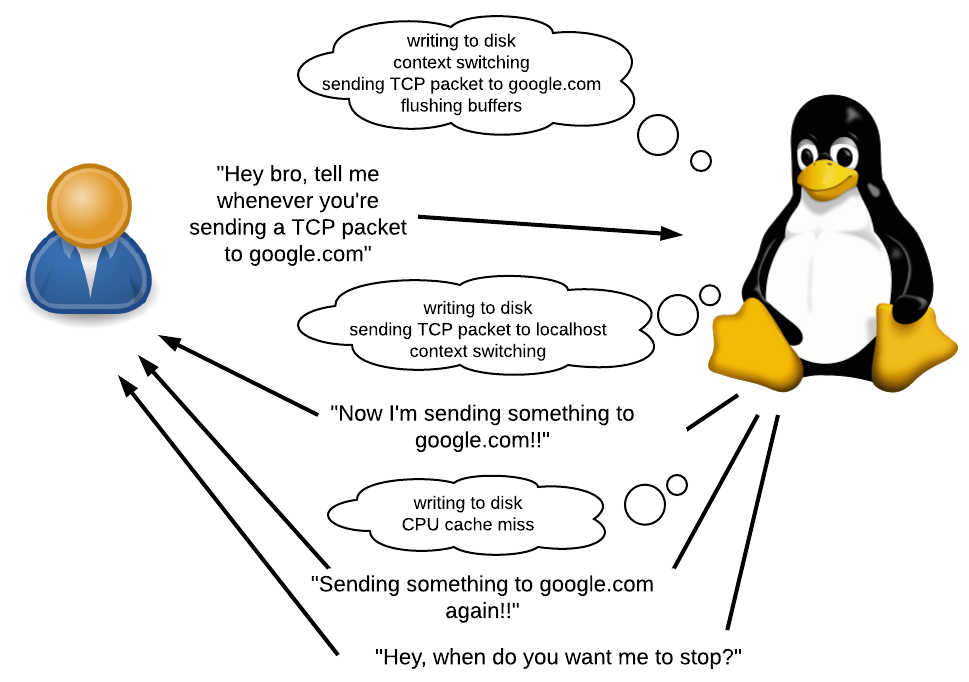
¿Qué es un rastro?
Como se mencionó anteriormente, bpftrace le permite escribir pequeños programas que se ejecutan cada vez que ocurre un evento.
¿Qué es un evento? Podría ser una llamada al sistema, una llamada a la función o incluso algo que ocurre dentro de tales solicitudes. También puede ser un temporizador o un evento de hardware, por ejemplo, "han transcurrido 50 ms desde el último de los mismos eventos", "se produjo un error de página", "se produjo un cambio de contexto" o "se produjo un procesador de pérdida de cobro".
¿Qué se puede hacer en respuesta a un evento? Puede prometer algo, recopilar estadísticas y ejecutar comandos de shell arbitrarios. Tendrá acceso a diversa información contextual, como el PID actual, el seguimiento de la pila, el tiempo, los argumentos de llamada, los valores de retorno, etc.
Cuando usar En muchos. Puede averiguar por qué la aplicación es lenta compilando una lista de las llamadas más lentas. Puede determinar si hay pérdidas de memoria en la aplicación y, de ser así, dónde. Lo uso para entender por qué Ruby usa tanta memoria.
La gran ventaja de bpftrace es que no necesita volver a compilar la aplicación. No es necesario escribir manualmente llamadas impresas ni ningún otro código de depuración en el código fuente de la aplicación en estudio. Ni siquiera es necesario reiniciar las aplicaciones. Y todo esto con gastos generales muy bajos. Esto hace que bpftrace sea especialmente útil para depurar sistemas directamente en el producto o en otra situación donde hay dificultades con la recompilación.
