En 1943, los neuropsicólogos estadounidenses McCallock y Pitts desarrollaron un modelo informático de una red neuronal, y en 1958 la
primera red de una sola capa en funcionamiento reconoció algunas letras. Ahora, las redes neuronales simplemente no se usan para qué: predecir el tipo de cambio, diagnosticar enfermedades, pilotos automáticos y crear gráficos en juegos de computadora. Solo sobre el último y hablamos.
Evgeni Tumanov trabaja como ingeniero de aprendizaje profundo en
NVIDIA . Con base en los resultados de su discurso en la conferencia HighLoad ++, preparamos una historia sobre el uso de Machine Learning y Deep Learning en gráficos. El aprendizaje automático no termina con PNL, visión artificial, sistemas de recomendación y tareas de búsqueda. Incluso si no está muy familiarizado con esta área, puede aplicar las mejores prácticas del artículo en su campo o industria.
La historia constará de tres partes. Revisaremos las tareas en el gráfico que se resuelven con la ayuda del aprendizaje automático, derivaremos la idea principal y describiremos el caso de aplicar esta idea en una tarea específica y específicamente en la
representación de nubes .
DL / ML supervisado en gráficos, o capacitación de maestros en gráficos
Analicemos dos grupos de tareas. Para empezar, denótalos brevemente.
Motor del mundo real o render :
- Creación de animaciones creíbles: locomoción, animación facial.
- Post-procesamiento de imágenes renderizadas: supermuestreo, anti-aliasing.
- Slowmotion: interpolación de trama.
- Generación de materiales.
El segundo grupo de tareas ahora se llama convencionalmente "
Algoritmo pesado ". Incluimos tareas como renderizar objetos complejos, como nubes, y
simulaciones físicas : agua, humo.
Nuestro objetivo es comprender la diferencia fundamental entre los dos grupos. Consideremos las tareas con más detalle.
Creación de animaciones creíbles: locomoción, animación facial.
En los últimos años,
han aparecido muchos
artículos , donde los investigadores ofrecen nuevas formas de generar hermosas animaciones. Usar el trabajo de artistas es costoso, y reemplazarlos con un algoritmo sería muy beneficioso para todos. Hace un año, en NVIDIA, estábamos trabajando en un proyecto en el que nos dedicamos a la animación facial de los personajes en los juegos: sincronizar la cara del héroe con la pista de audio del discurso. Intentamos "revivir" la cara para que cada punto se moviera, y sobre todo los labios, porque este es el momento más difícil de la animación. Manualmente un artista para hacer esto caro y durante mucho tiempo. ¿Cuáles son las opciones para resolver este problema y crear un
conjunto de
datos ?
La primera opción es
identificar las vocales: la boca se abre en las vocales, la boca se cierra en las consonantes . Este es un algoritmo simple, pero demasiado simple. En los juegos, queremos más calidad. La segunda opción es hacer
que las personas lean diferentes textos y escriban sus caras, y luego comparen las letras que pronuncian con expresiones faciales. Esta es una buena idea, y lo hicimos en un
proyecto conjunto con Remedy Entertainment. La única diferencia es que en el juego no mostramos un video, sino un modelo 3D de puntos. Para ensamblar un conjunto de datos, debe comprender cómo se mueven puntos específicos de la cara. Tomamos actores, pedimos leer textos con diferentes entonaciones, filmamos en muy buenas cámaras desde diferentes ángulos, después de lo cual restauramos el modelo 3D de caras en cada cuadro y predijimos la posición de los puntos en la cara por sonido.
Procesamiento de imagen de procesamiento posterior: supermuestreo, anti-aliasing
Considere un caso de un juego específico: tenemos un motor que genera imágenes en diferentes resoluciones. Queremos renderizar la imagen en una resolución de 1000 × 500 píxeles, y mostrarle al jugador 2000 × 1000, esto será más bonito. ¿Cómo ensamblar un conjunto de datos para esta tarea?
Primero renderice la imagen en alta resolución, luego baje la calidad y luego intente entrenar el sistema para convertir la imagen de baja resolución a alta resolución.
Cámara lenta: interpolación de trama
Tenemos un video y queremos que la red agregue fotogramas en el medio, para interpolar fotogramas. La idea es obvia: grabar un video real con una gran cantidad de cuadros, eliminar los intermedios e intentar predecir lo que la red eliminó.
