La principal ventaja en el mercado de IoT es el costo. Por lo tanto, se da prioridad a los componentes baratos pero poco confiables. Los dispositivos no confiables se rompen, cometen errores, se congelan y requieren mantenimiento. No es costumbre hablar de falta de fiabilidad en las conferencias, pero esto fue exactamente a lo que se dedicó el informe de
Stanislav Elizarov (
elstas ) en InoThings ++: cómo no funciona todo.

Bajo el corte, discutiremos métodos para compensar la falta de confiabilidad de los equipos, canales de comunicación y personal que utiliza software; problemas de tolerancia a fallas y sus soluciones; factor humano cintas y calcetines eléctricos como un medio universal para reparar naves espaciales y la transmisión de datos en camiones.
Acerca del orador :
Stanislav Elizarov está involucrado en el departamento de infraestructura de red de la compañía STRIZH, que produce medidores, sensores, estaciones base LTE y también recopila lecturas donde cualquier otro sistema de comunicación simplemente no funciona.
Inseguridad
"Si algo no funciona, entonces ya está desactualizado".
Esta es una cita del filósofo canadiense
Marshall McLuhan , que describe con precisión el estado del arte. Todo se niega: las computadoras se congelan, los teléfonos inteligentes se ralentizan, los ascensores se detienen entre pisos, las sondas espaciales se descarrían y la gente comete errores.
Primeros errores
El tema de la confiabilidad, especialmente su parte, es la tolerancia a fallas, tan grande como la seguridad. La letra S en el término IoT es responsable de la
seguridad , y la letra R es responsable de la
confiabilidad - confiabilidad.
Si hablamos de fiabilidad y errores, recordemos a
Johann Gutenberg . Oficialmente, él es la primera impresora, y según Ilf y Petrov, es la
primera impresora , porque cometió muchos errores en su Biblia.

La tecnología de Gutenberg ha progresado, el mercado del libro ha crecido, los volúmenes han aumentado y, con ellos, los errores. 50 años después de que se imprimiera el primer libro, a
Gabriel Pierry se le ocurrió Errata, una lista de errores tipográficos al final del libro. Fue un buen truco, porque volver a escribir lotes grandes es inconveniente y económicamente no rentable. Si el lector nota un error tipográfico, simplemente abre una lista de errores y analiza las correcciones críticas. El líder de los errores tipográficos fue Tomás de Aquino y su suma de teología: 180 páginas de errores en la errata oficial.
Las erratas modernas son producidas por productores de hierro. En la imagen a continuación, la
errata oficial del chip
CC1101 más popular, que aún es válida. En la lista de errores, el chip a veces no acepta algo, a veces transmite algo incorrecto y, a veces, el PLL no siempre funciona. Esto no es lo que espera de un procesador masivo que ha existido durante décadas.

Otro ejemplo es el microprocesador
MSP430 , basado en un conjunto de instrucciones. El microprocesador es casi el mismo que el
PDP-11 , en el que Kernigan y Ritchie desarrollaron Unix. Este no es el Errat Thomas Aquinas, pero el fabricante nos ofrece
27 páginas de errores , muchos de los cuales incluso él mismo no sabe cómo resolver.
Esto es exactamente lo que no es obvio en Internet de las cosas. Leemos la hoja de datos de un chip barato y vemos que todo está bien y todo funciona, hasta que abrimos las últimas páginas con una lista de errores.

Factor humano
Con el hierro, es más o menos claro, los errores se describen y reproducen, pero la mayor fuente de errores en los sistemas IoT es el
hombre .
El 13 de enero de 2018, todos los residentes de Gavaev
recibieron una alerta en los teléfonos móviles
sobre una amenaza de misiles y que necesitaban esconderse en un refugio antiaéreo.

No está claro quién estaba exactamente equivocado: el operador o la persona que diseñó la interfaz. Pero si miras la imagen, la respuesta se sugiere. ¿Qué presionar para desencadenar una prueba, en lugar de combatir, advirtiendo sobre una amenaza de misil? Si no sabe la respuesta, está equivocado.