DTrace: padre del rastro
Durante mucho tiempo, la mejor herramienta de rastreo fue
DTrace , un completo marco de rastreo dinámico desarrollado originalmente por Sun Microsystems (los creadores de Java). Al igual que bpftrace, DTrace le permite escribir pequeños programas que se ejecutan en respuesta a eventos. De hecho, muchos de los elementos clave del ecosistema son desarrollados en gran parte por
Brendan Gregg , un reconocido experto de DTrace que actualmente trabaja en Netflix. Lo que explica las similitudes entre DTrace y bpftrace.
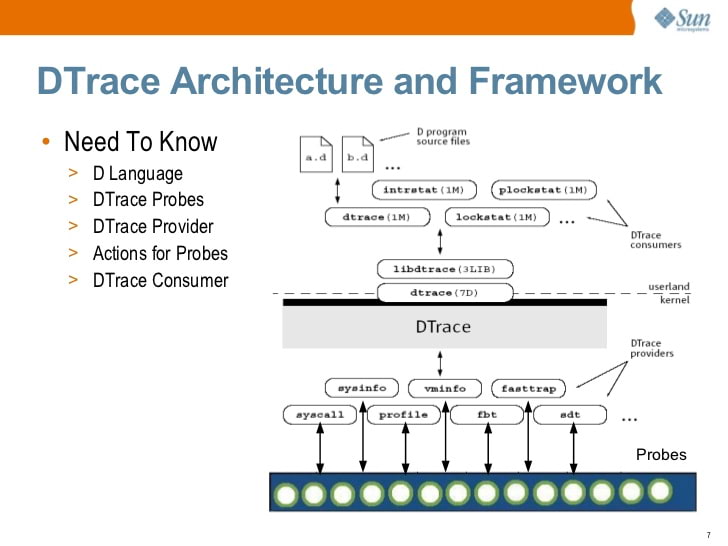 Introducción a Solaris DTrace (2009) por S. Tripathi, Sun Microsystems
Introducción a Solaris DTrace (2009) por S. Tripathi, Sun MicrosystemsEn algún momento, Sun abrió la fuente de DTrace. Hoy, DTrace está disponible en Solaris, FreeBSD y macOS (aunque la versión de macOS generalmente no funciona porque System Integrity Protection, SIP, ha roto muchos de los principios en los que se ejecuta DTrace).
Sí, has notado correctamente ... Linux no está en esta lista. Esto no es un problema de ingeniería, es un problema de licencia. DTrace se abrió bajo el CDDL en lugar de la GPL.
El puerto Linux DTrace ha estado disponible desde 2011, pero nunca ha sido compatible con los principales desarrolladores de Linux. A principios de 2018,
Oracle volvió a abrir DTrace bajo la GPL , pero para entonces ya era demasiado tarde.
Ecosistema de rastreo de Linux
Sin duda, el rastreo es muy útil, y la comunidad de Linux ha tratado de desarrollar sus propias soluciones a este tema. Pero, a diferencia de Solaris, Linux no está regulado por un proveedor específico y, por lo tanto, no hubo un esfuerzo deliberado para desarrollar un reemplazo completamente funcional para DTrace. El ecosistema de rastreo de Linux ha evolucionado lenta y naturalmente, resolviendo problemas a medida que surgen. Y solo recientemente este ecosistema ha crecido lo suficiente como para competir seriamente con DTrace.
Debido al crecimiento natural, este ecosistema puede parecer un poco caótico, y consta de muchos componentes diferentes. Afortunadamente, Julia Evans
escribió una revisión de este ecosistema (atención, fecha de publicación - 2017, antes del advenimiento de bpftrace).
 Ecosistema de rastreo de Linux descrito por Julia Evans
Ecosistema de rastreo de Linux descrito por Julia EvansNo todos los elementos son igualmente importantes. Permítanme resumir brevemente qué elementos considero más importantes.
Fuentes de eventosLos datos de eventos pueden provenir del núcleo o del espacio de usuario (aplicaciones y bibliotecas). Algunos de ellos están disponibles automáticamente, sin esfuerzos adicionales del desarrollador, mientras que otros requieren un anuncio manual.
