
Durante el año pasado, ha habido tantas publicaciones sobre microservicios que sería una pérdida de tiempo decir qué es y por qué, por lo que el resto de la discusión se centrará en la cuestión de cómo implementar esta arquitectura y por qué se enfrentó exactamente y qué problemas encontró.
Tuvimos grandes problemas en un banco pequeño: 3 monolitos de python conectados por una cantidad monstruosa de interacciones RPC sincrónicas con un gran volumen de legado. Para resolver al menos parcialmente todos los problemas que surgen al mismo tiempo, se decidió cambiar a una arquitectura de microservicio. Pero antes de decidirse por tal paso, debe responder 3 preguntas principales:
- Cómo dividir un monolito en microservicios y qué criterios se deben seguir.
- ¿Cómo interactuarán los microservicios?
- ¿Cómo monitorear?
En realidad, las respuestas breves a estas preguntas se dedicarán a este artículo.
Cómo dividir un monolito en microservicios y qué criterios se deben seguir.
Esta pregunta aparentemente simple finalmente determinó toda la arquitectura futura.
Somos un banco, por lo que todo el sistema gira en torno a operaciones con finanzas y varias cosas auxiliares. Ciertamente es posible transferir transacciones financieras de ACID a un sistema distribuido con sagas , pero en el caso general es extremadamente difícil. Así desarrollamos las siguientes reglas:
- Cumplir con S de SOLID para microservicios
- La transacción debe llevarse a cabo en su totalidad en el microservicio, sin transacciones distribuidas por el daño de la base de datos.
- Para funcionar, el microservicio necesita información de su propia base de datos o de una solicitud
- Trate de garantizar la limpieza (en el sentido de los lenguajes funcionales) para microservicios
Naturalmente, al mismo tiempo, era imposible satisfacerlos por completo, pero incluso la implementación parcial simplifica enormemente el desarrollo.
¿Cómo interactuarán los microservicios?
Hay muchas opciones, pero al final, todas se pueden extraer mediante simples "mensajes de intercambio de microservicios", pero si implementa un protocolo síncrono (por ejemplo, RPC a través de REST), la mayoría de las desventajas del monolito permanecerán, pero las ventajas de los microservicios difícilmente aparecerán. Entonces, la solución obvia era tomar cualquier intermediario de mensajes y comenzar. Elegir entre RabbitMQ y Kafka se decidió por este último, y aquí está el por qué:
- Kafka es más simple y proporciona un único modelo de mensajería - Publicar - suscribirse
- Es relativamente fácil obtener datos de Kafka por segunda vez. Esto es extremadamente conveniente para depurar o corregir errores durante el procesamiento incorrecto, así como para monitorear y registrar.
- Una forma clara y simple de escalar el servicio: particiones agregadas al tema, lanzó más suscriptores; el resto lo hará kafka.
Además, quiero llamar la atención sobre una comparación detallada y de muy alta calidad .
Las colas en kafka + asynchrony nos permiten:
- Apague cualquier microservicio para actualizaciones brevemente sin consecuencias notables para el resto
- Apague cualquier servicio durante mucho tiempo y no se moleste con la recuperación de datos. Por ejemplo, el microservicio de fiscalización cayó recientemente. Fue reparado después de 2 horas, tomó las cuentas en bruto de Kafka y procesó todo. No era necesario, como antes, restaurar lo que se suponía que sucedería allí y llevar a cabo manualmente registros HTTP y una tabla separada en la base de datos.
- Ejecute versiones de prueba de los servicios con los datos actuales de la venta y compare los resultados de su procesamiento con la versión del servicio de la venta.
Como sistema de serialización de datos, elegimos AVRO, por qué, descrito en un artículo separado .
