
Hasta la fecha, cualquier estudiante que haya tomado un curso en redes neuronales puede reconocer los caracteres coreanos. Dale una muestra y una computadora con una tarjeta de video, y después de un tiempo te traerá una red que reconocerá los caracteres coreanos casi sin errores.
Pero tal solución tendrá varias desventajas:
En primer lugar , una gran cantidad de cálculos necesarios, que afectan el tiempo de funcionamiento o la energía requerida (lo cual es muy importante para los dispositivos móviles). De hecho, si queremos reconocer al menos 3000 caracteres, este será el tamaño de la última capa de la red. Y si la entrada de esta capa es al menos 512, entonces obtenemos 512 * 3000 multiplicaciones. Demasiado
En segundo lugar , el tamaño. La misma última capa del ejemplo anterior pesará 512 * 3001 * 4 bytes, es decir, aproximadamente 6 megabytes. Esta es solo una capa, toda la red pesará decenas de megabytes. Está claro que este no es un gran problema para una computadora de escritorio, pero no todos estarán listos para almacenar tantos datos en un teléfono inteligente para reconocer un idioma.
En tercer lugar , una red de este tipo dará resultados impredecibles en imágenes que no son caracteres coreanos, pero que, sin embargo, se utilizan en textos coreanos. En condiciones de laboratorio, esto no es difícil, pero para la aplicación práctica de la tecnología, este problema tendrá que resolverse de alguna manera.
Y en cuarto lugar , el problema es la cantidad de caracteres: 3000 es lo suficientemente probable como para, por ejemplo, distinguir un filete de un pepino de mar frito en el menú del restaurante, pero a veces hay textos más complejos. Será difícil entrenar la red para un mayor número de caracteres: no solo será más lento, sino que también habrá un problema con la recolección de la muestra de entrenamiento, ya que la frecuencia de los caracteres disminuye aproximadamente exponencialmente. Por supuesto, puede obtener imágenes de fuentes y aumentarlas, pero esto no es suficiente para entrenar una buena red.
Y hoy les contaré cómo logramos resolver estos problemas.
¿Cómo funciona la escritura coreana?
La escritura coreana, Hangul, es un cruce entre la escritura china y la europea. Exteriormente, estos son caracteres cuadrados que se asemejan a jeroglíficos, y en una página del texto puede contar más de un centenar de caracteres únicos. Por otro lado, es escritura fonética, es decir, basada en la grabación de sonidos. Hay un alfabeto que contiene 24 letras (además, también puede contar difrafos y diptongos). Pero, a diferencia del alfabeto latino o cirílico, los sonidos no se escriben en una línea, sino que se combinan en bloques. Por ejemplo, si escribimos de la misma manera, la frase "Hola, Habr" podría escribirse en tres bloques como este:
Cada bloque puede constar de dos, tres o cuatro letras. En este caso, la consonante siempre viene primero, luego una o dos vocales, y al final puede haber otra consonante. Hay varias formas diferentes de combinar letras en bloques, es decir, en diferentes bloques, la segunda letra, por ejemplo, se ubicará en diferentes lugares.
La siguiente imagen muestra dos bloques que juntos forman la palabra "Hangul". La primera letra de cada bloque se indica en rojo, las vocales se resaltan en azul y la consonante final se resalta en verde.
Fuente de la imagen: Wikipedia.Modificar bloque Hangul
Es decir, resulta que un bloque Hangul puede describirse mediante la fórmula: Ci V [V] [Cf], donde Ci es la consonante inicial (posiblemente doble), V es la vocal y Cf es la consonante final (también puede ser doble). Tal representación es inconveniente para el reconocimiento, por lo que la cambiamos.
Primero, combine ambas vocales. Obtenemos la fórmula Ci V '[Cf], donde V': todas las opciones posibles para combinar letras, considerando la ausencia de la segunda letra. Como hay 10 vocales en el idioma, uno esperaría que como resultado obtengamos 10 * (10 + 1) opciones, pero en la práctica no todas son posibles, solo se obtienen 21.
Además, la última carta puede no ser. Agregue a las muchas letras esperadas al final una vacía. Luego obtenemos la fórmula Ci V 'Cf *. Por lo tanto, resulta que ahora el símbolo coreano siempre consta de tres "letras". Puedes aprender la cuadrícula.