 Descripción general de las fuentes más importantes de eventos rastreados en Linux
Descripción general de las fuentes más importantes de eventos rastreados en LinuxEn el lado del núcleo, hay kprobes (
de "sondas del núcleo", "sensor del núcleo", aprox. Per. ), Un mecanismo que le permite rastrear cualquier llamada de función dentro del núcleo. Con él, puede rastrear no solo las llamadas del sistema, sino también lo que sucede dentro de ellos (porque los puntos de entrada de las llamadas del sistema llaman a otras funciones internas). También puede usar kprobes para rastrear eventos del kernel que no son llamadas del sistema, por ejemplo, "los datos almacenados en el búfer se escriben en el disco", "el paquete TCP se envía a través de la red" o "el cambio de contexto está en curso".
Los puntos de rastreo del núcleo permiten rastrear eventos no estándar definidos por los desarrolladores del núcleo. Estos eventos no están al nivel de las llamadas a funciones. Para crear tales puntos, los desarrolladores del kernel colocan manualmente la macro TRACE_EVENT en el código del kernel.
Ambas fuentes tienen pros y contras. Kprobes funciona "automáticamente" porque no requiere que los desarrolladores del kernel codifiquen manualmente el código. Pero los eventos kprobe pueden cambiar arbitrariamente de una versión del kernel a otra, porque las funciones cambian constantemente: se agregan, eliminan y cambian de nombre.
Los puntos de traza del núcleo son generalmente más estables en el tiempo y pueden proporcionar información contextual útil que puede no estar disponible si se usa kprobes. Usando kprobes, puede acceder a argumentos de llamada de función. Pero con la ayuda de puntos de rastreo, puede obtener cualquier información que el desarrollador del núcleo decida describir manualmente.
En el espacio de usuario hay un análogo de kprobes: uprobes. Está diseñado para rastrear llamadas a funciones en el espacio del usuario.
Los sensores USDT ("Rastreos de espacio de usuario definidos estáticamente") son un análogo de los puntos de rastreo del núcleo en el espacio de usuario. Los desarrolladores de aplicaciones necesitan agregar manualmente sensores USDT a su código.
Dato interesante: DTrace ha proporcionado durante mucho tiempo la API de C para definir su propio análogo de sensores USDT (utilizando la macro DTRACE_PROBE). Los desarrolladores de ecosistemas de rastreo en Linux decidieron dejar el código fuente compatible con esta API, por lo que cualquier macro DTRACE_PROBE se convierte automáticamente en sensores USDT.
Por lo tanto, en teoría, strace se puede implementar usando kprobes, y ltrace se puede implementar usando uprobes. No estoy seguro de si esto ya se practica o no.
InterfacesLas interfaces son aplicaciones que permiten a los usuarios usar fácilmente orígenes de eventos.
Veamos cómo funcionan las fuentes de eventos. El flujo de trabajo es el siguiente:
- El kernel representa un mecanismo, generalmente un archivo / proc o / sys que está abierto para escritura, que registra tanto la intención de rastrear el evento como lo que debería seguir al evento.
- Después de registrarse, el núcleo localiza en la memoria el núcleo / función en el espacio de usuario / puntos de rastreo / sensores USDT y cambia su código para que ocurra algo más.
- El resultado de este "algo más" se puede recoger más tarde utilizando algún mecanismo.
¡No quisiera hacer todo esto manualmente! Por lo tanto, las interfaces vienen al rescate: hacen todo esto por usted.
Hay interfaces para todos los gustos y colores. En el campo de las
interfaces basadas en eBPF, existen
interfaces de bajo nivel que requieren una comprensión profunda de cómo interactuar con las fuentes de eventos y cómo funciona el bytecode de eBPF. Y son de alto nivel y fáciles de operar, aunque durante su existencia no demostraron una gran flexibilidad.
