Hola habr
Después de la publicación de la clasificación de artículos para
2017 y
2018 , la siguiente idea era obvia: recopilar una calificación generalizada para todos los años. Pero solo recopilar enlaces sería trivial (aunque también útil), por lo que se decidió expandir el procesamiento de datos y recopilar información más útil.

Calificaciones, estadísticas y un poco de código fuente en Python debajo del gato.
Procesamiento de datos
Aquellos que estén inmediatamente interesados en los resultados pueden saltarse este capítulo. Mientras tanto, descubriremos cómo funciona.
Como datos de origen, hay un archivo csv de aproximadamente el siguiente tipo:
datetime,link,title,votes,up,down,bookmarks,views,comments 2006-07-13T14:23Z,https://habr.com/ru/post/1/,"Wiki-FAQ ",votes:1,votesplus:1,votesmin:0,bookmarks:8,views:28300,comments:56 2006-07-13T20:45Z,https://habr.com/ru/post/2/," … !",votes:1,votesplus:1,votesmin:0,bookmarks:1,views:14600,comments:37 ... 2019-01-25T03:47Z,https://habr.com/ru/post/435118/,"Save File Me — ",votes:5,votesplus:5,votesmin:0,bookmarks:26,views:1800,comments:6 2019-01-08T03:09Z,https://habr.com/ru/post/435120/,"Lambda- SQL… ",votes:9,votesplus:13,votesmin:4,bookmarks:63,views:5700,comments:30
El índice de todos los artículos en este formulario toma 42 MB, y para recopilarlo se necesitaron unos 10 días para ejecutar el script en la Raspberry Pi (la descarga se realizó en una secuencia con pausas para no sobrecargar el servidor). Ahora veamos qué datos se pueden extraer de todo esto.
Audiencia del sitio
Comencemos con uno relativamente simple: evaluaremos la audiencia del sitio durante todos los años. Para una estimación aproximada, puede usar la cantidad de comentarios en los artículos. Descargue los datos y muestre un gráfico del número de comentarios.
import pandas as pd import matplotlib.pyplot as plt df = pd.read_csv(log_path, sep=',', encoding='utf-8', error_bad_lines=True, quotechar='"', comment='#') def to_int(s):
Los datos se parecen a esto:

El resultado es interesante: resulta que desde 2009 la audiencia activa del sitio (aquellos que dejan comentarios en los artículos) prácticamente no ha crecido. ¿Aunque tal vez todos los empleados de TI están aquí?
Como estamos hablando de la audiencia, es interesante recordar la última innovación de Habr: la adición de una versión en inglés del sitio. Enumere los artículos con "/ en /" dentro del enlace.
df = df[df['link'].str.contains("/en/")]
El resultado también es interesante (la escala vertical se deja especialmente igual):

¡El aumento en el número de publicaciones comenzó el 15 de enero de 2019, cuando se anunció
Hello World! O Habr en inglés , sin embargo, varios meses antes de que se publicaran estos 3 artículos:
1 ,
2 y
3 . ¿Probablemente fue una prueba beta?
Identificadores
El siguiente punto interesante, que no mencionamos en las partes anteriores, es la comparación de identificadores de artículos y fechas de publicación. Cada artículo tiene un enlace del tipo
habr.com/en/post/N , la numeración de los artículos es de principio a fin, el primer artículo tiene el identificador 1 y el que está leyendo es 441740. Parece que todo es simple. Pero en realidad no. Verifique la correspondencia de fechas e identificadores.
Cargue el archivo en el Marco de datos de Pandas, seleccione las fechas y la identificación, y complételas:
df = pd.read_csv(log_path, header=None, names=['datetime', 'votes', 'bookmarks', 'views', 'comments']) dates = pd.to_datetime(df['datetime'], format='%Y-%m-%dT%H:%M:%S.%f') dates += datetime.timedelta(hours=3) df['datetime'] = dates def link2id(link):
El resultado es sorprendente: los identificadores no siempre se toman en una fila, como se suponía originalmente, hay notables "valores atípicos".
