En el
último artículo, examinamos las limitaciones y obstáculos que surgen cuando necesita escalar datos horizontalmente y tener una garantía de las propiedades ACID de las transacciones. En este artículo, hablamos sobre la tecnología FoundationDB y entendemos cómo ayuda a superar estas limitaciones al desarrollar aplicaciones de misión crítica.
FoundationDB es una base de datos distribuida NoSQL con transacciones ACID serializables que almacena pares ordenados de valores clave-valor. Las claves y los valores pueden ser secuencias arbitrarias de bytes. No tiene un solo punto de incidencia: todas las máquinas de clúster son iguales. Distribuye los datos entre los servidores del clúster y se escala sobre la marcha: cuando necesita agregar recursos al clúster, simplemente agrega la dirección de la nueva máquina en los servidores de configuración y la base de datos la recoge por sí misma.
En FoundationDB, las transacciones nunca se bloquean entre sí. La lectura se implementa a través
del control de versiones multiversion (MVCC), y la lectura se implementa a través del
control de concurrencia optimista (OCC). Los desarrolladores afirman que cuando todas las máquinas de clúster están en el mismo centro de datos, la latencia de escritura es de 2-3 ms, y la latencia de lectura es inferior a un milisegundo. La documentación contiene estimaciones de 10-15 ms, lo que probablemente esté más cerca de los resultados en condiciones reales.
 * No admite propiedades ACID en varios fragmentos.
* No admite propiedades ACID en varios fragmentos.FoundationDB tiene una ventaja única: la reorganización automática. El propio DBMS asegura una carga uniforme de las máquinas en el clúster: cuando un servidor está lleno, redistribuye los datos a los vecinos en segundo plano. Al mismo tiempo, se preserva la garantía del nivel de Serializable para todas las transacciones, y el único efecto notable para los clientes es un ligero aumento en la latencia de las respuestas. La base de datos garantiza que la cantidad de datos en los servidores de clúster más y menos cargados difiere en no más del 5%.
Arquitectura
Lógicamente, un clúster FoundationDB es un conjunto de procesos del mismo tipo en diferentes máquinas físicas. Los procesos no tienen sus propios archivos de configuración, por lo que son intercambiables. Varios procesos fijos tienen un rol dedicado: coordinadores, y cada proceso de clúster al inicio conoce sus direcciones. Es importante que los bloqueos de los coordinadores sean lo más independientes posible, por lo que es mejor colocarlos en diferentes máquinas físicas o incluso en diferentes centros de datos.
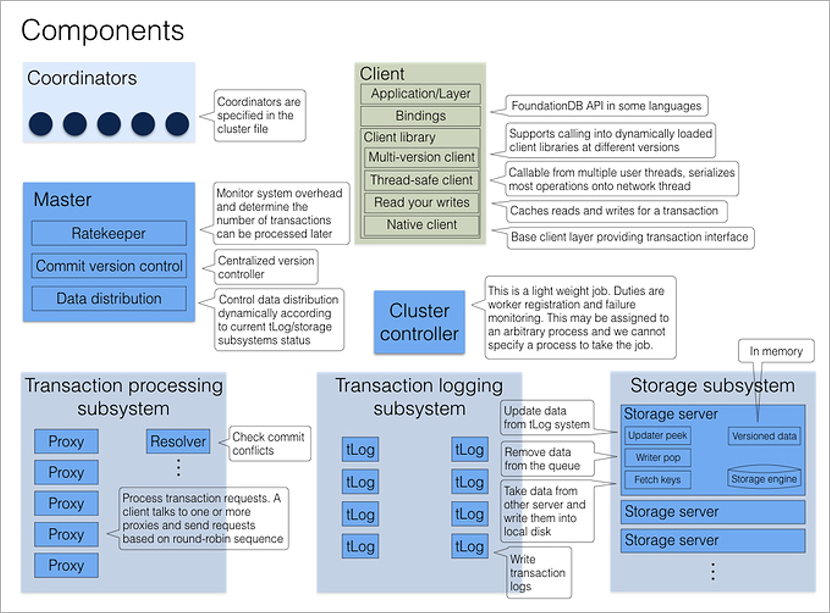
Los coordinadores acuerdan entre sí a través del algoritmo de consenso de
Paxos . Seleccionan el proceso del Cluster Controller, que luego asigna roles al resto de los procesos del clúster. Cluster Controller informa continuamente a todos los coordinadores que está vivo. Si la mayoría de los coordinadores piensan que está muerto, simplemente eligen uno nuevo. Ni Cluster Controller ni Coordinators están involucrados en el procesamiento de transacciones; su tarea principal es eliminar la situación del
cerebro dividido .
