Durante los últimos 7 años, junto con el equipo, he estado apoyando y desarrollando el núcleo del producto Miro (ex-RealtimeBoard): interacción cliente-servidor y clúster, trabajando con la base de datos.
Tenemos Java con diferentes bibliotecas a bordo. Todo se inicia fuera del contenedor, a través del complemento Maven. Se basa en la plataforma de nuestros socios, lo que nos permite trabajar con la base de datos y los flujos, gestionar la interacción cliente-servidor, etc. DB - Redis y PostgreSQL (mi colega
escribió sobre cómo nos movemos de una base de datos a otra ).
En términos de lógica de negocios, la aplicación contiene:
- trabajar con tableros personalizados y su contenido;
- funcionalidad para el registro de usuarios, creación y gestión de juntas;
- generador de recursos personalizados. Por ejemplo, optimiza las imágenes grandes cargadas en la aplicación para que no disminuyan la velocidad de nuestros clientes;
- Muchas integraciones con servicios de terceros.
En 2011, cuando recién comenzábamos, todo el Miro estaba en el mismo servidor. Todo estaba en él: Nginx en el que se convirtió php para un sitio, una aplicación Java y bases de datos.
El producto desarrollado, la cantidad de usuarios y el contenido que agregaron a las placas aumentaron, por lo que también aumentó la carga en el servidor. Debido a la gran cantidad de aplicaciones en nuestro servidor, en ese momento no podíamos entender qué da exactamente la carga y, en consecuencia, no podíamos optimizarla. Para solucionar esto, distribuimos todo a diferentes servidores y obtuvimos un servidor web, un servidor con nuestro servidor de aplicaciones y bases de datos.
Desafortunadamente, después de algún tiempo, los problemas surgieron nuevamente, ya que la carga en la aplicación continuó creciendo. Luego pensamos en cómo escalar la infraestructura.

A continuación, hablaré sobre las dificultades que encontramos al desarrollar clústeres y escalar aplicaciones e infraestructura Java.
Escalar la infraestructura horizontalmente
Comenzamos recopilando métricas: el uso de la memoria y la CPU, el tiempo que lleva ejecutar las consultas de los usuarios, el uso de los recursos del sistema y el trabajo con la base de datos. A partir de las métricas, estaba claro que la generación de recursos del usuario era un proceso impredecible. Podemos cargar el procesador al 100% y esperar decenas de segundos hasta que todo esté listo. Las solicitudes de los usuarios para tableros también a veces dieron una carga inesperada. Por ejemplo, cuando un usuario selecciona mil widgets y comienza a moverlos espontáneamente.
Comenzamos a pensar en cómo escalar estas partes del sistema y llegamos a soluciones obvias.
Escale el trabajo con tableros y contenido . El usuario abre el tablero de esta manera: el usuario abre el cliente → indica qué tablero quiere abrir → se conecta al servidor → se crea una transmisión en el servidor → todos los usuarios de este tablero se conectan a un flujo → cualquier cambio o creación del widget ocurre dentro de este flujo. Resulta que todo el trabajo con la placa está estrictamente limitado por el flujo, lo que significa que podemos distribuir estos flujos entre los servidores.
Escalar la generación de recursos del usuario . Podemos sacar el servidor para generar recursos por separado, y recibirá mensajes para la generación, y luego responderá que todo se genera.
Todo parece ser simple. Pero tan pronto como comenzamos a estudiar este tema más profundamente, resultó que necesitábamos resolver adicionalmente algunos problemas indirectos. Por ejemplo, si los usuarios expiran una suscripción paga, entonces debemos notificarles esto, sin importar en qué tablero estén. O bien, si el usuario ha actualizado la versión del recurso, debe asegurarse de que la memoria caché se vacíe correctamente en todos los servidores y le proporcionemos la versión correcta.
Hemos identificado los requisitos del sistema. El siguiente paso es entender cómo poner esto en práctica. De hecho, necesitábamos un sistema que permitiera a los servidores en el clúster comunicarse entre sí y en base al cual realizaríamos todas nuestras ideas.
El primer grupo fuera de la caja
No seleccionamos la primera versión del sistema, porque ya estaba parcialmente implementado en la plataforma asociada que usamos. En él, todos los servidores estaban conectados entre sí a través de TCP, y usando esta conexión podríamos enviar mensajes RPC a uno o todos los servidores a la vez.
Por ejemplo, tenemos tres servidores, están conectados entre sí a través de TCP, y en Redis tenemos una lista de estos servidores. Iniciamos un nuevo servidor en el clúster → se agrega a la lista en Redis → lee la lista para conocer todos los servidores en el clúster → se conecta a todos.
