Hola a todos! Ha llegado la primavera, lo que significa que queda menos de un mes antes del inicio del curso
Python Developer . Es a este curso que se dedicará nuestra publicación de hoy.

 Tareas
Tareas- Aprende sobre la estructura interna de Python;
- Comprender los principios de la construcción de un árbol de sintaxis abstracta (AST);
- Escribir código más eficiente en tiempo y memoria.
Recomendaciones preliminares:- Comprensión básica del intérprete (AST, tokens, etc.).
- Conocimiento de Python.
- Conocimientos básicos de C.
batuhan@arch-pc ~/blogs/cpython/exec_model python --version Python 3.7.0
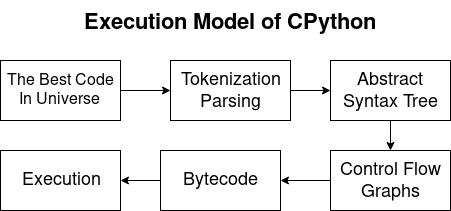
Modelo de ejecución de CPythonPython es un lenguaje compilado e interpretado. Por lo tanto, el compilador de Python genera bytecodes y el intérprete los ejecuta. Durante el artículo consideraremos los siguientes problemas:
- Análisis y tokenización:
- Transformación en AST;
- Gráfico de flujo de control (CFG);
- Bytecode
- Ejecutando en una máquina virtual CPython.
Análisis y tokenización.
GramáticaLa gramática define la semántica del lenguaje Python. También es útil para indicar la forma en que el analizador debe interpretar el idioma. La gramática de Python usa una sintaxis similar a la forma extendida de Backus-Naur. Tiene su propia gramática para un traductor del idioma de origen. Puede encontrar el archivo de gramática en el directorio "cpython / Grammar / Grammar".
El siguiente es un ejemplo de una gramática,
batuhan@arch-pc ~/cpython/Grammar master grep "simple_stmt" Grammar | head -n3 | tail -n1 simple_stmt: small_stmt (';' small_stmt)* [';'] NEWLINE
Las expresiones simples contienen pequeñas expresiones y corchetes, y el comando termina con una nueva línea. Las expresiones pequeñas parecen una lista de expresiones que importan ...
Algunas otras expresiones :)
small_stmt: (expr_stmt | del_stmt | pass_stmt | flow_stmt | import_stmt | global_stmt | nonlocal_stmt | assert_stmt) ... del_stmt: 'del' exprlist pass_stmt: 'pass' flow_stmt: break_stmt | continue_stmt | return_stmt | raise_stmt | yield_stmt break_stmt: 'break' continue_stmt: 'continue'
Tokenización (Lexing)La tokenización es el proceso de obtener un flujo de datos de texto y dividirlo en tokens de palabras significativas (para el intérprete) con metadatos adicionales (por ejemplo, dónde comienza y termina el token y cuál es el valor de cadena de este token).
FichasUn token es un archivo de encabezado que contiene definiciones de todos los tokens. Hay 59 tipos de tokens en Python (Incluir / token.h).
A continuación se muestra un ejemplo de algunos de ellos,
Los ves si divides algún código de Python en tokens.
Tokenización con CLIAquí está el archivo tests.py
def greetings(name: str): print(f"Hello {name}") greetings("Batuhan")
Luego lo tokenizamos utilizando el comando python -m tokenize y se genera lo siguiente:
batuhan@arch-pc ~/blogs/cpython/exec_model python -m tokenize tests.py 0,0-0,0: ENCODING 'utf-8' ... 2,0-2,4: INDENT ' ' 2,4-2,9: NAME 'print' ... 4,0-4,0: DEDENT '' ... 5,0-5,0: ENDMARKER ''
Aquí los números (por ejemplo, 1.4-1.13) muestran dónde comenzó el token y dónde terminó. Un token de codificación es siempre el primer token que recibimos. Proporciona información sobre la codificación del archivo fuente y, si hay algún problema, el intérprete lanza una excepción.
Tokenización con tokenize.tokenizeSi necesita tokenizar el archivo desde su código, puede usar el módulo
tokenize de
stdlib .
>>> with open('tests.py', 'rb') as f: ... for token in tokenize.tokenize(f.readline): ... print(token) ... TokenInfo(type=57 (ENCODING), string='utf-8', start=(0, 0), end=(0, 0), line='') ... TokenInfo(type=1 (NAME), string='greetings', start=(1, 4), end=(1, 13), line='def greetings(name: str):\n') ... TokenInfo(type=53 (OP), string=':', start=(1, 24), end=(1, 25), line='def greetings(name: str):\n') ...
