El interés en el análisis de imágenes para generar recomendaciones está creciendo cada día. Decidimos descubrir qué tan real trae este tema de tendencia. Hablamos de probar el uso del aprendizaje profundo (Deep Learning) para mejorar las recomendaciones de productos relacionados.

En este artículo, describimos la experiencia de aplicar tecnología de análisis de imágenes para mejorar el algoritmo de productos relacionados. Puede leerlo de dos maneras: aquellos que no estén interesados en los detalles técnicos del uso de redes neuronales pueden saltarse los capítulos sobre la creación de un conjunto de datos e implementar soluciones y pasar directamente a las pruebas AB y sus resultados. Y aquellos que tienen una comprensión básica de conceptos tales como incrustaciones, una capa de una red neuronal, etc., estarán interesados en todo el material.
Aprendizaje profundo en el contexto del análisis de imágenes
En nuestra pila de tecnología, Deep Learning se utiliza con bastante éxito para resolver algunos problemas. Durante algún tiempo no nos atrevimos a aplicarlo en el contexto del análisis de imágenes, pero recientemente aparecieron varias premisas que nos hicieron cambiar de opinión:
- mayor interés de la comunidad en el análisis de imágenes utilizando métodos de aprendizaje profundo;
- se definió un círculo de marcos "maduros" y redes neuronales pre-entrenadas, desde el cual se podía comenzar de manera bastante rápida y simple;
- El análisis de imágenes en los sistemas de recomendación a menudo se ha utilizado como una característica de marketing que garantiza mejoras "sin precedentes";
- Las necesidades alimentarias comenzaron a aparecer en este tipo de investigación.
En el contexto de la intersección de los sistemas de recomendación y el análisis de imágenes, puede haber muchas aplicaciones de aprendizaje profundo, sin embargo, en la primera etapa, identificamos por nosotros mismos tres formas principales de desarrollar esta área:
- Una mejora general en la calidad de las recomendaciones, por ejemplo, productos relacionados para un vestido, es más cualitativamente adecuada en color y estilo.
- Encontrar productos en la base de productos de una tienda usando una fotografía (Recuperación en la tienda) es un mecanismo que le permite encontrar productos en la base de datos de una tienda usando una foto cargada.
- Determinación de las propiedades / atributos del producto a partir de la foto (Etiquetado de atributos), cuando los atributos significativos se determinan a partir de la foto, por ejemplo, el tipo de producto: una camiseta, chaqueta, pantalón, etc.
La dirección más prioritaria y prometedora para nosotros es la primera opción, y decidimos explorarla.
¿Por qué elegiste un algoritmo para productos relacionados?
Cualquier sistema de recomendación tiene dos algoritmos básicos de productos estáticos: alternativas y productos relacionados. Y si todo está claro con las alternativas: estos son productos similares al modelo original (por ejemplo, diferentes tipos de camisas), entonces, con productos relacionados, todo es mucho más complicado. Aquí es importante no equivocarse con la correspondencia entre los productos básicos y recomendados, por ejemplo, el cargador debe ajustarse al teléfono, el color del vestido a los zapatos, etc .; debe tener en cuenta los comentarios, por ejemplo, no recomiende un teléfono al cargador, a pesar de que se compran juntos; y pensar en un montón de otros matices que surgen en la práctica. En gran parte debido a la presencia de varios matices, nuestra elección recayó en productos relacionados. Además, solo en productos relacionados es posible formar un aspecto completo, si hablamos del segmento de la moda.
Formulamos nuestro principal objetivo de investigación como "Comprender si el algoritmo actual para productos relacionados puede mejorarse significativamente utilizando métodos de aprendizaje profundo para el análisis de imágenes"
Noto que antes de eso no usamos la información de la imagen para calcular las recomendaciones del producto, y aquí está el por qué:
- Durante la existencia de la plataforma Retail Rocket, hemos adquirido una gran experiencia en el campo de las recomendaciones de productos. Y la conclusión principal que recibimos durante este tiempo es que el uso correcto del comportamiento del usuario proporciona casi el 90% del resultado. Sí, existe el problema de un arranque en frío, cuando las cosas de contenido, como la información sobre la imagen, pueden aclarar o mejorar las recomendaciones, pero en la práctica este efecto es mucho menor de lo que dicen en teoría. Por lo tanto, no ponemos mucho énfasis en las fuentes de información de contenido.