Generación de material
No nos detendremos mucho en la generación de materiales. Su esencia es que tomamos, por ejemplo, una pieza de madera en varios ángulos de iluminación e interpolamos la vista desde otros ángulos.
Examinamos el primer grupo de problemas. El segundo es fundamentalmente diferente. Hablaremos sobre la representación de objetos complejos, como nubes, más adelante, pero ahora trataremos con simulaciones físicas.
Simulaciones físicas de agua y humo.
Imagine una piscina en la que se encuentran objetos sólidos en movimiento. Queremos predecir el movimiento de partículas fluidas. Hay partículas en el grupo en el momento
t , y en el momento
t + Δt queremos obtener su posición. Para cada partícula, llamamos a una red neuronal y obtenemos una respuesta donde estará en el siguiente cuadro.
Para resolver el problema, utilizamos
la ecuación de Navier-Stokes , que describe el movimiento de un fluido. Para una simulación de agua plausible y físicamente correcta, tendremos que resolver la ecuación o aproximación a ella. Esto se puede hacer de manera computacional, muchos de los cuales se han inventado en los últimos 50 años: el algoritmo SPH, FLIP o el fluido basado en posición.
La diferencia entre el primer grupo de tareas del segundo
En el primer grupo, el maestro para el algoritmo es algo anterior: una grabación de la vida real, como en el caso de individuos, o algo del motor, por ejemplo, renderizar imágenes. En el segundo grupo de problemas, utilizamos el método de las matemáticas computacionales. A partir de esta división temática, surge una idea.
Idea principal
Tenemos una tarea computacionalmente compleja que es larga, difícil y difícil de resolver con el método clásico de la universidad de computación. Para resolverlo y acelerar, tal vez incluso perdiendo un poco de calidad, necesitamos:
- encuentre el lugar que consume más tiempo en la tarea donde el código dura más;
- mira lo que produce esta línea;
- intente predecir el resultado de una línea utilizando una red neuronal o cualquier otro algoritmo de aprendizaje automático.
Esta es una metodología general y la idea principal es una receta sobre cómo encontrar aplicaciones para el aprendizaje automático. ¿Qué debe hacer para que esta idea sea útil? No hay una respuesta exacta: usa la creatividad, mira tu trabajo y encuéntralo. Hago gráficos y no estoy tan familiarizado con otros campos, pero puedo imaginar que en el entorno académico, en física, química, robótica, definitivamente puedes encontrar una aplicación. Si resuelve una ecuación física compleja en su lugar de trabajo, también puede encontrar aplicación para esta idea. Para mayor claridad, considere un caso específico.
Tarea de renderizado en la nube
Estuvimos involucrados en este proyecto en NVIDIA hace seis meses: la tarea es dibujar una nube físicamente correcta, que se representa como la densidad de las gotas de líquido en el espacio.
Una nube es un objeto físicamente complejo, una suspensión de gotas de líquido que no se puede modelar como un objeto sólido.
No será posible imponer una textura y renderizar en la nube, porque las gotas de agua son geométricamente difíciles de ubicar en el espacio 3D y son complejas en sí mismas: prácticamente no absorben el color, sino que lo reflejan, anisotrópicamente, en todas las direcciones de diferentes maneras.
Si observa una gota de agua, sobre la que brilla el sol, y los vectores del ojo y del sol en una gota son paralelos, se observará un gran pico de intensidad de luz. Esto explica el fenómeno físico que todos han visto: en un clima soleado, uno de los bordes de la nube es muy brillante, casi blanco. Estamos mirando el borde de la nube, y la línea de visión y el vector desde este borde hasta el sol son casi paralelos.

La nube es un objeto físicamente complejo y su representación mediante el algoritmo clásico requiere mucho tiempo. Hablaremos sobre el algoritmo clásico un poco más tarde. Dependiendo de los parámetros, el proceso puede llevar horas o incluso días. Imagina que eres un artista y dibujas una película con efectos especiales. Tienes una escena complicada con una iluminación diferente con la que quieres jugar. Dibujamos una topología en la nube: no me gusta y desea volver a dibujarla y obtener una respuesta allí mismo. Es importante obtener una respuesta de un cambio de parámetro lo más rápido posible. Esto es un problema Por lo tanto, intentemos acelerar este proceso.
Solución clásica
Para resolver el problema, debes resolver esta complicada ecuación.

