
Te diré cómo logramos escribir un linter que resultó ser lo suficientemente rápido como para verificar los cambios durante cada git push y hacerlo en 5-10 segundos con una base de código de 5 millones de líneas en PHP. Lo llamamos NoVerify.
NoVerify admite cosas básicas, como la transición a la definición y la búsqueda de usos, y puede funcionar en modo
Servidor de idiomas . En primer lugar, nuestra herramienta se centra en la búsqueda de posibles errores, pero también puede verificar el estilo. Hoy, su código fuente apareció en código abierto en GitHub. Busque el enlace al final del artículo.
¿Por qué necesitamos nuestro linter?
A mediados de 2018, decidimos que era hora de implementar un linter para el código PHP. Había dos objetivos: reducir la cantidad de errores que ven los usuarios y supervisar más estrictamente el cumplimiento del estilo de código. El énfasis principal estaba en la prevención de errores típicos: la presencia de variables no declaradas y no utilizadas en el código, código inalcanzable y otros. También quería que el analizador estático funcionara lo más rápido posible en nuestra base de código (5-6 millones de líneas de código PHP en el momento de la escritura).
Como probablemente sepa, el código fuente de la mayor parte del sitio está escrito en PHP y compilado con
KPHP , por lo que sería lógico agregar estas comprobaciones al compilador. Pero, de hecho, no todo el código tiene sentido para ejecutarse a través de KPHP; por ejemplo, el compilador es débilmente compatible con bibliotecas de terceros, por lo que para algunas partes del sitio todavía se usa PHP normal. También son importantes y deben ser verificados por el linter, por lo que, desafortunadamente, no hay forma de integrarlo en KPHP.
Por qué NoVerify
Dada la cantidad de código PHP (le recordaré que esto es de 5 a 6 millones de líneas), no es posible "arreglarlo" de inmediato para que pase nuestros controles en la interfaz. Sin embargo, quiero que el código cambiante se vuelva gradualmente más limpio y siga más estrictamente los estándares de codificación, y también contenga menos errores. Por lo tanto, decidimos que la interfaz debería ser capaz de verificar los cambios que el desarrollador va a lanzar, y no maldecir el resto.
Para hacer esto, el linter necesita indexar todo el proyecto, analizar completamente los archivos antes y después de los cambios, y calcular la diferencia entre las advertencias generadas. Se muestran nuevas advertencias al desarrollador, y requerimos que se corrijan antes de que se pueda realizar la inserción.
Pero hay situaciones en las que este comportamiento no es deseable, y luego los desarrolladores pueden presionar sin enlaces locales, utilizando el
git push --no-verify . Opción
--no-verify y le dio un nombre a un linter :)
¿Cuáles fueron las alternativas?
La base de código en VK usa poca POO y básicamente consiste en funciones y clases con métodos estáticos. Si las clases en PHP admiten la carga automática, entonces las funciones no. Por lo tanto, no podemos usar analizadores estáticos sin modificaciones significativas, que basan su trabajo en el hecho de que la carga automática cargará todo el código faltante. Tales linters incluyen, por ejemplo, el
salmo de Vimeo .
Examinamos las siguientes herramientas de análisis estático:
- PHPStan : un solo subproceso, requiere carga automática, el análisis de base de código ha alcanzado el 30% en media hora;
- Phan : incluso en modo rápido con 20 procesos, el análisis se detuvo en un 5% después de 20 minutos;
- Salmo : requiere carga automática, el análisis tomó 10 minutos (todavía me gustaría ser mucho más rápido);
- PHPCS : comprueba el estilo, pero no la lógica;
- phpcf : solo verifica el formato.
Como puede adivinar por el título del artículo, ninguna de estas herramientas satisface nuestros requisitos, por lo que escribimos el nuestro.
¿Cómo se creó el prototipo?
Primero, decidimos construir un pequeño prototipo para comprender si vale la pena intentar hacer un linter completo. Dado que uno de los requisitos importantes para el linter es su velocidad, en lugar de PHP, elegimos Go. "Rápido" es dar retroalimentación al desarrollador lo más rápido posible, preferiblemente en no más de 10-20 segundos. De lo contrario, el ciclo "corrige el código, ejecuta el linter de nuevo" comienza a ralentizar significativamente el desarrollo y estropea el estado de ánimo de las personas :)
Como Go está seleccionado para el prototipo, necesita un analizador PHP. Hay varios de ellos, pero el proyecto
php-parser nos pareció el más maduro. Este analizador no es perfecto y todavía se está desarrollando, pero para nuestros propósitos es bastante adecuado.