Es por eso que bpftrace, la última interfaz, es mi favorita. Es fácil de usar y flexible como DTrace. Pero es bastante nuevo y requiere pulido.
eBPF
eBPF es la
nueva estrella de rastreo de Linux en la que se basa bpftrace. Cuando rastrea un evento, desea que algo suceda en el núcleo. ¿Qué manera flexible de determinar qué es este "algo"? Por supuesto, usando un lenguaje de programación (o usando código de máquina).
eBPF (versión mejorada del filtro de paquetes Berkeley). Esta es una máquina virtual de alto rendimiento que se ejecuta en el núcleo y tiene las siguientes propiedades / limitaciones:
- Todas las interacciones del espacio del usuario ocurren a través de "tarjetas" eBPF, que son almacenamiento de datos de valor clave.
- No hay ciclos para que cada programa eBPF finalice en un momento específico.
- Espera, dijimos Batch Filter? Tienes razón: originalmente fueron diseñados para filtrar paquetes de red. Esta es una tarea similar: al reenviar paquetes (la ocurrencia de un evento) debe realizar alguna acción administrativa (aceptar, descartar, registrar o redirigir un paquete, etc.) Se inventó una máquina virtual para acelerar tales acciones (con capacidad JIT) compilación). Se considera una versión "extendida" debido al hecho de que, en comparación con la versión original del Berkeley Packet Filter, eBPF puede usarse fuera del contexto de la red.
Ahí tienes. Con bpftrace, puede determinar qué eventos rastrear y qué debería suceder en respuesta. Bpftrace compila su programa bpftrace de alto nivel en el código de bytes eBPF, rastrea eventos y carga el código de bytes en el núcleo.
Días oscuros antes de eBPF
Antes de eBPF, las opciones de solución eran, por decirlo suavemente, incómodas.
SystemTap es un poco el predecesor "más serio" para bpftrace en la familia Linux. Los scripts de SystemTap se traducen al lenguaje C y se cargan en el núcleo como módulos. El módulo de kernel resultante se carga.
Este enfoque era muy frágil y mal soportado fuera de Red Hat Enterprise Linux. Para mí, nunca funcionó bien en Ubuntu, que tendió a romper SystemTap en cada actualización del núcleo debido a un cambio en la estructura de datos del núcleo. También se dice que en los primeros días de su existencia, SystemTap
fácilmente condujo al kernel panic .
Instalación de bpftrace
¡Es hora de remangarse las mangas! En esta guía, veremos cómo instalar bpftrace en Ubuntu 18.04. Las versiones más nuevas de la distribución no son deseables, porque durante la instalación, necesitaremos paquetes que aún no se hayan compilado para ellos.
Instalación de dependenciaPrimero, instale Clang 5.0, lbclang 5.0 y LLVM 5.0, incluidos todos los archivos de encabezado. Utilizaremos los paquetes proporcionados por llvm.org, porque los que están en los repositorios de Ubuntu son
problemáticos .
wget -O - https://apt.llvm.org/llvm-snapshot.gpg.key | sudo apt-key add - cat <<EOF | sudo tee -a /etc/apt/sources.list deb http://apt.llvm.org/xenial/ llvm-toolchain-xenial main deb-src http://apt.llvm.org/xenial/ llvm-toolchain-xenial main deb http://apt.llvm.org/xenial/ llvm-toolchain-xenial-5.0 main deb-src http://apt.llvm.org/xenial/ llvm-toolchain-xenial-5.0 main EOF sudo apt update sudo apt install clang-5.0 libclang-5.0-dev llvm-5.0 llvm-5.0-dev
Siguiente:
sudo apt install bison cmake flex g++ git libelf-dev zlib1g-dev libfl-dev
Y, por último, instale libbfcc-dev desde arriba, no desde el repositorio de Ubuntu. No
hay archivos de encabezado en el paquete que se encuentra en Ubuntu. Y este problema no se resolvió ni siquiera a las 18.10.
sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys 4052245BD4284CDD echo "deb https://repo.iovisor.org/apt/$(lsb_release -cs) $(lsb_release -cs) main" | sudo tee /etc/apt/sources.list.d/iovisor.list sudo apt update sudo apt install bcc-tools libbcc-examples linux-headers-$(uname -r)
Instalación principal de bpftrace¡Es hora de instalar bpftrace desde la fuente! Vamos a clonarlo, ensamblarlo e instalarlo en / usr / local:
git clone https://github.com/iovisor/bpftrace cd bpftrace mkdir build && cd build cmake -DCMAKE_BUILD_TYPE=DEBUG .. make -j4 sudo make install
Y ya terminaste! El ejecutable se instalará en / usr / local / bin / bpftrace. Puede cambiar el destino utilizando el argumento cmake, que se ve así de forma predeterminada:
DCMAKE_INSTALL_PREFIX=/usr/local.