La ecuación es dura, pero comprendamos su significado físico. Considere un rayo atravesado por una nube que atraviesa una nube. ¿Cómo entra la luz en la cámara en esta dirección? En primer lugar, la luz puede alcanzar el punto de salida del rayo desde la nube y luego propagarse a lo largo de este rayo dentro de la nube.
Para el segundo método de "propagación de luz a lo largo de la dirección" es el término integral de la ecuación. Su significado físico es el siguiente.
Considere el segmento dentro de la nube en el rayo, desde el punto de entrada hasta el punto de salida. La integración se lleva a cabo precisamente sobre este segmento, y para cada punto en él consideramos la llamada
energía de luz indirecta L (x, ω) - el significado de la integral I
1 - iluminación indirecta en el punto. Parece debido al hecho de que las gotas de diferentes maneras reflejan la luz solar. En consecuencia, una gran cantidad de rayos mediados por las gotas circundantes llega al punto. I
1 es la integral sobre la esfera que rodea un punto en el rayo. En el algoritmo clásico, se cuenta utilizando el método de
Monte Carlo .
El algoritmo clásico.
- Renderice una imagen a partir de píxeles y produzca un rayo que vaya desde el centro de la cámara a un píxel y luego más.
- Cruzamos la viga con la nube, encontramos los puntos de entrada y salida.
- Consideramos el último término de la ecuación: cruzar, conectar con el sol.
- Primeros pasos muestreo de importancia
Cómo considerar la estimación de Montecarlo I
1 que no analizaremos, porque es difícil y no tan importante. Baste decir que esta es la parte más larga y difícil de todo el algoritmo.
Conectamos redes neuronales
A partir de la idea principal y la descripción del algoritmo clásico, se sigue una receta sobre cómo aplicar redes neuronales a esta tarea. Lo más difícil es calcular el puntaje de Monte Carlo. Da un número que significa iluminación indirecta en un punto, y esto es exactamente lo que queremos predecir.

Hemos decidido la salida, ahora entenderemos la entrada, a partir de la cual quedará claro cuál es la magnitud de la luz indirecta en el punto. Esta es la luz que se refleja de las muchas gotas de agua que rodean el punto. La topología de la luz está fuertemente influenciada por la topología de densidad alrededor del punto, la dirección hacia la fuente y la dirección hacia la cámara.
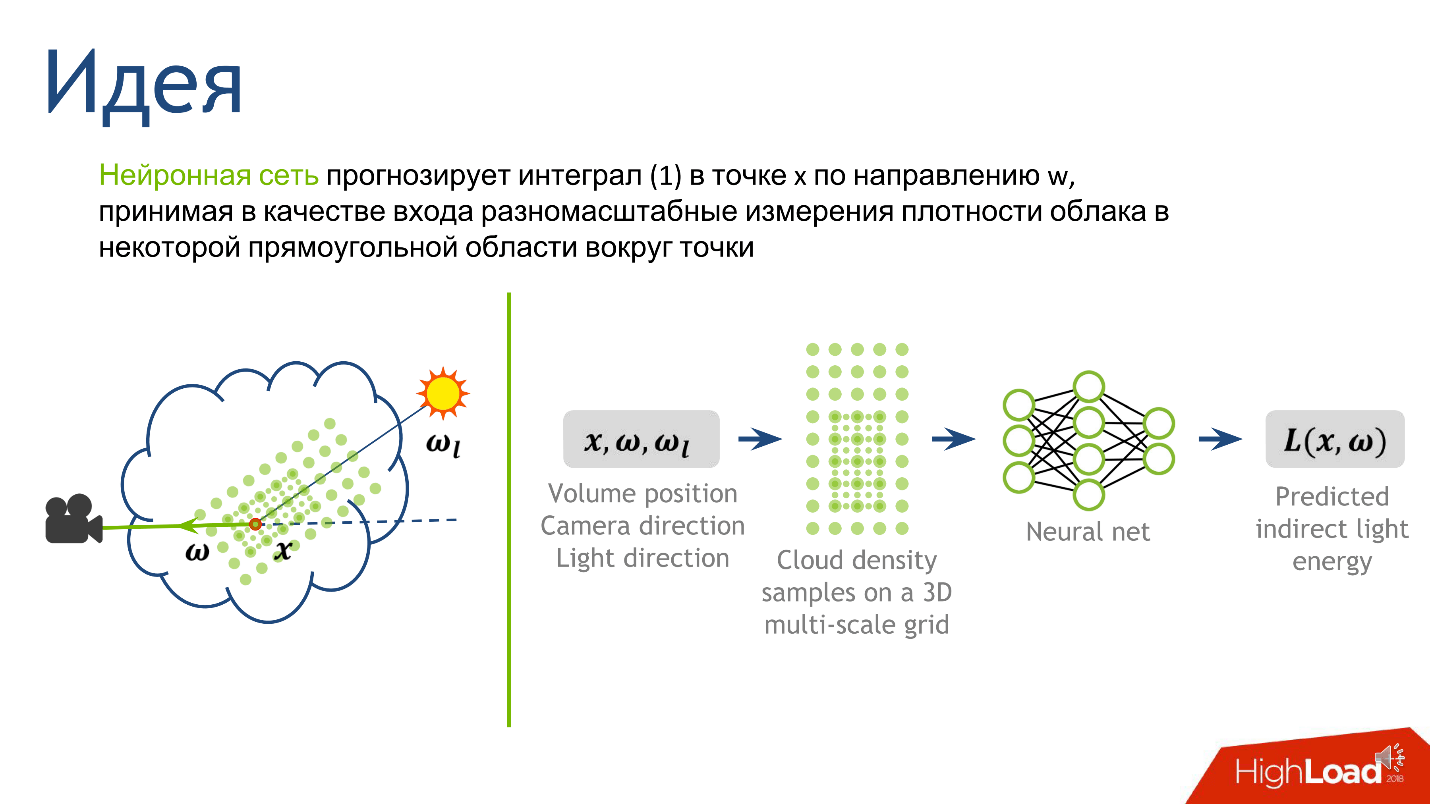
Para construir la entrada a la red neuronal, describimos la densidad local. Hay muchas maneras de hacer esto, pero nos centramos en el artículo