Cuando un cliente desea conectarse a la base de datos, se contacta inmediatamente con todos los coordinadores para obtener la dirección del controlador de clúster actual. Si la mayoría de las respuestas coinciden, recibe del Cluster Controller la configuración de clúster actual completa (si no coincide, vuelve a llamar a los Coordinadores).
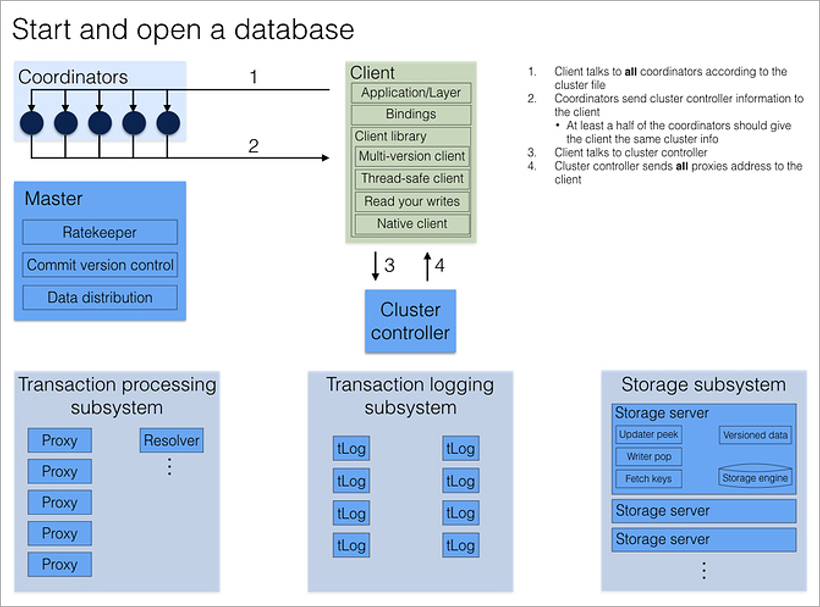
Cluster Controller conoce el número total de procesos disponibles y distribuye roles: estos 5 serán Proxy, estos 2 serán Resolver, este será Master. Y si alguno de ellos muere, inmediatamente encontrará un reemplazo para él, asignando el papel necesario a un proceso libre arbitrario. Todo esto sucede en segundo plano, invisible para el programador de la aplicación.
El proceso maestro es responsable del número de la versión actual del conjunto de datos (aumenta cada vez que se escribe en la base de datos), así como de la distribución de muchas claves entre servidores de almacenamiento y aceleración de velocidad (rendimiento artificialmente bajo bajo cargas pesadas: si el clúster sabe que el cliente hará muchas pequeñas solicitudes, esperará, las agrupará y responderá todo el paquete de una vez).
El registro de transacciones y el almacenamiento son dos subsistemas de almacenamiento independientes. El primero es el almacenamiento temporal para escribir datos rápidamente en el disco en el orden de recepción, el segundo es el almacenamiento permanente, donde los datos en el disco se ordenan en orden ascendente de claves. Cada confirmación de transacción, al menos tres procesos tLog deben guardar datos antes de que el clúster informe el éxito al cliente. Paralelamente, los datos en segundo plano se mueven de los servidores tLog a los servidores de almacenamiento (almacenamiento en el que también es redundante).
Procesamiento de solicitudes
Todas las solicitudes de clientes procesan procesos proxy. Al abrir una transacción, el cliente accede a cualquier Proxy, sondea a todos los otros Proxies y devuelve el número de versión actual de los datos del clúster. Todas las lecturas posteriores ocurren en este número de versión. Si otro cliente escribió los datos después de que abrí la transacción, simplemente no veré sus cambios.
