
Compartiré una historia sobre un pequeño proyecto: cómo encontrar las respuestas del autor en los comentarios sin saber quién es el autor de la publicación.
Comencé mi proyecto con un conocimiento mínimo sobre aprendizaje automático y creo que aquí no habrá nada nuevo para los especialistas. Este material es, en cierto sentido, una compilación de diferentes artículos, en él contaré cómo se acercó a la tarea, en el código puede encontrar pequeñas cosas y trucos útiles con el procesamiento del lenguaje natural.
Mis datos iniciales fueron los siguientes: una base de datos que contenía 2.5 millones de materiales multimedia y 39.5 millones de comentarios sobre ellos. Para publicaciones de 1M, de una forma u otra, se conocía al autor del material (esta información estaba presente en la base de datos o se obtuvo mediante el análisis de datos por motivos indirectos). Sobre esta base, se creó
un conjunto de datos a partir de 215K registros marcados.
Inicialmente, utilicé un enfoque basado en la heurística emitido por la inteligencia natural y traducido a consultas SQL con búsqueda de texto completo o expresiones regulares. Los ejemplos más simples de texto para analizar: "gracias por el comentario" o "gracias por las buenas calificaciones", este es el autor en el 99,99% de los casos, y "gracias por el trabajo" o "¡Gracias!" Enviar material por correo. Gracias! - revisión ordinaria. Con este enfoque, solo se pueden filtrar las coincidencias obvias, excepto en los casos de errores tipográficos banales o cuando el autor está en diálogo con los comentaristas. Por lo tanto, se decidió usar redes neuronales, esta idea surgió no sin la ayuda de un amigo.
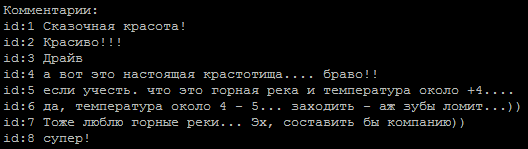
Una secuencia típica de comentarios, ¿cuál de ellos es el autor?
Se tomó como base el método para determinar la tonalidad del texto. La tarea es simple para nosotros en dos clases: el autor y no el autor. Para entrenar modelos, utilicé un
servicio de Google que proporciona máquinas virtuales con una GPU y una interfaz de computadora portátil Jupiter.
Ejemplos de redes encontradas en Internet:
embed_dim = 128 model = Sequential() model.add(Embedding(max_fatures, embed_dim,input_length = X_train.shape[1])) model.add(SpatialDropout1D(0.2)) model.add(LSTM(196, dropout=0.5, recurrent_dropout=0.2)) model.add(Dense(1,activation='softmax')) model.compile(loss = 'binary_crossentropy', optimizer='adam',metrics = ['accuracy'])
en las líneas libres de etiquetas html y caracteres especiales, dieron alrededor del 65-74% de precisión, lo que no difería mucho de lanzar una moneda.
Un punto interesante es que la alineación de las secuencias de entrada a través de
pad_sequences(x_train, maxlen=max_len, padding='pre') dio una diferencia significativa en los resultados. En mi caso, el mejor resultado fue con padding = 'post'.
El siguiente paso fue el uso de la lematización, que de inmediato dio un aumento en la precisión de hasta el 80% y esto se podría seguir trabajando. Ahora el problema principal es la limpieza correcta del texto. Por ejemplo, los errores tipográficos en la palabra "gracias" se convirtieron (los errores tipográficos se seleccionaron por frecuencia de uso) en una expresión tan regular (tales expresiones han acumulado entre media y dos docenas).
re16 = re.compile(ur"(?:\b:(?:1|c(?:|)|(?:|)|(?:(?:|(?:(?:(?:|(?:)?|))?|(?:)?))|)|(?:(?:(?:|)|)||||(?:(?:||(?:|)|(?:|(?:(?:(?:||(?:(?:||(?:[]|)|[]))?|[і]))?|||1)||)|)|||[]|(?:|)|(?:(?:(?:[]|)|?|(?:(?:(?:|(?:)?))?|)|(?:|)))?)||)|(?:|x))\b)", re.UNICODE)
Aquí, me gustaría expresar un agradecimiento especial a las personas demasiado educadas que consideran necesario agregar esta palabra a cada una de sus oraciones.
Era necesario reducir la proporción de errores tipográficos porque a la salida del lemmatizer dan palabras extrañas y perdemos información útil.
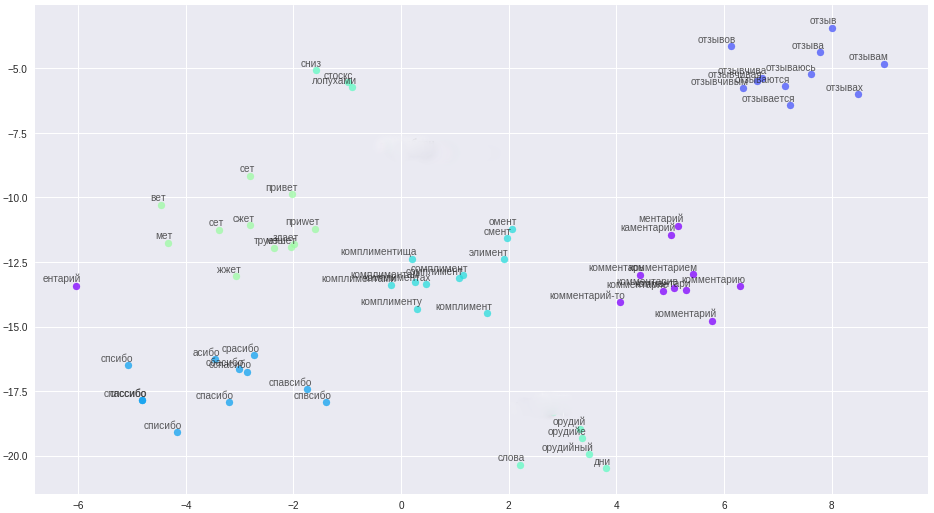
Pero hay un lado positivo, nos cansamos de lidiar con los errores tipográficos, de la limpieza de textos complejos, utilicé la representación vectorial de las palabras: word2vec. El método permitió traducir todos los errores tipográficos, errores tipográficos y sinónimos en vectores muy espaciados.