Respuesta correctaBMD False Alarm
El operador presionó el botón equivocado y comenzó el envío masivo. El sistema no tenía ningún parámetro por el cual sería posible prevenir o confirmar el envío: "¿Está seguro de que desea advertir sobre la amenaza de misiles?" Los empleados del centro tardaron 30 minutos en darse cuenta de lo sucedido y enviar un mensaje que indicaba que el ataque era falso.
El hombre es un sistema confiable.
¿Por qué no vemos estos errores y no pensamos que algo está mal? Porque el hombre mismo corrige todos los errores.
Estamos acostumbrados a corregir errores.
Si consideramos que la computadora no funciona muy bien, la reiniciaremos. Si vemos que la comunicación móvil ha desaparecido, entonces estamos buscando un lugar donde se capture. Si la máquina no funciona, la reparamos.
La foto a continuación muestra una comprensión humana de la que puedes estar orgulloso. Tres personas colgaban en
el Apolo 13 entre la Tierra y la Luna y pudieron resolver la tarea no trivial de meter un filtro cuadrado en un agujero redondo. Además de los filtros cuadrados, la misión tuvo mala suerte en otra: una explosión de cilindro de oxígeno, falta de agua, daños en el motor. El equipo intentó sobrevivir con la ayuda de calcetines, cinta aislante y paquetes de trajes.

El hombre, como dijeron en la NASA, es un muy buen sistema de respaldo y repara mucho. Resolver problemas en una nave espacial con cinta aislante y calcetines puede llamarse casi confiable: se realiza en poco tiempo, funcionará con garantía y la gente volverá con vida, pero no se puede permitir que entre en producción.
Problema de tolerancia a fallas
El problema de la tolerancia a fallas para Internet de las cosas es muy importante porque la cantidad de dispositivos está creciendo. Según una empresa de consultoría
McKinsey , en 2013, 10 mil millones de dispositivos IoT estaban operando en el mundo, y para 2020 este número aumentará a 30 mil millones.

Simplemente no podemos reparar físicamente todos estos contadores, simplemente no habrá suficiente tiempo. Los sistemas que fueron diseñados para ser atendidos por personas no nos ayudarán; en cambio, los repararemos.
En 2018,
aparecieron noticias en los medios y revistas científicas de que los chinos habían cubierto
100,000 sensores de 2 canales con una longitud total de 1,400 km. Un total de 130 tipos de sensores: agua, viento, cámaras. Desde el punto de vista de los gastos operativos, el sistema es simplemente desastroso: ¿a cuántas personas necesita limpiar las cámaras o eliminar inconvenientes? Todo el personal estará ocupado solo con la limpieza y el mantenimiento del sistema; no es muy autónomo.
Por lo tanto, quiero hablar un poco sobre la
tolerancia a fallas , sobre asegurar el funcionamiento del sistema. Con ejemplos simples, hablaré sobre trucos que ayudarán en poco tiempo a obtener una solución de trabajo garantizada para presentar un producto a los inversores, y luego pensaré en cómo aumentar la confiabilidad de manera incremental. Estos trucos son bastante versátiles y siempre ayudarán. Lo único que no son muy recomendables para su uso en producción, porque son como ese filtro.
Imagínese: llegará el día en que los inversores acudirán a usted para obtener un informe del proyecto, y deberá mostrar un producto que funcione. ¿Por dónde empezar, para no arruinarlo?
Simplificación
En la imagen a continuación hay dos dispositivos desconectados. A la izquierda hay un juguete llamado
"clasificador" : inserte redondo en redondo y cuadrado en cuadrado. Un niño de un año aprenderá a usar un juguete en 2-3 intentos, porque es imposible cometer un error con el "dispositivo": un triángulo no cabe en un cuadrado.