Pero independientemente del método de serialización elegido, es importante comprender cómo se actualizará el protocolo. Aunque AVRO admite la resolución de esquema, no utilizamos esto y decidimos puramente administrativamente:
- Los datos en los temas se escriben y leen solo a través de AVRO, el nombre del tema corresponde al nombre del esquema (y Confluent tiene un enfoque diferente : escriben esquemas de ID AVRO desde el registro en los bytes altos del mensaje, por lo que pueden tener diferentes tipos de mensajes en un tema
- Si necesita agregar o cambiar datos, se crea un nuevo esquema con un nuevo tema en kafka, después de lo cual todos los productores cambian a un nuevo tema y los siguen.
Almacenamos los circuitos AVRO en submódulos git y nos conectamos a todos los proyectos kafka. Decidieron no implementar todavía un registro centralizado de esquemas.
PD: los colegas hicieron la opción de código abierto, pero solo con el esquema JSON en lugar de AVRO .
Algunas sutilezas
Cada suscriptor recibe todos los mensajes del tema
Esta es la especificidad del modelo de interacción Publicar - suscribirse - cuando se suscribe a un tema, el suscriptor los recibirá a todos. Como resultado, si el servicio solo necesita algunos de los mensajes, tendrá que filtrarlos. Si esto se convierte en un problema, será posible crear un enrutador de servicio separado que presente los mensajes en varios temas diferentes, implementando así parte de la funcionalidad RabbitMQ que no está en el kafka. Ahora tenemos un suscriptor en Python en un hilo que procesa aproximadamente 7-5 mil mensajes por segundo, pero si se ejecuta desde PyPy, entonces la velocidad aumenta a 11-15 mil / seg.