Las palabras y sus relaciones en el espacio vectorial.
Las reglas de limpieza se simplificaron significativamente (aha, storyteller), todos los mensajes, nombres de usuario, se dividieron en oraciones y se cargaron en un archivo. Un punto importante: debido a la brevedad de nuestros comentaristas, para construir vectores de alta calidad, las palabras necesitan información contextual adicional, por ejemplo, del foro y Wikipedia. Se capacitaron tres modelos en el archivo resultante: word2vec clásico, Glove y FastText. Después de muchos experimentos, finalmente se decidió por FastText, como los grupos de palabras más cualitativamente distintivos en mi caso.
Todos estos cambios trajeron una precisión estable de 84-85 por ciento.
Ejemplos de modelos def model_conv_core(model_input, embd_size = 128): num_filters = 128 X = Embedding(total_unique_words, DIM, input_length=max_words, weights=[embedding_matrix], trainable=False, name='Word2Vec')(model_input) X = Conv1D(num_filters, 3, activation='relu', padding='same')(X) X = Dropout(0.3)(X) X = MaxPooling1D(2)(X) X = Conv1D(num_filters, 5, activation='relu', padding='same')(X) return X def model_conv1d(model_input, embd_size = 128, num_filters = 64, kernel_size=3): X = Embedding(total_unique_words, DIM, input_length=max_words, weights=[embedding_matrix], trainable=False, name='Word2Vec')(model_input) X = Conv1D(num_filters, kernel_size, padding='same', activation='relu', strides=1)(X)
y 6 modelos más en
código . Algunos de los modelos se toman de la red, algunos se inventan de forma independiente.
Se notó que diferentes comentarios se destacaban en diferentes modelos, esto impulsó la idea de usar conjuntos de modelos. Primero, ensamblé el conjunto manualmente, eligiendo los mejores pares de modelos, luego hice un generador. Para optimizar la búsqueda exhaustiva, tomé el código gris como base.
def gray_code(n): def gray_code_recurse (g,n): k = len(g) if n <= 0: return else: for i in range (k-1, -1, -1): char='1' + g[i] g.append(char) for i in range (k-1, -1, -1): g[i]='0' + g[i] gray_code_recurse (g, n-1) g = ['0','1'] gray_code_recurse(g, n-1) return g def gen_list(m): out = [] g = gray_code(len(m)) for i in range (len(g)): mask_str = g[i] idx = 0 v = [] for c in list(mask_str): if c == '1': v.append(m[idx]) idx += 1 if len(v) > 1: out.append(v) return out
Con el conjunto "la vida se ha vuelto más divertida" y el porcentaje actual de precisión del modelo se mantiene en 86-87%, lo que se asocia principalmente con una clasificación de baja calidad de algunos autores en el conjunto de datos.

Los problemas que encontré:
- Conjunto de datos no balanceado. El número de comentarios de los autores fue significativamente menor que el de otros comentaristas.
- Las clases en la muestra van en estricto orden. La conclusión es que el principio, el medio y el final difieren significativamente en la calidad de la clasificación. Esto es claramente visible en el proceso de aprendizaje en el cronograma de la medida f1.
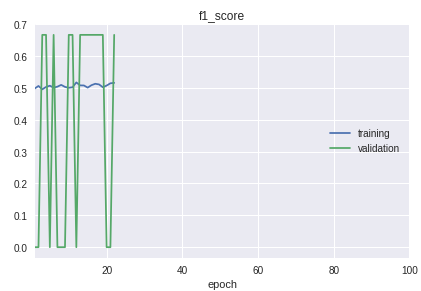
Para la solución, se hizo una bicicleta para la separación en muestras de entrenamiento y validación. Aunque en la práctica en la mayoría de los casos, el procedimiento train_test_split de la biblioteca sklearn es suficiente.
Gráfico del modelo de trabajo actual:

Como resultado, obtuve un modelo con una definición segura de autores a partir de comentarios breves. La mejora adicional se asociará con la limpieza y la transferencia de los resultados de la clasificación de datos reales al conjunto de datos de capacitación.
Todo el código con explicaciones adicionales está en el
repositorio .
Como postdata: si necesita clasificar grandes cantidades de texto, eche un vistazo al
modelo VDCNN "Red neuronal convolucional muy profunda" (
implementación en keras), este es un análogo de ResNet para textos.
Materiales utilizados
•
Descripción general de los cursos de aprendizaje automático•
Análisis de convolución usando convolución•
Redes convolucionales en PNL•
Métricas en aprendizaje automáticohttps://ld86.imtqy.com/ml-slides/unbalanced.html•
Una mirada al interior del modelo.