La misma idea fue propuesta por la compañía Harris, que produce estaciones de radio militares. La imagen de la derecha es
Harris Falcon 3 , una maravilla de la ingeniería. Mira las interfaces, todas son diferentes. En un estado de batalla, en condiciones donde no hay tiempo para pensar, el operador físicamente no podrá hacer algo mal. El cable de alimentación no ingresará al conector desde la antena, y por un simple busto, el operador de radio conectará todos los sistemas, incluso sin incluir el cerebro. Esta es una forma simple y funcional de prevenir errores y reducir su probabilidad. Tu dirás:
- Y si tenemos una presentación mañana. ¿Necesitamos soldar todas las interfaces? Allí hicimos todo igual: 4 puertos usb, 5 puertos ethernet, definitivamente cometeremos un error.Sin dudas, la simplificación también funciona aquí: cierre todo. Si tiene 4 puertos usb y uno de ellos está garantizado para funcionar, déjelo y cierre el resto. Por ejemplo, con cinta aislante, siéntete como un astronauta.
La simplificación no solo es crear una interfaz en la que los errores son imposibles, sino también eliminar todo lo superfluo. Aquí es donde comienza la fiabilidad.
Creamos un dispositivo simple: un prototipo, listo para ser mostrado. Que sigue Luego, piense en la redundancia.
Redundancia
Los dispositivos de Internet de las cosas funcionan según la
teoría de la información : hay una fuente de señal, un receptor, un codificador, un modulador, un medio de propagación y una fuente de error que interfiere y distorsiona la situación real. Una buena manera de reducir la interferencia es
agregar redundancia , con la ayuda de la cual podemos detectar una situación crítica y nivelar el efecto de la misma: notificar al operador o corregir el error.

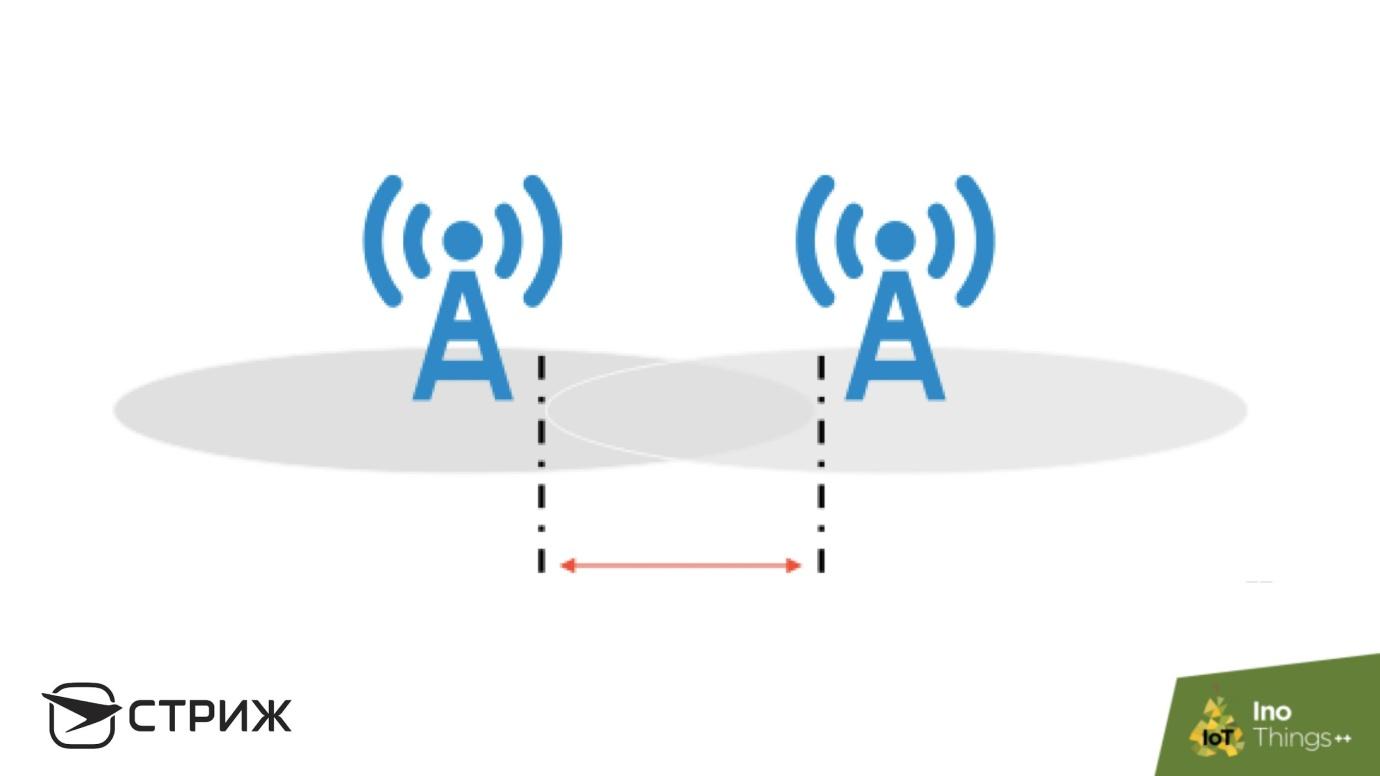
Un ejemplo de redundancia es la red STRIZH. La mayoría de los dispositivos en la red se transmiten sin confirmación: el dispositivo emite una señal y la estación base la recibe.
Imagina la situación. Tenemos una zona de interferencia en la que la probabilidad de entrega de mensajes a la estación base es del 90%, y en la presentación se requiere que no muestre más del 1% de pérdida. Parece que hay mucho trabajo: corregir los protocolos, reducir el rango, pero una solución rápida y simple es la redundancia. Junto a la estación que recibe la señal con una probabilidad de entrega de 0.9, coloque la segunda, con la misma probabilidad de entrega, y la probabilidad de falla de ambas estaciones al mismo tiempo es 0.01. El
teorema de multiplicación de probabilidad se aplica aquí: la probabilidad de falla de cada estación individualmente es 0.1, y la falla de ambas es solo del 1%, siempre que las estaciones base sean independientes. En esta área, habrá la mayor probabilidad de recepción entre estaciones base.
Otra forma de demostrar el principio de redundancia es
Watchdog Timer . Este es un dispositivo físico que está integrado por la mayoría de los fabricantes de procesadores. Si el temporizador de vigilancia no recibió una señal de la computadora después de un cierto período de tiempo, el dispositivo reinicia la computadora.