Limite la vida útil de un puntero en un tema
En la configuración del kafka hay un parámetro que limita el tiempo que el kafka "recuerda" dónde se detuvo el lector; el valor predeterminado es 2 días. Sería bueno aumentarlo a una semana, de modo que si el problema surge durante las vacaciones y no se resuelven 2 días, esto no conduciría a una pérdida de posición en el tema.
Límite de tiempo de confirmación de lectura
Si el lector Kafka no confirma la lectura en 30 segundos (un parámetro configurable), entonces el agente cree que algo salió mal y se produce un error al intentar confirmar la lectura. Para evitar esto, cuando procesamos un mensaje durante mucho tiempo, enviamos confirmaciones de lectura sin mover el puntero.
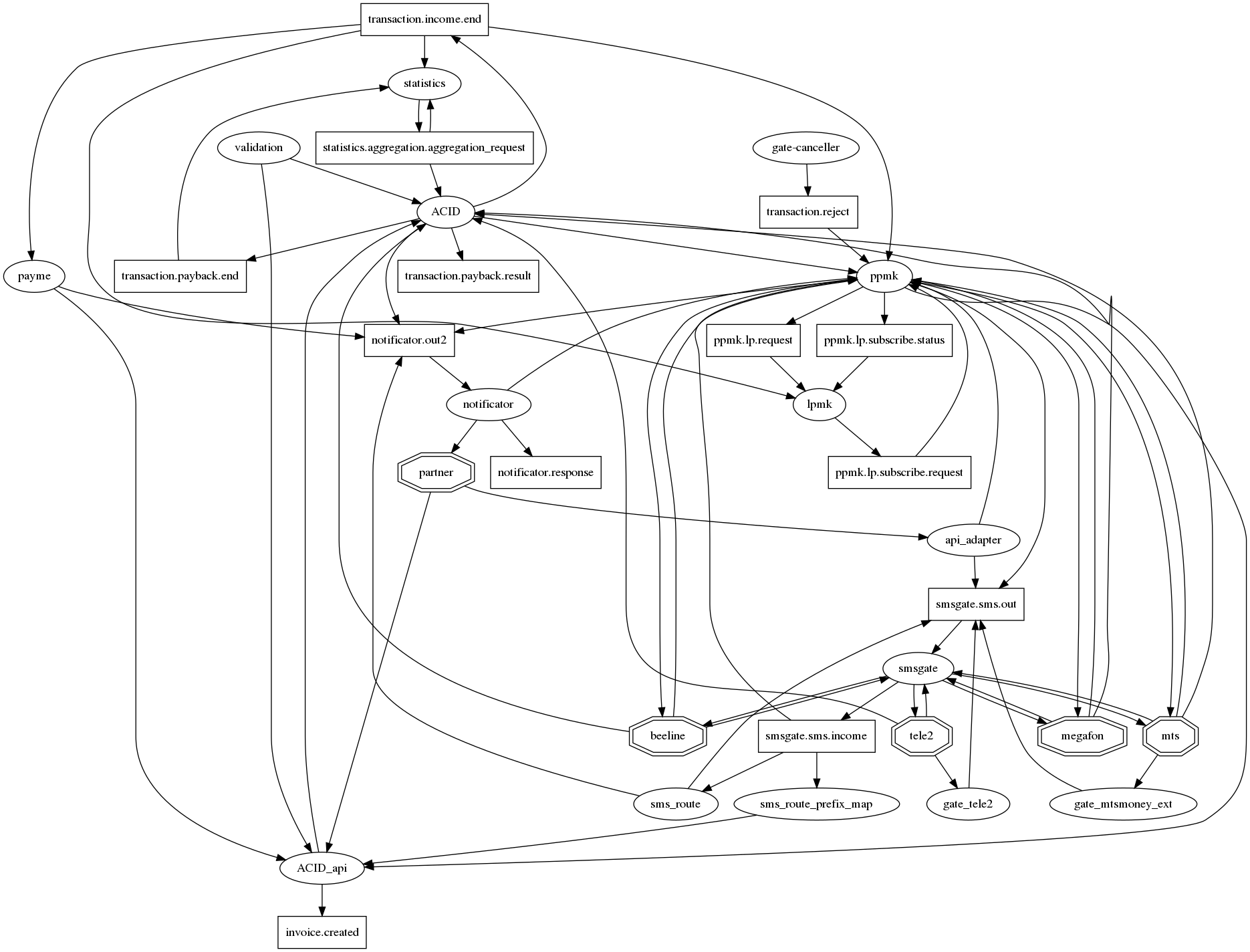
El gráfico de conexiones es difícil de entender.
Si honestamente dibuja todas las relaciones en graphviz, entonces hay un erizo del apocalipsis tradicional para microservicios con docenas de conexiones en un nodo. Para al menos de alguna manera hacer que (la gráfica de conexiones) sea legible, acordamos la siguiente notación: microservicios - óvalos, temas de kafka - rectángulos. Por lo tanto, en un gráfico, es posible mostrar tanto el hecho de la interacción como su tipo. Pero, por desgracia, no está mejorando mucho. Entonces esta pregunta aún está abierta.
¿Cómo monitorear?
Incluso como parte del monolito, teníamos registros en archivos y Centinela, pero a medida que pasamos a la interacción a través de Kafka y desplegamos a k8s, los registros se trasladaron a ElasticSearch y, en consecuencia, primero se monitorearon leyendo los registros del suscriptor en Elastic. Sin registros, sin trabajo.