El tipo de token es su id en el archivo de encabezado
token.h. La cadena es el valor del token. Inicio y Fin muestran dónde comienza y termina el token, respectivamente.
En otros idiomas, los bloques se indican entre paréntesis o declaraciones de inicio / fin, pero Python usa sangrías y diferentes niveles. Fichas INDENT y DEDENT e indican sangría. Estos tokens son necesarios para construir árboles de análisis relacional y / o árboles de sintaxis abstracta.
Generación de analizadorGeneración de analizador: un proceso que genera un analizador de acuerdo con una gramática dada. Los generadores de analizadores se conocen como PGen. Cpython tiene dos generadores de analizadores. Uno es el original (
Parser/pgen ) y el otro se reescribe en python (
/Lib/lib2to3/pgen2 ).
"El generador original fue el primer código que escribí para Python"
-GuidoDe la cita anterior, queda claro que
pgen es lo más importante en un lenguaje de programación. Cuando llama a pgen (en
Parser / pgen ) genera un archivo de encabezado y un archivo C (el analizador en sí). Si observa el código C generado, puede parecer inútil, ya que su apariencia significativa es opcional. Contiene muchos datos estáticos y estructuras. A continuación, trataremos de explicar sus componentes principales.
DFA (máquina de estado definida)El analizador define un DFA para cada no terminal. Cada DFA se define como una matriz de estados.
static dfa dfas[87] = { {256, "single_input", 0, 3, states_0, "\004\050\340\000\002\000\000\000\012\076\011\007\262\004\020\002\000\300\220\050\037\202\000"}, ... {342, "yield_arg", 0, 3, states_86, "\000\040\200\000\002\000\000\000\000\040\010\000\000\000\020\002\000\300\220\050\037\000\000"}, };
Para cada DFA, hay un kit de inicio que muestra con qué fichas puede comenzar un no terminal especial.
CondiciónCada estado está definido por una matriz de transiciones / aristas (arcos).
static state states_86[3] = { {2, arcs_86_0}, {1, arcs_86_1}, {1, arcs_86_2}, };
Transiciones (arcos)Cada matriz de transición tiene dos números. El primer número es el nombre de la transición (etiqueta de arco), se refiere al número de símbolo. El segundo número es el destino.
static arc arcs_86_0[2] = { {77, 1}, {47, 2}, }; static arc arcs_86_1[1] = { {26, 2}, }; static arc arcs_86_2[1] = { {0, 2}, };
Nombres (etiquetas)Esta es una tabla especial que asigna la identificación del personaje al nombre de la transición.
static label labels[177] = { {0, "EMPTY"}, {256, 0}, {4, 0}, ... {1, "async"}, {1, "def"}, ... {1, "yield"}, {342, 0}, };
El número 1 corresponde a todos los identificadores. Por lo tanto, cada uno de ellos obtiene diferentes nombres de transición, incluso si todos tienen la misma identificación de personaje.
Un simple ejemplo:Supongamos que tenemos un código que genera "Hola" si 1 - verdadero:
if 1: print('Hi')
El analizador considera este código como entrada única.
single_input: NEWLINE | simple_stmt | compound_stmt NEWLINE
Entonces nuestro árbol de análisis comienza en el nodo raíz de una entrada única.

Y el valor de nuestro DFA (single_input) es 0.
static dfa dfas[87] = { {256, "single_input", 0, 3, states_0, "\004\050\340\000\002\000\000\000\012\076\011\007\262\004\020\002\000\300\220\050\037\202\000"} ... }
Se verá así:
static arc arcs_0_0[3] = { {2, 1}, {3, 1}, {4, 2}, }; static arc arcs_0_1[1] = { {0, 1}, }; static arc arcs_0_2[1] = { {2, 1}, }; static state states_0[3] = { {3, arcs_0_0}, {1, arcs_0_1}, {1,
arcs_0_2},
};
Aquí
arc_0_0 consta de tres elementos. El primero es
NEWLINE , el segundo es
simple_stmt y el último es
compound_stmt .