Para el prototipo, se decidió intentar implementar una de las inspecciones más simples, a primera vista: acceso a una variable indefinida.
La idea básica para implementar dicha inspección parece simple: para cada rama (por ejemplo, para if), cree un ámbito anidado separado y combine los tipos de variables a la salida de él. Un ejemplo:
<?php if (rand()) { $a = 42;
Se ve simple, ¿verdad? En el caso de las declaraciones condicionales ordinarias, todo funciona bien. Pero debemos manejar, por ejemplo, cambiar sin interrupción;
<?php switch (rand()) { case 1: $a = 1;
El código no aclara de inmediato que $ c siempre se definirá. Específicamente, este ejemplo es ficticio, pero ilustra bien qué momentos difíciles son para la peluquera (y para la persona en este caso también).
Considere un ejemplo más complejo:
<?php exec("hostname", $out, $retval); echo $out, $retval;
Sin conocer la firma de la función ejecutiva, no se puede decir si se definirán $ out y $ retval. Las firmas de las funciones integradas se pueden tomar del repositorio
github.com/JetBrains/phpstorm-stubs . Pero se producirán los mismos problemas al llamar a funciones definidas por el usuario, y su firma solo se puede encontrar indexando todo el proyecto. La función exec toma los argumentos segundo y tercero por referencia, lo que significa que se pueden definir las variables $ out y $ retval. Aquí, acceder a estas variables no es necesariamente un error, y la interfaz no debe jurar ante dicho código.
Problemas similares con el paso implícito de enlaces surgen con los métodos, pero al mismo tiempo, se agrega la necesidad de deducir los tipos de variables:
<?php if (rand()) { $a = some_func(); } else { $a = other_func(); } $a->some_method($b); echo $b;
Necesitamos saber qué tipos devuelven las funciones some_func () y other_func () para luego encontrar un método llamado some_method en estas clases. Solo entonces podemos decir si la variable $ b se definirá o no. La situación se complica por el hecho de que a menudo las funciones y métodos simples no tienen anotaciones phpdoc, por lo que aún debe poder calcular los tipos de funciones y métodos en función de su implementación.
Al desarrollar el prototipo, tuve que implementar aproximadamente la mitad de toda la funcionalidad para que la inspección más simple funcionara como debería.
Trabaja como un servidor de idiomas
Para facilitar la depuración de la lógica de la interfaz y ver las advertencias que emite, decidimos agregar el modo operativo como un