Grabar una transacción es un poco más complicado ya que necesita resolver conflictos. Esto incluye el proceso Resolver, que almacena en la memoria todas las claves modificadas durante un cierto período de tiempo. Cuando el cliente completa la transacción de confirmación, el Resolver verifica si los datos que estaba leyendo no están actualizados. (Es decir, si la transacción que se abrió más tarde que la mía se completó y cambió las claves que leí). Si esto sucede, la transacción se revierte y la propia biblioteca del cliente (!) Hace un segundo intento de confirmación. Lo único en lo que el desarrollador debe pensar es que las transacciones son idempotentes, es decir, el uso repetido debería dar un resultado idéntico. Una forma de lograr esto es guardar un valor único dentro de la transacción y, al comienzo de la transacción, verificar su presencia en la base de datos.
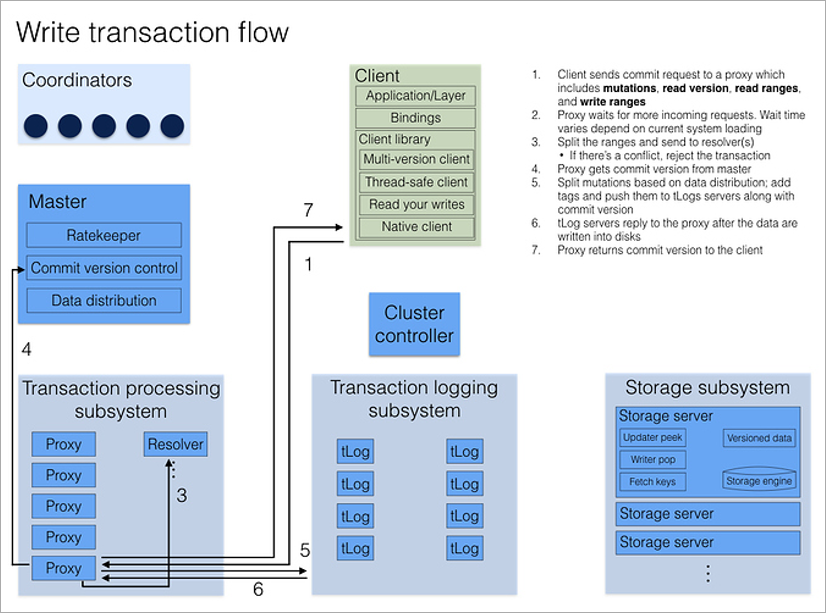
Como en cualquier sistema cliente-servidor, hay situaciones en las que la transacción se completa con éxito, pero el cliente no recibió confirmación debido a una desconexión. La biblioteca del cliente los trata como a cualquier otro error: simplemente vuelve a intentarlo. Esto podría conducir a la re-ejecución de toda la transacción. Sin embargo, si la transacción es idempotente, no hay problema con esto, no afectará el resultado final.
Escalamiento
Puede haber miles de servidores en un subsistema de almacenamiento. ¿Con cuál de ellos debe contactarse un cliente cuando necesita datos sobre una clave determinada? Desde Cluster Controller, el cliente conoce la configuración completa de todo el clúster e incluye rangos de claves en cada servidor de almacenamiento. Por lo tanto, simplemente accede a los servidores de almacenamiento deseados directamente sin ninguna solicitud intermedia.
Si el servidor de almacenamiento deseado no está disponible, la biblioteca del cliente toma una nueva configuración de Cluster Controller. Si, como resultado de un bloqueo del servidor, el clúster comprende que la redundancia es insuficiente, inmediatamente comienza a recopilar un nuevo nodo de piezas de otro Almacenamiento.
Suponga que guarda un gigabyte de datos en una transacción. ¿Cómo puede proporcionar una respuesta rápida? De ninguna manera, y por lo tanto, FoundationDB simplemente limitó el tamaño de una transacción a 10 megabytes. Además, esta es una restricción de todos los datos que
conciernen a la transacción: lecturas o escrituras. Cada entrada en la base de datos también está limitada: la clave no puede exceder los 10 kilobytes, el valor es de 100 kilobytes. (Al mismo tiempo, para un rendimiento óptimo, los desarrolladores recomiendan claves con una longitud de 32 bytes y valores con una longitud de 10 kilobytes).