El uso de WT mejora no la fiabilidad, sino la
disponibilidad . La computadora detecta el problema, toma medidas de control y reinicia la computadora. Es muy aficionado a la NASA y
conoce muchas maneras diferentes de usar Watchdog Timer.
A continuación se muestra un ejemplo de un temporizador de vigilancia de múltiples etapas: cuando ocurren ciertos eventos, envía un
NMI, una interrupción de hardware que será necesaria para trabajar en el procesador. Cuando se produce un evento, Watchdog le dice a la computadora: "Intente reiniciarse, de lo contrario apague la alimentación". Si el primer temporizador no funciona, el segundo funcionará.

La redundancia funciona bien dentro del sistema operativo. Nuestra estación base está estructurada de esta manera. Consta de varios
módulos independientes . La autonomía de los módulos evita errores de un módulo a otro: se crea un "grupo" con errores, que bloqueamos. Más arriba en la jerarquía hay un
conjunto de supervisores : scripts que monitorean la situación de acuerdo con ciertos parámetros. Por ejemplo, que el proceso está en el sistema operativo, no es un zombi y no fluye de la memoria. El elemento raíz es un
planificador , por ejemplo, cron.
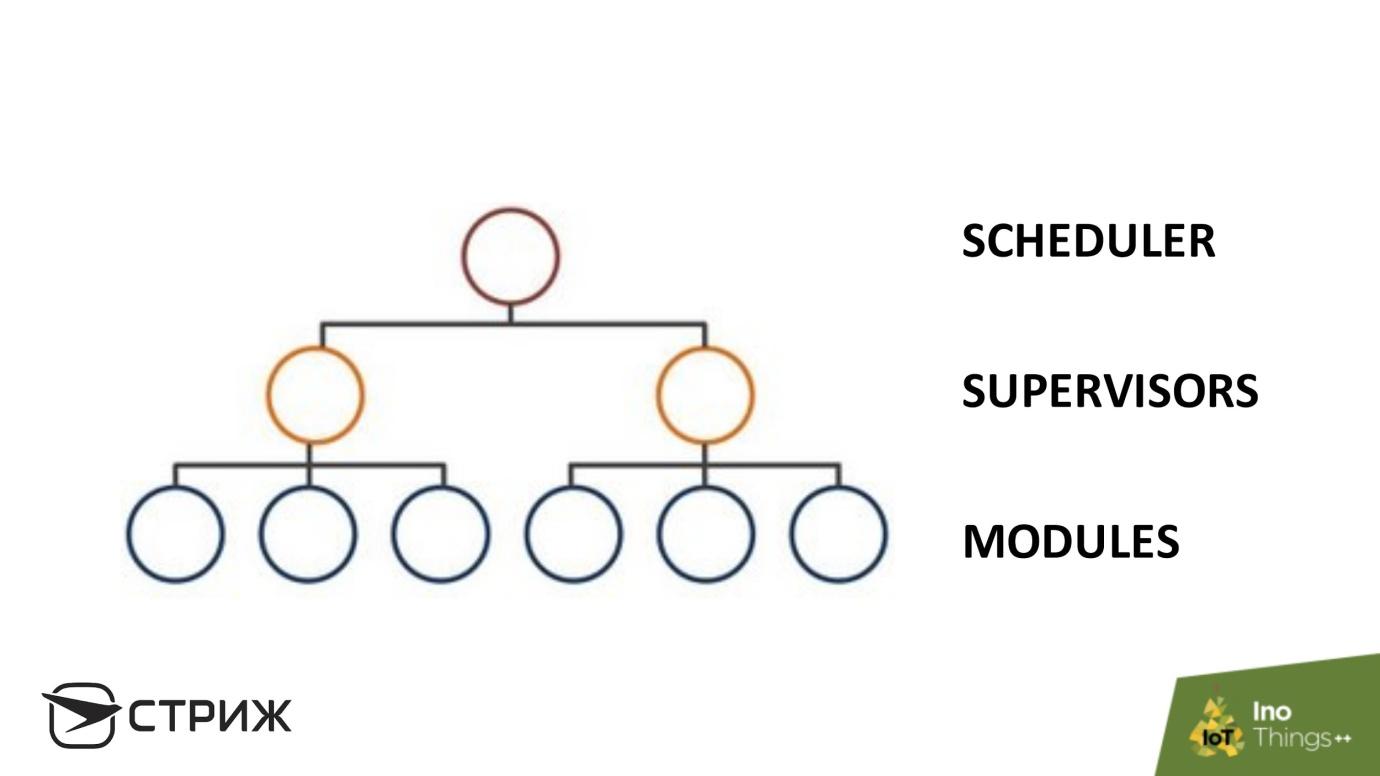
La estructura jerárquica crea buenos parámetros para la disponibilidad del sistema: si el módulo se cae, el supervisor ve y se reinicia, hay cierta redundancia en los módulos, algunos módulos realizan la función de otros.
Transición a otro sistema de referencia.
Mi método favorito y más popular entre los matemáticos. Si se sabe bajo qué condiciones opera el equipo, entonces en estas condiciones es necesario realizar un piloto. Te mostraré con ejemplos.
Ejemplo no 1 . Creamos un dispositivo que funciona bien a temperatura ambiente y nos dicen:
- Demostramos el proyecto en el extremo norte. Ahora hay −40, pero haz que funcione.Nos estamos ejecutando en Internet y estamos buscando una solución:
- Necesitamos unidades de cuarzo termoestables y unidades flash que no fallarán a −40.El tiempo se acaba, los recursos se reducen y hay más pánico. Creemos que el proyecto es un fracaso, pero la transición al sistema de referencia en el que opera la estación base nos salvará. Colocamos el dispositivo en la caja en la que se encuentran el calentador y el relé térmico. Son tipos bastante estables y trabajan casi siempre. Cuando hace frío afuera, la caja se calienta y el dispositivo funciona en condiciones normales, cambiamos a un sistema de referencia en el que conocemos y usamos la solución.
 Ejemplo No. 2
Ejemplo No. 2 . Transición a cuadros en movimiento. Imagine que recopilamos datos de contenedores de un tren. La primera solución estándar es utilizar módems gsm. Este método no es adecuado: para objetos que se mueven rápidamente, debe usar dispositivos LTE o 5G que hagan un buen trabajo con Doppler, lo cual es costoso. Si el tren cruza Rusia, cuando llegue a la estación de ferrocarril, todos los módems se conectarán a la estación y simplemente se bloqueará debido a la congestión de la red.
Solución: transición a un marco de referencia fijo. Recordemos la relatividad del movimiento: colocamos la estación base dentro del tren y está inmóvil en relación con el tren en movimiento. La estación recopilará información de todos los sensores y la transmitirá aún más utilizando una puerta de enlace, satélite o módem LTE.
Este enfoque aumenta la confiabilidad, ayuda a resolver tareas imposibles y organiza una
red tolerante a demoras , una
red que es resistente a las interrupciones . Por alguna razón, no les gusta el enfoque en Rusia, pero están promoviendo activamente la división