Construimos una red
La idea es que en lugar de reconocer el carácter completo, reconoceremos las letras individuales en ellos. Por lo tanto, en lugar de un softmax enorme al final, obtenemos tres pequeños, cada uno de unos pocos centímetros de tamaño. Corresponden a la primera, segunda y tercera "letras" en la sílaba. Como resultado, obtuvimos la siguiente arquitectura:
imagen en la que se puede hacer clic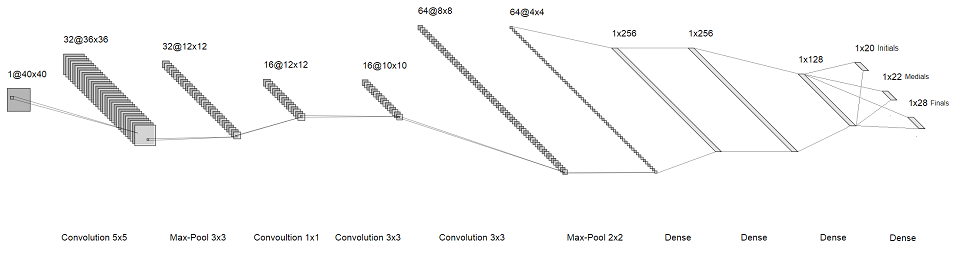
Entrenamos, corremos en una muestra separada. La calidad es buena, la red es rápida y pesa poco. Tratemos de sacarlo del laboratorio al mundo real.
Resolvemos problemas
Obtendremos el primer problema de inmediato: a veces las imágenes que no son caracteres coreanos entran en la entrada, y la red en ellas se comporta de manera extremadamente impredecible. Por supuesto, puede entrenar otra red que distinguirá los bloques coreanos de todo lo demás, pero lo haremos más fácil.
Hagamos lo mismo que hicimos con el tercer grupo de letras: agregue una salida por la ausencia de una letra. Entonces la fórmula del símbolo se verá así: Ci * V '* Cf *. Y en el conjunto de entrenamiento, agregaremos todo tipo de basura: caracteres chinos, caracteres cortados incorrectamente, letras europeas, y enseñaremos a la red a marcar tres letras vacías en él.
Entrenamos, probamos. Funciona, pero los problemas persisten. Resulta que con bastante frecuencia, por ejemplo, tales imágenes caen en la cuadrícula:
Este es el bloque coreano correcto al que se le pega una cita simple. Y es obvio que en ellos la red encuentra perfectamente las tres letras en las que consiste el bloque. Eso es solo que la imagen no es correcta, y debemos señalarlo. Es incorrecto devolver letras vacías aquí, ya que están en la imagen. Tratemos de aplicar lo que ya ha demostrado ser bueno: agregue dos salidas más para reconocer estos signos de puntuación pegajosos. En cada uno de ellos habrá una salida adicional para una situación en la que no hay nada superfluo en la imagen, pero además es necesario agregar una salida más para la situación "hay un marcador, pero no se reconoce, probablemente basura".
Entrenado En una grilla de este tipo es malo reconocer los signos de puntuación: distingue una coma de un paréntesis, pero ya es difícil desde un punto. Puede aumentar la complejidad de la cuadrícula, pero no lo desea. Nos ocuparemos del reconocimiento de los signos de puntuación más adelante, pero por ahora simplemente daremos a conocer si hay algo allí o no. Esta cuadrícula aprendió bien.
Descubrimos los signos de puntuación pegados, pero ¿qué pasa si, por el contrario, falta parte de la clave en la imagen? Había una palabra de dos caracteres, pero la cortamos en caracteres incorrectamente:
La red aquí sin ningún problema determina la letra central. Esta sería una cualidad muy útil si nuestra tarea fuera reconocer solo una selección de caracteres, pero en el mundo real sería dañino: cuando cortamos incorrectamente la cadena en caracteres, debemos pasar esta información arriba, porque de lo contrario la pieza restante se reconoce como algún tipo de puntuación, y en el texto resultante habrá un carácter extra.