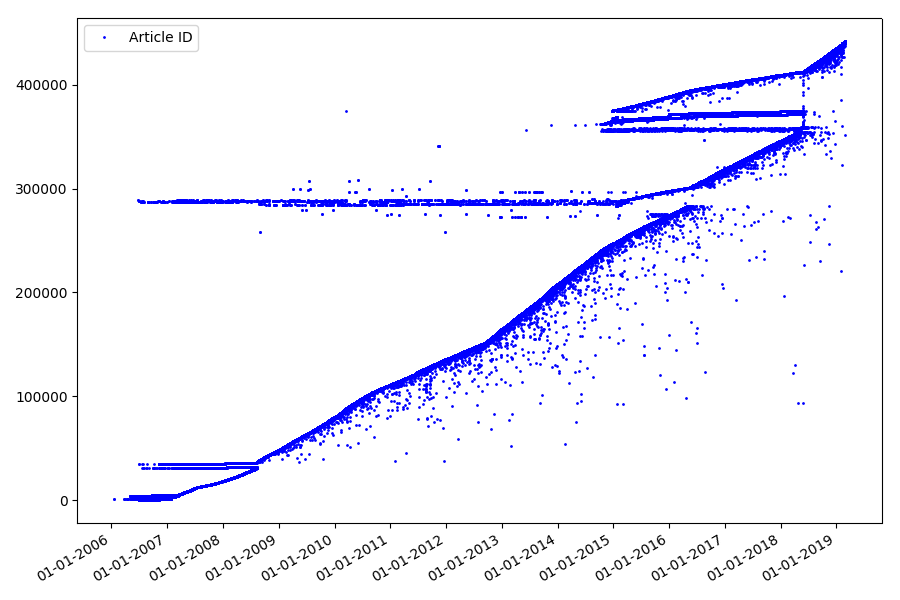
En parte debido a ellos, el público tenía preguntas sobre las calificaciones para 2017 y 2018: el analizador no tuvo en cuenta dichos artículos con la identificación "incorrecta". ¿Por qué es tan difícil de decir y no tan importante?
¿Qué podría ser interesante sobre los identificadores? Hay una hipótesis que no puedo probar formalmente, pero que parece obvio. Se asigna un identificador al momento de escribir el borrador del artículo, y la fecha de publicación obviamente viene más tarde. Alguien publica el artículo el mismo día, alguien publica el material más tarde. ¿Por qué todo esto? Coloquemos los identificadores en el eje X y las fechas verticalmente, y veamos un fragmento del gráfico con más detalle:
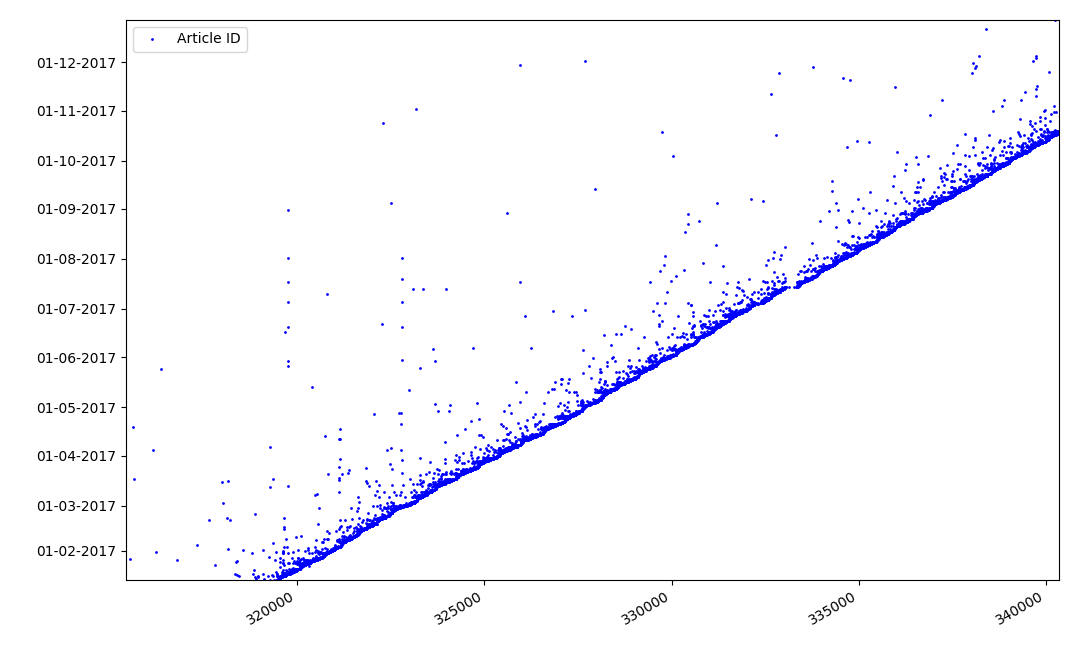
Resultado: vemos una nube de puntos sobre la línea continua, lo que nos muestra la distribución del tiempo durante
la creación de los artículos . Como puede ver, el máximo cae en el intervalo de hasta 1-2 semanas. Casi toda la masa de artículos se crea en no más de un mes, aunque algunos artículos se publican varios meses después de la creación del borrador (por supuesto, esto no nos garantiza que el autor trabajó en el artículo durante varios meses al día, pero el resultado sigue siendo bastante interesante).