Ejemplos de una líneaEjecutemos algunos bpftrace single-liners para comprender nuestras capacidades. Tomé estos de la
guía de
Brendan Gregg , que tiene una descripción detallada de cada uno de ellos.
# 1. Mostrar una lista de sensores
bpftrace -l 'tracepoint:syscalls:sys_enter_*'
# 2. Saludos
bpftrace -e 'BEGIN { printf("hello world\n"); }'
# 3. Abrir un archivo
bpftrace -e 'tracepoint:syscalls:sys_enter_open { printf("%s %s\n", comm, str(args->filename)); }'
# 4. El número de llamadas al sistema por proceso
bpftrace -e 'tracepoint:raw_syscalls:sys_enter { @[comm] = count(); }'
# 5. Distribución de llamadas read () por número de bytes
bpftrace -e 'tracepoint:syscalls:sys_exit_read /pid == 18644/ { @bytes = hist(args->retval); }'
# 6. Rastreo dinámico de contenido read ()
bpftrace -e 'kretprobe:vfs_read { @bytes = lhist(retval, 0, 2000, 200); }'
# 7. Tiempo empleado en llamadas read ()
bpftrace -e 'kprobe:vfs_read { @start[tid] = nsecs; } kretprobe:vfs_read /@start[tid]/ { @ns[comm] = hist(nsecs - @start[tid]); delete(@start[tid]); }'
# 8. Conteo de eventos a nivel de proceso
bpftrace -e 'tracepoint:sched:sched* { @[name] = count(); } interval:s:5 { exit(); }'
# 9. Pilar de trabajo del kernel de perfilado
bpftrace -e 'profile:hz:99 { @[stack] = count(); }'
# 10. Planificador de seguimiento
bpftrace -e 'tracepoint:sched:sched_switch { @[stack] = count(); }'
# 11. Rastreo de bloqueo de E / S
bpftrace -e 'tracepoint:block:block_rq_complete { @ = hist(args->nr_sector * 512); }'
Visite el sitio web de Brendan Gregg para averiguar
qué tipo de salida pueden generar los equipos anteriores .
Ejemplo de sintaxis de script y temporización de E / SLa cadena que se pasa a través del modificador '-e' es el contenido del script bpftrace. La sintaxis en este caso es, condicionalmente, un conjunto de construcciones:
<event source> /<optional filter>/ { <program body> }
Veamos el séptimo ejemplo, sobre los tiempos de las operaciones de lectura del sistema de archivos:
kprobe:vfs_read { @start[tid] = nsecs; } <- 1 -><-- 2 -> <---------- 3 --------->
Trazamos el evento desde el mecanismo
kprobe , es decir, rastreamos el comienzo de la función del núcleo.
La función del kernel para el rastreo es
vfs_read , esta función se llama cuando el kernel realiza una operación de lectura desde el sistema de archivos (VFS desde "Virtual FileSystem", abstracción del sistema de archivos dentro del kernel).
Cuando
vfs_read comienza a
ejecutarse (es decir, antes de que la función haya realizado un trabajo útil), se inicia el programa bpftrace. Guarda la marca de tiempo actual (en nanosegundos) en una matriz asociativa global llamada
st art . La clave es
tid , una referencia al id del subproceso actual.
kretprobe:vfs_read /@start[tid]/ { @ns[comm] = hist(nsecs - @start[tid]); delete(@start[tid]); } <-- 1 --> <-- 2 -> <---- 3 ----> <----------------------------- 4 ----------------------------->
1.
