Casi todos los sistemas de recomendación tienen dificultades con el contenido nuevo o raro, ya que solo una pequeña parte de los usuarios interactúa con él. En su informe en
el Yandex Inside, Daniil Burlakov compartió un conjunto de trucos que se utilizan en las recomendaciones de la Música y detalló el modelo popular Descomposición de valor singular (SVD).
Además, contamos con artistas que se llaman compositores y, por lo general, son menospreciados por los titulares de derechos de autor como un fanático. Solo Mozart había "grabado" más de un millón de composiciones.
- Hola a todos! Mi nombre es Daniil Burlakov, lidero un equipo de recomendaciones en Servicios de Medios. Hoy quiero hablar sobre algunos de los problemas que resolvemos cuando tratamos con recomendaciones en Música.
Tenemos un equipo maravilloso que hace recomendaciones no solo para Yandex.Music, sino también para todos los Servicios de Medios: este es Kinopoisk, Poster. Resolvemos muchos más problemas técnicos que las recomendaciones.

Hoy quiero hablar sobre el producto central Yandex. Música, nuestro producto más importante y favorito son las listas de reproducción inteligentes, que, probablemente, muchos de ustedes conocen y escuchan.

Revisaré brevemente qué tipo de listas de reproducción son y con qué contenido las llenamos.
La lista de reproducción del día se concibió como un conjunto de pistas que se crearán todos los días para que pueda descargarlas y escucharlas incluso donde no hay Internet. Pero será genial para ti, estará contigo, y debería actualizarse todos los días y contener algo nuevo. Lo que más te convenga.
Deja Vu es una lista de reproducción más interesante. Se actualiza una vez por semana, y habrá pistas que nunca escuchaste, y artistas que prácticamente no conoces o no conoces en absoluto. Premiere: una selección de nuevos productos de tus artistas que te pueden gustar.

El segundo producto es Yandex.Radio. En 2015, se lanzó, seguimos desarrollándolo.
La idea es permitir al usuario obtener una transmisión personalizada de música de audio sin hacer nada. De hecho, presioné un botón y obtuve una transmisión maravillosa que nunca terminará y lo deleitará durante muchas horas. A diferencia de las listas de reproducción, ya se puede etiquetar. Puede, por ejemplo, encender la radio por género: rock o música de fondo, si no desea distraerse durante el trabajo. O una transmisión de audio totalmente personalizada: lo que llamamos la radio "On Your Wave".

¿Qué problemas enfrentamos cuando hacemos estas recomendaciones? Nos enfrentamos a dos problemas principales, bastante típicos para la mayoría de los sistemas de recomendación. Estos son usuarios fríos que acaban de llegar a nuestro servicio y sobre los cuales aún no sabemos nada, y contenido genial. Incluye no solo pistas que han aparecido recientemente, sino también una gran cantidad de pistas raras. El catálogo Yandex.Music contiene más de 50 millones de pistas, muchas de ellas aún no han sido escuchadas por ningún usuario. Por lo tanto, surge un problema: incluso si la pista salió el tiempo suficiente, desafortunadamente, es posible que no sepamos nada sobre esta pista y no tengamos estadísticas.
Ambos problemas se agravaron especialmente y se volvieron especialmente importantes para nosotros, ya que Yandex.Music se convirtió en un servicio internacional y comenzó a ir a muchos países. Al ingresar a cada país, el contenido local de este país se vuelve, en primer lugar, muy importante. Está claro que cuando entras en un nuevo país, ignorar la música local es bastante desagradable. Es necesario recomendarlo, recomendarlo adecuadamente y comprender la estructura de esta música interna. De hecho, en Rusia nadie escucha música israelí, y hay muy pocas estadísticas al respecto, incluso si tenemos este contenido.
Repasemos estos problemas. Comencemos con el problema de los usuarios fríos. ¿Cómo se puede resolver?

