Conocer solo un enfoque para el raspado web resuelve el problema a corto plazo, pero todos los métodos tienen sus puntos fuertes y débiles. El conocimiento de esto ahorra tiempo y ayuda a resolver el problema de manera más eficiente.

Numerosos recursos hablan sobre el único método verdadero para recuperar datos de una página web. Pero la realidad es que para esto puede usar varias soluciones y herramientas.
- ¿Cuáles son las opciones para recuperar datos mediante programación de una página web?
- ¿Pros y contras de cada enfoque?
- ¿Cómo usar los recursos de la nube para aumentar el grado de automatización?
El artículo ayudará a obtener respuestas a estas preguntas.
Supongo que ya sabe qué son
las solicitudes
HTTP ,
DOM (Modelo de objetos de documento),
HTML ,
selectores CSS y
JavaScript asíncrono .
Si no, te aconsejo que profundices en la teoría y luego vuelvas al artículo.
Contenido estático
Fuentes HTMLComencemos con el enfoque más simple.
Si planea desechar páginas web, esto es lo primero para comenzar. Se requerirá poca energía de la computadora y un mínimo de tiempo.
Sin embargo, esto solo funciona si el código fuente HTML contiene los datos a los que se dirige. Para probar esto en Chrome, haga clic derecho en la página y seleccione Ver código de página. Ahora debería ver el código fuente HTML.
Una vez que encuentre los datos, escriba un
selector CSS que pertenezca al elemento de ajuste para que tenga un enlace más adelante.
Para la implementación, puede enviar una solicitud HTTP GET a la URL de la página y recuperar el código fuente HTML.
En
Node, puede usar la herramienta
CheerioJS para
analizar HTML sin procesar y recuperar datos utilizando un selector. El código se verá así:
const fetch = require('node-fetch'); const cheerio = require('cheerio'); const url = 'https://example.com/'; const selector = '.example'; fetch(url) .then(res => res.text()) .then(html => { const $ = cheerio.load(html); const data = $(selector); console.log(data.text()); });
Contenido dinámico
En muchos casos, no puede acceder a la información del código HTML sin procesar porque el DOM fue controlado por JavaScript que se ejecuta en segundo plano. Un ejemplo típico de esto es un SPA (aplicación de una sola página), donde un documento HTML contiene información mínima y JavaScript lo llena en tiempo de ejecución.
En esta situación, la solución es crear el DOM y ejecutar los scripts ubicados en el código fuente HTML, como lo hace el navegador. Después de eso, los datos se pueden extraer de este objeto utilizando selectores.
Navegadores sin cabezaEl navegador sin cabeza es igual que un navegador normal, solo que sin una interfaz de usuario. Se ejecuta en segundo plano y puede controlarlo mediante programación en lugar de hacer clic y escribir desde el teclado.
Puppeteer es uno de los navegadores sin cabeza más populares. Esta es una biblioteca de nodos fácil de usar que proporciona una API de alto nivel para administrar Chrome sin conexión. Se puede configurar para ejecutarse sin un encabezado, lo cual es muy conveniente durante el desarrollo. El siguiente código hace lo mismo que antes, pero funcionará con páginas dinámicas:
const puppeteer = require('puppeteer'); async function getData(url, selector){ const browser = await puppeteer.launch(); const page = await browser.newPage(); await page.goto(url); const data = await page.evaluate(selector => { return document.querySelector(selector).innerText; }, selector); await browser.close(); return data; } const url = 'https://example.com'; const selector = '.example'; getData(url,selector) .then(result => console.log(result));
Por supuesto, puedes hacer cosas más interesantes con Puppeteer, así que revisa la
documentación . Aquí hay un fragmento de código que navega por la URL, toma una captura de pantalla y la guarda:
const puppeteer = require('puppeteer'); async function takeScreenshot(url,path){ const browser = await puppeteer.launch(); const page = await browser.newPage(); await page.goto(url); await page.screenshot({path: path}); await browser.close(); } const url = 'https://example.com'; const path = 'example.png'; takeScreenshot(url, path);
El navegador requiere mucha más potencia informática que enviar una simple solicitud GET y analizar la respuesta. Por lo tanto, la ejecución es relativamente lenta. No solo eso, sino que también agregar un navegador como dependencia hace que el paquete sea masivo.
Por otro lado, este método es muy flexible. Puede usarlo para navegar por páginas, simular clics, movimientos del mouse y usar el teclado, completar formularios, crear capturas de pantalla o crear páginas PDF, ejecutar comandos en la consola, seleccionar elementos para extraer contenido de texto. Básicamente, todo lo que se puede hacer manualmente en un navegador.
