
¿Qué es lo que más te molesta cuando piensas en iniciar sesión en NodeJS? Si me preguntas, diré que no hay estándares de la industria para crear ID de rastreo. En este artículo, veremos cómo podemos crear estos ID de rastreo (lo que significa que examinaremos brevemente cómo funciona el almacenamiento local de continuación, también conocido como CLS ) y profundizaremos en cómo podemos utilizar Proxy para que funcione con CUALQUIER registrador.
¿Por qué es incluso un problema tener un ID de rastreo para cada solicitud en NodeJS?
Bueno, en plataformas que usan subprocesos múltiples y generan un nuevo subproceso para cada solicitud. Hay una cosa llamada almacenamiento local de subprocesos, también conocido como TLS , que permite mantener cualquier información arbitraria disponible para cualquier cosa dentro de un subproceso. Si tiene una API nativa para hacerlo, es bastante trivial generar una ID aleatoria para cada solicitud, colóquela en TLS y úsela en su controlador o servicio más adelante. Entonces, ¿cuál es el trato con NodeJS?
Como saben, NodeJS es una plataforma de un solo subproceso (ya no es cierto ya que ahora tenemos trabajadores, pero eso no cambia el panorama general), lo que hace que TLS sea obsoleto. En lugar de operar diferentes subprocesos, NodeJS ejecuta diferentes devoluciones de llamada dentro del mismo subproceso (hay una gran serie de artículos sobre el bucle de eventos en NodeJS si está interesado) y NodeJS nos proporciona una manera de identificar de forma única estas devoluciones de llamada y rastrear sus relaciones entre sí .
En los viejos tiempos (v0.11.11) teníamos addAsyncListener que nos permitía rastrear eventos asincrónicos. Sobre esta base, Forrest Norvell creó la primera implementación de almacenamiento local de continuación, también conocido como CLS . No vamos a cubrir esa implementación de CLS debido al hecho de que nosotros, como desarrolladores, ya fuimos despojados de esa API en v0.12.
Hasta NodeJS 8 no teníamos una forma oficial de conectarnos al procesamiento de eventos asíncronos de NodeJS. Y finalmente NodeJS 8 nos otorgó el poder que perdimos a través de async_hooks (si desea obtener una mejor comprensión de async_hooks, eche un vistazo a este artículo ). Esto nos lleva a la implementación moderna basada en async_hooks de CLS - cls-hooked .
Resumen de CLS
Aquí hay un flujo simplificado de cómo funciona CLS:
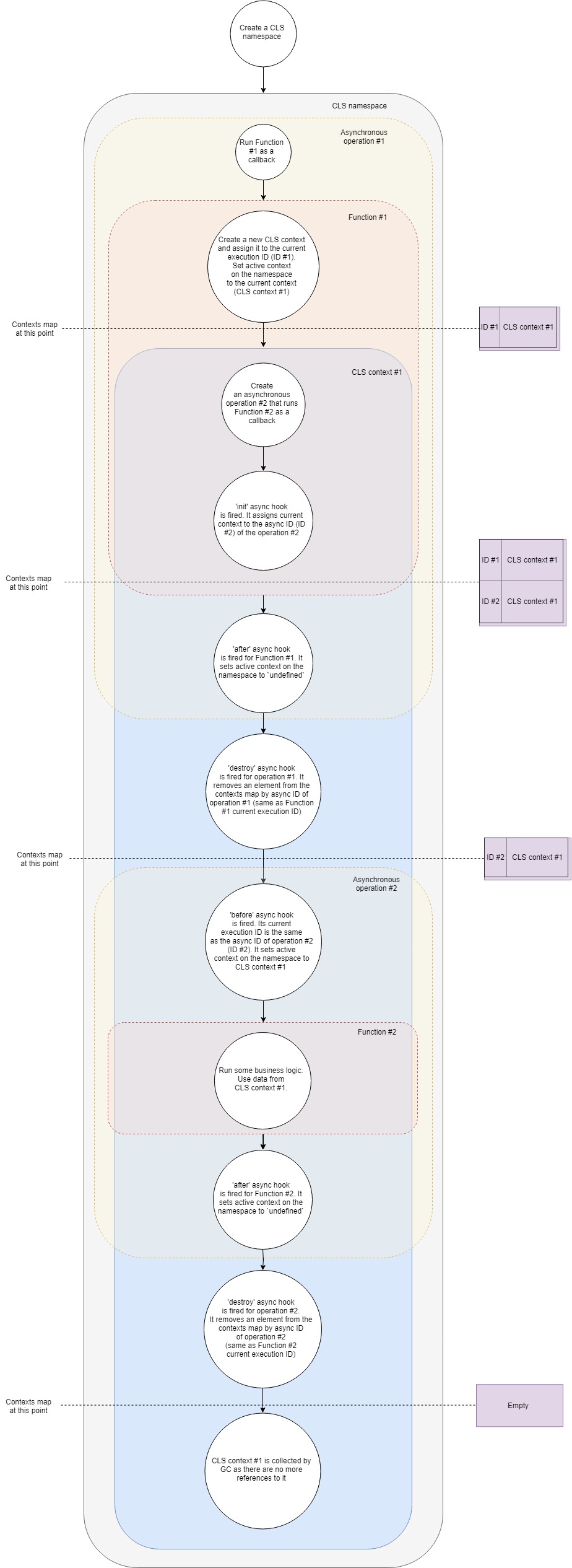
Vamos a desglosarlo paso a paso:
- Digamos que tenemos un servidor web típico. Primero tenemos que crear un espacio de nombres CLS. Una vez para toda la vida de nuestra aplicación.