- Para crear recomendaciones de productos en forma de información de contenido, utilizamos elementos como el precio, la categoría, la descripción y otras propiedades que la tienda nos pasa. Estas propiedades son independientes de la esfera y se validan cualitativamente al integrar nuestro servicio. El valor de la imagen, por el contrario, surge de hecho solo en el segmento de artículos de moda.
- Mantener el servicio de trabajar con imágenes, validar su calidad y conformidad con los productos es un proceso bastante complicado y un deber técnico serio en el que no quería incurrir sin confirmar la necesidad.
Sin embargo, decidimos dar una oportunidad a las imágenes y ver cómo afectarán la efectividad de las recomendaciones de construcción. Nuestro enfoque no es ideal, seguro que alguien resolvería el problema de manera diferente. El objetivo de este artículo es presentar nuestro enfoque con una descripción de los argumentos en cada paso y presentar los resultados al lector.
Formación del concepto
Comenzamos cruzando los tres componentes de cualquier producto: tecnología asequible, recursos disponibles y necesidades del cliente. El concepto de "mejorar las recomendaciones a través de la información sobre la imagen de productos relacionados" se ha desarrollado por sí mismo. La implementación "ideal" de este producto se formó como un problema compilado en la imagen de un aspecto seleccionado. Además, tales recomendaciones no solo deberían verse bien, sino que también deberían funcionar desde el punto de vista de las métricas básicas de comercio electrónico (Conversión, RPV, AOV) no peor que nuestro algoritmo básico.
Look es una imagen elegida por los estilistas, que incluye un conjunto de cosas diferentes que se combinan entre sí, por ejemplo, un vestido, chaqueta, bolso, cinturón, etc. Del lado de nuestros clientes, dicho trabajo generalmente lo realizan personas especialmente designadas cuyo trabajo está mal automatizado. Después de todo, no todas las redes neuronales pueden tener sentido del gusto.
 Una imagen de ejemplo (look).
Una imagen de ejemplo (look).Inmediatamente hubo restricciones en el uso de la información de la imagen; de hecho, la aplicación se encontró solo en el segmento de la moda.
Infraestructura y conjunto de datos
En primer lugar, planteamos un banco de pruebas para experimentos y creación de prototipos. Aquí todo es GPU + Python + Keras bastante estándar, por lo que no entraremos en detalles. Encontramos un conjunto de datos de alta calidad que fue diseñado para resolver varios problemas a la vez, desde la predicción de los atributos de la imagen hasta la generación de nuevas texturas de ropa. Lo que fue especialmente importante para nosotros, incluía fotografías que constituían prácticamente una sola mirada. Además, el conjunto de datos incluía fotografías de modelos de ropa desde diferentes ángulos, que intentamos usar en la primera etapa.
 Ejemplo de un conjunto de datos.
Ejemplo de un conjunto de datos. Ejemplos de imágenes del mismo modelo de ropa desde diferentes ángulos.
Ejemplos de imágenes del mismo modelo de ropa desde diferentes ángulos.Primeros pasos
La primera idea de implementar el producto final utilizando el conjunto de datos fue bastante simple: “Reduzcamos el problema a la tarea de reconocer la ropa por imagen. Por lo tanto, al formular recomendaciones, "levantaremos" aquellas recomendaciones que son similares al producto básico ". En consecuencia, se suponía que debía encontrar la función de "proximidad" de los bienes y, en el camino, resolver el problema de eliminar alternativas en el tema.
Debo decir de inmediato que este tipo de problema podría resolverse usando una red neuronal pre-entrenada convencional, como ResNet-50. De hecho: eliminamos la última capa, obtenemos incrustaciones, bueno, y luego el coseno, como una medida de "proximidad". Sin embargo, después de experimentar un poco con este enfoque, decidimos dejarlo principalmente por tres razones.
- No está muy claro cómo interpretar correctamente la proximidad resultante. Lo que se dice coseno = 0.7 en el dominio de las camisetas, donde por regla general todo es muy similar entre sí y lo que es coseno = 0.5 en el dominio de las chaquetas, donde las diferencias son más significativas. Necesitábamos este tipo de interpretación para eliminar simultáneamente productos muy cercanos: alternativas.