Construyendo un DOMPensará que no es necesario simular un navegador completo solo para crear un DOM. De hecho, esto es cierto, al menos en ciertas circunstancias.
Jsdom es una biblioteca de nodos que analiza el HTML que se transmite, tal como lo hace un navegador. Sin embargo, este no es un navegador, sino una
herramienta para construir el DOM a partir de un código fuente HTML dado , así como para ejecutar código JavaScript en este HTML.
Gracias a esta abstracción, Jsdom puede ejecutarse más rápido que un navegador sin cabeza. Si es más rápido, ¿por qué no usarlo en lugar de navegadores sin cabeza todo el tiempo?
Cita de la documentación :
Las personas a menudo tienen problemas para cargar scripts asincrónicamente cuando usan jsdom. Muchas páginas cargan scripts de forma asincrónica, pero es imposible determinar cuándo sucedió esto y, por lo tanto, cuándo ejecutar el código y verificar la estructura DOM resultante. Esta es una limitación fundamental.
Esta solución se muestra en el ejemplo. Cada 100 ms, se verifica si ha aparecido un elemento o si ha ocurrido un tiempo de espera (después de 2 segundos).
También a menudo da mensajes de error cuando Jsdom no implementa algunas funciones del navegador en la página, como: "
Error: No implementado: window.alert ..." o "Error: No implementado: window.scrollTo ... ". Este problema también se puede resolver con algunas soluciones (
consolas virtuales ).
Esta suele ser una API de nivel inferior que Puppeteer, por lo que debe implementar algunas cosas usted mismo.
Esto complica un poco el uso, como se puede ver en el ejemplo.
Jsdom ofrece una solución rápida para el mismo trabajo.
Veamos el mismo ejemplo, pero usando
Jsdom :
const jsdom = require("jsdom"); const { JSDOM } = jsdom; async function getData(url,selector,timeout) { const virtualConsole = new jsdom.VirtualConsole(); virtualConsole.sendTo(console, { omitJSDOMErrors: true }); const dom = await JSDOM.fromURL(url, { runScripts: "dangerously", resources: "usable", virtualConsole }); const data = await new Promise((res,rej)=>{ const started = Date.now(); const timer = setInterval(() => { const element = dom.window.document.querySelector(selector) if (element) { res(element.textContent); clearInterval(timer); } else if(Date.now()-started > timeout){ rej("Timed out"); clearInterval(timer); } }, 100); }); dom.window.close(); return data; } const url = "https://example.com/"; const selector = ".example"; getData(url,selector,2000).then(result => console.log(result));
Ingeniería inversaJsdom es una solución rápida y fácil, pero puede hacerlo aún más simple.
¿Necesitamos modelar el DOM?
La página web que desea desechar consta de los mismos HTML y JavaScript, las mismas tecnologías que ya conoce. Por lo tanto,
si encuentra un fragmento de código del que se obtuvieron los datos de destino, puede repetir la misma operación para obtener el mismo resultado .
Para simplificar las cosas, los datos que está buscando podrían ser:
- parte del código fuente HTML (como se ve en la primera parte del artículo)
- parte de un archivo estático al que se hace referencia en un documento HTML (por ejemplo, una línea en un archivo javascript),
- respuesta a una solicitud de red (por ejemplo, algún código JavaScript envió una solicitud AJAX a un servidor que respondió con una cadena JSON).
Se puede acceder a estas fuentes de datos mediante consultas de red . No importa si la página web utiliza HTTP, WebSockets o cualquier otro protocolo de comunicación, porque todos son reproducibles en teoría.
Una vez que encuentre un recurso que contenga datos, puede enviar una solicitud de red similar al mismo servidor que la página original. Como resultado, obtendrá una respuesta que contiene los datos de destino, que pueden extraerse fácilmente mediante expresiones regulares, métodos de cadena, JSON.parse, etc.
En palabras simples, puede tomar el recurso en el que se encuentran los datos, en lugar de procesar y cargar todo el material. Por lo tanto, el problema que se muestra en los ejemplos anteriores se puede resolver con una sola solicitud HTTP en lugar de controlar un navegador o un objeto JavaScript complejo.
Esta solución parece simple en teoría, pero en la mayoría de los casos puede llevar mucho tiempo y requiere experiencia con páginas web y servidores.