La primera solución más simple es no recomendar nada a los usuarios fríos. De hecho, la solución es muy simple, solo puede preguntar sobre preferencias explícitas. Estos son numerosos asistentes que pueden proporcionarse al usuario.
antes de que el usuario reciba su primera lista de reproducción del día, le pedimos que siga un asistente de este tipo, indicando sus preferencias, un conjunto de géneros y artistas que le gustaría.
Como resultado de esto, la primera lista de reproducción del usuario se vuelve bastante significativa, adecuada para el usuario y, muy probablemente, desde la primera lista de reproducción, el usuario se enamorará de él.
Desafortunadamente, este enfoque no siempre se puede hacer.

Nuestro segundo producto, Yandex.Radio, fue concebido como un producto que no requiere esfuerzo por parte del usuario. Él solo quiere venir y encender la música sin hacer nada. Además, Yandex.Radio está integrado en muchos otros sistemas, como Yandex.Drive, donde es bastante extraño e inconveniente simplemente obligar al usuario a sentarse en el automóvil, hacer clic en algún tipo de asistente si llegó por primera vez.
Por lo tanto, fuimos por el otro lado. Comenzamos con recomendaciones, digamos, para el usuario promedio, para que la mayoría de los usuarios de las primeras pistas obtengan el máximo placer y les guste la música. Y proporcionamos una personalización muy rápida. A diferencia de la lista de reproducción que recibió y él está con usted todo el día, todas sus 60 pistas. Y si, por ejemplo, no adivinamos con el hecho de que su género favorito es la música popular (que será una buena suposición para empezar), entonces las 60 pistas no serán sobre usted, y será triste, y lo más probable es que mañana no lo haga. vuelve
Sin embargo, si ponemos la primera pista de música popular en la radio y usted dice que no quiere escucharla, personalizaremos al instante la siguiente pista para usted y le ofreceremos algo más, por ejemplo, rock u otro género.
De hecho, estas dos soluciones cierran el problema de los usuarios fríos en un grado u otro.
¿Cómo podría resolverse el problema del contenido por analogía? La solución número uno, así como sobre los usuarios, no es recomendar contenido interesante. Pero aquí, a diferencia de los usuarios, el contenido en sí no se recuperará y no se calentará. Por lo tanto, el problema es que si nosotros mismos no recopilamos estadísticas sobre él, entonces el nuevo producto del artista que acaba de ser lanzado no se entregará, y los usuarios que no hayan visto las noticias de su artista probablemente se molestarán.

Una situación similar con contenido internacional. Fuimos a un nuevo país, y no recomendarlo, ignorar este contenido, obviamente, no nos conviene.
La segunda solución, si actuamos completamente por analogía, la recomendamos de alguna manera en promedio. La analogía más simple es transmitir este contenido a todos en una fila o recomendarlo como música popular. Con la opción de recomendar, en promedio, generalmente no está muy claro qué música promedio es. Esto se puede llamar música popular por la fuerza, pero difícilmente se puede decir que toda la música es tan similar entre sí que parece música popular. Por lo tanto, si encuentra una composición de Beethoven entre música popular, es poco probable que la mayoría de las personas estén felices de recibirla. Por lo tanto, esta solución tampoco nos conviene.

¿Qué más hay sobre las pistas? Junto con la pista en sí, nos llegan muchos metadatos del titular de los derechos de autor, como el género de la pista, el artista, el álbum y el año de lanzamiento. Vamos a pasar ¿Cómo podrían ser utilizados? Por ejemplo, un género. Un género es buena información que nos permite adivinar más o menos. Por ejemplo, resuelve el problema con Beethoven o un chanson que podría haber aparecido accidentalmente en alguien en la radio: conocemos el género de la pista, y es poco probable que la traslademos a aquellos a quienes no encaja.
Pero desafortunadamente, él no permite construir una buena recomendación, porque el concepto del género en sí es bastante subjetivo, y no permite construir buenas recomendaciones sobre la base de él. Naturalmente, hay muchos subgéneros dentro de los géneros, y eso es exactamente lo que nos envían los titulares de derechos de autor.

