
¿Qué es lo que más te enfurece cuando intentas organizar registros legibles en tu aplicación NodeJS? Personalmente, estoy extremadamente molesto por la falta de estándares maduros razonables para crear ID de rastreo. En este artículo, hablaremos sobre las opciones para crear un ID de rastreo, echemos un vistazo a cómo funciona el almacenamiento local de continuación o CLS en nuestros dedos y recurramos a la fuerza de Proxy para obtener todo con absolutamente cualquier registrador.
¿Por qué hay algún problema en NodeJS con la creación de un ID de rastreo para cada solicitud?
En los viejos, viejos, viejos tiempos, cuando los mamuts aún caminaban por la tierra, los servidores de todo-todo-todo eran multihilo y creaban un nuevo hilo para una solicitud. Dentro del marco de este paradigma, crear una identificación de rastreo es trivial, porque Existe el almacenamiento local de subprocesos o TLS , que le permite guardar en la memoria algunos datos disponibles para cualquier función en esta secuencia. Al comienzo del procesamiento de la solicitud, puede canjear el ID de rastreo aleatorio, ponerlo en TLS y luego leerlo en cualquier servicio y hacer algo con él. El problema es que esto no funcionará en NodeJS.
NodeJS es de un solo subproceso (no del todo, dada la apariencia de los trabajadores, pero dentro del marco del problema con la identificación de rastreo, los trabajadores no juegan ningún papel), por lo que puede olvidarse de TLS. Aquí el paradigma es diferente: hacer malabarismos con varias devoluciones de llamada diferentes dentro del mismo hilo, y tan pronto como la función quiera hacer algo asincrónico, envíe esta solicitud asincrónica y dele tiempo al procesador a otra función en la cola (si está interesado en cómo funciona esta cosa, orgullosamente llamada Event Loop) debajo del capó, recomiendo leer esta serie de artículos ). Si piensa en cómo NodeJS entiende a qué devolución de llamada llamar, puede suponer que cada uno de ellos debe corresponder a algún ID. Además, NodeJS incluso tiene una API que proporciona acceso a estos ID. Lo usaremos
En la antigüedad, cuando los mamuts se extinguieron, pero la gente aún no conocía los beneficios de las aguas residuales centrales (NodeJS v0.11.11) teníamos addAsyncListener . Sobre esta base, Forrest Norvell creó la primera implementación de almacenamiento local de continuación o CLS . Pero no hablaremos sobre cómo funcionó, ya que esta API (estoy hablando de addAsyncLustener) ordenó una larga vida. Él ya murió en NodeJS v0.12.
Antes de NodeJS 8, no había una forma oficial de realizar un seguimiento de la cola de eventos asincrónicos. Y finalmente, en la versión 8, los desarrolladores de NodeJS restauraron la justicia y nos presentaron la API async_hooks . Si desea obtener más información sobre async_hooks, le recomiendo que lea este artículo . Basado en async_hooks, se realizó la refactorización de la implementación anterior de CLS. La biblioteca se llama cls-hooked .