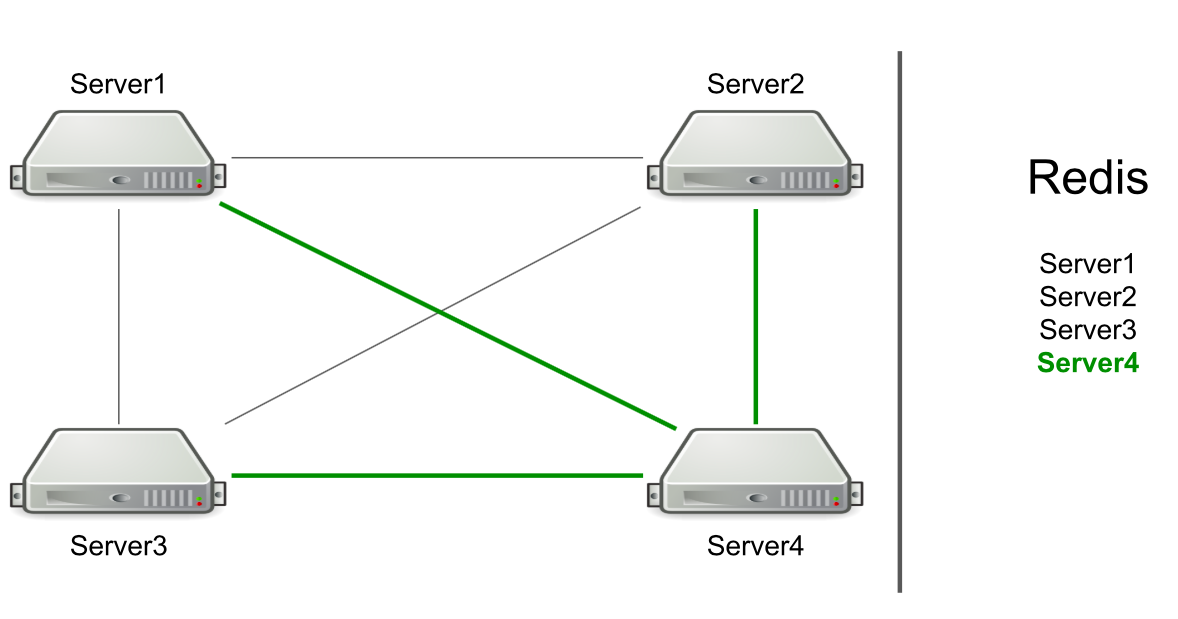
Basado en RPC, el soporte para vaciar la caché y redirigir a los usuarios al servidor deseado ya se ha implementado. Tuvimos que hacer una generación de recursos de usuario y notificar a los usuarios que algo había sucedido (por ejemplo, una cuenta había caducado). Para generar recursos, elegimos un servidor arbitrario y le enviamos una solicitud de generación, y para las notificaciones sobre el vencimiento de una suscripción, enviamos un comando a todos los servidores con la esperanza de que el mensaje alcanzara el objetivo.
El servidor mismo determina a quién enviar el mensaje.
Suena como una característica, no un problema. Pero el servidor se centra solo en la conexión a otro servidor. Si hay conexiones, entonces hay un candidato para enviar un mensaje.
El problema es que el servidor número 1 no sabe que el servidor número 4 está bajo una carga alta en este momento y no puede responderlo lo suficientemente rápido. Como resultado, las solicitudes del servidor n. ° 1 se procesan más lentamente de lo que podrían.
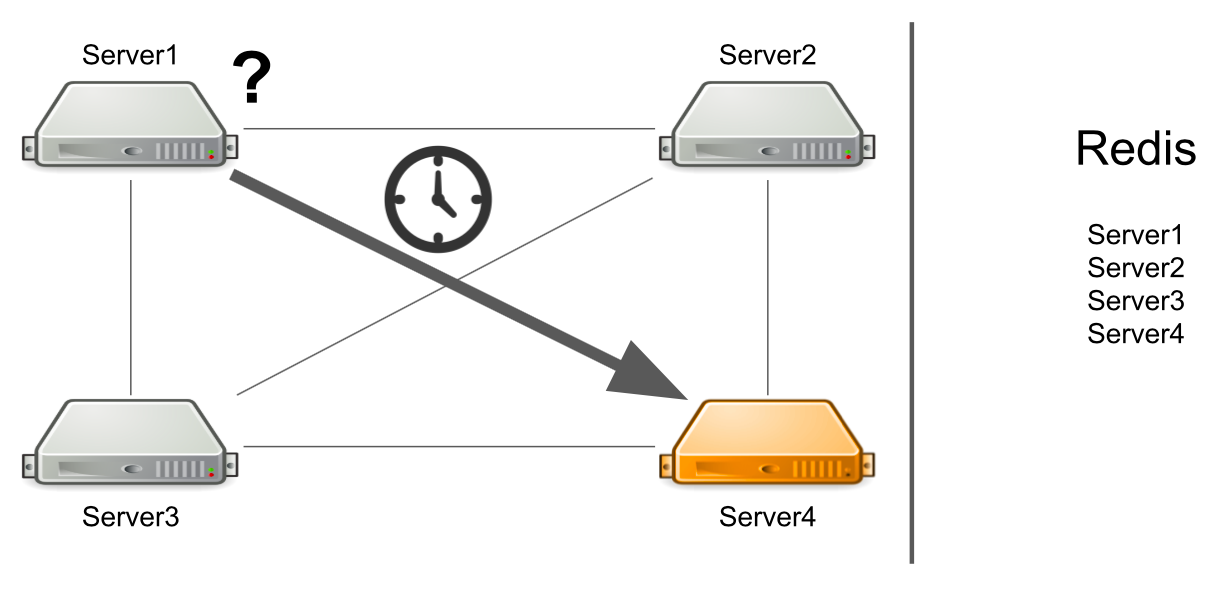
El servidor no sabe que el segundo servidor está congelado
Pero, ¿qué sucede si el servidor no solo está muy cargado, sino que generalmente se congela? Además, se cuelga para que ya no cobre vida. Por ejemplo, he agotado toda la memoria disponible.