Dispersión profunda: renderización de nubes atmosféricas con redes neuronales que predicen la radiación, Kallwcit et al. 2017 y muchas ideas vinieron de allí.
Brevemente, el método de representación local de la densidad alrededor de un punto se ve así.
- Arregla una constante bastante pequeña . Que sea el camino libre medio en la nube.
- Dibuje alrededor de un punto en nuestro segmento una cuadrícula rectangular volumétrica de un tamaño fijo , digamos 5 * 5 * 9. En el centro de este cubo estará nuestro punto. El espaciado de la cuadrícula es una pequeña constante fija. En los nodos de la cuadrícula mediremos la densidad de la nube.
- Aumentemos la constante 2 veces , dibujemos una cuadrícula más grande y hagamos lo mismo: mida la densidad en los nodos de la cuadrícula.
- Repita el paso anterior varias veces . Hicimos esto 10 veces, y después del procedimiento obtuvimos 10 cuadrículas: 10 tensores, cada uno de los cuales almacena la densidad de la nube, y cada uno de los tensores cubre un vecindario cada vez más grande alrededor del punto.
Este enfoque nos brinda la descripción más detallada de un área pequeña: cuanto más cerca del punto, más detallada es la descripción. Decidido sobre la salida y la entrada de la red, queda por entender cómo entrenarla.
Entrenamiento
Generaremos 100 nubes diferentes con diferentes topologías. Simplemente los representaremos utilizando el algoritmo clásico, anotaremos lo que el algoritmo recibe en la línea donde realiza la integración de Monte Carlo y anotaremos las propiedades que corresponden al punto. Entonces obtenemos un conjunto de datos sobre el cual aprender.

Qué enseñar o arquitectura de red
La arquitectura de red para esta tarea no es el momento más crucial, y si no comprende nada, no se preocupe, esto no es lo más importante que quería transmitir. Utilizamos la siguiente arquitectura: para cada punto hay 10 tensores, cada uno de los cuales se calcula en una cuadrícula cada vez más grande. Cada uno de estos tensores cae en el bloque correspondiente.
- Primero en la primera capa regular completamente conectada .
- Después de salir de la primera capa totalmente conectada, en la segunda capa completamente conectada, que no tiene activación.
Una capa completamente conectada sin activación es solo la multiplicación por una matriz. Al resultado de multiplicar por la matriz, agregamos la salida del
bloque residual anterior, y solo entonces aplicamos la activación.