Cualquier transacción puede convertirse potencialmente en una fuente de conflicto, y luego tendrá que revertirse. Por lo tanto, en aras de la velocidad, hasta que llegue el comando commit, tiene sentido mantener los cambios actuales en la RAM y no en el disco. Suponga que está escribiendo datos en una base de datos con una carga de 1 GB / segundo. Luego, en un caso extremo, su clúster asignará 3 GB de RAM cada segundo (escribimos transacciones en 3 máquinas). ¿Cómo limitar un crecimiento semejante a una avalancha de memoria usada? Es muy simple limitar el tiempo máximo de transacción. En FoundationDB, una transacción no puede durar más de 5 segundos. Si el cliente intenta acceder a la base de datos 5 segundos después de que se abre la transacción, el clúster ignorará todos sus comandos hasta que abra uno nuevo.
Índices
Supongamos que mantiene una lista de personas, cada persona tiene un identificador único, lo usamos como clave y en el valor escribimos todos los demás atributos: nombre, género, edad, etc.
| Clave | Valor |
| 12345 | (Ivanov Ivan Ivanovich, M, 35 años) |
¿Cómo obtener una lista de todas las personas que tienen 30 años sin una búsqueda exhaustiva? Por lo general, se crea un índice en la base de datos para esto. Un índice es otra vista de datos diseñada para buscar rápidamente atributos adicionales. Simplemente podemos agregar entradas del formulario:
Ahora, para obtener la lista que necesita, solo tiene que buscar el rango de teclas (30, *). Como FoundationDB almacena datos ordenados por clave, dicha consulta se ejecutará muy rápidamente. Por supuesto, el índice ocupa espacio en disco adicional, pero muy poco. Tenga en cuenta que no todos los atributos están duplicados, sino solo la edad y el identificador.
Es importante que las operaciones de agregar el registro en sí y el índice se realicen en una transacción.
Fiabilidad
FoundationDB está escrito en C ++. Los autores comenzaron a trabajar en él en 2009, la primera versión se lanzó en 2013, y en marzo de 2015, Apple los compró. Tres años después, Apple abrió inesperadamente el código fuente.
Se rumorea que Apple lo usa, entre otras cosas, para almacenar datos de servicio de iCloud.
Los desarrolladores experimentados generalmente no confían de inmediato en las nuevas soluciones. Pueden pasar años antes de que la tecnología se establezca de manera confiable y comience a usarse masivamente en productos. Para reducir este tiempo, los autores hicieron una extensión interesante del lenguaje C ++:
Flow . Le permite emular con gracia el trabajo con componentes externos poco confiables con la posibilidad de una repetición predecible completa de la ejecución del programa. Cada llamada a una red o disco está envuelta en algún contenedor (Actor), y cada Actor tiene varias implementaciones. La implementación estándar escribe datos en el disco o en la red, según lo previsto. Y el otro escribe en el disco 999 veces de 1000, y pierde 1 de 1000. Una implementación de red alternativa puede, por ejemplo, intercambiar bytes en paquetes de red. Incluso hay actores que imitan el trabajo de un administrador de sistema descuidado. Esto puede eliminar la carpeta de datos o intercambiar dos carpetas. Los desarrolladores
manejan miles de simulaciones , sustituyen a diferentes actores y utilizan Flow para lograr una reproducibilidad del 100%: si alguna prueba falla, pueden reiniciar la simulación y obtener un bloqueo en el mismo lugar. En particular, para eliminar la incertidumbre introducida por los hilos de conmutación del planificador del sistema operativo, cada proceso de FoundationDB es estrictamente de un solo subproceso.
Cuando se le pidió al
investigador , que descubrió
escenarios de pérdida de datos en casi todas las soluciones populares de NoSQL , que probara FoundationDB, se negó, señalando que no veía el punto, porque los autores
hicieron un trabajo gigante y los
probaron mucho más profundamente y más a fondo que el suyo.
Es habitual pensar que las fallas de clúster son aleatorias, pero los desarrolladores experimentados saben que esto está lejos de ser el caso. Si tiene 10 mil discos del mismo fabricante y el mismo número de otros, entonces la tasa de fallas será diferente. En FoundationDB, es posible una configuración denominada de máquina en la que puede decirle al clúster qué máquinas están en el mismo centro de datos y qué procesos están en la misma máquina. La base de datos tendrá esto en cuenta al distribuir la carga entre las máquinas. Y las máquinas en un clúster generalmente tienen características diferentes. FoundationDB también tiene esto en cuenta, analiza la longitud de las colas de solicitudes y redistribuye la carga de manera equilibrada: las máquinas más débiles reciben menos solicitudes.