Trazamos el evento desde el mecanismo
kretprobe , que es similar a
kprobe , excepto que se llama cuando la función devuelve el resultado de su ejecución.
2. La función del núcleo para el rastreo es
vfs_read .
3. Este es un filtro opcional. Comprueba si la hora de inicio se ha registrado previamente. Sin este filtro, el programa se puede iniciar mientras lee y captura solo el final, lo que resulta en un tiempo
estimado nsecs - 0 , en lugar de
nsecs - start .
4. El cuerpo del programa.
nsecs - st art [tid] calcula cuánto tiempo ha pasado desde el inicio de la función vfs_read.
@ns [comm] = hist (...) agrega los datos especificados al histograma bidimensional almacenado en
@ns . La tecla de
comunicación se refiere al nombre de la aplicación actual. Entonces tendremos un histograma comando por comando.
delete (...) elimina la hora de inicio de la matriz asociativa, porque ya no la necesitamos.
Esta es la conclusión final. Tenga en cuenta que todos los histogramas se muestran automáticamente. No se requiere el uso explícito del comando print histogram.
@ns no es una variable especial, por lo que el histograma no se muestra por eso.
@ns[snmp-pass]: [0, 1] 0 | | [2, 4) 0 | | [4, 8) 0 | | [8, 16) 0 | | [16, 32) 0 | | [32, 64) 0 | | [64, 128) 0 | | [128, 256) 0 | | [256, 512) 27 |@@@@@@@@@ | [512, 1k) 125 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ | [1k, 2k) 22 |@@@@@@@ | [2k, 4k) 1 | | [4k, 8k) 10 |@@@ | [8k, 16k) 1 | | [16k, 32k) 3 |@ | [32k, 64k) 144 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@| [64k, 128k) 7 |@@ | [128k, 256k) 28 |@@@@@@@@@@ | [256k, 512k) 2 | | [512k, 1M) 3 |@ | [1M, 2M) 1 | |
Ejemplo de sensor de USDTTomemos este código C y guárdelo en el archivo
tracetest.c :
#include <sys/sdt.h> #include <sys/time.h> #include <unistd.h> #include <stdio.h> static long myclock() { struct timeval tv; gettimeofday(&tv, NULL); DTRACE_PROBE1(tracetest, testprobe, tv.tv_sec); return tv.tv_sec; } int main(int argc, char **argv) { while (1) { myclock(); sleep(1); } return 0; }
Este programa se ejecuta sin cesar llamando a
myclock () una vez por segundo.
myclock () consulta la hora actual y devuelve el número de segundos desde el comienzo de la era.
La llamada a
DTRACE_PROBE1 aquí define un punto de rastreo estático USDT.
- La macro DTRACE_PROBE1 se toma de sys / sdt.h. La macro oficial de USDT, que hace lo mismo, se llama STAP_PROBE1 (STAP de SystemTap, que fue el primer mecanismo de Linux admitido en USDT). Pero dado que USDT es compatible con los sensores de espacio de usuario DTrace, DTRACE_PROBE1 es solo una referencia a STAP_PROBE1 .
- El primer parámetro es el nombre del proveedor. Creo que este es un vestigio sobrante de DTrace, porque bpftrace no parece estar haciendo nada útil con él. Sin embargo, hay un matiz ( que descubrí al depurar el problema en la aplicación 328 ): el nombre del proveedor debe ser idéntico al nombre del archivo binario de la aplicación; de lo contrario, bpftrace no podrá encontrar el punto de rastreo.
- El segundo parámetro es el nombre del punto de rastreo.
- Cualquier parámetro adicional es el contexto proporcionado por los desarrolladores. El número 1 en DTRACE_PROBE1 significa que queremos pasar un parámetro adicional.