- En segundo lugar, tenemos que configurar un middleware para crear un nuevo contexto CLS para cada solicitud. Para simplificar, supongamos que este middleware es solo una devolución de llamada que se llama al recibir una nueva solicitud.
- Entonces, cuando llega una nueva solicitud, llamamos a esa función de devolución de llamada.
- Dentro de esa función, creamos un nuevo contexto CLS (una de las formas es utilizar ejecutar la llamada a la API).
- En este punto, CLS coloca el nuevo contexto en un mapa de contextos por ID de ejecución actual .
- Cada espacio de nombres CLS tiene propiedad
active . En esta etapa, CLS asigna active al contexto. - Dentro del contexto, hacemos una llamada a un recurso asíncrono, por ejemplo, solicitamos algunos datos de la base de datos. Pasamos una devolución de llamada a la llamada, que se ejecutará una vez que se complete la solicitud a la base de datos.
- el gancho asíncrono init se activa para una nueva operación asincrónica. Agrega el contexto actual al mapa de contextos por ID asíncrono (considérelo un identificador de la nueva operación asincrónica).
- Como no tenemos más lógica dentro de nuestra primera devolución de llamada, finaliza efectivamente nuestra primera operación asincrónica.
- después de que se active el enlace asíncrono para la primera devolución de llamada. Establece el contexto activo en el espacio de nombres como
undefined (no siempre es cierto ya que podemos tener múltiples contextos anidados, pero para el caso más simple es cierto). - Desbloquear gancho se dispara para la primera operación. Elimina el contexto de nuestro mapa de contextos por su ID asíncrona (es lo mismo que la ID de ejecución actual de nuestra primera devolución de llamada).
- La solicitud a la base de datos ha finalizado y nuestra segunda devolución de llamada está a punto de activarse.
- En este punto, antes de que el gancho asíncrono entre en juego. Su ID de ejecución actual es la misma que la ID asíncrona de la segunda operación (solicitud de base de datos). Establece
active propiedad active del espacio de nombres en el contexto encontrado por su ID de ejecución actual. Es el contexto que creamos antes. - Ahora ejecutamos nuestra segunda devolución de llamada. Ejecutar un poco de lógica de negocios en el interior. Dentro de esa función, podemos obtener cualquier valor por clave del CLS y devolverá lo que encuentre por la clave en el contexto que creamos antes.
- Suponiendo que es el final del procesamiento de la solicitud, nuestra función regresa.