Después de eso, comenzaron a usar Prometheus y kafka-exporter modificó ligeramente su tablero: https://github.com/kkirsanov/articles/blob/master/2019-habr-kafka/dashboard.json
Como resultado, obtenemos estas imágenes:
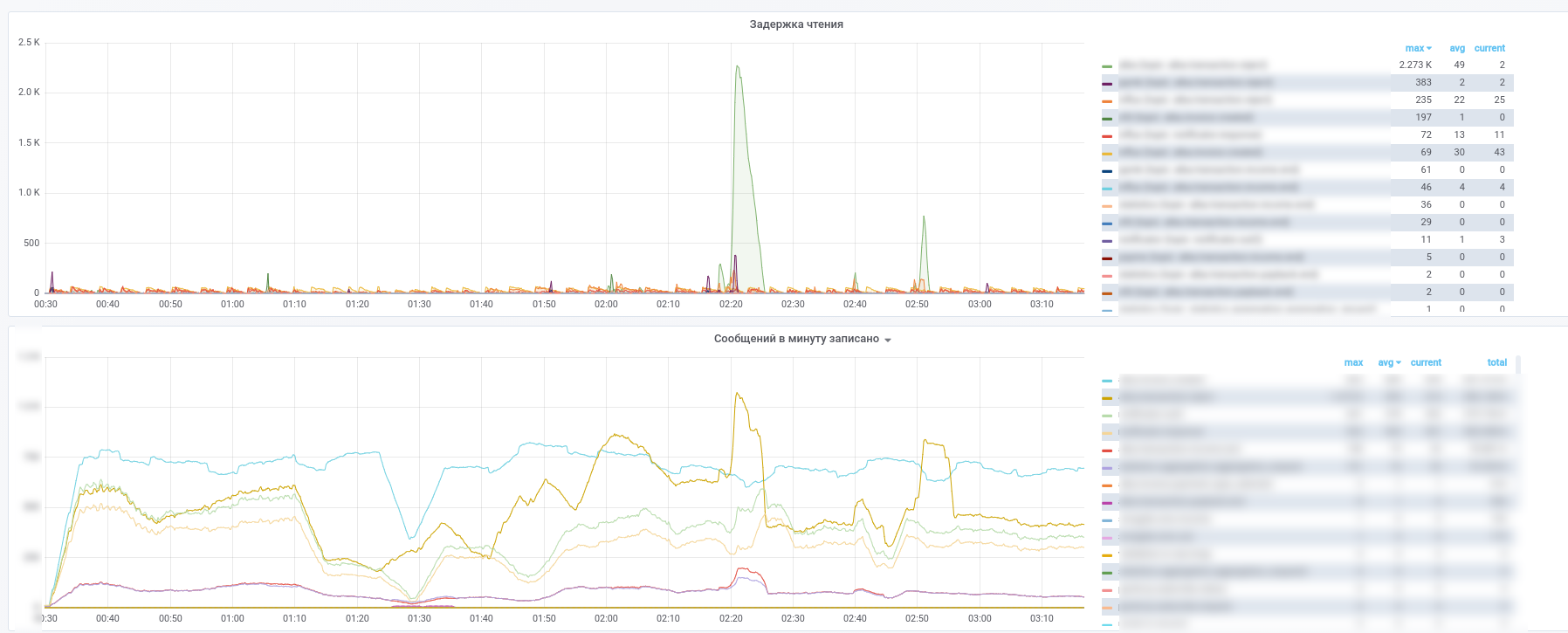
Puede ver qué servicio ha dejado de procesar qué mensajes.
Además, todos los mensajes de los temas clave (transacciones de pago, notificaciones de socios, etc.) se copian a InfluxDB, que se configura en la misma grafana. Por lo tanto, no solo podemos registrar el hecho del paso del mensaje, sino también hacer varias muestras de acuerdo con el contenido. Por lo tanto, las respuestas a preguntas como "¿cuál es el tiempo de demora promedio para una respuesta de un servicio" o "¿Es el flujo de transacciones muy diferente hoy de ayer en esta tienda" siempre están a la mano.
Además, para simplificar el análisis de incidentes, utilizamos el siguiente enfoque: cada servicio, cuando procesa un mensaje, lo complementa con metainformación que contiene el UUID emitido cuando el sistema muestra una serie de registros del tipo:
- nombre del servicio
- UUID del proceso de procesamiento en este microservicio
- marca de tiempo de inicio del proceso
- tiempo de proceso
- conjunto de etiquetas
Como resultado, a medida que el mensaje pasa por el gráfico computacional, el mensaje se enriquece con información sobre la ruta recorrida en el gráfico. Resulta un análogo de zipkin / opentracing para MQ, que permite recibir un mensaje para restaurar fácilmente su ruta en el gráfico. Esto adquiere un valor especial en aquellos casos en que aparecen ciclos en el gráfico. Recuerde el ejemplo de un servicio pequeño, cuya parte de los pagos es de solo 0.0001%. Al analizar la metainformación en el mensaje, puede determinar si fueron los iniciadores del pago, sin contactar a la base de datos para su verificación.