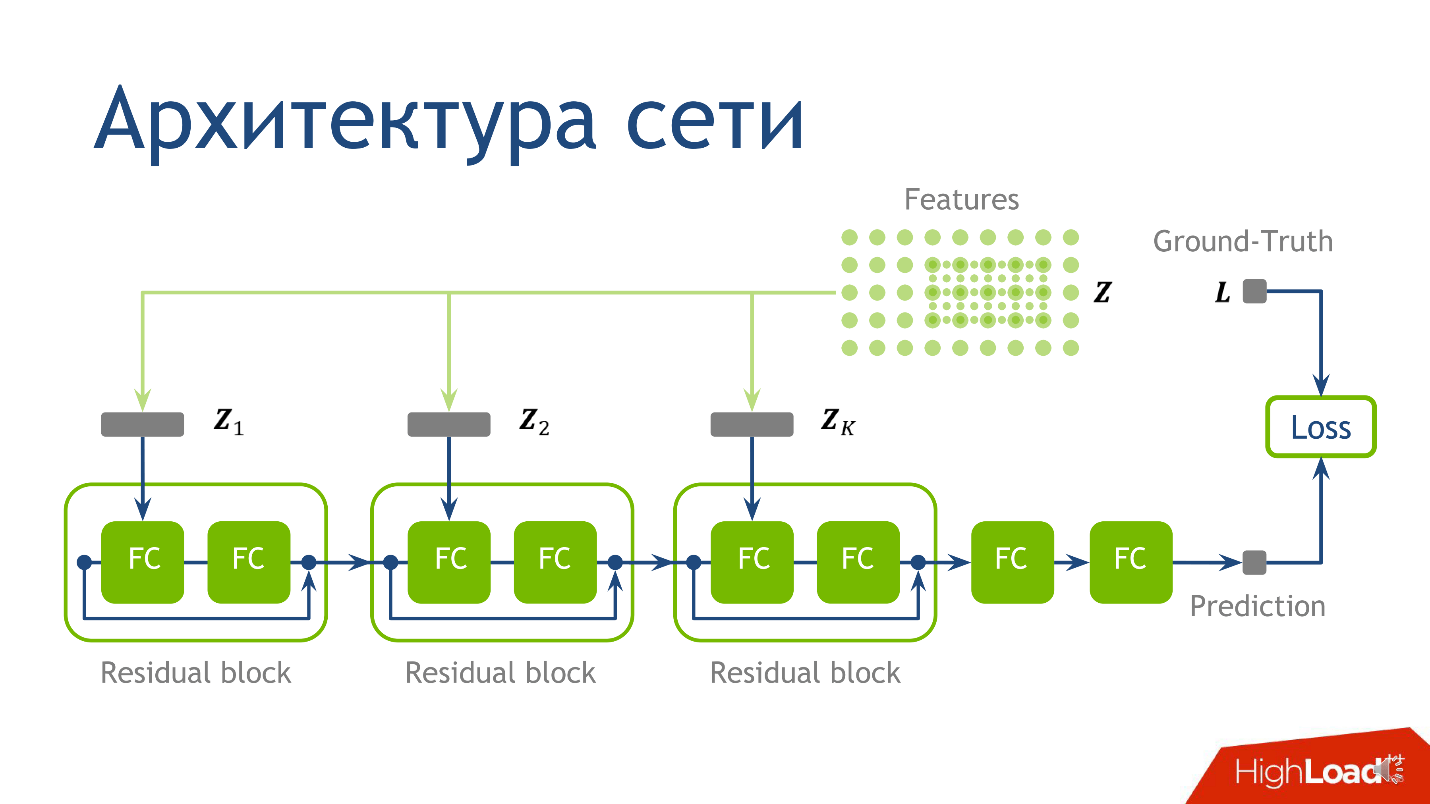
Tomamos un punto, contamos los valores en cada una de las cuadrículas, colocamos los tensores obtenidos en el bloque residual correspondiente, y puede realizar la
inferencia de la red neuronal , el modo de producción de la red. Hicimos esto y nos aseguramos de obtener imágenes de nubes.
Resultados
La primera observación: obtuvimos lo que queríamos: una llamada de red neuronal, en comparación con la estimación de Monte Carlo, funciona más rápido, lo cual ya es bueno.