Dado el conjunto inicial de
simple_stmt podemos concluir que
simple_stmt no puede comenzar con
if . Sin embargo, incluso si no es una nueva línea,
compound_stmt aún puede comenzar con
if . Por lo tanto, pasamos del último
arc ({4;2}) y agregamos el nodo
compound_stmt al árbol de análisis y antes de pasar al número 2, cambiamos al nuevo DFA. Obtenemos un árbol de análisis actualizado:

El nuevo DFA analiza las declaraciones compuestas.
compound_stmt: if_stmt | while_stmt | for_stmt | try_stmt | with_stmt | funcdef | classdef | decorated | async_stmt
Y obtenemos lo siguiente:
static arc arcs_39_0[9] = { {91, 1}, {92, 1}, {93, 1}, {94, 1}, {95, 1}, {19, 1}, {18, 1}, {17, 1}, {96, 1}, }; static arc arcs_39_1[1] = { {0, 1}, }; static state states_39[2] = { {9, arcs_39_0}, {1, arcs_39_1}, };
Solo el primer salto puede comenzar con
if . Obtenemos un árbol de análisis actualizado.
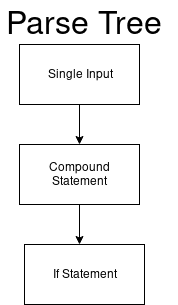
Luego cambiamos nuevamente el DFA y los siguientes ifs de DFA.
if_stmt: 'if' test ':' suite ('elif' test ':' suite)* ['else' ':' suite]
Como resultado, obtenemos la única transición con la designación 97. Coincide con el token
if .
static arc arcs_41_0[1] = { {97, 1}, }; static arc arcs_41_1[1] = { {26, 2}, }; static arc arcs_41_2[1] = { {27, 3}, }; static arc arcs_41_3[1] = { {28, 4}, }; static arc arcs_41_4[3] = { {98, 1}, {99, 5}, {0, 4}, }; static arc arcs_41_5[1] = { {27, 6}, }; static arc arcs_41_6[1] = { {28, 7}, }; ...
Cuando cambiamos al siguiente estado, que permanece en el mismo DFA, el siguiente arcs_41_1 también tiene solo una transición. Esto es cierto para el terminal de prueba. Debe comenzar con un número (por ejemplo, 1).
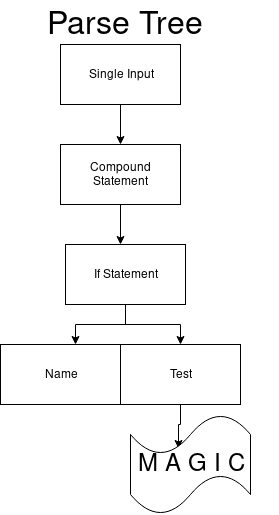
Solo hay una transición en arc_41_2 que obtiene el token de dos puntos (:).

Entonces obtenemos un conjunto que puede comenzar con un valor de impresión. Finalmente, ve a arcs_41_4. La primera transición en el conjunto es una expresión elif, la segunda es otra cosa y la tercera es para el último estado. Y obtenemos la vista final del árbol de análisis.
 Interfaz de Python para analizador.
Interfaz de Python para analizador.
Python le permite editar el árbol de análisis para expresiones usando un módulo llamado analizador.
>>> import parser >>> code = "if 1: print('Hi')"
Puede generar un árbol de sintaxis específico (Árbol de sintaxis concreta, CST) usando parser.suite.
>>> parser.suite(code).tolist() [257, [269, [295, [297, [1, 'if'], [305, [309, [310, [311, [312, [315, [316, [317, [318, [319, [320, [321, [322, [323, [324, [2, '1']]]]]]]]]]]]]]]], [11, ':'], [304, [270, [271, [272, [274, [305, [309, [310, [311, [312, [315, [316, [317, [318, [319, [320, [321, [322, [323, [324, [1, 'print']], [326, [7, '('], [334, [335, [305, [309, [310, [311, [312, [315, [316, [317, [318, [319, [320, [321, [322, [323, [324, [3, "'Hi'"]]]]]]]]]]]]]]]]]], [8, ')']]]]]]]]]]]]]]]]]]], [4, '']]]]]], [4, ''], [0, '']]
El valor de salida será una lista anidada. Cada lista en la estructura tiene 2 elementos. El primero es el id del personaje (0-256 - terminales, 256+ - no terminales) y el segundo es la cadena de tokens para el terminal.
Árbol de sintaxis abstractaDe hecho, un árbol de sintaxis abstracta (AST) es una representación estructural del código fuente en forma de árbol, donde cada vértice denota diferentes tipos de construcciones de lenguaje (expresión, variable, operador, etc.)
¿Qué es un árbol?Un árbol es una estructura de datos que tiene un vértice raíz como punto de partida. El vértice raíz se baja por ramas (transiciones) hacia otros vértices. Cada vértice, excepto la raíz, tiene un vértice padre único.
Hay una cierta diferencia entre el árbol de sintaxis abstracta y el árbol de análisis.