En este caso, el servidor n. ° 1 no sabe cuál es el problema, por lo que continúa esperando una respuesta. Los servidores restantes en el clúster tampoco conocen la situación con el servidor número 4, por lo que enviarán muchos mensajes al servidor número 4 y esperarán una respuesta. Así será hasta que muera el servidor número 4.
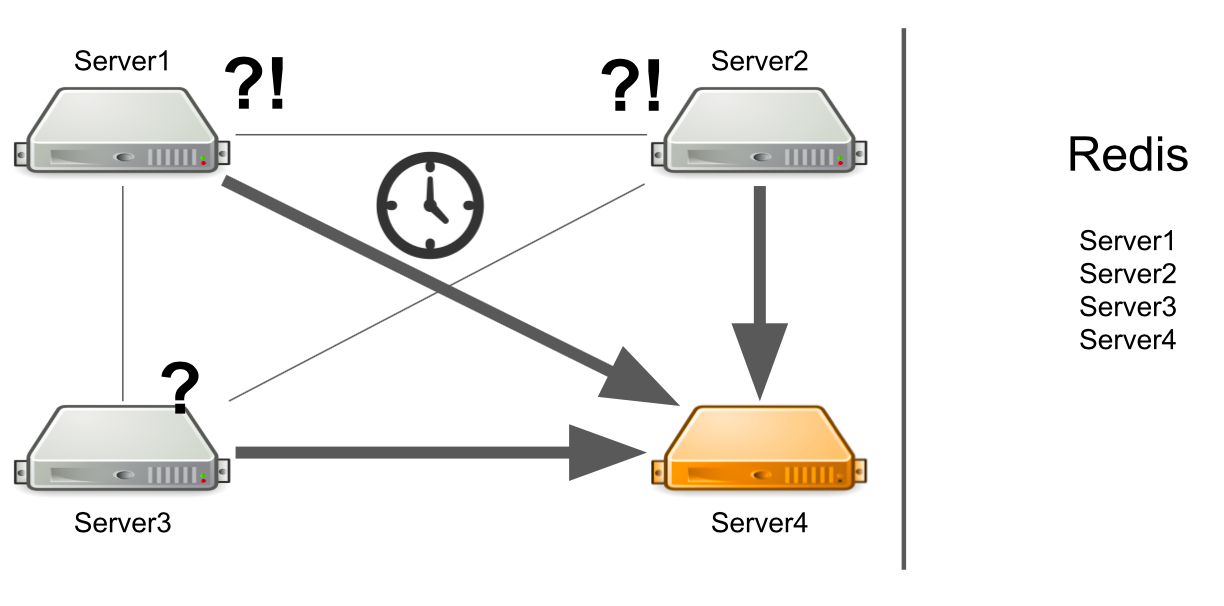
Que hacer Podemos agregar independientemente una verificación de estado del servidor al sistema. O podemos redirigir mensajes de servidores "enfermos" a servidores "sanos". Todo esto llevará demasiado tiempo a los desarrolladores. En 2012, teníamos poca experiencia en esta área, por lo que comenzamos a buscar soluciones listas para todos nuestros problemas a la vez.
Intermediario de mensajes. Activemq
Decidimos ir en la dirección de Message Broker para configurar correctamente la comunicación entre servidores. Eligieron ActiveMQ debido a la capacidad de configurar la recepción de mensajes en el consumidor en un momento determinado. Es cierto que nunca aprovechamos esta oportunidad, por lo que podríamos elegir RabbitMQ, por ejemplo.
Como resultado, transferimos todo nuestro sistema de clúster a ActiveMQ. ¿Qué dio?
- El servidor ya no determina por sí mismo a quién se envía el mensaje, porque todos los mensajes pasan por la cola.
- Configuración de tolerancia a fallos. Para leer la cola, puede ejecutar no uno, sino varios servidores. Incluso si uno de ellos cae, el sistema continuará funcionando.