Pero hay otra observación sobre los resultados del entrenamiento: es la convergencia en el número de muestras. De que estas hablando

Al renderizar una imagen, córtela en pequeños mosaicos: cuadrados de píxeles, digamos 16 * 16. Considere un mosaico de imagen sin pérdida de generalidad. Cuando renderizamos este mosaico, para cada píxel de la cámara, liberamos muchos rayos correspondientes a un píxel y agregamos un poco de ruido a los rayos para que sean ligeramente diferentes. Estos rayos se llaman
anti-aliasing y se inventan para reducir el ruido en la imagen final.
- Lanzamos varios rayos anti-alias para cada píxel.
- En el interior del haz de la cámara, en la nube, en un segmento, calculamos n muestras de puntos en los que queremos realizar una evaluación de Monte Carlo, o llamar a una red para ellos.
Todavía hay muestras que corresponden a la conexión con las fuentes de luz. Aparecen cuando conectamos un punto con una fuente de luz, por ejemplo, con el sol. Esto es fácil de hacer, porque el sol son los rayos que caen sobre la tierra paralelos entre sí. Por ejemplo, el cielo, como fuente de luz, es mucho más complicado, porque aparece como una esfera infinitamente distante, que tiene una función de color en la dirección. Si el vector se ve verticalmente hacia el cielo, entonces el color es azul. Cuanto más bajo, más brillante. En la parte inferior de la esfera suele haber un color neutro que imita a la tierra: verde, marrón.
Cuando conectamos un punto con el cielo para comprender cuánta luz entra, siempre liberamos algunos rayos para obtener una respuesta que converja con la verdad. Lanzamos más de un rayo para obtener una mejor calificación. Por lo tanto, todo el
procesamiento de la tubería necesita tantas muestras.
Cuando entrenamos la red neuronal, notamos que aprende una solución mucho más promedio. Si fijamos el número de muestras, vemos que el algoritmo clásico converge a la fila izquierda de la columna de la imagen, y la red aprende a la derecha. Esto no significa que el método original sea malo, solo convergemos más rápido. Cuando aumentamos el número de muestras, el método original estará cada vez más cerca de lo que obtenemos.
Nuestro principal resultado que queríamos obtener es un aumento en la velocidad de renderizado. Para una nube específica en una resolución específica con parámetros de muestra, vemos que las imágenes obtenidas por la red y el método clásico son casi idénticas, pero obtenemos la imagen correcta 800 veces más rápido.

Implementación
Hay un programa de código abierto para modelado 3D:
Blender , que implementa el algoritmo clásico. Nosotros mismos no escribimos un algoritmo, pero usamos este programa: nos capacitamos en Blender, escribiendo todo lo que necesitábamos para el algoritmo. La producción también se realizó en el programa: capacitamos a la red en
TensorFlow , la transferimos a C ++ usando TensorRT, y ya integramos la red TensorRT en Blender, porque su código está abierto.
Como hicimos todo por Blender, nuestra solución tiene todas las características del programa: podemos renderizar cualquier tipo de escena y muchas nubes. Las nubes en nuestra solución se establecen creando un cubo, dentro del cual determinamos la función de densidad de una manera específica para programas 3D. Optimizamos este proceso: densidad de caché. Si un usuario quiere dibujar la misma nube en una pila de diferentes configuraciones de una escena: bajo diferentes condiciones de iluminación, con diferentes objetos en el escenario, entonces no necesita recalcular constantemente la densidad de la nube. Lo que pasó, puedes ver el
video .
En conclusión, repito una vez más la idea principal que quería transmitir:
si en su trabajo durante mucho tiempo y duro considera algo como un algoritmo computacional específico, y esto no le conviene: encuentre el lugar más difícil en el código, reemplácelo con una red neuronal, y Quizás esto te ayude.Las redes neuronales y la inteligencia artificial son uno de los nuevos temas que discutiremos en Saint HighLoad ++ 2019 en abril. Ya hemos recibido varias solicitudes sobre este tema, y si tiene una buena experiencia, no necesariamente en redes neuronales, envíe una solicitud para un informe antes del 1 de marzo . Estaremos encantados de verte entre nuestros oradores.
Para mantenerse al tanto de cómo se forma el programa y qué informes se aceptan, suscríbase al boletín . En él, solo publicamos colecciones temáticas de informes, resúmenes de artículos y nuevos videos.