- después de que se active el enlace asíncrono para la segunda devolución de llamada. Establece el contexto activo en el espacio de nombres como
undefined . destroy gancho se dispara para la segunda operación asincrónica. Elimina nuestro contexto del mapa de contextos por su ID asíncrono, dejándolo absolutamente vacío.- Como ya no tenemos referencias al objeto de contexto, nuestro recolector de basura libera la memoria asociada a él.
Es una versión simplificada de lo que sucede debajo del capó, pero cubre todos los pasos principales. Si quieres profundizar más, puedes echar un vistazo al código fuente . Son menos de 500 líneas.
Generando ID de rastreo
Entonces, una vez que tengamos una comprensión general de CLS, pensemos cómo podemos utilizarlo para nuestro propio bien. Una cosa que podríamos hacer es crear un middleware que envuelva cada solicitud en un contexto, genere un identificador aleatorio y lo traceID en CLS por la clave traceID . Más tarde, dentro de uno de nuestros millones de controladores y servicios podríamos obtener ese identificador de CLS.
Para expresar este middleware podría verse así:
const cls = require('cls-hooked') const uuidv4 = require('uuid/v4') const clsNamespace = cls.createNamespace('app') const clsMiddleware = (req, res, next) => {
Luego, en nuestro controlador, podríamos obtener el ID de rastreo generado de esta manera:
const controller = (req, res, next) => { const traceID = clsNamespace.get('traceID') }
No hay mucho uso de este ID de rastreo a menos que lo agreguemos a nuestros registros.
Añádalo a nuestro winston .
const { createLogger, format, transports } = require('winston') const addTraceId = printf((info) => { let message = info.message const traceID = clsNamespace.get('taceID') if (traceID) { message = `[TraceID: ${traceID}]: ${message}` } return message }) const logger = createLogger({ format: addTraceId, transports: [new transports.Console()], })
Bueno, si todos los registradores admitieran formateadores en una forma de funciones (muchos de ellos no lo hacen por una buena razón) este artículo no existiría. Entonces, ¿cómo agregaría una identificación de rastreo a mi amado pino ? Proxy al rescate!
Combinando Proxy y CLS
Proxy es un objeto que envuelve nuestro objeto original y nos permite anular su comportamiento en ciertas situaciones. La lista de estas situaciones (en realidad se llaman trampas) es limitada y puede ver todo el conjunto aquí , pero solo estamos interesados en atrapar trampas. Nos proporciona la capacidad de interceptar el acceso a la propiedad. Significa que si tenemos un objeto const a = { prop: 1 } y lo envolvemos en un Proxy, con get trap podríamos devolver lo que queramos para a.prop .
Por lo tanto, la idea es generar un ID de rastreo aleatorio para cada solicitud y crear un registrador de pino secundario con el ID de rastreo y ponerlo en CLS. Entonces podríamos envolver nuestro registrador original con un Proxy, que redirigiría todas las solicitudes de registro al registrador secundario en CLS si se encuentra uno y seguiría usando el registrador original de lo contrario.
En este escenario, nuestro Proxy podría verse así:
const pino = require('pino') const logger = pino() const loggerCls = new Proxy(logger, { get(target, property, receiver) {
Nuestro middleware se transformaría en algo como esto:
const cls = require('cls-hooked') const uuidv4 = require('uuid/v4') const clsMiddleware = (req, res, next) => {
Y podríamos usar el registrador de esta manera:
const controller = (req, res, next) => { loggerCls.info('Long live rocknroll!')
Basado en la idea anterior, se creó una pequeña biblioteca llamada cls-proxify . Tiene integración con express , koa y fastify fuera de la caja.
Se aplica no solo get trap al objeto original, sino también a muchos otros . Entonces hay infinitas aplicaciones posibles. Podrías llamar a funciones proxy, construcción de clases, ¡casi cualquier cosa! ¡Estás limitado solo por tu imaginación!
Eche un vistazo a las demostraciones en vivo de su uso con pino y fastify, pino y express .
Con suerte, has encontrado algo útil para tu proyecto. ¡No dudes en comunicarme tus comentarios! Aprecio mucho cualquier crítica y pregunta.