El segundo problema es que una persona común generalmente puede nombrar una docena de géneros, mientras que los titulares de derechos de autor nos envían miles de géneros, y este es un problema lo suficientemente grande como para agruparlos, encontrar otros similares entre ellos, etc. Lamentablemente, este problema no siempre se resuelve.
Entonces, obviamente, hay problemas con el hecho de que, desafortunadamente, los titulares de los derechos de autor a menudo se confunden y cometen errores. Y tenemos problemas regulares e informes de que recopilamos pistas que son populares en radio rock, y el titular de los derechos de autor les puso el género rock. Por analogía, recopilamos jazz y otras estaciones de radio. Y regularmente tenemos informes de usuarios que solicitan ser corregidos, porque una pista con un error ha volado a estas estaciones de radio.
Quiero ofrecerte a adivinar el género de la canción.
Esta no es una banda sonora. Esto es metal Y tenemos un gran problema cuando nos envían ese marcado.
Propongo pasar a la siguiente parte y hablar sobre los intérpretes de la pista. Ya dije que hay un problema, que sale un nuevo artista, una nueva pista o álbum, y debería recomendarse. En particular, la información sobre el artista siempre nos salvará. Sabemos que el usuario escuchó a este artista, y podemos recomendarlo en consecuencia. Así lo hacemos Sin embargo, también hay dificultades. Por ejemplo, si no sabíamos nada sobre el propio artista o si el usuario no lo escuchaba, la información que tiene esta pista sobre tal artista no nos dice nada. Del mismo modo con pistas raras. Hubo una canción rara de un artista raro, aprendimos que ahora esta canción rara le pertenece. Desafortunadamente, nuevamente no hay mucha información que le permita ser recomendado de alguna manera a otras personas que no están familiarizadas con su trabajo.

El segundo problema son las portadas y las remezclas. Una vez más, los titulares de derechos de autor viles intervienen aquí y a menudo cometen errores. En particular, cuando tenemos una pista original y su portada, los titulares de los derechos de autor a menudo no se molestan en nombrar estas pistas de diferentes maneras, para firmar que una de ellas es un remix o incluso simplemente descalificar a diferentes artistas para ellas, cuando lo es.
Quiero ofrecerle dos pistas para comprender cuán diferente es el sonido para las pistas que se llaman exactamente igual. Por lo tanto, obtenemos dos pistas que se pueden llamar similares, tienen un ritmo relativamente similar, un texto relativamente similar, pero son diferentes. Y para nosotros es una misma pista, porque su nombre, artista y todo lo demás son exactamente iguales.
Además, tenemos artistas tan viles que se llaman compositores y que los titulares de los derechos de autor suelen despreciar como un fanático. Solo Mozart había "grabado" más de un millón de composiciones. Está claro que para los amantes de la música clásica esto no será posible. Si el usuario dice que le gusta Mozart, entonces tenemos millones de pistas, varias repeticiones de melodías clásicas estándar. Como resultado, casi no podemos hacer nada al respecto.