Por lo tanto, FoundationDB proporciona transacciones ACID y el más alto nivel de aislamiento, serializable, en un grupo de miles de máquinas. Junto con una increíble flexibilidad y alto rendimiento, suena mágico. Pero hay que pagar por todo, por lo que existen algunas limitaciones tecnológicas.
Limitaciones
Además de los límites ya mencionados en el tamaño y la duración de la transacción, es importante tener en cuenta las siguientes características:
- El lenguaje de consulta no es SQL, es decir, los desarrolladores con experiencia en SQL tendrán que volver a aprender.
- La biblioteca del cliente solo admite 5 lenguajes de alto nivel (Phyton, Ruby, Java, Golang y C). Todavía no hay un cliente oficial para C #. Como no hay una API REST, la única forma de admitir otro lenguaje es escribir un contenedor encima de la biblioteca C estándar.
- No existen mecanismos para compartir, su aplicación debe proporcionar toda esta lógica.
- El formato de almacenamiento de datos no está documentado (aunque generalmente tampoco está documentado en bases de datos comerciales). Esto es un riesgo, porque si de repente el clúster no se ensambla, no está claro de inmediato qué hacer y tendrá que profundizar en los archivos de origen.
- Un modelo de programación estrictamente asincrónico puede parecer complicado para los desarrolladores novatos.
- Debe pensar constantemente en la idempotencia de las transacciones.
- Si tiene que dividir las transacciones largas en pequeñas, entonces usted mismo debe cuidar la integridad a nivel global.
Traducido del inglés, "Fundación" significa "Fundación" y los autores de este DBMS ven su función de esta manera: proporcionan un alto nivel de confiabilidad a nivel de registros simples, y cualquier otra base de datos puede implementarse como un complemento sobre la funcionalidad básica. Por lo tanto, además de FoundationDB, puede crear otras capas diferentes: documentos, gráficos, etc. La pregunta sigue siendo cómo se escalarán estas capas sin perder rendimiento. Por ejemplo, los autores de CockroachDB ya han tomado este camino: al construir una capa SQL sobre RocksDB (almacén de valores de clave local) y obtener problemas de rendimiento inherentes a las uniones relacionales.
Hasta la fecha, Apple ha desarrollado y publicado 2 capas sobre FoundationDB:
Document Layer (admite MongoDB API) y
Record Layer (almacena registros como conjuntos de campos en formato
Protocol Buffers , admite índices, solo está disponible en Java). Es agradable y gratamente sorprendente que la empresa históricamente cerrada de Apple siga hoy los pasos de Google y Microsoft y publique el código fuente de las tecnologías utilizadas en su interior.
Perspectivas
Existe un conflicto existencial en el desarrollo de software: la empresa constantemente quiere cambios, mejoras del producto. Pero al mismo tiempo quiere un software confiable. Y estos dos requisitos se contradicen entre sí, porque cuando el software cambia, aparecen errores y la empresa sufre esto. Por lo tanto, si en su producto puede confiar en alguna tecnología confiable y probada y escribir menos código usted mismo, siempre vale la pena hacerlo. En este sentido, a pesar de ciertas restricciones, es genial no poder esculpir muletas en diferentes bases de datos NoSQL, sino utilizar una solución probada en producción con propiedades ACID.
Hace un año, estábamos
optimistas acerca de otra tecnología: CockroachDB, pero no cumplió con nuestras expectativas de rendimiento. Desde entonces, hemos perdido el apetito por la idea de una capa SQL sobre un almacén de valores clave distribuido y, por lo tanto, no
analizamos cuidadosamente, por ejemplo,
TiDB . Planeamos probar cuidadosamente FoundationDB como una base de datos secundaria para los conjuntos de datos más grandes de nuestro proyecto. Si ya tiene experiencia en el uso real de FoundationDB o TiDB en la producción, estaremos encantados de escuchar su opinión en los comentarios.