- Este enfoque nos limitó un poco desde el punto de vista de la educación adicional para nuestras tareas específicas. Por ejemplo, las características importantes que forman una imagen holística no siempre son las mismas de un dominio a otro. En alguna parte, el color y la forma son más importantes, pero en alguna parte el material y su textura. Además, queríamos capacitar a la red para cometer menos errores de género cuando se recomienda a las mujeres para la ropa de los hombres. Tal error es inmediatamente evidente y debe encontrarse tan raramente como sea posible. Con el simple uso de redes neuronales pre-entrenadas, parecía que estábamos un poco limitados por la incapacidad de proporcionar ejemplos que son bien "similares" en términos de imagen.
- El uso de las redes siamesas, que son más adecuadas para estas tareas, parecía ser una opción más natural y mejor estudiada.
Un poco sobre la red neuronal siamesa
Las redes neuronales siamesas se utilizan ampliamente para resolver tareas relacionadas con el reconocimiento facial. En la entrada, se proporciona una imagen de la persona, en la salida, el nombre de la persona de la base de datos a la que pertenece. Tal problema se puede resolver directamente, si usa softmax y el número de clases igual al número de personas reconocibles en la última capa de la red neuronal. Sin embargo, este enfoque tiene varias limitaciones:
- necesitas tener una cantidad suficientemente grande de imágenes para cada clase, lo cual es prácticamente imposible.
- una red neuronal de este tipo tendrá que volverse a entrenar cada vez que se agregue una nueva persona a la base de datos, lo cual es muy inconveniente.
Una solución lógica en tal situación sería obtener la función de "similitud" de las dos fotos para responder en cualquier momento si las dos fotos, suministradas a la entrada de la red neuronal y la referencia de la base de datos, pertenecen a la misma persona y, en consecuencia, resuelven el problema del reconocimiento facial. Esto es más consistente con el comportamiento de una persona. Por ejemplo, un guardia mira la cara de una persona y una foto en una placa y responde a la pregunta de si esa persona es una o no. La red neuronal siamesa implementa un concepto similar.
El componente principal de la red neuronal siamesa es la red neuronal troncal, que genera una incrustación de imágenes. Esta incrustación se puede utilizar para determinar el grado de similitud entre las dos imágenes. En la arquitectura de la red neuronal siamesa, el componente principal se usa dos veces, cada vez para recibir la incrustación de la imagen. El investigador necesita mostrar los valores de salida 0 o 1, dependiendo de si una o diferentes personas son propietarias de las fotos, y ajustar la red neuronal de la red troncal.
 Un ejemplo de una red neuronal siamesa. Las incrustaciones de las imágenes superior e inferior se obtienen de la columna vertebral de la red neuronal. Imagen tomada del curso "Redes neuronales convolucionales" de Andrey Ng.
Un ejemplo de una red neuronal siamesa. Las incrustaciones de las imágenes superior e inferior se obtienen de la columna vertebral de la red neuronal. Imagen tomada del curso "Redes neuronales convolucionales" de Andrey Ng.Solución básica
Por lo tanto, después de algunos experimentos, la primera versión del algoritmo fue la siguiente:
- Tomamos cualquier red neuronal pre-entrenada como columna vertebral. Experimentamos con ResNet-50 e InceptionV3. Seleccionado en función del equilibrio del tamaño de la red y la precisión de las predicciones. Nos centramos en los datos presentados en la documentación oficial de la sección de Keras "Documentación para modelos individuales".
- Creamos una red siamesa sobre la base y utilizamos la pérdida de triplete para el entrenamiento.
- Como ejemplos positivos, servimos la misma imagen, pero desde un ángulo diferente. Como ejemplo negativo, estamos sirviendo otro producto.
- Con un modelo entrenado, obtenemos la métrica de proximidad para cualquier par de productos de la misma manera que se considera la pérdida de triplete.