Fecha y hora de publicación
Un punto interesante, aunque intuitivo, es el momento de publicación de artículos.
Estadísticas de salida en días laborables:
print("Group by hour (average, working days):") df_workdays = df[(df['day'] < 5)] g = df_workdays.groupby(['hour']) hour_count = g.size().reset_index(name='counts') grouped = g.median().reset_index() grouped['counts'] = hour_count['counts'] print(grouped[['hour', 'counts', 'views', 'comments', 'votes', 'votesperview']]) print() view_hours = grouped['hour'].values view_hours_avg = grouped['counts'].values fig, ax = plt.subplots() plt.bar(view_hours, view_hours_avg, align='edge', label='Publication Time (Mo-Fr)') ax.set_xticks(range(24)) ax.xaxis.set_major_formatter(FormatStrFormatter('%d:00')) plt.legend(loc='best') fig.autofmt_xdate() plt.tight_layout() plt.show()
La dependencia del número de artículos en el momento de la publicación de lunes a viernes:
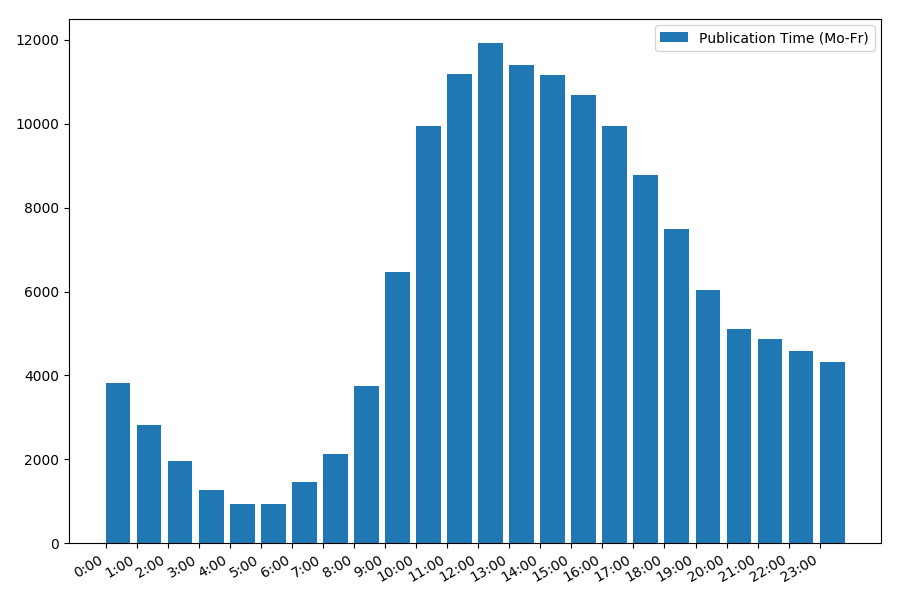
La imagen es interesante, la mayoría de las publicaciones se refieren al horario laboral. Sigue siendo interesante, para la mayoría de los autores escribir artículos es el trabajo principal, ¿o simplemente lo hacen durante las horas de trabajo? ;) Pero el calendario de distribución del fin de semana da una imagen diferente:
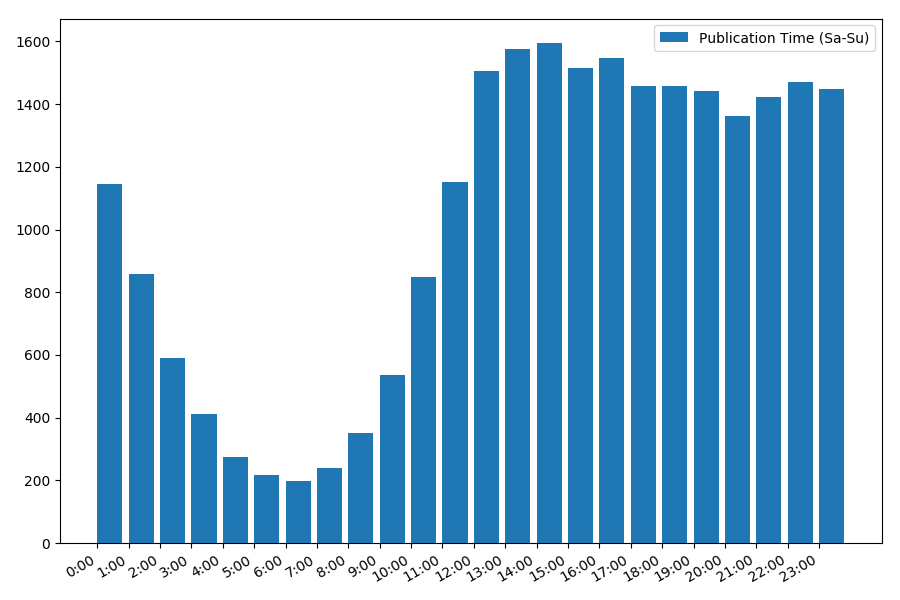