- Los servidores aparecieron roles, lo que permitió dividir el servidor por tipo de carga. Por ejemplo, un generador de recursos solo puede conectarse a una cola para leer mensajes para generar recursos, y un servidor con placas puede conectarse a una cola para abrir placas.
- Hizo comunicación RPC, es decir cada servidor tiene su propia cola privada, donde otros servidores le envían eventos.
- Puede enviar mensajes a todos los servidores a través del Tema, que usamos para restablecer las suscripciones.
El esquema parece simple: todos los servidores están conectados al intermediario y gestiona la comunicación entre ellos. Todo funciona, se envían y reciben mensajes, se crean recursos. Pero hay nuevos problemas.
¿Qué hacer cuando todos los servidores necesarios están mintiendo?
Digamos que el servidor n. ° 3 quiere enviar un mensaje para generar recursos en una cola. Espera que su mensaje sea procesado. Pero él no sabe que por alguna razón no hay un solo destinatario del mensaje. Por ejemplo, los destinatarios se bloquearon debido a un error.
Durante todo el tiempo de espera, el servidor envía muchos mensajes con una solicitud, por lo que aparece una cola de mensajes. Por lo tanto, cuando aparecen servidores en funcionamiento, se ven obligados a procesar primero la cola acumulada, lo que lleva tiempo. Por parte del usuario, esto lleva al hecho de que la imagen cargada por él no aparece de inmediato. No está listo para esperar, por lo que deja el tablero.
Como resultado, gastamos la capacidad del servidor en la generación de recursos, y nadie necesita el resultado.
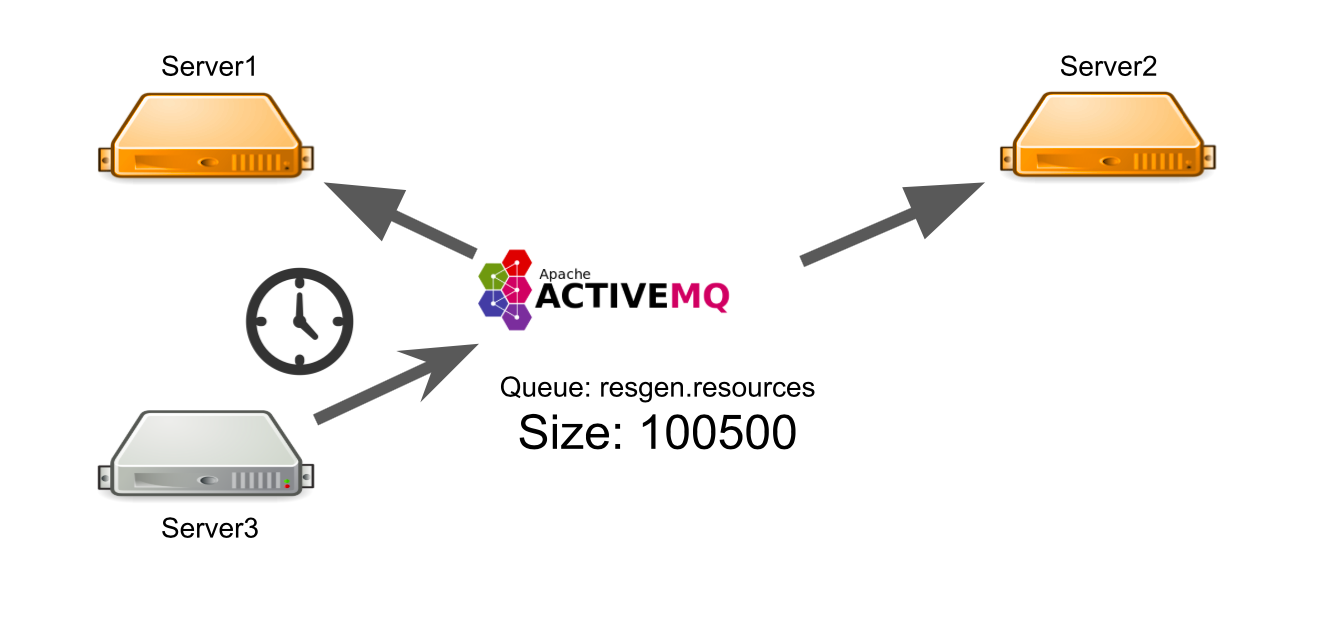
¿Cómo puedo resolver el problema? Podemos configurar el monitoreo, que le notificará lo que está sucediendo. Pero desde el momento en que el monitoreo informa algo, hasta el momento en que comprendemos que nuestros servidores son malos, el tiempo pasará. Esto no nos conviene.
Otra opción es ejecutar Service Discovery, o un registro de servicios que sepa qué servidores con qué roles se están ejecutando. En este caso, recibiremos inmediatamente un mensaje de error si no hay servidores libres.