Código de cálculo de pérdida de triplete.El acuerdo con Triplet Loss en un proyecto real fue la primera vez, lo que creó una serie de dificultades. Al principio, lucharon durante mucho tiempo con el hecho de que las incrustaciones recibidas se redujeron a un punto. Hubo varias razones: no normalizamos las incrustaciones antes de calcular la pérdida; margen el parámetro alfa era demasiado pequeño y los ejemplos demasiado difíciles. La normalización y las incorporaciones añadidas comenzaron a variar. El segundo problema inesperadamente se convirtió en Gradient Exploding. Afortunadamente, Keras hizo posible resolver este problema de manera bastante simple: agregamos clipnorm = 1.0 al optimizador, lo que no permitió que los gradientes crecieran durante el entrenamiento.
El trabajo fue iterativo: capacitamos al modelo, bajamos la pérdida, observamos el resultado final y decidimos por expertos en qué dirección íbamos. En algún momento, quedó claro que de inmediato establecemos ejemplos bastante complejos y que la complejidad no cambia en el proceso de aprendizaje, lo que afecta negativamente el resultado final. Afortunadamente, el conjunto de datos con el que trabajamos tenía una buena estructura de árbol que reflejaba el producto en sí, por ejemplo, Hombres -> Pantalones, Hombres -> Suéteres, etc. Esto nos permitió rehacer el generador y comenzamos a dar ejemplos "fáciles" para las primeras eras, luego las más complejas y así sucesivamente. Los ejemplos más difíciles son productos de la misma categoría de productos, por ejemplo Pantalones, como negativos.
Como resultado, obtuvimos un modelo que difería en su salida de la metodología "ingenua" para usar ResNet-50. Sin embargo, la calidad de las recomendaciones finales no nos satisfizo completamente. En primer lugar, hubo un problema con los errores de género, pero se entendió cómo se podría resolver. Dado que el conjunto de datos dividió la ropa en hombres y mujeres, fue fácil recopilar ejemplos negativos para el entrenamiento. En segundo lugar, al entrenar en el conjunto de datos el resultado final, verificamos visualmente a nuestros clientes; de inmediato quedó claro que era necesario volver a entrenar sus ejemplos, ya que para algunos el algoritmo funcionó muy mal si los productos no se superponían bien con lo que se mostró durante el entrenamiento . Finalmente, la calidad era a menudo deficiente, porque la imagen del entrenamiento a menudo era ruidosa y contenía, por ejemplo, no solo jeans, sino también una camiseta.
 La imagen de jeans en la que, de hecho, también muestra una camiseta y botas.
La imagen de jeans en la que, de hecho, también muestra una camiseta y botas.La primera experiencia sirvió de base para la solución posterior, aunque no comenzamos de inmediato a implementar un modelo mejorado.
 Un ejemplo de recomendaciones basadas en una solución básica. Hay errores de género, también surgen alternativas.
Un ejemplo de recomendaciones basadas en una solución básica. Hay errores de género, también surgen alternativas.Modelo mejorado
Comenzamos entrenando ResNet-50 sobre los datos de nuestro conjunto de datos. El conjunto de datos contiene información sobre lo que se muestra en la imagen. Se extrae de la estructura del conjunto de datos Hombres -> Pantalones, Mujeres -> Cárdigans y más. Este procedimiento se realizó por dos razones: en primer lugar, querían "dirigir" la columna vertebral: una red neuronal al dominio de la ropa; En segundo lugar, dado que la ropa también se divide por género, esperaban deshacerse del problema de los errores de género que se encontraron en la primera versión.
En la segunda etapa, tratamos de eliminar simultáneamente el ruido de las imágenes de entrada y obtener pares positivos de productos relacionados para capacitación adicional. El conjunto de datos que utilizamos también está diseñado para resolver el problema de detectar objetos en la imagen. En otras palabras, para cada imagen hay: las coordenadas del rectángulo que describe el objeto y su clase. Para resolver este tipo de problema, utilizamos un
proyecto listo para usar. Este proyecto utiliza la arquitectura de red neuronal RetinaNet utilizando una pérdida focal especial. La esencia de esta pérdida es enfocarse más no en el fondo de la imagen, que está en casi todas las imágenes, sino en el objeto que necesita ser detectado. Como columna vertebral de una red neuronal para el entrenamiento, utilizamos nuestra red pre-entrenada ResNet-50.