Comience por monitorear el tráfico de red. Una gran herramienta para esto es la pestaña
Red en Chrome DevTools . Verá todas las solicitudes salientes con respuestas (incluidos archivos estáticos, solicitudes AJAX, etc.) para recorrerlas y buscar datos.
Si algún código cambia la respuesta antes de mostrarla en la pantalla, el proceso será más lento. En este caso, debe encontrar esta parte del código y comprender lo que está sucediendo.
Como puede ver, dicho método puede requerir mucho más trabajo que los métodos descritos anteriormente. Por otro lado, proporciona el mejor rendimiento.
El diagrama muestra el tiempo de ejecución requerido y el tamaño del paquete en comparación con Jsdom y Puppeteer:
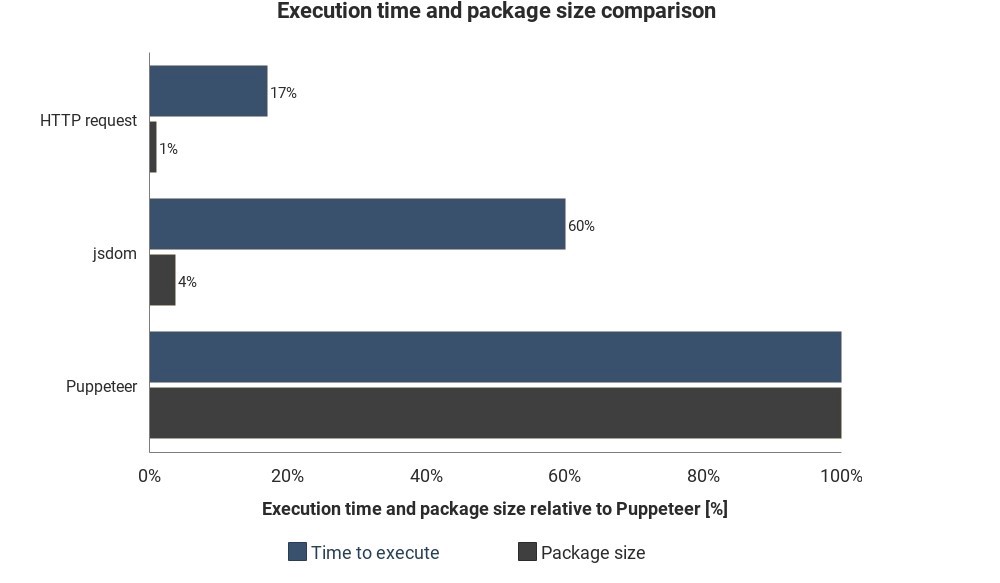
Los resultados no se basan en mediciones precisas y pueden variar, pero muestran buenas diferencias aproximadas entre estos métodos.
Integración de servicios en la nube
Supongamos que ha implementado una de estas soluciones. Una forma de ejecutar el script es encender la computadora, abrir el terminal e iniciarlo manualmente.
Pero se volverá molesto e ineficiente, por lo que sería mejor si solo pudiera cargar el script en el servidor y ejecutaría el código regularmente dependiendo de la configuración.
Esto se puede hacer iniciando el servidor real y estableciendo las reglas cuando ejecutar el script. En otros casos, la función de nube es una forma más fácil.
Las funciones en la nube son almacenamientos diseñados para ejecutar código descargado cuando ocurre un evento. Esto significa que no necesita administrar los servidores, esto lo hace automáticamente su proveedor de la nube.
Un desencadenante puede ser un horario, una solicitud de red y muchos otros eventos. Puede guardar los datos recopilados en una base de datos, escribirlos en una
hoja de Google o enviarlos por
correo electrónico . Todo depende de tu imaginación.
Proveedores en la nube populares:
Amazon Web Services (AWS),
Google Cloud Platform (GCP) y
Microsoft Azure :
Puede utilizar estos servicios de forma gratuita, pero no por mucho tiempo.
Si usa Puppeteer, las
funciones de Google Cloud son la solución más fácil. El tamaño del paquete en formato Chrome sin cabeza (~ 130 MB) excede el tamaño de archivo máximo permitido en AWS Lambda (50 MB). Hay varios métodos para que funcione con Lambda, pero las funciones de GCP son
compatibles con Chrome sin encabezado , solo debe incluir Puppeteer como una dependencia en
package.json .
Si desea obtener más información sobre las características de la nube en general, consulte la información de arquitectura sin servidor. Ya se han escrito muchos buenos tutoriales sobre este tema, y la mayoría de los proveedores tienen documentación fácil de entender.