servidor de lenguaje para PHP . En modo de integración con Visual Studio Code, se ve así:
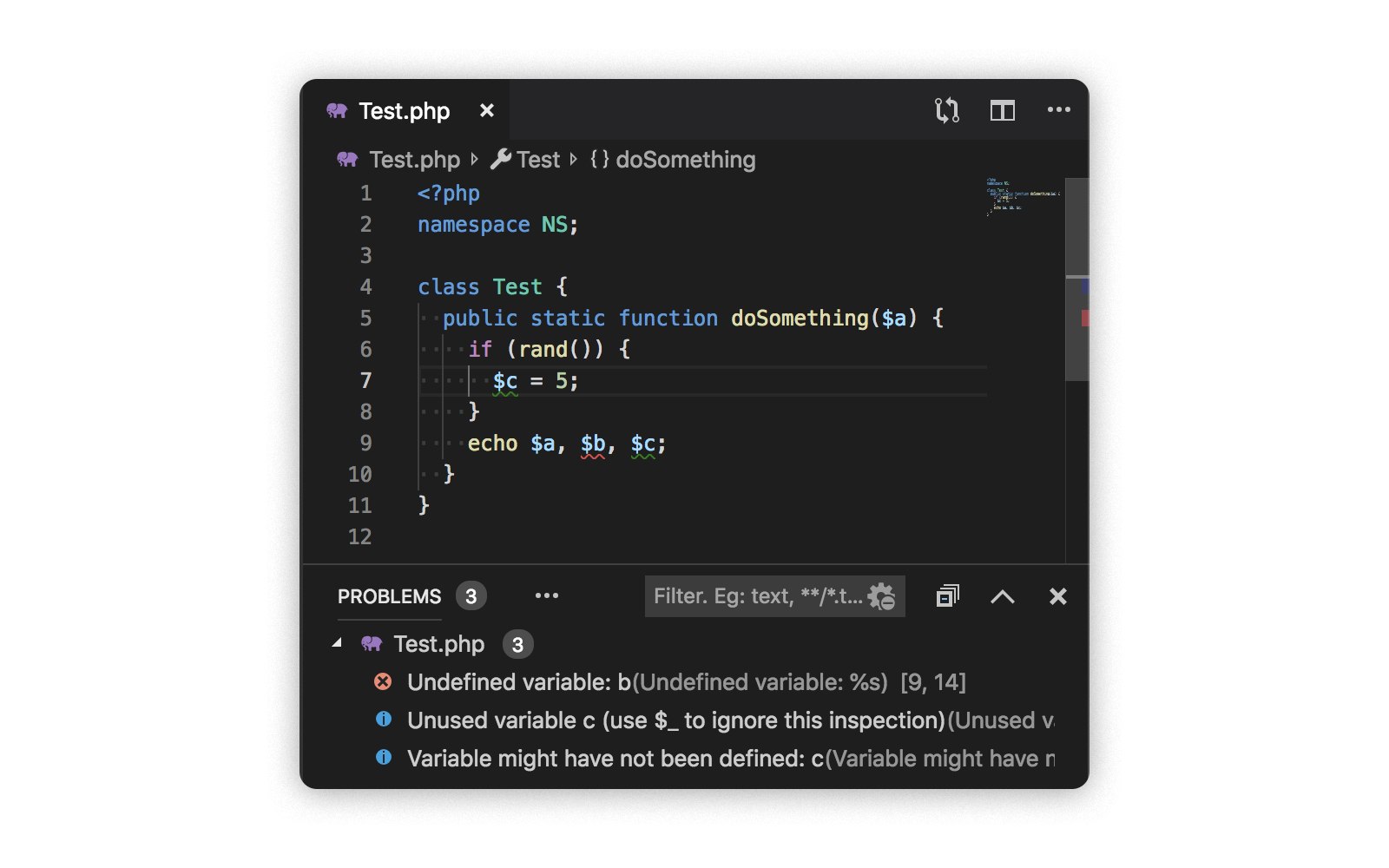
En este modo, es conveniente probar hipótesis y probar casos complejos (después de eso, debe escribir pruebas, por supuesto). También es bueno probar el rendimiento: incluso en archivos grandes, php-parser on Go muestra buena velocidad.
El soporte del servidor de idiomas está lejos de ser ideal, ya que su propósito principal es depurar las reglas de la interfaz. Sin embargo, en este modo hay varias características adicionales:
- Consejos para nombres de variables, constantes, funciones, propiedades y métodos.
- Resalte los tipos derivados de variables.
- Ve a la definición.
- Búsqueda de usos.
Inferencia de tipo "perezosa"
En el modo de servidor de idiomas, se requiere lo siguiente para trabajar: cambia el código en un archivo y luego, cuando cambia a otro, debe trabajar con información ya actualizada sobre qué tipos se devuelven en funciones o métodos. Imagine que los archivos se editan en el siguiente orden:
<?php
Dado que no forzamos a los desarrolladores a escribir siempre PHPDoc (especialmente en casos tan simples), necesitamos una forma de almacenar información sobre qué tipo devuelve la función B :: something (). De modo que cuando el archivo A.php cambia, la información de tipo en el archivo C.php está inmediatamente actualizada.
Una posible solución es almacenar "tipos perezosos". Por ejemplo, el tipo de retorno del método B :: something () es en realidad un tipo de expresión (nueva A) -> prop. De esta forma, el linter almacena información sobre el tipo y, gracias a esto, puede almacenar en caché toda la metainformación para cada archivo y actualizarla solo cuando este archivo cambie. Esto debe hacerse con cuidado para que accidentalmente no se filtre información demasiado específica sobre los tipos. También es necesario cambiar la versión de caché cuando cambia la lógica de inferencia de tipo. Sin embargo, tal caché acelera la fase de indexación (que analizaré más adelante) entre 5 y 10 veces en comparación con el análisis repetido de todos los archivos.
Dos fases de trabajo: indexación y análisis.
Como recordamos, incluso para el análisis de código más simple, se requiere información al menos sobre todas las funciones y métodos en el proyecto. Esto significa que no puede analizar solo un archivo por separado del proyecto. Y, sin embargo, que esto no se puede hacer de una sola vez: por ejemplo, PHP le permite acceder a funciones que se declaran más adelante en el archivo.