CLS debajo del capó
En términos generales, el esquema de operación de CLS se puede representar de la siguiente manera:
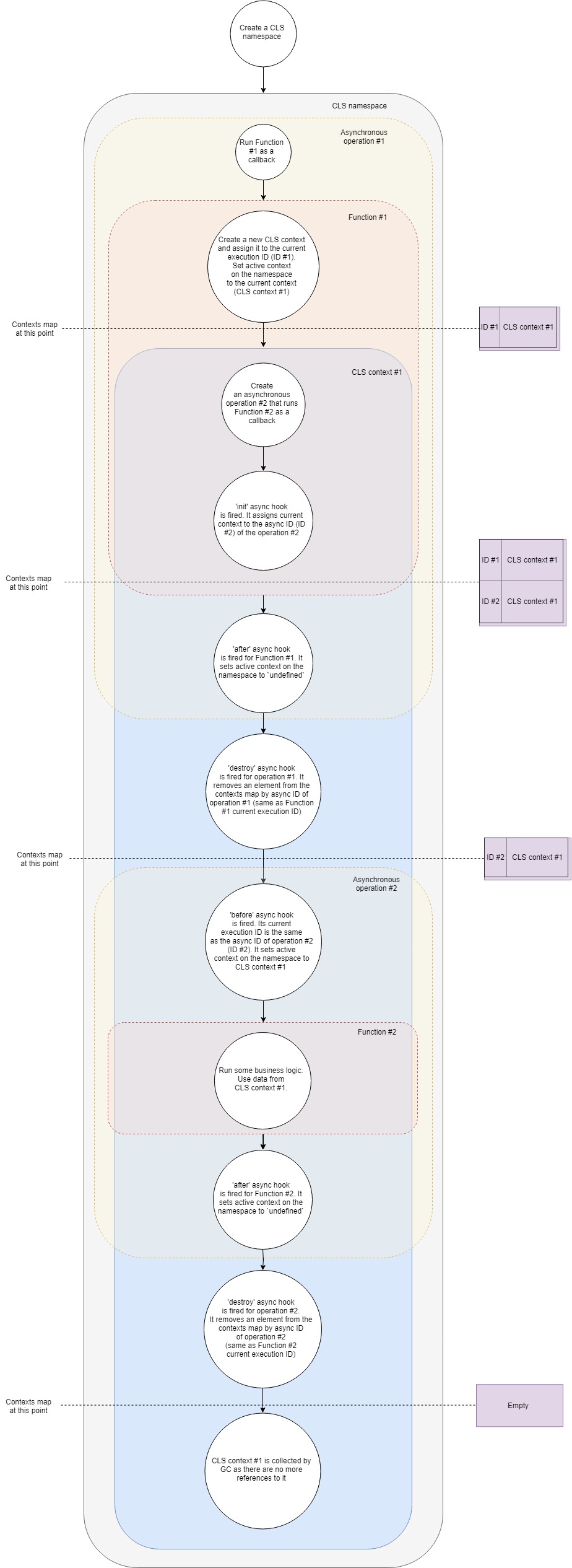
Veamos un poco más en detalle:
- Supongamos que tenemos un servidor web Express típico. Primero, cree un nuevo espacio de nombres CLS. Una vez y para toda la vida de la aplicación.
- En segundo lugar, crearemos middleware, que creará nuestro propio contexto CLS para cada solicitud.
- Cuando llega una nueva solicitud, se llama a este middleware (Función # 1).
- En esta función, cree un nuevo contexto CLS (como una opción, puede usar Namespace.run ). En Namespace.run pasamos una función que se ejecutará en el ámbito de nuestro contexto.
- CLS agrega un contexto recién creado a Map con contextos con la clave de ID de ejecución actual .
- Cada espacio de nombres CLS tiene una propiedad
active . CLS asigna a esta propiedad una referencia a nuestro contexto. - En un ámbito de contexto, realizamos algún tipo de consulta asincrónica, por ejemplo, a la base de datos. Pasamos la devolución de llamada al controlador de la base de datos, que se llamará cuando se complete la solicitud.
- El gancho de arranque asíncrono se dispara . Agrega el contexto actual al Mapa con contextos por ID asíncrono (ID de la nueva operación asincrónica).
- Porque nuestra función ya no tiene instrucciones adicionales; completa la ejecución.
- Un gancho asíncrono después funciona para ella. Asigna la propiedad
active al espacio de nombres undefined (de hecho, no siempre, porque podemos tener varios contextos anidados, pero para el caso más simple es). - El anzuelo asincrónico destruye incendios para nuestra primera operación asincrónica. Elimina el contexto del Mapa con contextos mediante el ID asíncrono de esta operación (es el mismo que el ID de ejecución actual de la primera devolución de llamada).
- La consulta en la base de datos se completa y se llama a la segunda devolución de llamada.
- Gancho asincrónico antes . Su ID de ejecución actual es la misma que la ID asíncrona de la segunda operación (consulta de la base de datos). A
active propiedad active espacio de nombres se le asigna el contexto que se encuentra en el Mapa con contextos por ID de ejecución actual. Este es el contexto que creamos antes. - Ahora se ejecuta la segunda devolución de llamada. Algún tipo de lógica de negocios está funcionando, los demonios están bailando, el vodka está vertiendo. Dentro de esto, podemos obtener cualquier valor del contexto por clave . CLS intentará encontrar la clave dada en el contexto actual o volverá
undefined . - El enlace posterior asíncrono para esta devolución de llamada se activa cuando se completa. Establece la propiedad
active del espacio de nombres en undefined . - El gancho de disparo asíncrono destruye para esta operación. Elimina el contexto del Mapa con contextos mediante el ID asíncrono de esta operación (es el mismo que el ID de ejecución actual de la segunda devolución de llamada).