Algunos servicios no se pueden escalar horizontalmente
Este es un problema de nuestro código inicial, no de ActiveMQ. Déjame mostrarte un ejemplo:
Permission ownerPermission = service.getOwnerPermission(board); Permission permission = service.getPermission(board,user); ownerPermission.setRole(EDITOR); permission.setRole(OWNER);
Tenemos un servicio para trabajar con derechos de usuario en la pizarra: el usuario puede ser el propietario de la pizarra o su editor. Solo puede haber un propietario en el tablero. Supongamos que tenemos un escenario en el que queremos transferir la propiedad de una placa de un usuario a otro. En la primera línea tenemos al propietario actual del tablero, en la segunda, tomamos al usuario que fue el editor, y ahora se convierte en el propietario. Además, al propietario actual le asignamos el rol de EDITOR, y al antiguo editor, el rol de PROPIETARIO.
Veamos cómo funcionará esto en un entorno multiproceso. Cuando el primer subproceso establece la función EDITOR, y el segundo subproceso intenta tomar el PROPIETARIO actual, puede suceder que el PROPIETARIO no exista, pero hay dos EDITORES.
La razón es la falta de sincronización. Podemos resolver el problema agregando un bloque de sincronización en el tablero.
synchronized (board) { Permission ownerPermission = service.getOwnerPermission(board); Permission permission = service.getPermission(board,user); ownerPermission.setRole(EDITOR); permission.setRole(OWNER); }
Esta solución no funcionará en el clúster. La base de datos SQL podría ayudarnos con esto con la ayuda de las transacciones. Pero tenemos a Redis.
Otra solución es agregar bloqueos distribuidos al clúster para que la sincronización esté dentro de todo el clúster y no solo en un servidor.
Un solo punto de falla al ingresar al tablero
El modelo de interacción entre el cliente y el servidor es con estado. Por lo tanto, debemos almacenar el estado de la placa en el servidor. Por lo tanto, hicimos una función separada para los servidores: BoardServer, que maneja las solicitudes de los usuarios relacionadas con las placas.
Imagine que tenemos tres BoardServer, uno de los cuales es el principal. El usuario le envía una solicitud "Ábreme la placa con id = 123" → el servidor busca en su base de datos si la placa está abierta y en qué servidor se encuentra. En este ejemplo, el tablero está abierto.
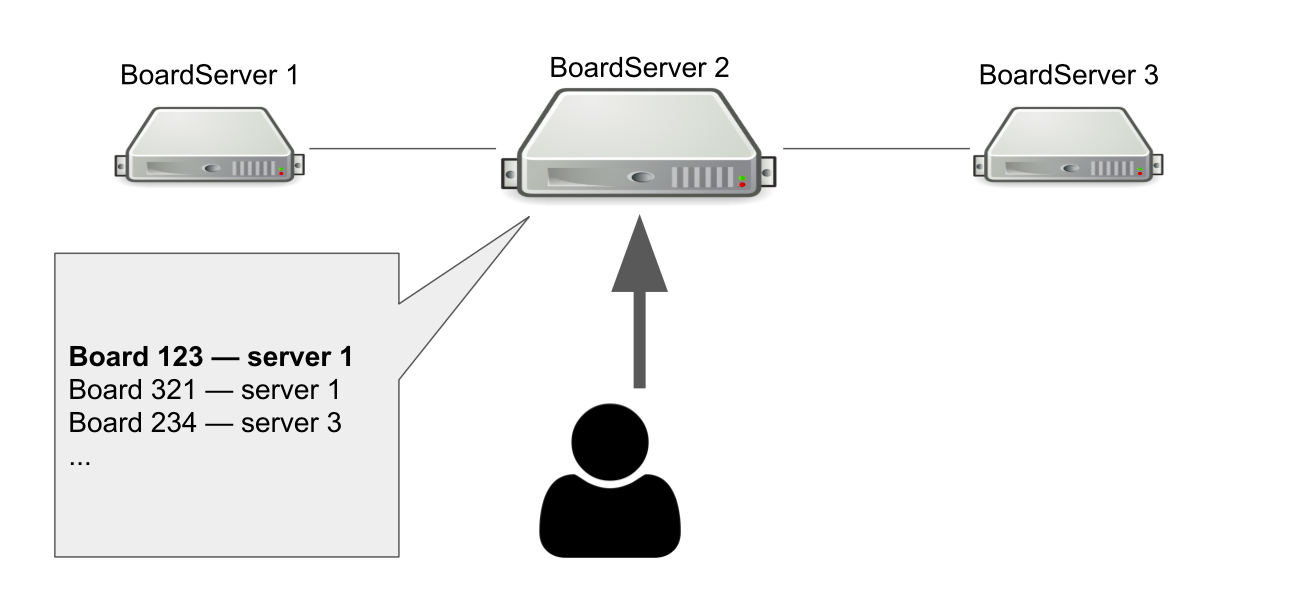
El servidor principal responde que necesita conectarse al servidor No. 1 → el usuario se está conectando. Obviamente, si el servidor principal muere, el usuario ya no podrá acceder a nuevas placas.