Quiero contarles más sobre cómo se podría resolver este problema, pero para empezar, relajemos nuestros requisitos. Queríamos recomendar pistas que nadie escuchó, y ahora pensemos en cómo recomendar solo pistas que serían raras. El filtrado colaborativo viene en nuestra ayuda aquí. ¿Cómo funciona y qué obtenemos al final?
Para comenzar, necesitamos hacer una matriz de calificaciones de usuarios, donde habrá usuarios en las líneas, habrá pistas en las columnas, en la intersección de la columna y la línea será su calificación. Está claro que para la mayoría de la matriz no conocemos los comentarios de los usuarios, los usuarios no podían escuchar nuestro catálogo completo ni siquiera cerca.
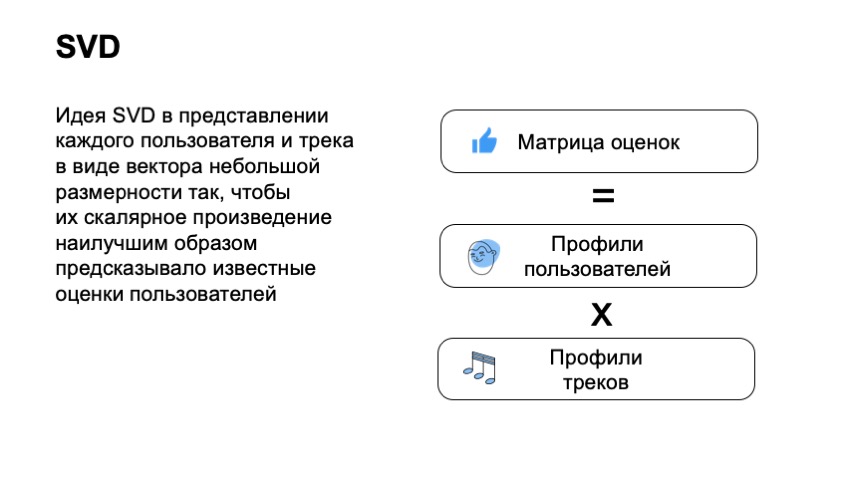
Con esta matriz, queremos que el usuario y la pista asocien vectores pequeños y lo suficientemente cortos para que el producto escalar del vector del usuario y del vector del elemento prediga bien la calificación del usuario. Por lo tanto, obtenemos que para cada elemento y para cada usuario, debemos encontrar dos vectores para que su producto final prediga mejor nuestra estimación. Por ejemplo, si en este caso diríamos que al usuario le gustó la pista, este es 1, si no, - 0. Y en este caso podemos aplicar la técnica estándar, la descomposición SVD y obtener los vectores óptimos para los usuarios y para las pistas.