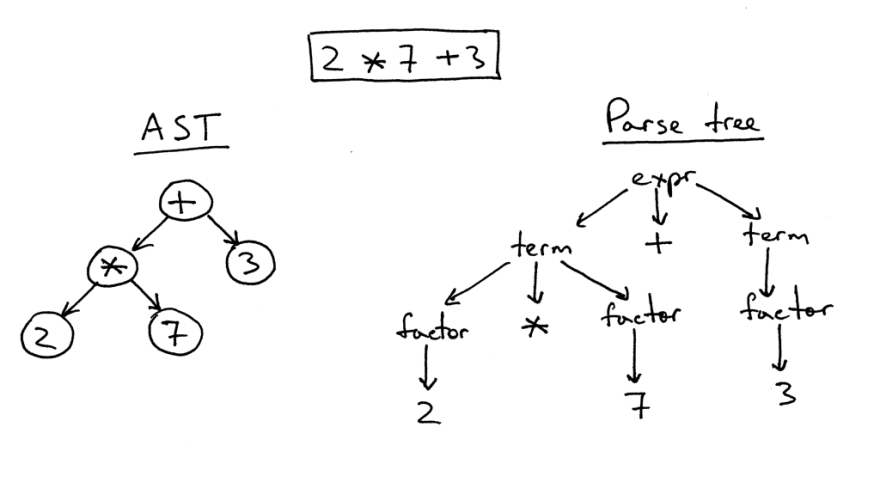
A la derecha hay un árbol de análisis para la expresión 2 * 7 + 3. Esta es literalmente una imagen de fuente uno a uno en forma de árbol. Todas las expresiones, términos y valores son visibles en él. Sin embargo, dicha imagen es demasiado complicada para una simple pieza de código, por lo que simplemente podemos eliminar todas las expresiones sintácticas que tuvimos que definir en el código para los cálculos.
Tal árbol simplificado se llama árbol de sintaxis abstracta (AST). A la izquierda en la figura se muestra exactamente para el mismo código. Todas las expresiones de sintaxis se han descartado para facilitar la comprensión, pero recuerde que se ha perdido cierta información.
Ejemplo
Python ofrece un módulo AST incorporado para trabajar con AST. Para generar código a partir de árboles AST, puede usar módulos de terceros, por ejemplo
Astor .
Por ejemplo, considere el mismo código que antes.
>>> import ast >>> code = "if 1: print('Hi')"
Para obtener AST, utilizamos el método ast.parse.
>>> tree = ast.parse(code) >>> tree <_ast.Module object at 0x7f37651d76d8>
Intente usar el método
ast.dump para obtener un árbol de sintaxis abstracta más legible.
>>> ast.dump(tree) "Module(body=[If(test=Num(n=1), body=[Expr(value=Call(func=Name(id='print', ctx=Load()), args=[Str(s='Hi')], keywords=[]))], orelse=[])])"
AST generalmente se considera más visual y fácil de entender que el árbol de análisis.
Control de flujo Graf (CFG)Los gráficos de flujo de control son gráficos direccionales que modelan el flujo de un programa utilizando bloques base que contienen una representación intermedia.
Normalmente, CFG es el paso anterior antes de obtener los valores del código de salida. El código se genera directamente desde los bloques base utilizando una búsqueda de profundidad hacia atrás en CFG, comenzando desde la parte superior.
BytecodePython bytecode es un conjunto intermedio de instrucciones que funcionan en una máquina virtual Python. Cuando ejecuta el código fuente, Python crea un directorio llamado __pycache__. Almacena el código compilado para ahorrar tiempo en caso de reiniciar la compilación.
Considere una función simple de Python en func.py.
def say_hello(name: str): print("Hello", name) print(f"How are you {name}?")
>>> from func import say_hello >>> say_hello("Batuhan") Hello Batuhan How are you Batuhan?
El
say_hello objeto
say_hello es una función.
>>> type(say_hello) <class 'function'>
Tiene el atributo
__code__ .
>>> say_hello.__code__ <code object say_hello at 0x7f13777d9150, file "/home/batuhan/blogs/cpython/exec_model/func.py", line 1>
Objetos de códigoLos objetos de código son estructuras de datos inmutables que contienen las instrucciones o metadatos necesarios para ejecutar el código. En pocas palabras, estas son representaciones de código Python. También puede obtener objetos de código compilando árboles de sintaxis abstracta utilizando el método de
compilación .