- El recolector de basura (GC) libera memoria asociada con el objeto de contexto, porque en nuestra aplicación no hay más enlaces a ella.
Esta es una vista simplificada de lo que sucede debajo del capó, pero cubre las fases y pasos principales. Si desea profundizar un poco más, le recomiendo que se familiarice con el tipo . Solo hay 500 líneas de código.
Crear ID de rastreo
Entonces, habiendo tratado con el CLS, intentaremos usar esto para el beneficio de la humanidad. Creemos middleware, que para cada solicitud crea su propio contexto CLS, crea un ID de rastreo aleatorio y lo agrega al contexto utilizando la clave traceID . Luego, dentro del ofigilliard de nuestros controladores y servicios, obtenemos esta identificación de rastreo.
Para express, un middleware similar podría verse así:
const cls = require('cls-hooked') const uuidv4 = require('uuid/v4') const clsNamespace = cls.createNamespace('app') const clsMiddleware = (req, res, next) => {
Y en nuestro controlador o servicio, podemos obtener este traceID en una sola línea de código:
const controller = (req, res, next) => { const traceID = clsNamespace.get('traceID') }
Es cierto que sin agregar esta identificación de rastreo a los registros, se beneficia de ella, como de un quitanieves en el verano.
Escribamos un formateador simple de Winston que agregará la identificación de rastreo automáticamente.
const { createLogger, format, transports } = require('winston') const addTraceId = printf((info) => { let message = info.message const traceID = clsNamespace.get('taceID') if (traceID) { message = `[TraceID: ${traceID}]: ${message}` } return message }) const logger = createLogger({ format: addTraceId, transports: [new transports.Console()], })
Y si todos los registradores admitieran formateadores personalizados en forma de funciones (muchos de ellos tienen razones para no hacerlo), entonces este artículo probablemente no lo hubiera sido. Entonces, ¿cómo podría agregar una identificación de rastreo a los registros del pino adorado?
Hacemos un llamado a Proxy para hacer amigos CUALQUIER registrador y CLS
Algunas palabras sobre Proxy en sí: esto es algo que envuelve nuestro objeto original y nos permite redefinir su comportamiento en ciertas situaciones. En una lista limitada de situaciones estrictamente definida (en ciencia se llaman traps ). Puede encontrar la lista completa aquí , solo estamos interesados en trap get . Nos da la oportunidad de anular el valor de retorno al acceder a la propiedad del objeto, es decir. si tomamos el objeto const a = { prop: 1 } y lo envolvemos en Proxy, con la ayuda de trap get podemos devolver todo lo que queramos cuando llamamos a.prop .
En el caso de pino idea es la siguiente: creamos un ID de rastreo aleatorio para cada solicitud, creamos una instancia secundaria de pino en la que pasamos este ID de rastreo y colocamos esta instancia secundaria en el CLS. Luego envolvemos nuestro registrador de origen en Proxy, que usará esta misma instancia secundaria para el registro, si hay un contexto activo y hay un registrador secundario, o use el registrador original.
Para tal caso, el proxy se verá así:
const pino = require('pino') const logger = pino() const loggerCls = new Proxy(logger, { get(target, property, receiver) {
Nuestro middleware se verá así:
const cls = require('cls-hooked') const uuidv4 = require('uuid/v4') const clsMiddleware = (req, res, next) => {
Y podemos usar el registrador de esta manera:
const controller = (req, res, next) => { loggerCls.info('Long live rocknroll!')
Basado en la idea anterior, se creó una pequeña biblioteca cls-proxify . Ella trabaja fuera de la caja con express , koa y fastify . Además de crear trampa para get , crea otras trampas para dar al desarrollador más libertad. Debido a esto, podemos usar Proxy para ajustar funciones, clases y más. Hay una demostración en vivo sobre cómo integrar pino y fastify, pino y express .
Espero que no hayas perdido el tiempo en vano, y el artículo fue al menos un poco útil para ti. Por favor patea y critica. Aprenderemos a codificar mejor juntos.