Disney Research de la misma corporación. No tienen Internet de las cosas, sino Internet de los juguetes:
Internet de los juguetes . A la compañía le preocupa que los niños africanos no vean dibujos animados de Disney. Llevar a cabo redes de datos, instalar torres, extraer fibra en África es costoso, pero de todos modos lo robarán, por lo que se volcaron y utilizaron
las ideas de
Richard Hamming :
La transmisión remota es lo mismo que la transmisión en el tiempo, es decir, el almacenamiento. Si no puede transmitir, guarde la información y transfiérala al receptor.
Disney
hizo exactamente eso : equiparon las estaciones y autobuses con un sistema de enrutadores Wi-Fi más baratos y un conjunto de discos duros. El autobús se detiene en la estación, sube rápidamente un juego de películas de Disney a través de Wi-Fi a las unidades y continúa. Él viene a un pueblo, a otro, y sube películas en cada uno: los niños africanos están satisfechos. Esto, las llamadas
Mul-Networks , mulas baratas que se mueven lentamente, funcionan mal con Doppler, pero entregan información en todos los puntos.
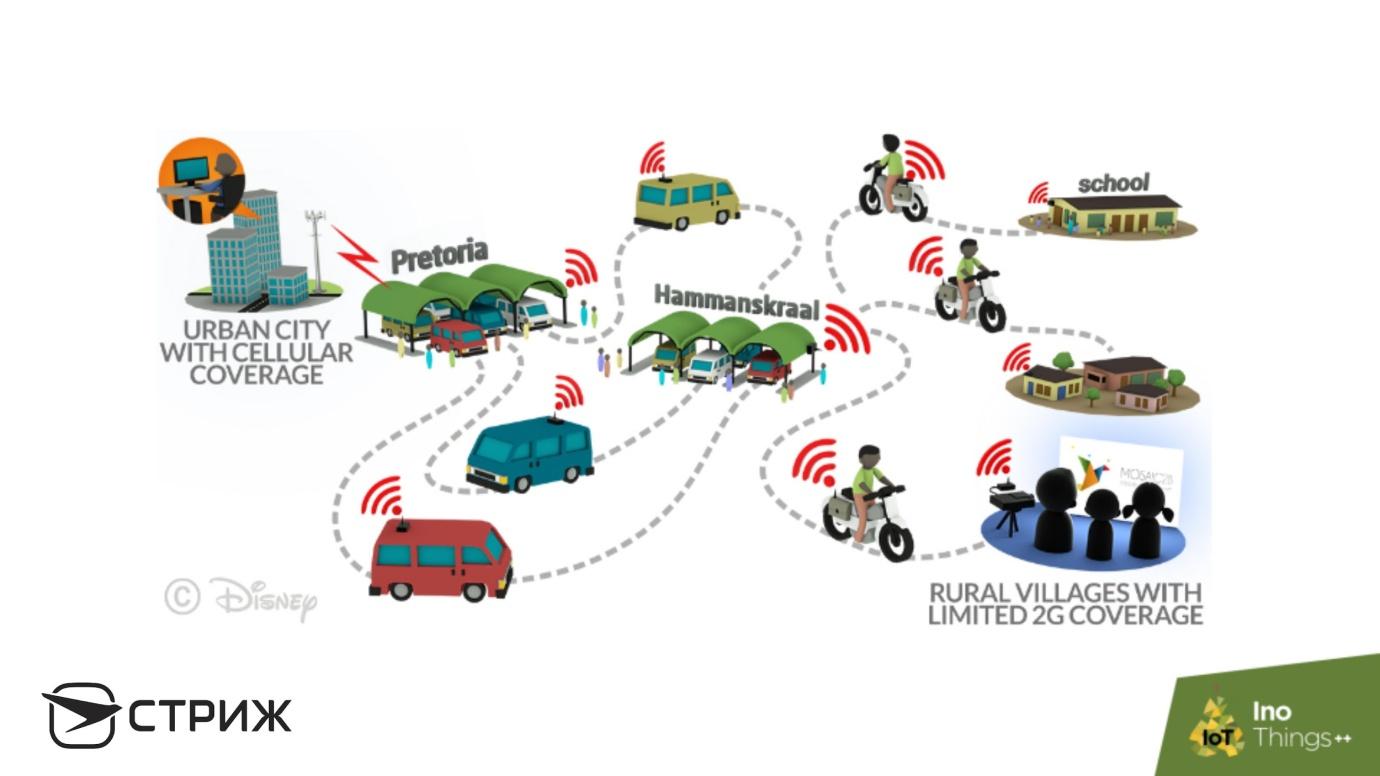
Existen desarrollos similares en Disney para enviar correos electrónicos: una carta le llegará en autobús. Tecnología muy divertida, pero a Amazon, por ejemplo, le encanta.
Amazon tiene un servicio para transportar
exabytes de datos : un millón de terabytes. Si tiene un gran centro de datos y está pensando en mudarse a Amazon, porque todo ya está allí, entonces en Estados Unidos pueden adaptar dicho camión y transportar sus datos. Si los retrasos no son importantes para usted, entonces esta es una buena manera: tasas de transferencia de datos del orden de decenas o cientos de Gb / s. Además de los camiones, Amazon puede enviarle una bolsa con discos duros: bola de nieve.