Como hablamos de fecha y hora, veamos el valor promedio de las vistas y la cantidad de artículos por día de la semana.
g = df.groupby(['day', 'dayofweek']) dayofweek_count = g.size().reset_index(name='counts') grouped = g.median().reset_index() grouped['counts'] = dayofweek_count['counts'] grouped.sort_values('day', ascending=False) print(grouped[['day', 'dayofweek', 'counts', 'views', 'comments', 'votes', 'votesperview']]) print() view_days = grouped['day'].values view_per_day = grouped['views'].values counts_per_day = grouped['counts'].values days_of_week = grouped['dayofweek'].values plt.bar(view_days, view_per_day, align='edge', label='Avg.Views/day') plt.bar(view_days, counts_per_day, align='edge', label='Amount/day') plt.xticks(view_days, days_of_week) plt.ylim(bottom=0, top=10000) plt.show()
El resultado es interesante:
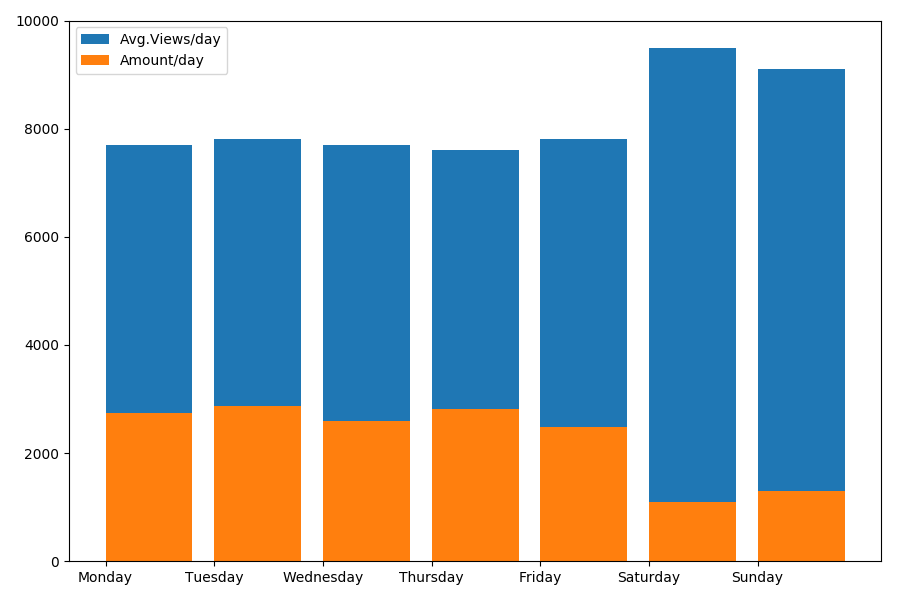
Como puede ver, se publican notablemente menos artículos los fines de semana. Pero luego, cada artículo gana más puntos de vista, por lo que publicar artículos durante el fin de semana parece bastante aconsejable (como se encontró en la
primera parte , la vida activa del artículo no es más de 3-4 días, por lo que los primeros dos días son bastante críticos).
El artículo tal vez se está haciendo demasiado largo. El final en la
segunda parte .