Entonces, ¿por qué necesitamos un servidor que sepa dónde están abiertas las placas? Para que tengamos un único punto de decisión. Si algo le sucede a los servidores, debemos entender si la placa está realmente disponible para eliminarla del registro o volver a abrirla en otro lugar. Sería posible organizar esto con la ayuda de un quórum, cuando varios servidores resuelven un problema similar, pero en ese momento no teníamos el conocimiento para implementar el quórum de forma independiente.
Cambiar a Hazelcast
De una forma u otra, enfrentamos los problemas que surgieron, pero puede que no sea la forma más hermosa. Ahora necesitábamos comprender cómo resolverlos correctamente, por lo que formulamos una lista de requisitos para una nueva solución de clúster:
- Necesitamos algo que monitoree el estado de todos los servidores y sus roles. Llámalo Service Discovery.
- Necesitamos bloqueos de clúster que ayudarán a garantizar la coherencia al ejecutar consultas peligrosas.
- Necesitamos una estructura de datos distribuidos que garantice que las placas estén en ciertos servidores e informe si algo salió mal.
Era el año 2015. Optamos por Hazelcast - In-Memory Data Grid, un sistema de clúster para almacenar información en la RAM. Luego pensamos que habíamos encontrado una solución milagrosa, el santo grial del mundo de la interacción de clúster, un marco milagroso que puede hacer todo y combina estructuras de datos distribuidos, bloqueos, mensajes RPC y colas.
Al igual que con ActiveMQ, transferimos casi todo a Hazelcast:
- generación de recursos de usuario a través de ExecutorService;
- bloqueo distribuido cuando se cambian los derechos;
- roles y atributos de los servidores (Service Discovery);
- un registro único de tableros abiertos, etc.
Topologías Hazelcast
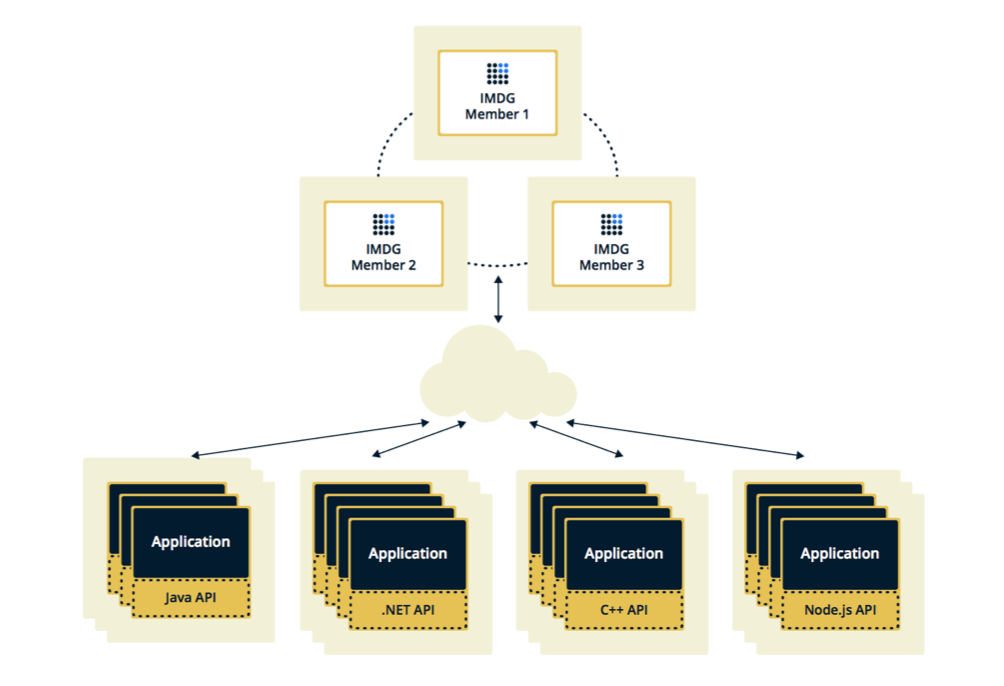
Hazelcast se puede configurar en dos topologías. La primera opción es Cliente-Servidor, cuando los miembros se ubican por separado de la aplicación principal, ellos mismos forman un clúster y todas las aplicaciones se conectan a ellos como una base de datos.
La segunda topología es Embebido, cuando los miembros de Hazelcast están incrustados en la aplicación misma. En este caso, podemos usar menos instancias, el acceso a los datos es más rápido, porque los datos y la lógica de negocios en sí están en el mismo lugar.