Como resultado, se detectan tres clases de objetos en cada imagen del conjunto de datos: "arriba", "abajo" y "vista general". Después de definir las clases "superior" e "inferior", simplemente cortamos la imagen en dos imágenes separadas, que luego se utilizarán como un par de ejemplos positivos para calcular la pérdida de triplete. La calidad de detección de objetos resultó ser bastante alta, la única queja era que no siempre era posible encontrar una clase en la imagen. Esto no fue un problema para nosotros, ya que podíamos aumentar fácilmente el número de imágenes para las predicciones.
 Un ejemplo de detectar las clases "arriba" y "abajo" y cortar la imagen.
Un ejemplo de detectar las clases "arriba" y "abajo" y cortar la imagen.Al tener este tipo de divisor de imágenes, tuvimos la oportunidad de echar un vistazo a Internet y dividirlo en componentes para usar en la capacitación. Para aumentar la muestra de capacitación y vencer el problema con una cobertura insuficiente de ejemplos que surgieron durante el desarrollo de la solución básica, ampliamos el conjunto de datos debido a las imágenes "cortadas" de uno de nuestros clientes. El único problema era que no distinguíamos objetos como "accesorio", "tocado", "zapatos", etc. Esto creó algunas limitaciones, pero fue bastante adecuado para probar el concepto. Después de recibir resultados positivos, planeamos expandir el modelo a las clases descritas anteriormente.
Habiendo recibido un conjunto de datos extendido, utilizamos la metodología ya probada para construir la red siamesa a partir de una solución básica, aunque hubo varias diferencias. En primer lugar, como la columna vertebral de la red neuronal, utilizamos la red ResNet-50 ahora capacitada descrita anteriormente. En segundo lugar, ahora, como ejemplos positivos, hemos presentado pares de arriba a abajo y viceversa, permitiéndonos aprender de la red neuronal exactamente la "correspondencia" de la imagen. Bueno, en realidad una docena de épocas más tarde, apareció un mecanismo que nos dio la oportunidad de evaluar la "conformidad" de los productos con una sola imagen.
 Un ejemplo de recomendaciones basadas en el uso de una red neuronal. Se recomiendan pantalones cortos para el producto básico; se recomiendan camisetas.
Un ejemplo de recomendaciones basadas en el uso de una red neuronal. Se recomiendan pantalones cortos para el producto básico; se recomiendan camisetas.El resultado final nos agradó: las recomendaciones resultaron ser visualmente de buena calidad y, lo que es especialmente bueno, su construcción no requirió ningún historial de interacciones del usuario. Sin embargo, los problemas persistieron, el principal fue la disponibilidad de alternativas en la extradición. Entonces encontré extradiciones en las que el "fondo" se recomendaba al "fondo", lo mismo sucedió con la categoría "superior". Esto nos hizo pensar y refinar la solución para eliminar alternativas.
Eliminar alternativas
Para resolver el problema de la disponibilidad de alternativas, la emisión fue bastante rápida. Los experimentos iniciales con el ResNet-50 "vainilla" ayudaron. Tal red neuronal dio como bienes "similares" a los que más coincidían en la imagen, de hecho, alternativas. Es decir, podría usarse para identificar alternativas.
 Un ejemplo de recomendaciones basadas en el ResNet-50 "vainilla". Los bienes son alternativas.
Un ejemplo de recomendaciones basadas en el ResNet-50 "vainilla". Los bienes son alternativas.Usando esta útil propiedad de ResNet-50, comenzamos a filtrar los productos lo más cerca posible de la emisión, eliminando así las alternativas. También hubo desventajas en este enfoque: la misma situación incomprensible con la que elegir el umbral para el filtrado. A veces se filtraron muchos productos, a pesar de que externamente no eran alternativas. Sin embargo, no nos centramos en este problema y seguimos trabajando más.
Preparación de pruebas AB
Para la verificación final de prácticamente cualquier cambio en los algoritmos, utilizamos ampliamente la herramienta de prueba AB. Además, solo tenemos una regla: "no importa cuán pequeña sea la pérdida, no importa cuán compleja y de múltiples capas sea la red neuronal, cuán hermosas pueden ser las recomendaciones; todo esto no se tiene en cuenta si no hay resultados en la prueba AB". La lógica es bastante simple: una prueba AB es la más honesta, comprensible para todas las partes (especialmente clientes y empresas) y un método preciso para medir el resultado. Retail Rocket - ( «
A/- 99% - ? »). - .
-. ,
RecSys 2016 . . , , , , . , - , .