¿Qué nos da esto? Esto nos da la próxima gran ventaja. Para la mayoría de los enfoques, no podemos decir que las dos pistas son similares si nadie escuchaba juntas. Por lo general, una parte importante de los enfoques se basa en el hecho de que tenemos algunos usuarios que interactuaron con los elementos A y B, y vemos que son similares como resultado de esto. El filtrado colaborativo en forma de SVD nos permite hacer esto incluso si ningún usuario escuchó dos pistas juntas. Nos permiten evaluarlo bastante bien. Esta es la primera ventaja.
¿Qué nos da esto? Al tener un vector de pista, podemos recomendarlo a un círculo mucho más amplio de personas y recomendar pistas mucho menos populares. Y la ventaja principal es que todavía obtenemos una representación vectorial de las pistas, lo cual es muy conveniente para trabajar, con lo que puede buscar rápidamente pistas similares.
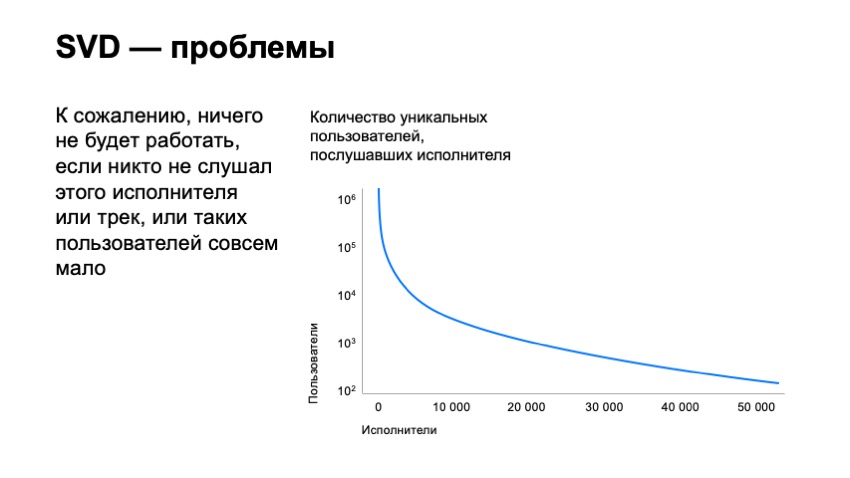
Sin embargo, esto no resuelve todos nuestros problemas. solo movimos ligeramente la barra para la cantidad de pistas que podemos recomendar. Si construimos un gráfico de la cantidad de usuarios que escucharon a los artistas intérpretes o ejecutantes, clasificamos a los artistas intérpretes o ejecutantes de hecho por su popularidad, veremos que millones de usuarios están escuchando a los mejores artistas en nuestro servicio. Si observamos la posición número 10 mil de estos artistas, solo habrá mil usuarios. Si miramos al artista número 50,000, solo habrá un centenar de usuarios. Está claro que sus pistas solo tendrán docenas de usuarios que lo escucharon, lo que de hecho hace que sea imposible recomendarlas, ya que el vector SVD para tales pistas será extremadamente inestable y no funcionará.
¿Cómo podemos tratar de resolver esto? Que queremos
Queremos tomar una pista nueva y rara de la que no sabemos nada, por ejemplo, una pista rara de Israel, y queremos obtener algún tipo de representación vectorial para ella, que sería muy similar a nuestro vector SVD, con el cual es muy conveniente trabajar y hacer recomendaciones.
Lo único que no consideramos es el audio de esta pista en sí. Gracias al audio, podríamos recomendar las pistas. ¿Cómo podríamos, usando una pista de audio, obtener un vector SVD? Lo primero que queremos hacer es una pequeña conversión.
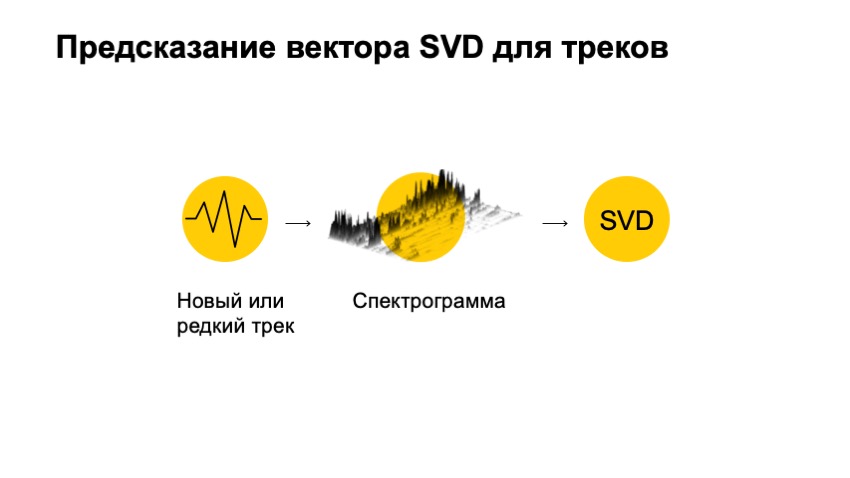
¿Qué es esencialmente audio? Puedes imaginar un gráfico de voltaje. En cualquier caso, este es un conjunto de números unidimensional, con el cual es bastante incómodo trabajar, es muy grande y largo, tiene poco sentido en sí mismo. Pero podemos verificar su espectro, hacer que Fourier se transforme en él, muy brevemente, para ver cuánto se parece a un tipo específico de sinusoide. Cuánto se parece a una especie de sinusoide. Y vea cuántos sinusoides hay en este gráfico, y haga lo mismo para cada una de las frecuencias.