Asegurémonos de que sys / sdt.h esté disponible para nosotros, y armemos el programa:
sudo apt install systemtap-sdt-dev gcc tracetest.c -o tracetest -Wall -g
Le indicamos a bpftrace que muestre el PID y "el tiempo es [número]" cada
vez que se alcanza la
prueba de prueba :
sudo bpftrace -e 'usdt:/full-path-to/tracetest:testprobe { printf("%d: time is %d\n", pid, arg0); }'
Bpftrace continúa funcionando mientras presionamos Ctrl-C. Por lo tanto, abra una nueva terminal y ejecute
tracetest allí:
# En la nueva terminal
./tracetest
Regrese a la primera terminal con bpftrace, allí debería ver algo como:
Attaching 1 probe... 30909: time is 1549023215 30909: time is 1549023216 30909: time is 1549023217 ... ^C
Ejemplo de asignación de memoria usando glibc ptmallocUtilizo bpftrace para entender por qué Ruby usa tanta memoria. Y como parte de mi investigación, necesito comprender cómo el asignador de memoria de glibc usa
regiones de memoria .
Para optimizar el rendimiento multinúcleo, el asignador de memoria glibc asigna varias "áreas" del sistema operativo. Cuando la aplicación solicita la asignación de memoria, el asignador selecciona un área que no está en uso y marca parte de esta área como "usada". Dado que los subprocesos utilizan diferentes áreas, se reduce el número de bloqueos, lo que conduce a un rendimiento mejorado de subprocesos múltiples.
Pero este enfoque genera mucha basura, y parece que un consumo de memoria tan alto en Ruby se debe precisamente a eso. Para comprender mejor la naturaleza de esta basura, me preguntaba: ¿qué significa "elegir un área que no se utiliza"? Esto puede significar uno de:
- Cada vez que se llama a malloc () , el asignador recorre en iteración todas las áreas y encuentra la que no está bloqueada actualmente. Y solo si están todos bloqueados, intentará crear uno nuevo.
- La primera vez que se llama a malloc () en un subproceso específico (o cuando se inicia el subproceso), el asignador seleccionará el que no está bloqueado actualmente. Y si todos están bloqueados, intentará crear uno nuevo.
- La primera vez que se llama a malloc () en un subproceso específico (o cuando se inicia el subproceso), el asignador intentará crear una nueva región, independientemente de si hay regiones desbloqueadas. Solo si no se puede crear un área nueva (por ejemplo, cuando se agota el límite), reutilizará la existente.
- Probablemente hay más opciones que no he considerado.
No hay una respuesta específica en la documentación, cuál de estas características le permite seleccionar un área que no se utiliza. Estudié el código fuente de glibc, que sugirió que la opción 3 podría hacer esto. Pero quería verificar experimentalmente que interpretaba el código fuente correctamente, sin la necesidad de depurar el código en glibc.
Aquí está la función del asignador de memoria glibc que crea una nueva área. Pero puede llamarlo solo después de verificar el límite.
static mstate _int_new_arena(size_t size) { mstate arena; size = calculate_how_much_memory_to_ask_from_os(size); arena = do_some_stuff_to_allocate_memory_from_os(); LIBC_PROBE(memory_arena_new, 2, arena, size); do_more_stuff(); return arena; }
¿Puedo usar
uprobes para rastrear la función
_int_new_arena ? Lamentablemente no. Por alguna razón, este símbolo no está disponible en glibc Ubuntu 18.04. Incluso después de instalar símbolos de depuración.
Afortunadamente, hay un sensor USDT en esta función.
LIBC_PROBE es un macro alias para
STAP_PROBE .
El nombre del proveedor es libc.
El nombre del sensor es memory_arena_new.
El número 2 significa que hay 2 argumentos adicionales especificados por el desarrollador.
arena es la dirección del área que se extrajo del sistema operativo, y el tamaño es su tamaño.