, . , . , . - . , , , , - . : .
- , . -, , , , . -, — , , , , . , . , , , “», .
:
- “” “”, , , , . , , , .
- , . proof-of-concept , .
, , . , , .
AB-
, , - . — fashion. . , , . , , .
. 3 . , 95%.
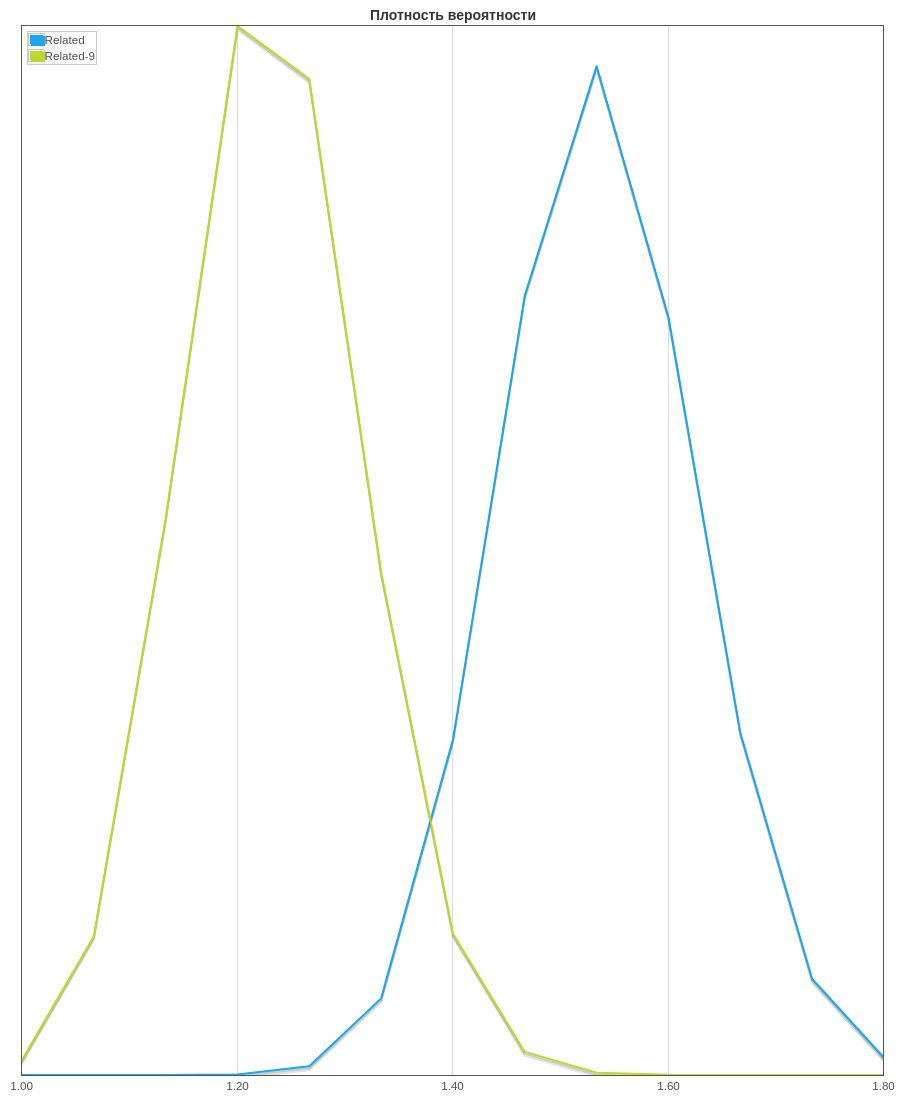
 . Related-9 — “” , Related — .
. Related-9 — “” , Related — . . Related-9 “” . : Mann-Whitney Test Bootstrap. 97%.
. Related-9 “” . : Mann-Whitney Test Bootstrap. 97%.: . , , , “” CTR. , , CTR , . - , - - , -. , .
 CTR. . CTR Related-9, “” , () Related — (). CTR ( ) — 95%.
CTR. . CTR Related-9, “” , () Related — (). CTR ( ) — 95%., , , , . , , . , , . .
Conclusiones
, , . , , . - . , — — , . , . , , , Retail Rocket.
, , , , « ». , . , .
, Retail Rocket