>>> import ast >>> code = """ ... def say_hello(name: str): ... print("Hello", name) ... print(f"How are you {name}?") ... say_hello("Batuhan") ... """ >>> tree = ast.parse(code, mode='exec') >>> code = compile(tree, '<string>', mode='exec') >>> type(code) <class 'code'>
Cada objeto de código tiene atributos que contienen cierta información (con el prefijo co_). Aquí mencionamos solo algunos de ellos.
co_namePara empezar, un nombre. Si existe una función, entonces debe tener un nombre, respectivamente, este nombre será el nombre de la función, una situación similar con la clase. En el ejemplo de AST, usamos módulos y podemos decirle al compilador exactamente cómo queremos nombrarlos. Que sean solo un
module .
>>> code.co_name '<module>' >>> say_hello.__code__.co_name 'say_hello'
co_varnamesEsta es una tupla que contiene todas las variables locales, incluidos los argumentos.
>>> say_hello.__code__.co_varnames ('name',)
co_contsUna tupla que contiene todos los literales y valores constantes a los que accedimos en el cuerpo de la función. Aquí vale la pena señalar el valor de Ninguno. No incluimos None en el cuerpo de la función, sin embargo, Python lo indicó, porque si la función comienza a ejecutarse y luego termina sin recibir ningún valor de retorno, devolverá None.
>>> say_hello.__code__.co_consts (None, 'Hello', 'How are you ', '?')
Bytecode (co_code)El siguiente es el bytecode de nuestra función.
>>> bytecode = say_hello.__code__.co_code >>> bytecode b't\x00d\x01|\x00\x83\x02\x01\x00t\x00d\x02|\x00\x9b\x00d\x03\x9d\x03\x83\x01\x01\x00d\x00S\x00'
Esto no es una cadena, es un objeto byte, es decir, una secuencia de bytes.
>>> type(bytecode) <class 'bytes'>
El primer carácter impreso es "t". Si solicitamos su valor numérico, obtenemos lo siguiente.
>>> ord('t') 116
116 es lo mismo que bytecode [0].
>>> assert bytecode[0] == ord('t')
Para nosotros, un valor de 116 no significa nada. Afortunadamente, Python proporciona una biblioteca estándar llamada dis (desde el desmontaje). Es útil cuando se trabaja con la lista de nombres de operación. Esta es una lista de todas las instrucciones de código de bytes, donde cada índice es el nombre de la instrucción.
>>> dis.opname[ord('t')] 'LOAD_GLOBAL'
Creemos otra función más compleja.
>>> def multiple_it(a: int): ... if a % 2 == 0: ... return 0 ... return a * 2 ... >>> multiple_it(6) 0 >>> multiple_it(7) 14 >>> bytecode = multiple_it.__code__.co_code
Y descubrimos la primera instrucción en bytecode.
>>> dis.opname[bytecode[0]] 'LOAD_FAST
La instrucción LOAD_FAST consta de dos elementos.
>>> dis.opname[bytecode[0]] + ' ' + dis.opname[bytecode[1]] 'LOAD_FAST <0>'
La instrucción Loadfast 0 busca buscar nombres de variables en una tupla y empuja un elemento con un índice cero a una tupla en la pila de ejecución.
>>> multiple_it.__code__.co_varnames[bytecode[1]] 'a'
Nuestro código se puede desmontar usando dis.dis y convertir el código de bytes a una vista familiar. Aquí los números (2,3,4) son los números de línea. Cada línea de código en Python se expande como un conjunto de instrucciones.
>>> dis.dis(multiple_it) 2 0 LOAD_FAST 0 (a) 2 LOAD_CONST 1 (2) 4 BINARY_MODULO 6 LOAD_CONST 2 (0) 8 COMPARE_OP 2 (==) 10 POP_JUMP_IF_FALSE 16 3 12 LOAD_CONST 2 (0) 14 RETURN_VALUE 4 >> 16 LOAD_FAST 0 (a) 18 LOAD_CONST 1 (2) 20 BINARY_MULTIPLY 22 RETURN_VALUE
Plazo de entregaCPython es una máquina virtual orientada a la pila, no una colección de registros. Esto significa que el código Python se compila para una máquina virtual con una arquitectura de pila.
Al llamar a una función, Python usa dos pilas juntas. La primera es la pila de ejecución, y la segunda es la pila de bloques. La mayoría de las llamadas ocurren en la pila de ejecución; la pila de bloques realiza un seguimiento de cuántos bloques están actualmente activos, así como otros parámetros relacionados con bloques y ámbitos.
Esperamos sus comentarios sobre el material y lo invitamos a
un seminario web abierto sobre el tema: "Libérelo: aspectos prácticos de la liberación de software confiable", que será realizado por nuestro maestro, el programador del sistema de publicidad en Mail.Ru,
Stanislav Stupnikov .