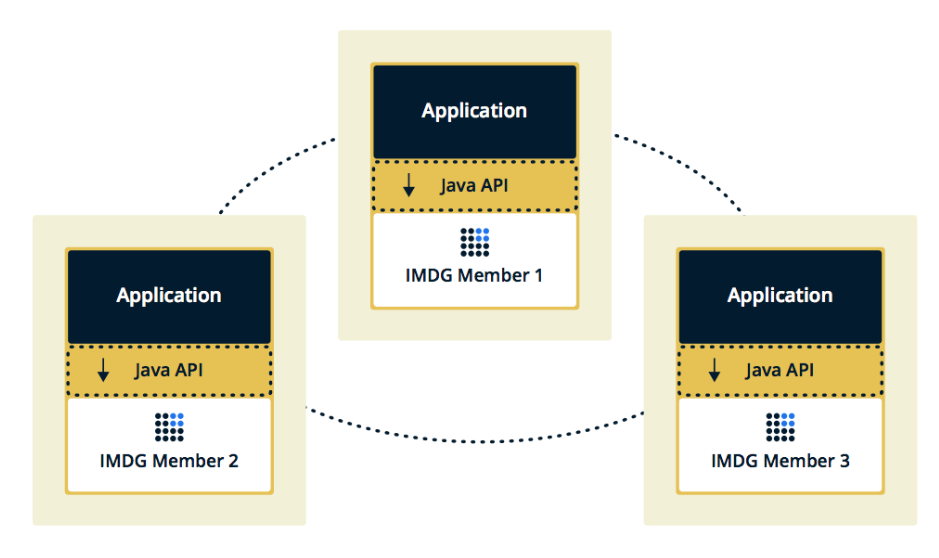
Elegimos la segunda solución porque la consideramos más efectiva y económica de implementar. Efectivo, porque la velocidad de acceso a los datos de Hazelcast será menor, porque tal vez estos datos estén en el servidor actual. Económico, porque no necesitamos gastar dinero en instancias adicionales.
El clúster se cuelga cuando el miembro se cuelga
Un par de semanas después de encender Hazelcast, aparecieron problemas en el producto.
Al principio, nuestro monitoreo mostró que uno de los servidores comenzó a sobrecargar gradualmente la memoria. Mientras observamos este servidor, el resto de los servidores también comenzaron a cargarse: la CPU creció, luego la RAM y, después de cinco minutos, todos los servidores usaron toda la memoria disponible.
En este punto en las consolas vimos estos mensajes:
2015-07-15 15:35:51,466 [WARN] (cached18) com.hazelcast.spi.impl.operationservice.impl.Invocation: [my.host.address.com]:5701 [dev] [3.5] Asking ifoperation execution has been started: com.hazelcast.spi.impl.operationservice.impl.IsStillRunningService$InvokeIsStillRunningOperationRunnable@6d4274d7 2015-07-15 15:35:51,467 [WARN] (hz._hzInstance_1_dev.async.thread-3) com.hazelcast.spi.impl.operationservice.impl.Invocation:[my.host.address.com]:5701 [dev] [3.5] 'is-executing': true -> Invocation{ serviceName='hz:impl:executorService', op=com.hazelcast.executor.impl.operations.MemberCallableTaskOperation{serviceName='null', partitionId=-1, callId=18062, invocationTime=1436974430783, waitTimeout=-1,callTimeout=60000}, partitionId=-1, replicaIndex=0, tryCount=250, tryPauseMillis=500, invokeCount=1, callTimeout=60000,target=Address[my.host2.address.com]:5701, backupsExpected=0, backupsCompleted=0}
Aquí, Hazelcast verifica si la operación que se envió al primer servidor "moribundo" está en progreso. Hazelcast intentó mantenerse al día y verificó el estado de la operación varias veces por segundo. Como resultado, envió spam a todos los demás servidores con esta operación, y después de unos minutos se quedaron sin memoria, y recopilamos varios GB de registros de cada uno de ellos.
La situación se repitió varias veces. Resultó que este es un error en Hazelcast versión 3.5, en la que se implementó el mecanismo de latido, que verifica el estado de las solicitudes. No verificó algunos de los casos límite que encontramos. Tuve que optimizar la aplicación para no caer en estos casos, y después de algunas semanas Hazelcast corrigió el error en casa.
Agregar y eliminar miembros de Hazelcast con frecuencia
El siguiente problema que descubrimos es agregar y eliminar miembros de Hazelcast.
Primero, describiré brevemente cómo funciona Hazelcast con particiones. Por ejemplo, hay cuatro servidores, y cada uno almacena una parte de los datos (en la figura, son de diferentes colores). La unidad es la partición primaria, el deuce es la partición secundaria, es decir copia de seguridad de la partición principal.

Cuando un servidor está apagado, las particiones se envían a otros servidores. En caso de que el servidor muera, las particiones se transfieren no desde él, sino desde aquellos servidores que aún están vivos y que tienen una copia de seguridad de estas particiones.