Para resolver este problema, usaremos lo que queda de algunos viejos experimentos de hace muchos años. La idea de reconocer los caracteres coreanos por letras apareció hace mucho tiempo, y los primeros intentos se hicieron incluso antes de la era de las redes neuronales, pero no encontraron una aplicación práctica. Pero desde entonces, han quedado cosas interesantes:
- Marcar donde cada bloque tiene una letra.
- Alta calidad, aunque rápida, cortando estas letras de los símbolos.
Después de limpiar el polvo, con la ayuda de estas cosas generaremos una cantidad suficiente de imágenes problemáticas sin una de las letras y le enseñaremos especialmente a la red a responder que son una letra vacía.
Eso es todo, no hay más problemas para reconocer los caracteres coreanos, pero la vida vuelve a poner palos en las ruedas.
El hecho es que además de los caracteres Hangeul, los textos coreanos también consisten en una gran cantidad de otros caracteres: signos de puntuación, caracteres europeos (al menos números) y caracteres chinos. Pero, naturalmente, ocurren con mucha menos frecuencia. Los dividiremos en dos grupos: jeroglíficos y todo lo demás, y entrenaremos nuestra cuadrícula para cada uno de ellos. Y haremos un clasificador simple, que de acuerdo con los resultados de la red para reconocer los caracteres coreanos y para algunos otros signos (geométricos, en primer lugar) responderá si al menos uno de ellos necesita ser lanzado, y si es así, cuál. Debe reconocer un poco de caracteres europeos, por lo que la cuadrícula será pequeña, pero para los jeroglíficos ... Ahorra que rara vez se encuentren en los textos, así que vamos a torcer nuestro clasificador para que muy raramente sugiera reconocerlos.
En general, con estas dos cuadrículas, el problema de una respuesta adecuada surge en las imágenes que no son símbolos en los que fue entrenada, pero hablaremos sobre cómo resolver este problema en otra ocasión.
Realizar experimentos
El primero Hay dos bases de imágenes, llamémoslas Real y Sintético. Real consiste en imágenes reales que se obtienen de documentos escaneados, y sintéticas: imágenes obtenidas de fuentes. En la primera base hay imágenes para 2374 bloques (el resto son muy raros), y de las fuentes obtuvimos todos los 11172 caracteres posibles. Intentemos entrenar la red en los bloques que están en Real (tomaremos las imágenes de ambas bases), y probar en aquellos que solo están en Synthetic. Resultados:

Es decir, en aproximadamente el 60% de los casos, la red puede reconocer esos bloques, ejemplos de los cuales no se vio en absoluto durante el entrenamiento. La calidad podría haber sido mayor si no fuera por un problema: entre las letras finales hay muy raras, y durante el entrenamiento la red vio muy pocas imágenes de bloques en ellas. Esto explica la baja calidad en la última columna. Si fuera posible elegir los 2374 bloques en los que estudiamos, de una manera diferente, entonces la calidad probablemente sería notablemente mayor.
Segunda . Compare nuestra red con una red "normal", que tiene softmax al final. Me gustaría que tenga un tamaño de 11172, pero no podemos encontrar una cantidad suficiente de imágenes reales para bloques raros, por lo que nos restringimos a 2374. La calidad y la velocidad de esta red dependen del tamaño de las capas ocultas. Solo enseñaremos en Real, lo probaremos (por otro lado, por supuesto).

Es decir, incluso si nos limitamos a reconocer solo 2374 bloques, nuestra red es más rápida y al mismo nivel de calidad.
Tercero Supongamos que pudiéramos obtener en algún lugar una gran base de todos los 11172 bloques coreanos. Si entrenamos una red con softmax, ¿cuánto tiempo funcionará a tiempo? Es costoso realizar todos los experimentos, por lo que solo consideraremos una red con 256 tamaños de capa ocultos:

Obtenemos los resultados
Sin ellos, nada hubiera pasado
Expreso mi gratitud a mi colega Jura Chulinin, el autor original de la idea. Está
patentado en Rusia y, además, se ha
presentado una solicitud similar
ante la Oficina de Patentes de los Estados Unidos (USPTO). Muchas gracias a la desarrolladora Misha Zatsepin, quien implementó todo esto y realizó todos los experimentos.
Yuri Vatlin,
Jefe del grupo de Scripts complejos