Nos dimos cuenta de que la confiabilidad es importante porque tanto las personas como la tecnología fallan. La fiabilidad debe considerarse como seguridad. Para presentaciones piloto, active Watchdog, agregue redundancia y simplifique para que no pueda cometer un error. Piense en cómo entrar en condiciones bajo las cuales se garantiza que el sistema funcione. Y ahora pasemos al último método, que es diferente del resto, y los técnicos a menudo lo ignoran.
Belleza
Te perdonarán mucho si tu prototipo se ve hermoso. Si durante la presentación algo sale mal y todo falla, escuchará: “Sí, todo se ha roto, pero tienes un producto tan genial. Creo que debes hacer otro intento para mejorar ". El principio funciona para Tesla: la compañía tiene problemas con el envío, el piloto automático, los accidentes, pero todos los aman, porque los autos tienen un diseño genial. Por esto, todos los perdonan.

Conclusiones
El futuro de Internet de las cosas es la
inseguridad : IoT está dirigido a los mercados de masas, y para el mercado de masas el factor decisivo es el precio. Entonces, la Internet de las cosas consistirá en muchos
dispositivos baratos y poco confiables . Con el creciente número de dispositivos, aumentará el número de fallas. Simplemente no tenemos suficientes manos para corregir todos los errores. Por lo tanto, la única forma: los
dispositivos deben lidiar independientemente con las consecuencias de las fallas . Estos son sistemas autónomos que deben aprender a repararse a sí mismos.
Le sugiero que aborde el tema de la confiabilidad y aprenda a mostrar a los pilotos de una manera genial utilizando tres métodos:
simplifique todo lo que pueda,
agregue redundancia y
cree las condiciones bajo las cuales se garantiza que el piloto funcione. No olvides que todos somos personas y
no nos guiamos por la lógica, sino por los sentimientos , así que crea
hermosos proyectos .
No hay libros o conjunto de artículos sobre confiabilidad. Para profundizar en el tema, comience con un artículo sobre
operabilidad, confiabilidad, seguridad y luego estudie la experiencia
del Laboratorio de Propulsión a Chorro de la NASA . Crearon Voyager y Curiosity y
saben todo sobre confiabilidad . Inspírate con los grandes.
Queda poco más de un mes para la próxima Conferencia de desarrolladores de Internet de las cosas de InoThings ++ , que tendrá lugar el 4 de abril. Prepararemos un programa que cubrirá todos los aspectos del mundo de Internet de las cosas: el desarrollo de hardware y software para dispositivos, seguridad para los usuarios, métodos de transferencia de información entre dispositivos y el "servidor" y sus pruebas, operación y cambio de procesos comerciales bajo la influencia de las tecnologías IoT. Pero quizás su informe no sea suficiente para cubrir todos los temas: envíe su solicitud antes del 1 de marzo.