Si hacemos esto para toda la pista en su conjunto, por supuesto, obtendremos algo de información, pero muy poco, dirá muy poco, porque, por ejemplo, las transiciones entre partes de la pista son muy importantes para la música, mientras que en el espectro lo haremos tener en forma indirecta un cambio en frecuencias muy grandes, que debería relacionarse con segundos, con minutos, y esto es bastante inconveniente y está mal presentado en forma de espectro.
Por lo tanto, vamos más allá y cortamos la pista en pedazos pequeños. En cada pieza hacemos tal transformación. Como resultado, obtenemos una imagen así, la dibujé en forma tridimensional, para que sea más visible que tenemos frecuencias desplegadas en un plano en el tiempo y en altura, la energía que era en ese momento en el tiempo. Y obtuvieron el llamado espectrograma.
¿Cómo podríamos, usando este espectrograma, obtener el vector SVD? La respuesta en nuestro tiempo es bastante banal: tomemos una red neuronal y entrenémosla para predecir el vector SVD.
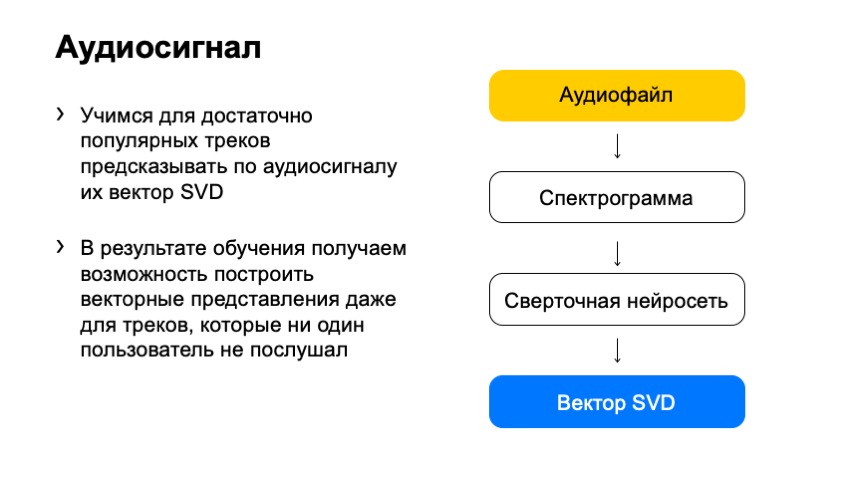
Entonces lo hicimos. ¿Qué elegimos como entrenamiento? Esas pistas SVD cuyo vector sabemos con certeza. Seleccionamos especialmente pistas populares cuya retroalimentación era lo suficientemente grande como para que el vector SVD ya fuera completamente silencioso, y pudimos calcularlo claramente. Y - entrenaron a la red neuronal para predecir estos vectores.
¿Qué obtuvimos al final? Una red que puede tomar cualquier pista y predecir su vector SVD. Tenemos una solución muy simple que funciona muy bien.
Quiero mostrar un ejemplo de un par de pistas que sacamos. Una de estas pistas es bastante popular, y su vector SVD podría reconocerse con bastante precisión, y la segunda es muy impopular. Quiero sugerir adivinar cuál de estas pistas es menos popular y cuál es más popular.
Primera pista:
Segunda pista:
La respuesta
La primera pista es más popular. Si observa el número de oyentes que conocían esta pista y pudieron encontrarla ellos mismos, sin la ayuda de recomendaciones, entonces la primera pista podría ser encontrada por más de 1000 usuarios, y la segunda, solo 10. Y cómo aplicamos nuestra tecnología, no pudimos incluso trate de recomendar esta pista, porque no había nada a lo que aferrarse para obtener recomendaciones. Solo podríamos ofrecerlo a estos 10 usuarios.
Cuando aplicamos esto en producción, obtuvimos muchos comentarios excelentes. Una de las listas de reproducción, "Deja Vu", donde tenemos que insertar pistas que el usuario no escuchó, organizar el descubrimiento para el usuario, ha mejorado significativamente después de que pudimos aplicar esta tecnología.
Por supuesto, aplicamos esto al ingresar a nuevos países y también recibimos muchas críticas positivas. Señalaron que las listas de reproducción saben cómo personalizar bien. Además, los editores en Israel estaban bastante sorprendidos de que el servicio ruso en Israel no recomiende artistas rusos en grandes cantidades, sino música local y música internacional.

Sobre los números que logramos alcanzar. Lo que es más importante, queríamos lograr la cantidad de nuevos productos para los usuarios en la transmisión de audio, para que fuera más diversa. , . , : . . . 1,5% . , . , - , , . , , .
: . , , , . . Gracias por su atencion