Antes de que podamos usar este sensor, debemos
solucionar el problema 328 . Necesitamos crear un enlace simbólico con glibc en algún lugar con el nombre
libc , porque bpftrace espera que el nombre de la biblioteca (que de lo contrario sería
libc-2.27.so ) sea idéntico al nombre del proveedor
(libc) .
ln -s /lib/x86_64-linux-gnu/libc-2.27.so /tmp/libc
Ahora le indicamos a bpftrace que se conecte al sensor memory_arena_new del USDT, cuyo nombre de proveedor es
libc :
sudo bpftrace -e 'usdt:/tmp/libc:memory_arena_new { printf("PID %d: created new arena at %p, size %d\n", pid, arg0, arg1); }'
En otra terminal, ejecutaremos Ruby, que creará tres hilos que no hacen nada y terminan en un segundo. Debido al bloqueo global del intérprete, Ruby
malloc () no debe ser llamado en paralelo por diferentes hilos.
ruby -e '3.times { Thread.new { } }; sleep 1'
Volviendo a la terminal con bpftrace, veremos:
Attaching 1 probe... PID 431: created new arena at 0x7f40e8000020, size 576 PID 431: created new arena at 0x7f40e0000020, size 576 PID 431: created new arena at 0x7f40e4000020, size 576
¡Aquí está la respuesta a nuestra pregunta! Cada vez que crea un nuevo hilo en Ruby, glibc resalta un área nueva independientemente de la competitividad.
¿Qué puntos de rastreo están disponibles? ¿Qué debo rastrear?Puede enumerar todos los puntos de rastreo de hardware, temporizadores, kprobe y kernel estático ejecutando el comando:
sudo bpftrace -l
Puede enumerar todos los puntos de rastreo de uprobe (caracteres de función) de una aplicación o biblioteca haciendo:
nm /path-to-binary
Puede enumerar todos los puntos de rastreo de la aplicación o biblioteca USDT ejecutando el siguiente comando:
/usr/share/bcc/tools/tplist -l /path-to/binary
Con respecto a qué puntos de rastreo usar: no estaría de más entender el código fuente de lo que va a rastrear. Te recomiendo que estudies el código fuente.
Consejo: un formato estructural para puntos de rastreo en el núcleoAquí hay un consejo útil sobre los puntos de rastreo del núcleo. ¡Puede verificar qué campos de argumento están disponibles leyendo el archivo / sys / kernel / debug / tracing / events!
Por ejemplo, suponga que desea rastrear llamadas a
madvise (..., MADV_DONTNEED) :
sudo bpftrace -l | grep madvise
- nos dirá que podemos usar tracepoint: syscalls: sys_enter_madvise.
sudo cat /sys/kernel/debug/tracing/events/syscalls/sys_enter_madvise/format
- nos dará la siguiente información:
name: sys_enter_madvise ID: 569 format: field:unsigned short common_type; offset:0; size:2; signed:0; field:unsigned char common_flags; offset:2; size:1; signed:0; field:unsigned char common_preempt_count; offset:3; size:1; signed:0; field:int common_pid; offset:4; size:4; signed:1; field:int __syscall_nr; offset:8; size:4; signed:1; field:unsigned long start; offset:16; size:8; signed:0; field:size_t len_in; offset:24; size:8; signed:0; field:int behavior; offset:32; size:8; signed:0; print fmt: "start: 0x%08lx, len_in: 0x%08lx, behavior: 0x%08lx", ((unsigned long)(REC->start)), ((unsigned long)(REC->len_in)), ((unsigned long)(REC->behavior))
Firma de Madvise según el manual:
(void * addr, size_t length, int advice) . ¡Los últimos tres campos de esta estructura corresponden a estos parámetros!
¿Cuál es el significado de MADV_DONTNEED? A juzgar por grep MADV_DONTNEED / usr / include, es igual a 4:
/usr/include/x86_64-linux-gnu/bits/mman-linux.h:80:# define MADV_DONTNEED 4 /* Don't need these pages. */
Entonces nuestro equipo bpftrace se convierte en:
sudo bpftrace -e 'tracepoint:syscalls:sys_enter_madvise /args->behavior == 4/ { printf("madvise DONTNEED called\n"); }'
Conclusión
¡Bpftrace es maravilloso! Bpftrace es el futuro!
Si desea saber más sobre él, le recomiendo que se familiarice con
su liderazgo , así como con la
primera publicación de 2019 en el blog de Brendan Gregg.
Buena depuración!