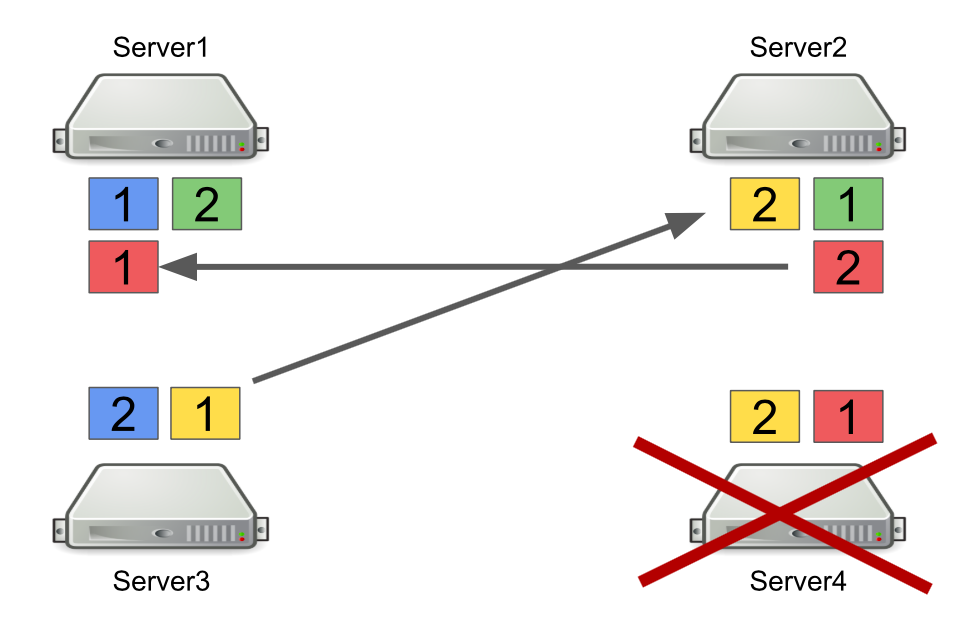
Este es un mecanismo confiable. El problema es que a menudo encendemos y apagamos los servidores para equilibrar la carga, y reequilibrar las particiones también lleva tiempo. Y mientras más servidores se estén ejecutando y cuantos más datos almacenemos en Hazelcast, más tiempo llevará volver a equilibrar las particiones.
Por supuesto, podemos reducir la cantidad de copias de seguridad, es decir particiones secundarias. Pero esto no es seguro, ya que definitivamente algo saldrá mal.
Otra solución es cambiar a la topología Cliente-Servidor para que el encendido y apagado de los servidores no afecte al clúster principal de Hazelcast. Intentamos hacer esto, y resultó que las solicitudes RPC no se pueden realizar en los clientes. A ver por qué.
Para hacer esto, considere el ejemplo de enviar una solicitud RPC a otro servidor. Tomamos el ExecutorService, que le permite enviar mensajes RPC y enviarlos con una nueva tarea.
hazelcastInstance .getExecutorService(...) .submit(new Task(), ...);
La tarea en sí parece una clase Java normal que implementa Callable.
public class Task implements Callable<Long> { @Override public Long call() { return 42; } }
El problema es que los clientes Hazelcast pueden ser no solo aplicaciones Java, sino también aplicaciones C ++, .NET y otras. Naturalmente, no podemos generar y convertir nuestra clase Java a otra plataforma.
Una opción es cambiar al uso de solicitudes http en caso de que queramos enviar algo de un servidor a otro y obtener una respuesta. Pero luego tendremos que abandonar parcialmente Hazelcast.
Por lo tanto, como solución, elegimos usar colas en lugar de ExecutorService. Para hacer esto, implementamos independientemente un mecanismo para esperar a que un elemento se ejecute en la cola, que procesa casos límite y devuelve el resultado al servidor solicitante.
Que hemos aprendido
Lay flexibilidad en el sistema. El futuro cambia constantemente, por lo que no hay soluciones perfectas. Hacerlo bien "correcto" no funciona, pero puede intentar ser flexible e incorporarlo al sistema. Esto nos permitió posponer decisiones arquitectónicas importantes hasta el momento en que ya no es imposible aceptarlas.
Robert Martin en Clean Architecture escribe sobre este principio:
“El objetivo del arquitecto es crear un formulario para el sistema que haga de la política el elemento más importante y los detalles no relacionados con la política. Esto retrasará y retrasará las decisiones sobre los detalles ".
Las herramientas y soluciones universales no existen. Si le parece que algún marco resuelve todos sus problemas, lo más probable es que no sea así. Por lo tanto, al implementar cualquier marco, es importante comprender no solo qué problemas resolverá, sino cuáles traerá consigo.
No reescribas todo de inmediato. Si se enfrenta a un problema en la arquitectura y parece que la única solución correcta es escribir todo desde cero, espere. Si el problema es realmente grave, encuentre una solución rápida y observe cómo funcionará el sistema en el futuro. Lo más probable es que este no sea el único problema en arquitectura, con el tiempo encontrará más. Y solo cuando recoja un número suficiente de áreas problemáticas puede comenzar a refactorizar. Solo en este caso habrá más ventajas que su valor.