Debido a estas limitaciones, el funcionamiento de linter consta de dos fases: indexación primaria y posterior análisis de solo los archivos necesarios. Ahora más sobre estas dos fases.
Fase de indexación
En esta fase, se analizan todos los archivos y se realiza un análisis local del código de métodos y funciones, así como el código en el nivel superior (por ejemplo, para determinar los tipos de variables globales). La información sobre las variables globales declaradas, constantes, funciones, clases y sus métodos se recopila y escribe en la memoria caché. Para cada archivo en el proyecto, el caché es un archivo separado en el disco.
Se compila un diccionario global de toda la metainformación sobre el proyecto, que no cambia en el futuro, * a partir de piezas individuales.
* Además del modo de operación como servidor de idiomas, cuando se realiza la indexación y el análisis del archivo modificado para cada edición.Fase de análisis
En esta fase, podemos usar metainformación (sobre funciones, clases ...) y ya analizar directamente el código. Aquí hay una lista de lo que NoVerify puede verificar por defecto:
- código inalcanzable;
- acceso a objetos como una matriz;
- número insuficiente de argumentos al llamar a la función;
- llamar a un método / función indefinido;
- acceso a la propiedad de clase faltante / constante;
- falta de clase;
- PHPDoc inválido
- acceso a una variable indefinida;
- acceso a una variable que no siempre está definida;
- falta de "descanso"; después del caso en las construcciones switch / case;
- error de sintaxis
- variable no utilizada
La lista es bastante corta, pero puede agregar controles específicos para su proyecto.
Durante el funcionamiento del linter, resultó que la inspección más útil es solo la última (variable no utilizada). Esto sucede a menudo cuando refactoriza el código (o escribe uno nuevo) y lo sella con el nombre de la variable: este código es válido desde el punto de vista de PHP, pero es erróneo en lógica.
Velocidad de trabajo
¿Cuánto tiempo se verifica el cambio que queremos impulsar? Todo depende de la cantidad de archivos. Con NoVerify, el proceso puede tomar hasta un minuto (fue cuando cambié 1400 archivos en el repositorio), pero si hubo pocas ediciones, generalmente todas las comprobaciones pasan en 4-5 segundos. Durante este tiempo, el proyecto está completamente indexado, analizando nuevos archivos, así como su análisis. Pudimos crear un linter para PHP, que funciona rápidamente incluso con nuestra gran base de código.
Cual es el resultado?
Dado que la solución está escrita en Go, es necesario usar el repositorio
github.com/JetBrains/phpstorm-stubs para tener definiciones de todas las funciones y clases integradas en PHP. A cambio, obtuvimos una alta velocidad de trabajo (indexando 1 millón de líneas por segundo, análisis de 100 mil líneas por segundo) y pudimos agregar cheques con un linter como uno de los primeros pasos en ganchos de empuje git.
Se desarrolló una base conveniente para crear nuevas inspecciones y se logró un nivel de comprensión del código cercano a PHPStorm. Debido al hecho de que es compatible con el modo con cálculo de diferencias, es posible mejorar gradualmente el código, evitando nuevas construcciones potencialmente problemáticas en el nuevo código.
Contar diff no es lo ideal: por ejemplo, si un archivo grande se dividió en varios pequeños, entonces git y, por lo tanto, NoVerify, no podrán determinar si el código se movió, y el linter requerirá corregir todos los problemas encontrados. En este sentido, el cálculo de diff evita la refactorización a gran escala, por lo que en tales casos a menudo se desactiva.
Escribir un linter en Go tiene una ventaja más: no solo el analizador AST es más rápido y consume menos memoria que en PHP, sino que el análisis posterior también es muy rápido en comparación con cualquier cosa que se pueda hacer en PHP. Esto significa que nuestro linter puede realizar un análisis más complejo y profundo del código, mientras mantiene un alto rendimiento (por ejemplo, la función "tipos diferidos" requiere una cantidad bastante grande de cálculos en el proceso).
Código abierto
NoVerify disponible en código abierto en GitHub¡Disfruta de tu uso en tu proyecto!
UPD: preparé una
demostración que funciona a través de WebAssembly . La única limitación de esta demostración es la falta de definiciones de funciones de phpstorm-stubs, por lo que linter jurará sobre las funciones integradas.
Yuri Nasretdinov, desarrollador del departamento de infraestructura de VKontakte